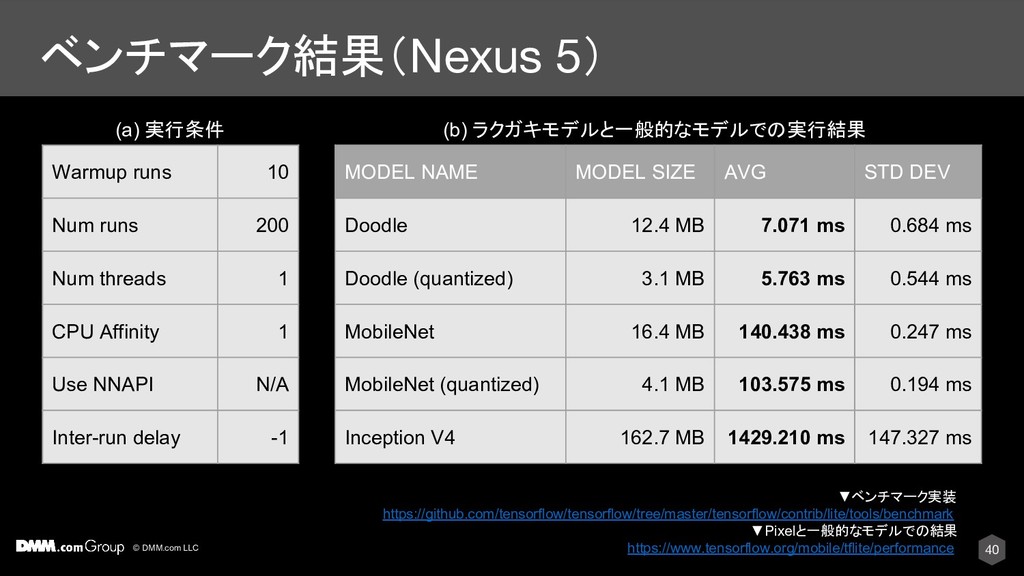
200 Num threads 1 CPU Affinity 1 Use NNAPI N/A Inter-run delay -1 MODEL NAME MODEL SIZE AVG STD DEV Doodle 12.4 MB 7.071 ms 0.684 ms Doodle (quantized) 3.1 MB 5.763 ms 0.544 ms MobileNet 16.4 MB 140.438 ms 0.247 ms MobileNet (quantized) 4.1 MB 103.575 ms 0.194 ms Inception V4 162.7 MB 1429.210 ms 147.327 ms (a) 実行条件 (b) ラクガキモデルと一般的なモデルでの実行結果 ▼ベンチマーク実装 https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite/tools/benchmark ▼Pixelと一般的なモデルでの結果 https://www.tensorflow.org/mobile/tflite/performance 40
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© DMM.com LLC サンプル実装 https://github.com/maru-labo/doodle/blob/master/examples/tensorflow_lite_android/src/net/marulabo/doodle/MainActivity.java image = new float[BATCH][IMAGE_HEIGHT][IMAGE_WIDTH][IMAGE_CHANNEL]; probabilities](https://files.speakerdeck.com/presentations/cee3a4a2bc23429dafde05afa0b9ca84/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
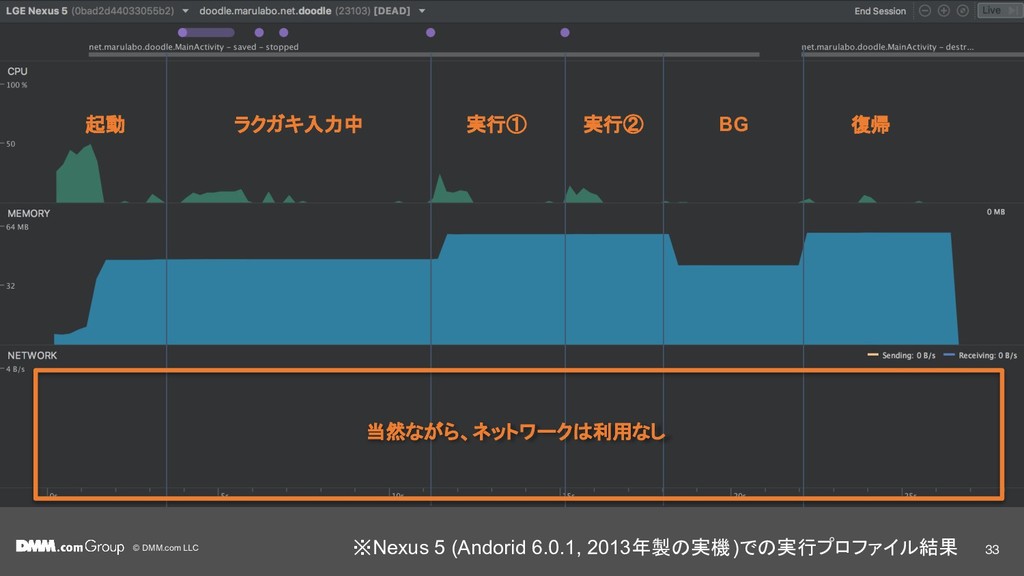{kind=link}
{kind=link}
{kind=link}
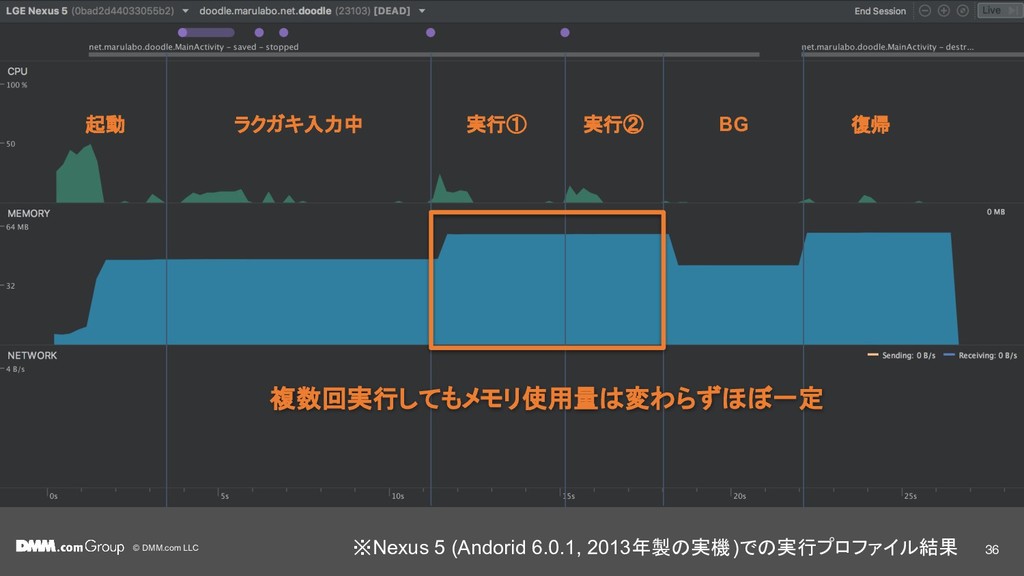{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}