Everyone knows Python's basic datatypes and their most common containers (list, tuple, dict and set).
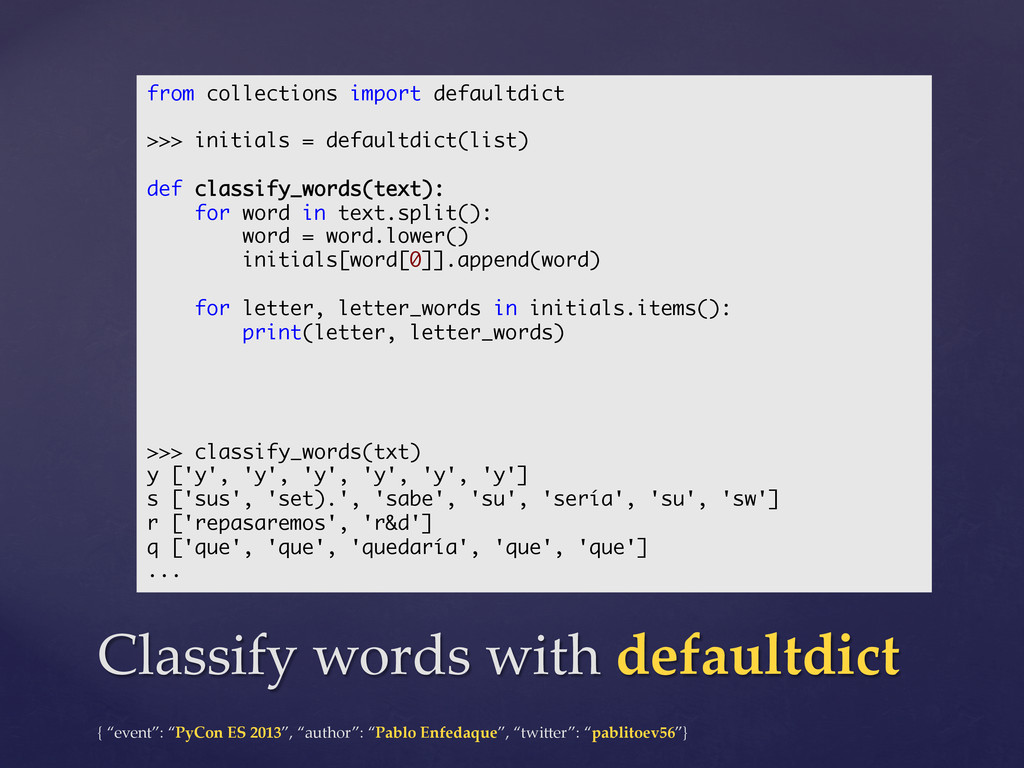
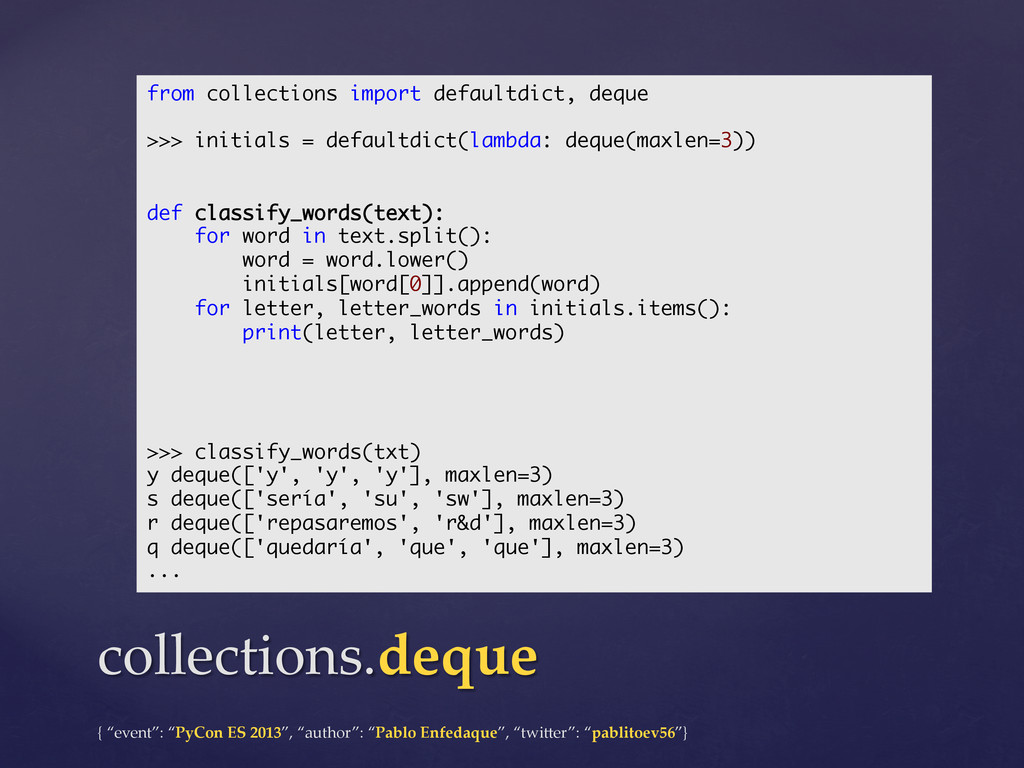
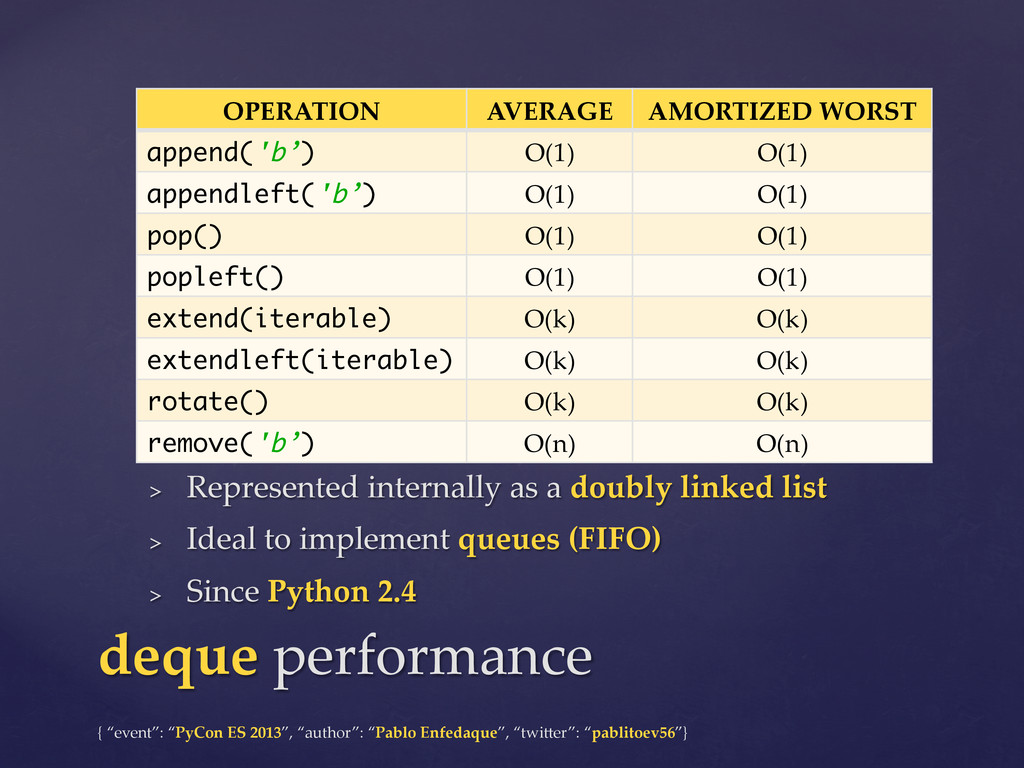
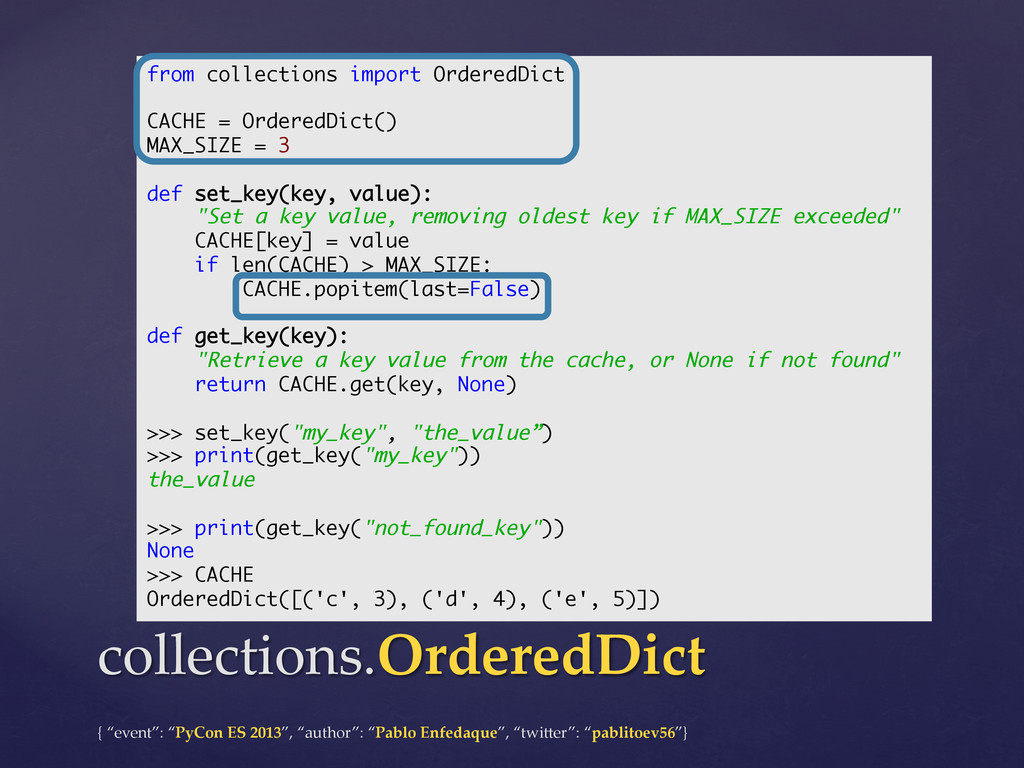
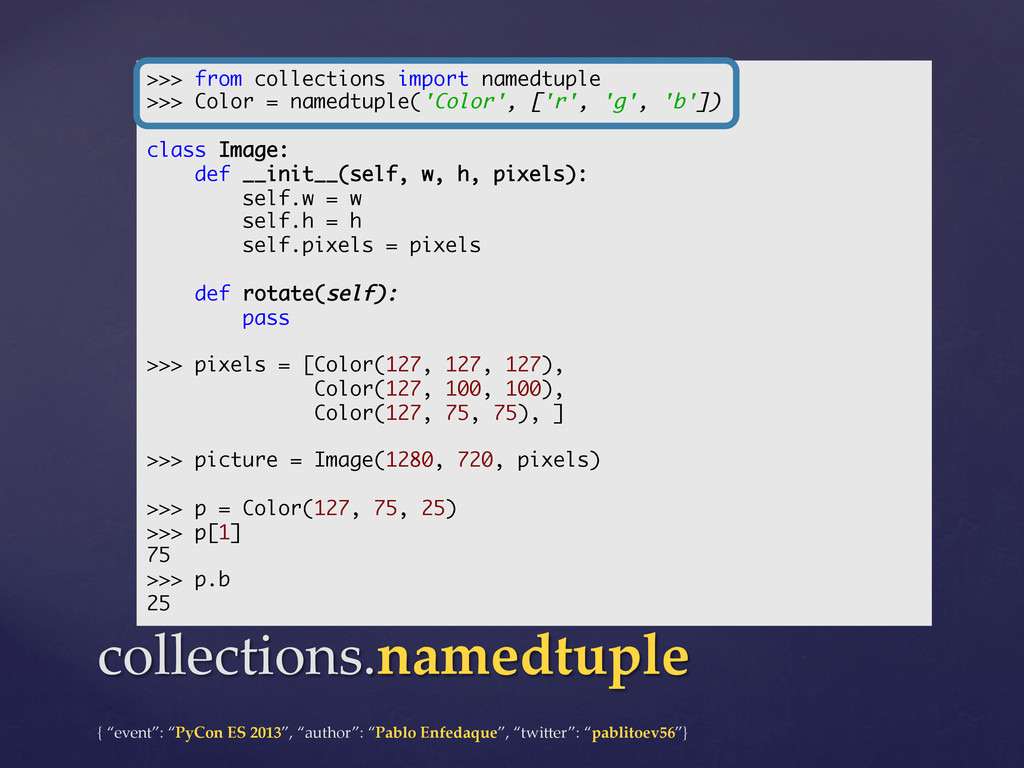
However, few people know that they should use a deque to implement a queue, that using defaultdict their code would be cleaner and that they could be a bit more efficient using namedtuples instead of creating new classes.
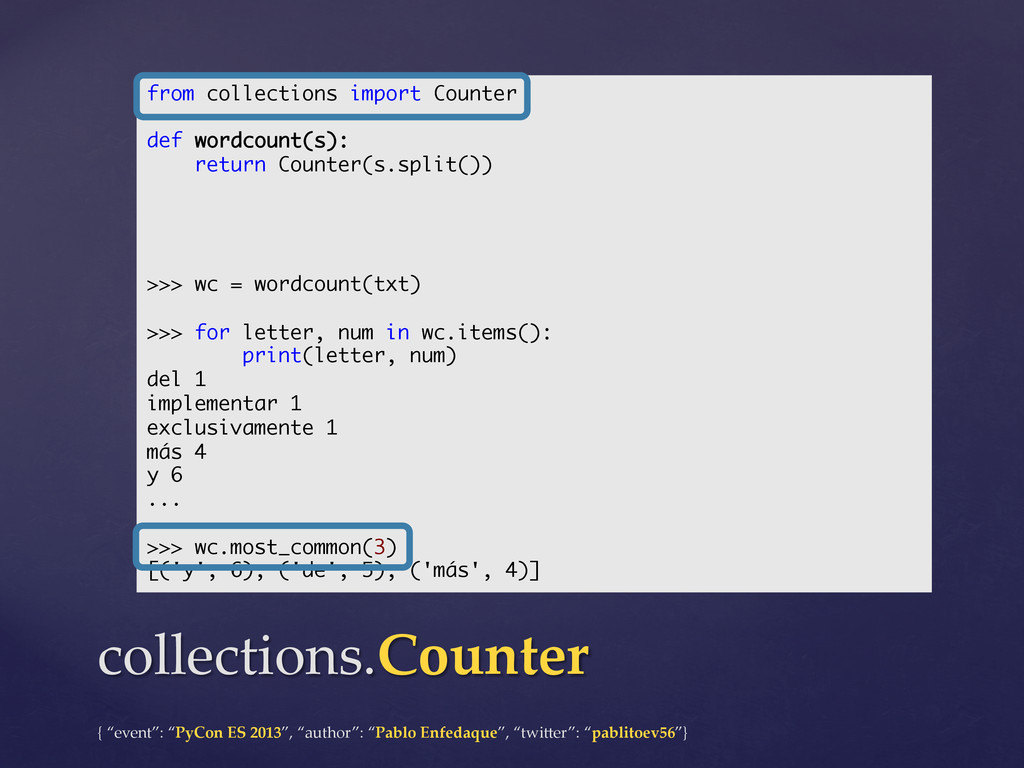
This talk will review the data structures of Python's "collections" module of the standard library (namedtuple, deque, Counter, defaultdict and OrderedDict) and we will also compare them with the built-in basic datatypes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}