web crawling framework • Simple, productive, fast, extensible, portable, open-source, well documented & tested • Popular - 1.5k github followers, several messages a day on newsgroup & stackoverflow, elance jobs, a few companies hiring and providing commercial support • Developed at mydeco.com to crawl data for a vertical search engine.
vs many assorted wikis) • easier to customize unless you are quite familiar with Java and Hadoop framework • more portable (runs the same way on Windows/Mac/Linux) • easier to crawl specific websites, more agile to bootstrap and power vertical search engines • Less focussed on distributed crawling
Define a Spider class that: a. Extends BaseSpider b. has start url(s), or a method to generate them c. has a 'parse' method that generates requests or items d. has a name 3. Define an item class that contains the fields extracted 4. scrapy crawl SPIDER_NAME
• Selectors - Convenient mechanism for extracting based on xpath • CrawlSpider - crawl a single site, rules define links to follow. • Feed Exports - output items as JSON, CSV, XML, etc. or customize your own • Item Loaders - abstraction to create and populate items by using xpath and composing data transformations. • Signals - callbacks for events in the engine • Contracts - simple spider testing
scrapy, fetch pages, view in browser, inspect requests etc. • statistics - request count, bytes sent/downloaded, errors, etc. • interact with a running crawler via telnet console or web service • scrapyd - server for queueing and running jobs. Clients add and manage jobs via an API
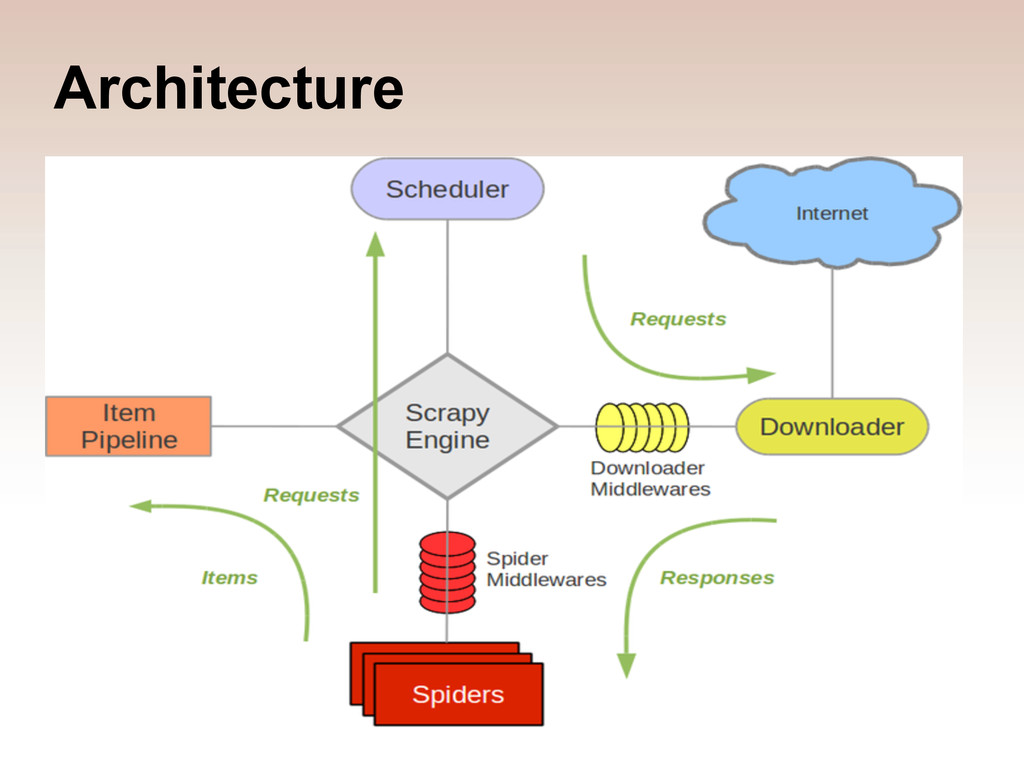
mechanisms to implement much of the functionality: • Spider middleware - process spider input and output: set referrer URL, filter requests, reject invalid URLS... • Downloader middleware - process downloader input and output: cookies, cache, gzip, auth, proxies, robots. txt, standard headers.. • Extensions - loaded at startup, access the API: stats, webservice, memory/python debugging, crawl limiting.. • Item pipeline - post-process extracted data: filter duplicates, export data... and if that isn't enough, core classes can be extended or replaced via settings!
common for smaller number of sites - efficient and high quality (often CrawlSpider) • Feeds - provided by some websites or data aggregators (XMLFeedSpider, CSVFeedSpider) • Scrape with templates - annotate some pages, generic crawler with configuration (scrapely/slybot) • Generic Parsing - e.g. machine learning extraction, rules based (like readability), etc. • Hybrid - projects that use multiple techniques
each time, set termination cond. • Find only new items (delta-fetch extension) • Custom function combining new item discovery, freshness of existing data, probability of change.. • Search crawlers may use prominence in search results, or query independent ranking factors Scheduling models • Batch Crawling - Long-term scheduling to make batch, Short-term scheduling within scrapy job • Continuous Crawling - reading from & writing to external crawl frontier
usually cron. One big box, load balance scrapyd or partition multiple spiders. • Scrapy-redis - replaces some scrapy components with redis-backed storage. Single crawl becomes distributed. • Custom - e.g. with AWS, LTS in EMR, push to SQS, crawler nodes autoscale, output to S3, etc. • Heroku - easy to run scrapy, scrapy-heroku integration • Scrapy Cloud - Management via graphical UI and API, data & log inspection and filtering, stats, notifications, monitoring, crawl-by-example, proxy network, download data in multiple formats, lots more!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![class DmozSpider(BaseSpider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls =](https://files.speakerdeck.com/presentations/1be146f02672013141e36e50b70190e8/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}