almost anything from home. メルカリは、ミッションである「新たな価値を生みだす世界的なマーケットプレイスを創る」ことを目指し、創業翌年から海外展開を推 し進めています。2014年9月にUS事業を開始し、現地の嗜好やマーケットの特徴に合わせたブランディングやUI・UXの改良、配送 網の構築等に取り組んでいます。巨大かつ多様性に富む人口基盤を有するUSでの成功が、メルカリのミッションを実現する上で重 要なマイルストーンであると認識しており、注力しています。 3 Your Marketplace Factbookより引用
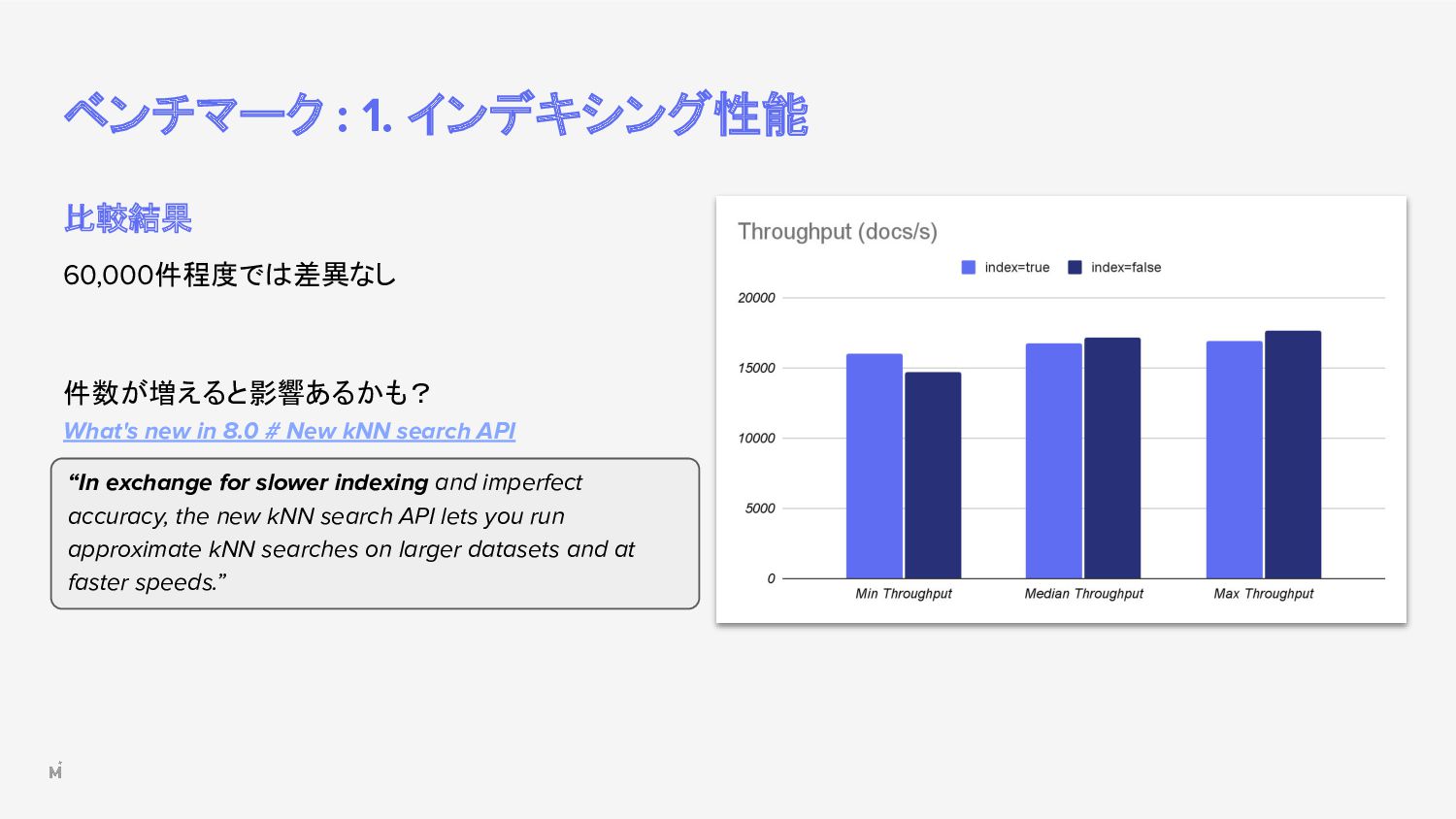
8.0 # New kNN search API “In exchange for slower indexing and imperfect accuracy, the new kNN search API lets you run approximate kNN searches on larger datasets and at faster speeds.”
ms 9 ms 90%ile (original) 60 ms 10 ms 50%ile (# doc × 2) 119 ms 10 ms 90%ile (# doc × 2) 119 ms 11 ms 50%ile (# doc × 3) 178 ms 11 ms 90%ile (# doc × 3) 179 ms 12 ms kNN(script)はドキュメント数に比例、ANNは穏やか
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考文献 • [1] : [CVPR20 Tutorial] Billion-scale Approximate Nearest Neighbor](https://files.speakerdeck.com/presentations/c229dfa6245f46aeb6502ea4177072cf/slide_28.jpg){kind=link}