BFF Layer App BFF ReplicationController Web BFF ReplicationController App Search Service API ReplicationController Indexing Worker Worker ReplicationController Update Queue Pub/Sub Elasticsearch Production Index Other Microservices API ReplicationController Search
今後も商品数・リクエスト数が増える事を加味すると、 柔軟なスケーリングが必須条件となった。 3. Maintainability 自分たちではコントロールしようのない事象が度々発生。 透明性が高く自らコードレベルで調査できる検索エンジンが好まし かった。 Migration by Nick Youngson CC BY-SA 3.0 Pix4free
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
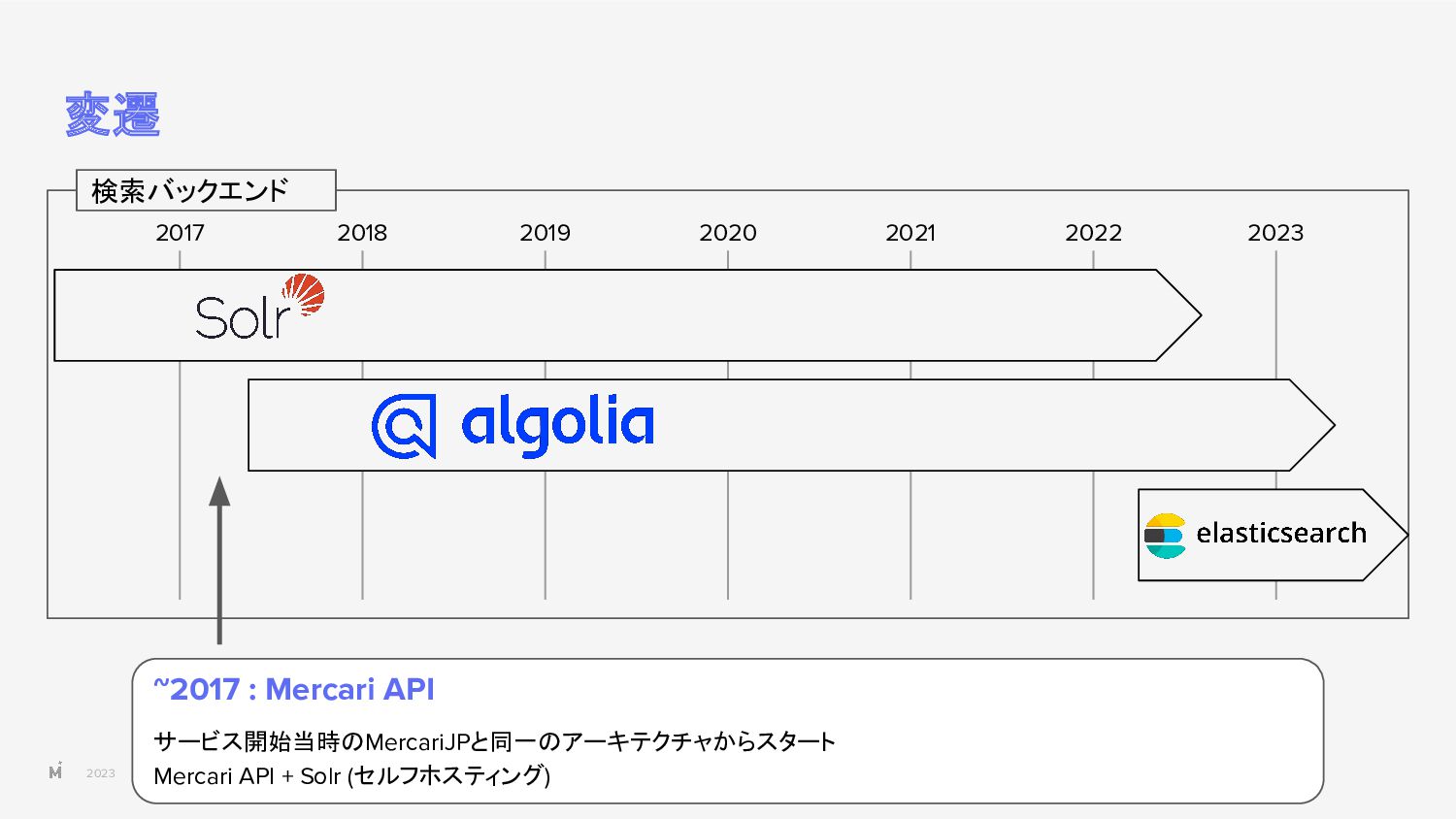{kind=link}
{kind=link}
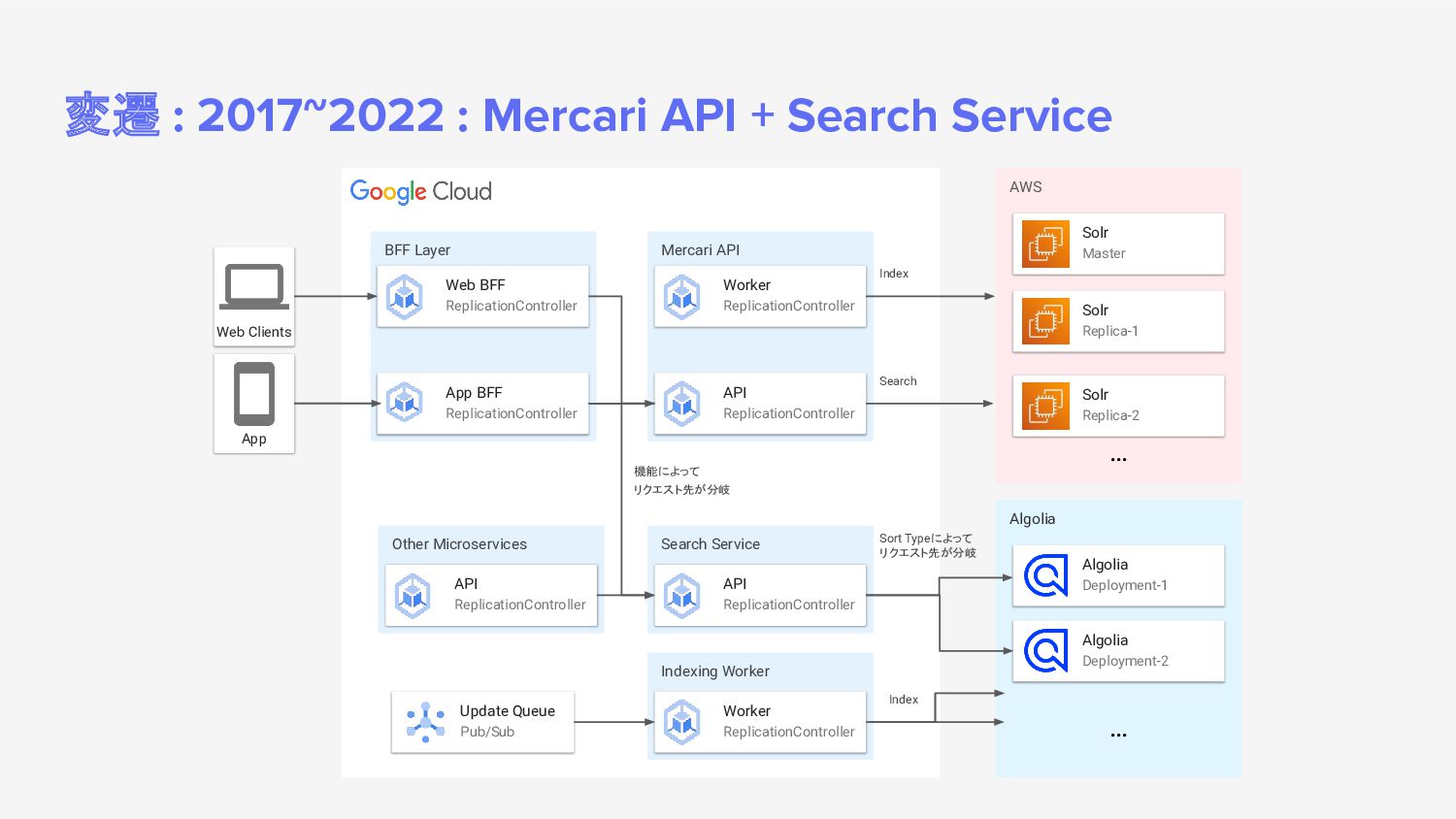{kind=link}
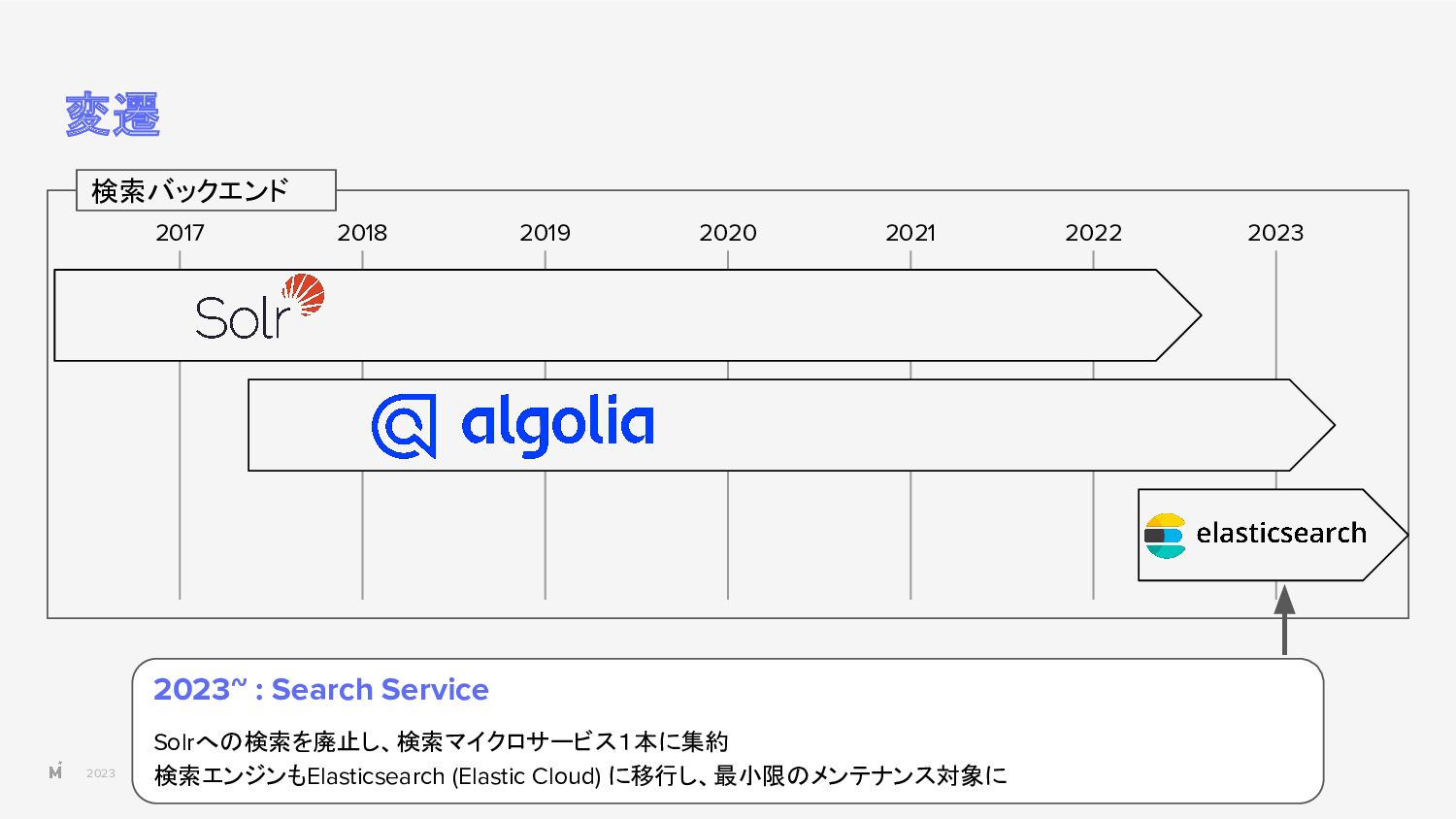{kind=link}
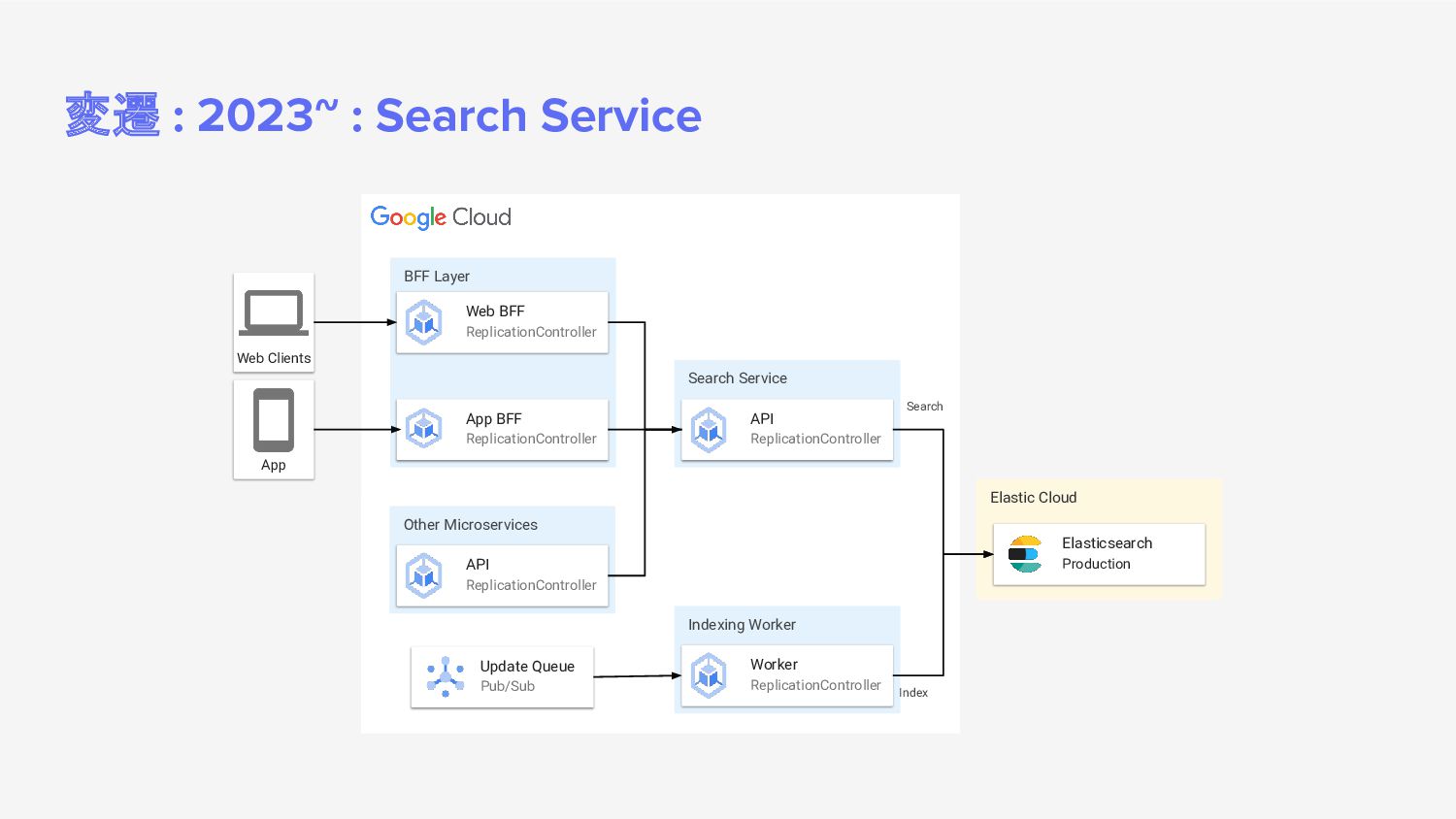{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
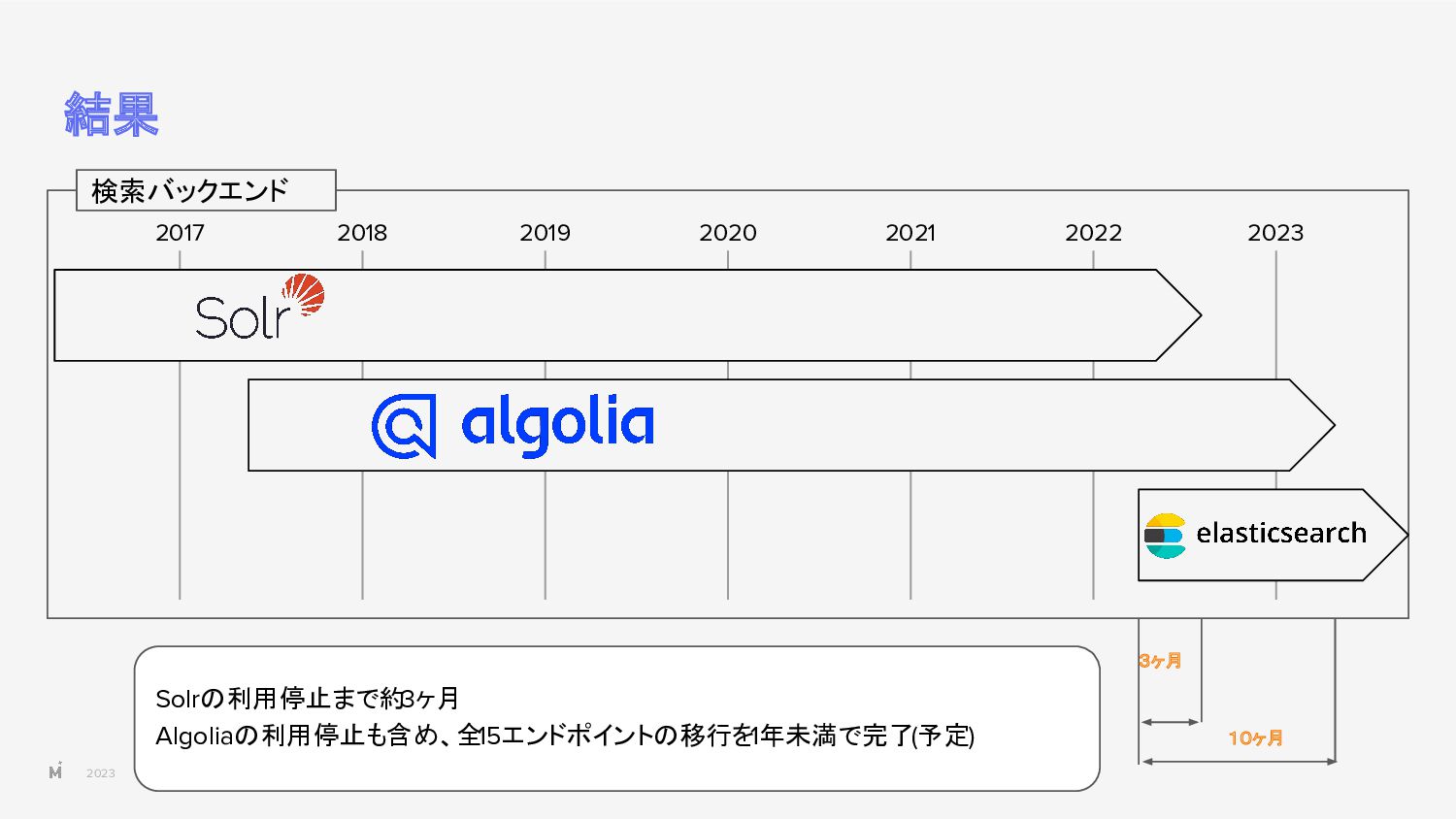{kind=link}
{kind=link}
{kind=link}
{kind=link}
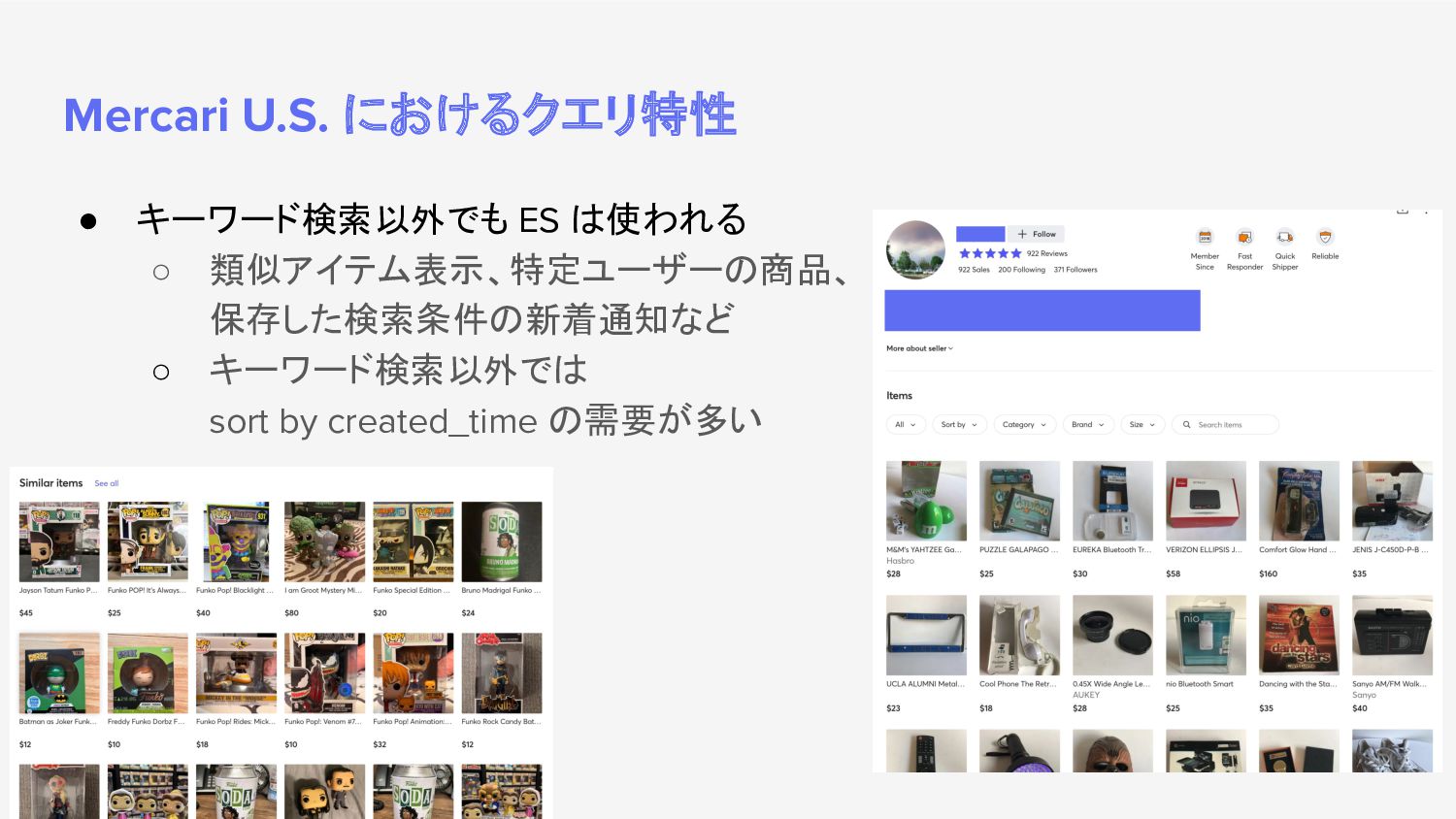{kind=link}
{kind=link}
{kind=link}
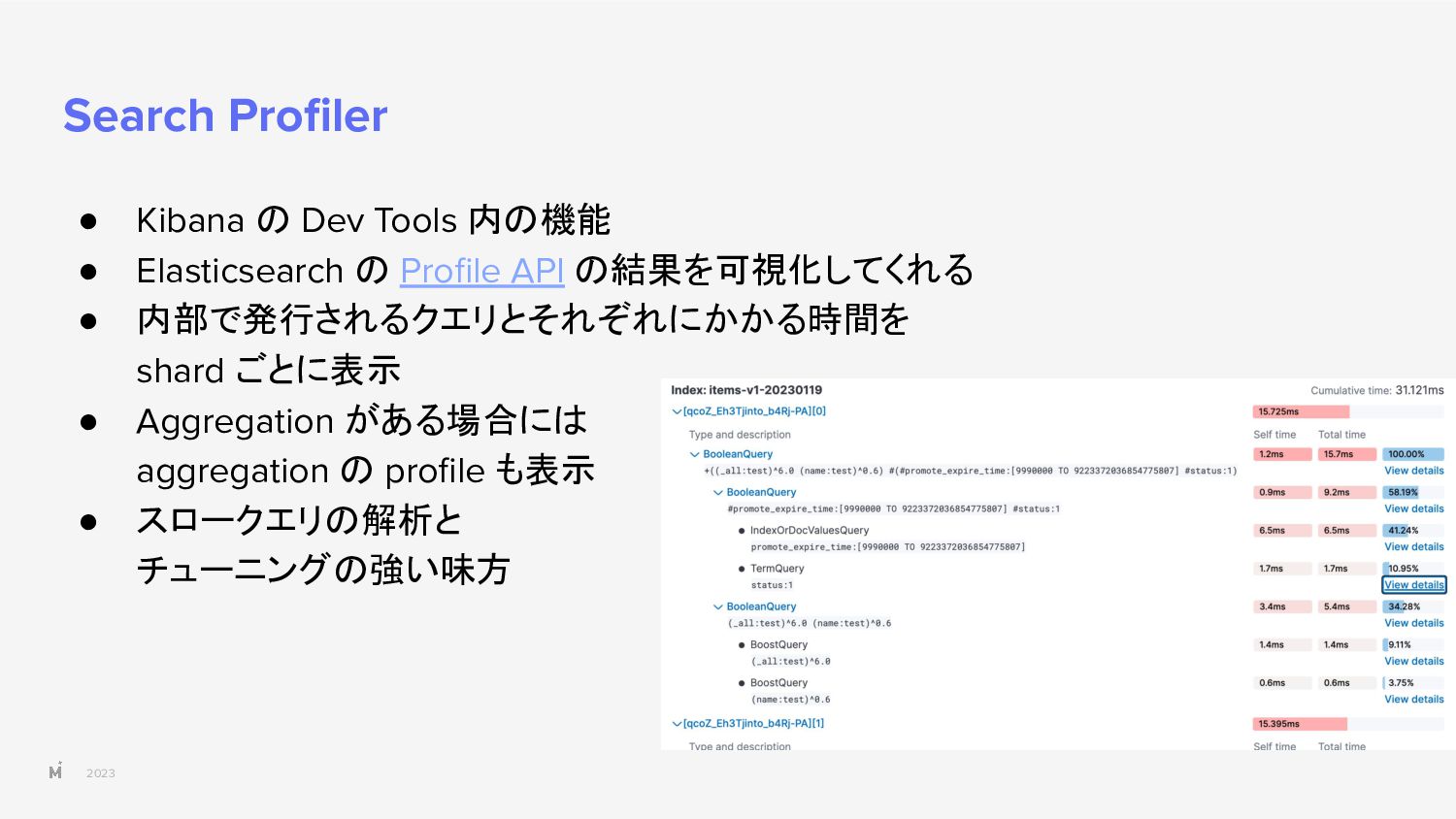{kind=link}
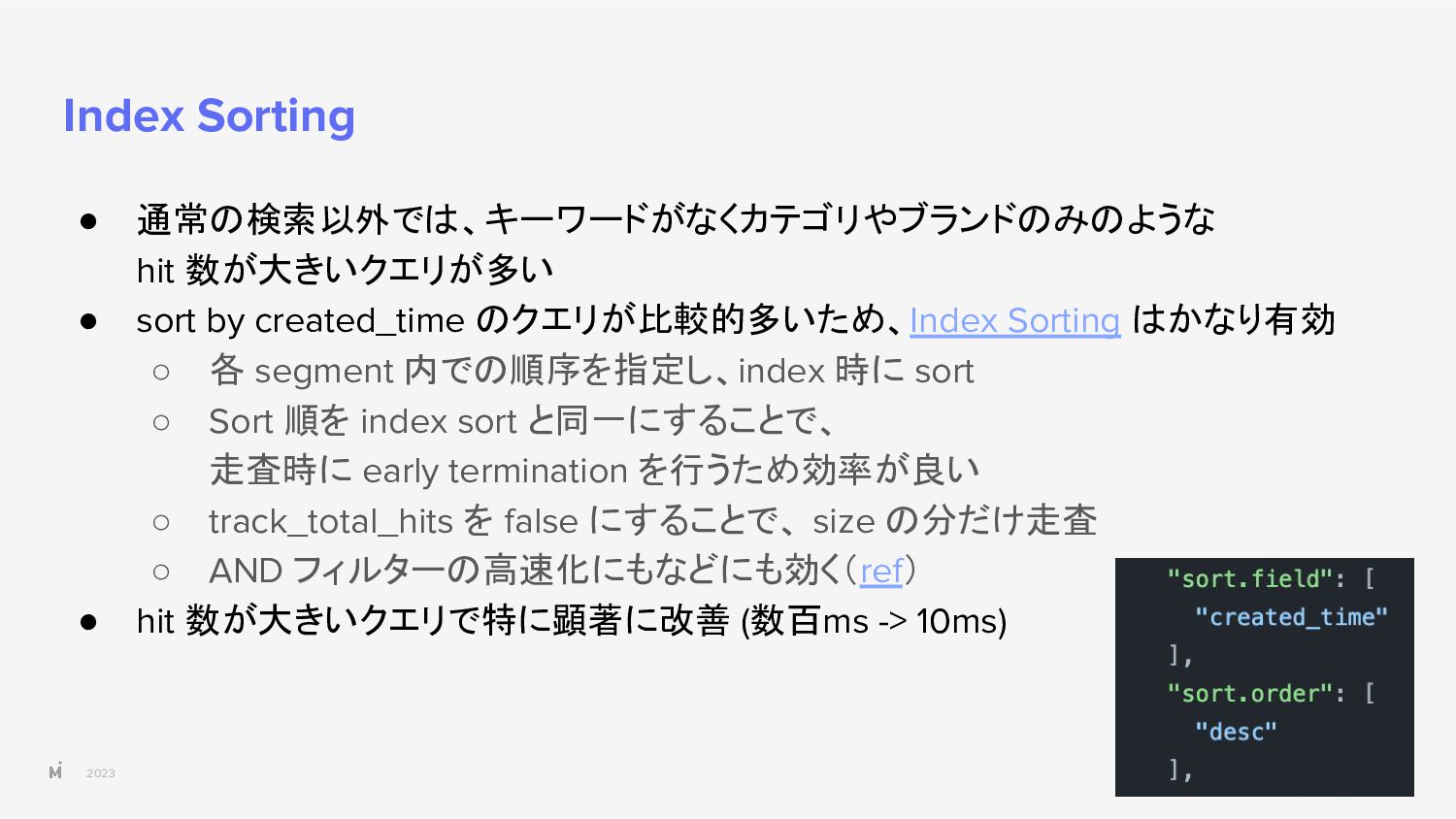{kind=link}
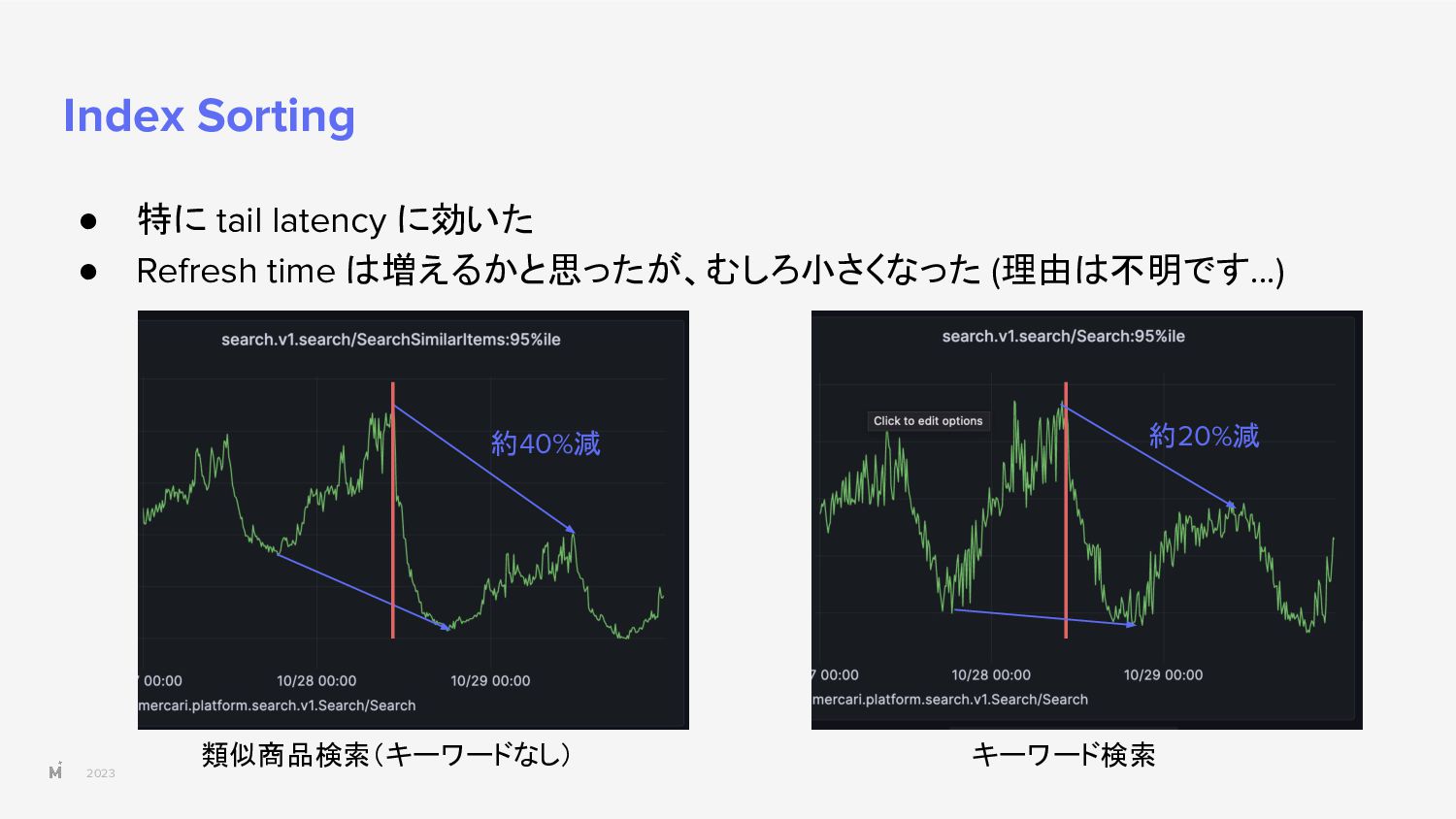{kind=link}
{kind=link}
{kind=link}
{kind=link}
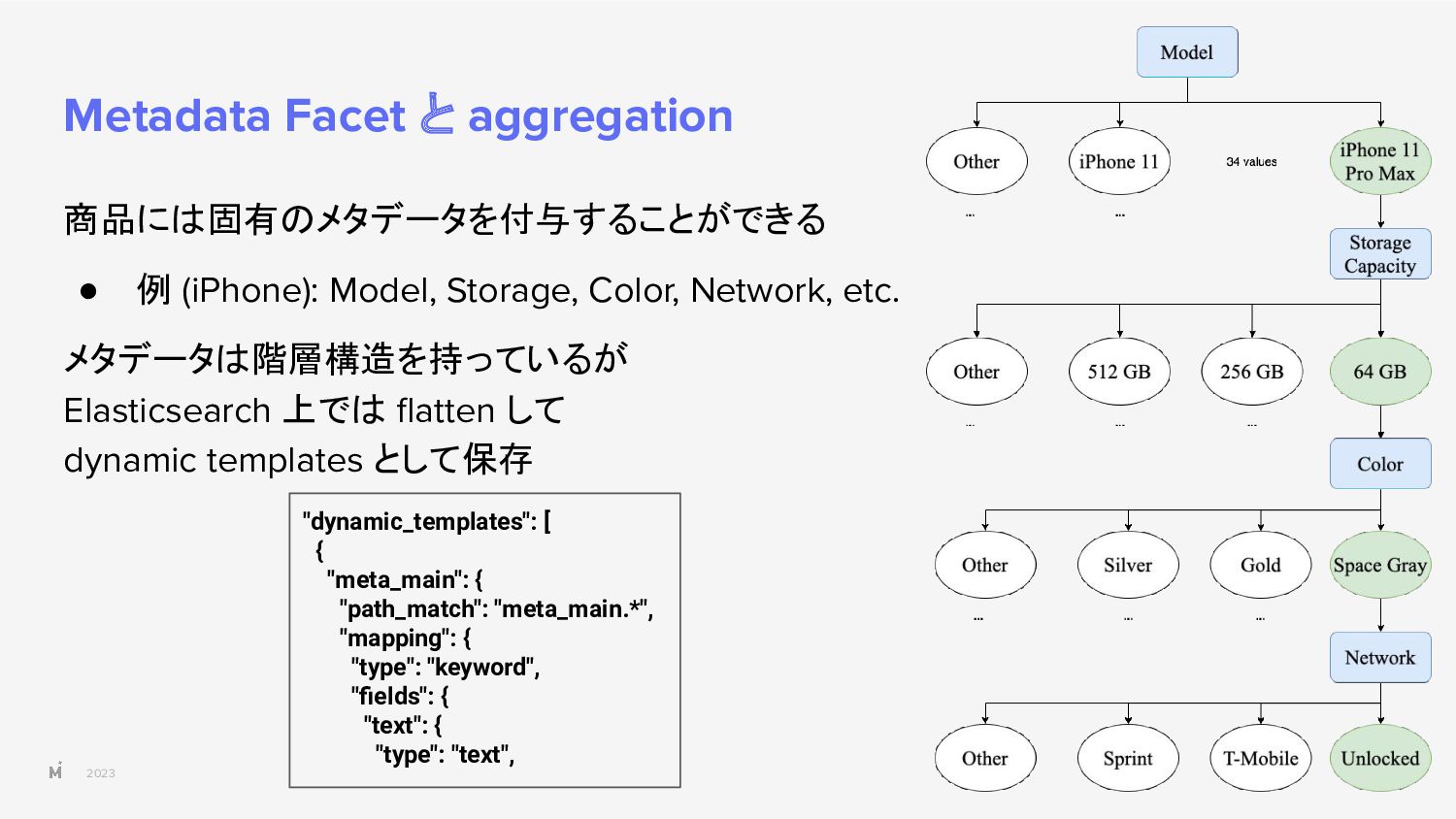{kind=link}
{kind=link}
{kind=link}
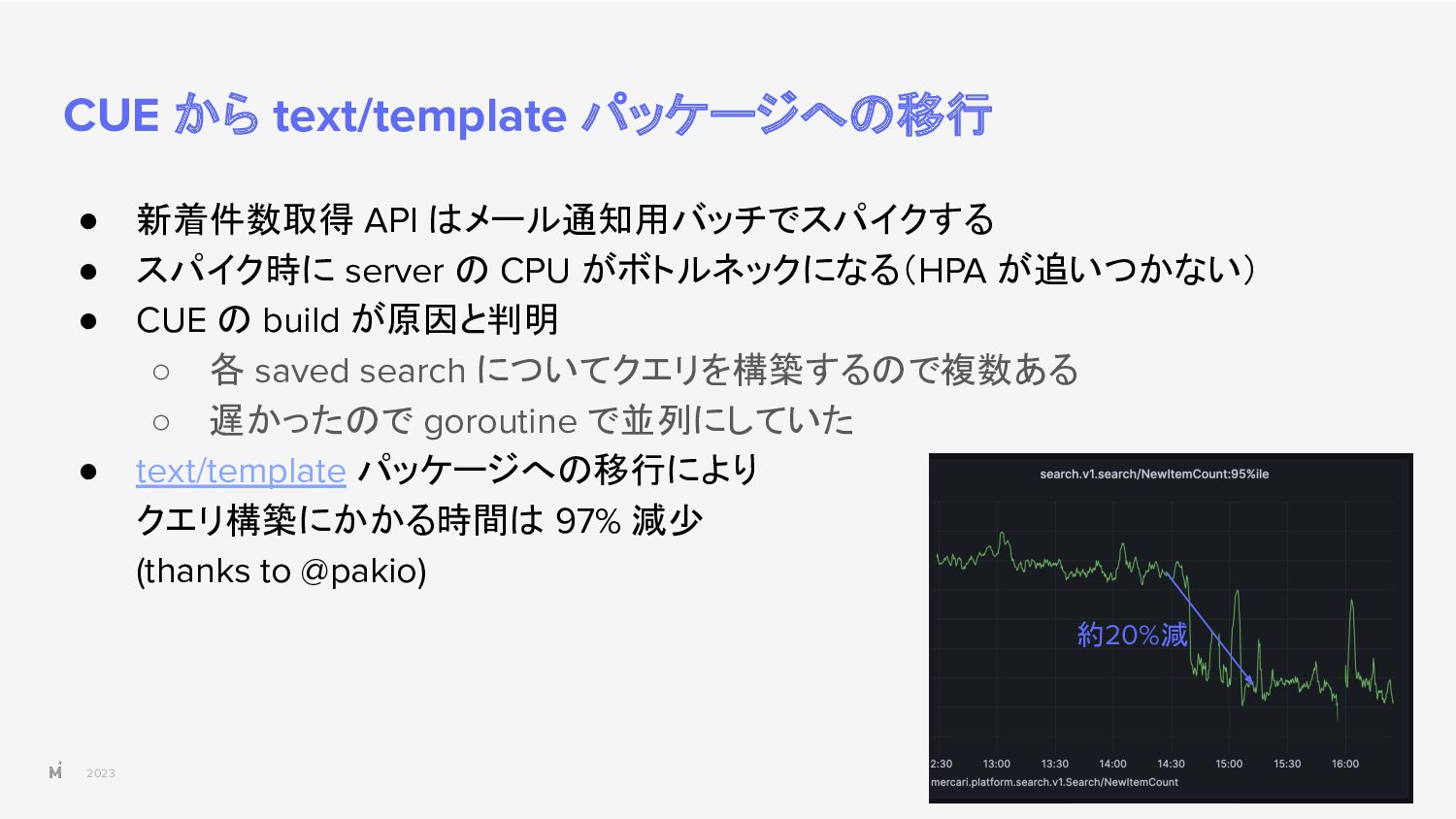{kind=link}
{kind=link}
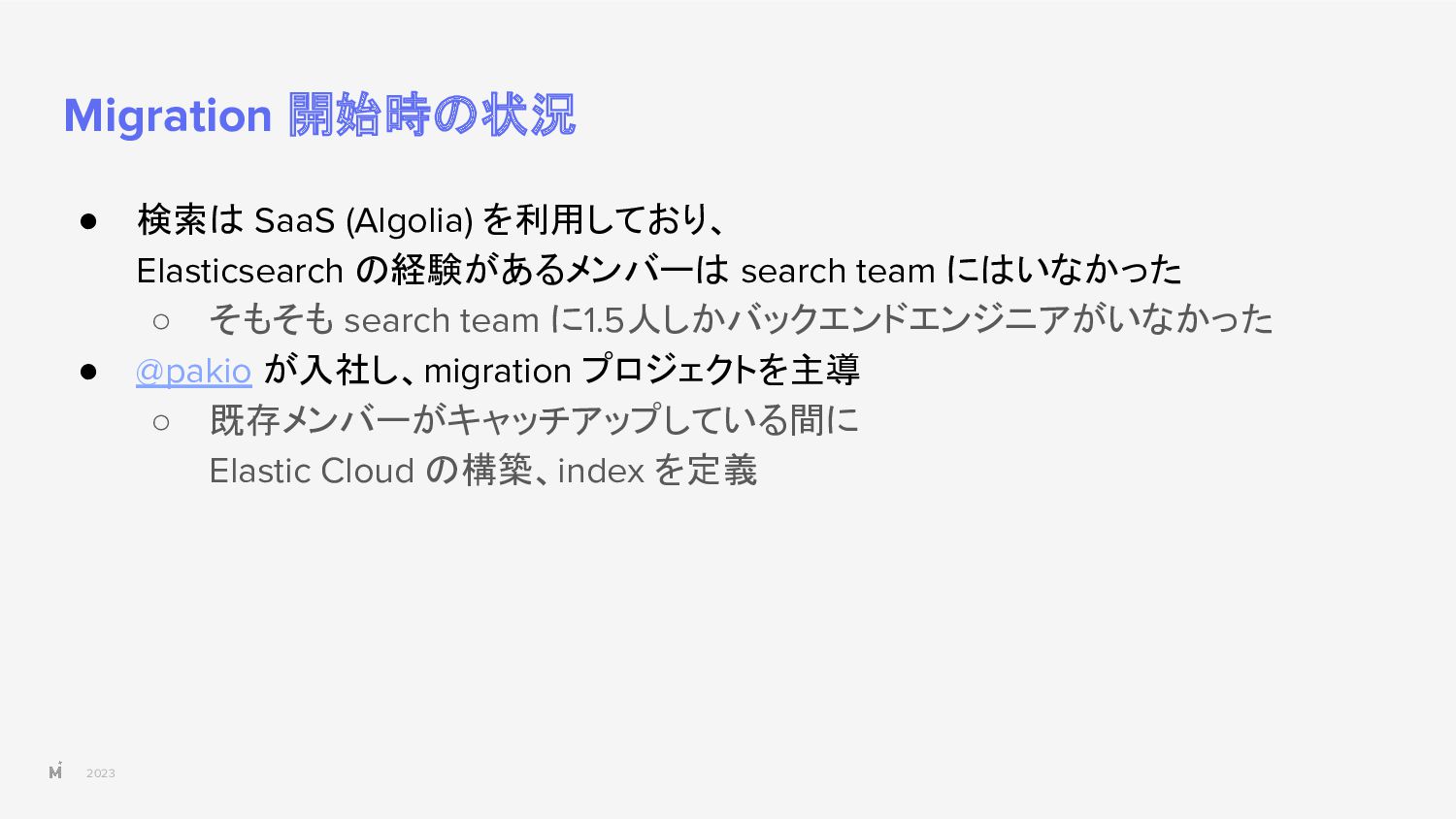{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}