Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
TUT Python スクレイピングハンズオン
Search
panakuma
February 03, 2018
Education
450
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
TUT Python スクレイピングハンズオン
panakuma
February 03, 2018
More Decks by panakuma
See All by panakuma
jsnog-lt-1_イベントNOCの裏側
panakuma
0
280
DTCP-IPをVPNで
panakuma
0
3.1k
TUT Python 初心者入門
panakuma
0
440
Other Decks in Education
See All in Education
2026年度春学期 統計学 第2回 統計資料の収集と読み方 (2026. 4. 16)
akiraasano
PRO
0
170
生成AI時代のエンジニア育成について考えてみた
akasan
0
140
解決策を教えても次期リーダーは育たない ─ 器の発達に伴走するために / Partnering with leaders in their vertical development
matsu0228
0
220
2026年度春学期 統計学 第1回 イントロダクション ー 統計的なものの見方・考え方について (2026. 4. 9)
akiraasano
PRO
0
150
Curso de Consagração ao Sagrado Coração de Jesus - O Sagrado Coração na História (Aula 01)
cm_manaus
0
220
0415
cbtlibrary
0
210
AI-Based Speaking Assessment of a Short-Term Study Abroad Program
uranoken
0
300
偶然のチャンスを掴みに行けるのは君だ!
kotomin_m
2
120
Πλουτοκρατία: Η Τυραννία του Μαμμωνά και η Μεταανθρώπινη Δουλεία
amethyst1
0
260
Padlet opetuksessa
matleenalaakso
12
16k
Stardy 会社紹介資料
stardy
0
530
2026年度春学期 統計学 講義の進め方と成績評価について (2026. 4. 9)
akiraasano
PRO
0
190
Featured
See All Featured
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Embracing the Ebb and Flow
colly
88
5.1k
RailsConf 2023
tenderlove
30
1.5k
How GitHub (no longer) Works
holman
316
150k
Into the Great Unknown - MozCon
thekraken
41
2.6k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
140
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.5k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Un-Boring Meetings
codingconduct
0
310
Done Done
chrislema
186
16k
Transcript
Python Boot Camp in TUT Python 初心者入門 第2回 スクレイピング
スクレイピングとは • ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。 (Wikipedia 日本語版 ウェブスクレイピング より引用)
スクレイピングに必要なモノ(ライブラリ) •urlilb5 •beautifulsoup4
ライブラリのインストール (1) •pipyというライブラリ管理ツールを使います。 •ubuntu でいうaptitude(apt)と同じような感じのものと思って下さい。
ライブラリのインストール (2) •まず、pip3をaptでインストールします。 •sudo apt install python3-pip •pip3でurlli5とbeautifulsoup4をインストールします。 •sudo pip3
install urllib5 beautifulsoup4
ライブラリの使い方 (1) •プログラム内でライブラリを使うときにはimportをします。 • importの仕方 ライブラリ全体をimport import ライブラリ名 ライブラリの一部をimport from
ライブラリ名 import 関数名など
ライブラリの使い方 (2) •importしたものに別の名前をつけることもできます。 •例えば長い関数名を省略したいときなんかに便利です。 from ライブラリ名 import 関数名 as 別名
スクレイピングの基本 •まずスクレイピングするサイトの構造を観察します。 •自分が取得したい情報が入っているタグなどを見つけます。 •またタグに振ってあるクラスやIDも手がかりになります。
構造の観察 (1) •今回、「妹さえいればいい。」のニュースページをスクレイピングして いきたいと思いますので、まずそのサイトを開き、キーボードの[F12] を押して下さい。 •開発者ツールが開きますので、開発者ツール左上の要素選択ツー ルをクリックして、拾いたい要素(今回はニュースのタイトル)をクリッ クします。
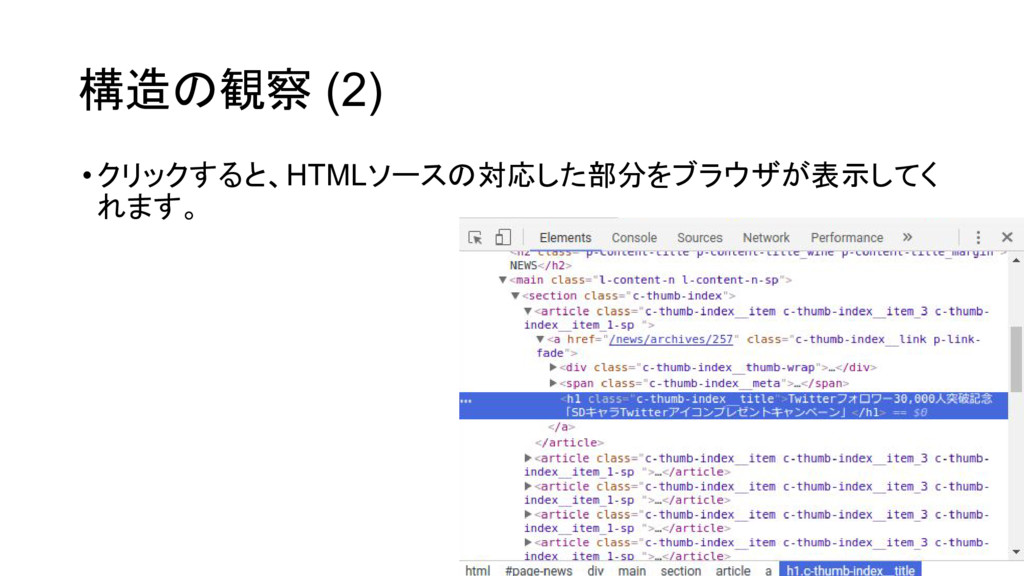
構造の観察 (2) •クリックすると、HTMLソースの対応した部分をブラウザが表示してく れます。
構造の観察 (3) •この要素は h1タグで 「c-thumb-index__title」というクラスである •ということがわかります。 •これを手がかりに、データを抽出していきます。
スクレイピング (1) •まずは以下のサイトのコードを「scraping.py」というファイルに入力し て実行してみたください。 https://goo.gl/mDyxXU
None
スクレイピング (2) • 行っていることの解説 • まず最初の2行 from urllib import request
from bs4 import BeautifulSoup as BS • urllibというライブラリからrequestという機能をインポート • bs4というライブラリからBeautifulSoupという機能をインポートしてBSという別 名を付与
スクレイピング (3) url = "http://imotosae.com/news/" req = request.Request(url) res =
request.urlopen(req) html = res.read() • 変数urlにスクレイピングするサイトのurlを代入 • urlを取得するというオブジェクトをreqに代入 • reqを実行して得られたオブジェクトをresに代入 • htmlにresをStringとして代入
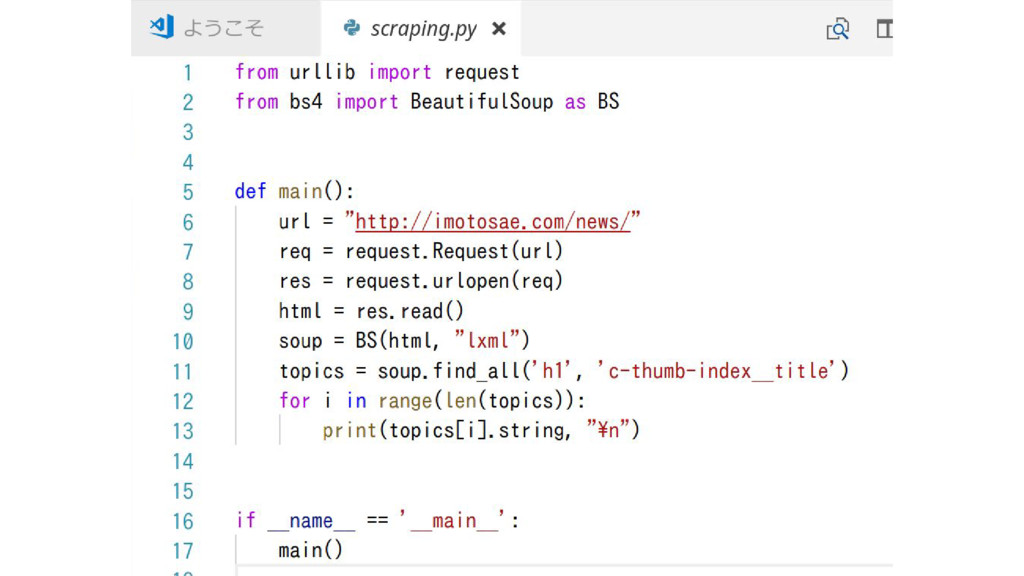
スクレイピング (4) soup = BS(html, "lxml") topics = soup.find_all('h1', 'c-thumb-index__title')
for i in range(len(topics)): print(topics[i].string, "\n") • htmlを「lxml」というHTMLパーサを使って内容を解析して 結果を変数 soup に代入 • soupの中から「c-thumb-index__title」というクラス名を持つ「h1」タ グを抽出して変数 topics にリストとして代入 • topicsの中身を出力
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![構造の観察 (1) •今回、「妹さえいればいい。」のニュースページをスクレイピングして いきたいと思いますので、まずそのサイトを開き、キーボードの[F12] を押して下さい。 •開発者ツールが開きますので、開発者ツール左上の要素選択ツー ルをクリックして、拾いたい要素(今回はニュースのタイトル)をクリッ クします。](https://files.speakerdeck.com/presentations/b2fbd13d5ac94fb4bf38cf95cffebad4/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}