Seminario de Apache Solr, organizado por Paradigma Tecnologico y Javahispano, presentado por Marco Martinez y Alejandro Marques el 8 de Junio de 2010
Mas info:
Instalación Indexación Esquema de Datos Búsqueda Parámetros de Búsqueda Búsqueda Avanzada Analizadores de Texto Tokenización Stemming Sinónimos Stop Words N-Gramas Componentes de Búsqueda Highlighting Corrección ortográfica More like this
Lucene. Lucene : Proyecto de código abierto escrito en java. Librería que proporciona búsquedas de texto de alto rendimiento haciendo uso de índices invertidos. Mayor velocidad en la búsqueda de cadenas de texto. Menor dependencia del tamaño del índice. Mayor flexibilidad en las búsquedas de texto: Búsquedas por término, mediante N-Gramas, búsquedas fonéticas… Mayor facilidad para ordenaciones por score y ponderaciones. Características adicionales: Analizadores de texto, resaltado de coincidencias, corrector ortográfico, etc. Introducción (I): Lucene
Invertido vs. Índice Directo 1 que es esto 2 esto es un texto 3 este texto es otro texto que 1 es 1, 2, 3 esto 1, 2 un 2 texto 2, 3 este 3 otro 3 que (1,1) es (1,2) (2,2) (3,3) esto (1,3) (2,1) un (2,3) texto (2,4) (3,2) (3,5) este (3,1) otro (3,4)
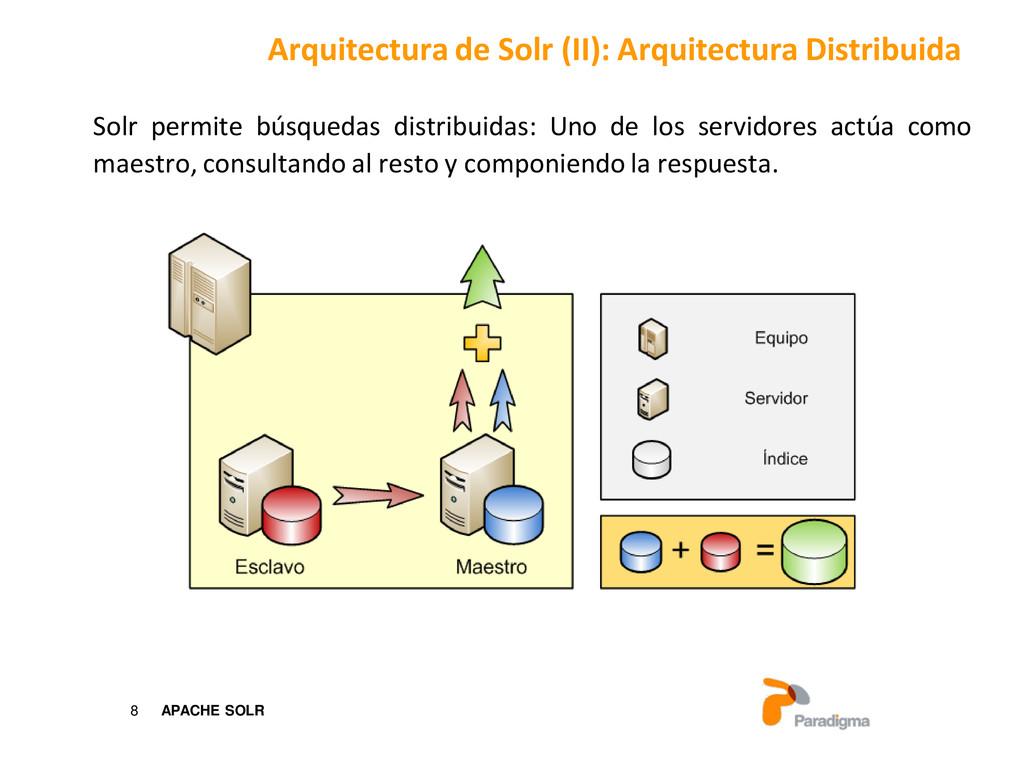
escrito en java que proporciona un recubrimiento de Lucene añadiendo características adicionales: Acceso HTTP a Lucene. Cachés para lograr mayor velocidad en las búsquedas. Interfaz de administración web. Configuración del esquema de datos y del servidor mediante archivos XML. Facetado de resultados (Agrupación de resultados con contadores). Distribución de servidores. Introducción (III): Solr
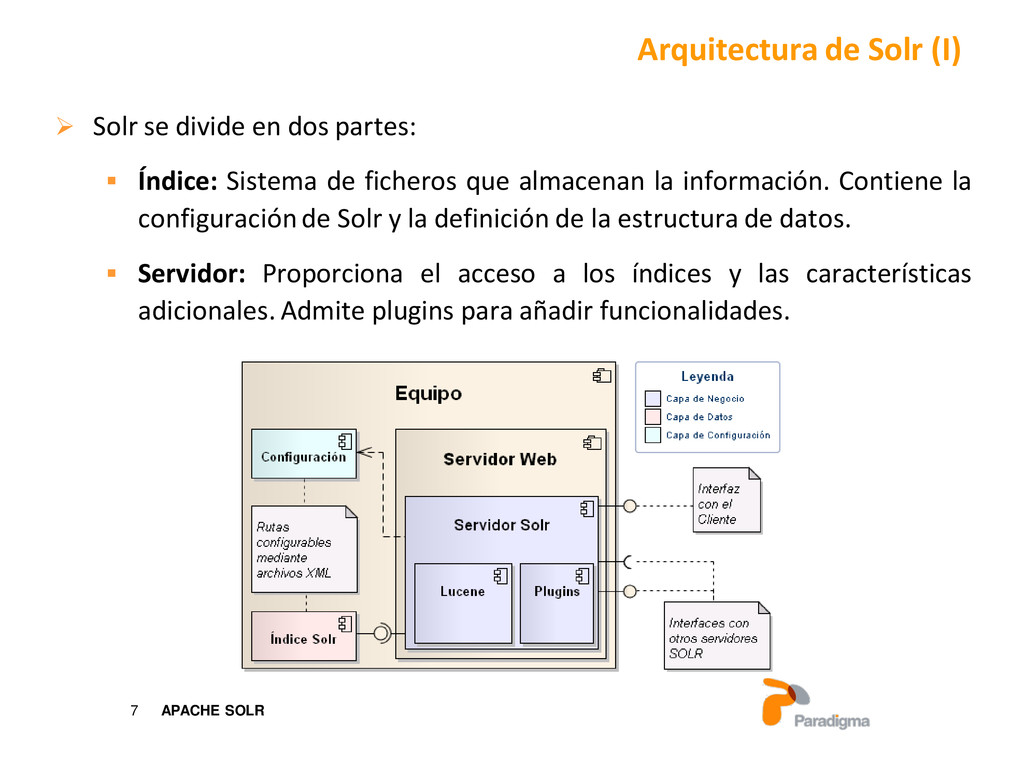
Índice: Sistema de ficheros que almacenan la información. Contiene la configuraciónde Solr y la definición de la estructura de datos. Servidor: Proporciona el acceso a los índices y las características adicionales. Admite plugins para añadir funcionalidades. Arquitectura de Solr (I)
de aplicaciones Descarga: http://apache.rediris.es/lucene/solr/ Pasos: Copia de índice. Despliegue de servidor sobre el servidor de aplicaciones. Configuración de enlace entre servidor e índice. (Modificación del fichero web.xml) Instalación de Solr
estructura de datos a indexar. Estructura de campo: Tipos de Datos: Definidos por clases java. Parámetros opcionales: default: Valor a usar si no se recibe ninguno required: Define si un campo es obligatorio. indexed: Determina si un campo es buscable u ordenable. stored: Determina si un campo se puede recuperar en una consulta. multiValued: El campo contiene más de un valor. Indexación de Contenidos (I): Esquema de datos <field name=“nombre de campo" type=“tipo de dato" />
Petición HTTP: Envío de instrucción y datos asociados vía HTTP POST. Cliente Solrj: Cliente java. Permite realizar las diferentes operaciones sobre el índice y enviar la información en diferentes formatos. Fuentes de datos para la indexación: XML: Coherente con la estructura de datos definida. Objetos Java: Representación binaria del documento XML. CSV: Documento de texto con valores separados. Documentos enriquecidos: PDF, XLS, DOC, PPT, … Base de Datos: Adaptador intermedio (DataImportHandler). Indexación de Contenidos (II)
Envío de instrucción de búsqueda y parámetros mediante HTTP GET. Administrador de Solr: proporciona un recubrimiento para simplificar la petición HTTP. Cliente Solrj: Posee también los métodos necesarios para realizar búsquedas sobre los índices. Respuesta como estructura XML. Búsquedas (I)
Documento inicial a partir del cual se van a mostrar los resultados. rows: Indica el número máximo de resultados a mostrar. facets: Indica si se desean mostrar facetas. Parámetros adicionales para indicar el campo por el que realizarlas, límite, ordenación, etc. sort: Define la ordenación de los resultados. Ordenaciones combinadas. Formato de ordenaciones: “precio desc, nombre asc” fl: Campos que se devuelven en la respuesta fq: Mismo formato que “q”. Limita la query (actúa como filtro). Los resultados se cachean. … Búsquedas (II): Parámetros de Búsqueda
B]” Boosting: Se pueden ordenar resultados dando más importancia a ciertos campos nombre:jose^2 AND alias:pepe^0.7 Fuzzy: Busca términos similares basándose en número de inserciones, borrados o intercambios de caracteres. Puede definirse el grado de proximidad. nombre: sony~0.9 -> Devuelve resultados con nombre “sony” nombre: sony~0.4 -> Devuelve resultados con nombre “coby” Búsquedas (IV): Búsqueda Avanzada
de implementar nuevos analizadores. Configurables por XML (schema.xml). Aplicables a campos específicos. Aplicables en tiempo de indexación, durante la búsqueda o en ambos. Existen múltiples analizadores y se pueden definir analizadores propios, algunos de los que proporciona Solr: Analizadores de Texto (I) Tokenización Stemming Sinónimos Stop Words N-Gramas
expresiones (Espacios en blanco, etiquetas html, signos de puntuación, expresiones regulares…) Stemming: Reducción de términos derivados a su forma raíz. Sinónimos: Transformación de texto mediante definición explícita de relaciones de sinonimia. Analizadores de Texto (II): Tokenización, Stemming, Sinónimos <tokenizer class="solr.WhitespaceTokenizerFactory"/> <filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt"/> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
significativas para el proceso de búsqueda. N-Gramas: Separación de texto en los diferentes grupos de caracteres que lo componen. Analizadores de Texto (III): Stop Words, N-Gramas <filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/> <filter class="solr.NGramFilterFactory" minGramSize="2" maxGramSize="15"/>
adicionales a la recuperaciónde resultados. Son configurables en tiempo de consulta (Algunos pueden necesitar configuraciónadicional en los archivos xml). Algunos de los componentes de búsqueda que proporciona Solr: Highlighting: Resaltado de términos. Spell Checker: Corrección ortográfica. More Like This: Resultados similares. Componentes de Búsqueda (I)
Ofrece el resaltado de términos buscados dentro de una cadena de texto. Algunos parámetros de configuración: hl=true: Activa el resaltado de términos hl.fl=[fieldnames]: Campo o campos sobre los que se realizará el resaltado. hl.simple.pre / hl.simple.post=[etiqueta]: Etiqueta que se añadirá antes y después del término resaltado (Ej. <span class=“bold”> término </span>)
ortográficos basadas en el contenido indexado o en un diccionario. Para sugerencias por contenido indexado es recomendable crear un campo para corrección ortográfica (De tipo “textSpell” o “textSpellPhrase”). Configuración: Componentes de Búsqueda (III): Corrección Ortográfica <searchComponent name="spellcheck" class="solr.SpellCheckComponent"> <str name="queryAnalyzerFieldType">textSpell</str> <lst name="spellchecker"> <str name="name">default</str> <str name="classname">solr.IndexBasedSpellChecker</str> <str name="field">corrector</str> <str name="spellcheckIndexDir">./spellchecker</str> </lst> </searchComponent>
de documentos similares. Se basa en los términos que aparecen en el documento recuperado y la frecuencia de los mismos. Configuraciónpor parámetros de búsqueda: mlt=true: Activa la utilidad de resultados similares. mlt.fl=[fieldnames]: Campo o campos analizados. mlt.count=[número]: Número de resultados devueltos. mlt.qf=[field1^2.0 field2^5.0]: Configuración de ponderación sobre diferentes campos para el cálculo de similitud. … Componentes de Búsqueda (IV): More Like This
http://lucene.apache.org/solr/ Wiki: http://wiki.apache.org/solr/ Mailing list: http://mail-archives.apache.org/mod_mbox/lucene-solr-user/ Manuales: Smiley, D. y Pugh, E. (2009). Solr 1.4 Enterprise Search Server. Packt Publishing Referencias y Enlaces de Interés
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}