Claude Coulombe at May 21, 2019 event of montrealml.dev
Title: Text Data Augmentation Made Simple By Leveraging NLP Cloud APIs
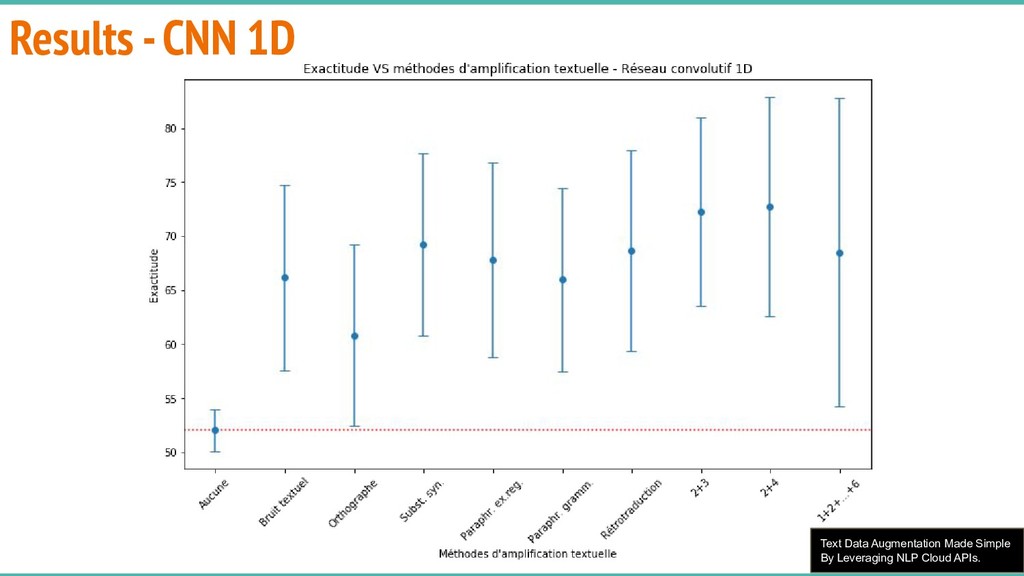
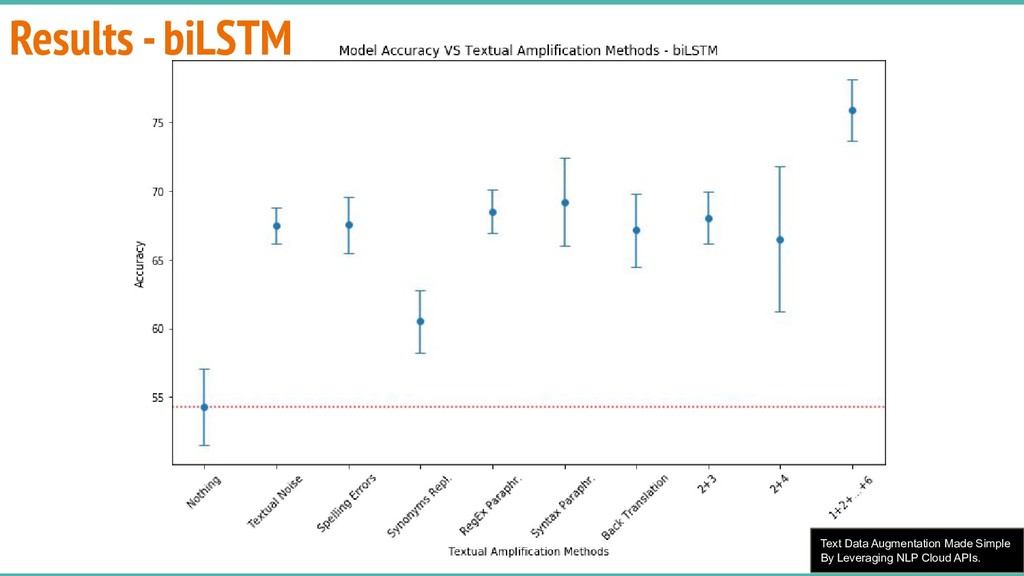
Summary: In natural language processing, it is common to find oneself with far too little data to train a deep model. This “Big Data wall” represents a challenge for minority language communities, organizations, laboratories and companies that compete with the web GAFAM web giants. In this presentation we will discuss various simple, practical and robust text data augmentation techniques based on NLP and machine learning to overcome the lack of text data for training large statistical models, particularly for deep learning.
Bio: Claude Coulombe has evolved from the budding young scientist who participated in 15 science fairs, got a B.Sc. in physics and a master’s degree in AI at Université de Montréal (Homo Scientificus), evolved to become a Québec’s passionated high-tech entrepreneur, co-founder of an AI startup called Machina Sapiens, where he participated in the creation of a new generation of grammatical checker tools (Homo Québecensis). Following the bursting of the technology bubble, Claude took a new evolutionary path to start a family, launch Lingua Technologies, which combines machine translation and web technologies, and undertake a PhD in machine learning at MILA under the supervision of Yoshua Bengio (Homo FamilIA). In 2008, resources becoming scarce, Claude transformed into a Java tech lead, specializing in the creation of rich web applications with Ajax, HTML5, Javascript, GWT, REST architectures, cloud and mobile applications (Java Man). In 2013, Claude started a new PhD in cognitive science, participated in the development of two massive open online courses (MOOC) at TÉLUQ, learned Python and deep learning (Python Man, not to be confused with the Piltdown Man). In short, Claude is an old fossil that has evolved, reproduced, created tools and being adapted to the rhythm of his passions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}