Masood Krohy at May 21, 2019 event of montrealml.dev
Title: Large-scale Experimentation with Spark & Productionizing Native Spark ML Models
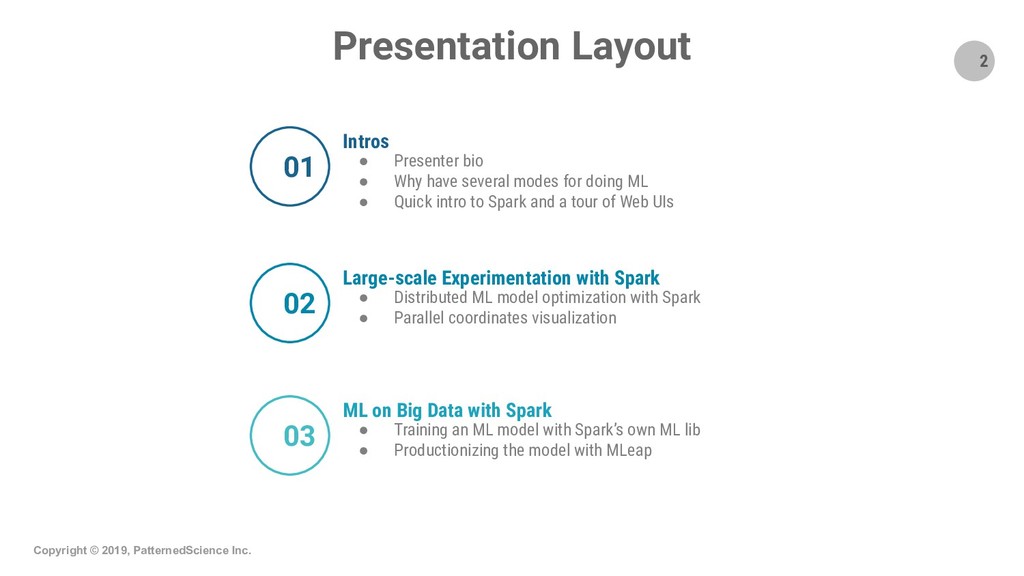
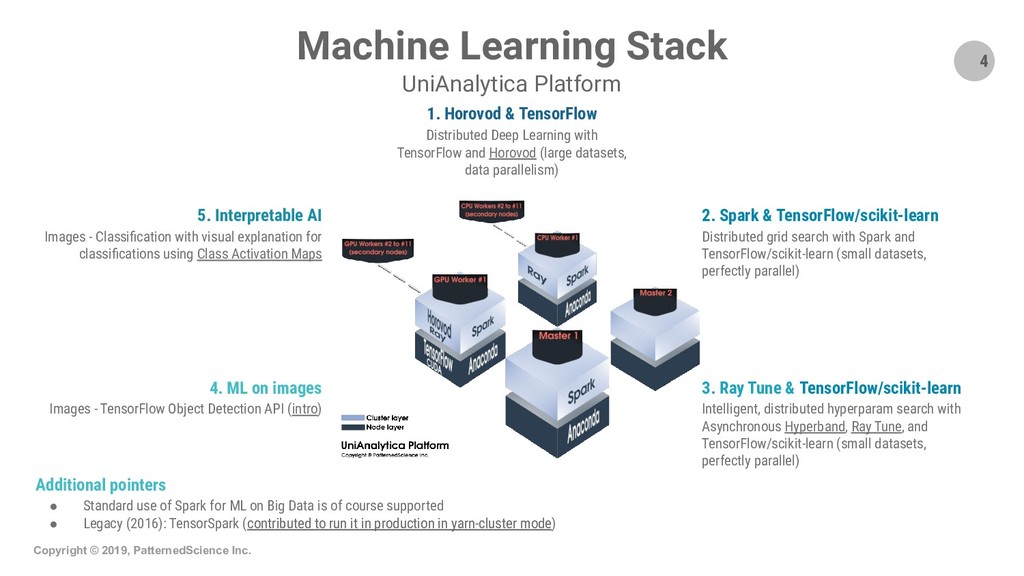
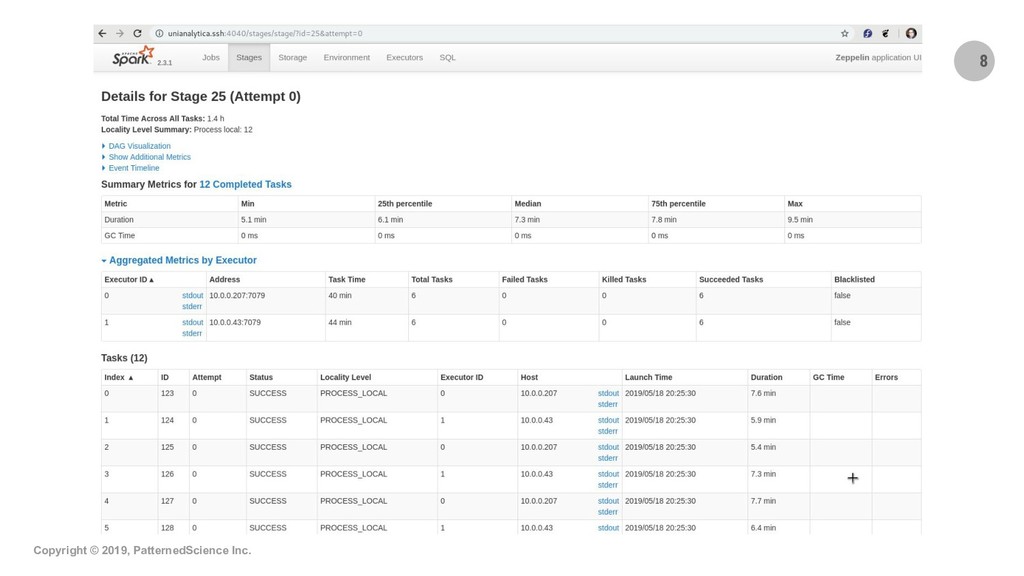
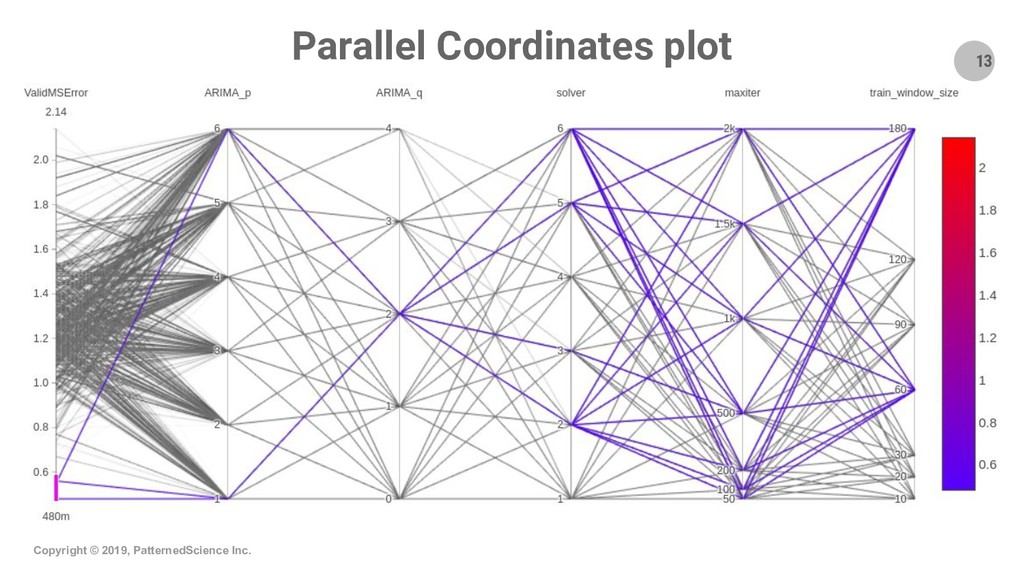
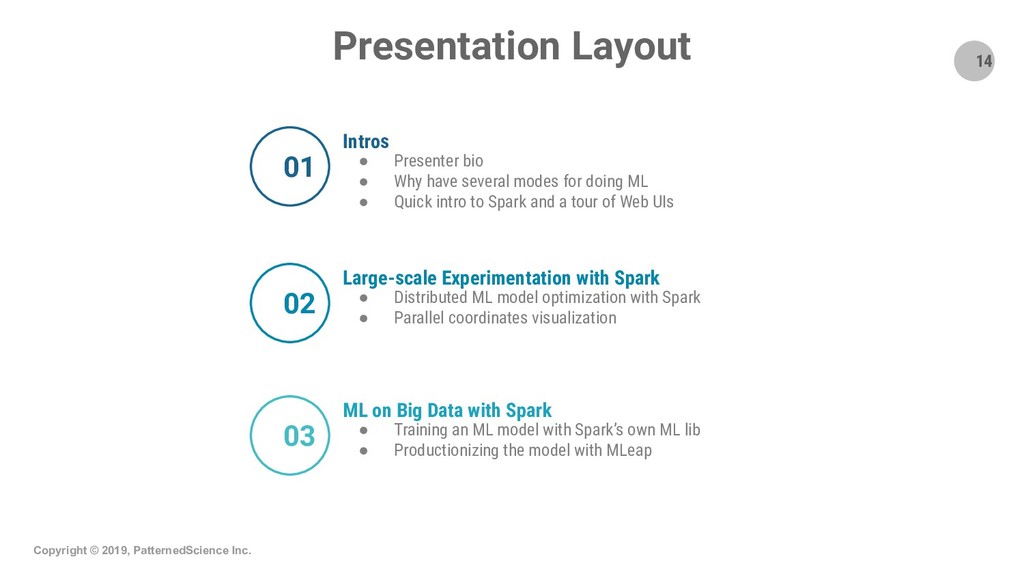
Summary: Apache Spark is the state-of-the-art distributed processing, analytics and ML engine and we are presenting and demo-ing two interesting ways one can use Spark in ML projects: 1) we use Spark to distribute the grid-search optimization of a generic ML model (from a regular, single-machine ML library). We show how Spark can distribute processing tasks over the CPU cores of a cluster which gives a near-linear speedup and lowers processing times; hence it facilitates the exploration of a much larger space to find the optimal hyperparameters for the ML model. This use case is suitable when the projects do not involve Big Data and we use Big Data technologies, i.e., Spark, for the purpose of speeding up the processing of tasks; 2) we demonstrate how to train an example model using the ML lib of Spark itself and how to serve the model with MLeap, a production-quality, low-latency serving engine. This second use case/workflow is suitable when projects do involve Big Data.
Bio: Masood Krohy is a Data Science Platform Architect/Advisor and most recently acted as the Chief Architect of UniAnalytica, an advanced data science platform with wide, out-of-the-box support for time-series and geospatial use cases. He has worked with several corporations in different industries in the past few years to design, implement and productionize Deep Learning and Big Data products. He holds a Ph.D. in computer engineering.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}