Masood Krohy at June 11, 2019 event of EDPP Montreal (montrealml.dev/data)
Title: Big Geospatial Data with Open-source Tech (Vectors, Rasters & Map-matching)
Presentation/Demo video: check out PatternedScience's YouTube channel at https://www.youtube.com/channel/UCjbEIZlS2DA45Bswi5EXWRw
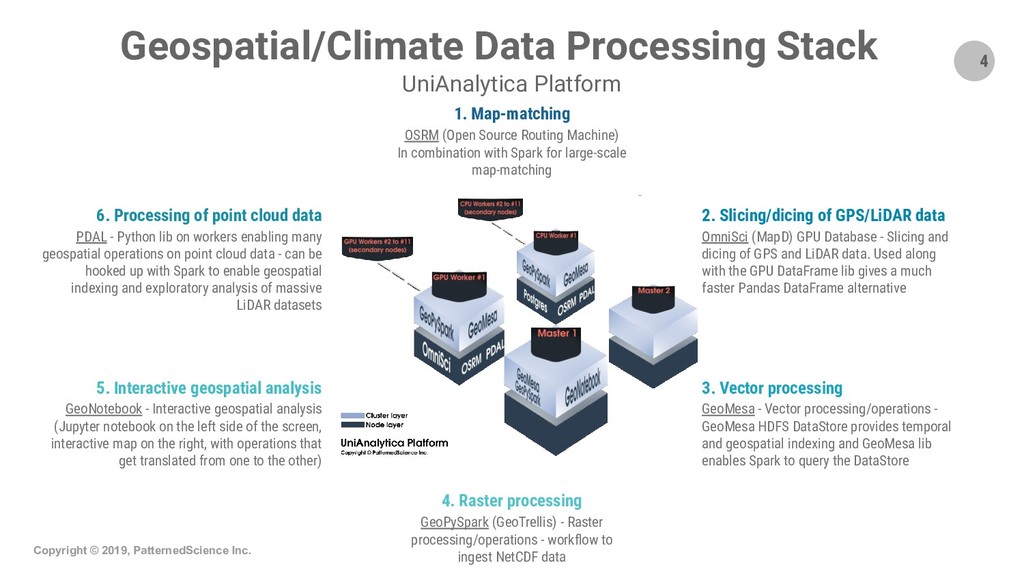
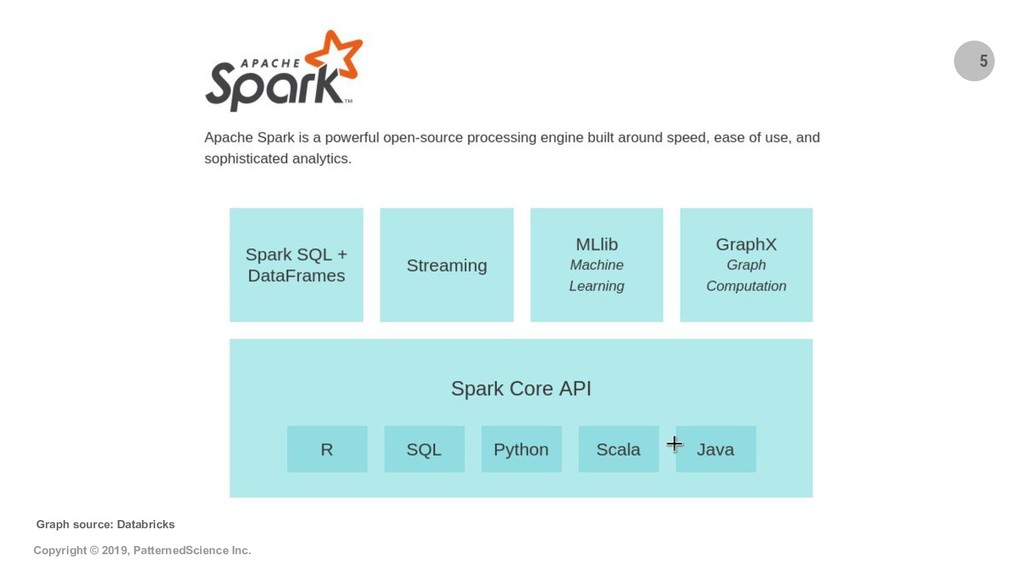
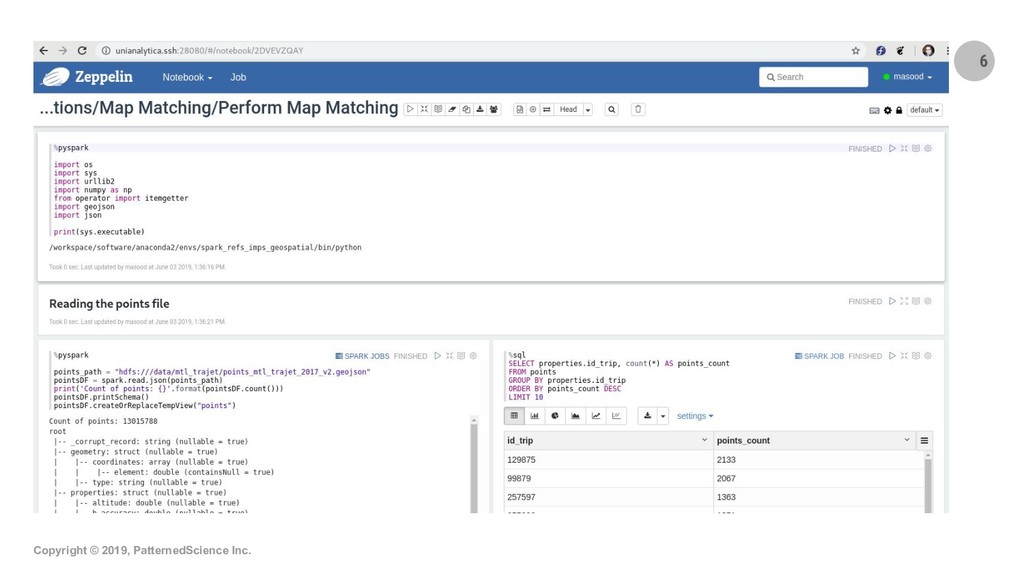
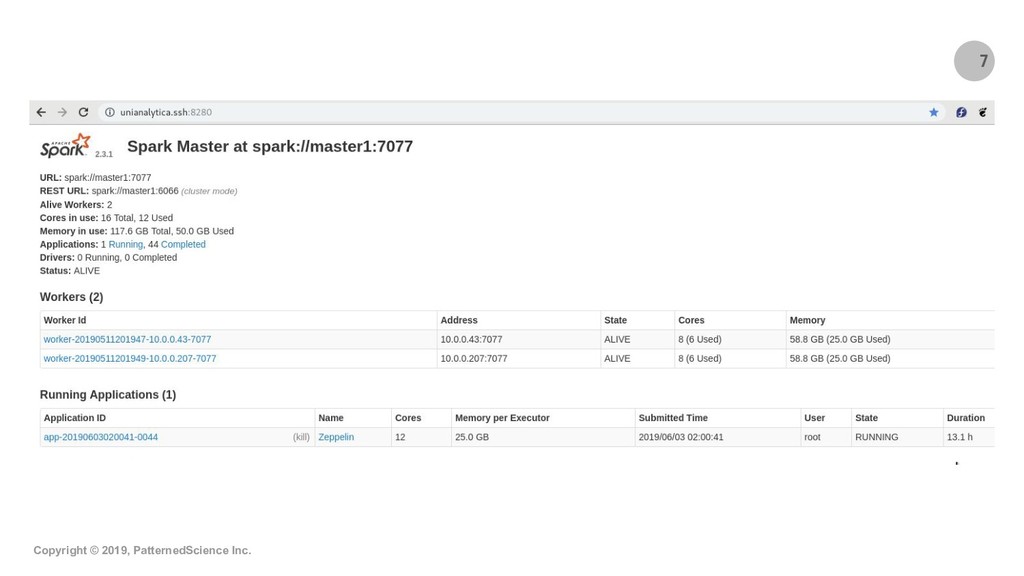
Summary: Geospatial datasets (i.e. geocoded data points) are everywhere nowadays and often add enormous value to data analytics/mining and machine learning projects. In this new era of Big Data, libraries and engines such as GeoPandas, PostGIS and the equivalent products in the commercial space often fall short and cannot scale up sufficiently to let us tap into the Big Data that is being collected in many use cases and by many organizations. In this talk/demo, we explore free, open-source, Big Data-ready technologies and workflows like GeoMesa, GeoPySpark and OSRM-on-Spark and show how to use these Apache Spark-based tech/workflows for key geospatial operations and use cases. We start by introducing GeoMesa and demo-ing how it can be used to ingest Big Geospatial Data and perform operations on vectors. Next, we briefly introduce GeoPySpark, the Python interface to Geotrellis, for performing operations on rasters. At the end, we turn to map-matching which is the process of associating names to geocoded data points from an underlying network (e.g., determining which street a particular GPS point should be associated with). We describe and demo how we can combine OSRM with Spark to do scalable map-matching on Big Data and therefore open up a lot of possibilities for advanced data mining and machine learning projects.
Bio: Masood Krohy is a Data Science Platform Architect/Advisor and most recently acted as the Chief Architect of UniAnalytica, an advanced data science platform with wide, out-of-the-box support for time-series and geospatial use cases. He has worked with several corporations in different industries in the past few years to design, implement and productionize Deep Learning and Big Data products. He holds a Ph.D. in computer engineering.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}