the O/R mapper do its job? • What are the performance indicators? General advices Execution plans Talking Points Note: Caching is completely ortogonal and is not in scope of this session
when the queries take hours Materialized views • Rather for special use cases Restructuring or splitting a query • Requires understanding of queries generated by an O/R mapper Database indexes • Requires the knowledge of operations executed by the database Use O/R Mapper • Not really a means to improve performance Possibilities to improve Performance
(seemingly) simple O/R mapper will optimize the queries for us Errors are thrown at runtime by the database • Even if the query compiles in .NET Higher memory and CPU consumption O/R Mappers
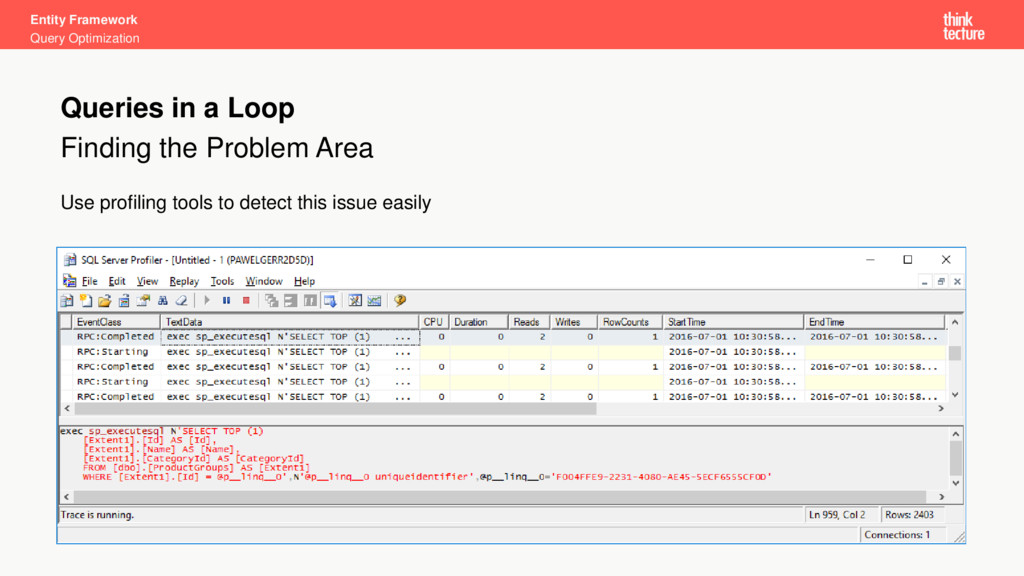
query shown below is easy to find and to fix Queries in a Loop using (var ctx = CreateContext()) { foreach (var product in products) { var group = ctx.ProductGroups.FirstOrDefault(g => g.Id == product.GroupId); } }
go • Load all records when the data set is small • Use Contains() for small collections (say groupIds < 50) • Use temp tables with bulk insert for big collections Queries in a Loop var groupIds = products.Select(p => p.GroupId).Distinct().ToList(); var groupsLookup = ctx.ProductGroups.Where(g => groupIds.Contains(g.Id)).ToDictionary(g => g.Id); foreach (var product in products) { Do(product, groupsLookup[product.GroupId]); } ... public static void Do(Product product, ProductGroup group) { // do something }
temp table to Entity Framework For detailed information see my blog: Entity Framework: High performance querying trick using SqlBulkCopy and temp tables Temp Tables in Entity Framework <EntitySet Name="TempTable" EntityType="Self.TempTable"> <DefiningQuery> SELECT #TempTable.Id FROM #TempTable </DefiningQuery> </EntitySet> // insert group ids into temp table using SqlBulkCopy var groupsLookup = ctx.ProductGroups .Join(ctx.TempTable, group => group.Id, temp => temp.Id, (group, temp) => group) .ToDictionary(g => g.Id); ...
is good or not? Is the database properly indexed? Understanding Queries var products = ctx.Products .Select(p => new { p.Name, FirstPriceStartdate = p.Prices.OrderBy(price => price.Startdate).FirstOrDefault().Startdate, FirstPriceValue = p.Prices.OrderBy(price => price.Startdate).FirstOrDefault().Value, }) .ToList();
tend to be huge The analysis of such query can be tedious Understanding Queries SELECT 1 AS [C1], [Project2].[Name] AS [Name], [Project2].[C1] AS [C2], [Limit2].[Value] AS [Value] FROM (SELECT [Extent1].[Id] AS [Id], [Extent1].[Name] AS [Name], (SELECT TOP (1) [Project1].[Startdate] AS [Startdate] FROM ( SELECT [Extent2].[Startdate] AS [Startdate] FROM [dbo].[Prices] AS [Extent2] WHERE [Extent1].[Id] = [Extent2].[ProductId] ) AS [Project1] ORDER BY [Project1].[Startdate] ASC) AS [C1] FROM [dbo].[Products] AS [Extent1] ) AS [Project2] OUTER APPLY (SELECT TOP (1) [Project3].[Value] AS [Value] FROM ( SELECT [Extent3].[Startdate] AS [Startdate], [Extent3].[Value] AS [Value] FROM [dbo].[Prices] AS [Extent3] WHERE [Project2].[Id] = [Extent3].[ProductId] ) AS [Project3] ORDER BY [Project3].[Startdate] ASC ) AS [Limit2]
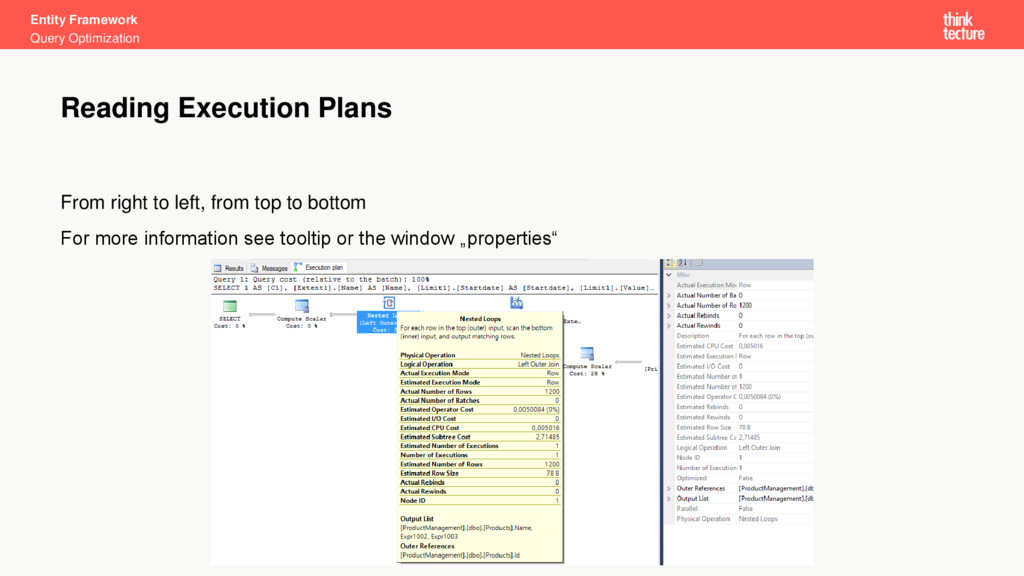
database operations • Type and the order of operations (JOIN, filter, projection, ...) • Indexes being used • Amount of data flowing between two operations • Costs of an operation and a subtree Types • Estimated Execution Plan • Actual Execution Plan Execution Plans
The last operation of a reading query Filter • Filtering of a result set according to a predicate (WHERE clause) when none of the indexes match Sort • „Stop and Go“ operator Top • Returns first x records Execution Plans
MIN(), MAX(), AVG() Arithmetic Expression • Arithmetic computations applied on every record Compute Scalar • Computes new values from existing values in a row Execution Plans
Table does not have a clustered index • Database iterates over whole table Clustered Index Scan • Database iterates over clustered index Non-Clustered Index Scan • Database iterates over non-clustered index Clustered Index Seek • Database uses clustered index to „jump“ directly to the record Non-Clustered Index Seek • Database uses non-clustered index to „jump“ directly to the record Execution Plans
when both sets are ordered by the join condition • Very performant Hash Match Join • 2 phases: • Build: building of a hash table for the first data set • Probe: computes the hash values for the second data set and searches for the matching records in the previously computed hash table • Computation of the hash values requires more resources but is performant afterwards Nested Loop Join • Like 2 nested for-each-loops Execution Plans
Caching of interim results in a temporary table for reuse in other operations Non-Clustered Index Spool • Creation of temporary index Types of spool operations • Eager Spool: • „Stop and Go“ operator • All records will be cached at once • Lazy Spool: • Cache record by record on demand Execution Plans
data to compute it in parallel Gather Streams • Merging of result sets Parallelism • Is used along with other operations to indicate parallelism Execution Plans
the execution time of specific tasks from hours to milliseconds • Rewriting a query in .NET has effekt on the SQL statement generated by Entity Framework • Use profiling tools to detect unnecessary queries like queries in loops • Use execution plans to optimize a query Summary
![Entity Framework Query Optimization Pawel Gerr @pawelgerr [email protected]](https://files.speakerdeck.com/presentations/64f9e00a5b574230b58fc64b02bb2f83/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}