2025年12月16日に東京ミッドタウンホール&カンファレンスで開催された『MN-Core Technology Conference 25』の講演スライドです。本スライドは、以下のスケジュールで行われたセッションの発表資料です。
A会場
1.MN-Coreの展望 的矢 知樹(AIコンピューティング事業本部 事業戦略・プロダクトマーケティング部 部長)
2.MN-Coreの設計思想 牧野 淳一郎(コンピュータアーキテクチャ担当CTO)
3.MN-Core Arch deep dive 真島 優輔(AIコンピューティング事業本部 MN-Core 開発部 Engineering Manager)
4.誰もがMN-Coreを利用できるAIクラウドサービス: Preferred Computing Platform 照屋 大地(AIコンピューティング事業本部 基盤技術部 部長)
B会場
MN-Coreの性能を引き出す技術〜HPL/姫野ベンチマーク編〜 安達 知也(AIコンピューティング事業本部 ソフトウェア開発部 エンジニア)
MN-Core SDK × LLM推論 樋口 兼一(AIコンピューティング事業本部 ソフトウェア開発部) /坂本 亮(AIコンピューティング事業本部 ソフトウェア開発部 部長)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
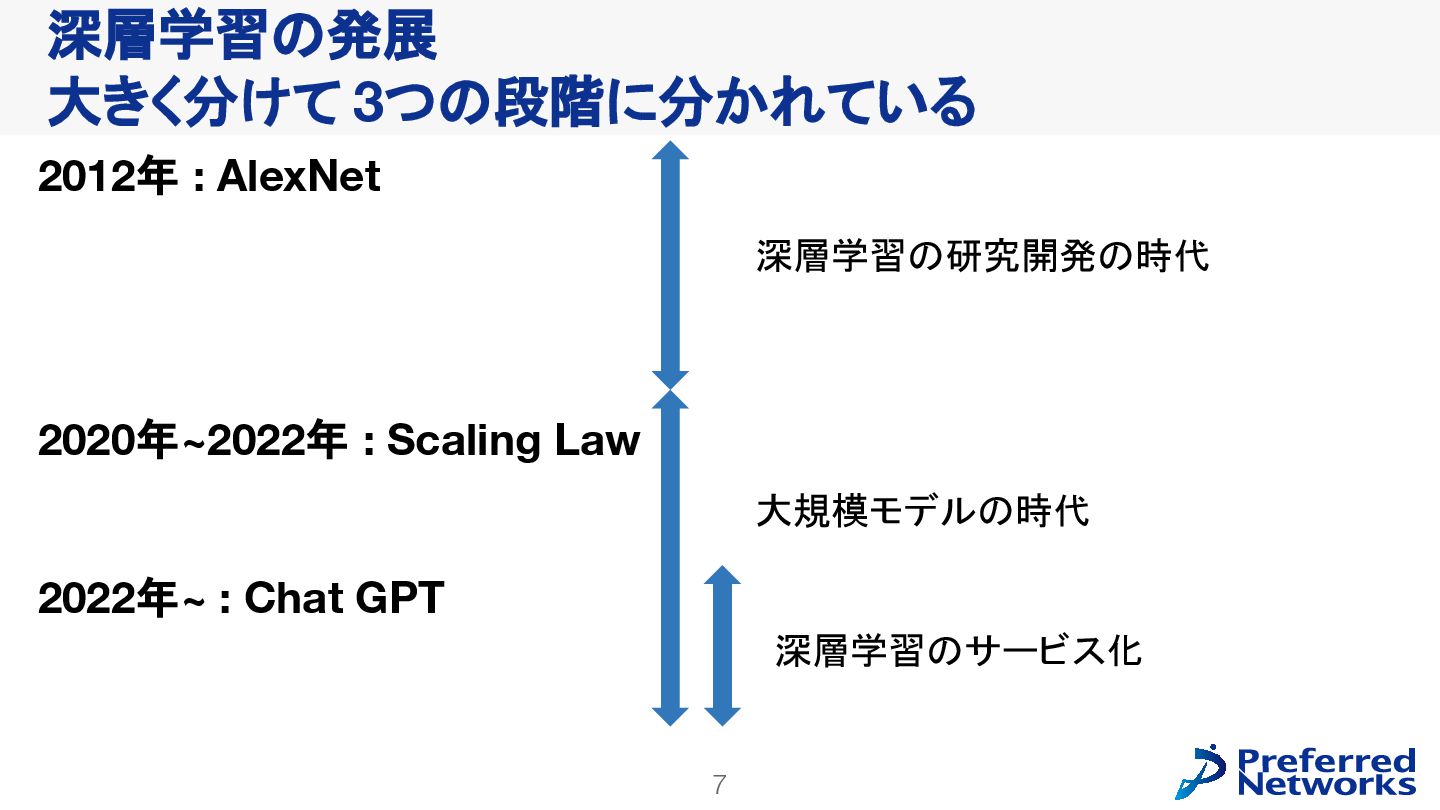{kind=link}
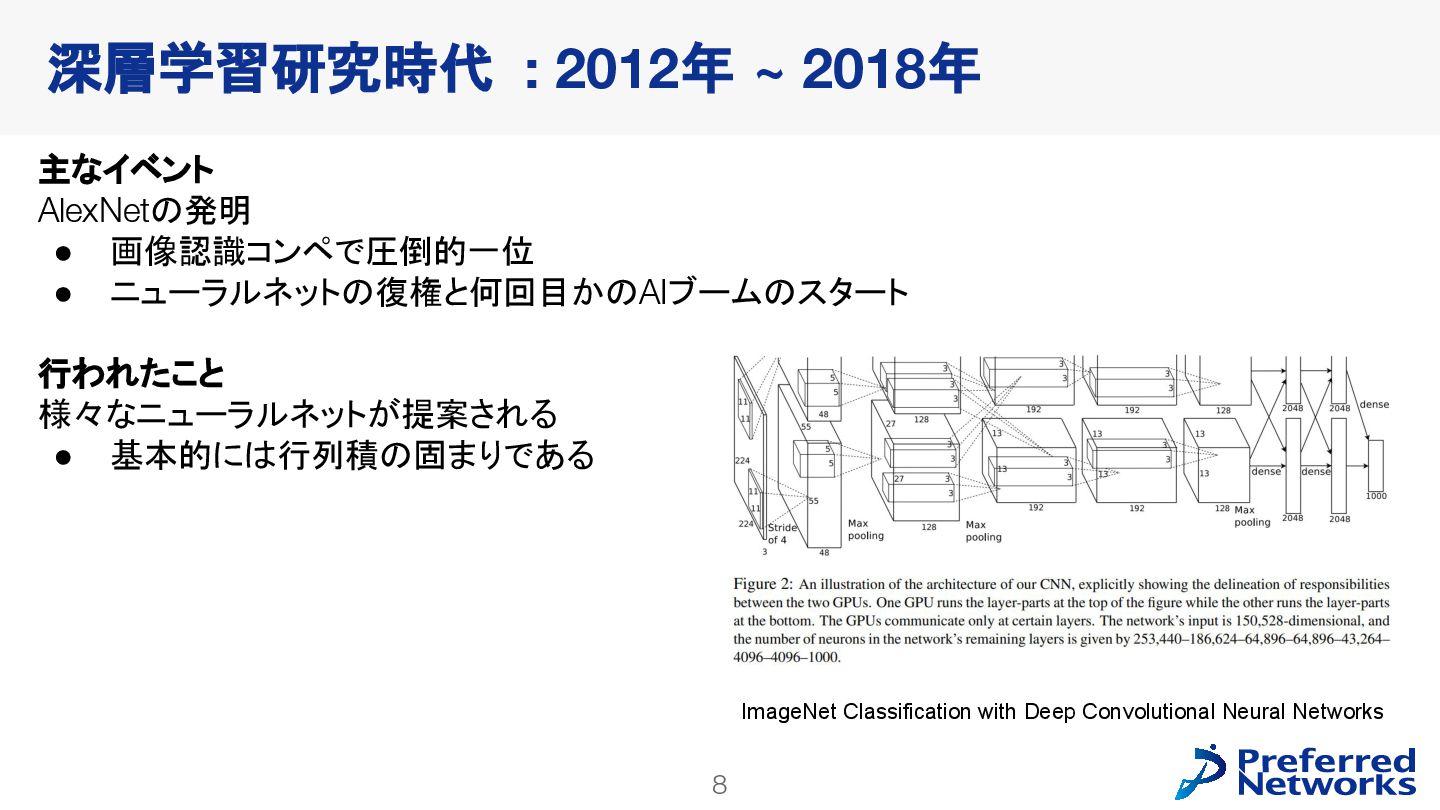{kind=link}
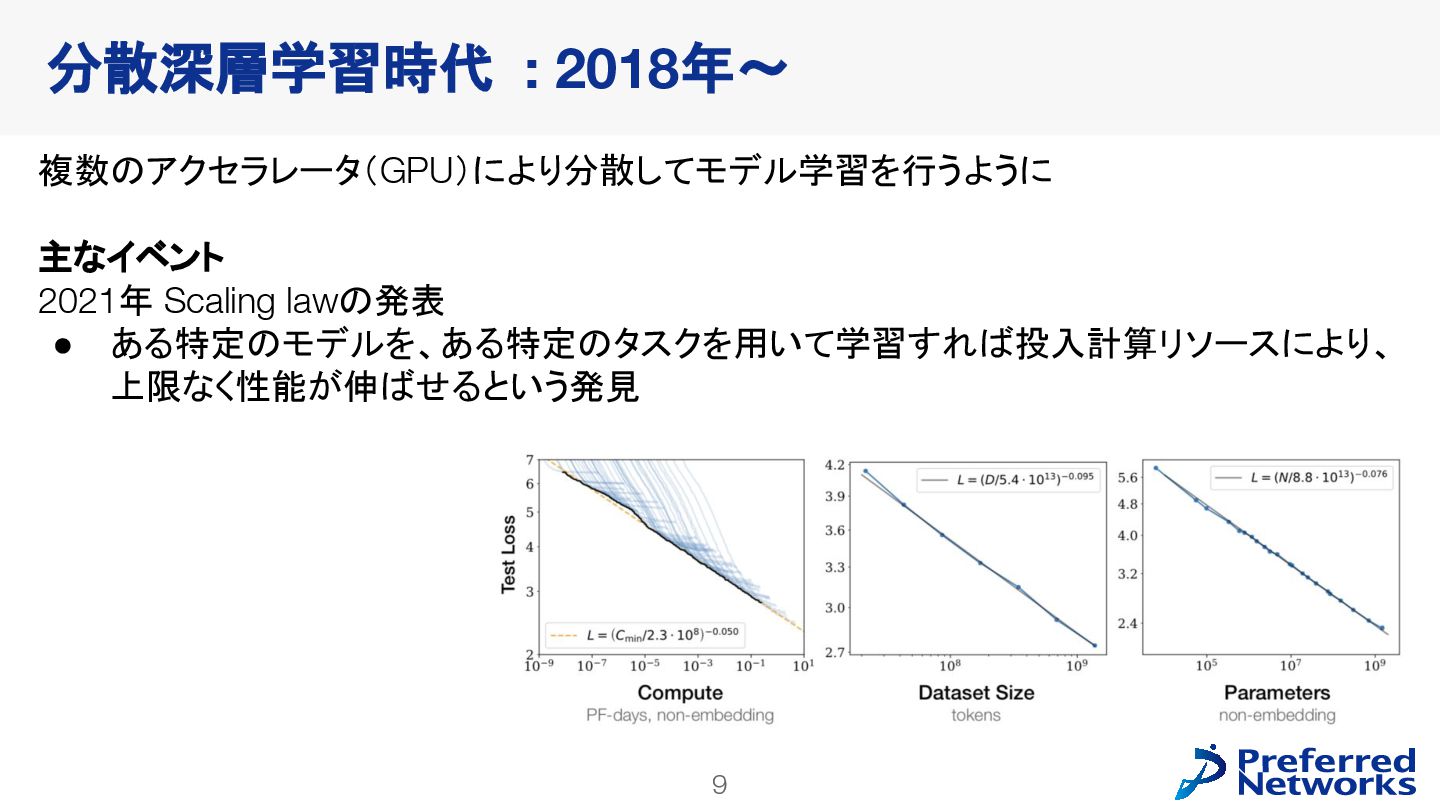{kind=link}
{kind=link}
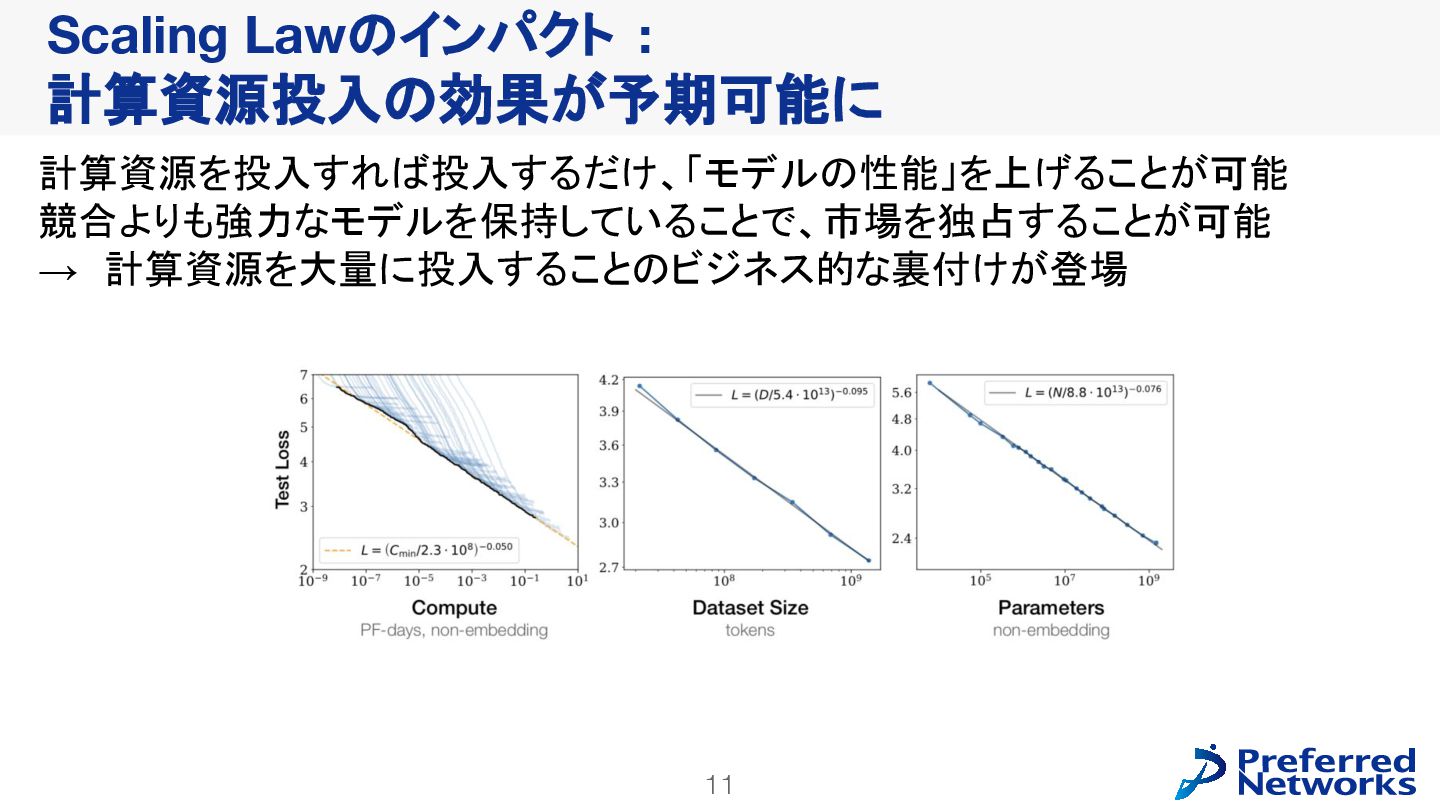{kind=link}
{kind=link}
{kind=link}
{kind=link}
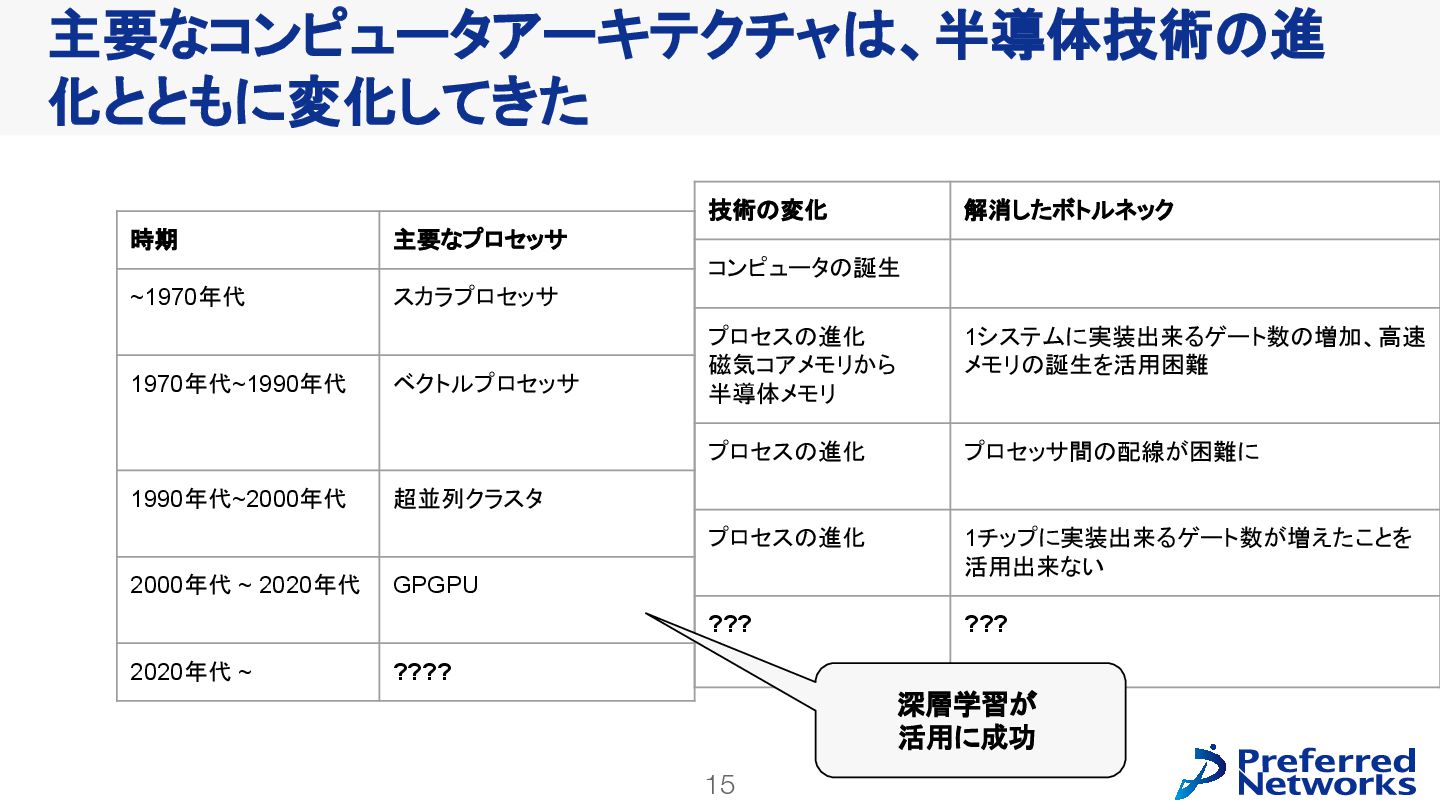{kind=link}
{kind=link}
{kind=link}
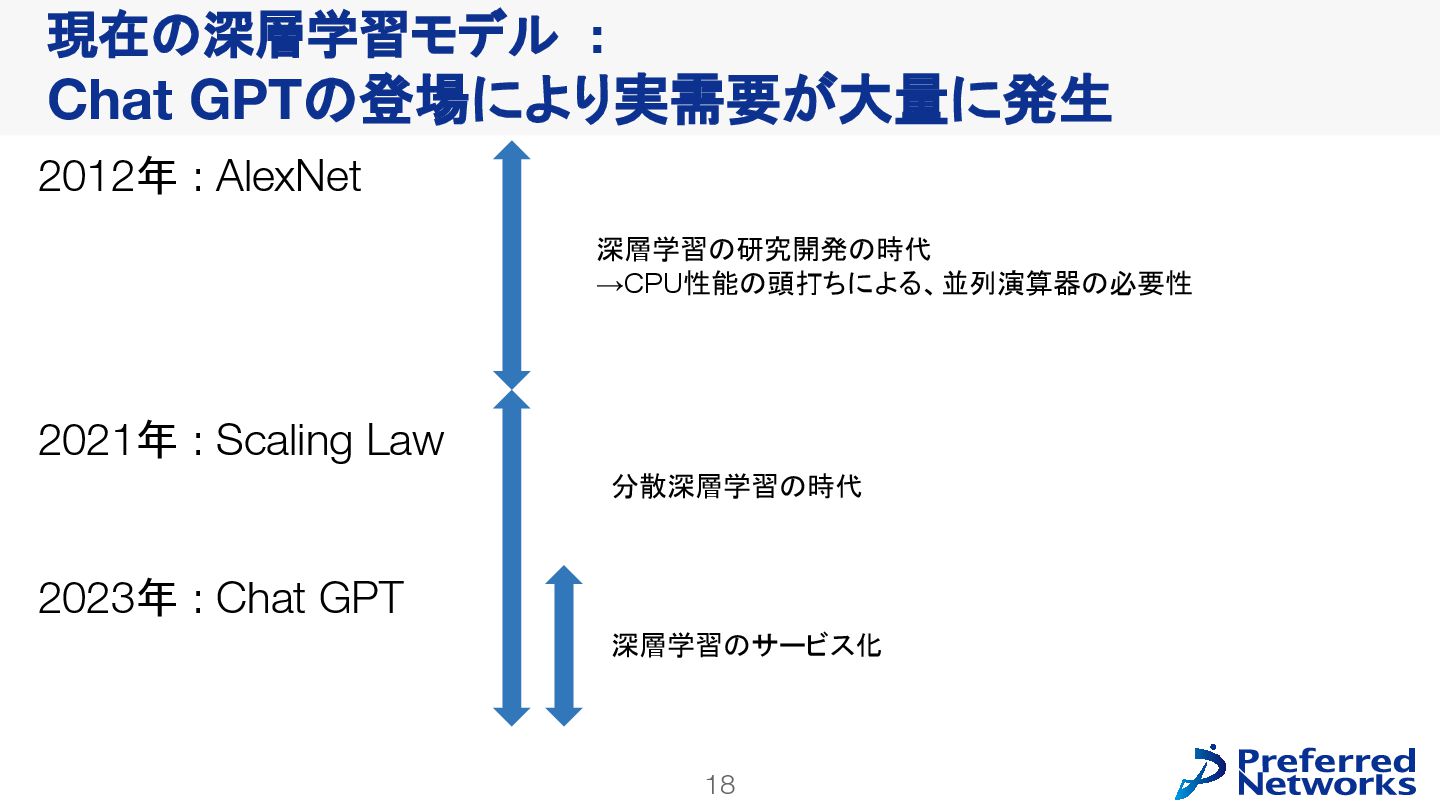{kind=link}
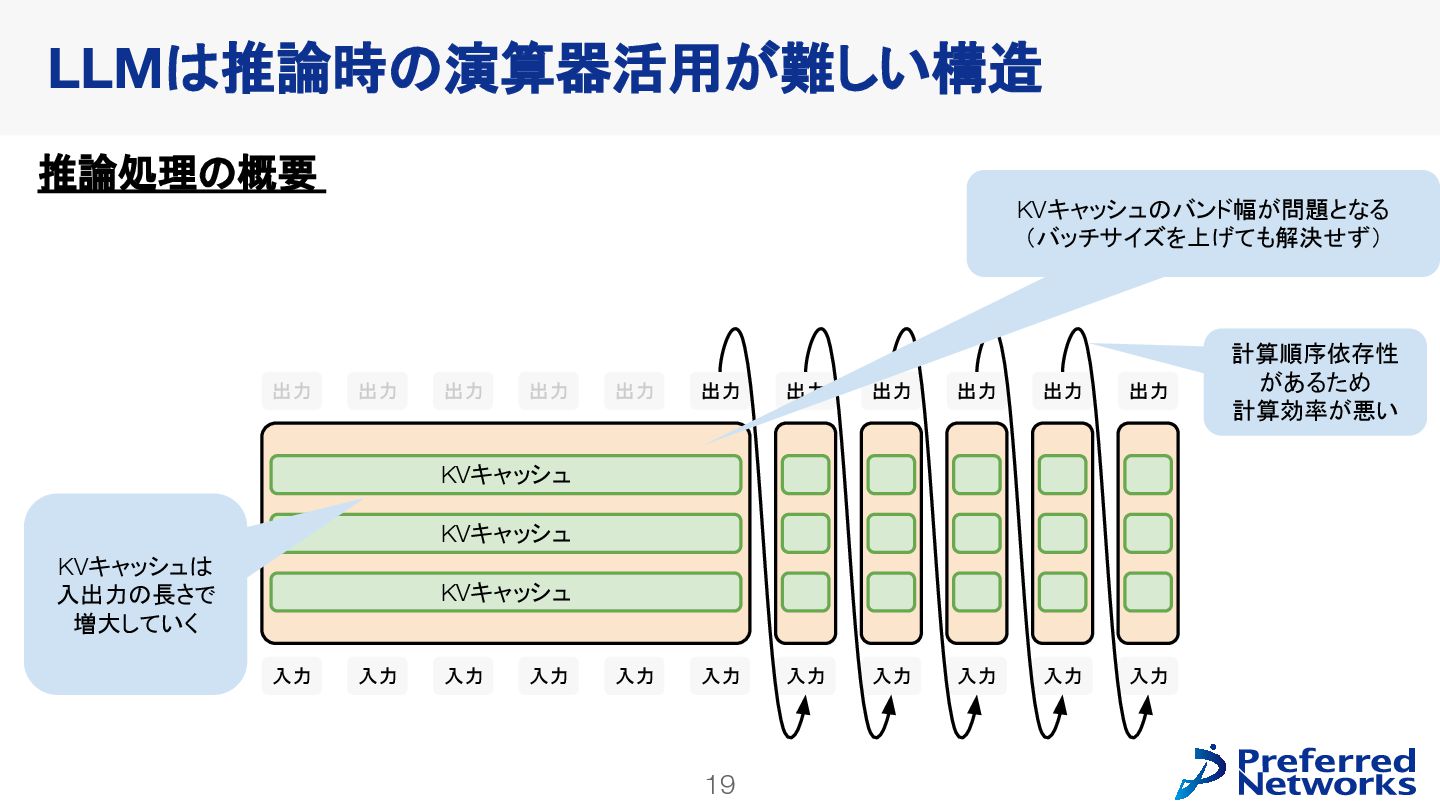{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}