AVG(sales) OVER (PARTITION BY gtime) FROM tenant_master as tm, user_sales as us where tm.name = “pingcap”; データ量が増えた場合にバッチ処理へ バッチ処理なしでリアルタイムに結果を出力が可能に 個別ユーザの集計するクエリが多くなると遅くなるとクエ リでは対応できない為、バッチ処理が必須
1* 読み書き可能 Region 2 バックアップ TiKV B Region 3 バックアップ Region 1 バックアップ Region 2* 読み書き可能 TiKV C Region 3* 読み書き可能 Region 1 バックアップ Region 2 バックアップ ユーザーテーブル データサイズは、デフォルト 96MB ※小さいサイズにする事で柔軟性を確保 Raftログによるコンセンサスアルゴリズム ひとつの読込/書込ポイントと2つのバックアップ ※ 圧縮を行っているので、バックアップありの状態でMySQL一台の容量とほぼ同じになる事も 96MB 96MB 96MB TiDBアーキテクチャー
バックアップ Region 1* 読み書き可能 Region 2 バックアップ TiKV Region 3 バックアップ Region 1 バックアップ Region 2* 読み書き可能 TiKV Region 3* 読み書き可能 Region 1 バックアップ Region 2 バックアップ オンラインでの容量伸縮 96MBという小さいサイズで管理している為、 ノード追加した瞬間からデータ移行が開始 バックアップが読み書きを引き継ぐ機能により様々な問題を解決 昇格(リーダ) ノーメンテナンス運用を実現 ファームウェアアップデート時にリーダーを 別ノードへ移動しローリングアップグレードが可能 TiKV Region 3 バックアップ Region 1* 読み書き可能 Region 2 バックアップ TiKV Region 3 バックアップ Region 1 バックアップ Region 2* 読み書き可能 TiKV Region 3* 読み書き可能 Region 1 バックアップ Region 2 バックアップ TiKV バックアップデータを移動し リーダーに昇格 TiKV Region 3 バックアップ Region 1* 読み書き可能 Region 2 バックアップ TiKV Region 3 バックアップ Region 1 バックアップ Region 2* 読み書き可能 TiKV Region 3* 読み書き可能 Region 1 バックアップ Region 2 バックアップ 昇格(リーダ) まず、このノードをアップグレードしリーダを 移動しながら順に対応 TiDBアーキテクチャー
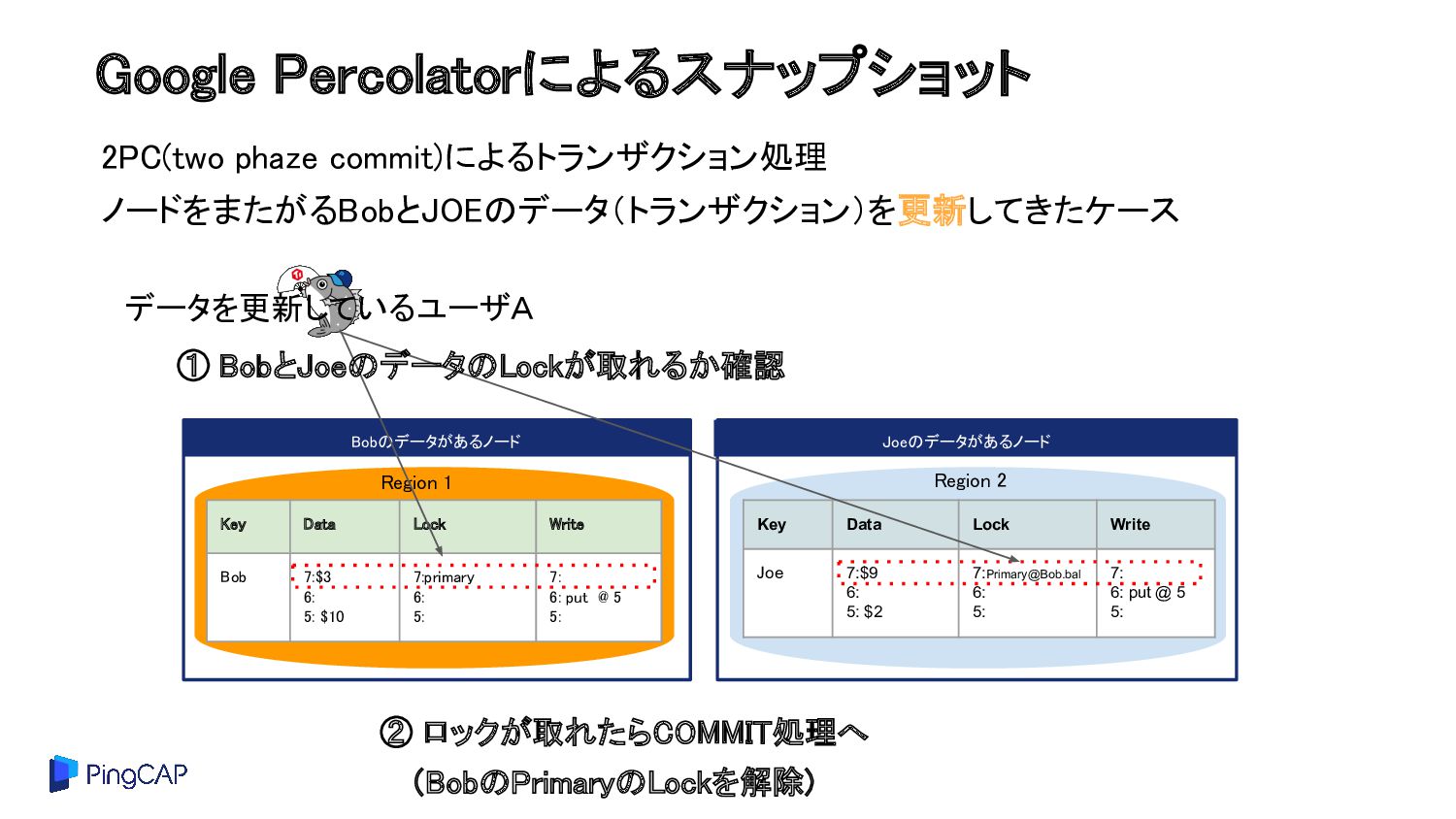
Key Data Lock Write Bob 7:$3 6: 5: $10 7:primary 6: 5: 7: 6: put @ 5 5: Key Data Lock Write Joe 7:$9 6: 5: $2 7:[email protected] 6: 5: 7: 6: put @ 5 5: Region 2 Joeのデータがあるノード ① BobとJoeのデータのLockが取れるか確認 ② ロックが取れたらCOMMIT処理へ (BobのPrimaryのLockを解除)
悲観ロック 楽観ロック Column Family Key Value CF_Write key, commit_ts Lockステータスあり WAITでロック解放を待つ ロックでの待ちは発生なし Select … for updateによるロック挙動 Google Percolatorによるスナップショット
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}