Estimating the size of the treatment effects: Moving beyond p values. Psychiatry 6, 21-29. Moonesinghe, R., Khoury, M. J., Janssens, A. C. J. W. (2007). Most published research findings are fales- But a little replication foes a long way. PLoS Med 4 e28. Retrieved from http://www.plosmedicine.org/article/info%3Adoi%2F10.1371%2Fjournal.pmed.0040028#pmed-0040028-g002 Platt, J. R. (1964). Strong inference: Certain systematic method of scientific thinking may produce much more rapid progress than others. Science 146, 347-353. Ross, J. S., Mulvey, G. K., Hines, E. M., Nissen, S. E., Krumholz, H. M. (2009). Trial Publication after registration in clincaltrials.gov: A Cross-sectional analysis. Rossi, J. S. (1990). Statistical power of psychological research: What have we gained in 20 years? Journal of Consulting and Clinical Psychology 58, 646-656. Scragle, J. D. (2000). Publication bias: The “File-Drawer” problem in scientific inference. Journal of Scientific Exploration 14, 91- 106. Simons, D. J. (2014). The value of direct replication. Perspectives on Psychological Science 9, 76-80. Song, F., Parekh-Bhurke, S., Hooper, L., Loke, Y. K., Ryder, J. J., Sutton, A. J., Hing, C. B., & Harvey, I. (2009) Extent of publication bias in different categories of research cohorts: A Meta-analysis of empirical studies. British Medical Journal 9, 79-93. Sullivan, G. M. & Feinn, R. .(2012). Using effect size- or why P value is not enough. Journal of Graduate Medical Education 4, 279- 282. van Assen, M. A. L. M., van Aert, R. C. M., Nuijten, M. B., & Wicherts, J. M. (2014). Why publishing everything is more important then selective publishing of statistically significant results. PLoS ONE: 9, 10.1371.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
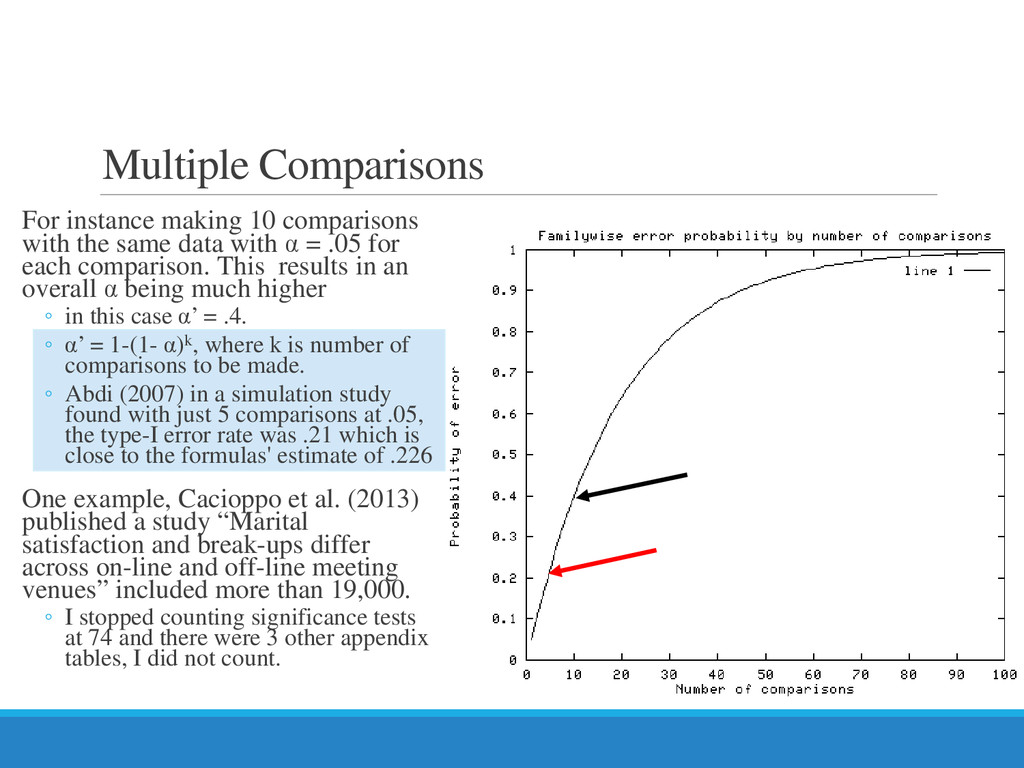{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
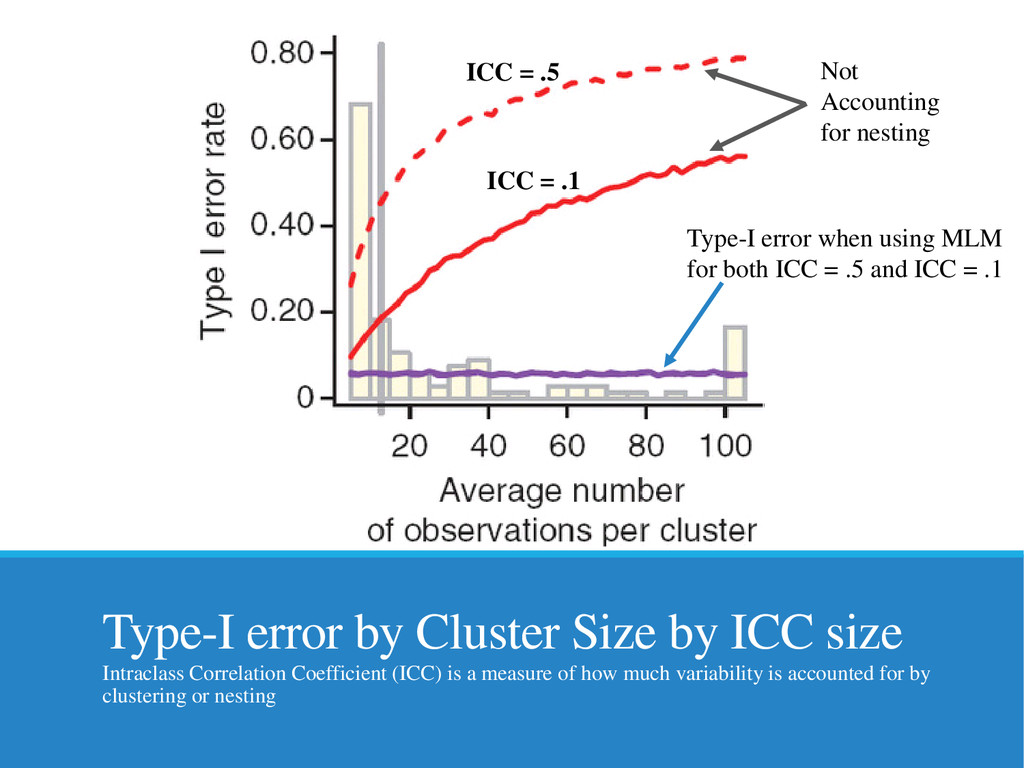{kind=link}
![Under [and Over] Powered Authors will claim with an increase](https://files.speakerdeck.com/presentations/0e3dc9309e920131ae820e8bbe6a5680/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Assumption Checking Assumptions [talk in its own right] ◦ Every](https://files.speakerdeck.com/presentations/0e3dc9309e920131ae820e8bbe6a5680/slide_40.jpg){kind=link}
{kind=link}
![Missing Data Missing data [Another talk in its own right]](https://files.speakerdeck.com/presentations/0e3dc9309e920131ae820e8bbe6a5680/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
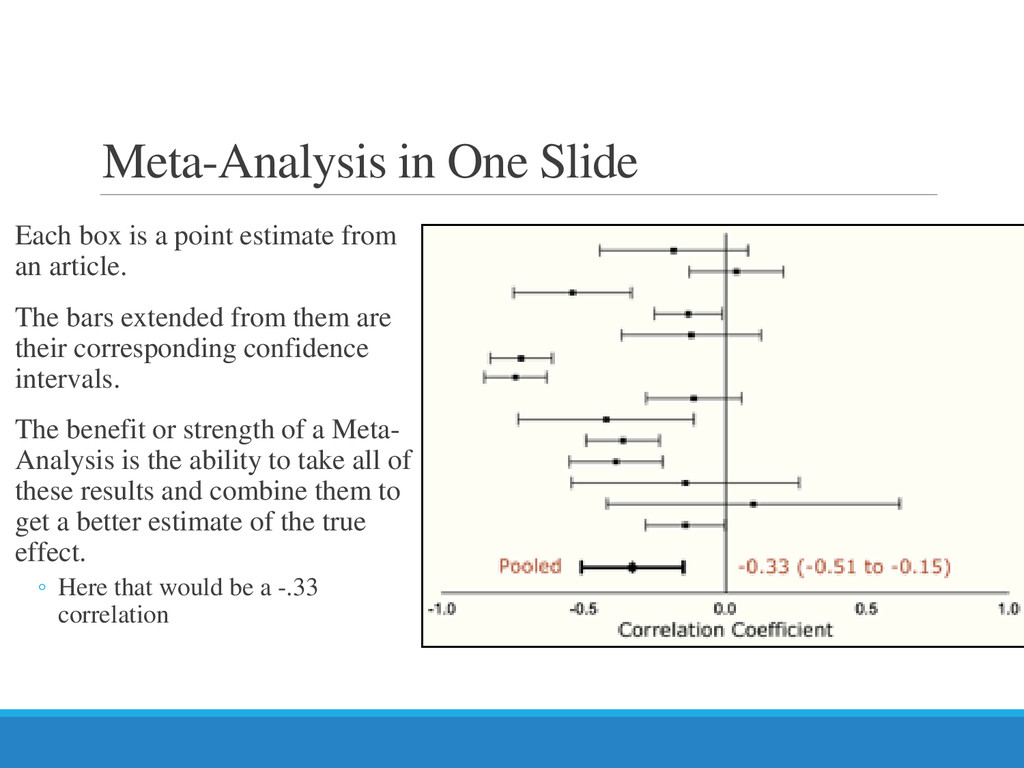{kind=link}
{kind=link}
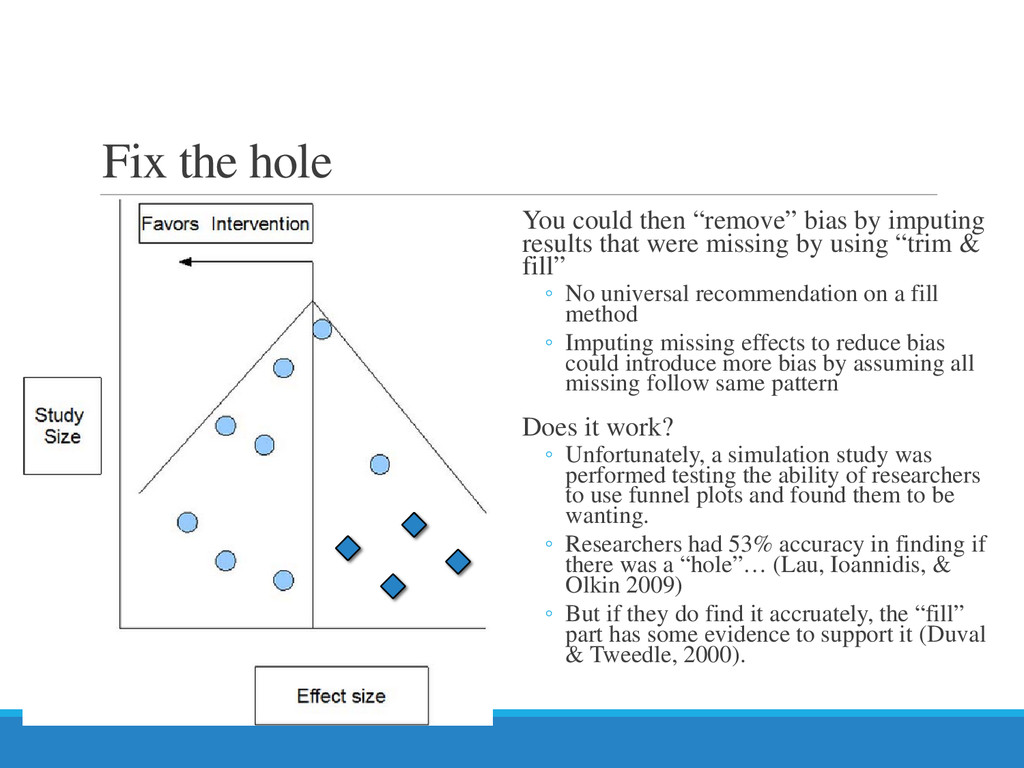{kind=link}
{kind=link}
{kind=link}
{kind=link}
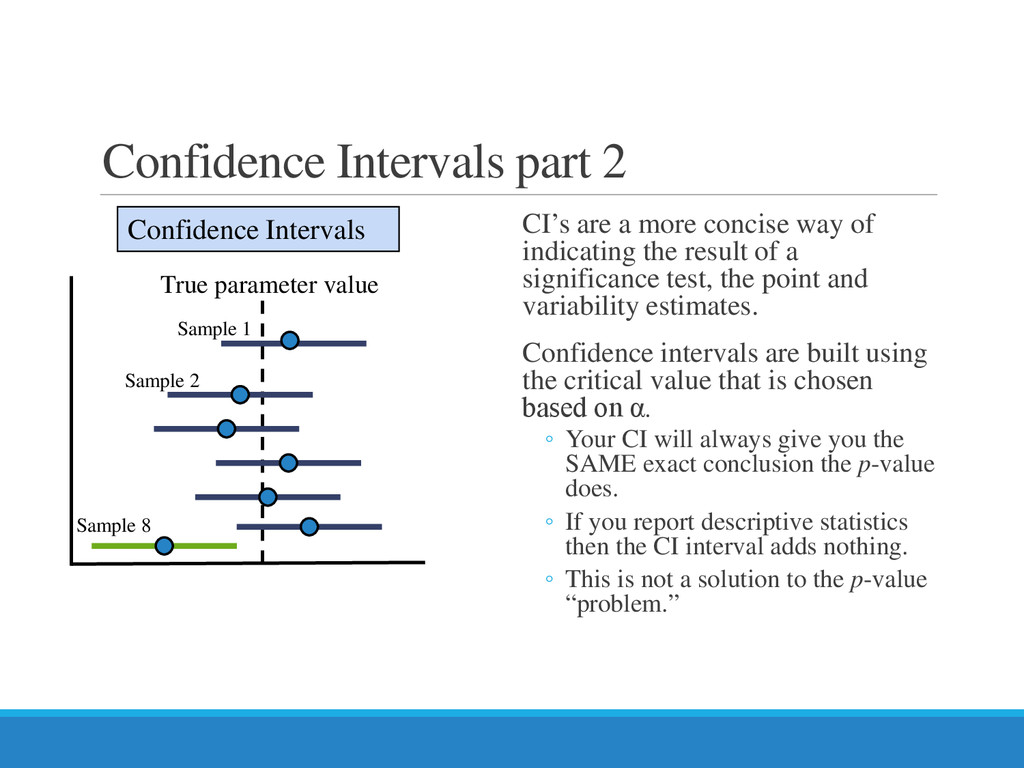{kind=link}
{kind=link}
{kind=link}
{kind=link}
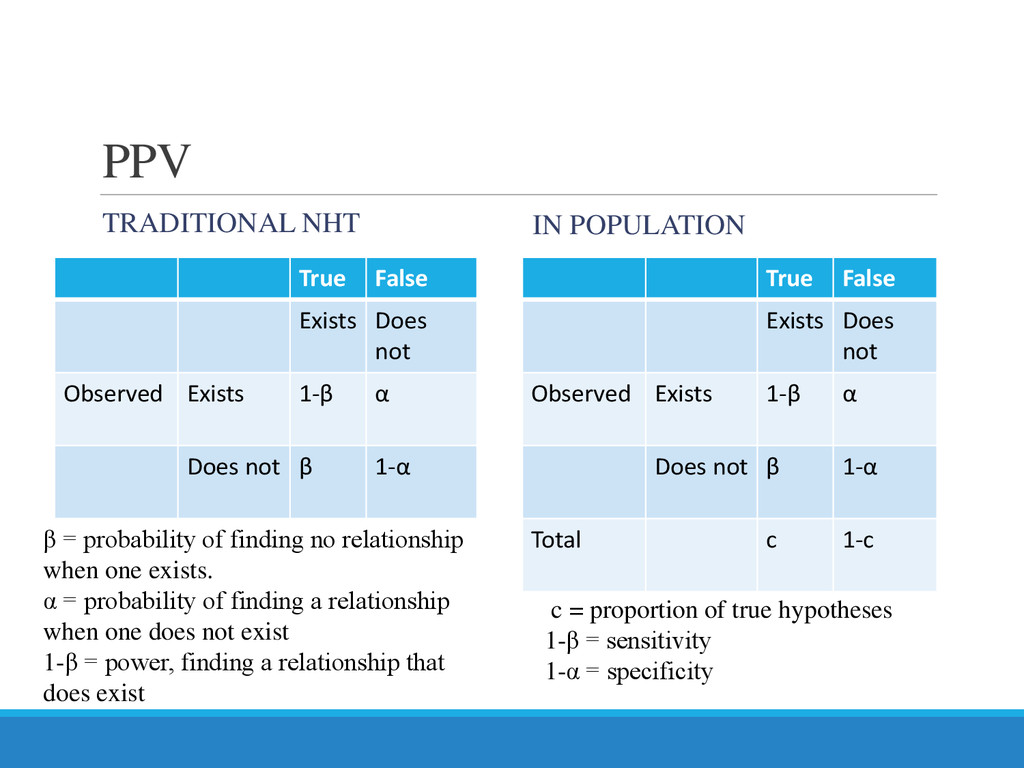{kind=link}
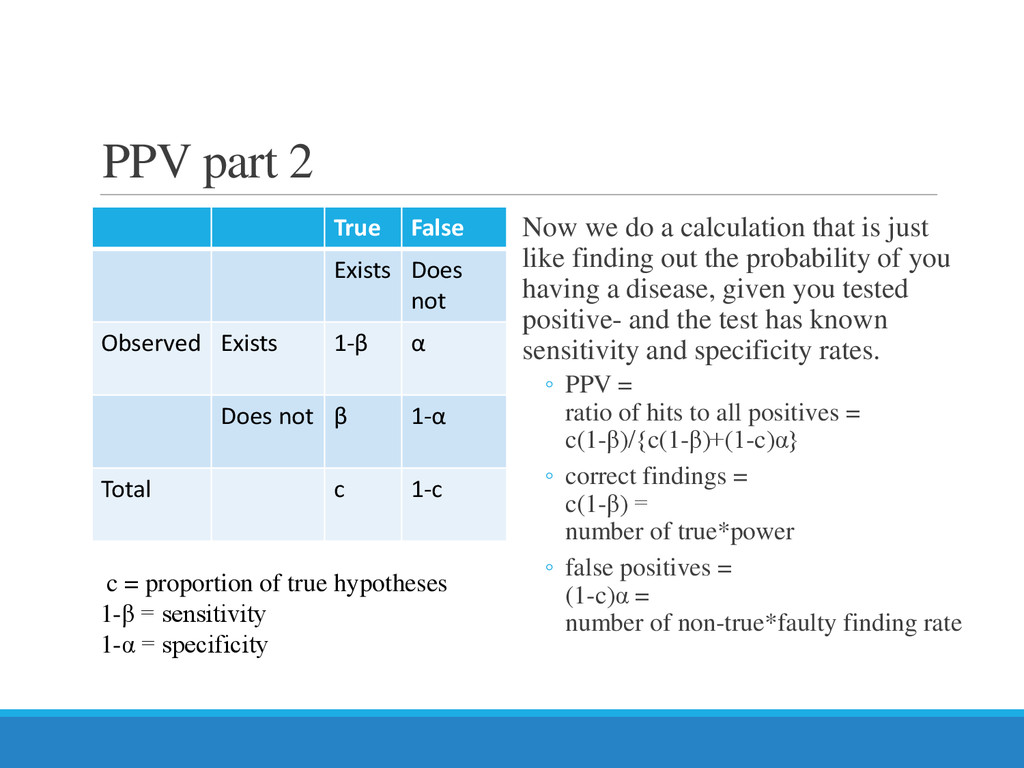{kind=link}
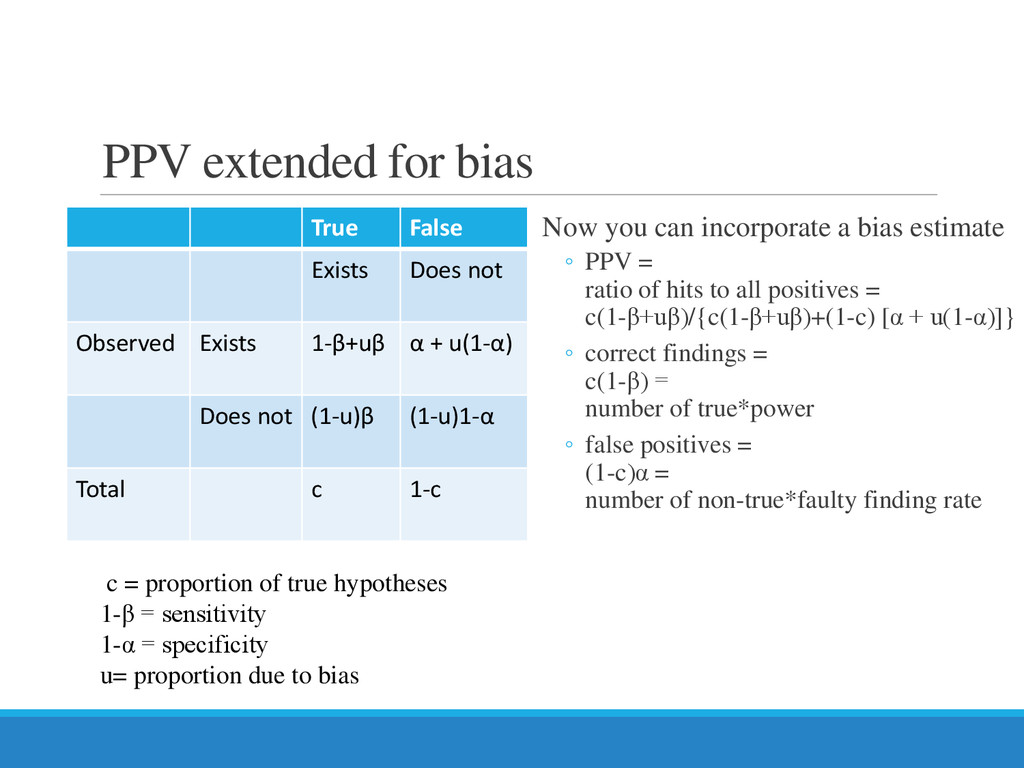{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![In closing “[N]o scientific worker has a fixed level of](https://files.speakerdeck.com/presentations/0e3dc9309e920131ae820e8bbe6a5680/slide_82.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}