Critical application more signification today o Multi Cloud / Hybrid cloud solution is all around • Challenge and solution ? o Cloud facilities for HA o Kubernetes across region o Kubernetes cluster federation (KubeFed) o ClusterMesh new game changer (with Cilium 1.12) • Service Affinity for Multi-Cluster Load-Balancing
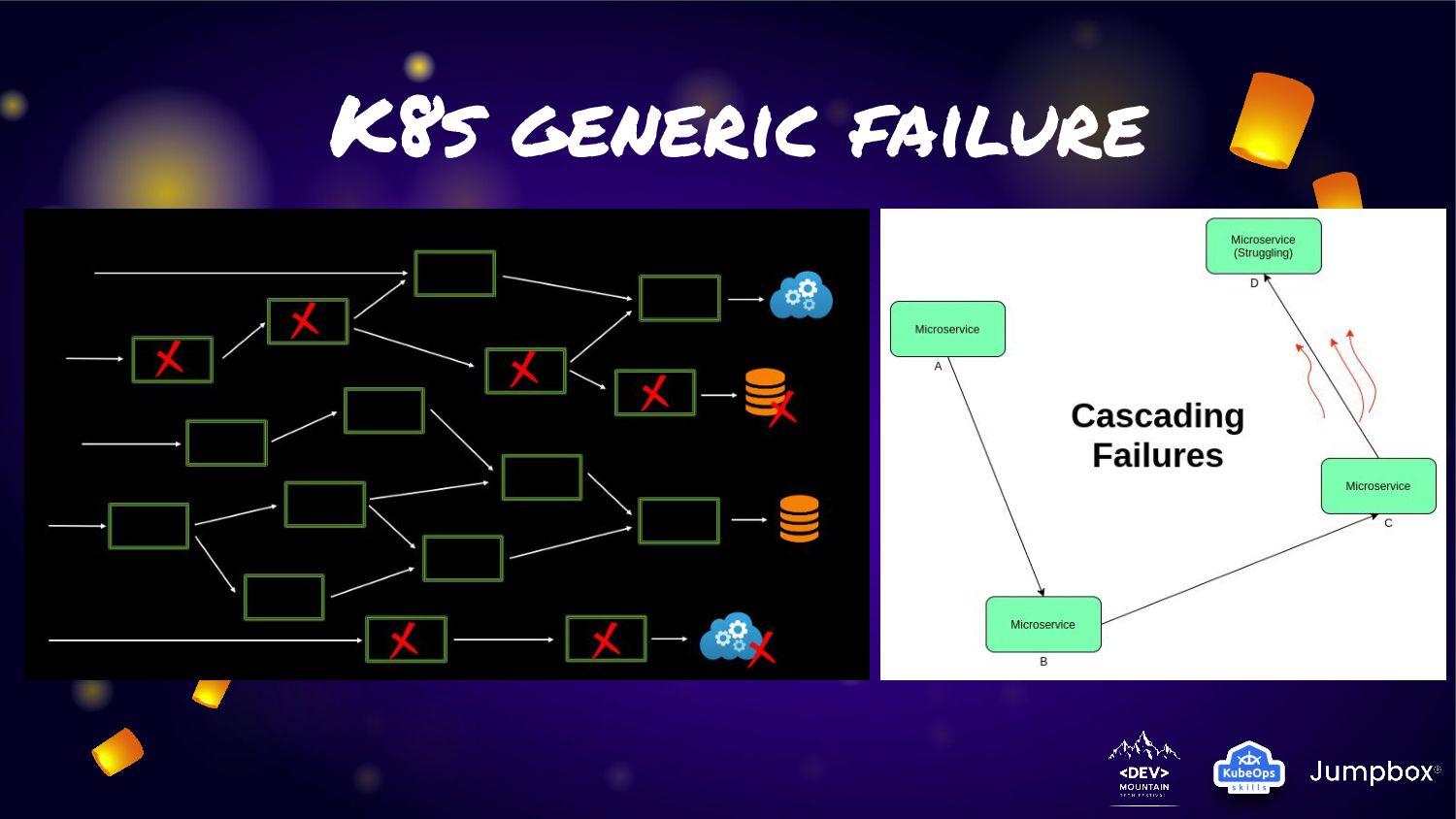
people every day. • Failure can happen in every component. But user more expect available for our system (24 hours x 7 days). • Solution for extreme HA was need. As the proactive for single element failure may not enough. • As application today is microservice. So some critical microservice may bring cascade failure!!!
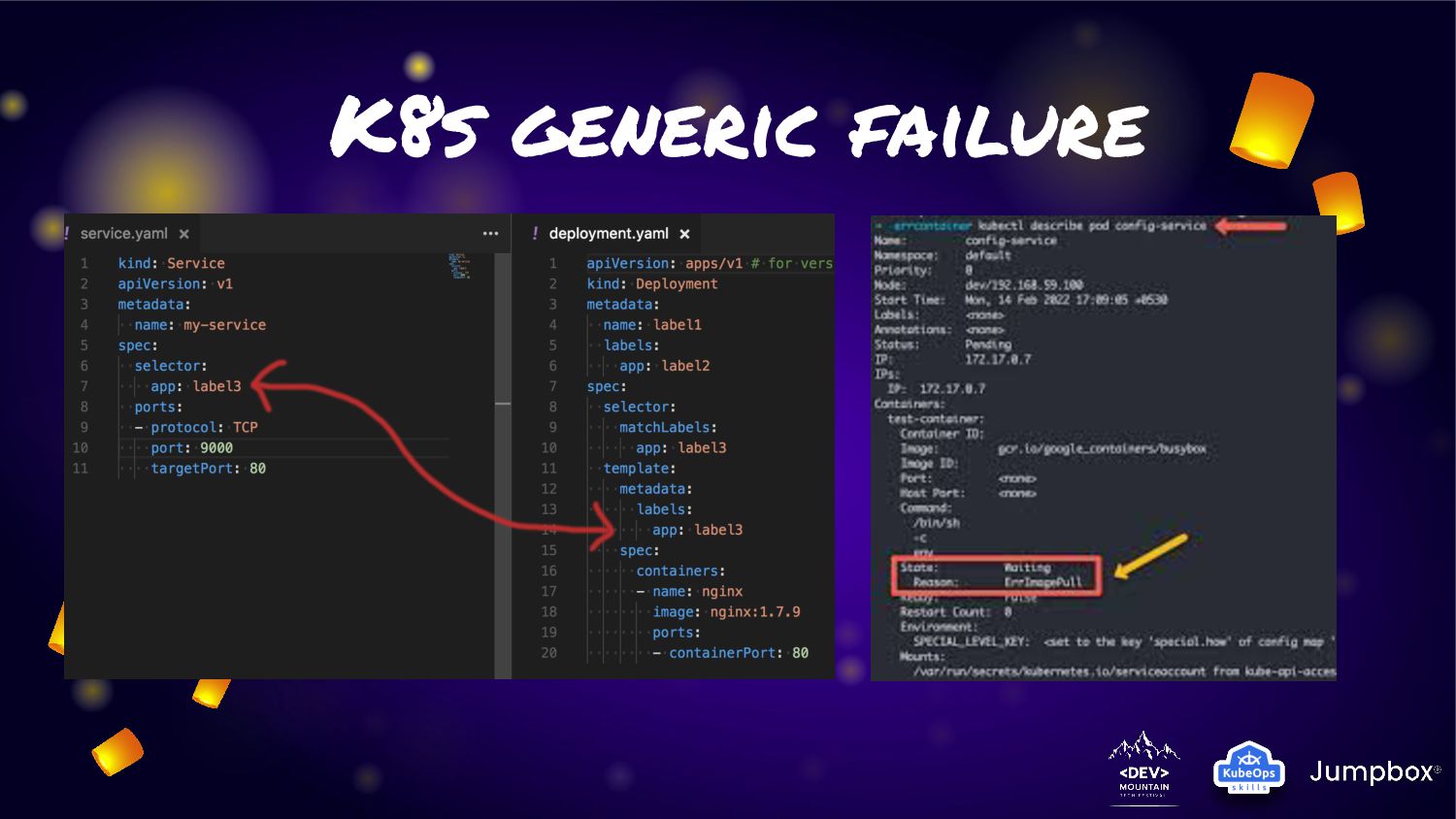
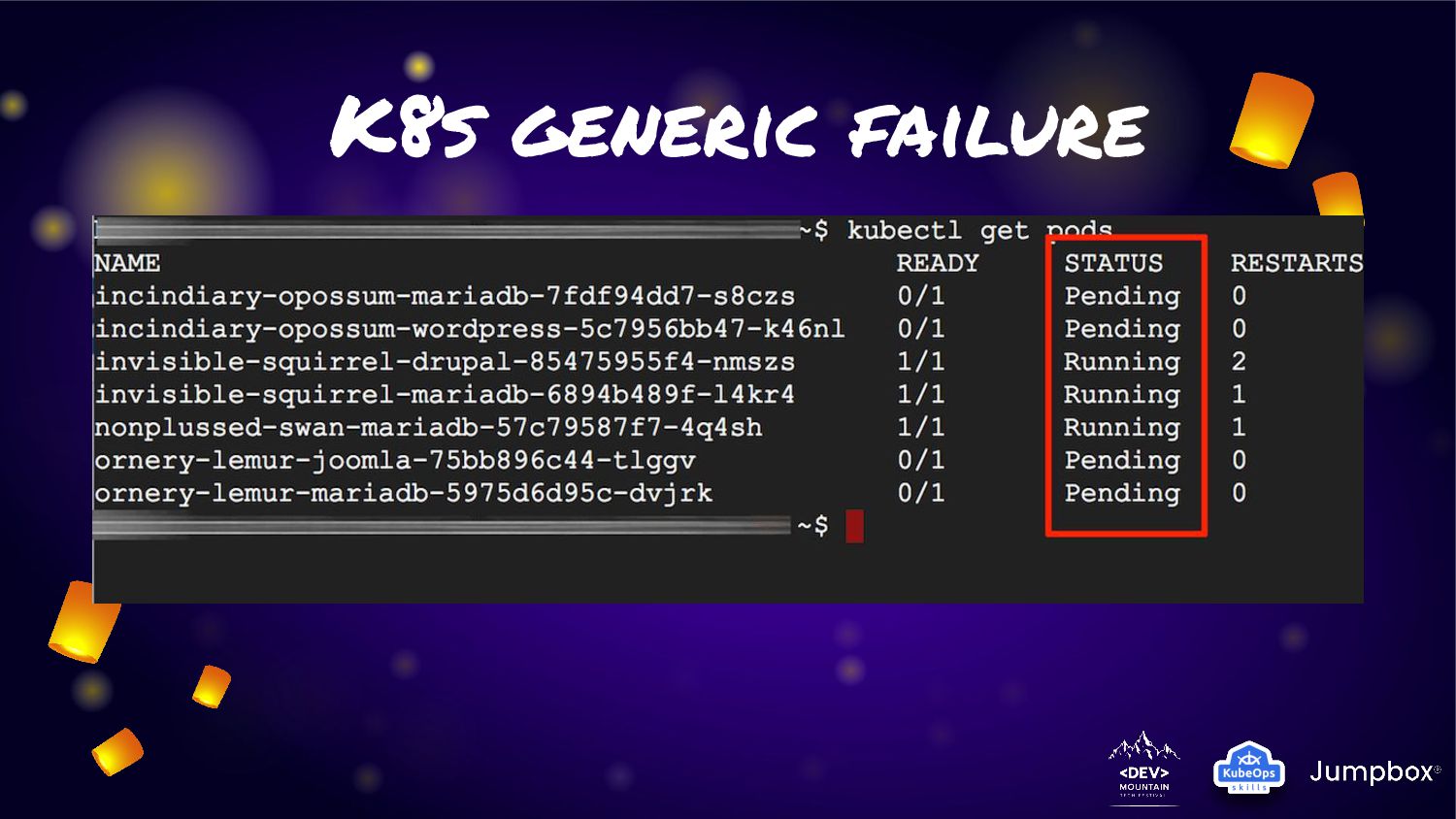
on container. Almost of application workload was primary protect on Kubernetes platform • Basic failure (Ex: server failure in cluster) was protect by default • Anyway for provide extreme ha in some application. We need to deploy application in multiple cluster for protect cluster failure • Ex: Accident shutdown a lot server in cluster? / Apply wrong configuration for block all traffic ? / etc. • But how can we provide solution to fit the situation?
of environment ◦ On-prem native environment ◦ On-cloud native environment ◦ Platform on-prem (Karbon/Tanzu/Openshift etc.) ◦ Platform on-cloud (EKS/AKS/CCE/GKE etc.) • Not for all application that we need extreme. Solution should not x2 or X3 investment • Many case failure occur only partial microservice on stack • Recovery should be automation for fix failure and keep application continue as soon as possible
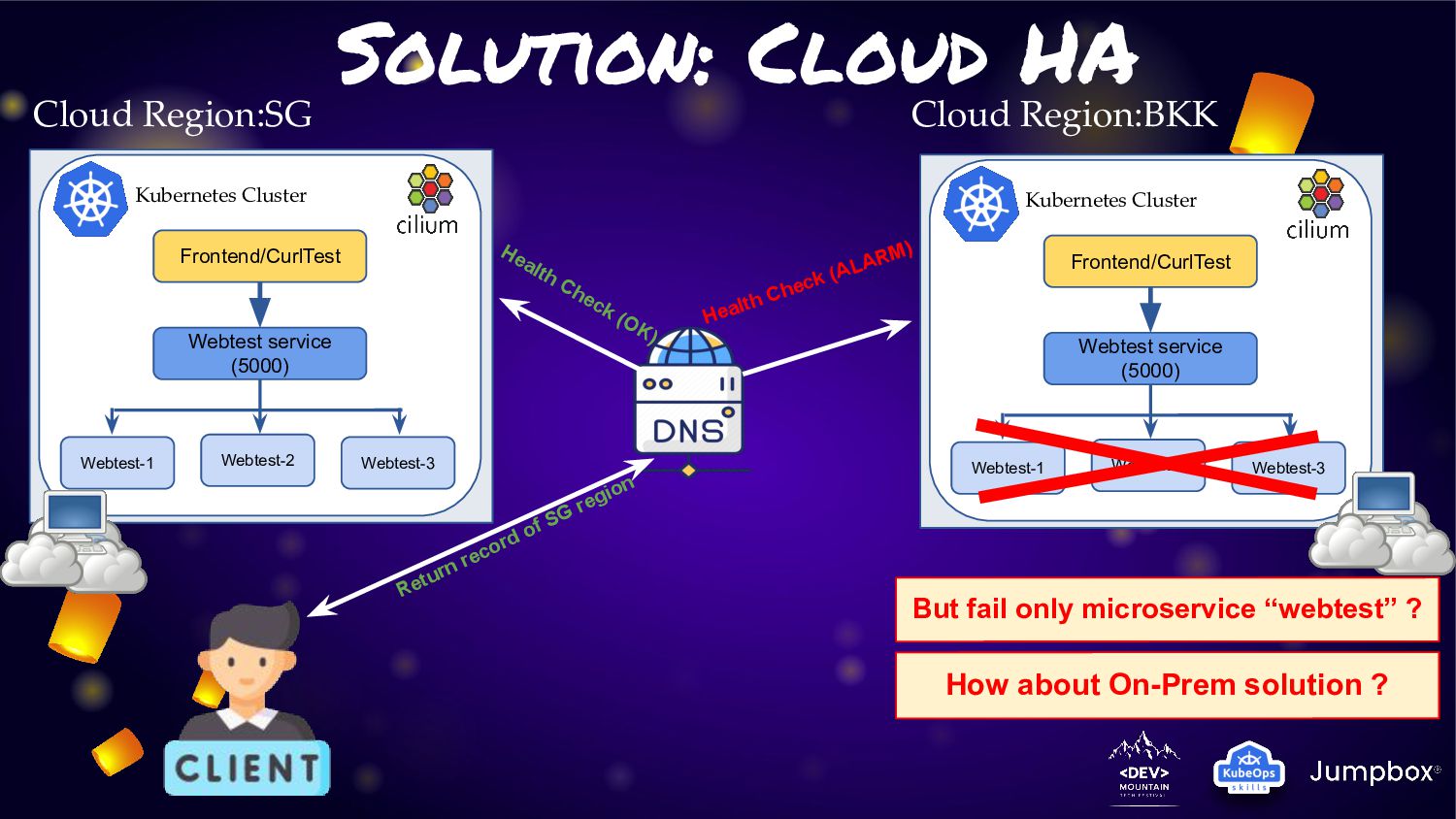
provide health-check on layer of DNS or L7 LB for failover between cluster • This solution easy to fix solution for client access channel. • But this may not fit for all problem on this scope ◦ Lock-in with some provider’s feature ◦ Not solve problem of partial microservice fail ◦ Health-check is incredible hard to check all microservice below. So this solution may fail ◦ As redirect entire endpoint. So user journey may need to relogin/initial process again. ◦ How about on-prem workload ?
Webtest-2 Webtest-3 Cloud Region:BKK Kubernetes Cluster Frontend/CurlTest Webtest service (5000) Webtest-1 Webtest-2 Webtest-3 Cloud Region:SG Health Check (ALARM) Health Check (OK) But fail only microservice “webtest” ? Return record of SG region How about On-Prem solution ?
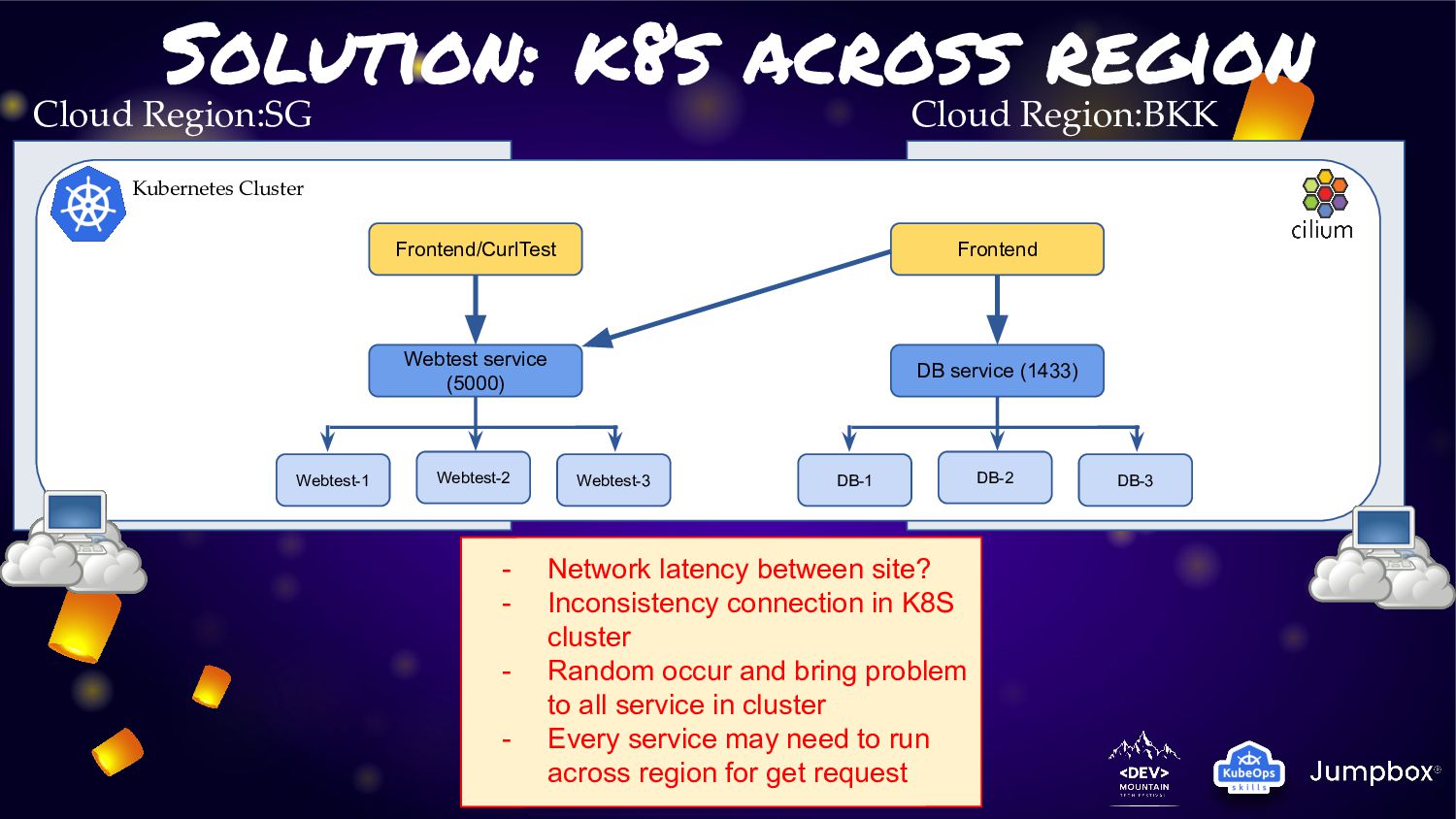
idea in several year ago until now for manage risk in term of region/country • When you have node in multiple region. This will high available by design !!!!. • Anyway on real-world apply. We usually found multi problem that impact reliability of cluster from latency • Across region will have some high latency than same region. So node may got stable “unknow” in many time • Effect to service workload is unstable for entire of cluster as random • So this solution still bad ending. Except you can control Qos the latency and bandwidth
Frontend/CurlTest Webtest service (5000) Webtest-1 Webtest-2 Webtest-3 Frontend DB service (1433) DB-1 DB-2 DB-3 - Network latency between site? - Inconsistency connection in K8S cluster - Random occur and bring problem to all service in cluster - Every service may need to run across region for get request
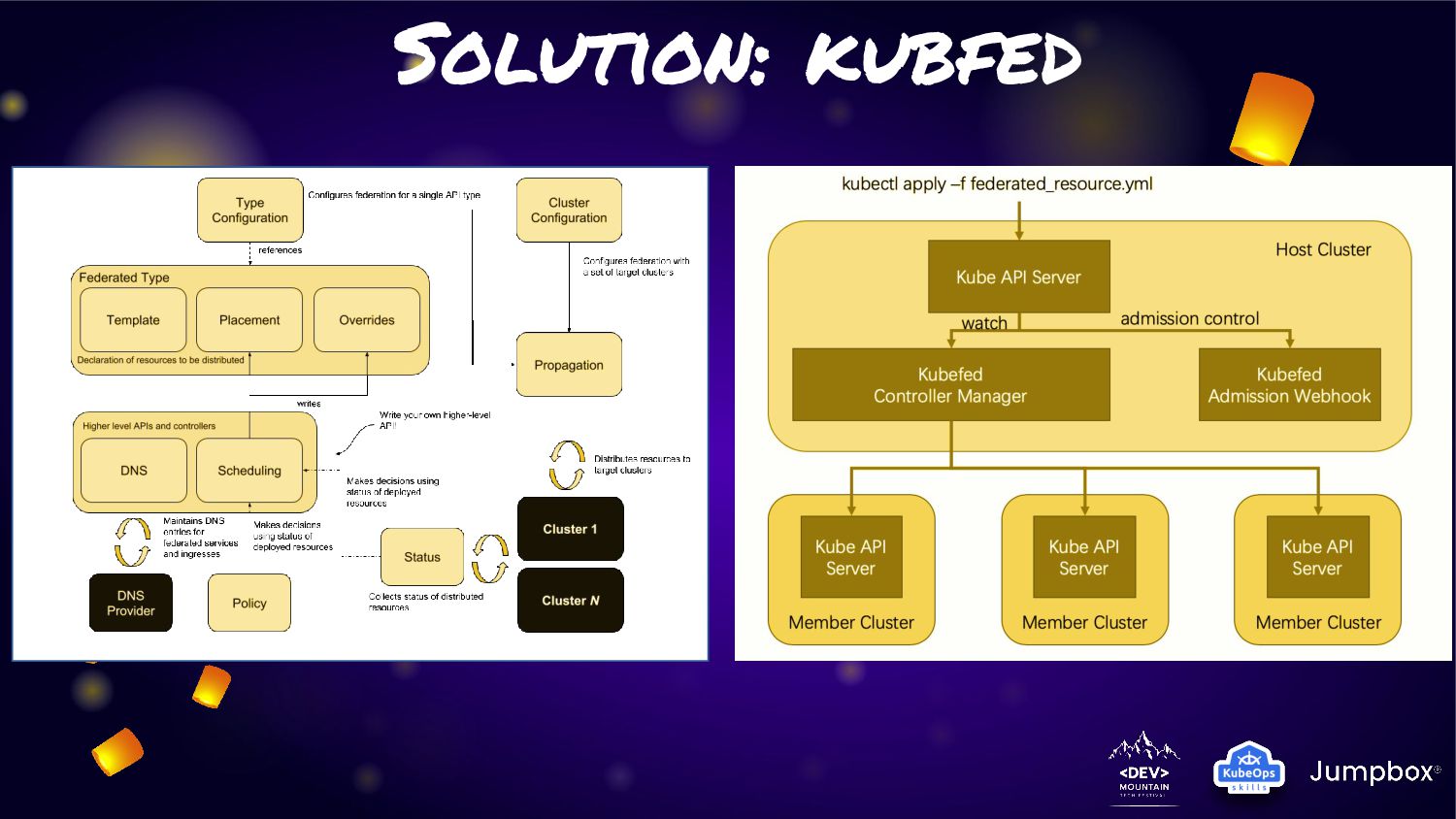
to create/manage multiple kubernetes cluster with single API • Design for single apply to many cluster in federation and aware about far site limitation • The concept of KubeFed is very strong and fit for solution. But why we not found site to use in real world ? • Add huge complicate for manage and service cluster and all YAML need to change !!! • All deployment/service need to consideration about cluster placement • Still not fix problem for partial microservice fail • Still in “beta” version more than 4 years
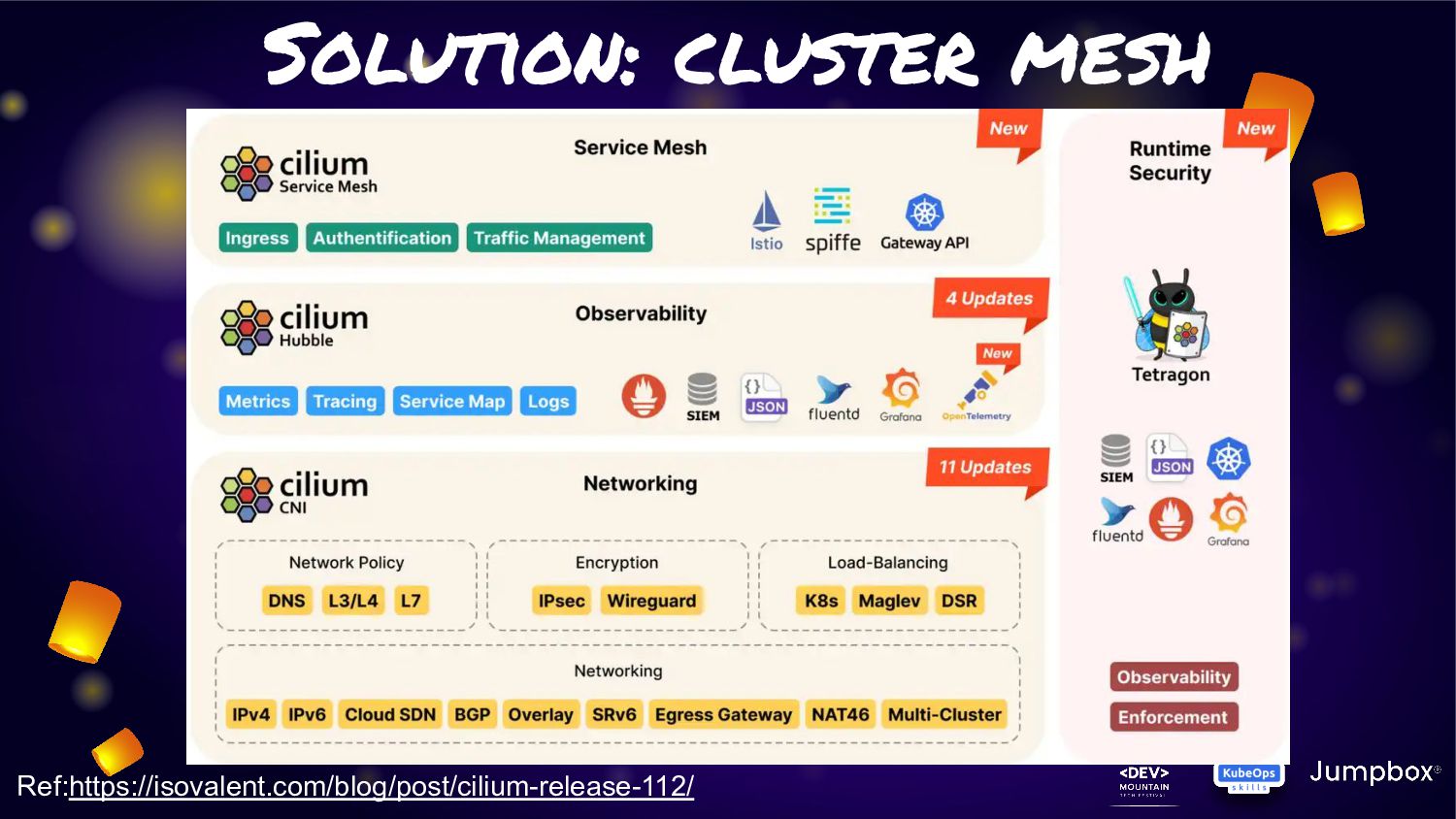
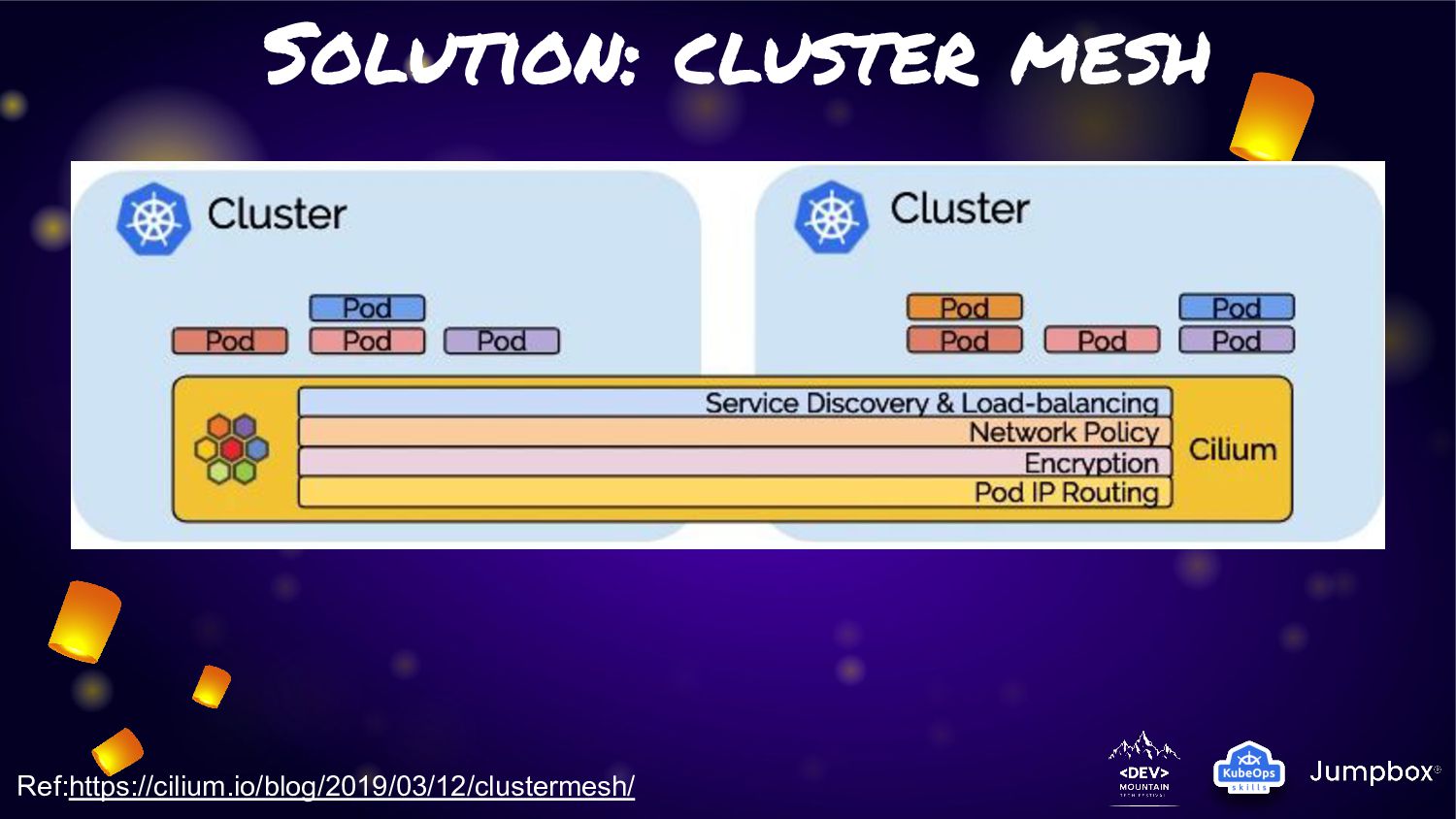
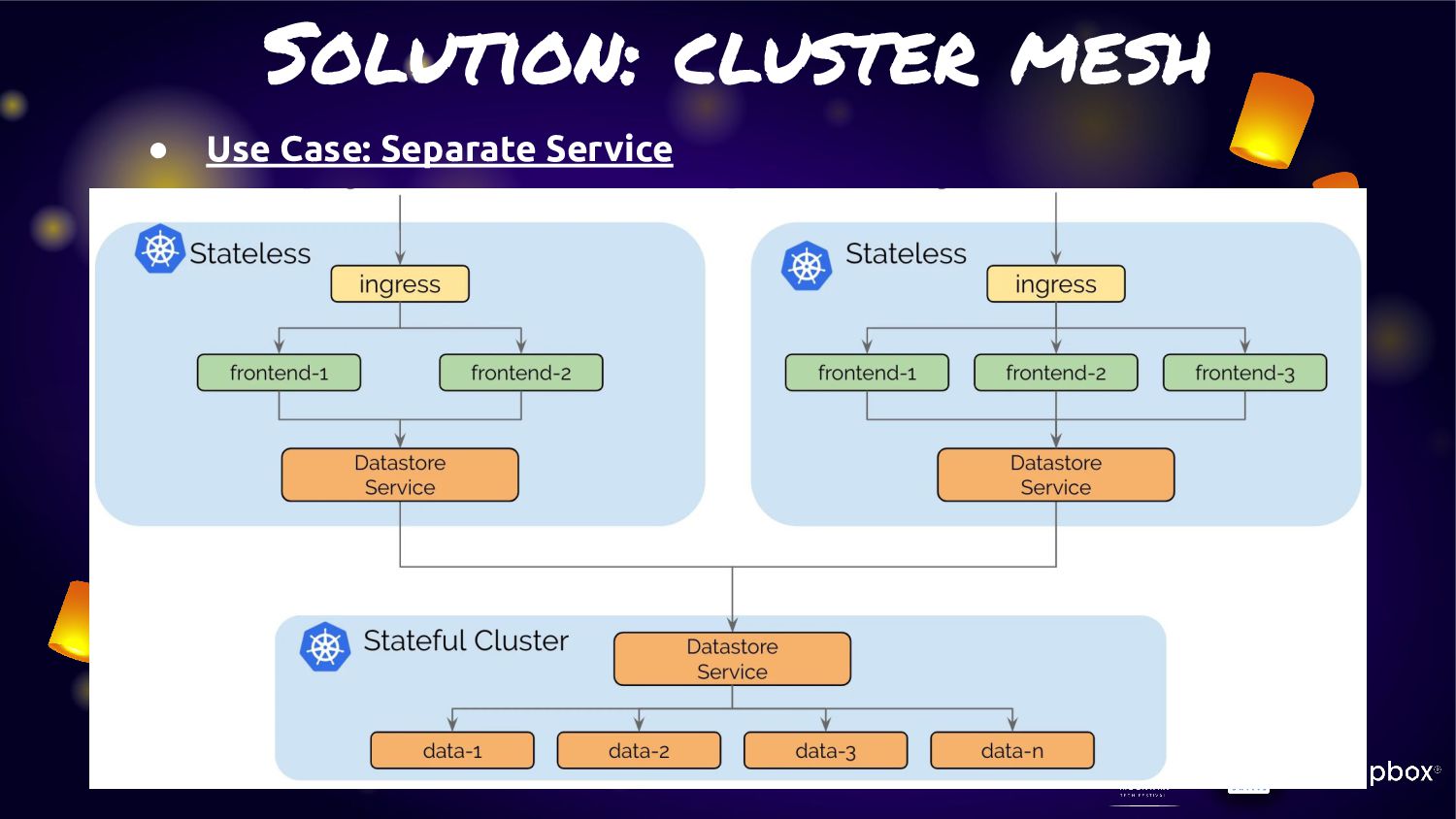
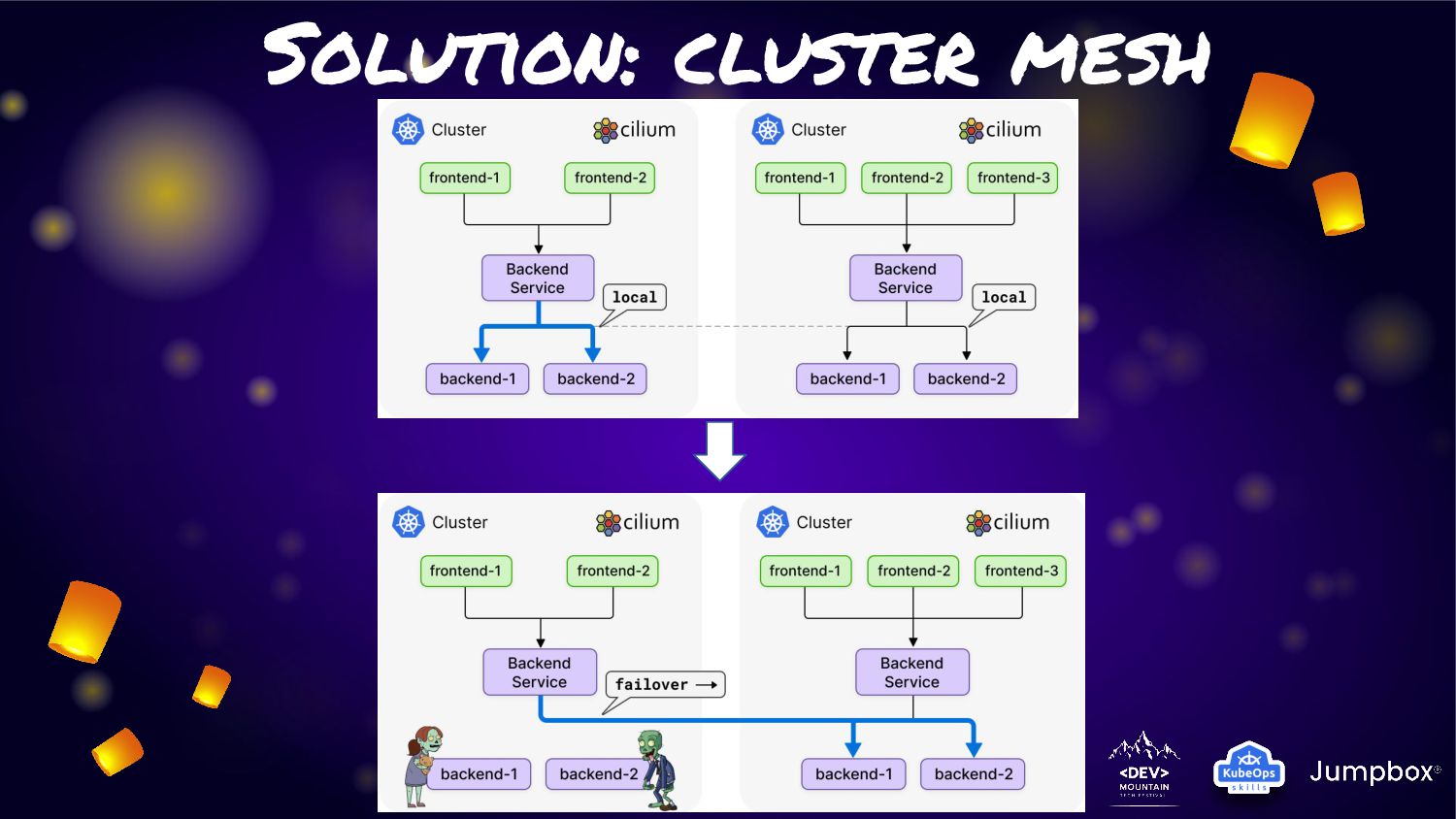
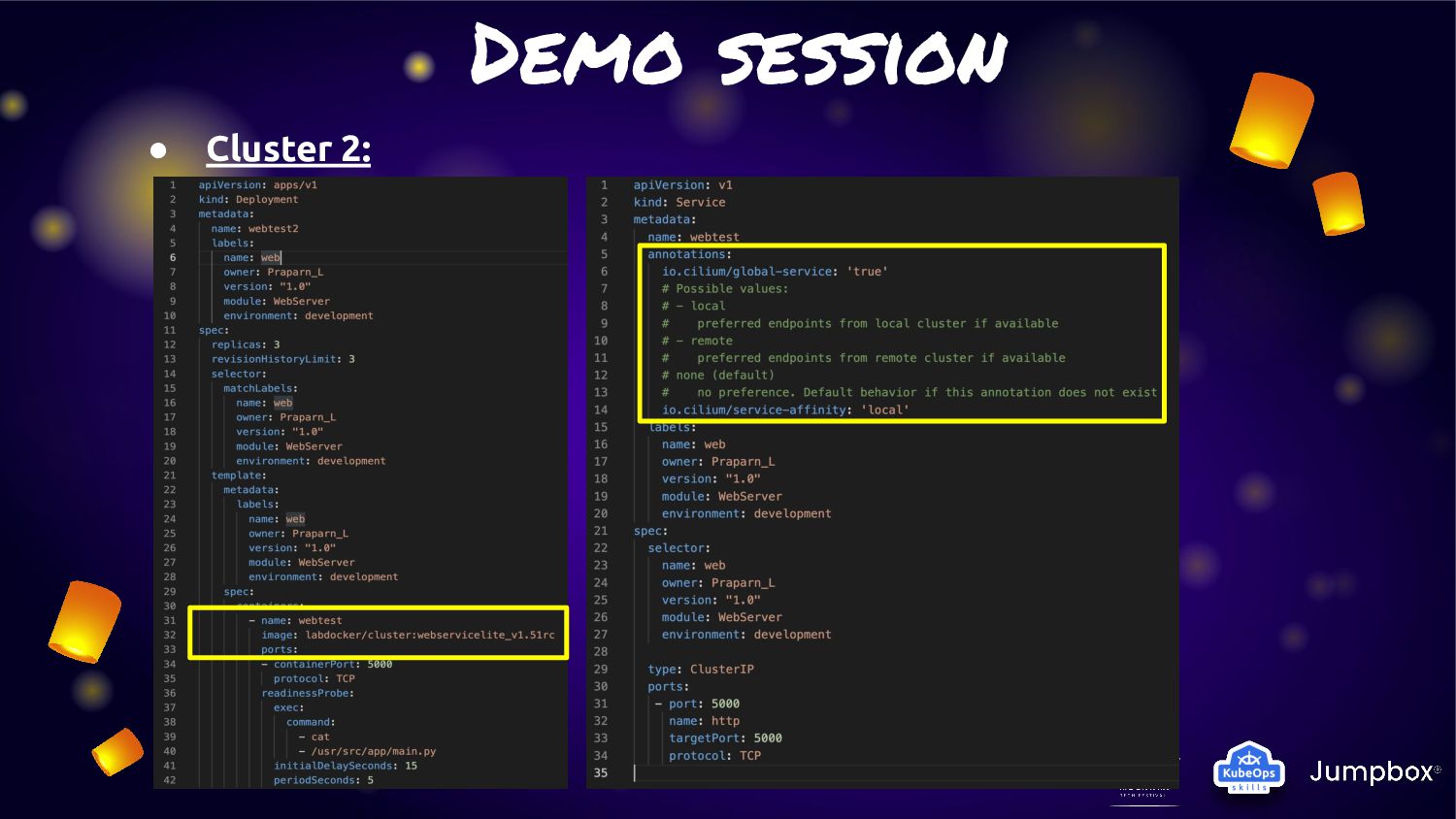
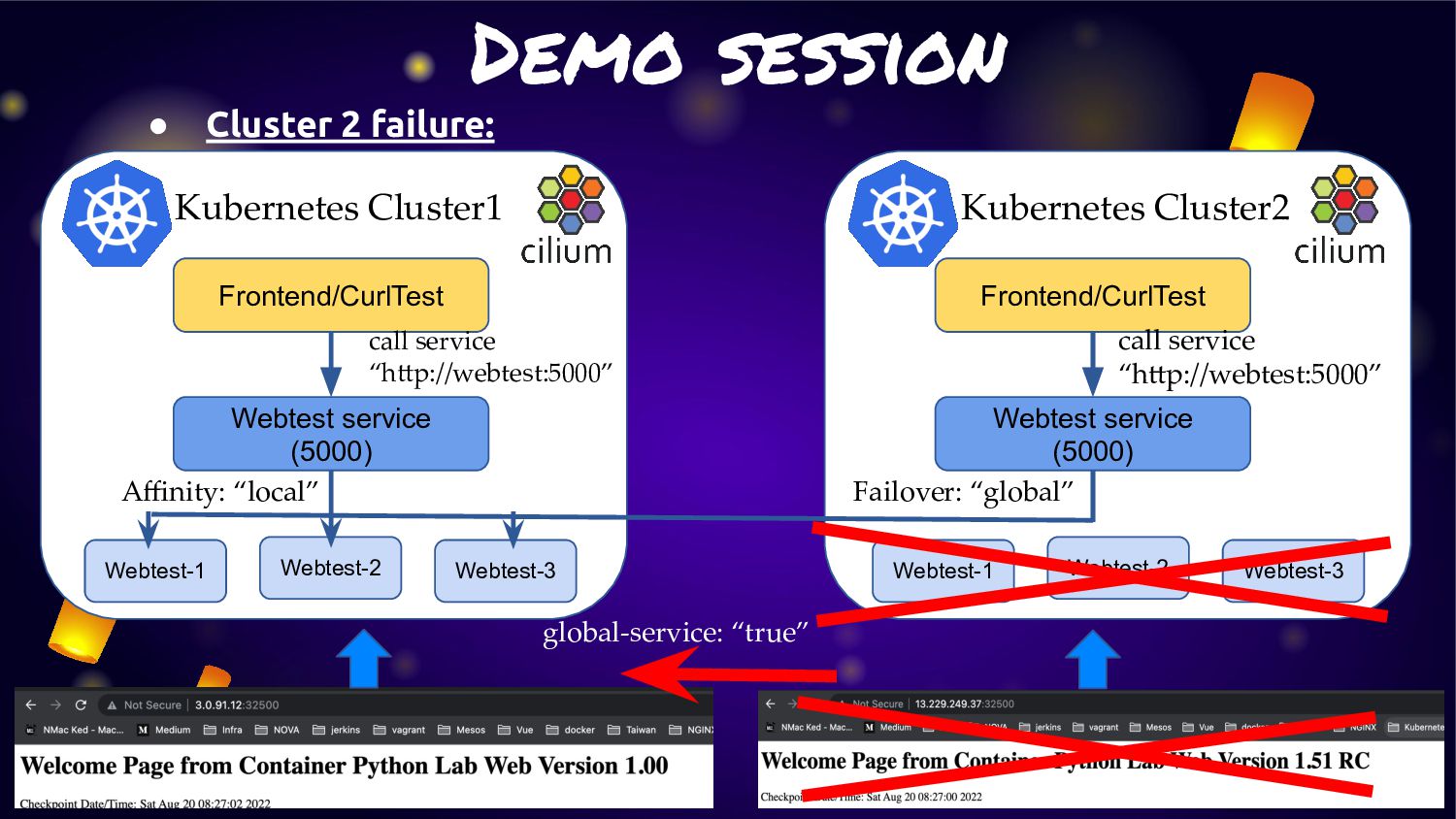
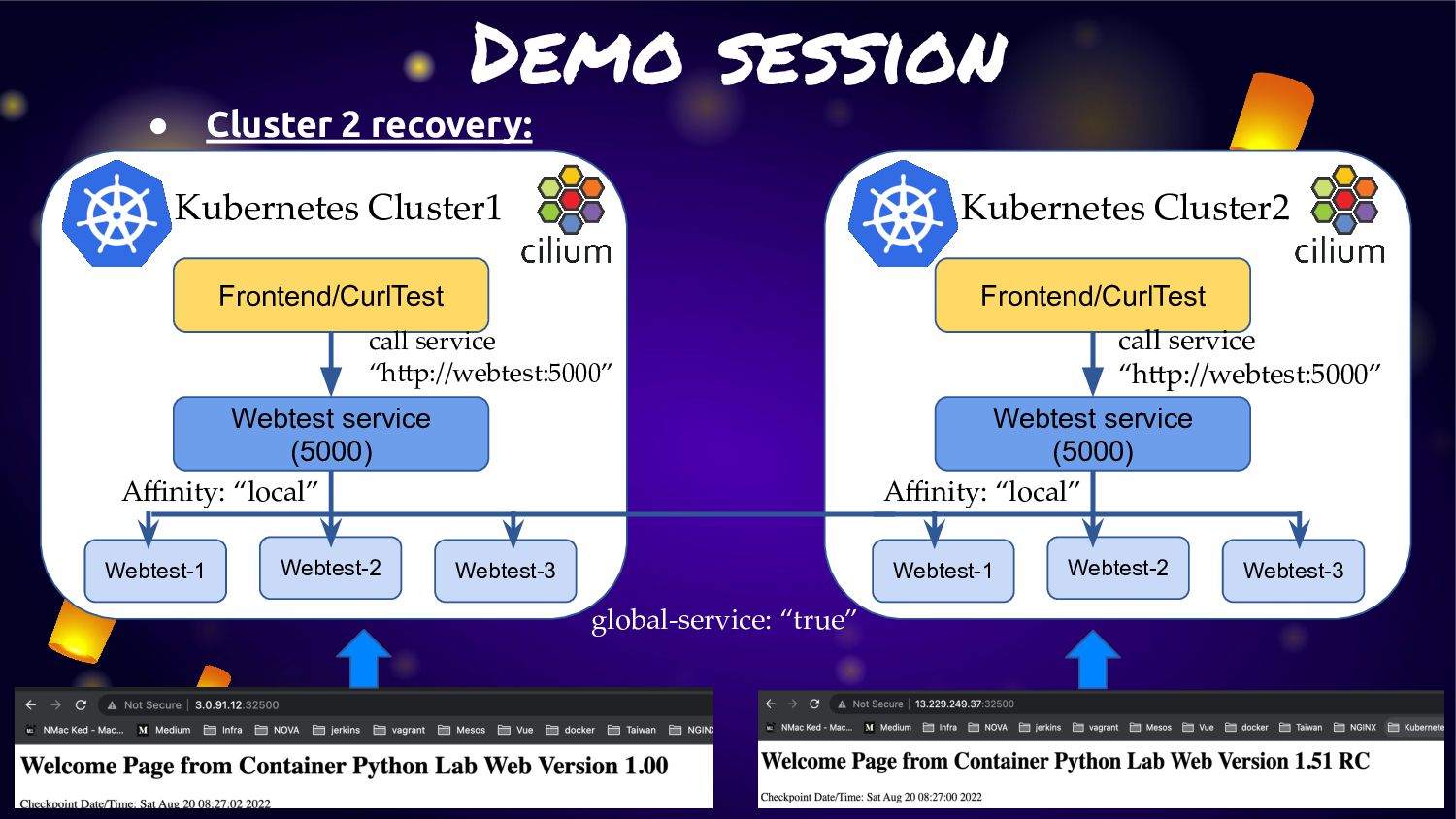
One feature very interest is about “Cluster Mesh” • Cluster Mesh (Multi-Cluster) can allow application have connection across cluster of K8S with cilium network without any additional on K8S side • In last year this feature was announced. Anyway from that point of time. Service in cluster mesh will span traffic across cluster. That mean some traffic may got in cluster some traffic is not. • From last announced of cilium 1.12 on july 2022. This feature had been improvement with “Service Affinity for Multi-Cluster Load-Balancing”
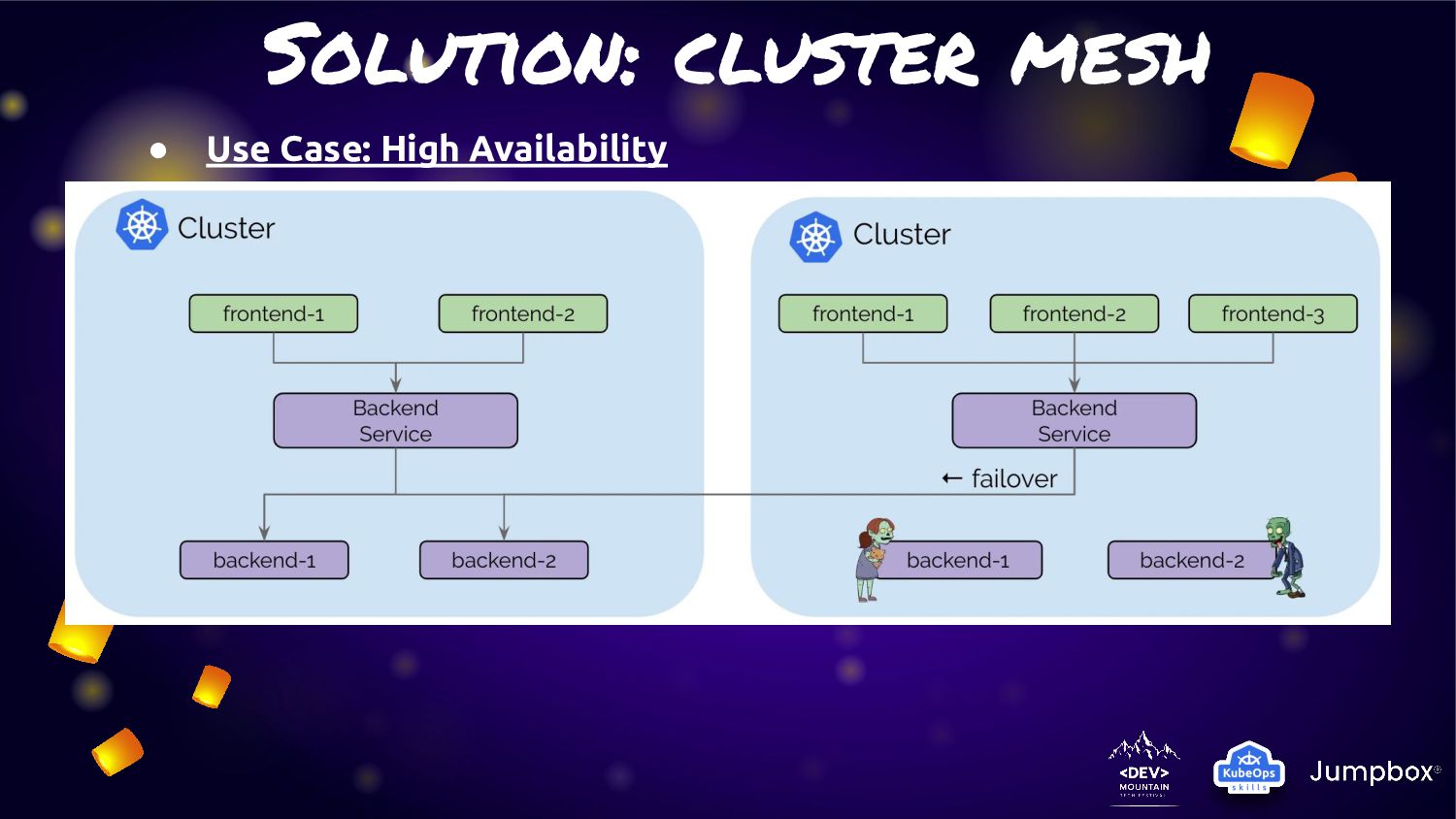
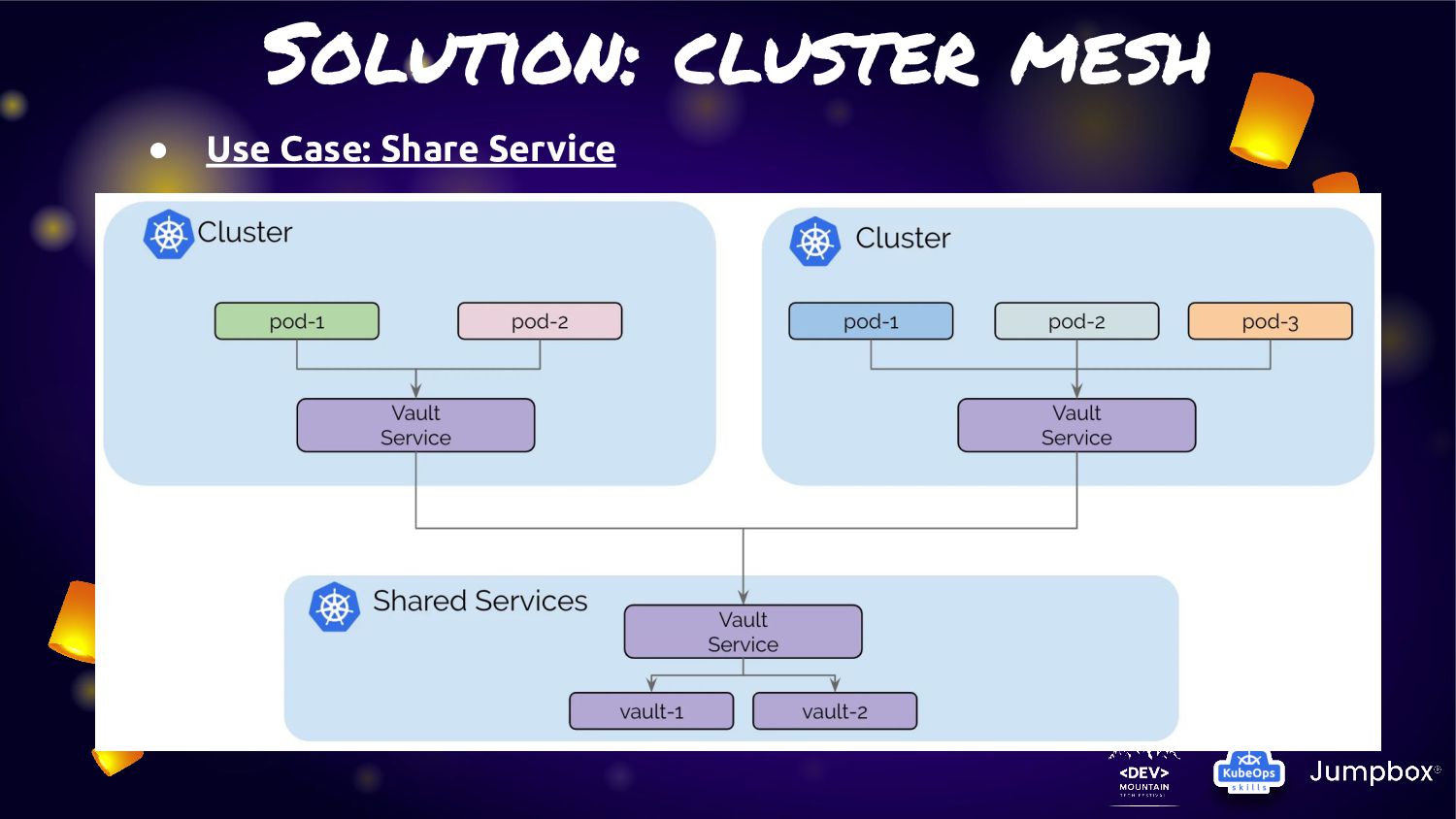
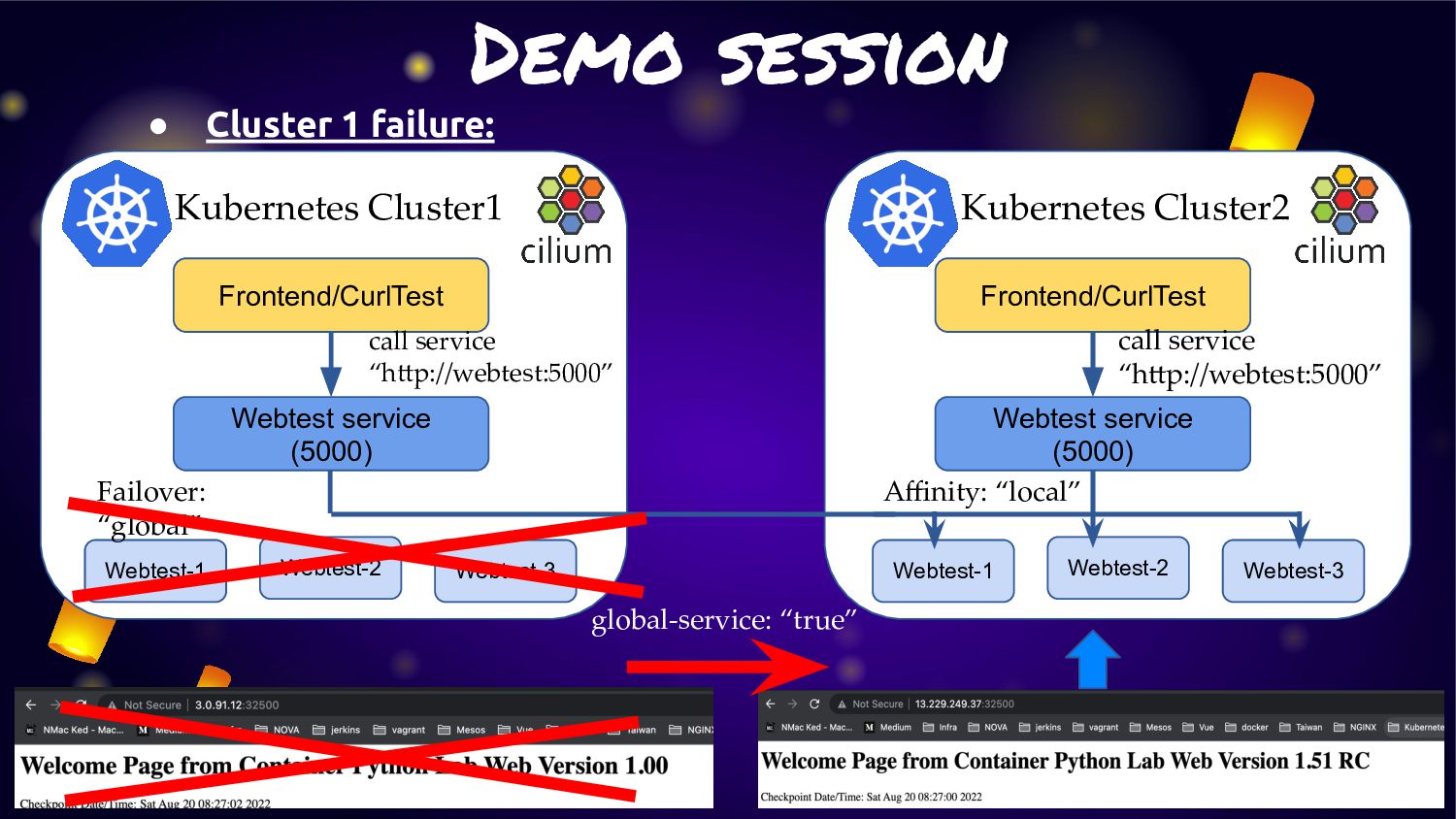
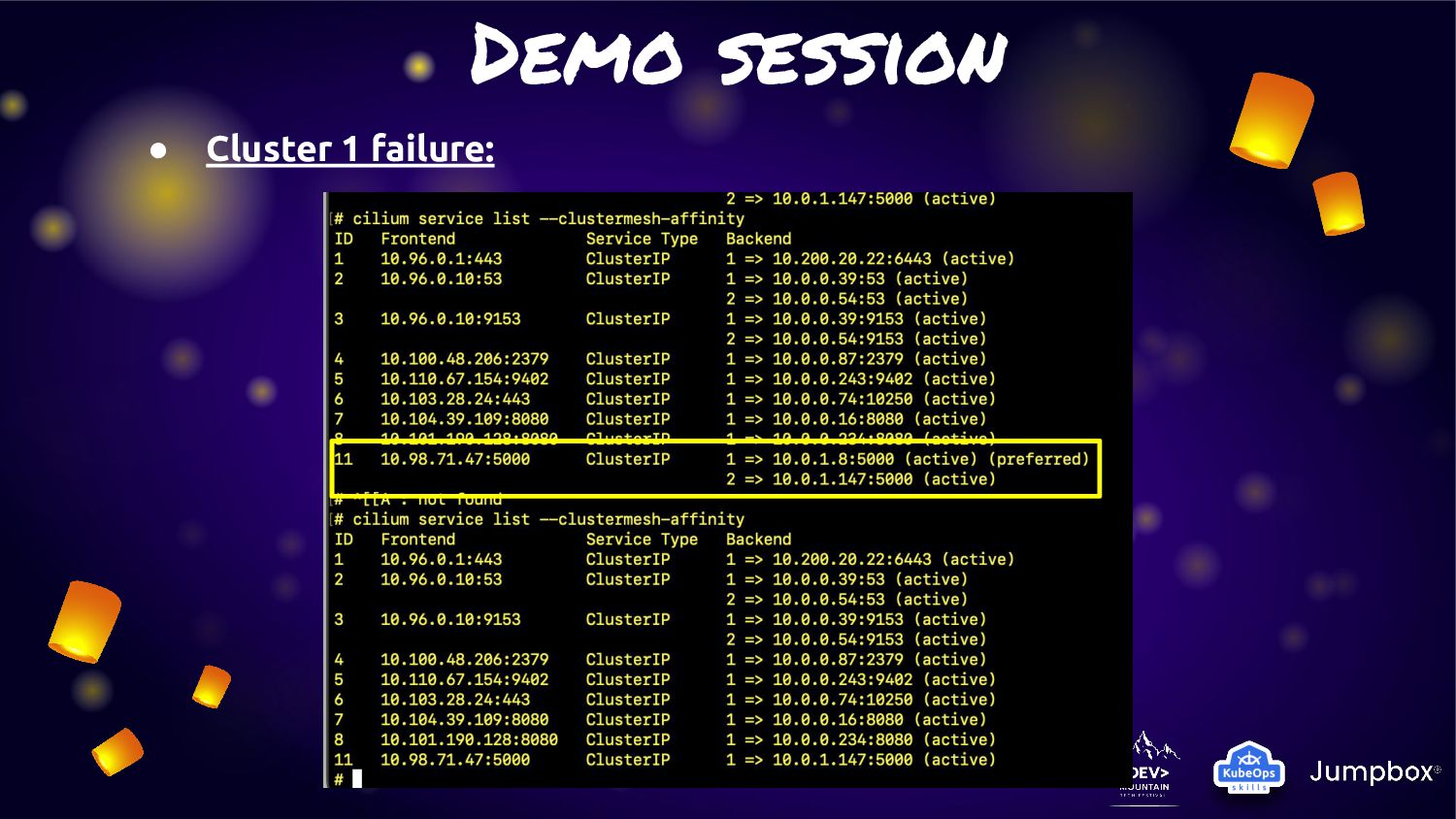
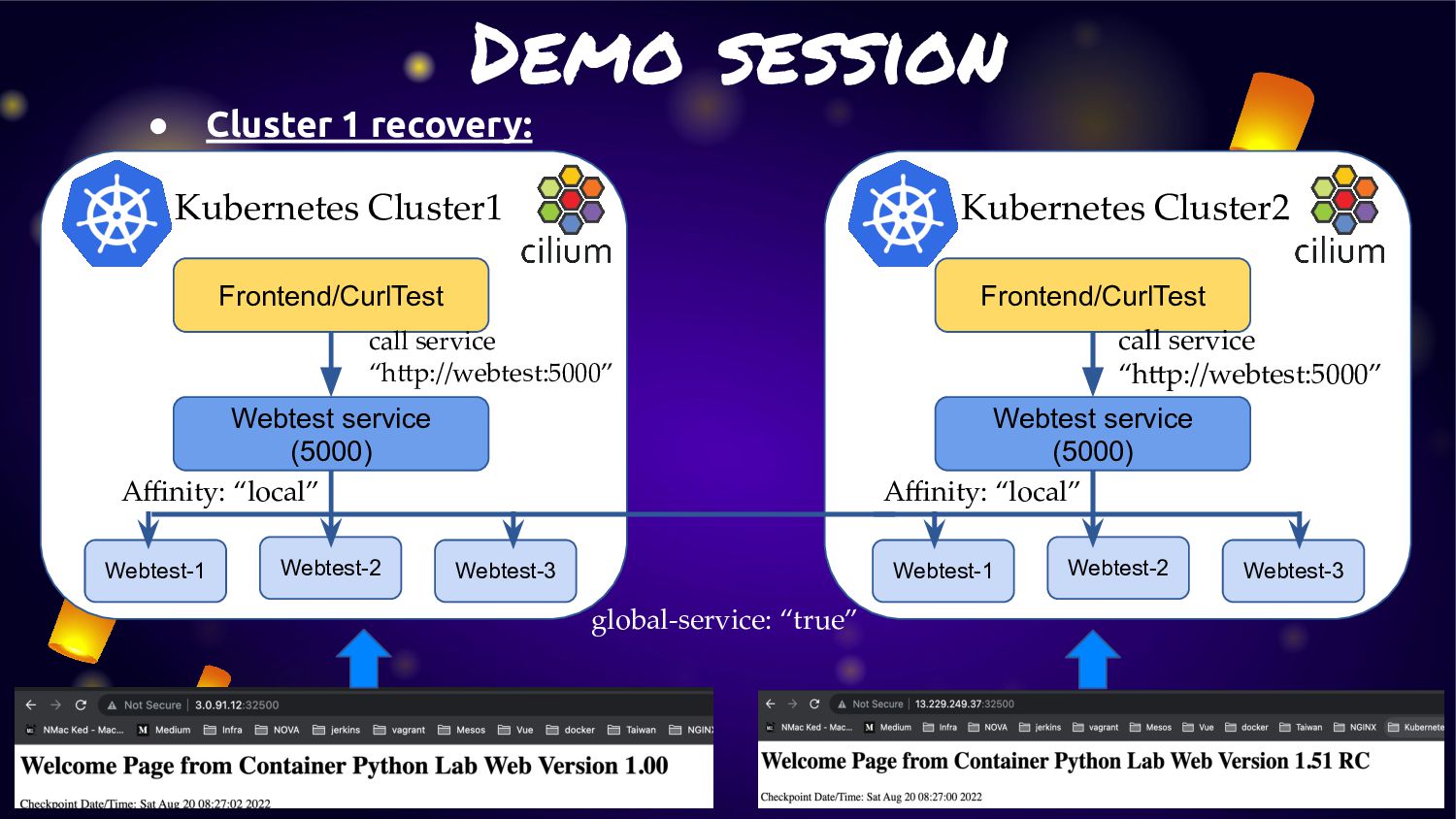
service traffic to pods within local cluster first. If it not available. They will fail-over to other cluster. • From this feature can fit the solution to provide “Extreme HA” for any microservice in K8S. • As Cilium is run base on “EBPF” so this activity will not have any overhead or latency like other service mesh management • Many use case can adoption this feature for manage microservice on K8S cluster
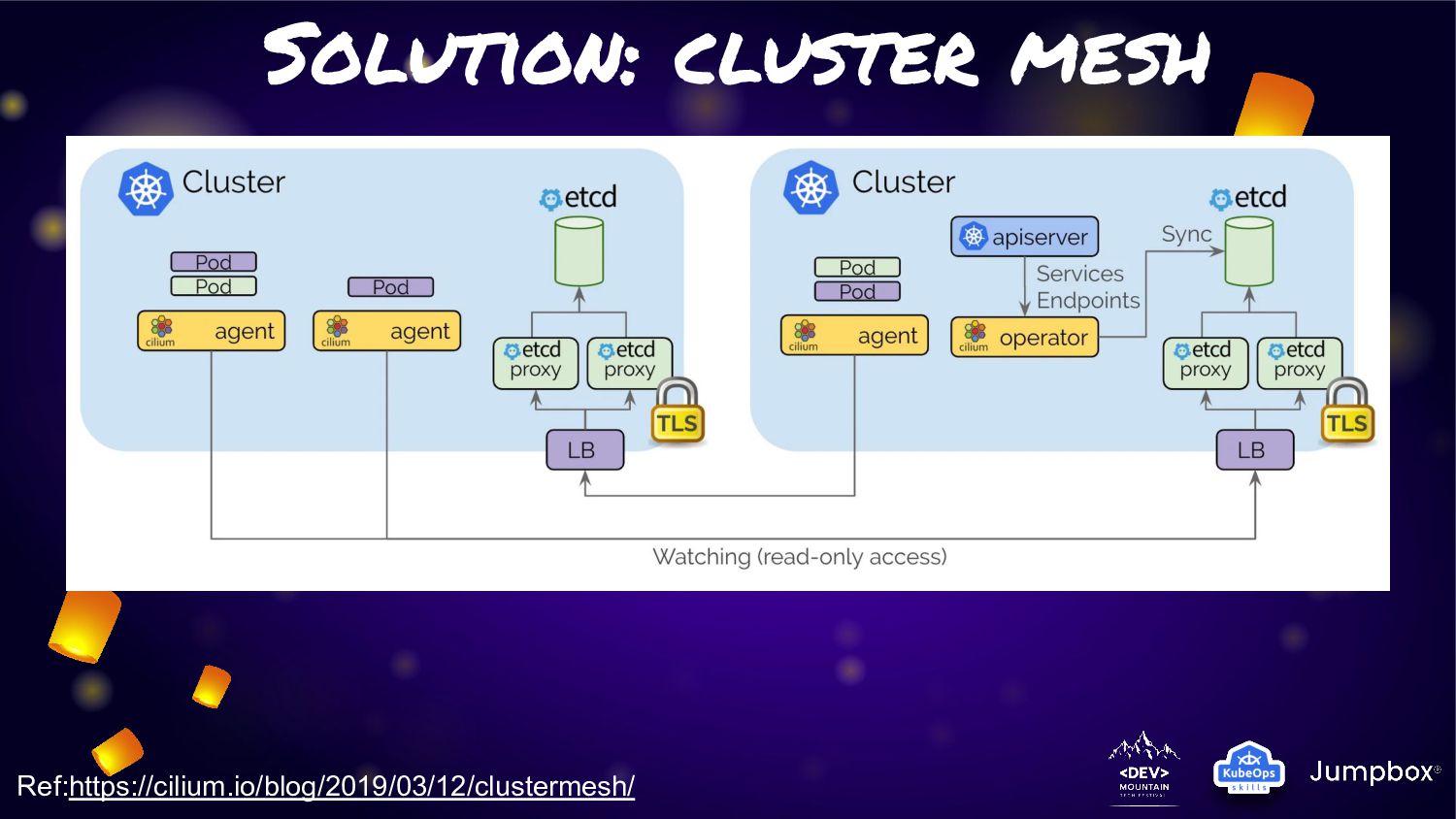
Cilium will know about service/pods in each cluster and provide connection across cluster available in any time the service need to connect to pods • With this underly process. We can simply solution for extreme HA connection with similar yaml file for pods and service like generic one
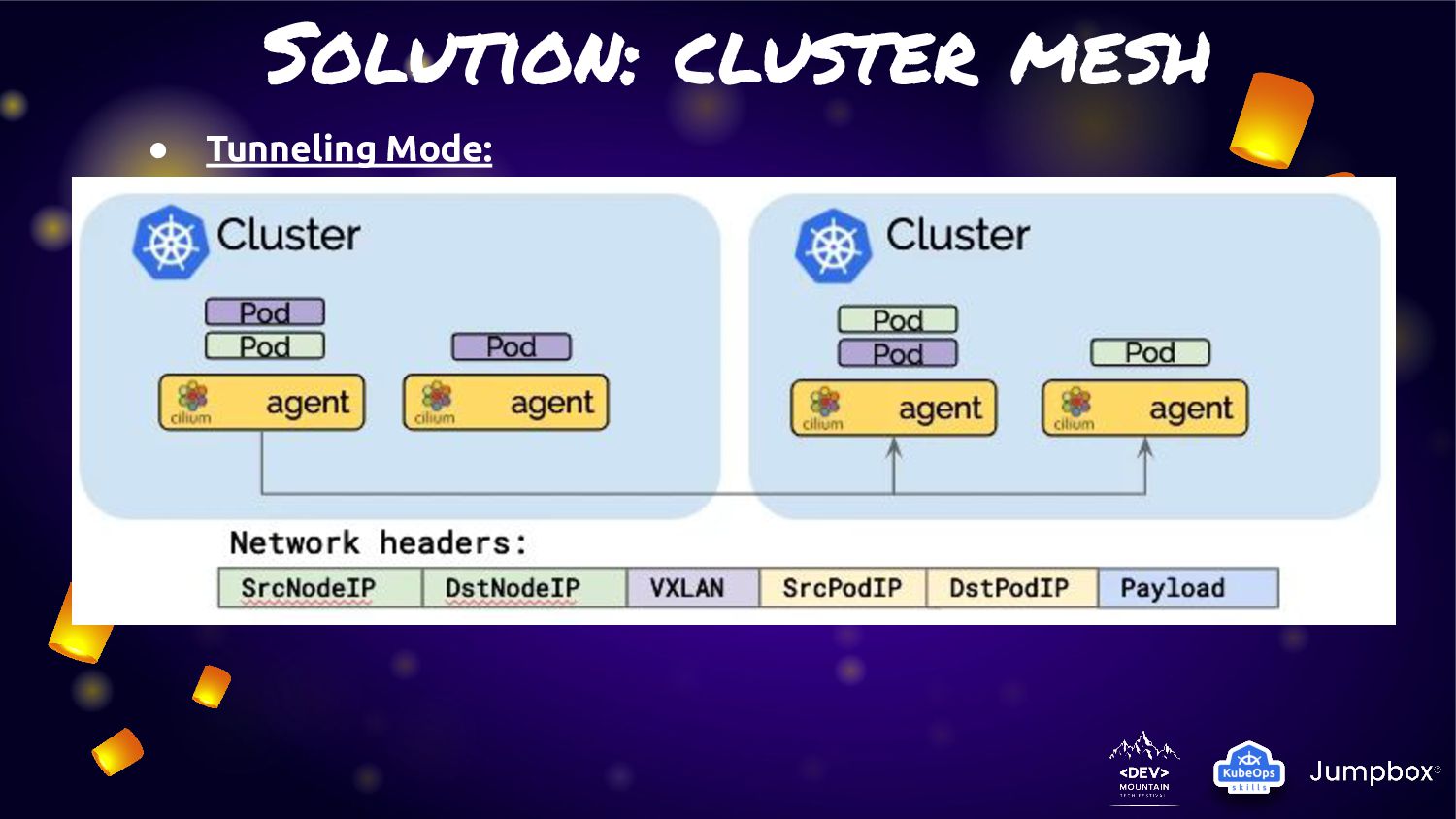
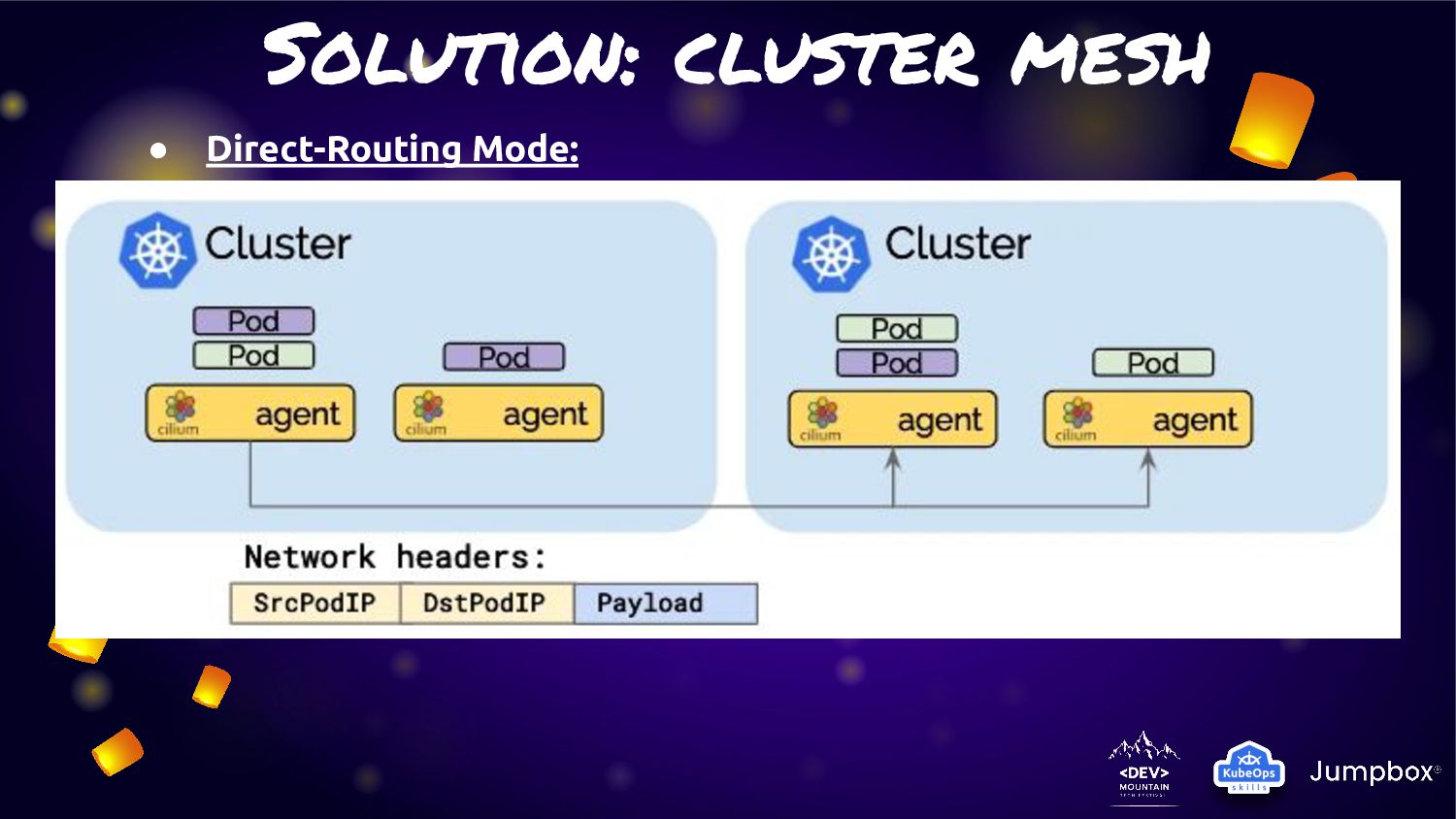
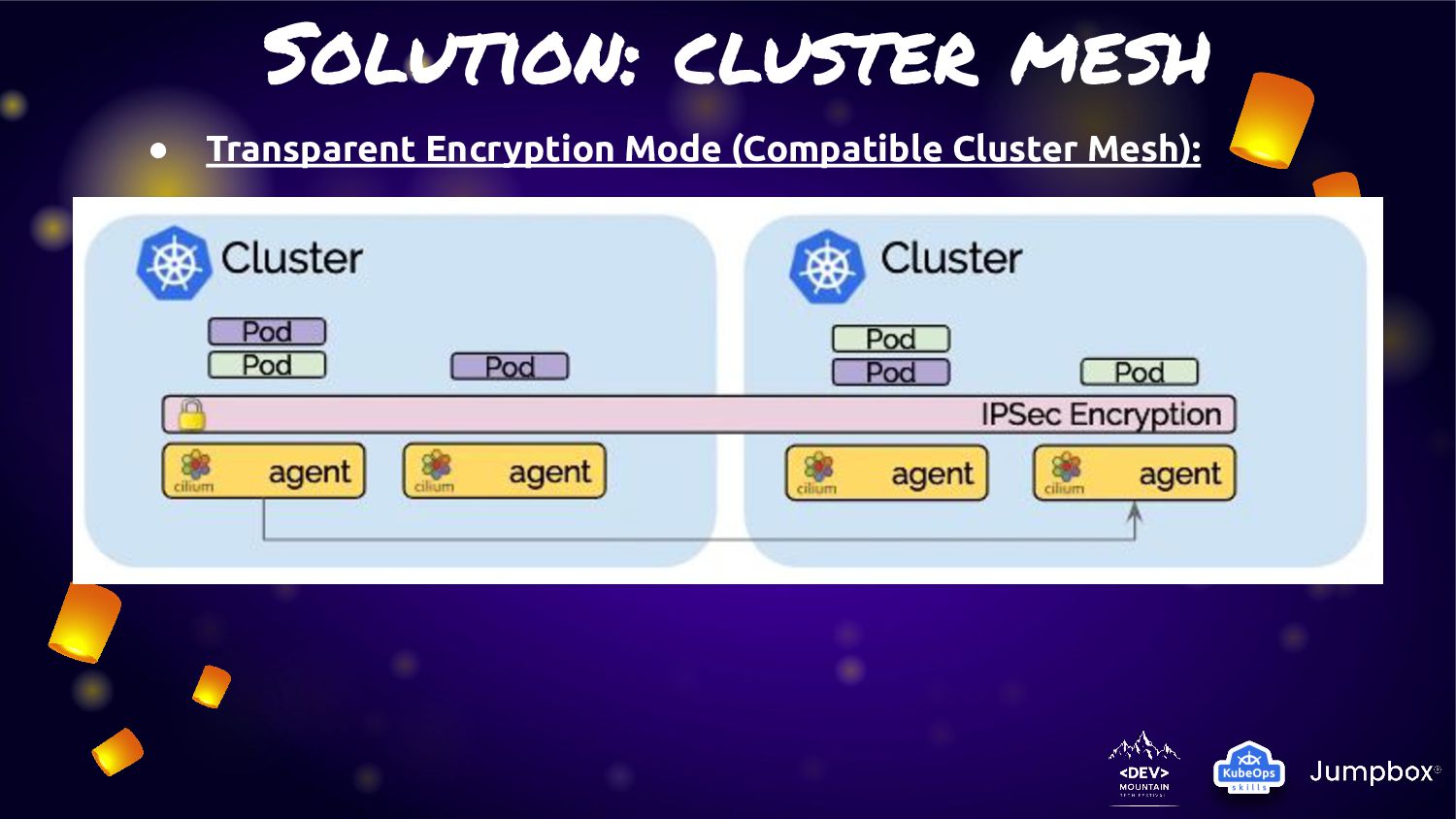
pods routing across cluster in three mode • Tunneling Mode: Encapsulates all network packets emitted by pods in a so-called encapsulation header. The encapsulation header can consist of a VXLAN or Geneve frame (VPN Approach) • Direct-routing mode: All network packets are routed directly to the network. This requires the network to be capable of routing pod IPs • Hybrid mode: Direct-routing when available which will typically be in the local cluster or other clusters in the same VPC with a fall-back to tunneling mode when spanning VPCs or cloud-providers.
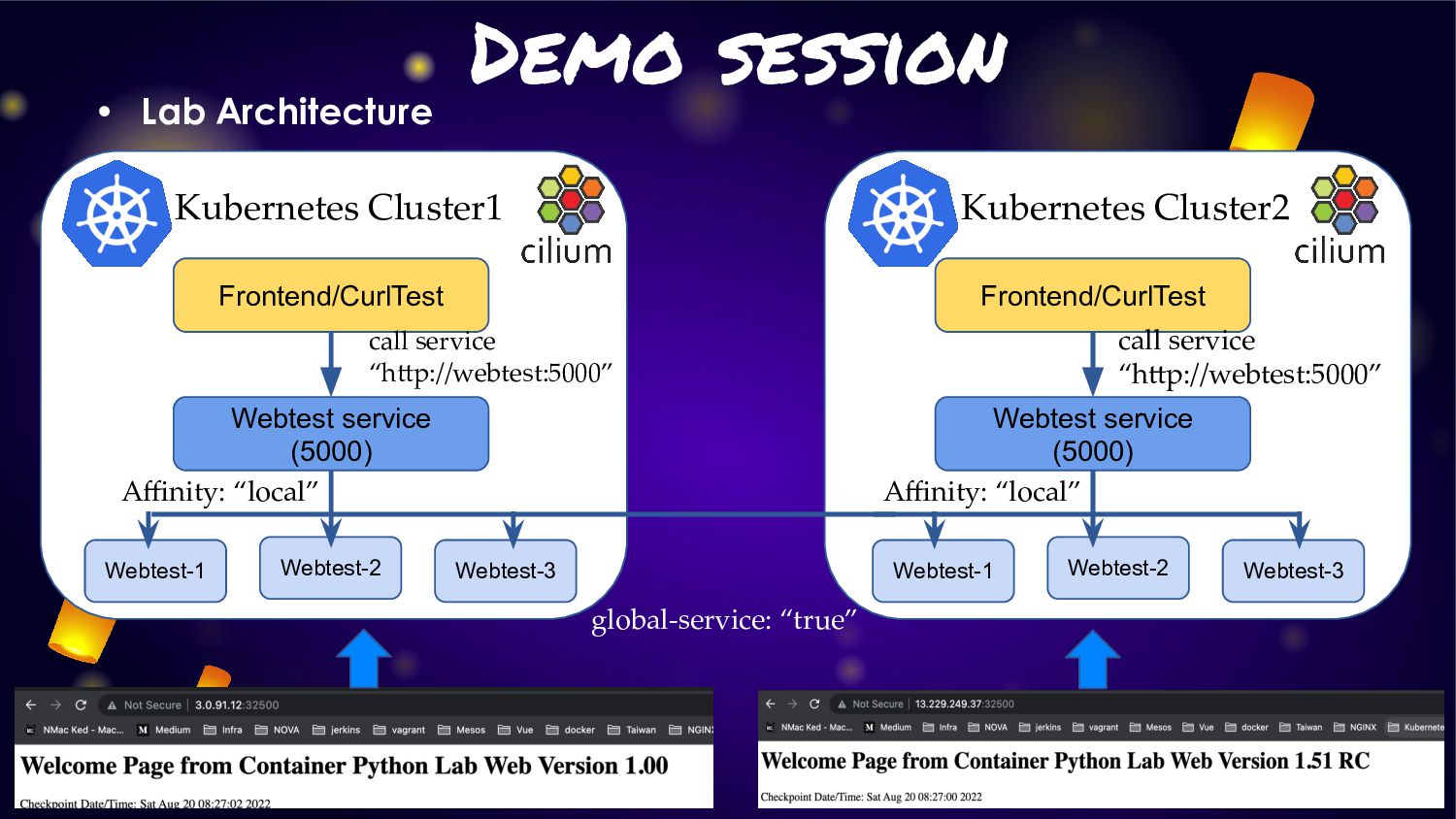
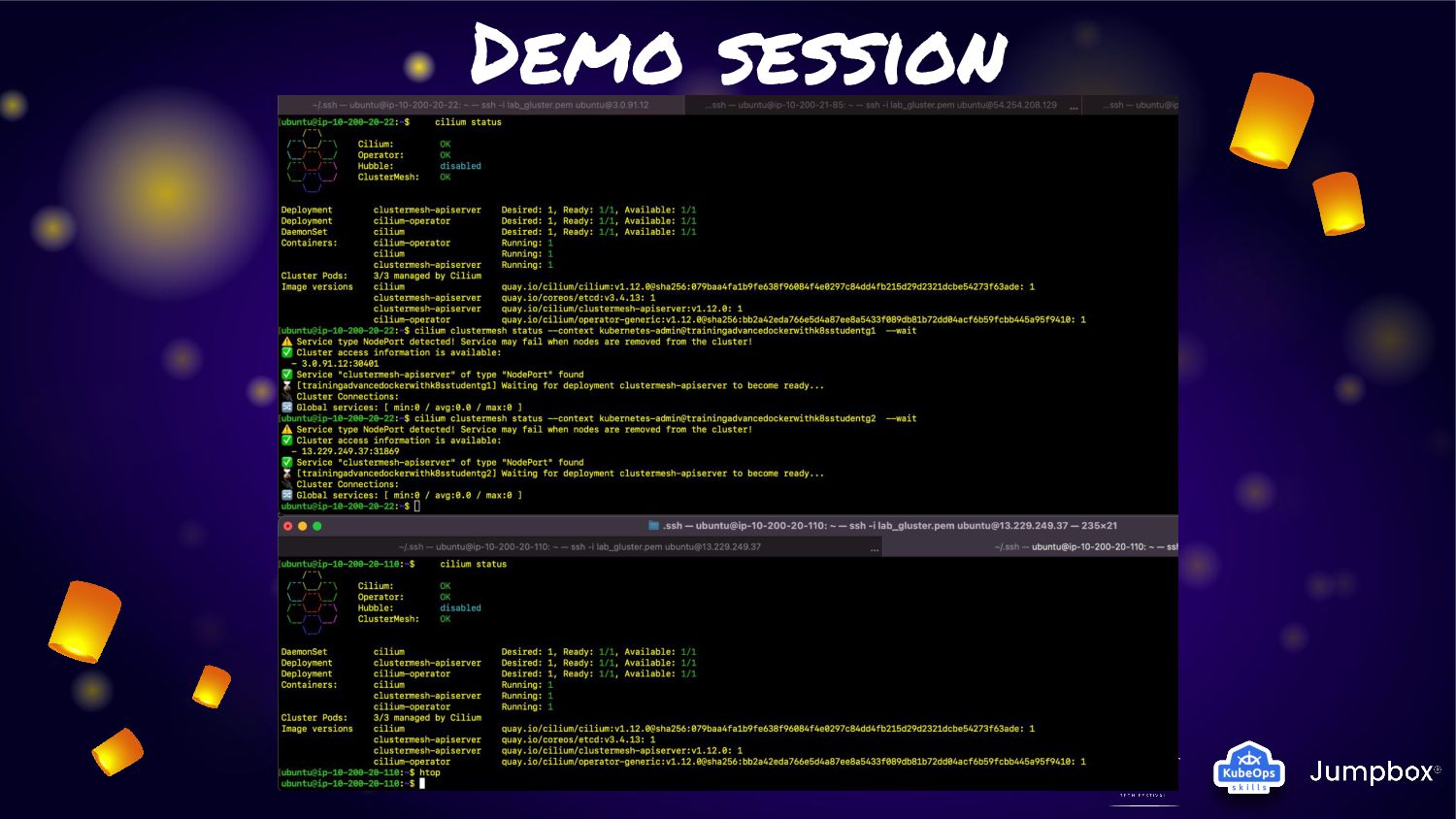
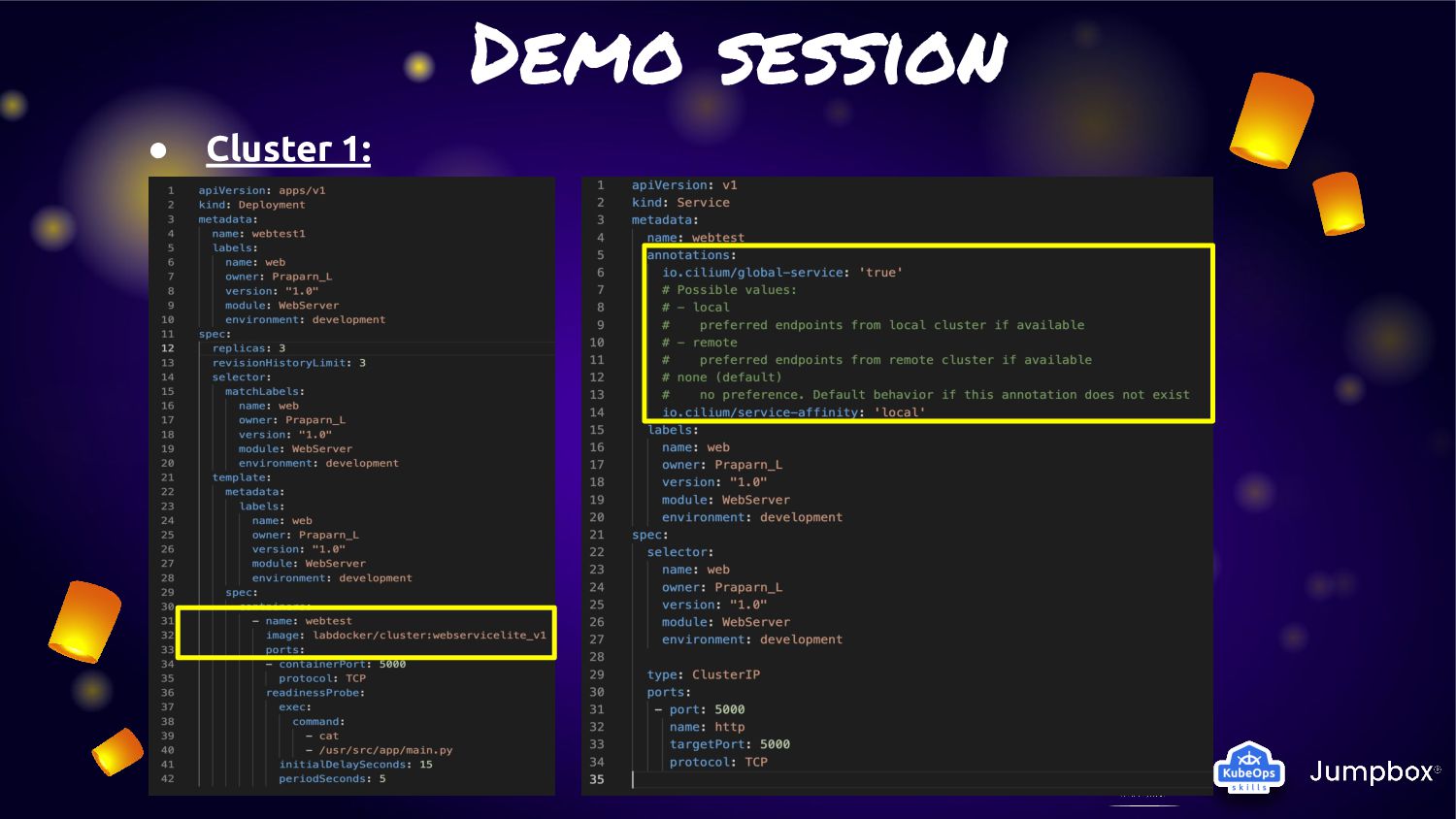
cluster (cluster1/cluster2) of Kubernetes with “Cluster Mesh” enable • Each cluster will deploy application and service: ◦ Cluster1: Deploy application version 1.0 ◦ Cluster2: Deploy application version 1.51RC1 • For make application extreme durability. We will enable “Cluster Mesh” with service affinity • Normal condition: ◦ Service will route traffic in local cluster for less latency • Fail condition: ◦ Service will kick traffic across cluster for HA and durability
{kind=link}
{kind=link}
![Praparn Luangphoonlap github.com/praparn : [email protected]](https://files.speakerdeck.com/presentations/f9f9456cd7444a638ac0236a8ab94e96/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}