جຊతʹڭࢣ͋ΓֶशʢڧԽֶशΛ׆༻͢Δ͜ͱଟ͍͕…ʣ u ܇࿅࣌ͱςετ࣌Ͱͷγϑτʹ੬ऑ͗͢Δ Ø ेྔͷσϞϯετϨʔγϣϯ͕ඞཁ… u ଟ͘ͷλεΫ͕ෳͷ࠷దํࡦΛ࣋ͭ Ø ʢݴޠʹΑΔʣλεΫͷࡉԽ or ଟๆͳϞσϧ͕ඞཁ… u ख़࿅ऀʹਓ͕ඇϚϧίϑੑʴෳࡶͳ෦ঢ়ଶΛ࣋ͭ Ø ؍ଌཤྺਓͷҙਤਪఆ͕ඞཁ… Ø େنσϞϯετϨʔγϣϯʴৄࡉͳݴޠΞϊςʔγϣϯͰ େنTransformerϕʔεͷϞσϧΛֶश͢ΕOKʁʂ
جຊతʹڭࢣ͋ΓֶशʢڧԽֶशΛ׆༻͢Δ͜ͱଟ͍͕…ʣ u σϞϯετϨʔγϣϯʴৄࡉͳݴޠΞϊςʔγϣϯίετ͕େ Ø ϩϘοτΛڭࣔ͠ͳ͍ํ๏Ͱεέʔϧ͍ͨ͘͢͠͠… u ߴ࣭ͳσϞϯετϨʔγϣϯ͚ͩूΊΔͱσʔλ͕ܹݮ Ø ࣭ͳσϞϯετϨʔγϣϯ༨͢͜ͱͳ͍͘Γ͍ͨ… u ࣮ੈքҙ֎ͱඇఆৗͳͷͰࣄલʹ༻ҙͨ͠σʔλ͚ͩͰෆ Ø ඞཁेͳσϞϯετϨʔγϣϯΛదٓՃͯ͠Β͍͍ͨ… Ø ݶΒΕͨϦιʔεͷΤοδʢϩϘοτʣͰௐͯ͠΄͍͠…
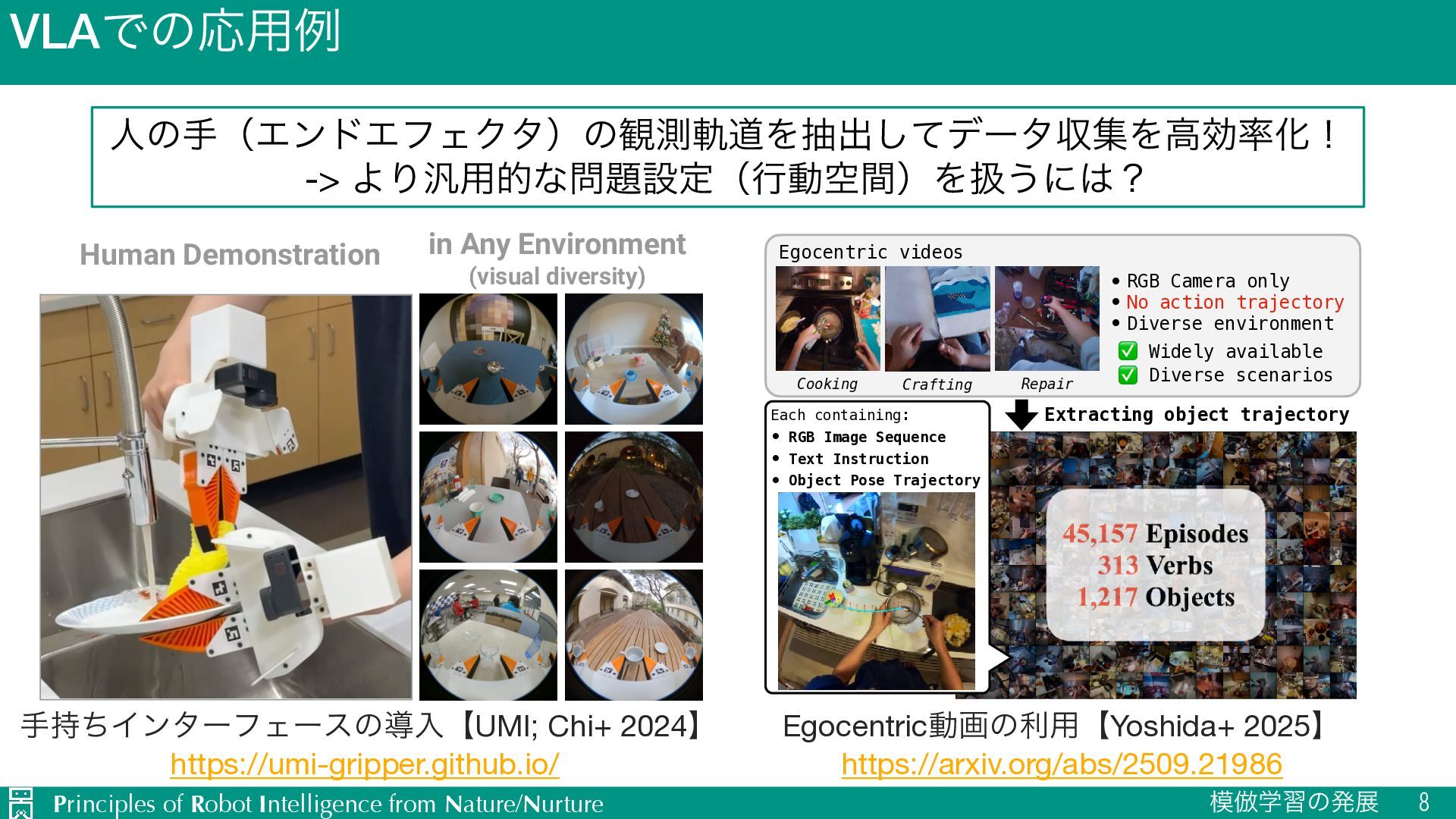
-> ΑΓ൚༻తͳઃఆʢߦಈۭؒʣΛѻ͏ʹʁ Cheng Chi→1,2, Zhenjia Xu→1,2, Chuer Pan1, Eric Cousineau3, Benjamin Burchfiel3, Siyuan Feng3, Russ Tedrake3, Shuran Song1,2 1Stanford University, 2 Columbia University, 3Toyota Research Insititute https://umi-gripper.github.io for Any Actions (action diversity) Human Demonstration in Any Environment (visual diversity) for Many Robot (embodiment diversi Dynamic Bimanual Precise Long-Horizon 7DoF 6DoF Fig. 1: Universal Manipulation Interface (UMI) is a portable, intuitive, low-cost data collection and policy learning framework. T framework allows us to transfer diverse human demonstrations to effective visuomotor policies. We showcase the framework for tasks t would be difficult with traditional teleoperation, such as dynamic, precise, bimanual and long-horizon tasks. ख࣋ͪΠϯλʔϑΣʔεͷಋೖʲUMI; Chi+ 2024ʳ https://umi-gripper.github.io/ Egocentricಈըͷར༻ʲYoshida+ 2025ʳ https://arxiv.org/abs/2509.21986 Prior approach Egocentric recordings • Specialized device/sensor • Hand pose labels • Controlled environment e.g., multi-camera Our approach Extracting object trajectory • Expertise + robot hardware • Action trajectory • Controlled environment Human teleoperation data Egocentric videos • RGB Camera only • No action trajectory • Diverse environment Cooking Crafting Repair ✅ Widely available ✅ Diverse scenarios Each containing: • RGB Image Sequence • Text Instruction • Object Pose Trajectory Fig. 1: Comparison of conventional VLA pre-training sources and ours. We leverage egocentric videos without auxiliary labels for VLA pre-training. Using EgoScaler [1] to extract 6DoF object manipulation trajectories, we construct a large-scale dataset. The multi-camera example is adapted from [2].
-> σϞσʔλͦͷͷʹޡͬͨߦಈ͕ࠞೖͨ͠߹ʁ Published as a conference paper at ICLR 2026 Figure 1: Framework of our paper. We evaluate VLA robustness under 17 uncertainties across 4 modalities. Based on the findings, we enhance robustness against both VLA inputs and outputs. BYOVLA (Hancock et al., 2025) mitigates irrelevant visual details by identifying, segmenting, and ཏతͳؤ݈ੑͷௐࠪɾରࡦʲGuo+ 2026ʳ https://arxiv.org/abs/2510.00037v4
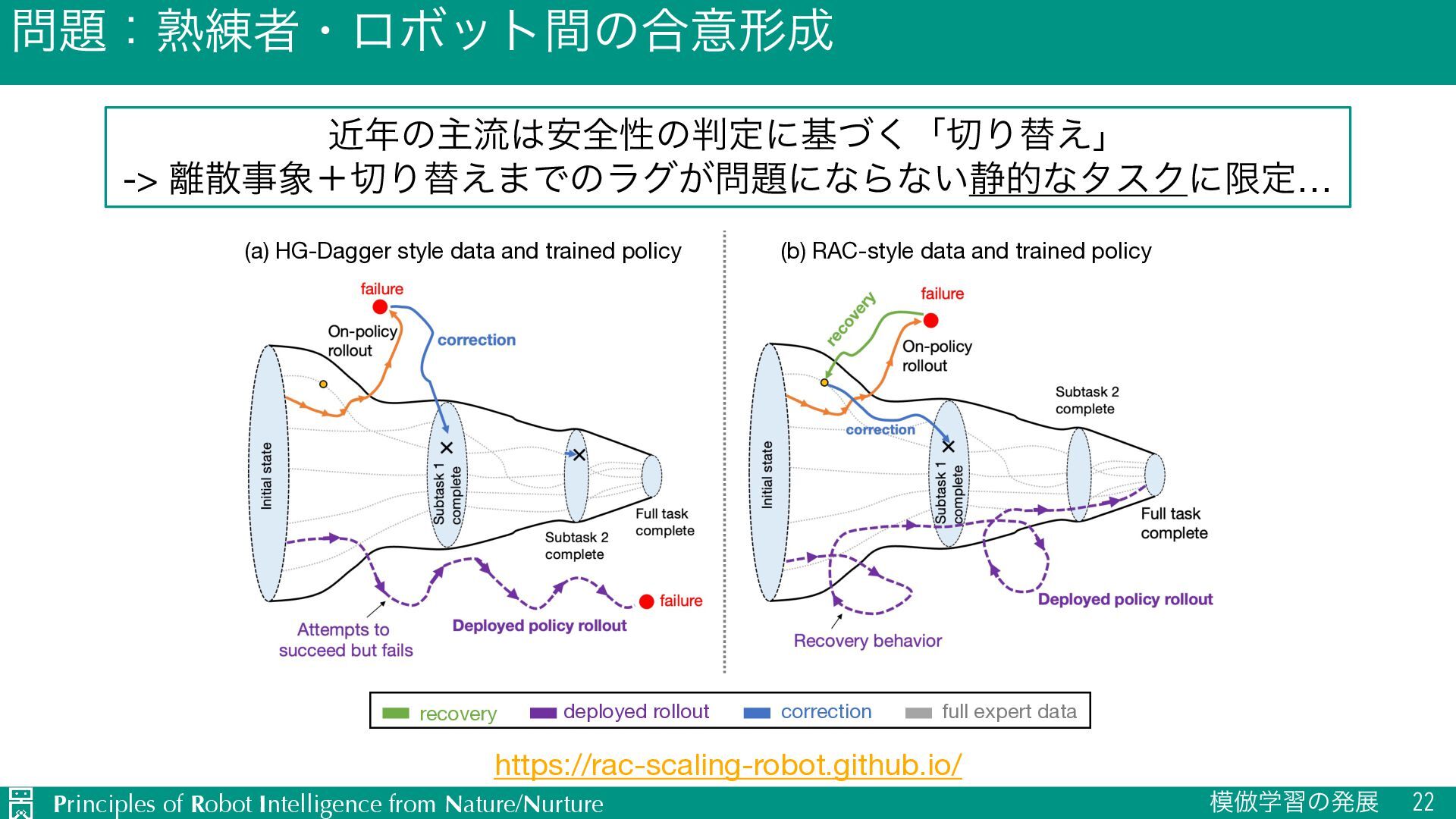
-> ࢄࣄʴΓସ͑·Ͱͷϥά͕ʹͳΒͳ͍੩తͳλεΫʹݶఆ… RaC: Robot Learning for Long-Horizon Tasks by Scaling Recovery and Correction (a) HG-Dagger style data and trained policy (b) RAC-style data and trained policy recovery deployed rollout full expert data correction Figure 3: Illustrating the core concept behind RaC. Data collected via human interventions prescribed by RaC and a sample policy rollout when training on only correction data (“HG-DAgger”) vs recovery and correction data (RaC). Typical intervention https://rac-scaling-robot.github.io/
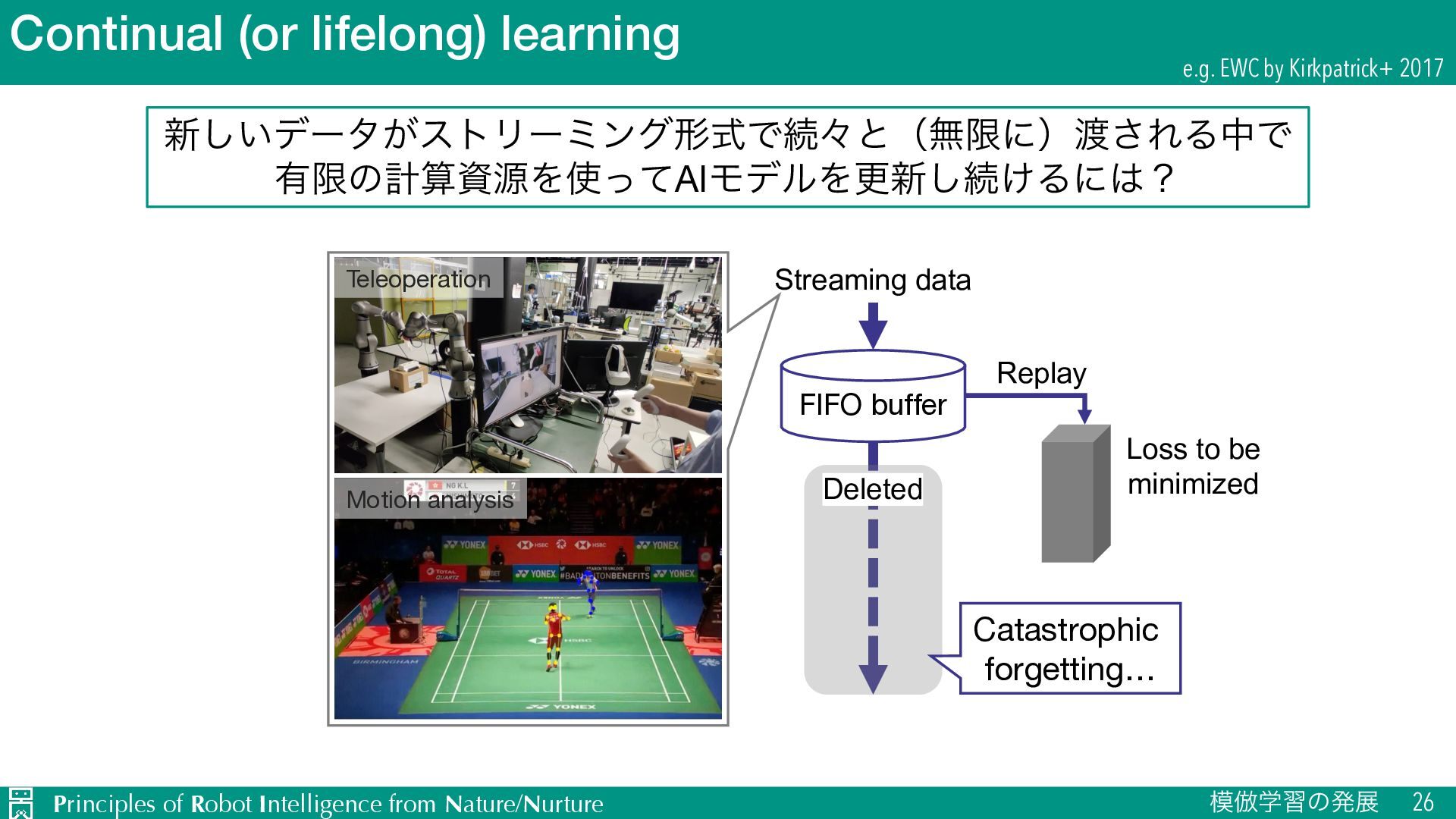
฿ֶशͷൃల 26 e.g. EWC by Kirkpatrick+ 2017 ৽͍͠σʔλ͕ετϦʔϛϯάܗࣜͰଓʑͱʢແݶʹʣ͞ΕΔதͰ ༗ݶͷܭࢉࢿݯΛͬͯAIϞσϧΛߋ৽͠ଓ͚Δʹʁ Streaming data FIFO buffer Deleted Catastrophic forgetting… Replay Loss to be minimized Teleoperation Motion analysis
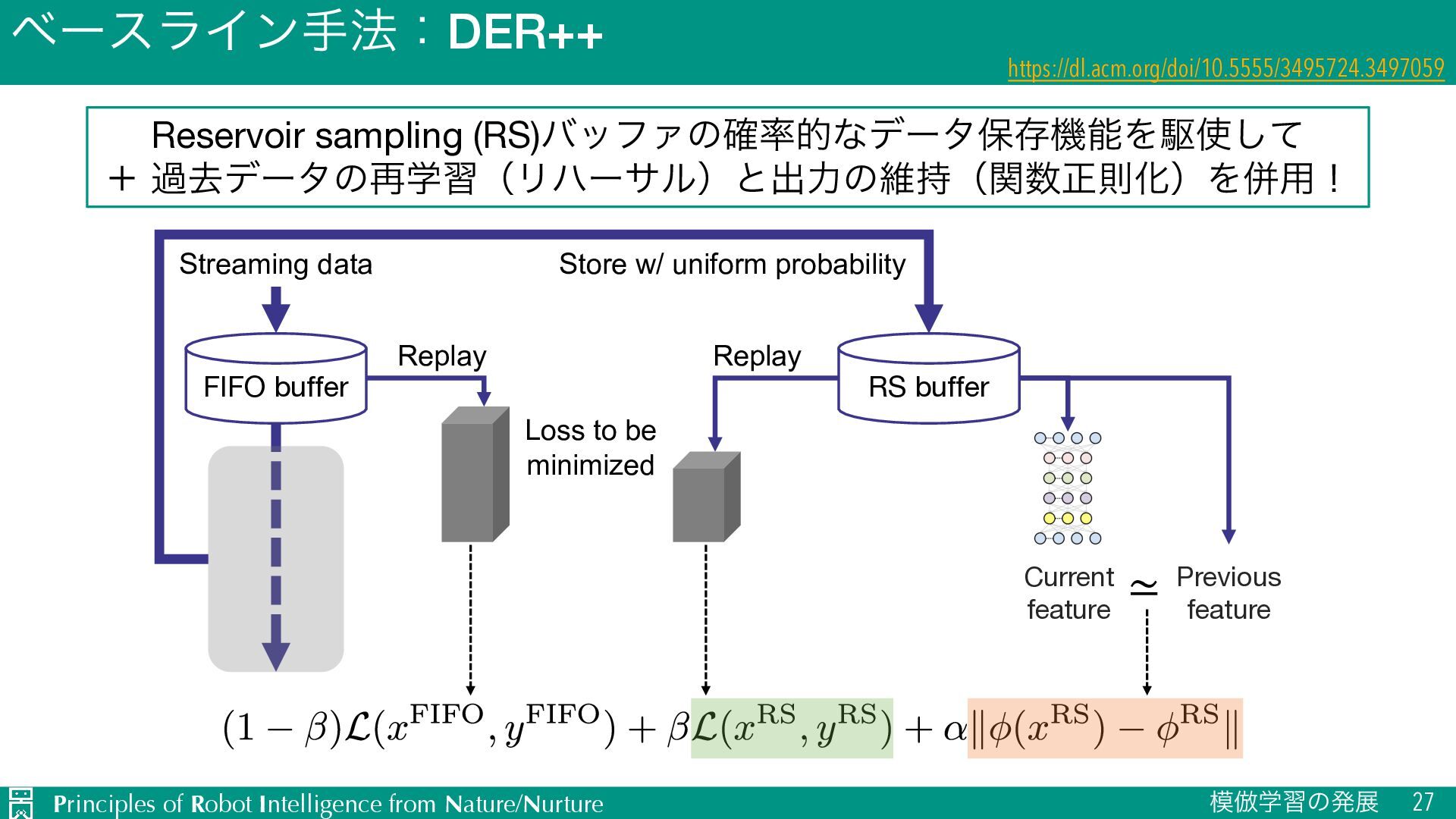
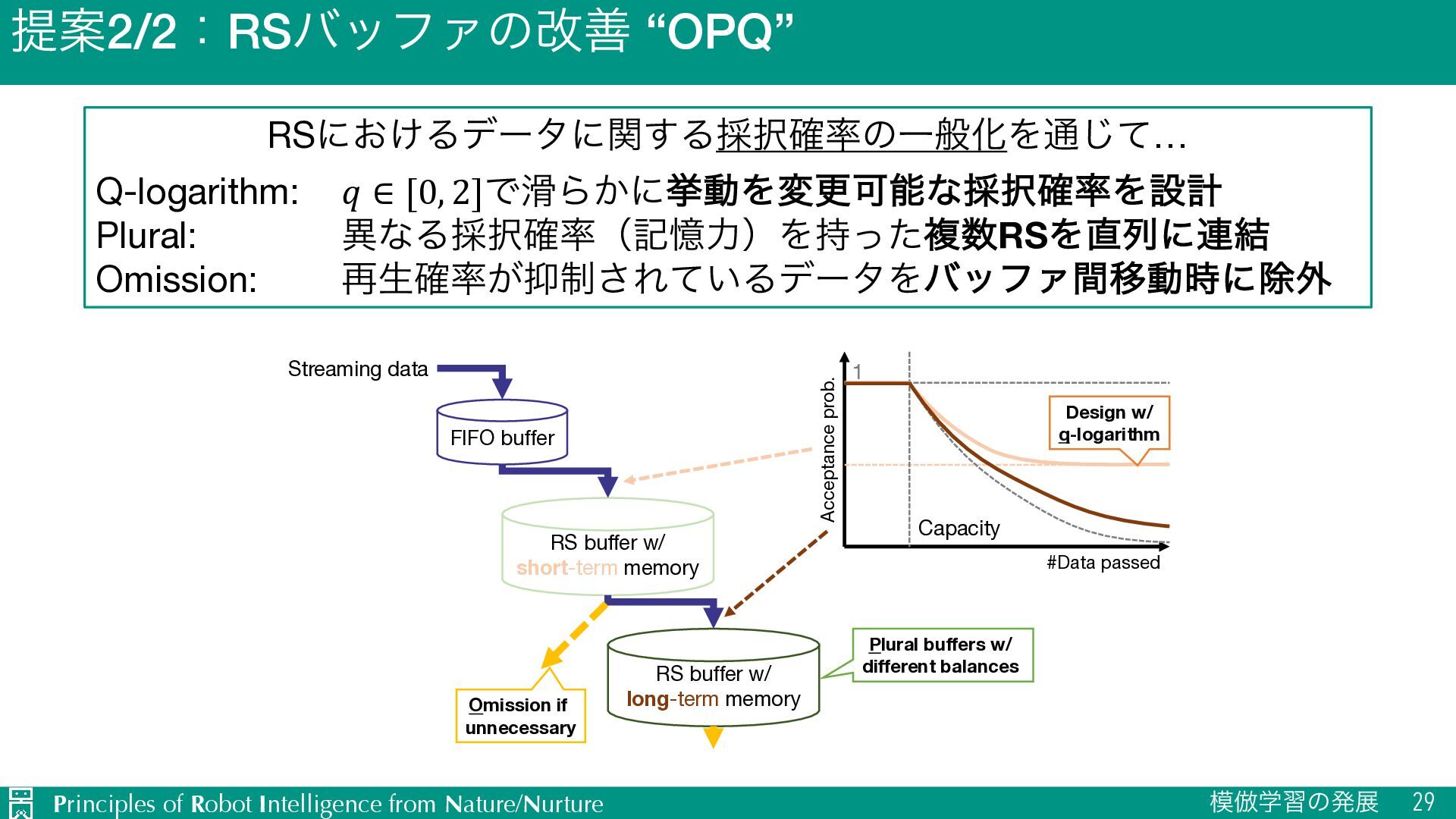
Reservoir sampling (RS)όοϑΝͷ֬తͳσʔλอଘػೳΛۦͯ͠ ʴ աڈσʔλͷ࠶ֶशʢϦϋʔαϧʣͱग़ྗͷҡ࣋ʢؔਖ਼ଇԽʣΛซ༻ʂ Streaming data FIFO buffer Replay Loss to be minimized RS buffer Store w/ uniform probability Replay Current output Previous output ≃ Current feature Previous feature
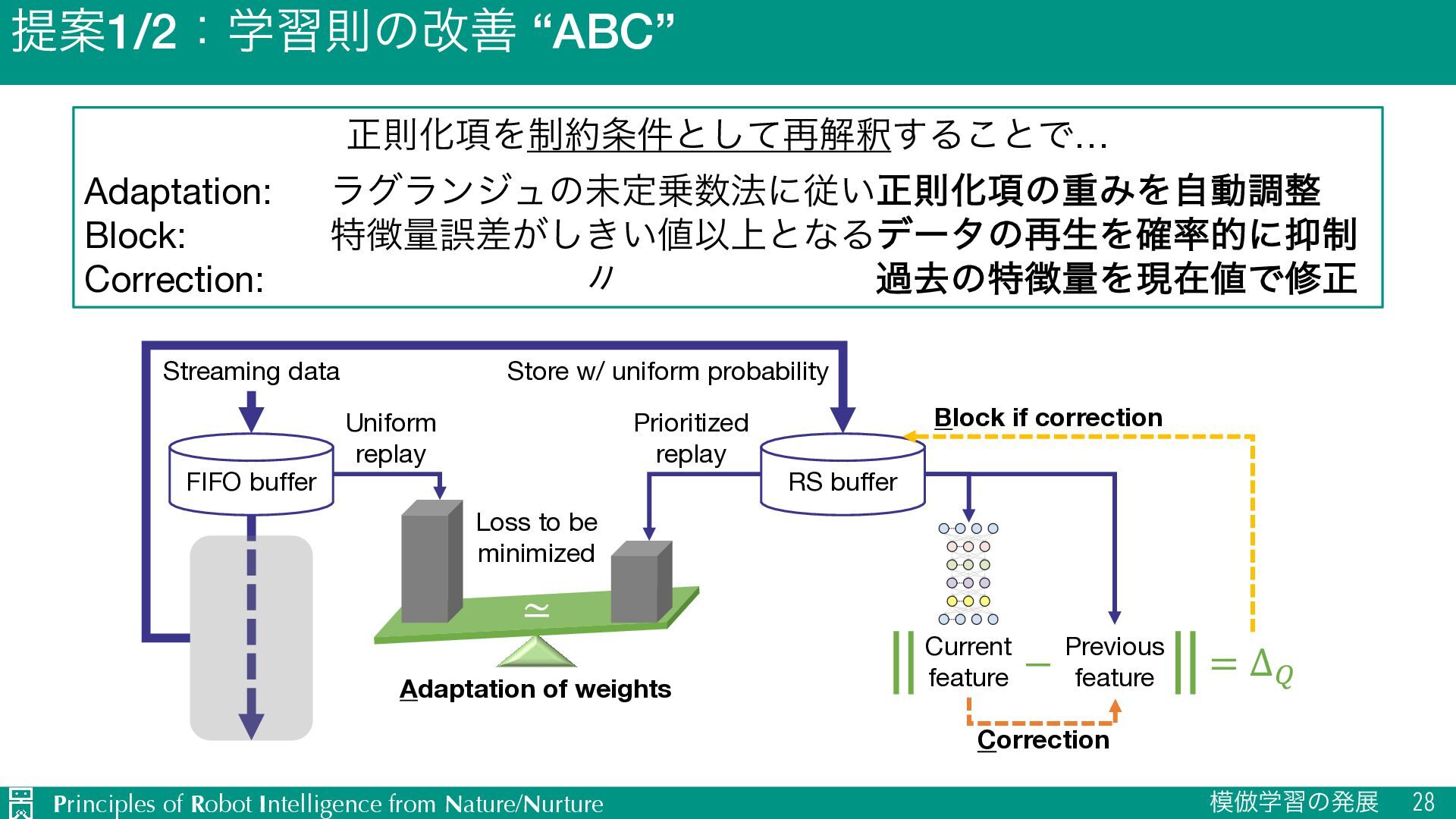
ਖ਼ଇԽ߲Λ੍݅ͱͯ͠࠶ղऍ͢Δ͜ͱͰ… Adaptation: ϥάϥϯδϡͷະఆ๏ʹै͍ਖ਼ଇԽ߲ͷॏΈΛࣗಈௐ Block: ಛྔޡ͕͖͍ࠩ͠Ҏ্ͱͳΔσʔλͷ࠶ੜΛ֬తʹ੍ Correction: ʏ աڈͷಛྔΛݱࡏͰमਖ਼ ≃ Streaming data FIFO buffer Uniform replay Loss to be minimized RS buffer Store w/ uniform probability Prioritized replay Current feature Previous feature − = Δ! Correction Block if correction Adaptation of weights
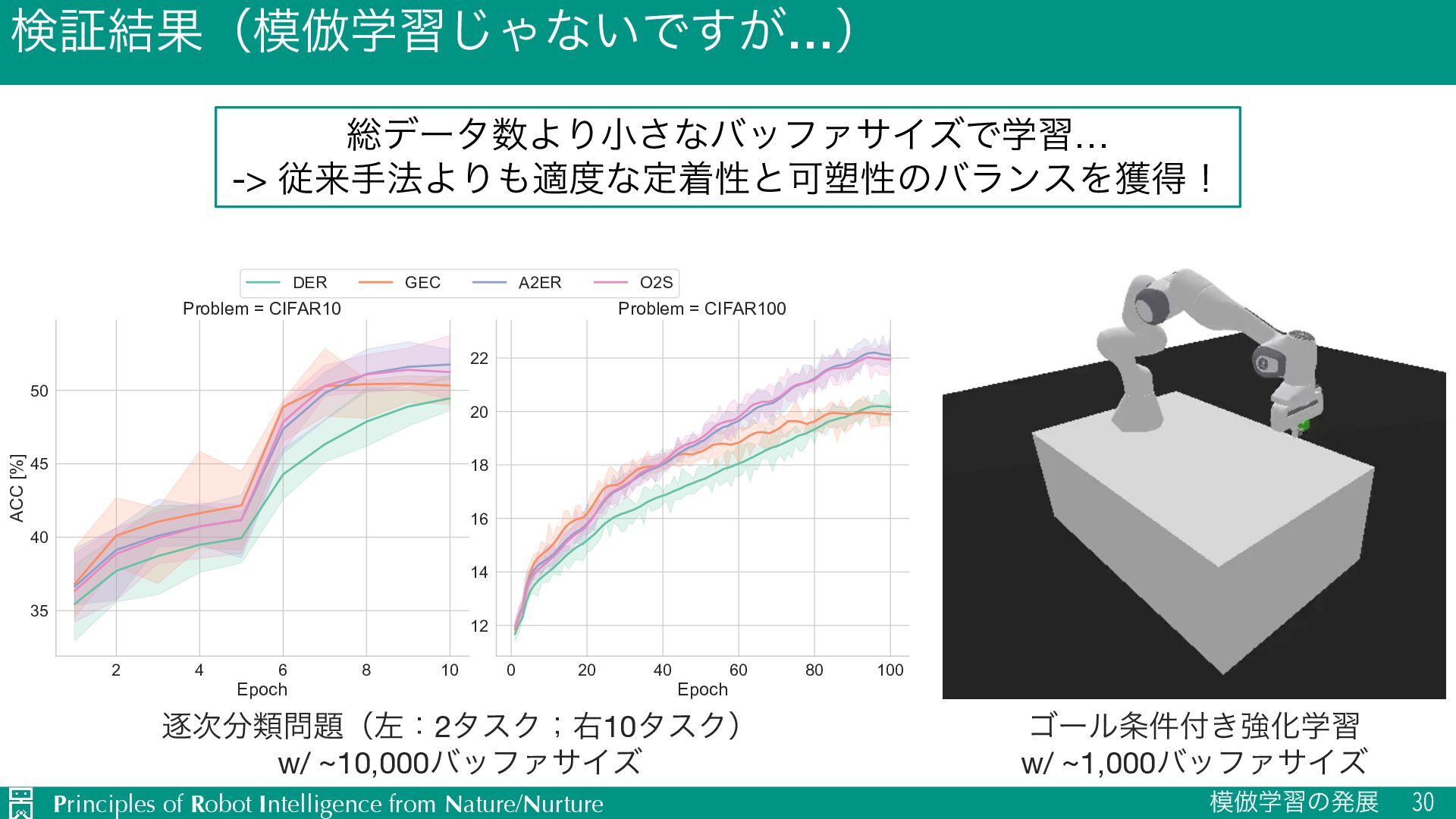
u ࣄલֶशɿଟ༷ͳσʔλΛڐ༰͍ͨ͠ ü ऩू͍ͯ͠ͳ͍ख़࿅ऀͷߦಈσʔλΛ҆શʹਪఆʂ ü ޡΓΛؚΉσϞσʔλ͔ΒͰؤ݈ʹֶशʂ u ࣄޙֶशɿֶश͠ଓ͚͍ͨ ü ಈతλεΫͰ҆શʹσϞσʔλΛஞ࣍Ճʂ ü Θ͔ͣͳܭࢉࢿݯͰఆணੑͱՄ઼ੑΛֶཱ྆ͯ͠शʂ u ՝… pࣄޙֶश݁ՌΛࣄલֶशࡁΈϞσϧʹ͢Έ͕ඞཁ Ø ࿈߹ֶशͳͲʁMoEܗࣜͩͱεέʔϧ͠ͳ͍ʁ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
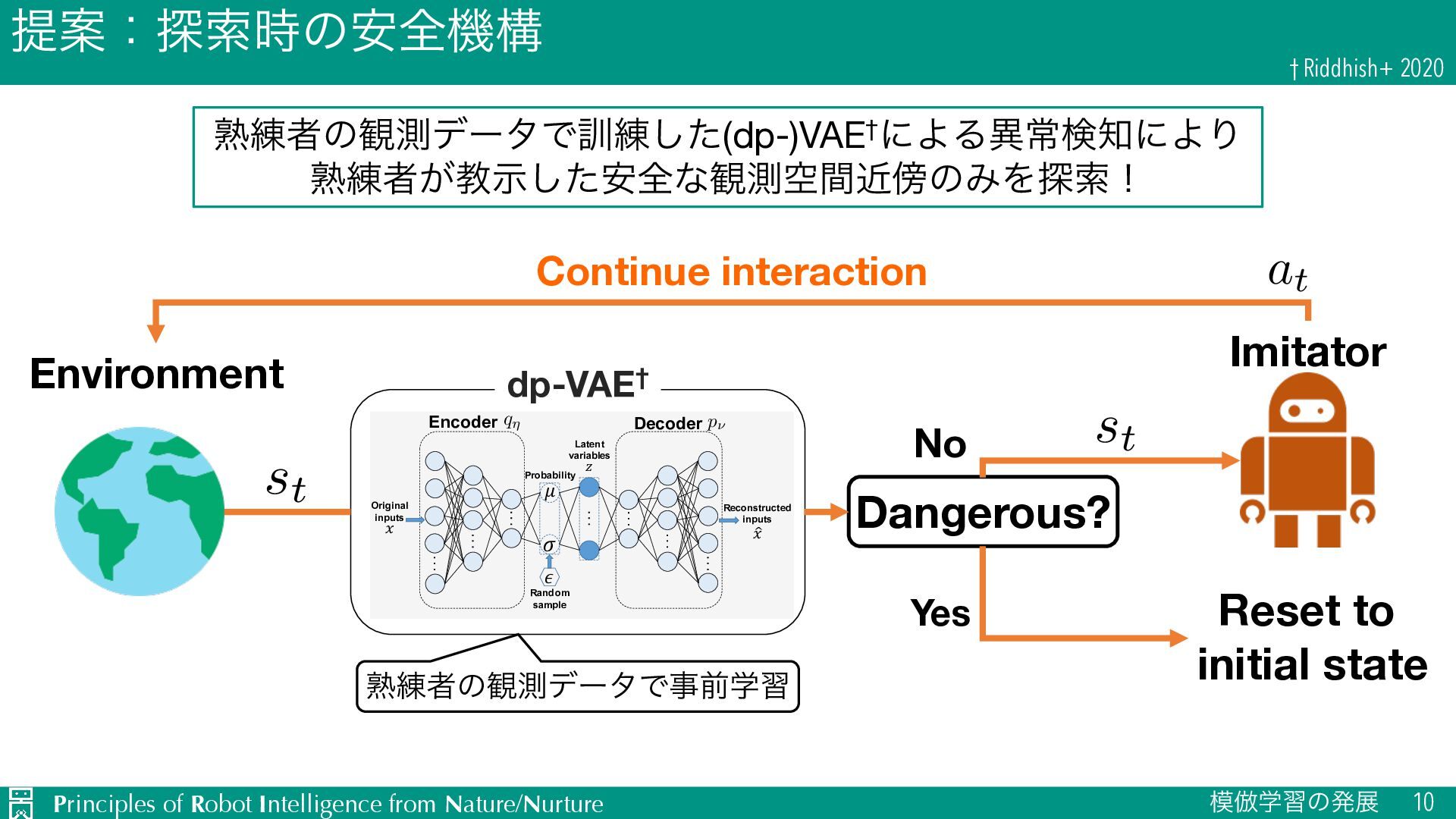{kind=link}
{kind=link}
{kind=link}
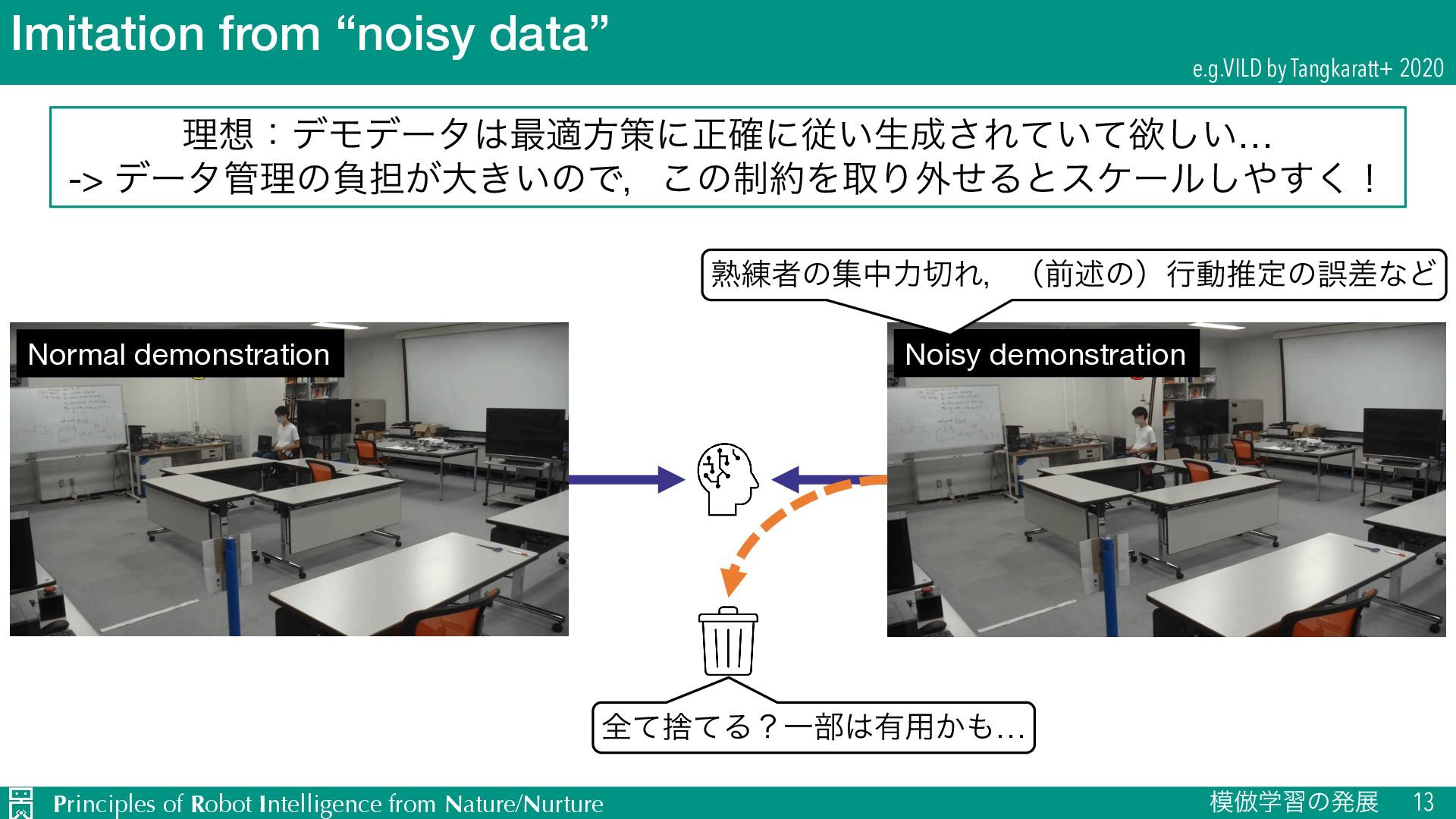{kind=link}
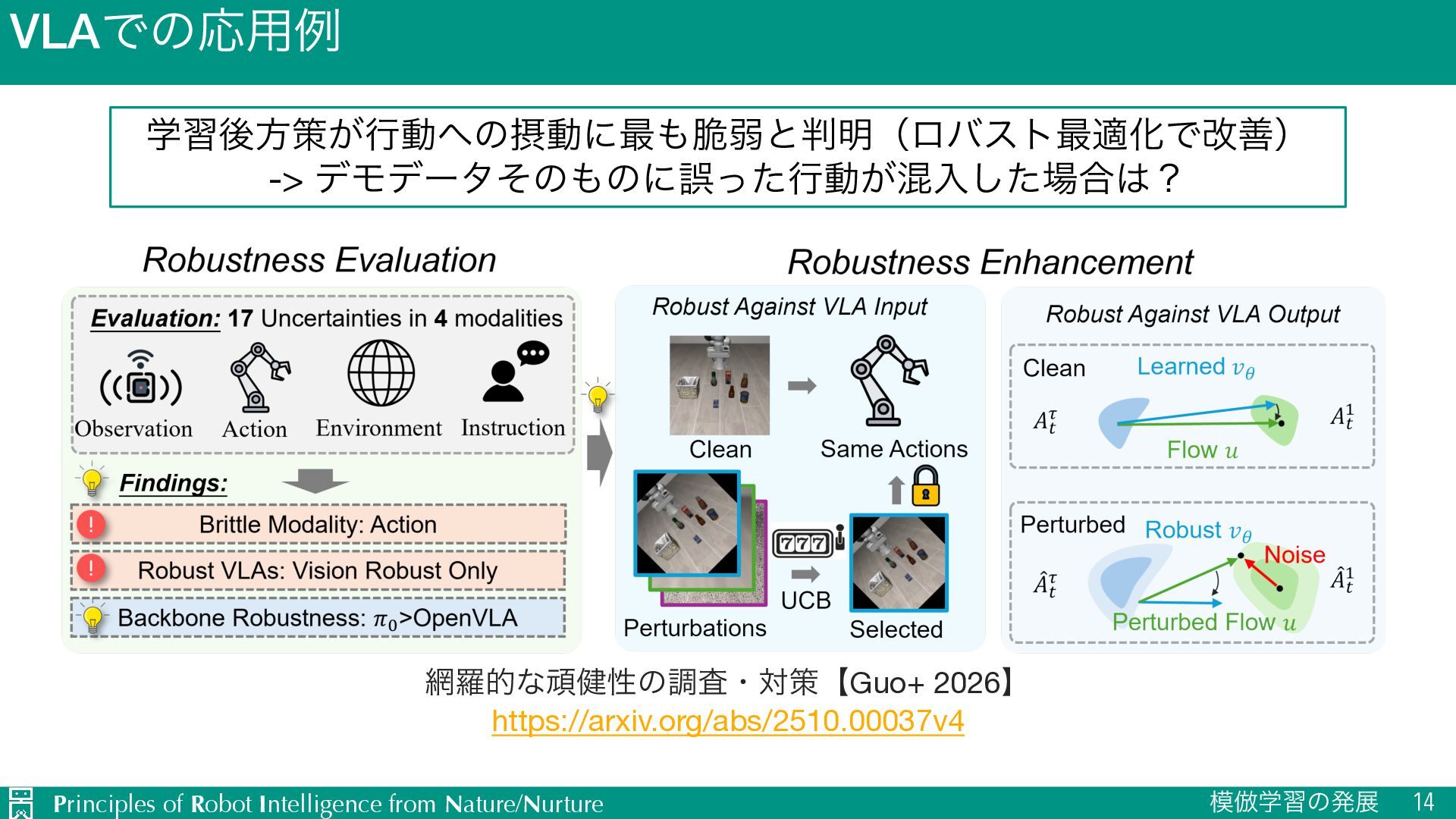{kind=link}
{kind=link}
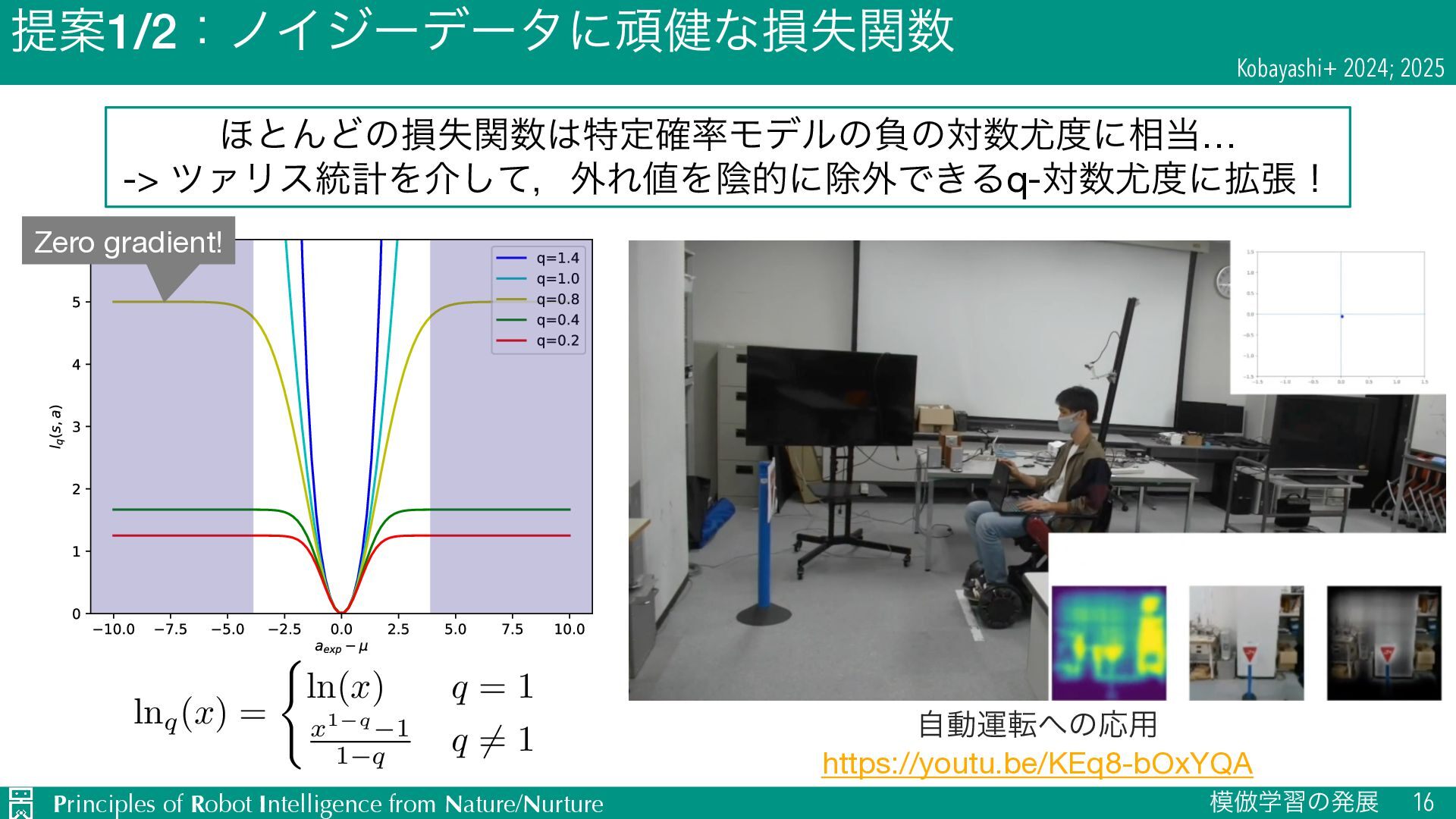{kind=link}
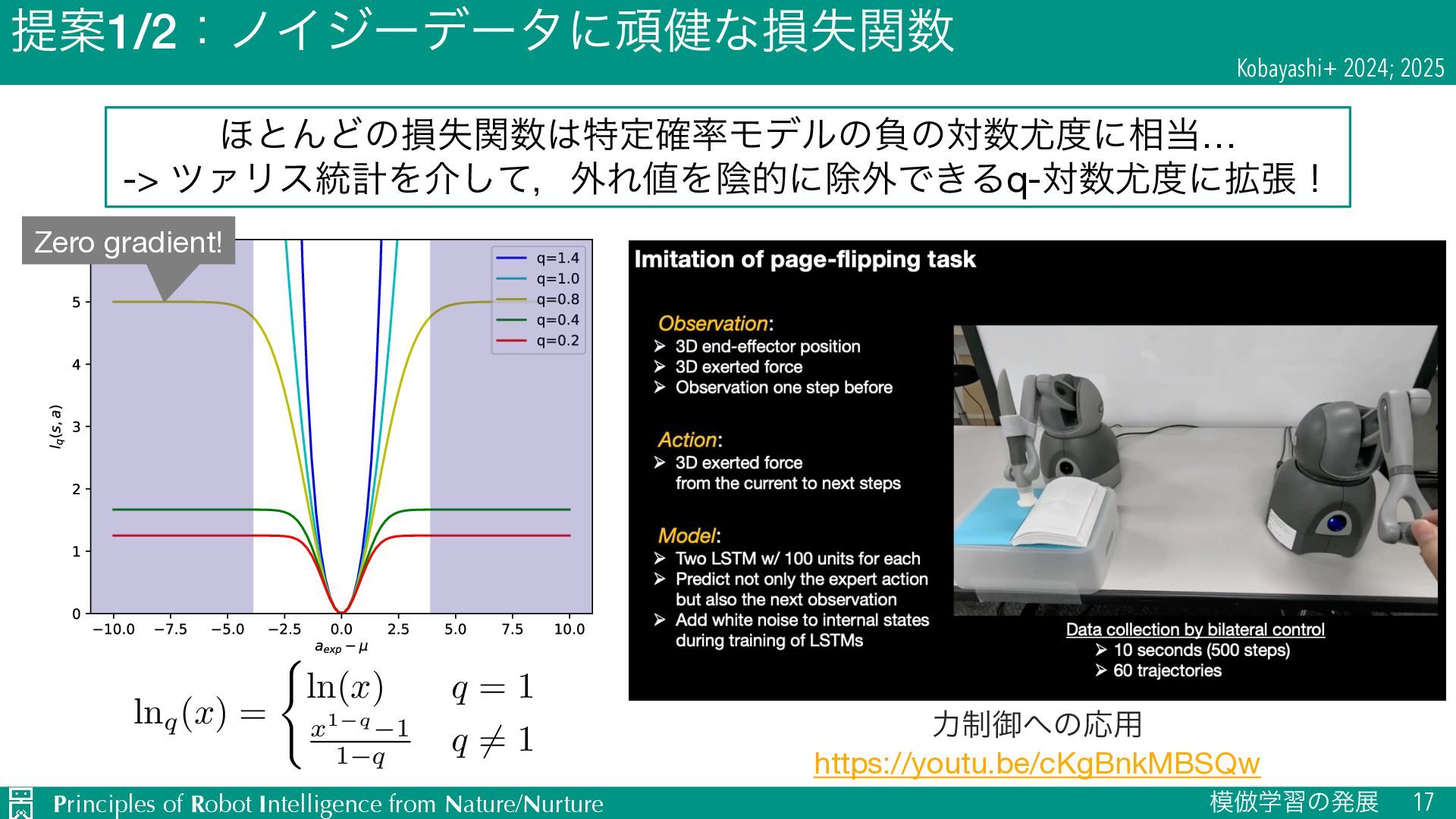{kind=link}
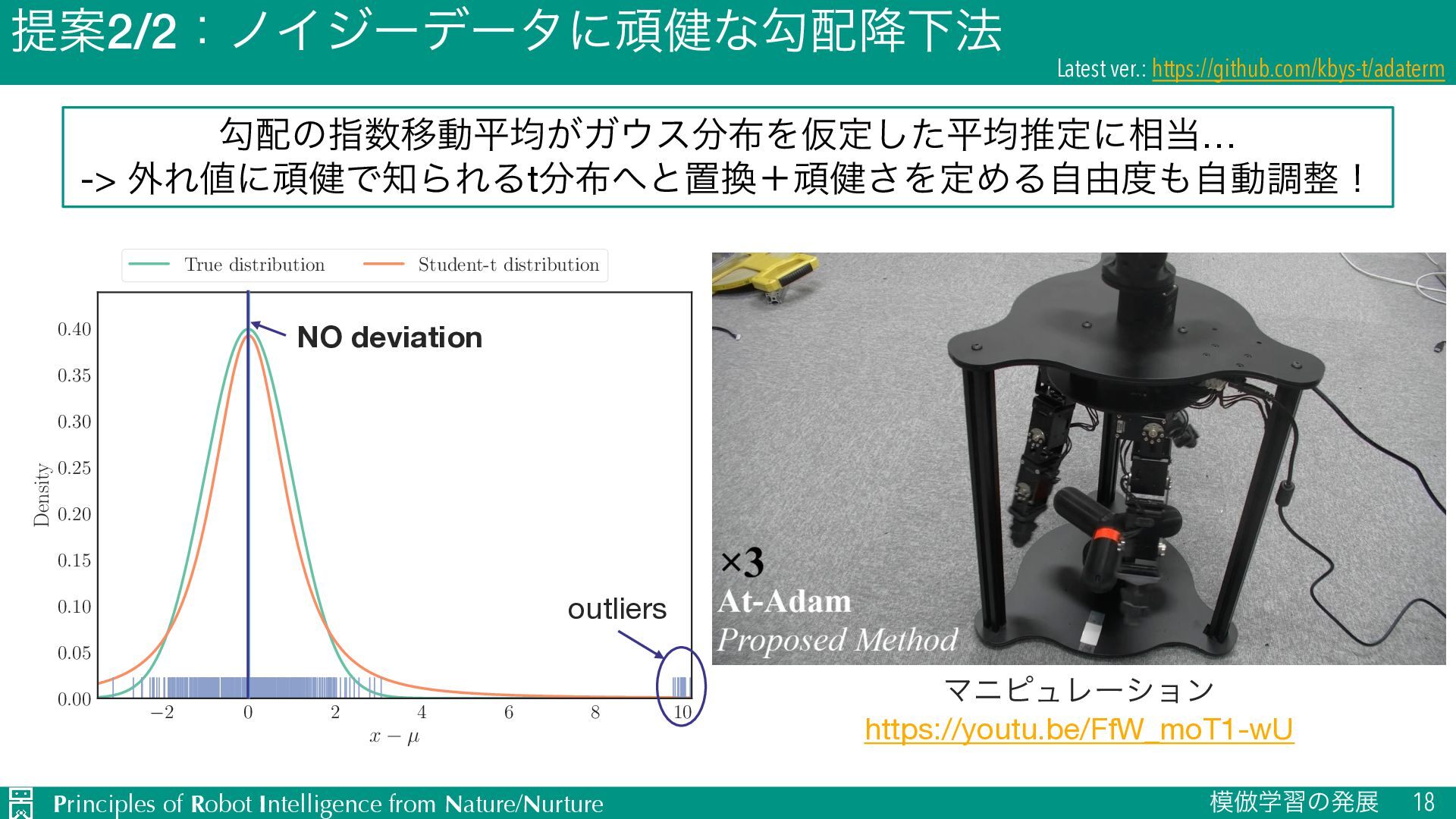{kind=link}
{kind=link}
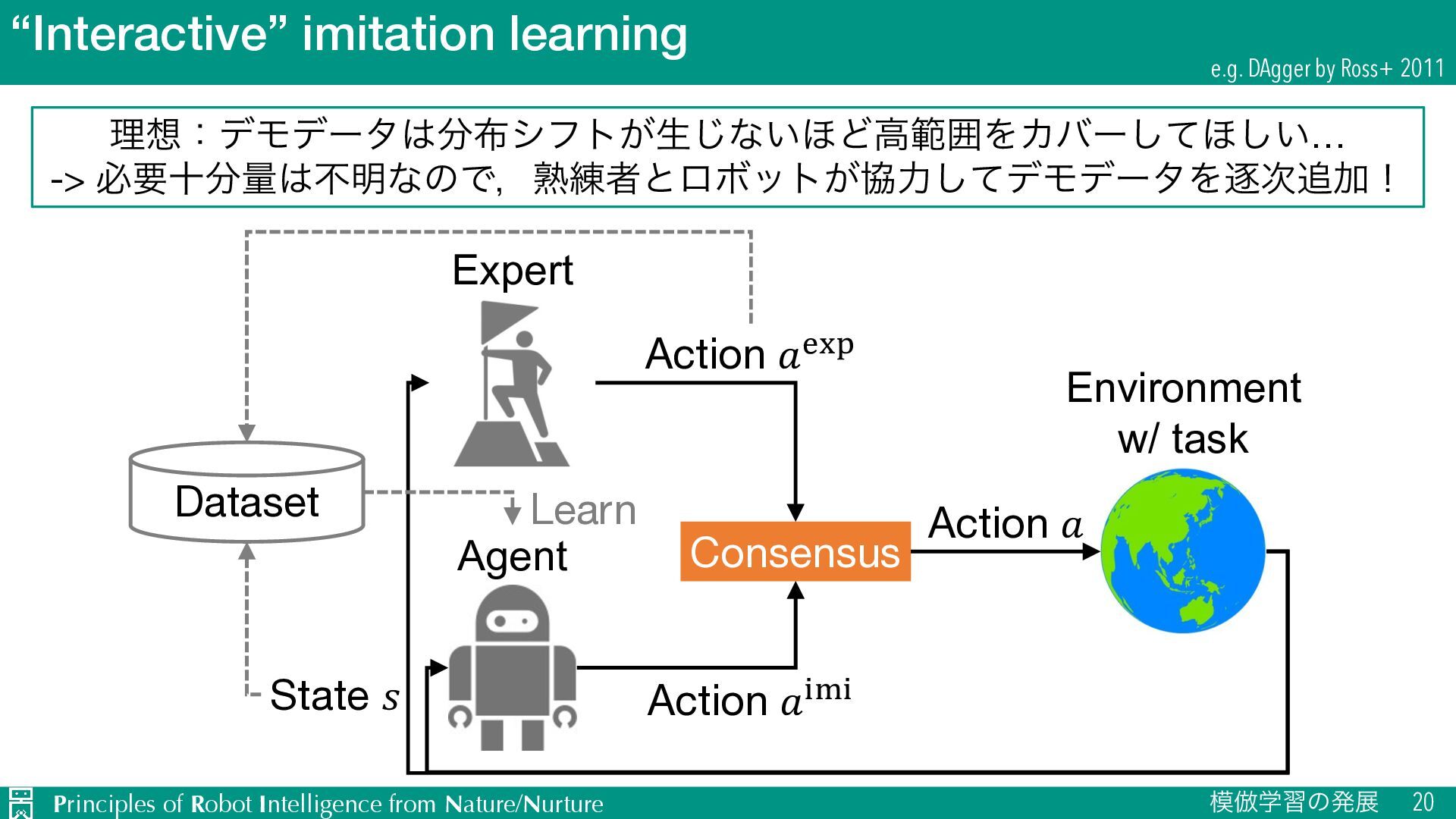{kind=link}
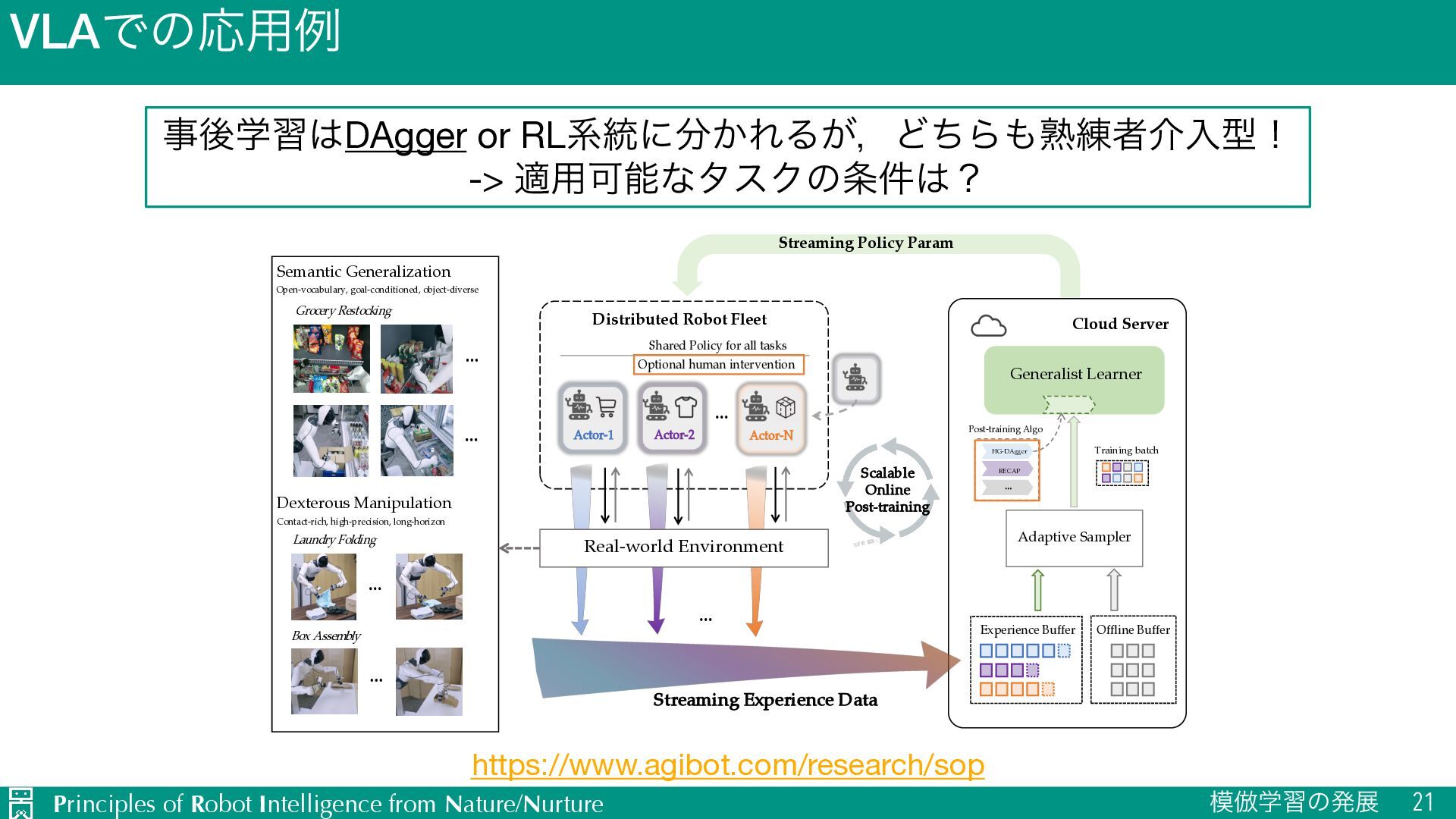{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}