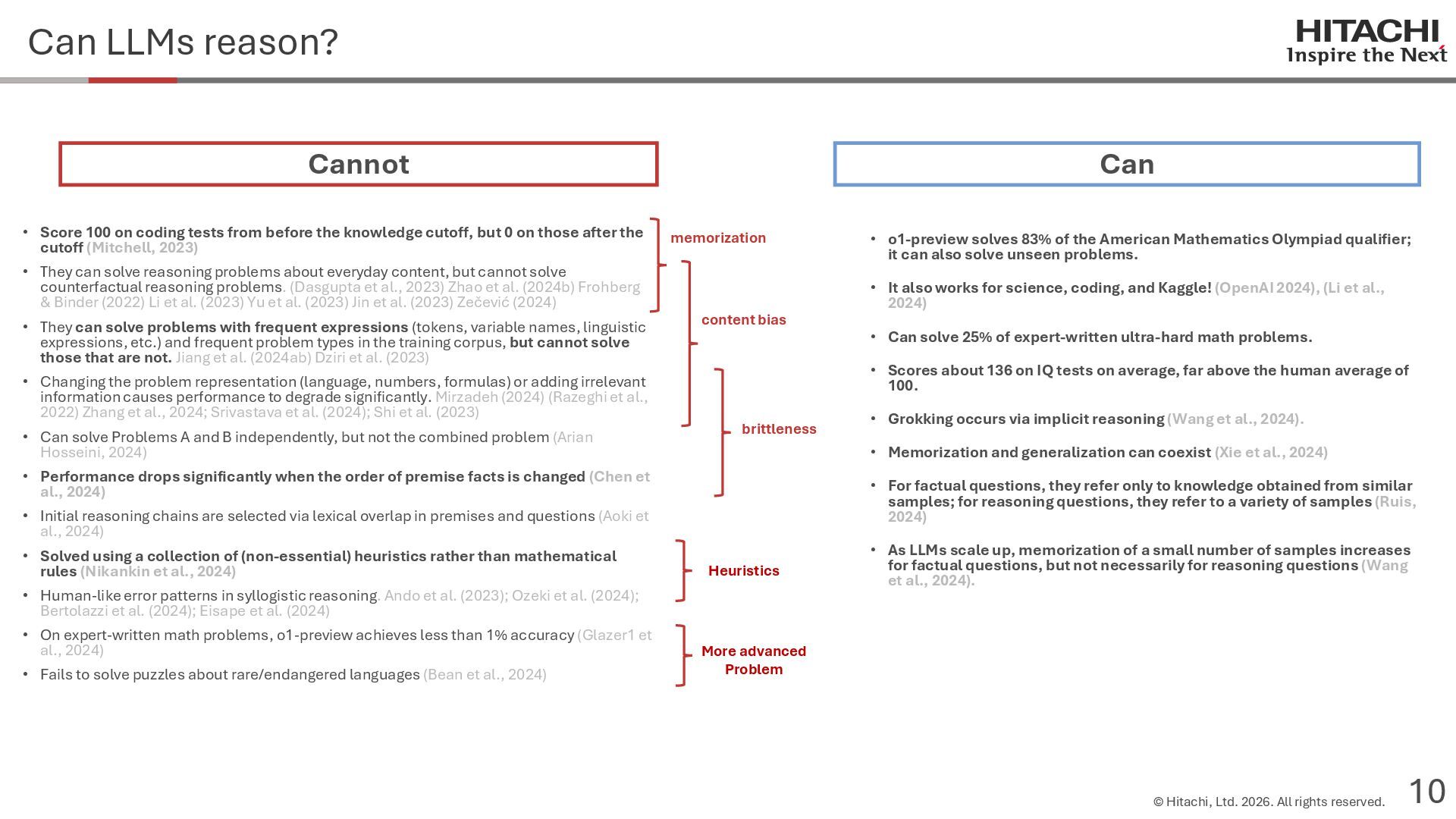
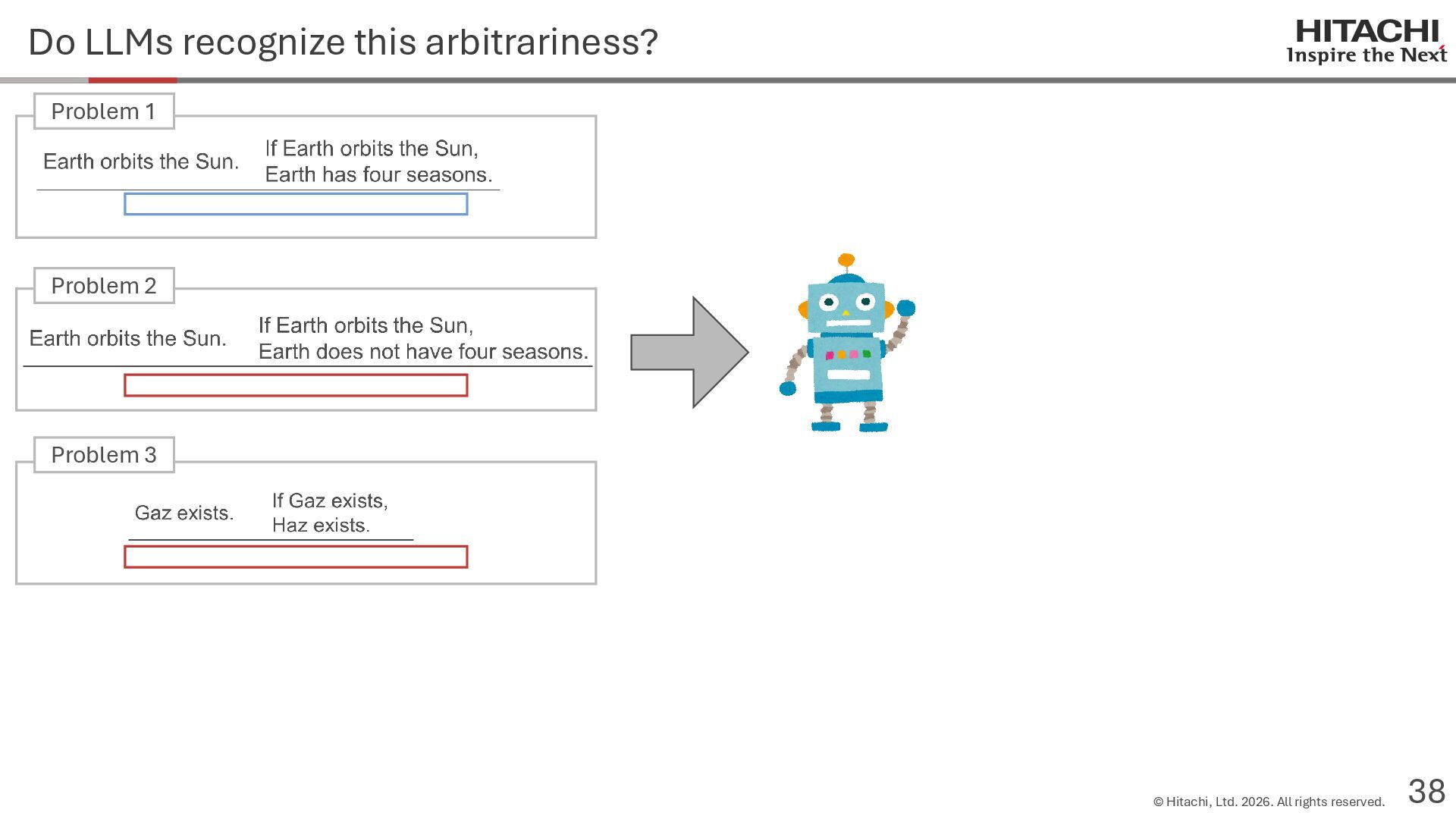
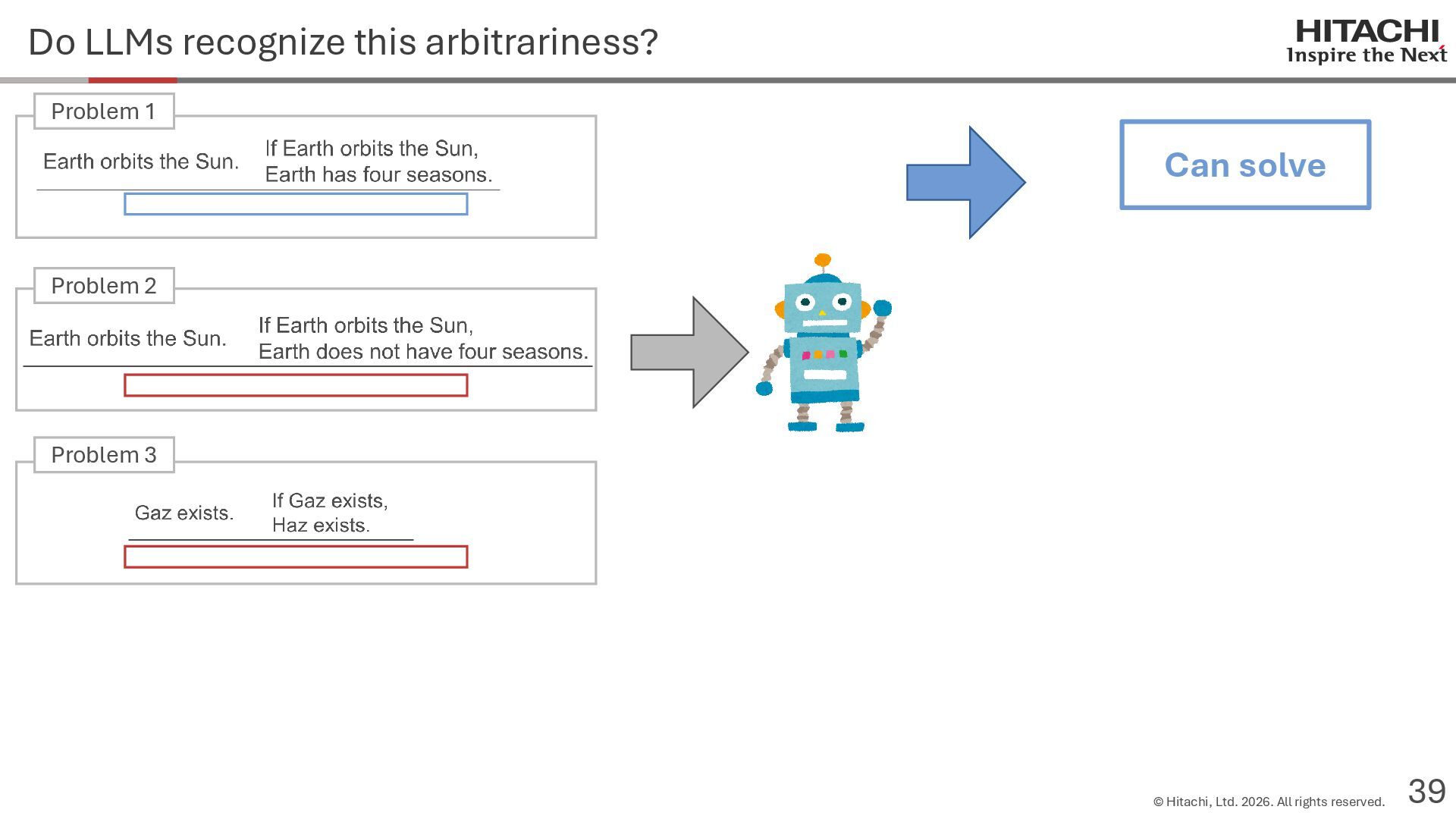
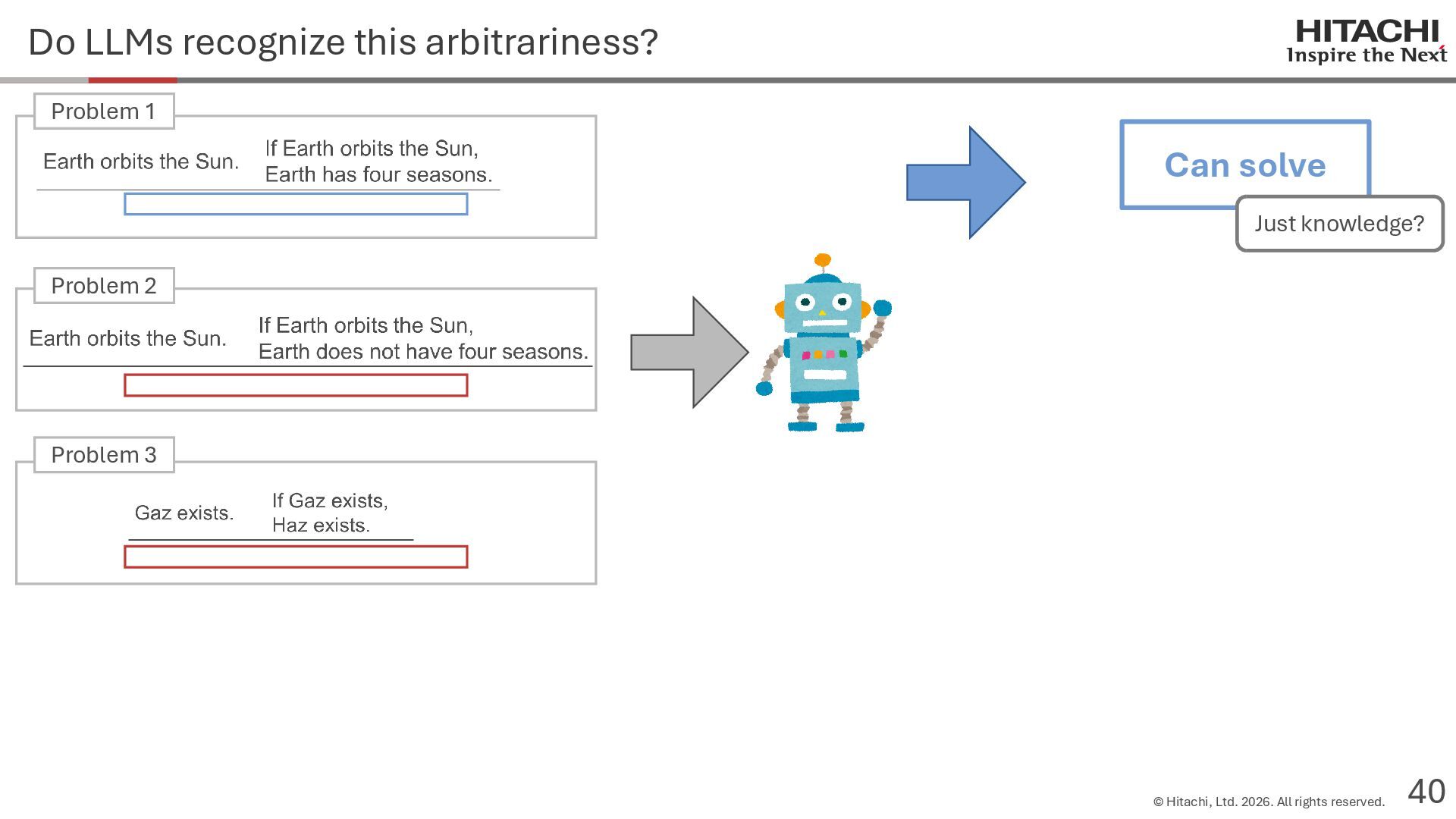
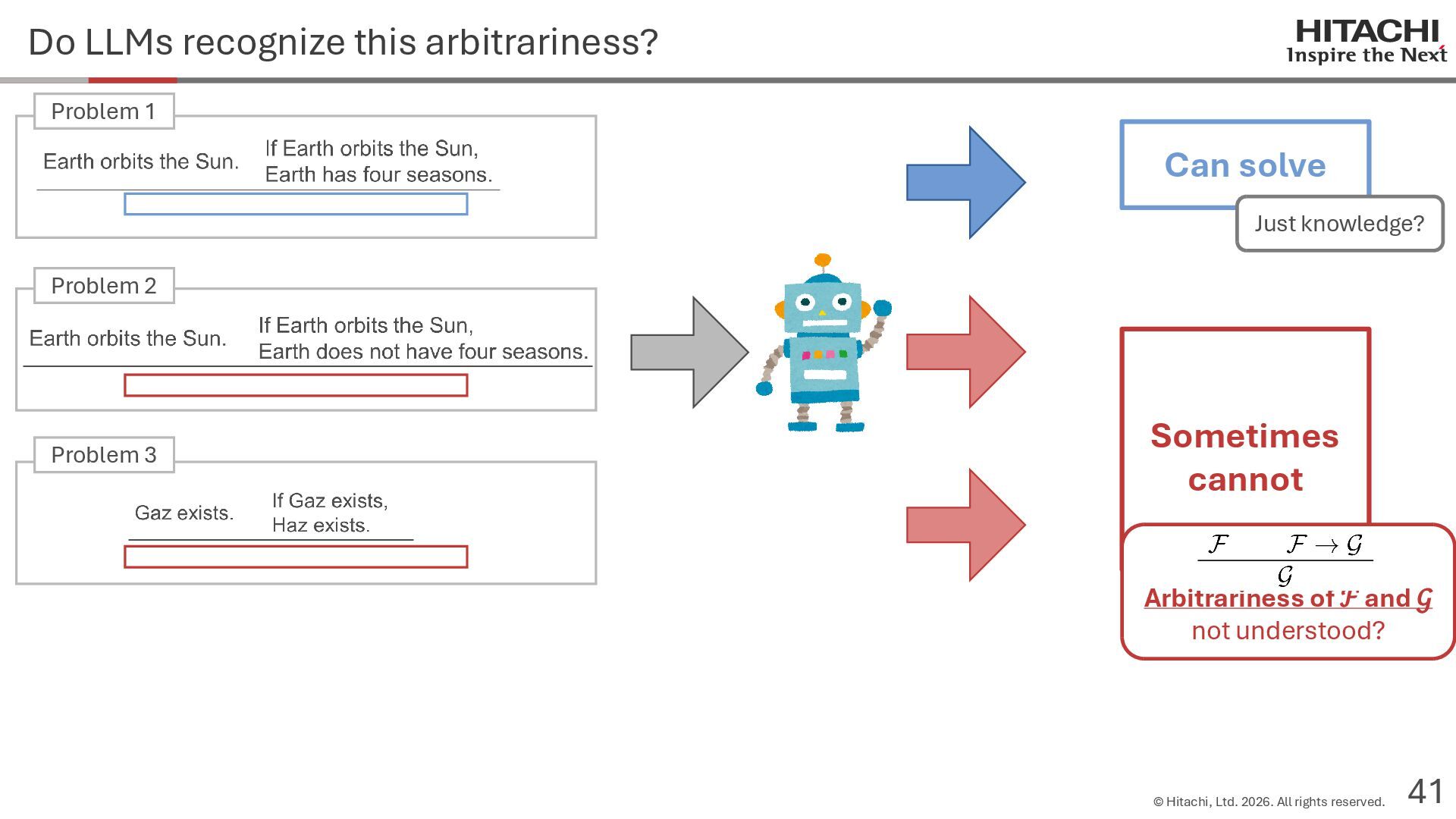
reason? Can Cannot • Score 100 on coding tests from before the knowledge cutoff, but 0 on those after the cutoff (Mitchell, 2023) • They can solve reasoning problems about everyday content, but cannot solve counterfactual reasoning problems. (Dasgupta et al., 2023) Zhao et al. (2024b) Frohberg & Binder (2022) Li et al. (2023) Yu et al. (2023) Jin et al. (2023) Zečević (2024) • They can solve problems with frequent expressions (tokens, variable names, linguistic expressions, etc.) and frequent problem types in the training corpus, but cannot solve those that are not. Jiang et al. (2024ab) Dziri et al. (2023) • Changing the problem representation (language, numbers, formulas) or adding irrelevant information causes performance to degrade significantly. Mirzadeh (2024) (Razeghi et al., 2022) Zhang et al., 2024; Srivastava et al. (2024); Shi et al. (2023) • Can solve Problems A and B independently, but not the combined problem (Arian Hosseini, 2024) • Performance drops significantly when the order of premise facts is changed (Chen et al., 2024) • Initial reasoning chains are selected via lexical overlap in premises and questions (Aoki et al., 2024) • Solved using a collection of (non-essential) heuristics rather than mathematical rules (Nikankin et al., 2024) • Human-like error patterns in syllogistic reasoning. Ando et al. (2023); Ozeki et al. (2024); Bertolazzi et al. (2024); Eisape et al. (2024) • On expert-written math problems, o1-preview achieves less than 1% accuracy (Glazer1 et al., 2024) • Fails to solve puzzles about rare/endangered languages (Bean et al., 2024) memorization content bias brittleness Heuristics • o1-preview solves 83% of the American Mathematics Olympiad qualifier; it can also solve unseen problems. • It also works for science, coding, and Kaggle! (OpenAI 2024), (Li et al., 2024) • Can solve 25% of expert-written ultra-hard math problems. • Scores about 136 on IQ tests on average, far above the human average of 100. • Grokking occurs via implicit reasoning (Wang et al., 2024). • Memorization and generalization can coexist (Xie et al., 2024) • For factual questions, they refer only to knowledge obtained from similar samples; for reasoning questions, they refer to a variety of samples (Ruis, 2024) • As LLMs scale up, memorization of a small number of samples increases for factual questions, but not necessarily for reasoning questions (Wang et al., 2024). More advanced Problem
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
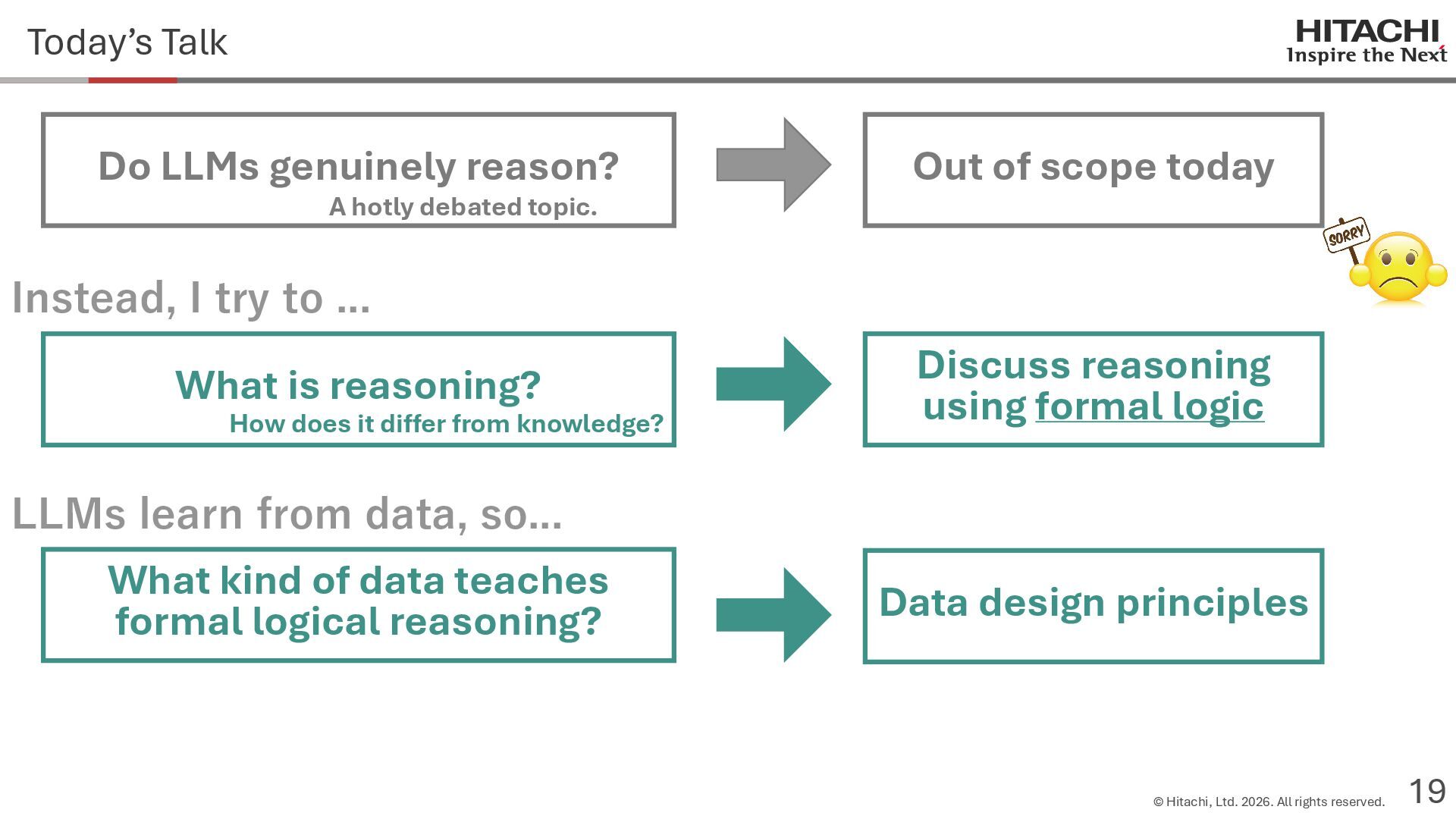{kind=link}
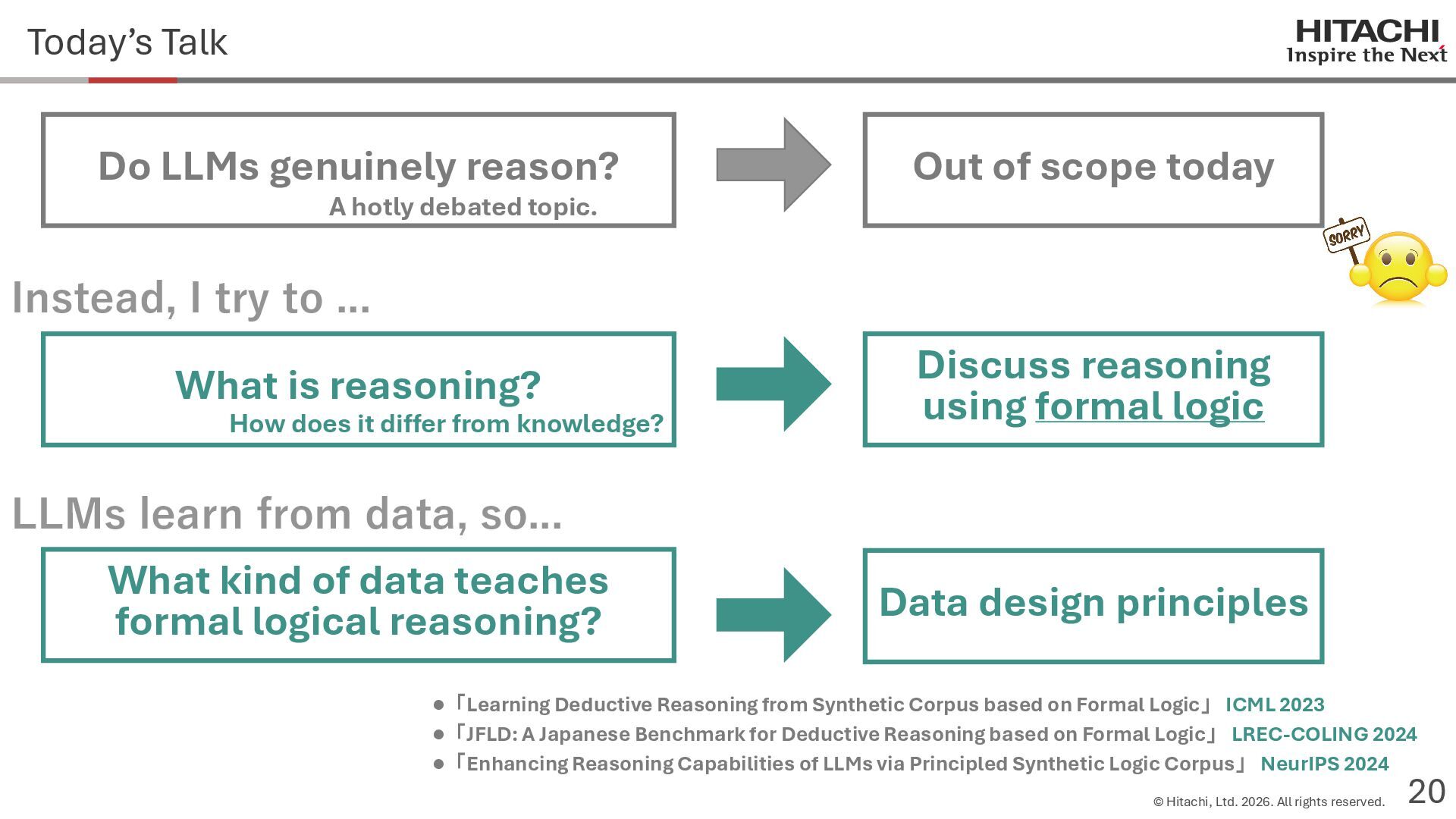{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
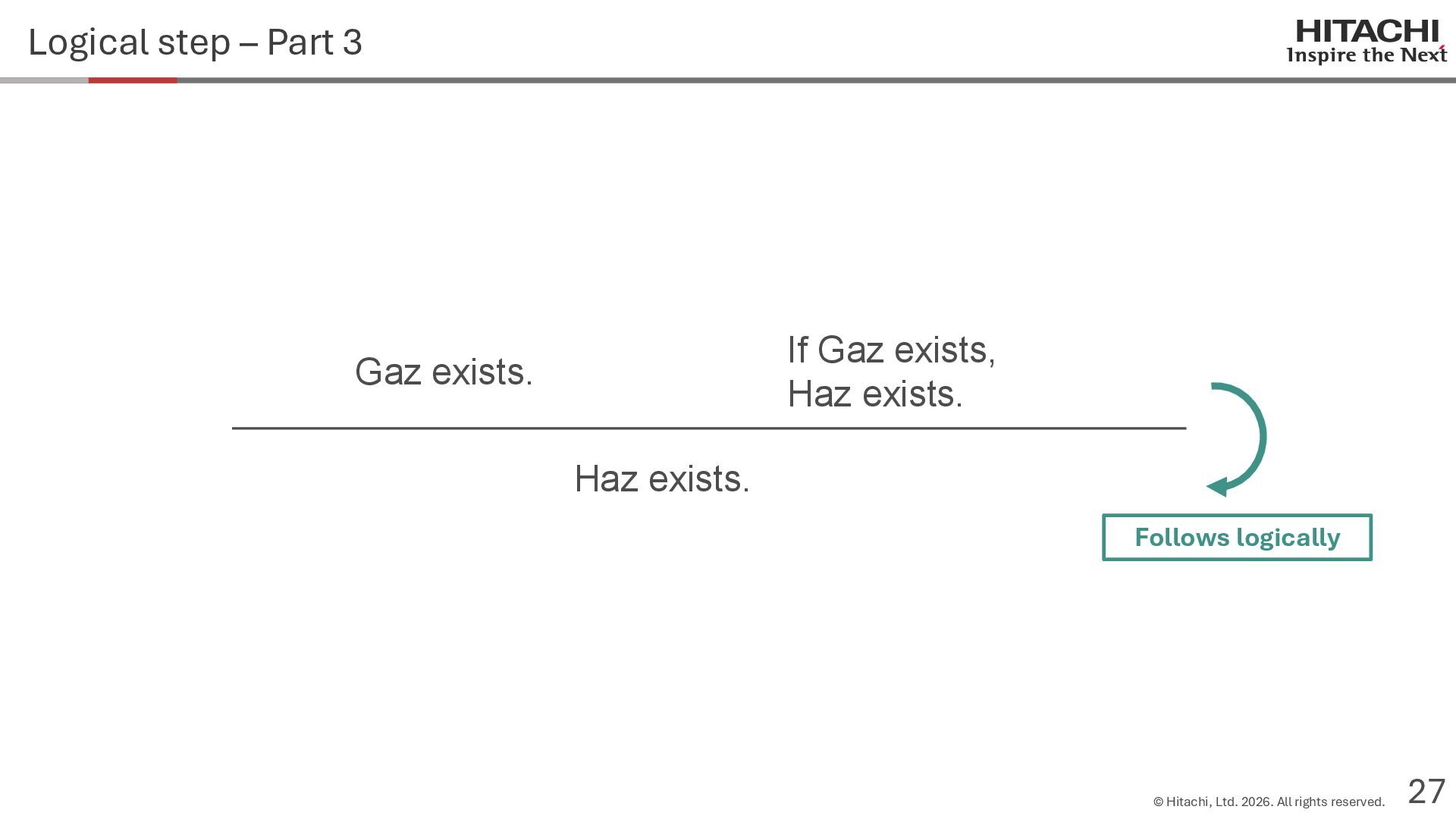{kind=link}
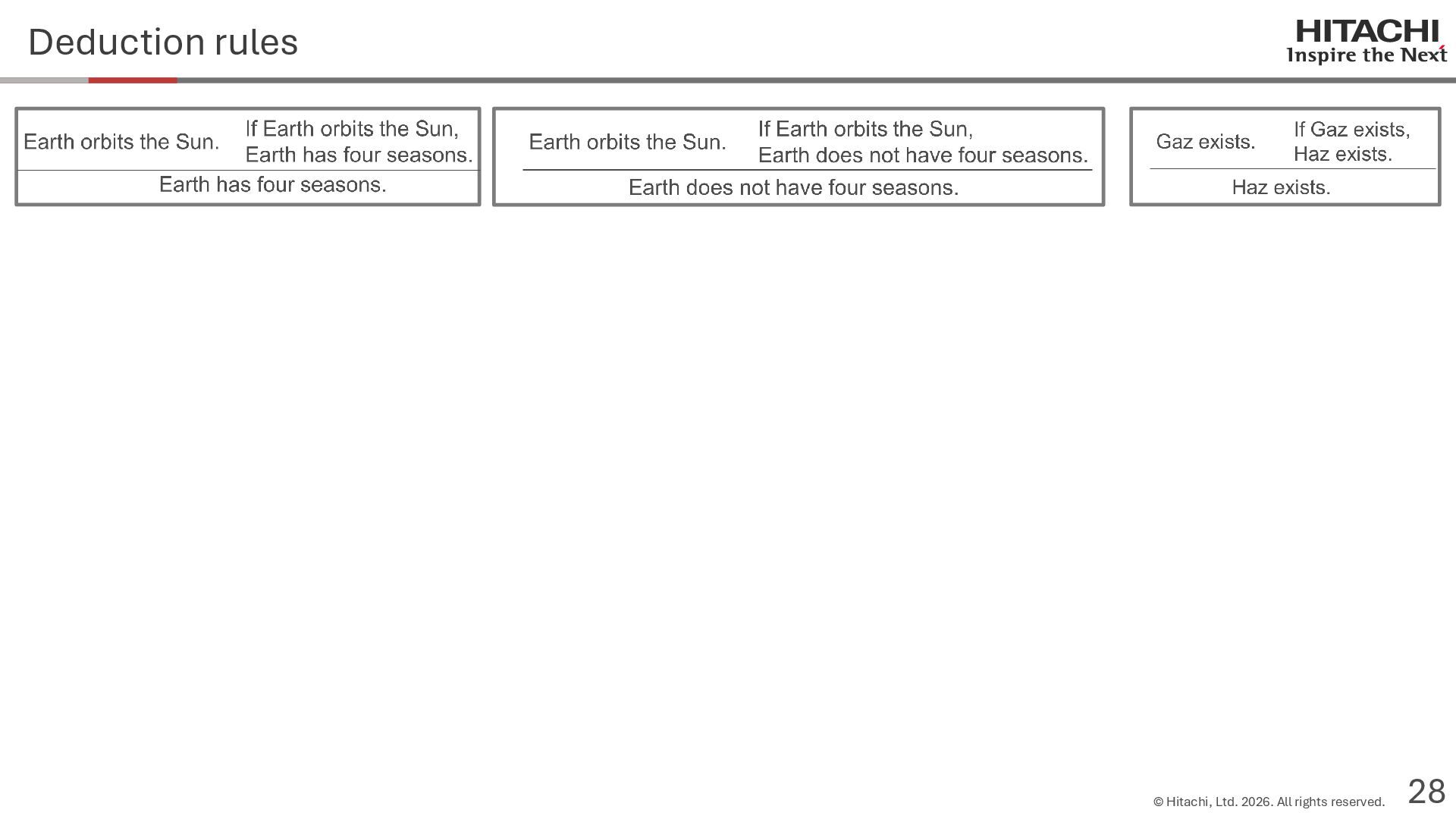{kind=link}
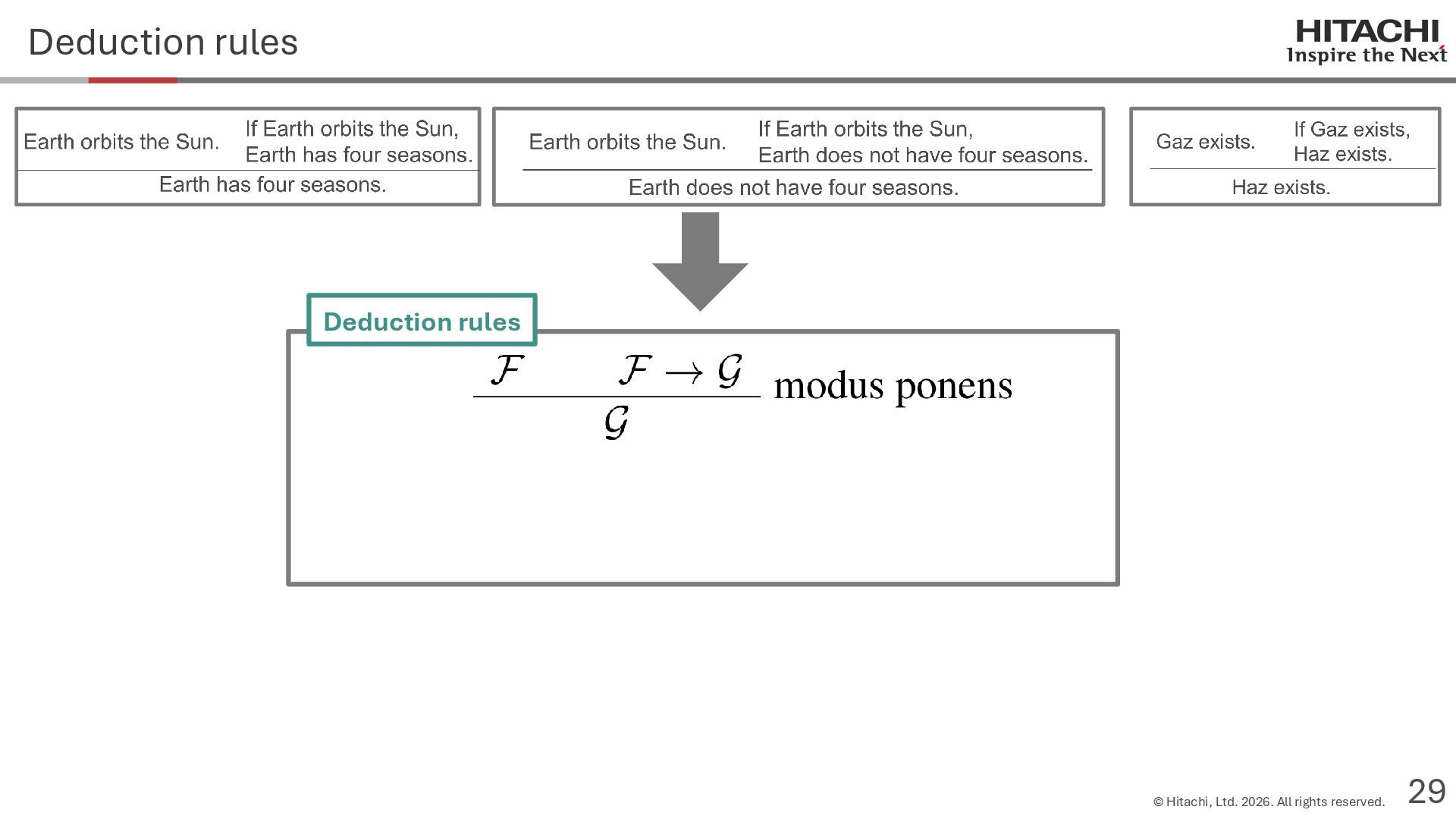{kind=link}
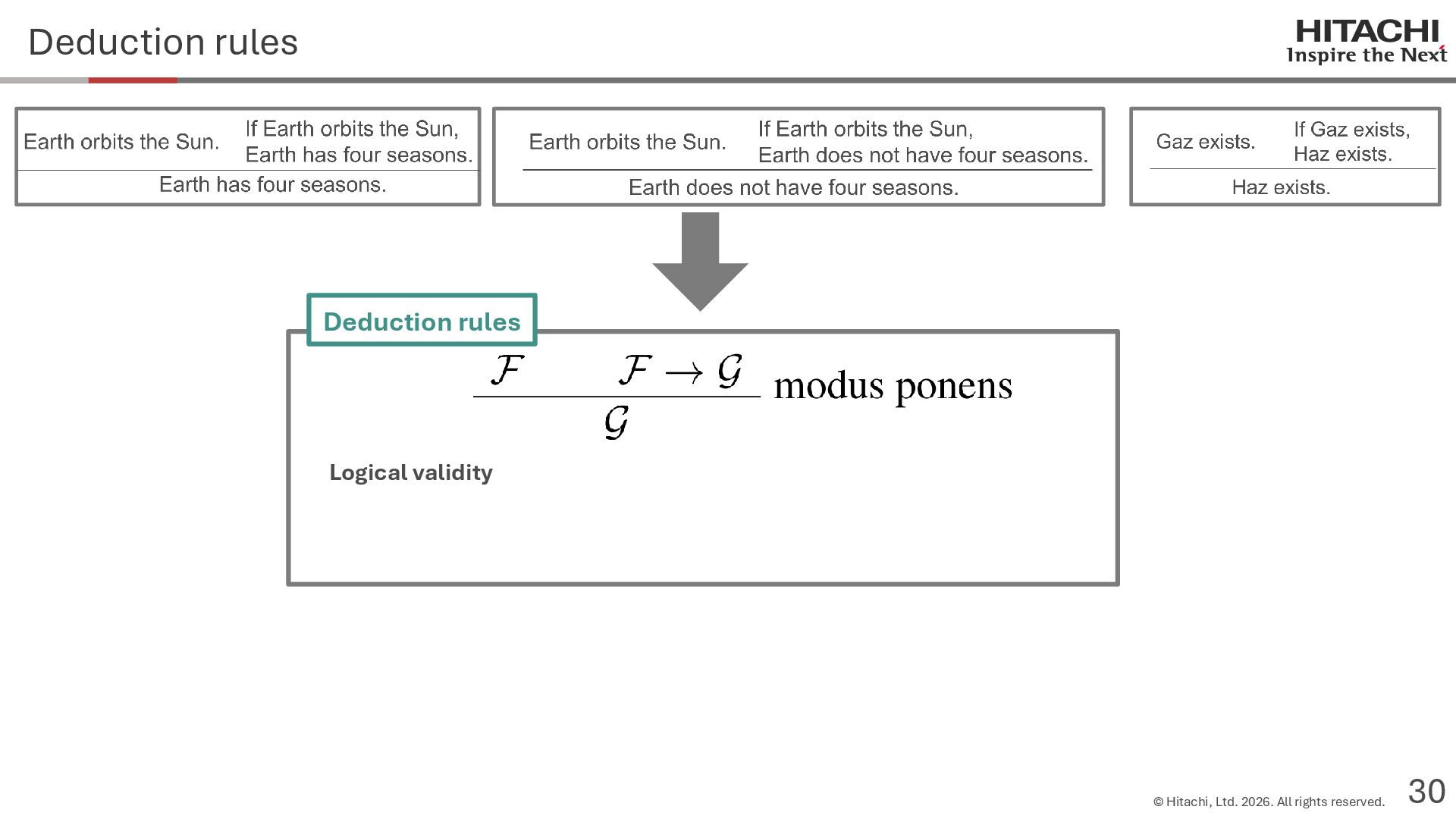{kind=link}
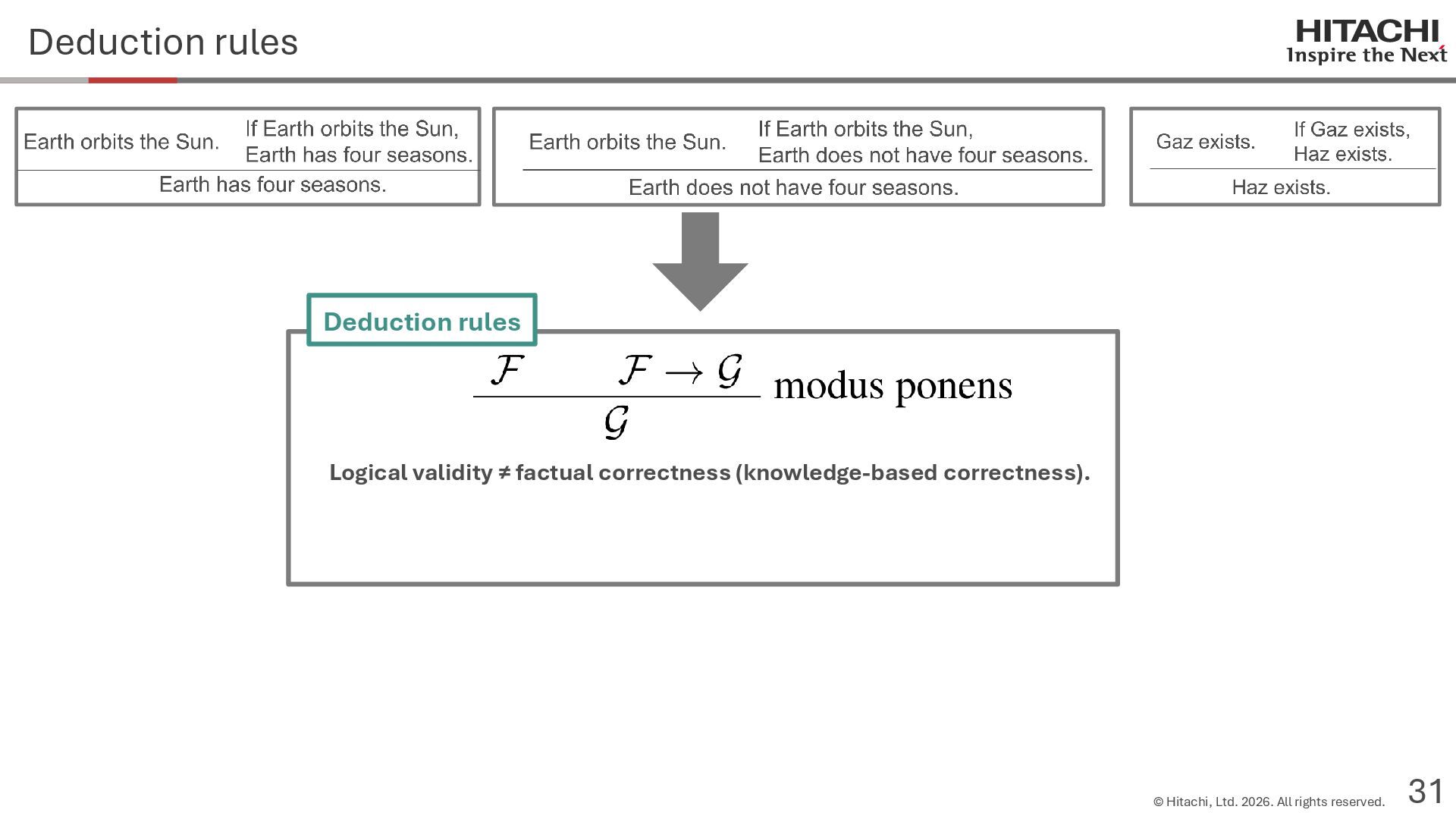{kind=link}
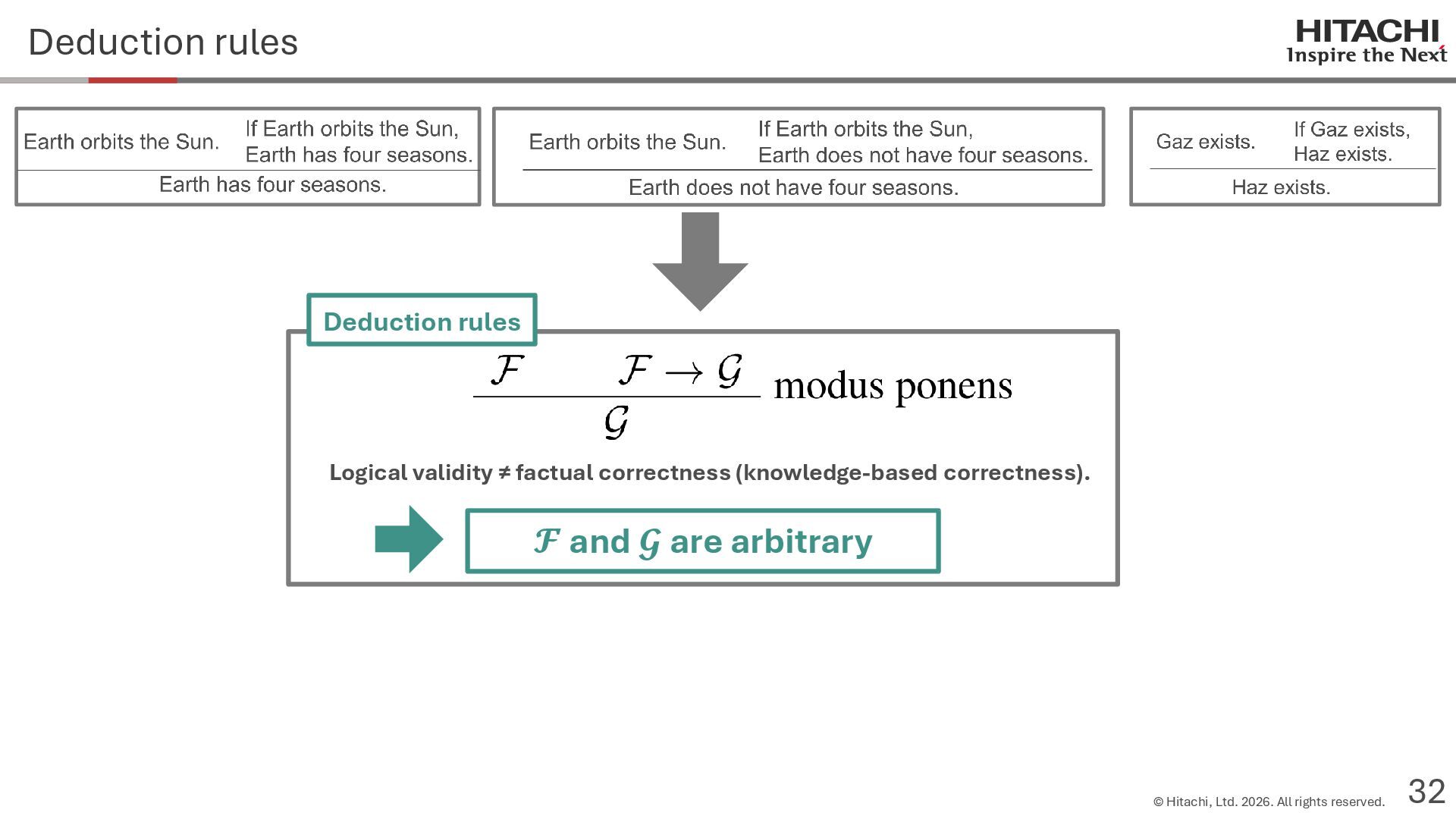{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
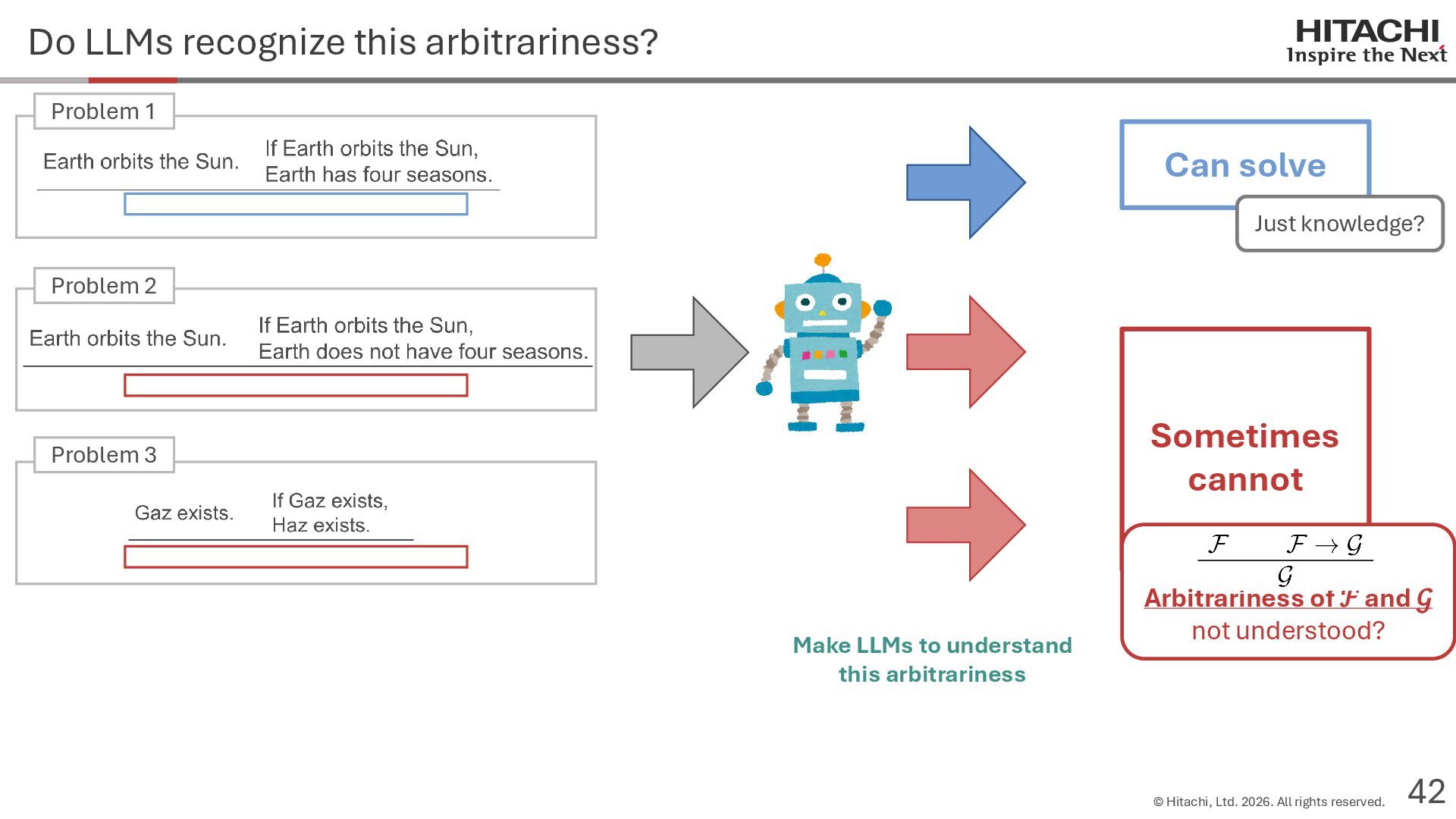{kind=link}
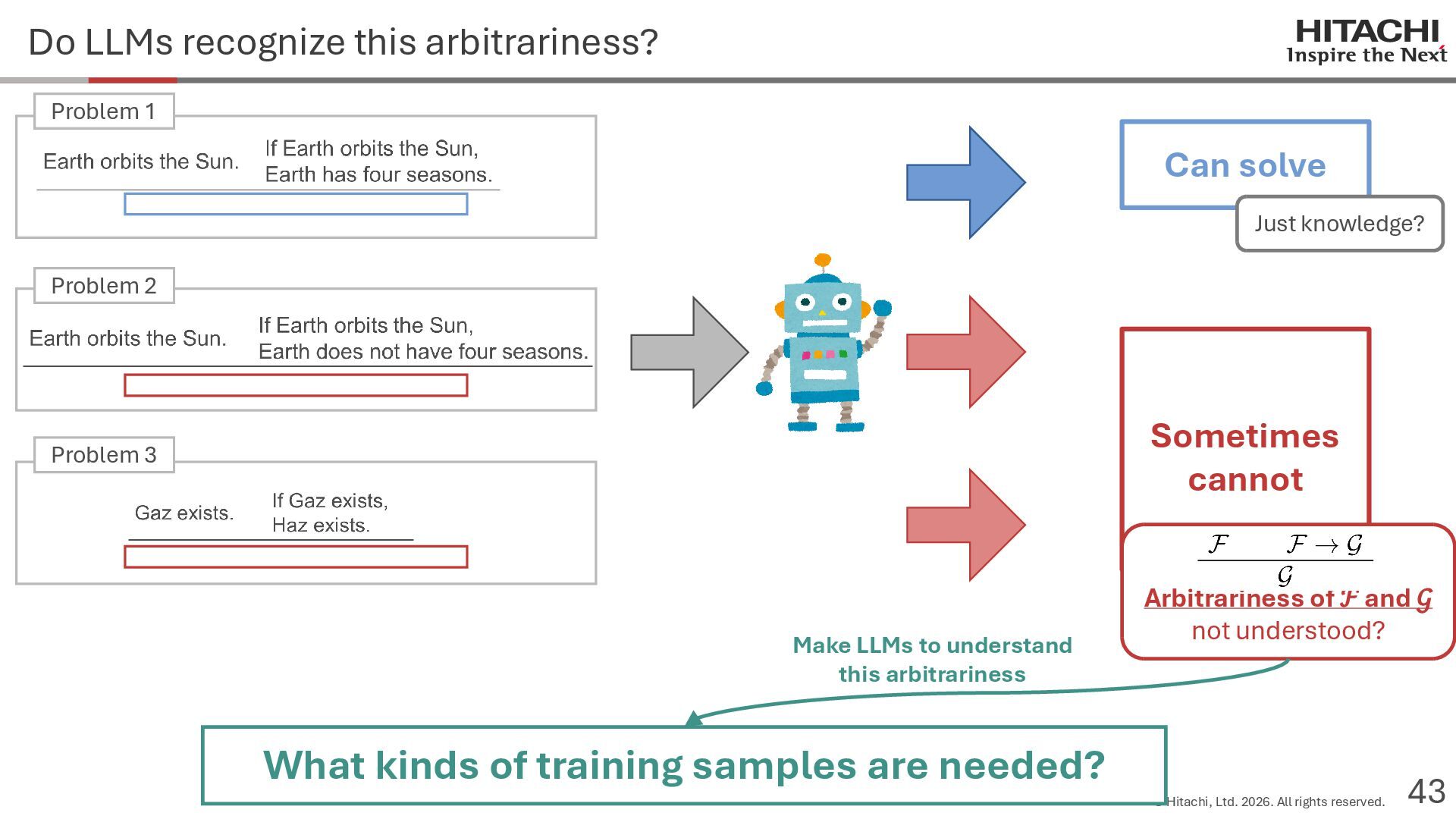{kind=link}
{kind=link}
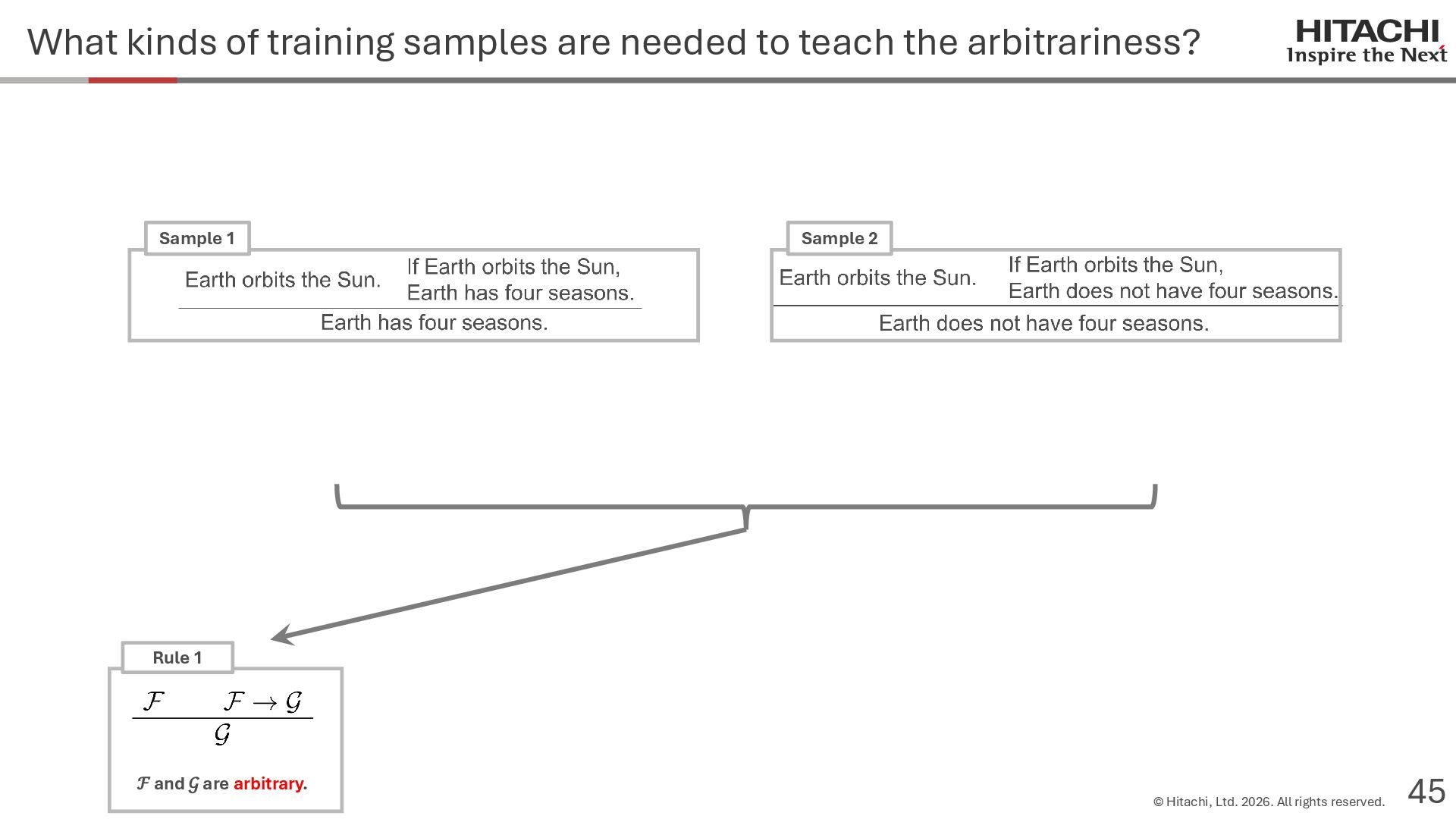{kind=link}
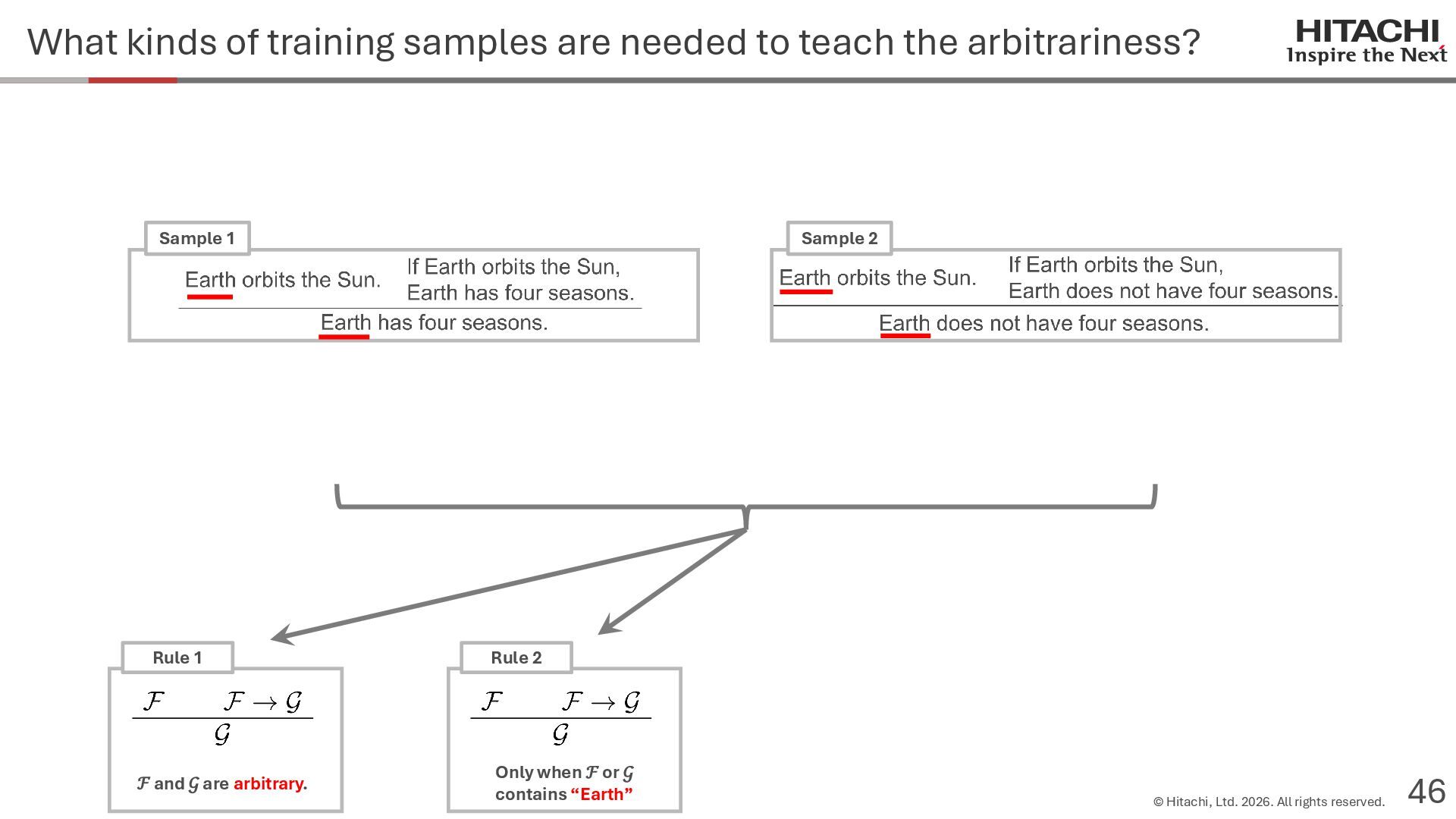{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
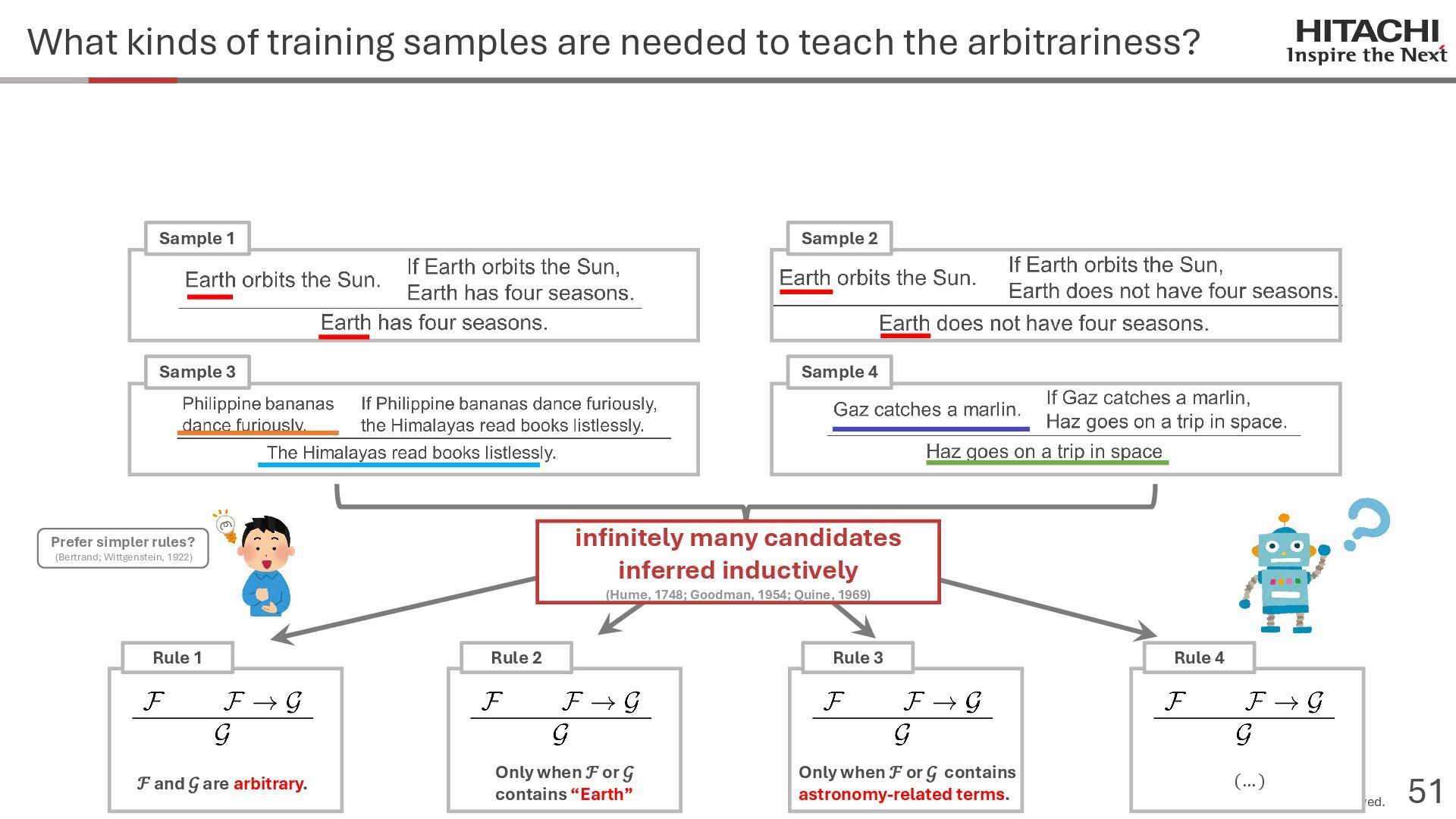{kind=link}
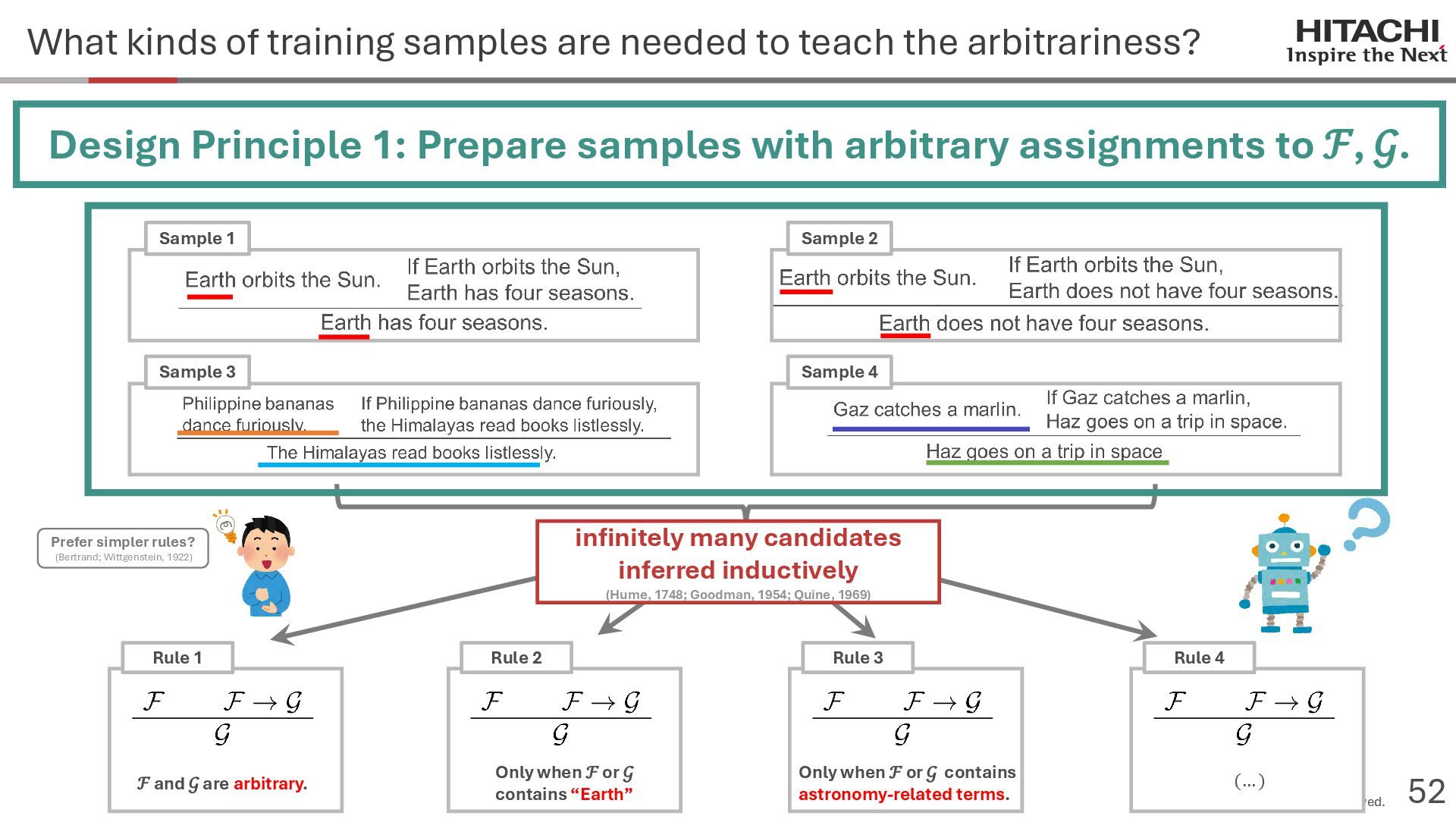{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
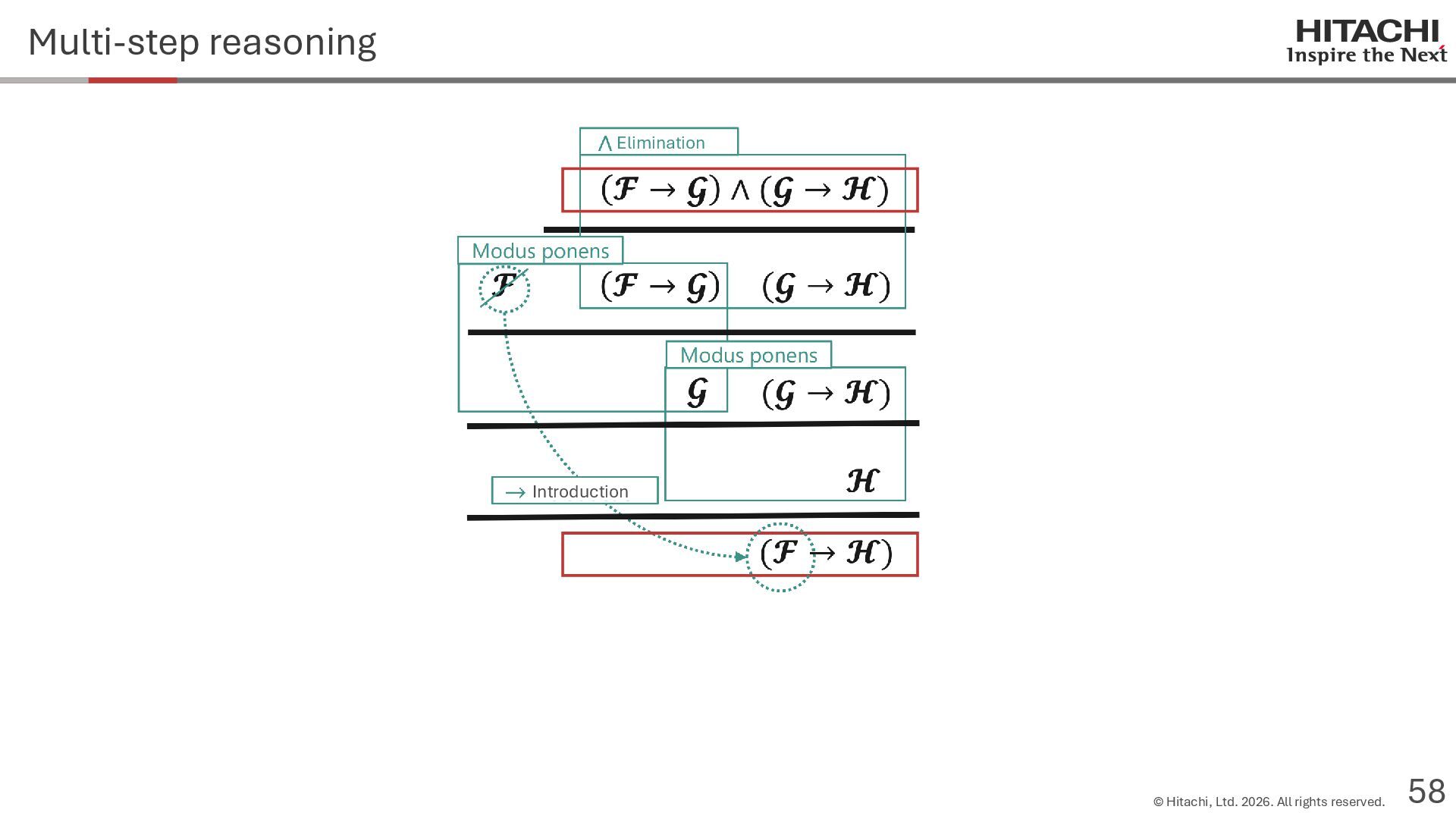{kind=link}
{kind=link}
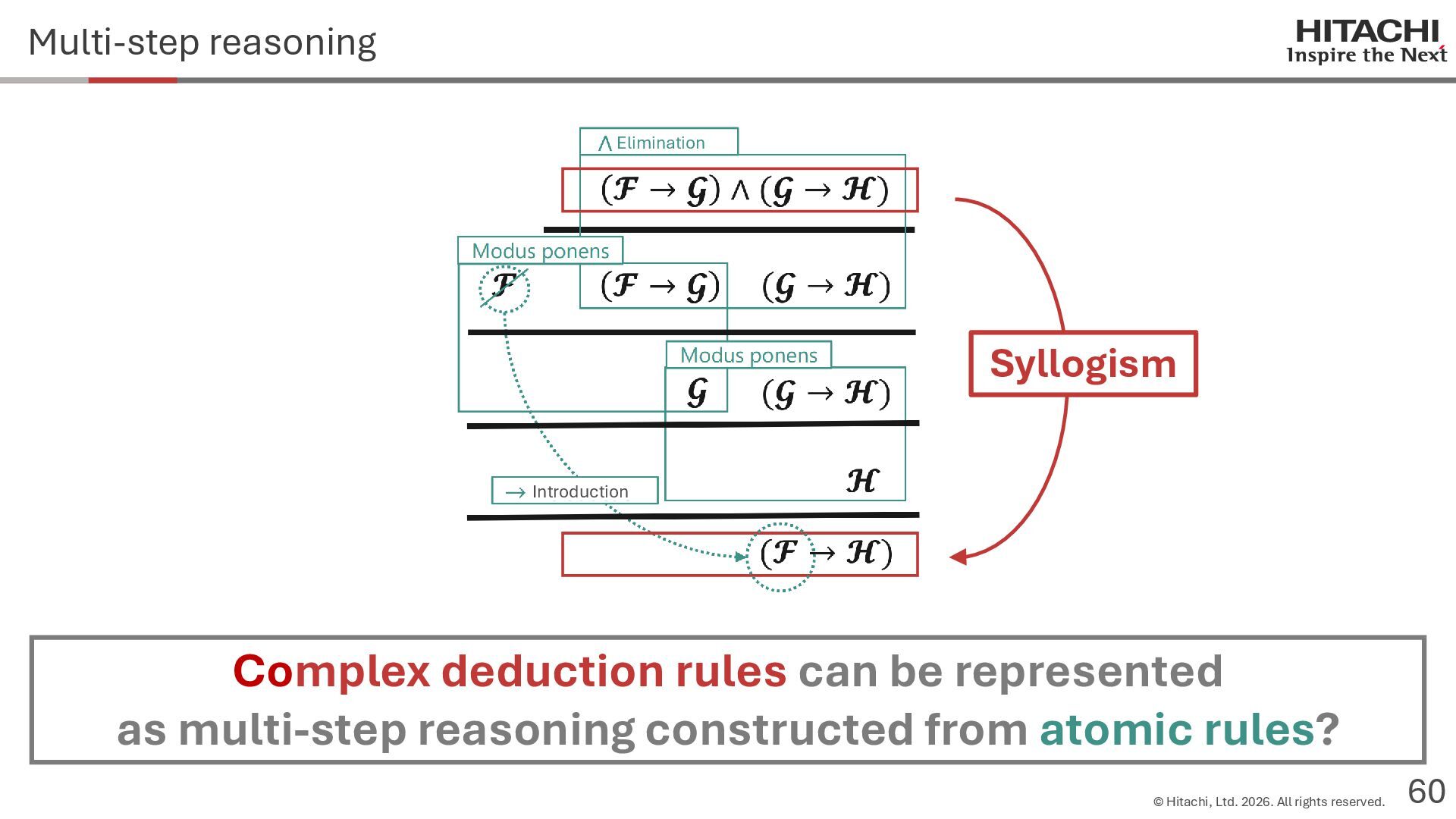{kind=link}
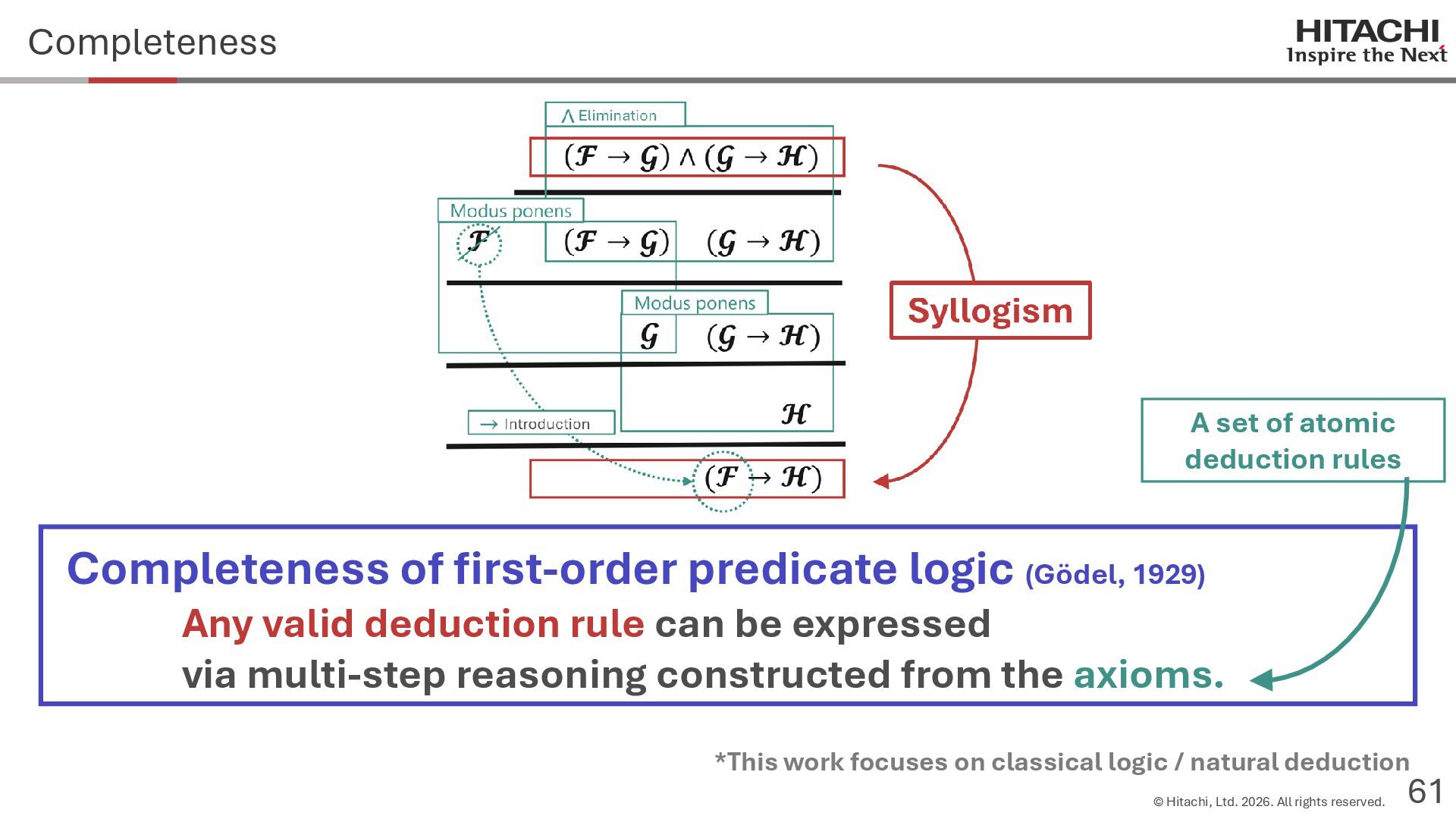{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
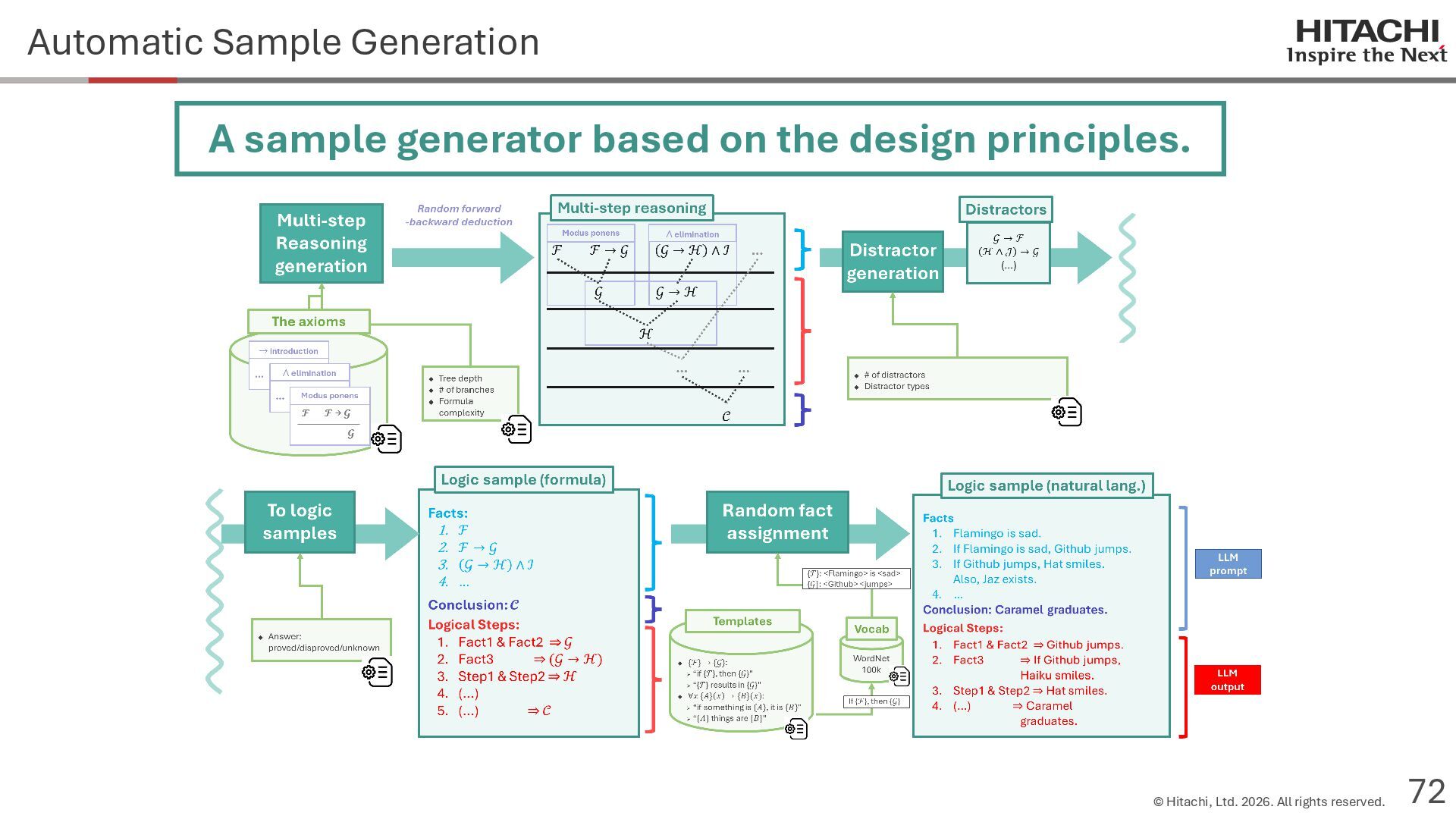{kind=link}
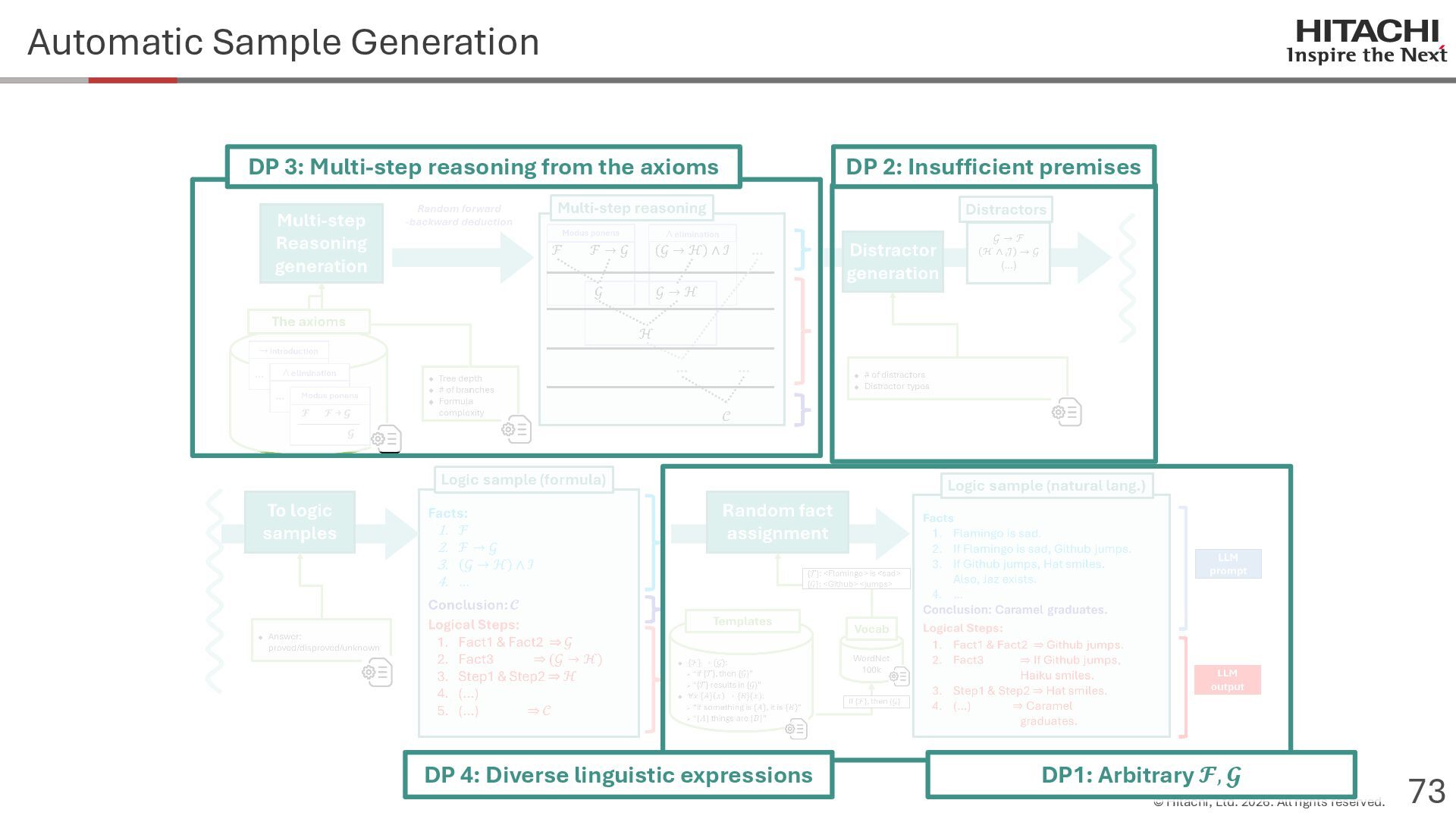{kind=link}
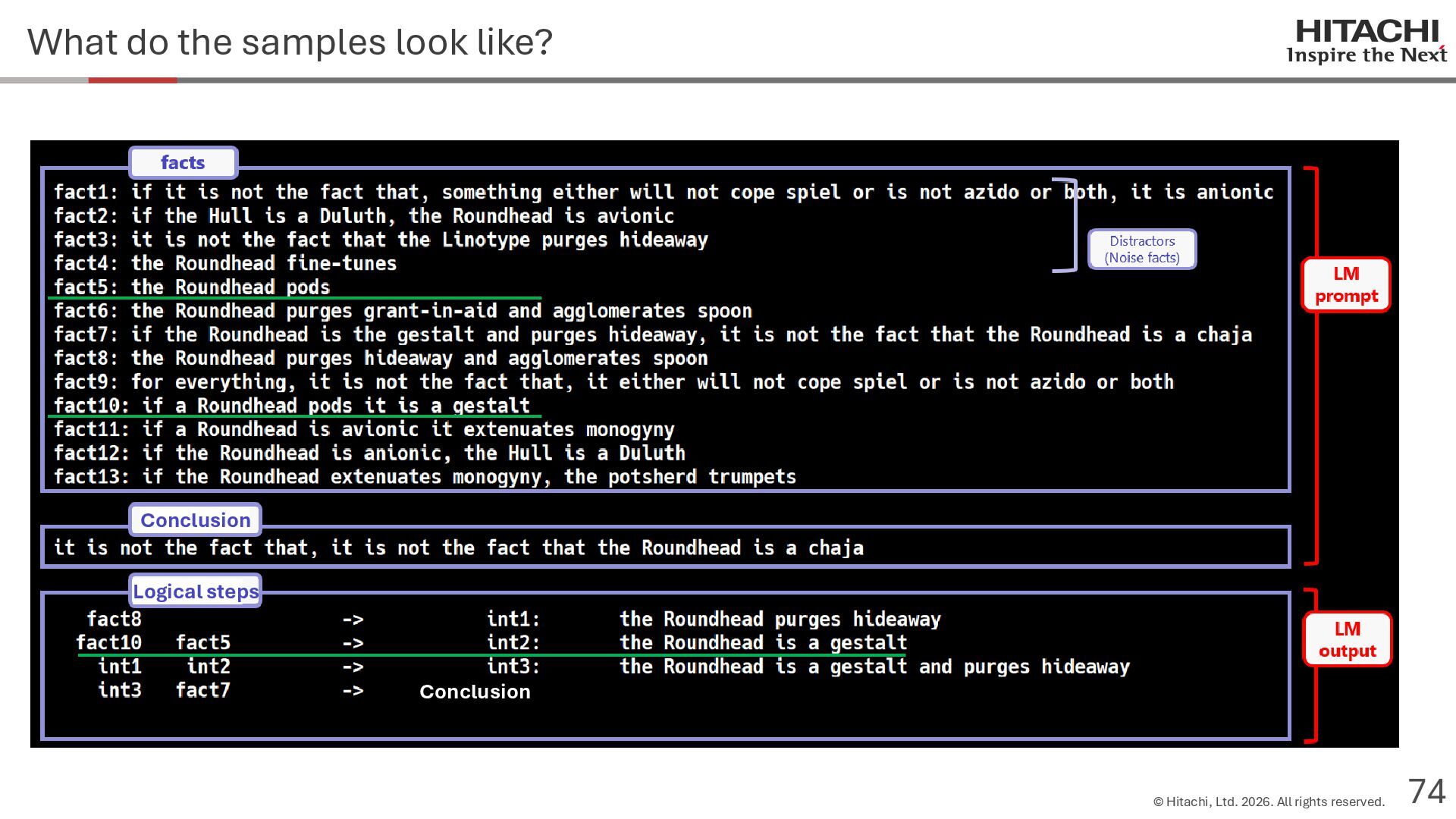{kind=link}
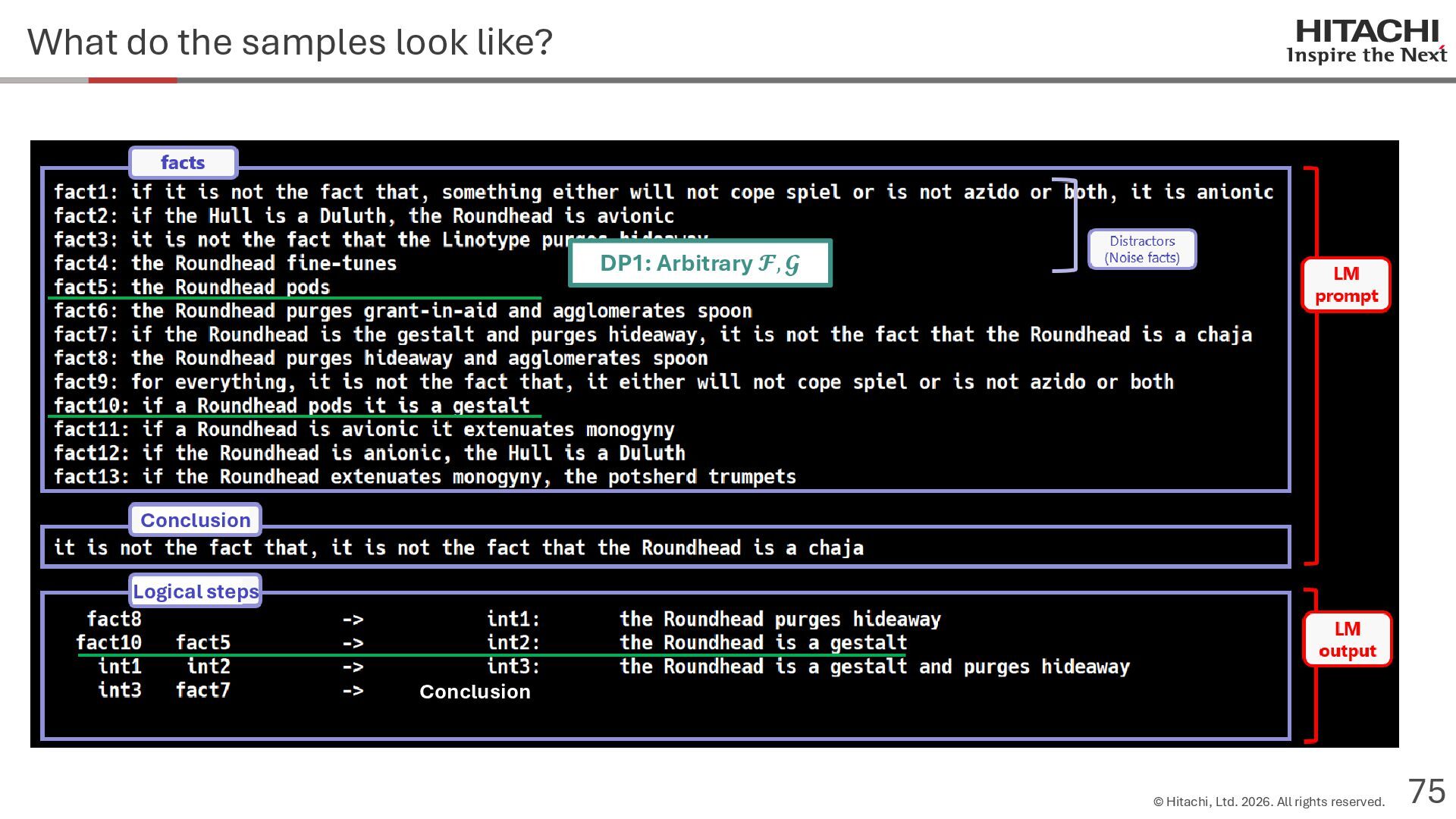{kind=link}
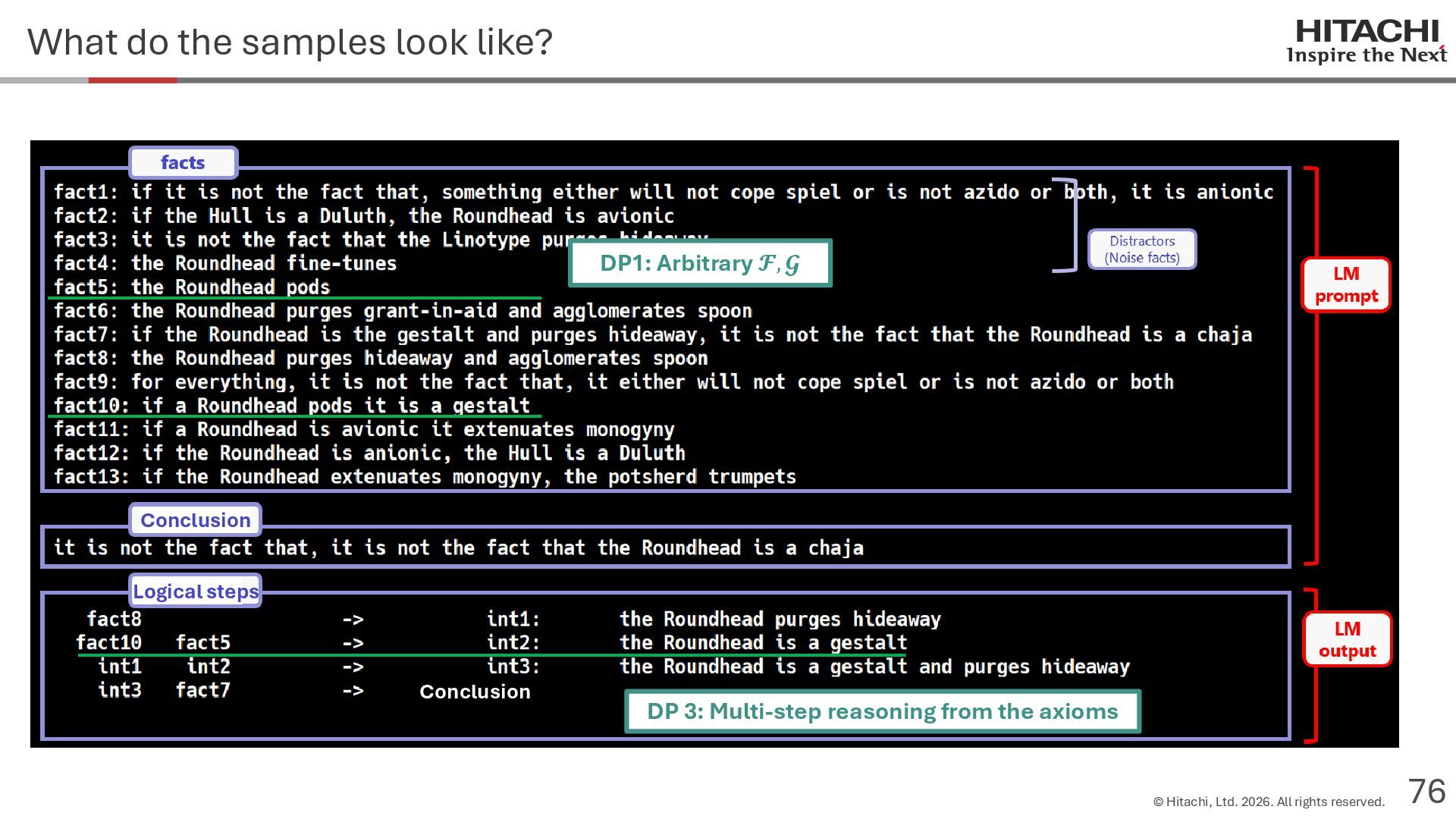{kind=link}
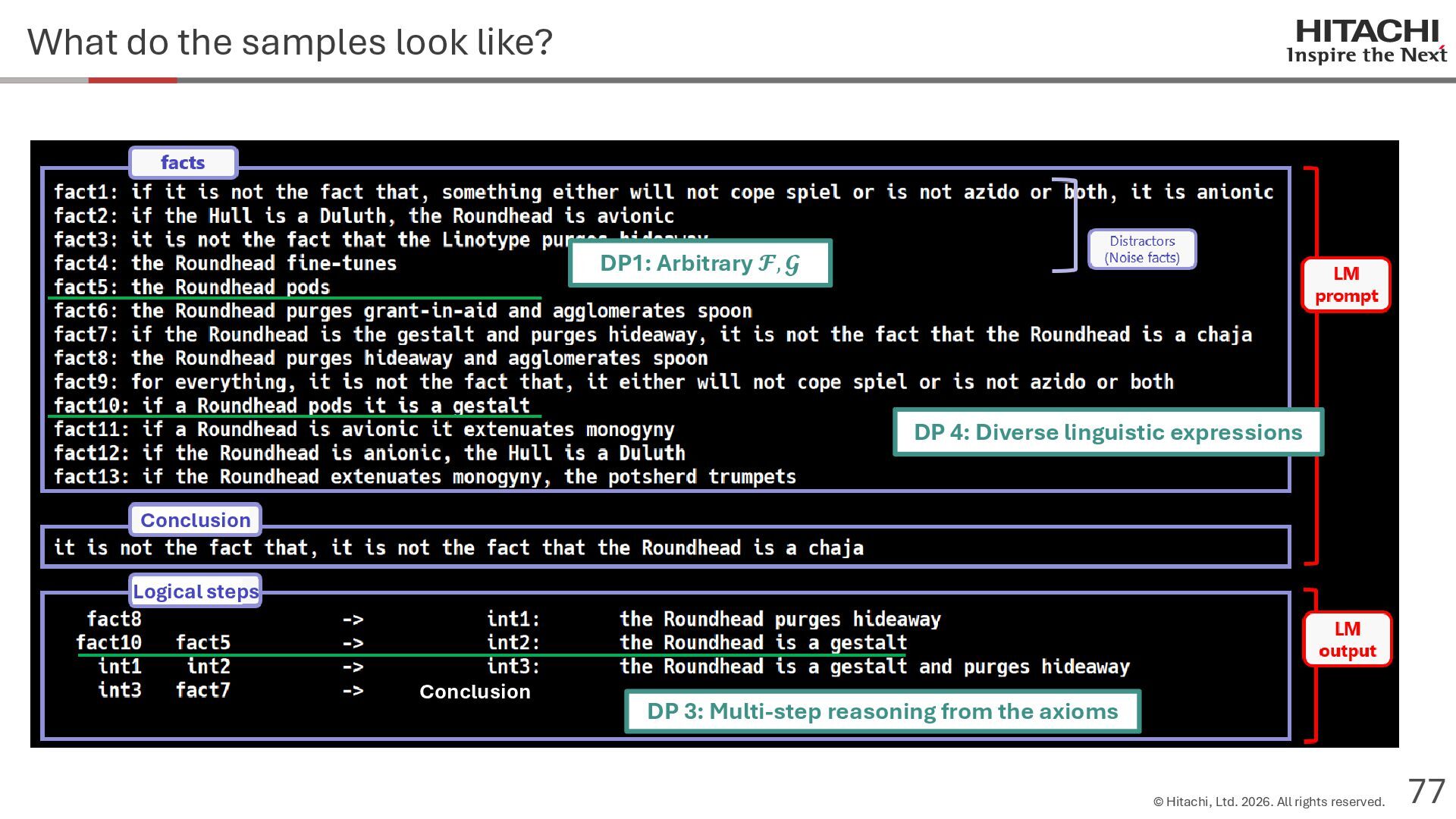{kind=link}
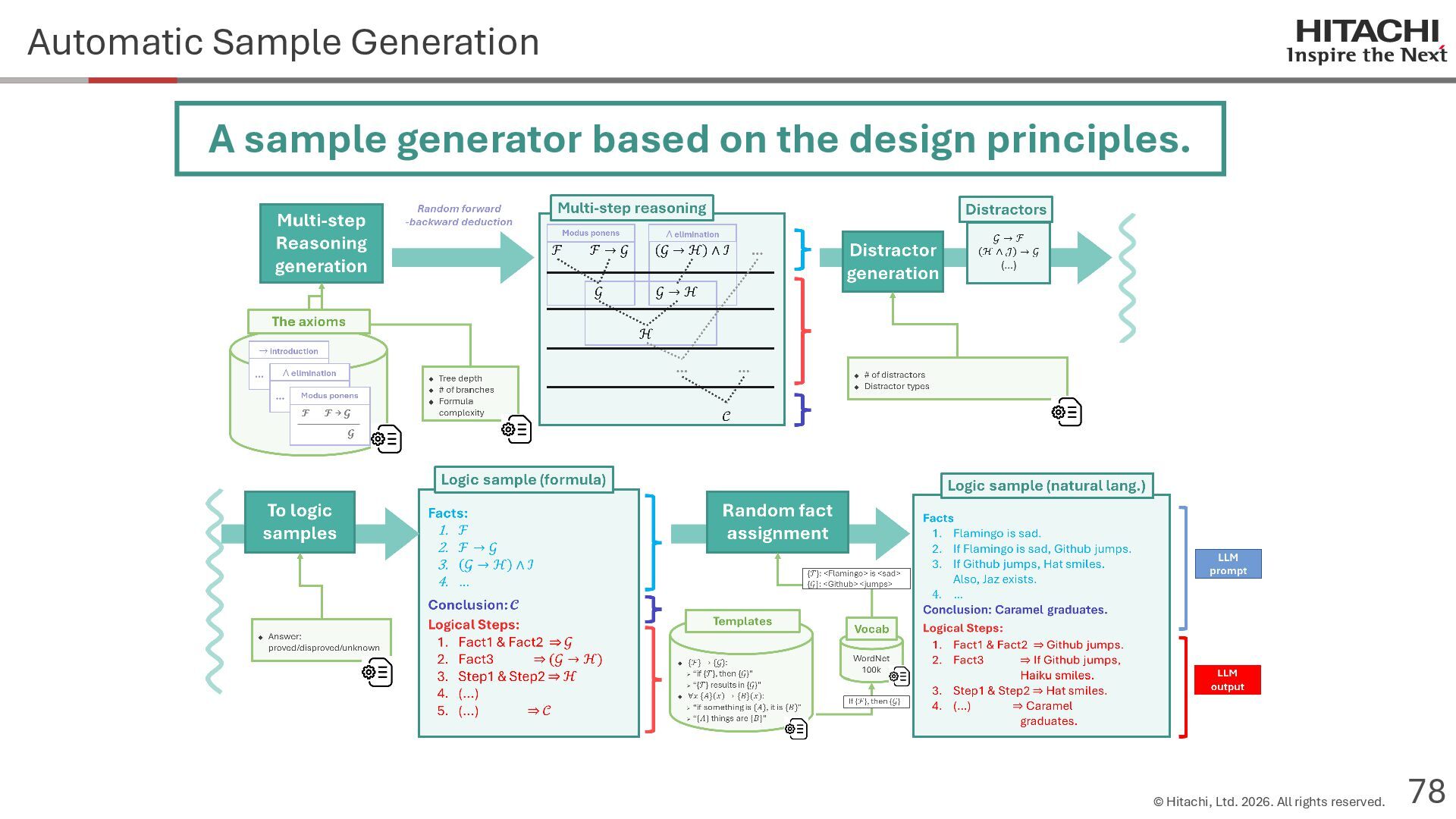{kind=link}
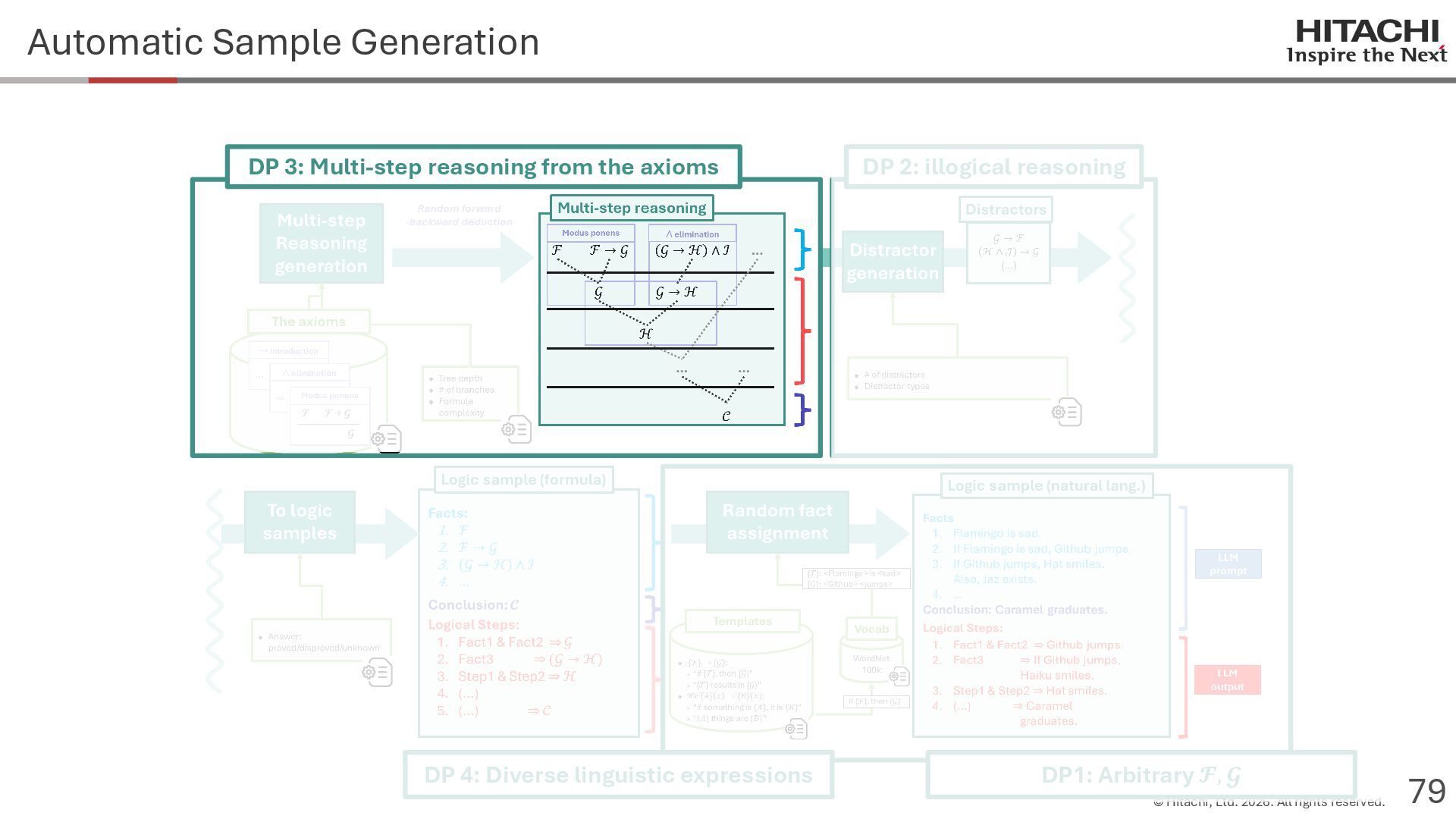{kind=link}
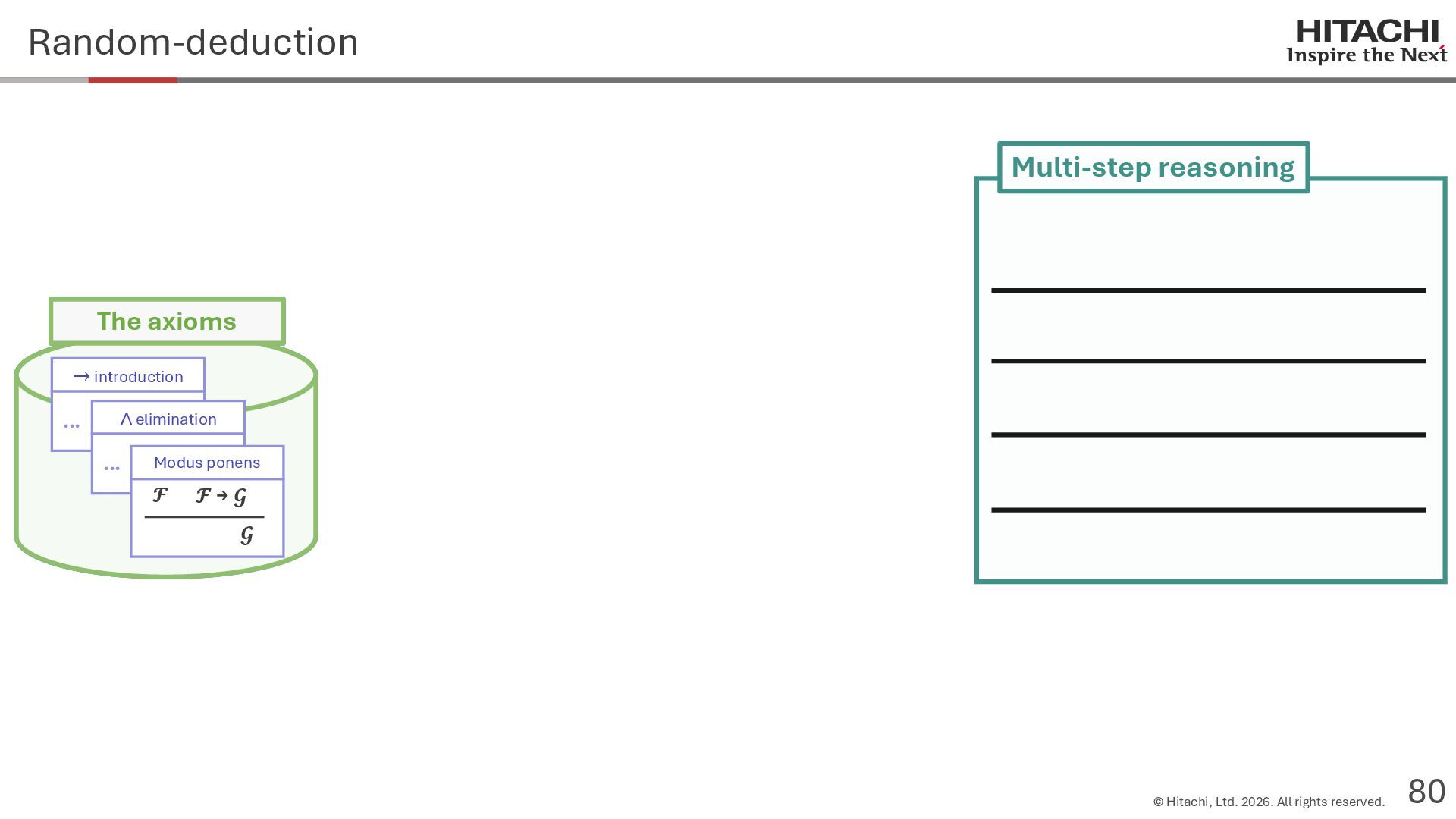{kind=link}
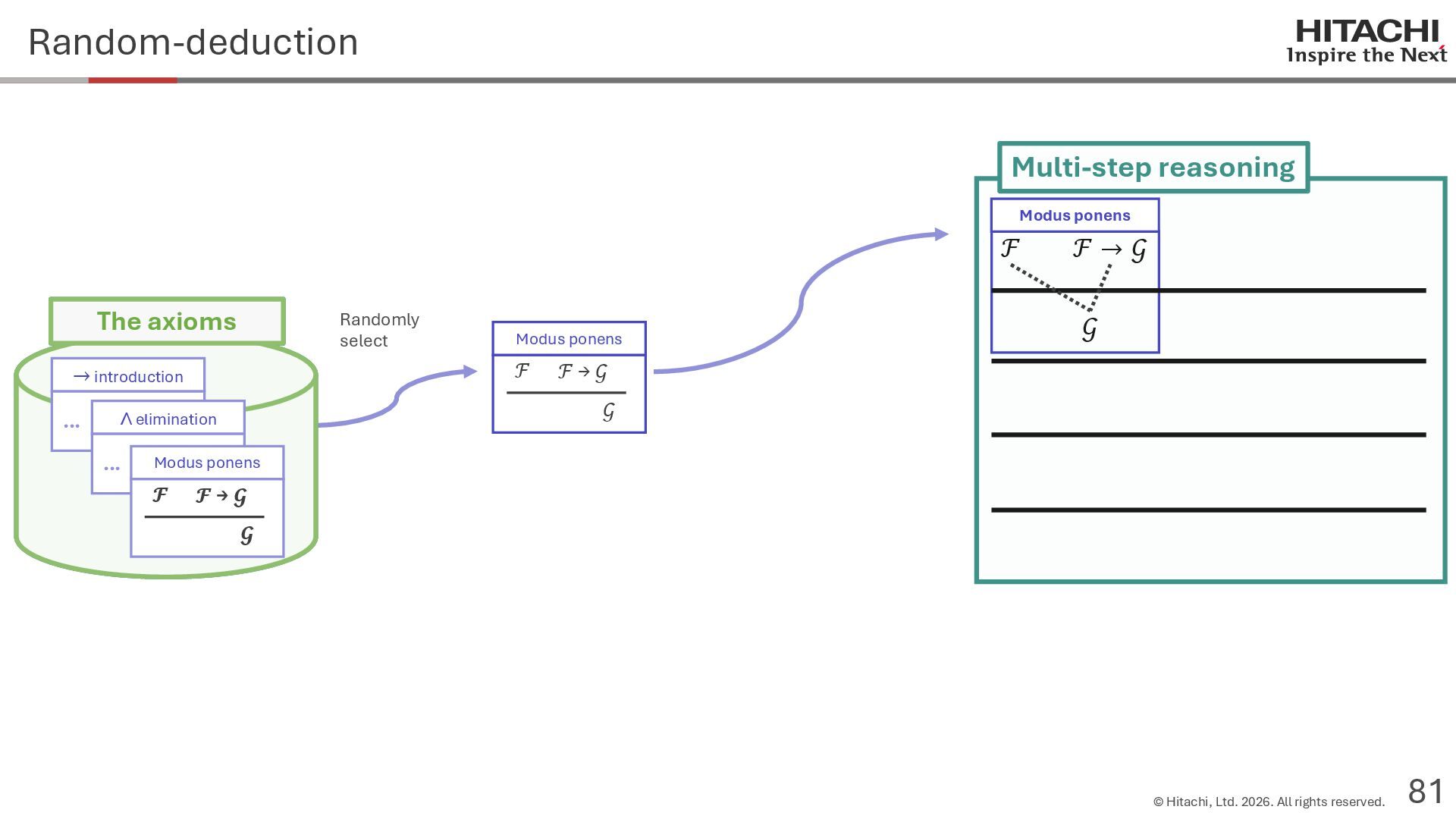{kind=link}
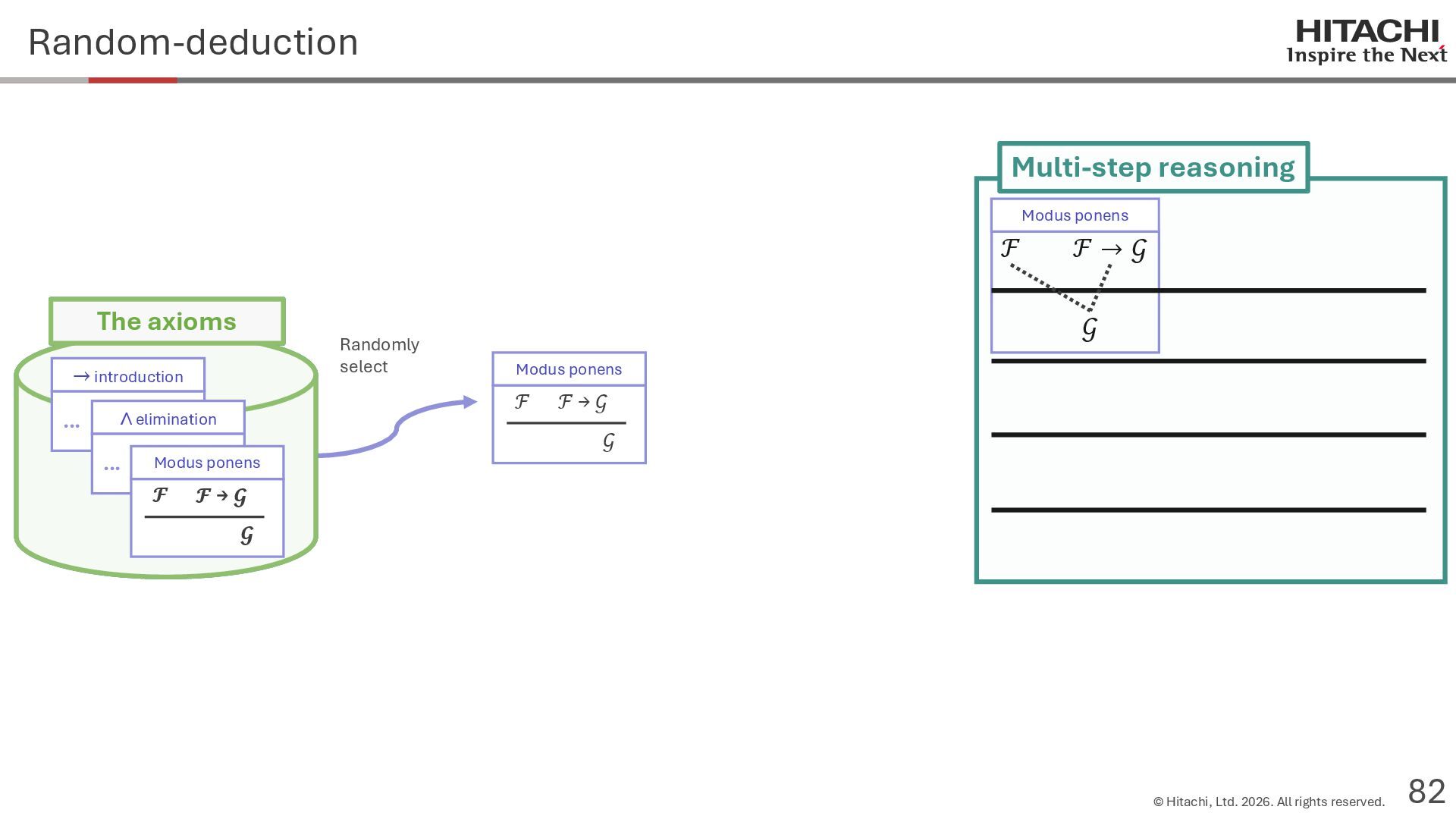{kind=link}
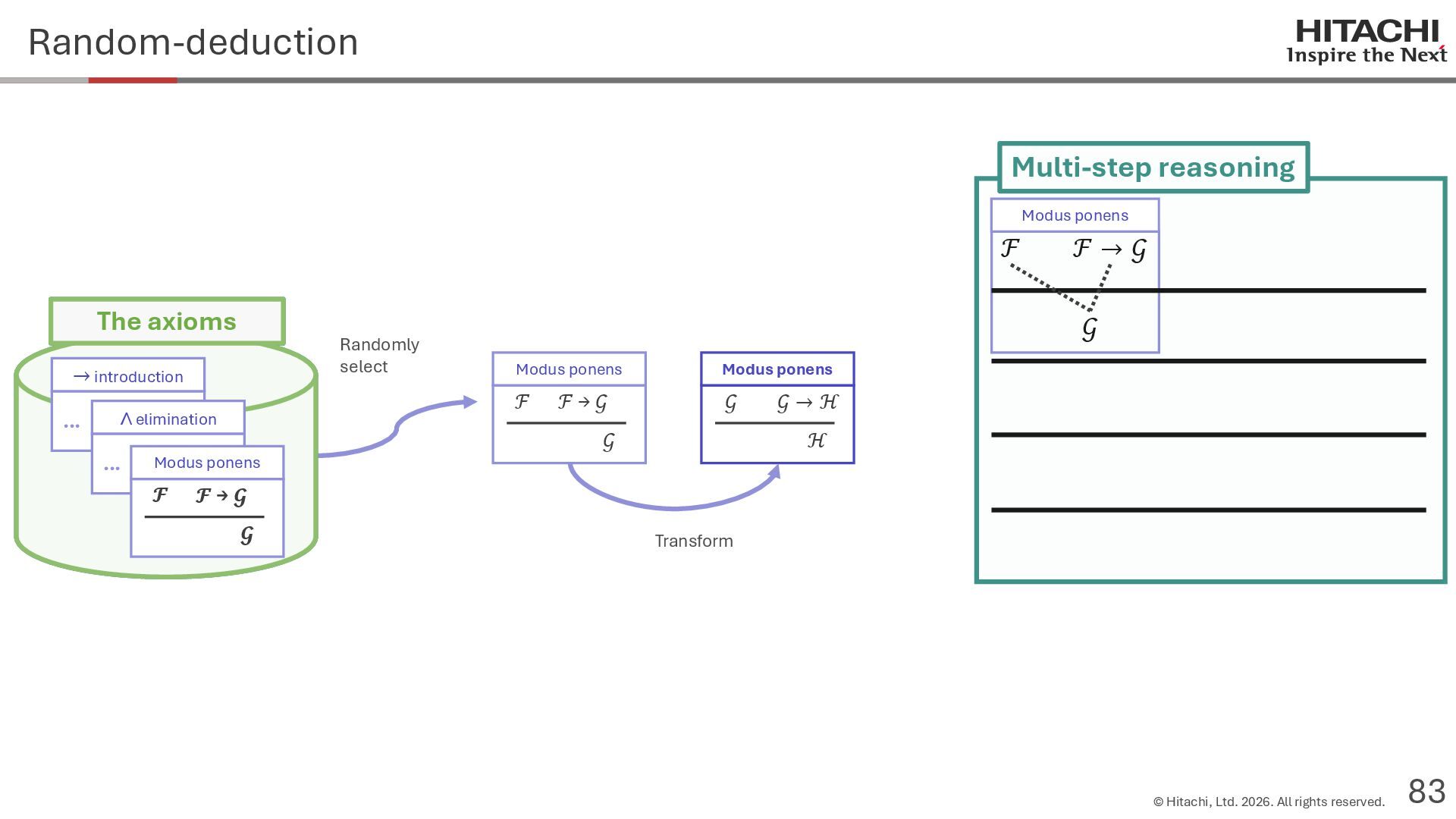{kind=link}
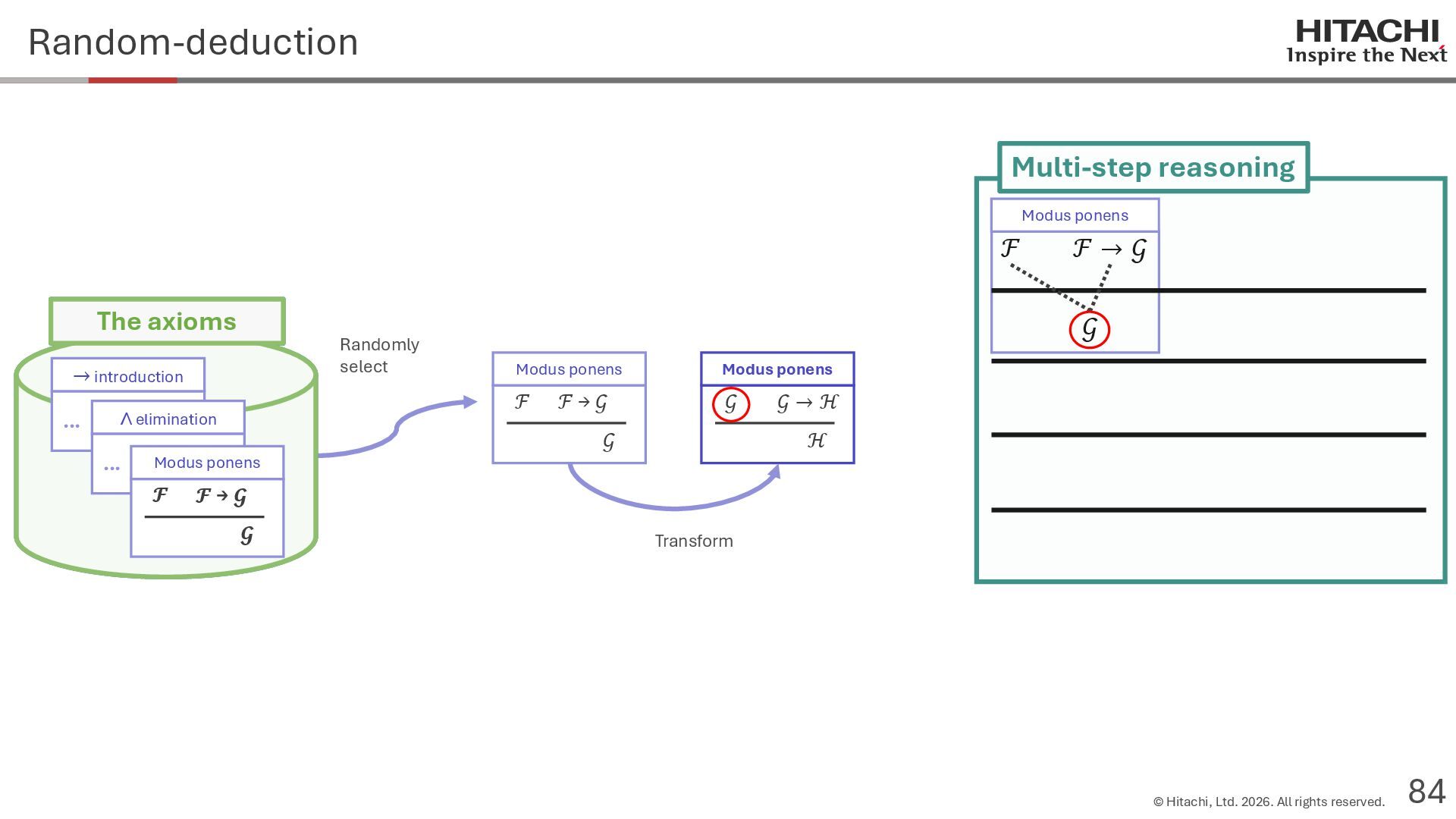{kind=link}
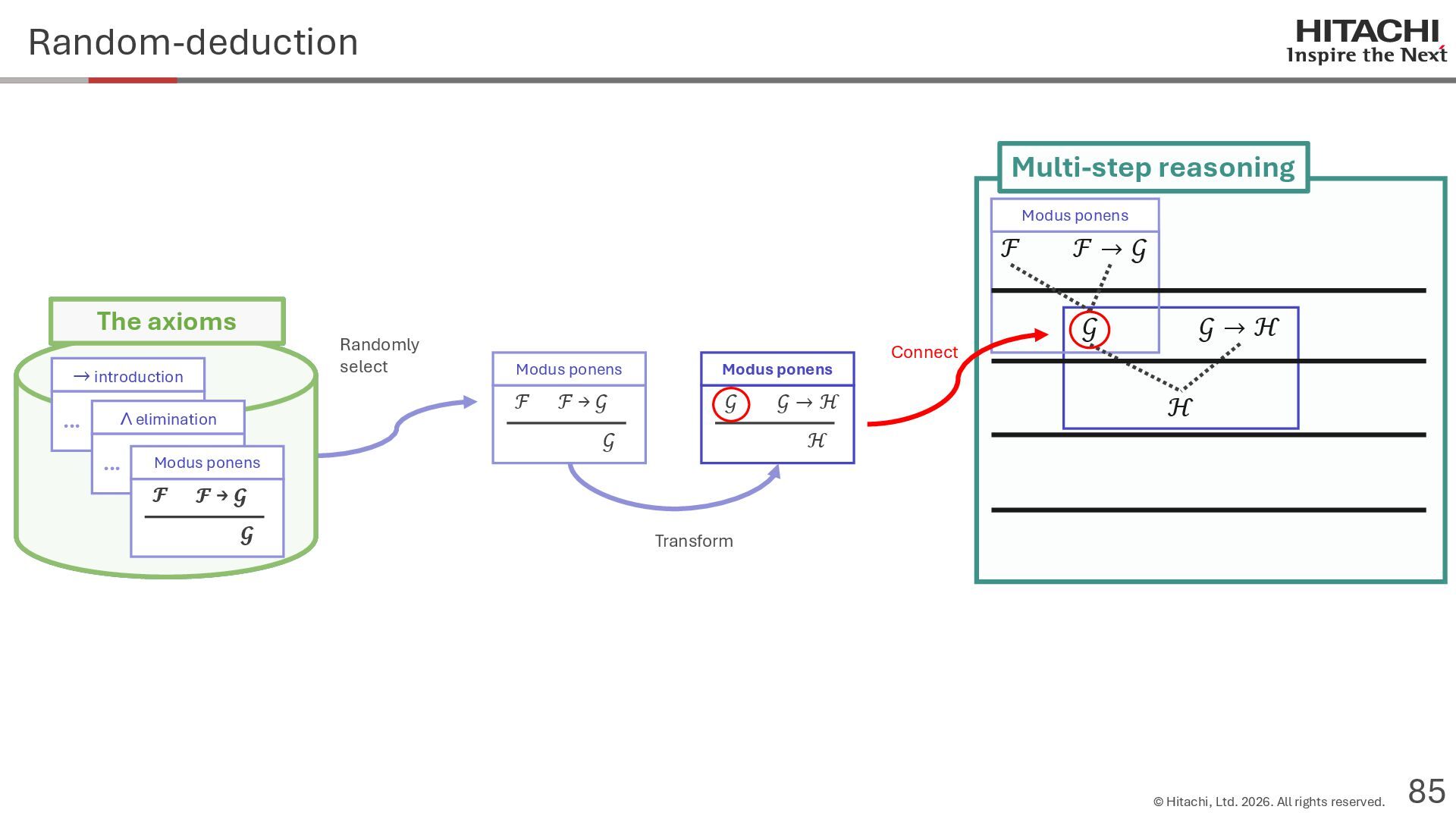{kind=link}
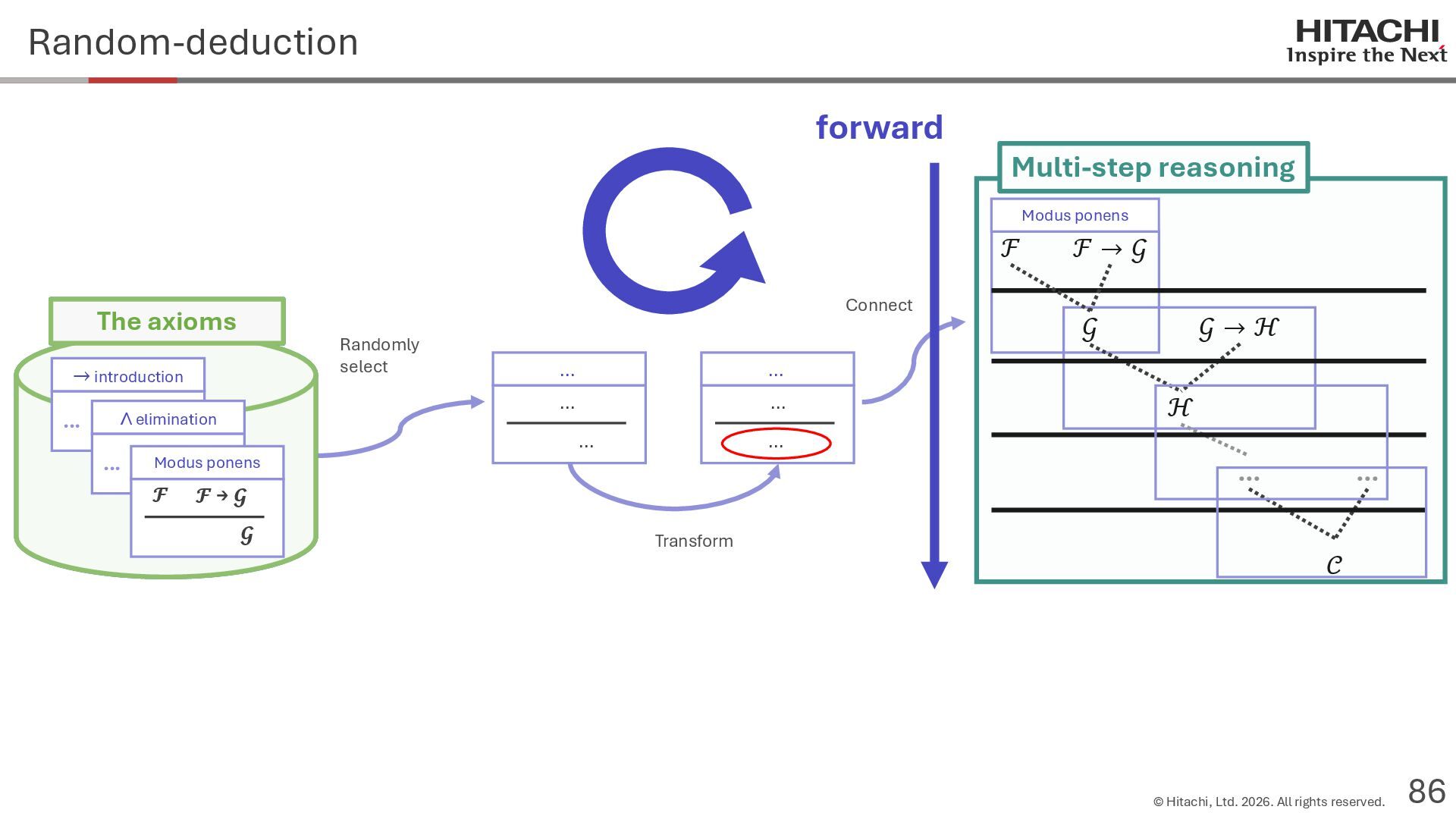{kind=link}
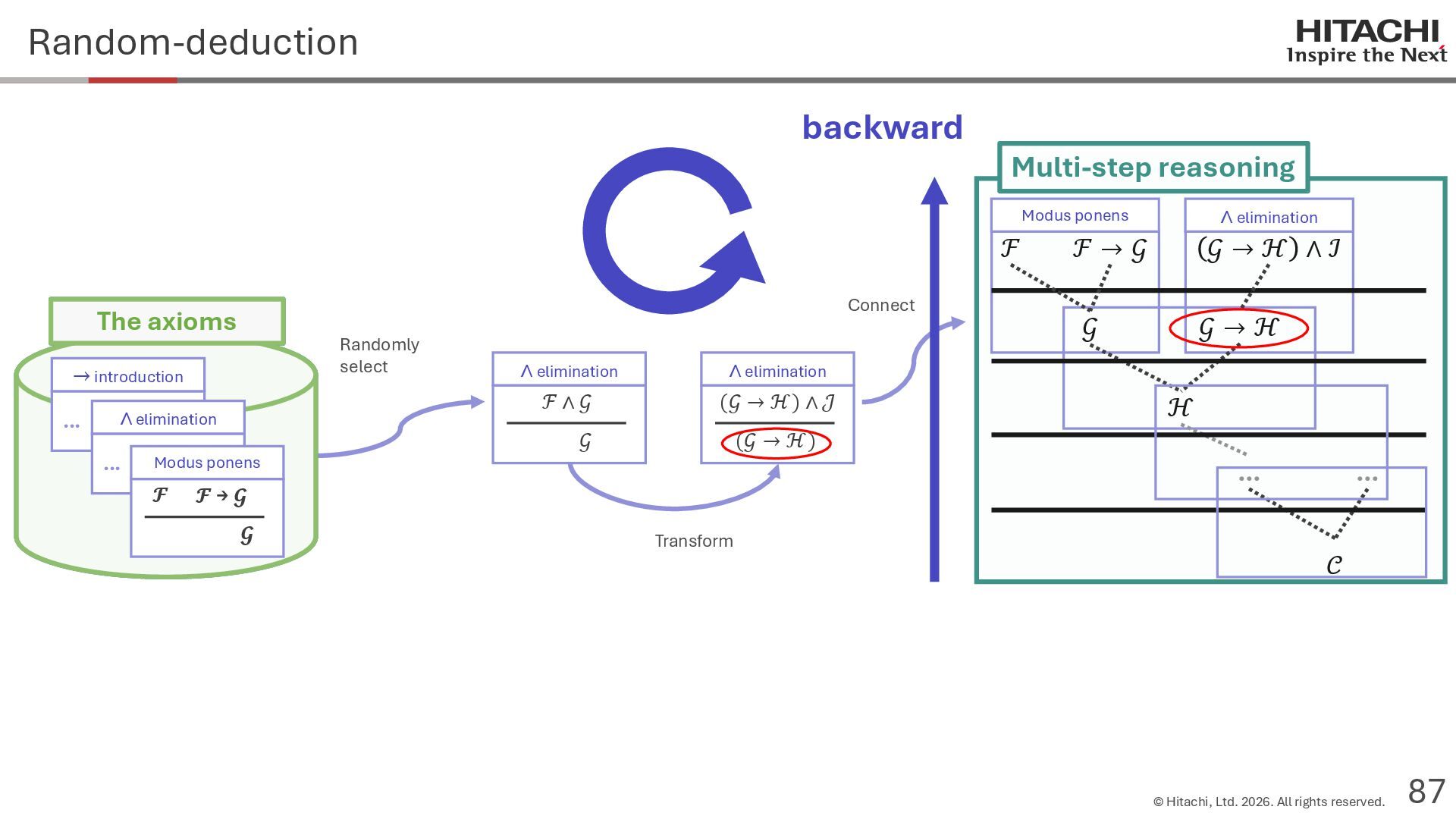{kind=link}
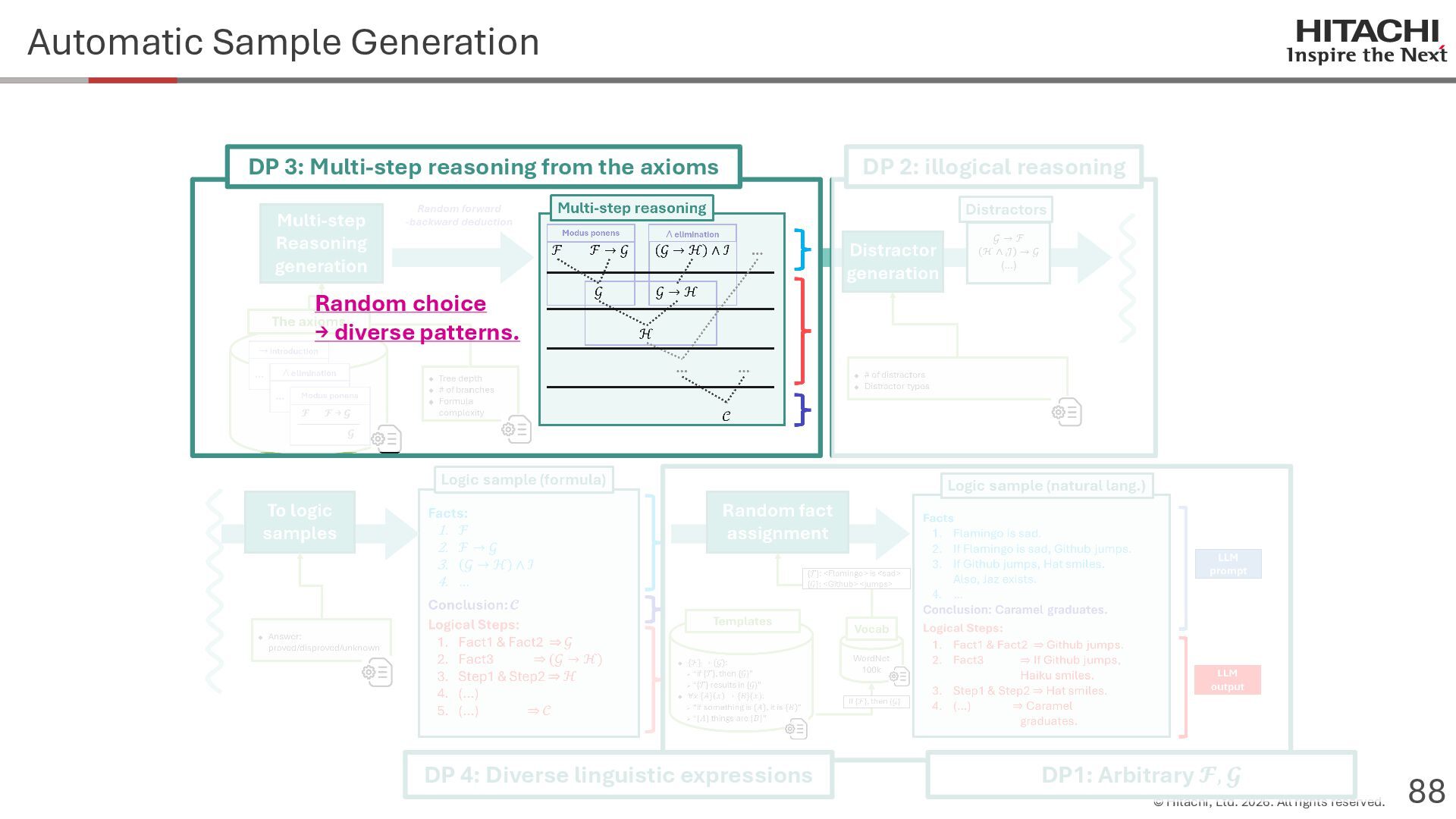{kind=link}
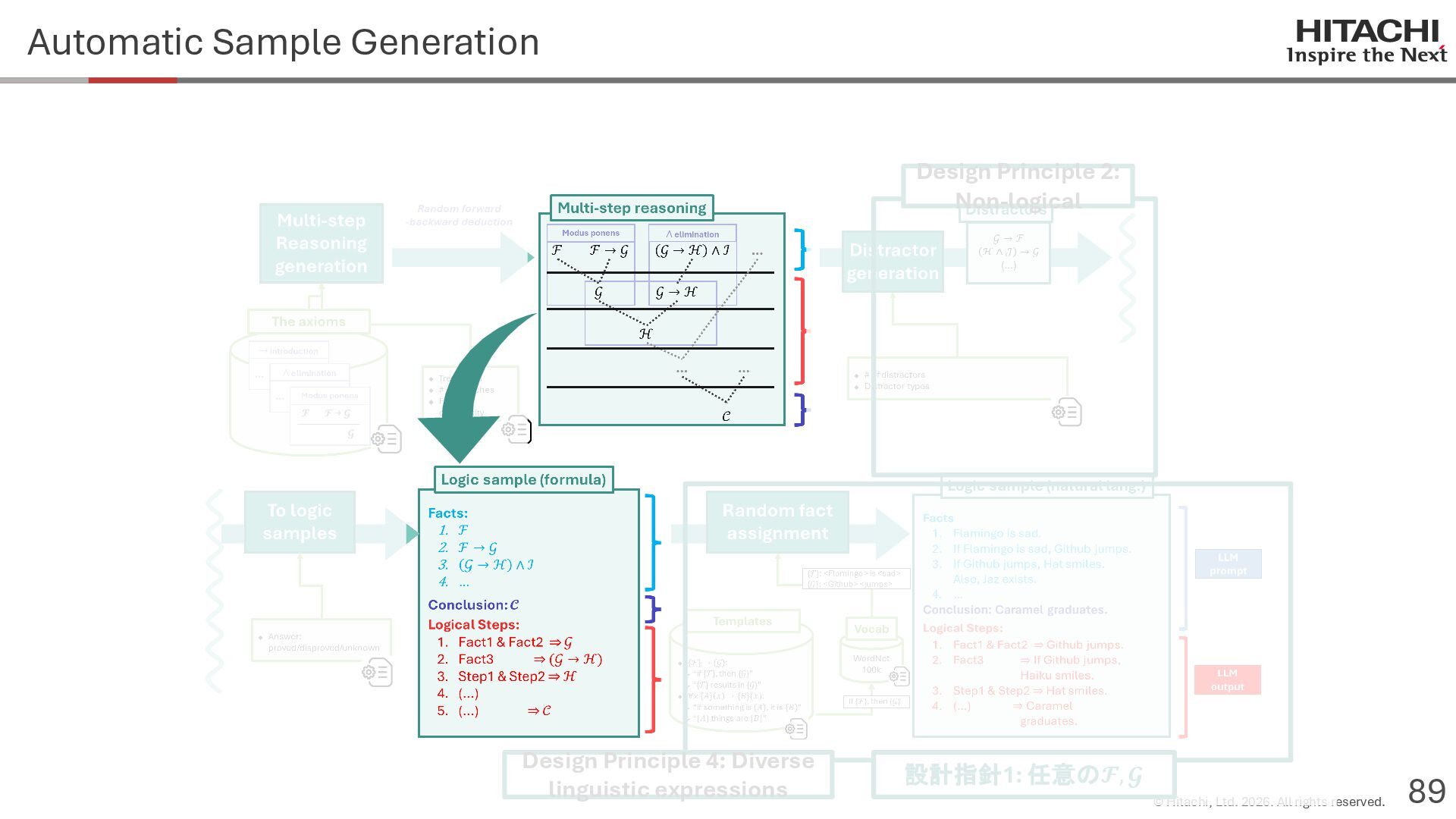{kind=link}
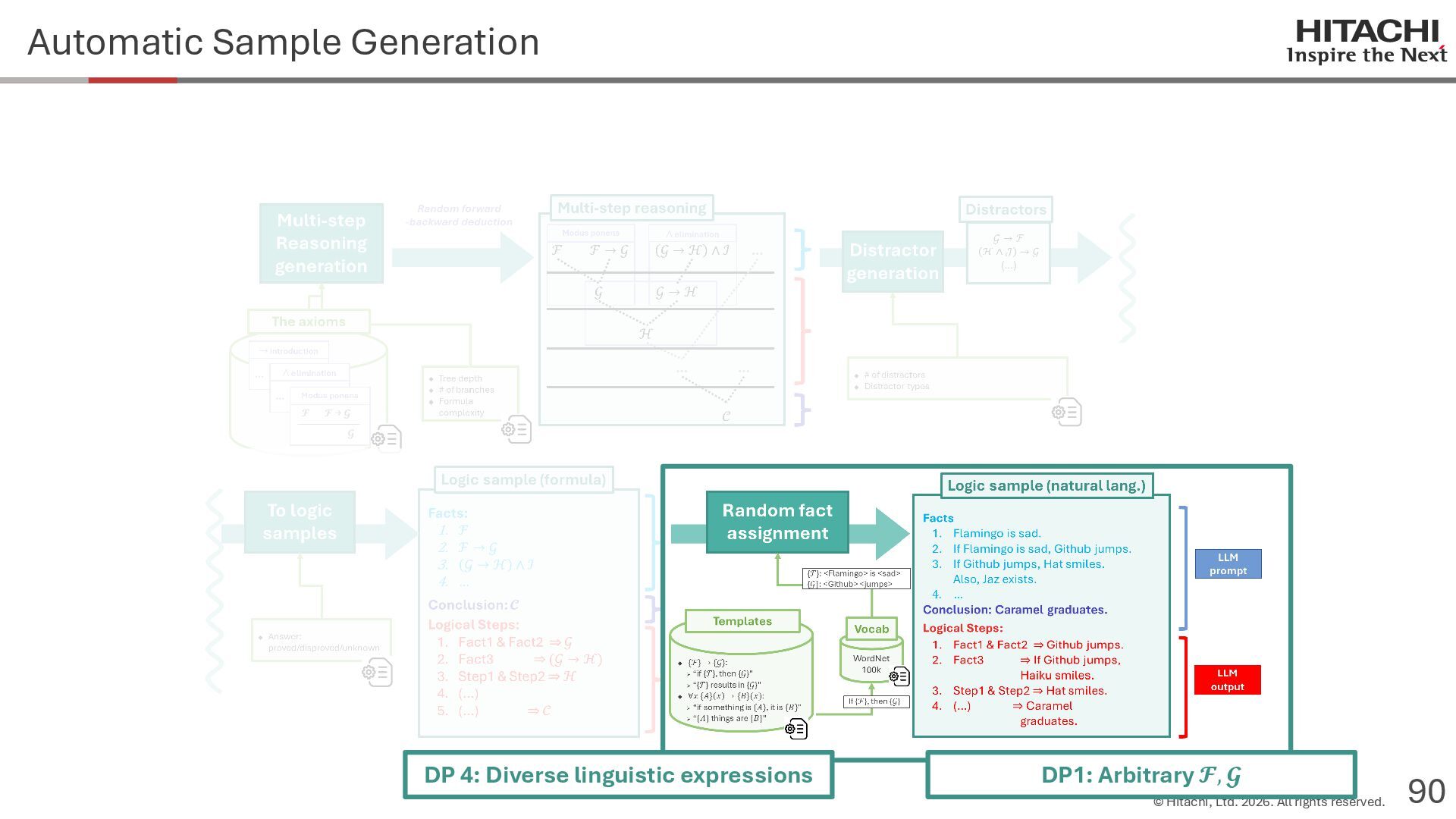{kind=link}
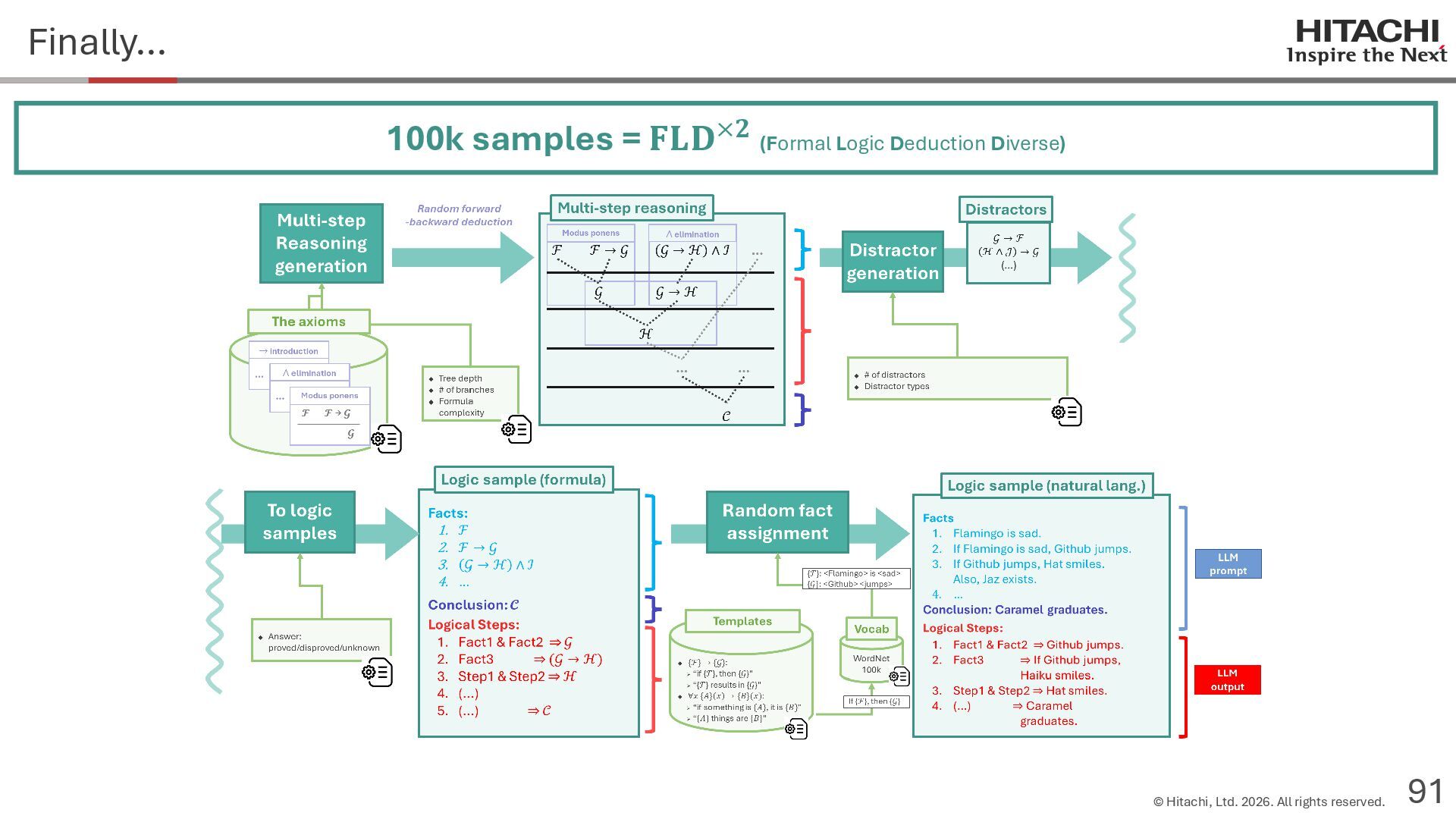{kind=link}
{kind=link}
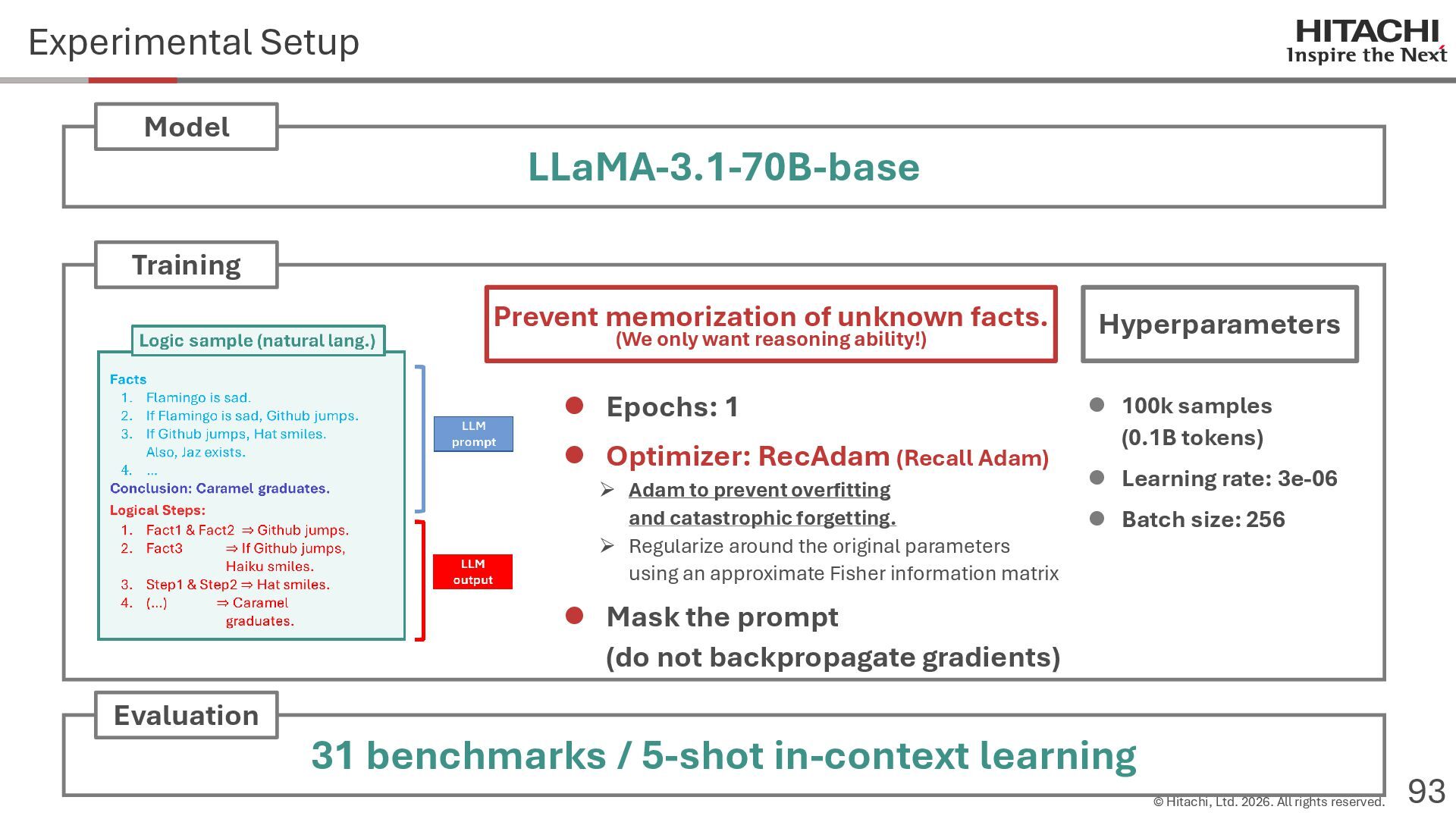{kind=link}
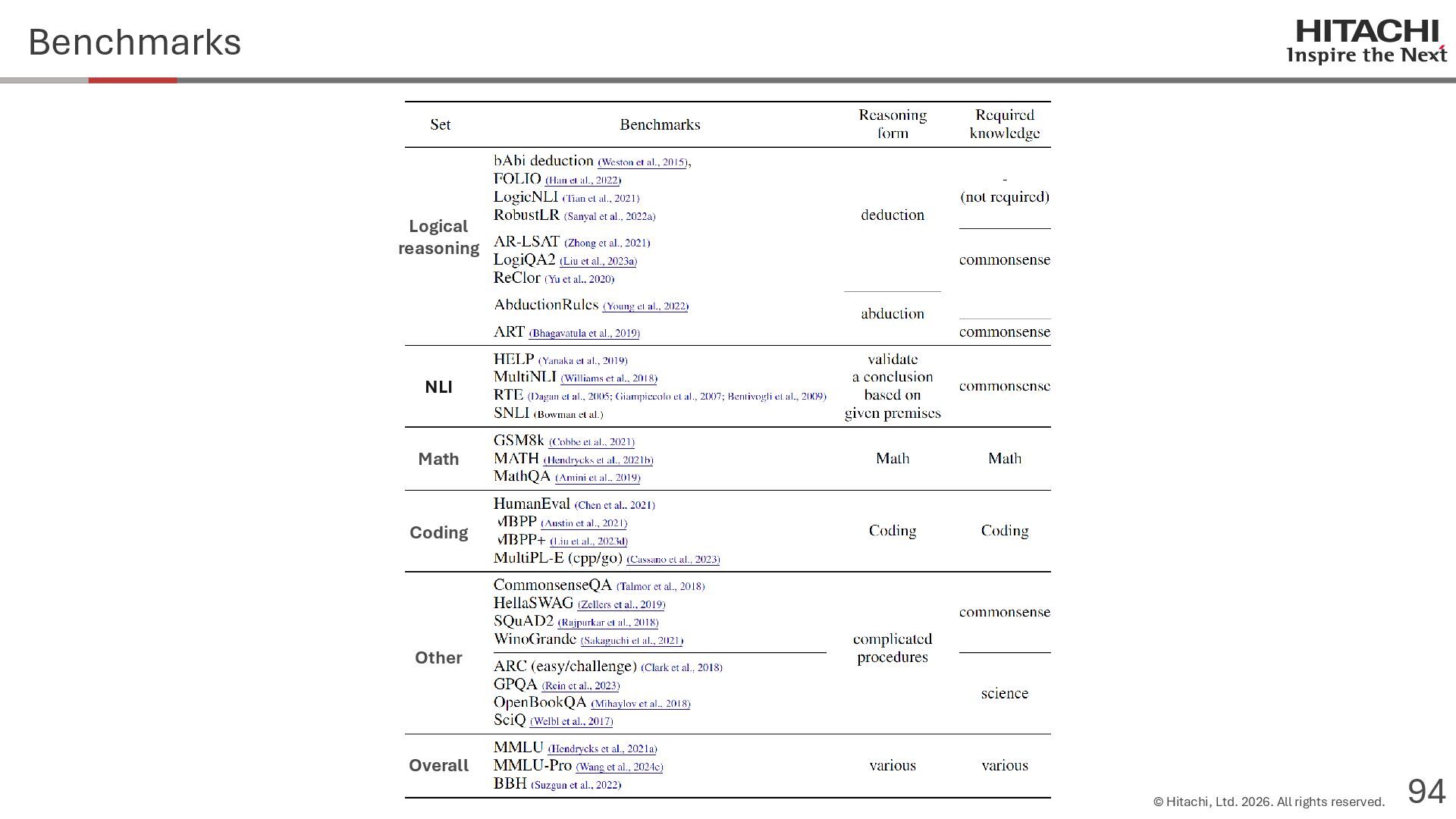{kind=link}
{kind=link}
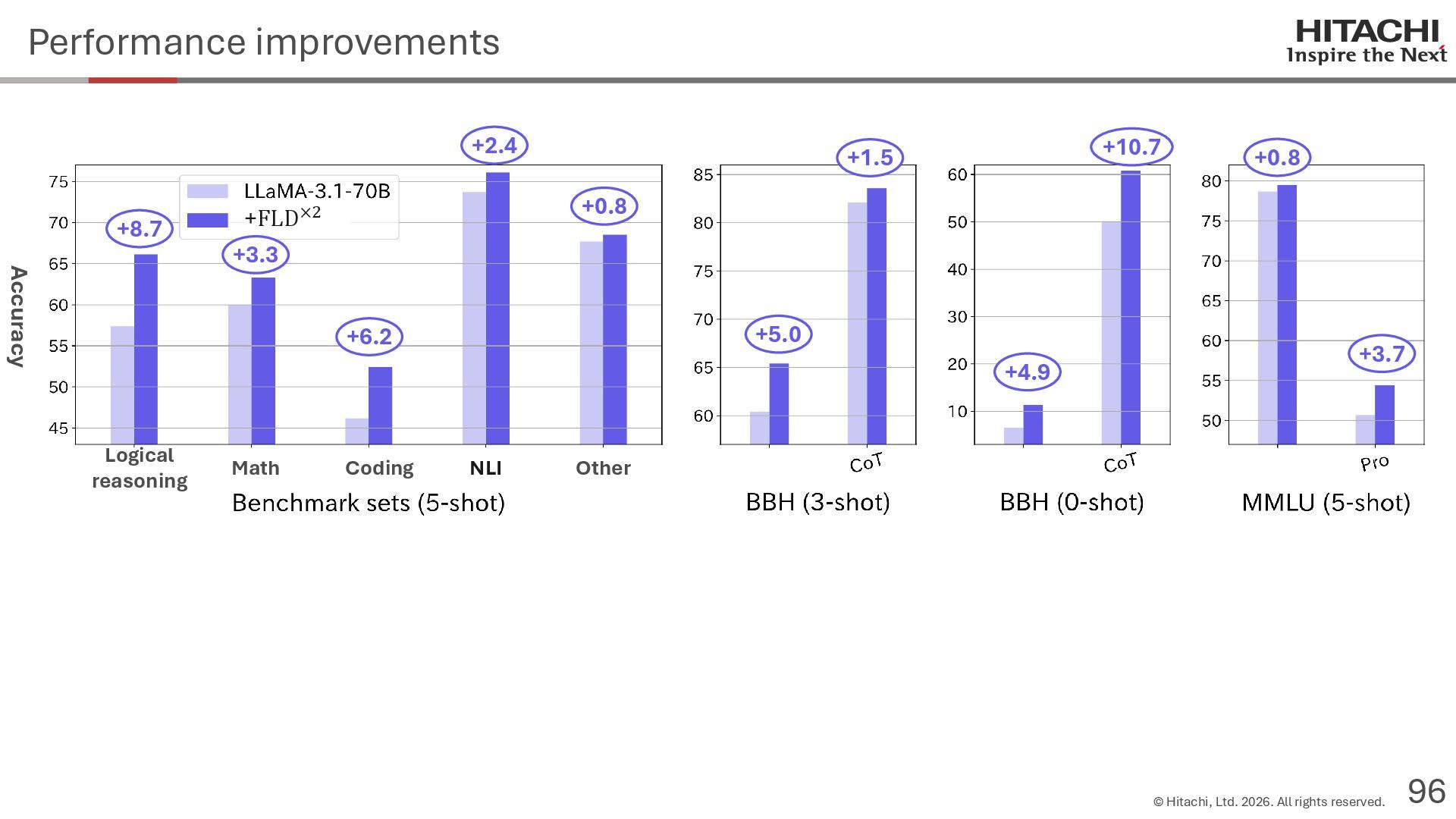{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}