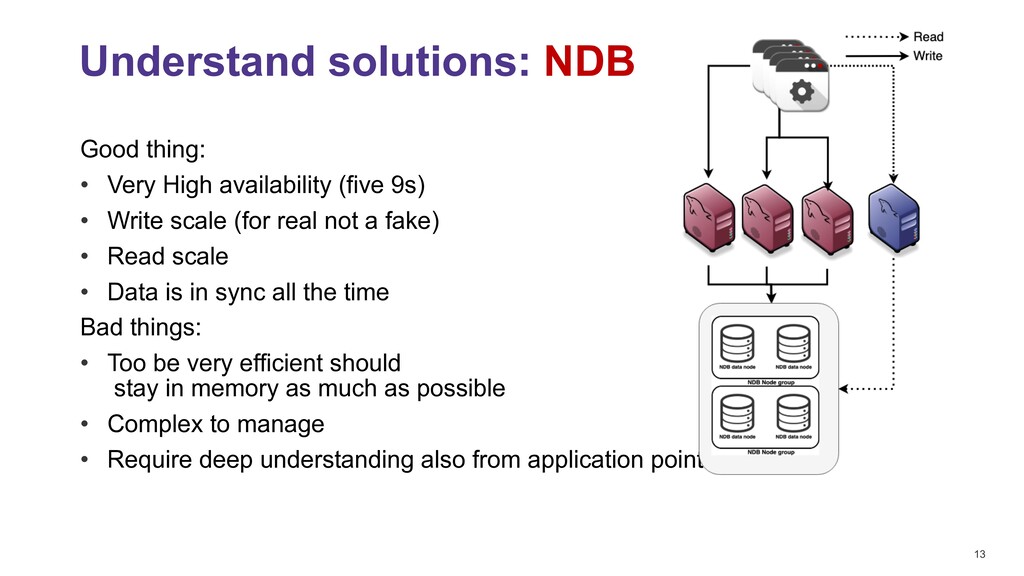
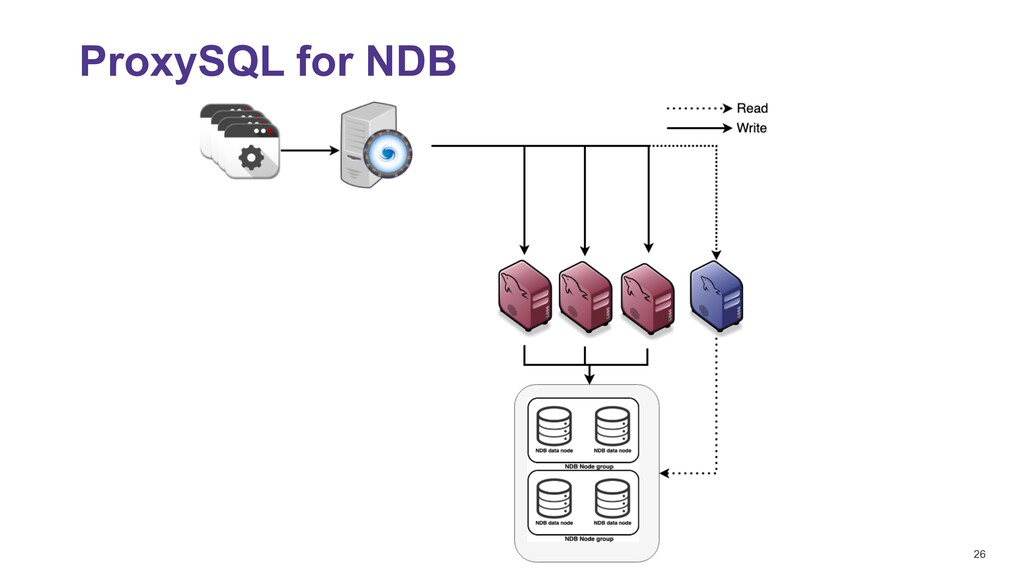
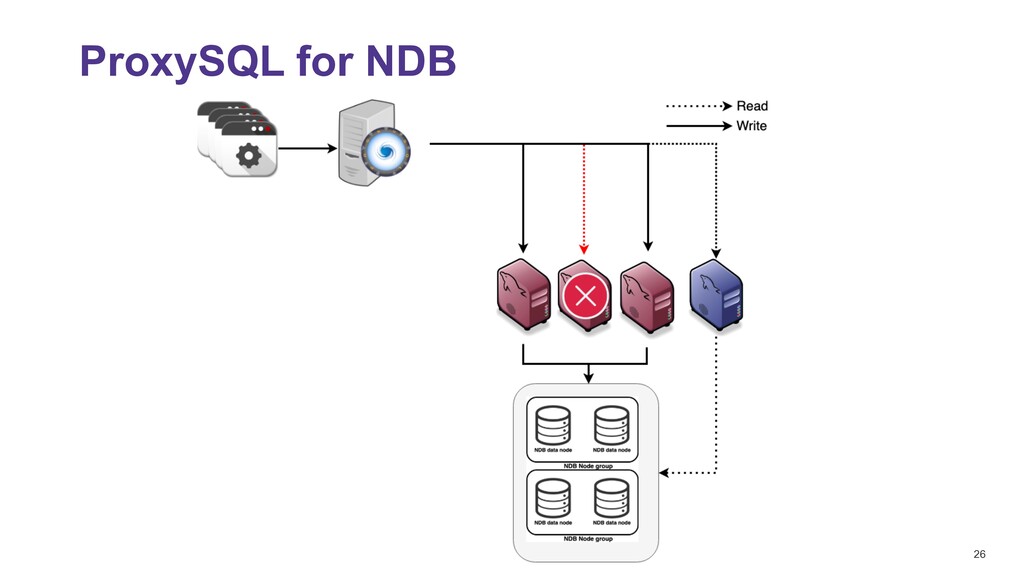
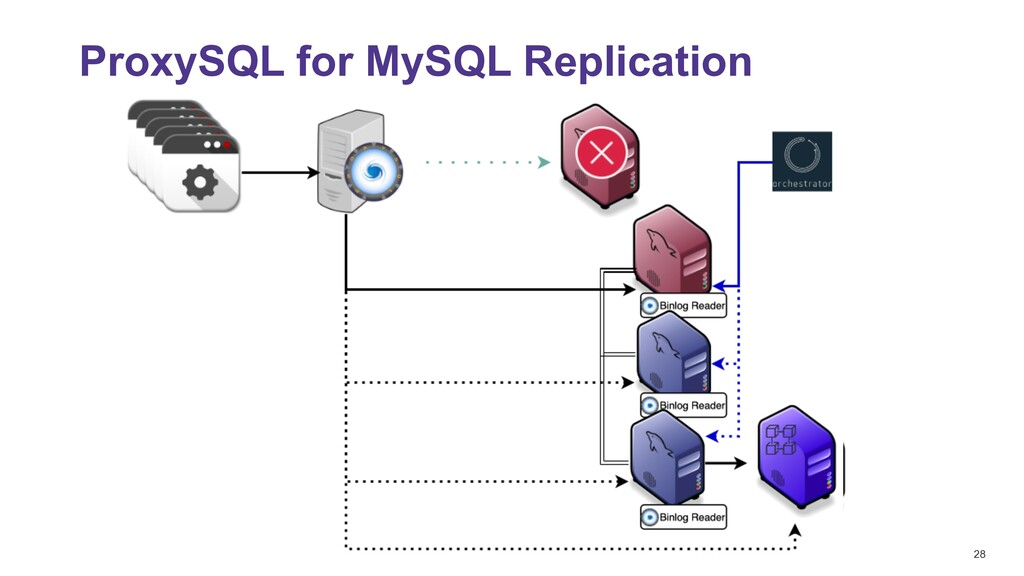
NDB Simpler to configure, no replication lag either ON or OFF delete from mysql_servers where hostgroup_id in (300,301); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections,comment) VALUES ('10.0.0.107',300,3306,10000,2000,'DC1 writer'); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections,comment) VALUES ('10.0.0.107',301,3306,10000,2000,'DC1 Reader'); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections,comment) VALUES ('10.0.0.108',300,3306,10000,2000,'DC1 writer'); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections,comment) VALUES ('10.0.0.108',301,3306,10000,2000,'DC1 Reader'); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections,comment) VALUES ('10.0.0.109',300,3306,10000,2000,'DC1 writer'); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections,comment) VALUES ('10.0.0.109',301,3306,10000,2000,'DC1 Reader'); INSERT INTO mysql_replication_hostgroups VALUES (300,301,'read_only','NDB_cluster'); LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK; Easy to monitor select b.weight, c.* from stats_mysql_connection_pool c left JOIN runtime_mysql_servers b ON c.hostgroup=b.hostgroup_id and c.srv_host=b.hostname and c.srv_port = b.port where hostgroup in (300,301) order by hostgroup,srv_host desc; +--------+-----------+------------+----------+--------+...+------------+ | weight | hostgroup | srv_host | srv_port | status |...| Latency_us | +--------+-----------+------------+----------+--------+...+------------+ | 10000 | 300 | 10.0.0.109 | 3306 | ONLINE |...| 561 | | 10000 | 300 | 10.0.0.108 | 3306 | ONLINE |...| 494 | | 10000 | 300 | 10.0.0.107 | 3306 | ONLINE |...| 457 | | 10000 | 301 | 10.0.0.109 | 3306 | ONLINE |...| 561 | | 10000 | 301 | 10.0.0.108 | 3306 | ONLINE |...| 494 | | 10000 | 301 | 10.0.0.107 | 3306 | ONLINE |...| 457 | +--------+-----------+------------+----------+--------+...+------------+
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}