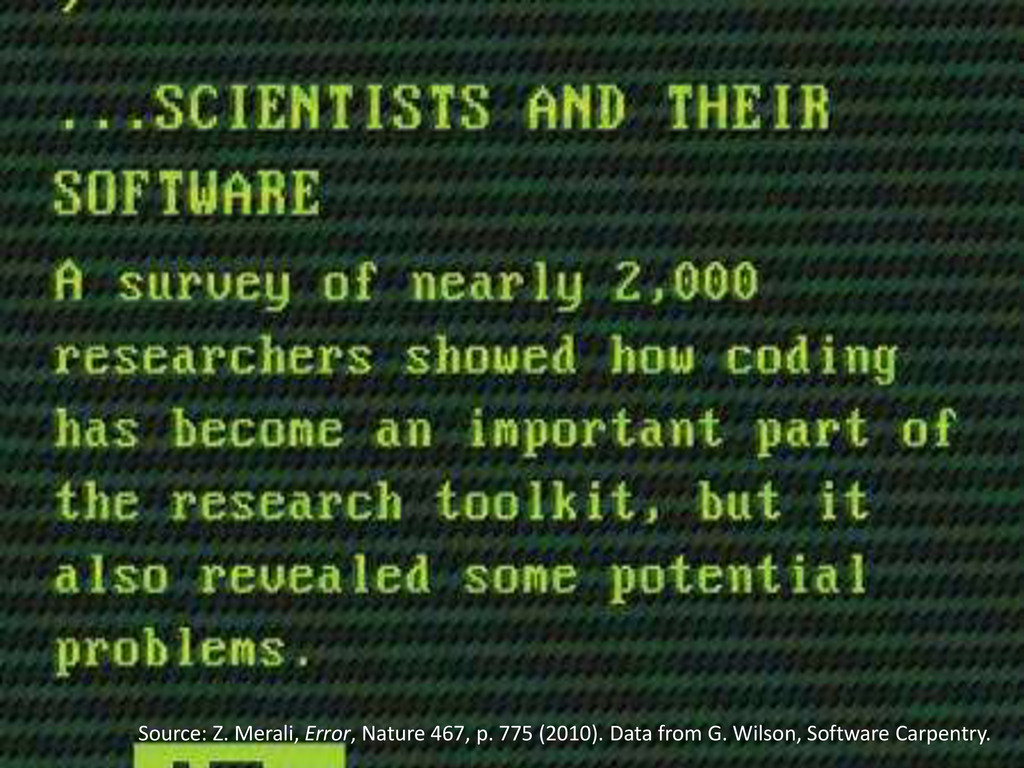
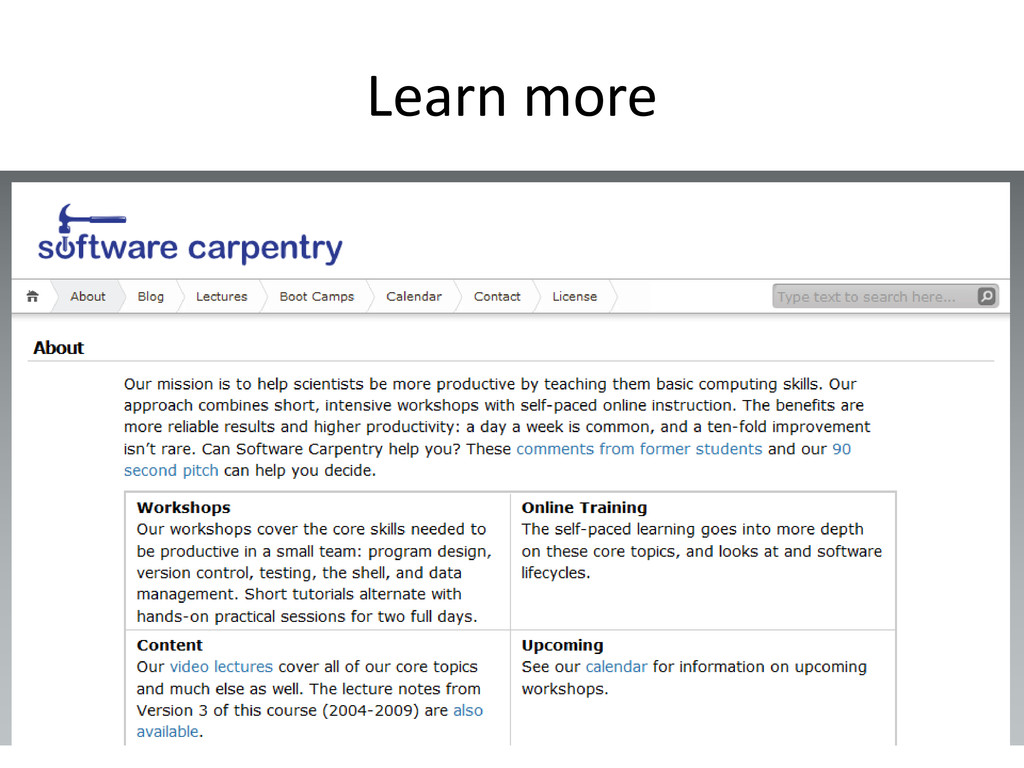
A lunch talk I gave, based on a recent editorial in Nature. Why computer code used in scientific research should be open, and why scientists should be better educated in programming techniques.
make code available, but we do expect a description detailed enough to allow others to write their own code to do similar analysis.” (Editorial: Devil in the Details, Nature 470, p. 305, Feb. 16 2011) RIGOROUS “To address the growing complexity of data and analyses, Science is extending our data access requirement […] to include computer codes involved in the creation or analysis of data.” (Editorial: Making Data Maximally Available, Science 331, p. 649, Feb. 11 2011) This section is a summary of: Ince, Hatton, Graham-Cumming. The case for open computer programs. Nature 482, p. 485. (2012).
natural or mathematical language can be turned into any number of different programs. sinc − + 2 2 + 2 2 ∞ −∞ Adaptive Simpson quadrature won’t work on that, because it has a pole near the real axis. It’ll give you a garbage result.
could be entirely unambiguous. One data set 6 significant figures Nine different results with only 1 or 2 digits agreement Nine different commercial implementations of the same algorithm Hatton, Roberts (1994). How accurate is scientific software? IEEE Trans Softw Eng. 20, 785.
could be entirely unambiguous. Image: “Bulford Dolphin in dry dock” by “Jetset” from Wikimedia Commons, CC-BY-SA “These data, however, were used by geologists to site extremely expensive marine drilling rigs”
(Eric S. Raymond, The Cathedral and the Bazaar) One-third of all software failures in a large-scale IBM study only occurred for the first time after 5000 execution-years. (Adams, IBM J Res. Develop. 28, p. 2, 1984)
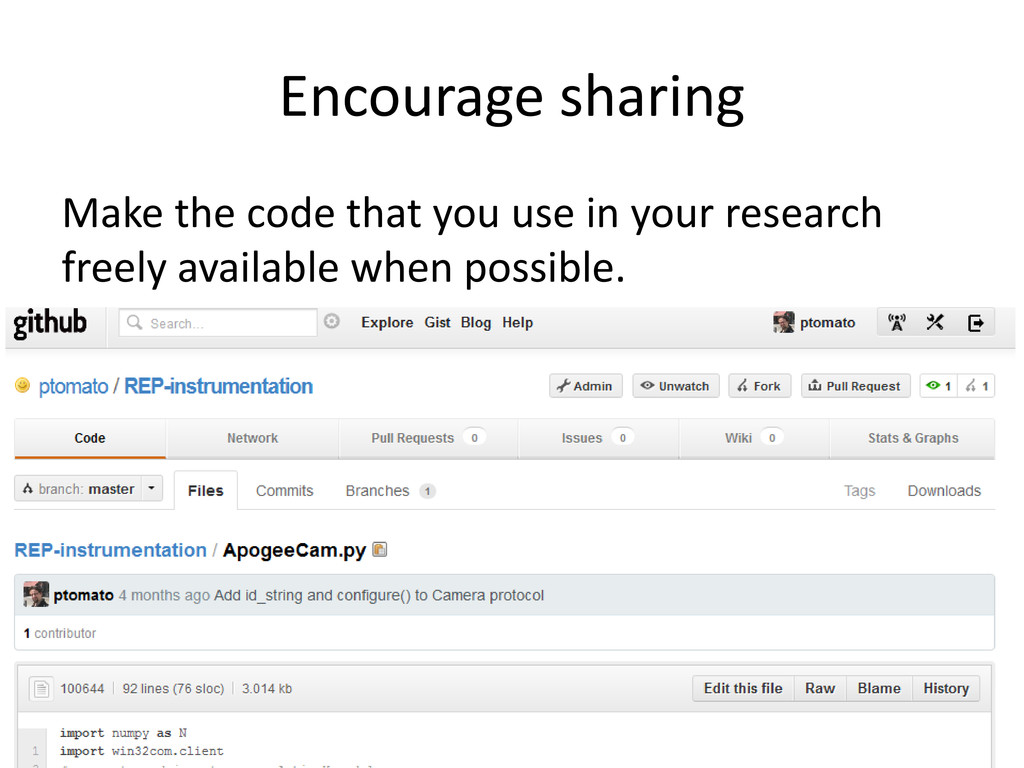
that records every change you make. Put your raw data, processing code, and other primary material into it, to keep a record of what you did, how, and when. “Wooden file cabinet” by “Pptudela” on Wikimedia Commons, CC-BY-SA
results from your sources automatically. Write everything in scripts so you don’t do any manipulation by hand. “tracks” by “hbakkh” on Flickr, CC-BY-NC
large codes from easily testable chunks, and test how they react to broken input. Get other people to review your code. “Checklist” by “adesigna” on Flickr, CC-BY-NC-SA
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}