In a world where most companies claim to be data driven the ingestion pipeline has become a critical part of every days infrastructure. This talk will explore the mechanics of past, current and future of data processing pipelines with special emphasis in common challenges such as how to scale data consumption across teams, assuring reprocessing, optimal performance, scalability and reliability, etc.
During this presentation we will analyse architecture patterns, and
antipatterns, stream or batch organisations and the complexity of
different data transformation graphs. By the end of it you will take
home a collection of do’s and don’ts ready to be applied to your day
job.
Talk delivered at bedcon and codemotion berlin in 2017
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
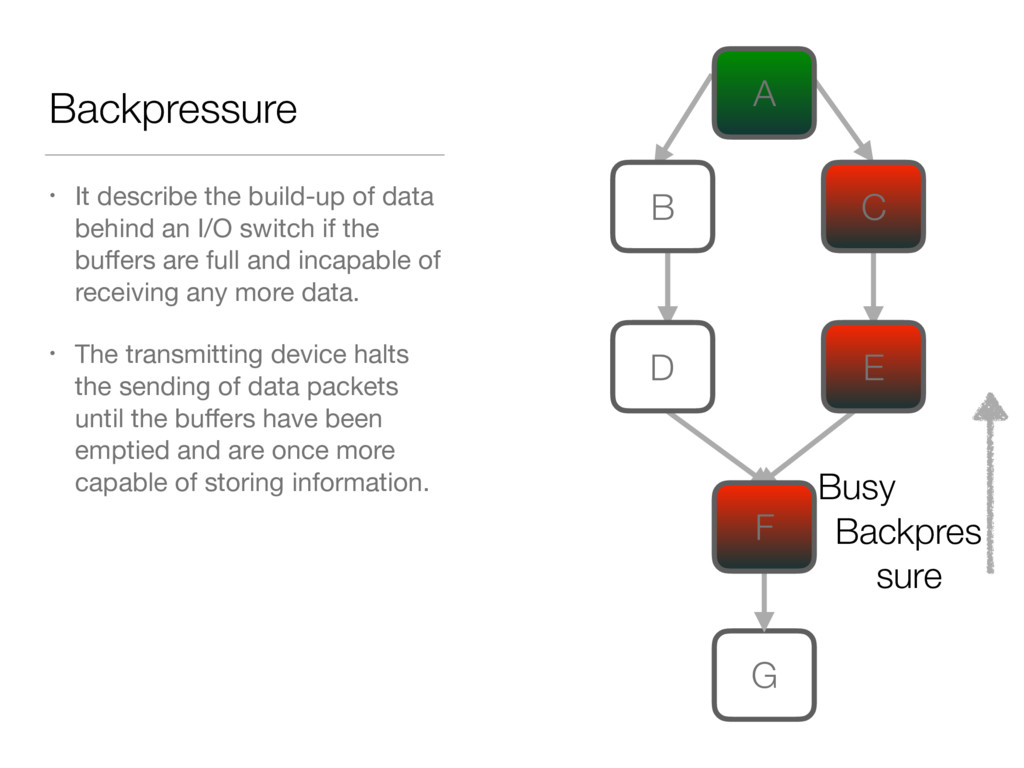{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
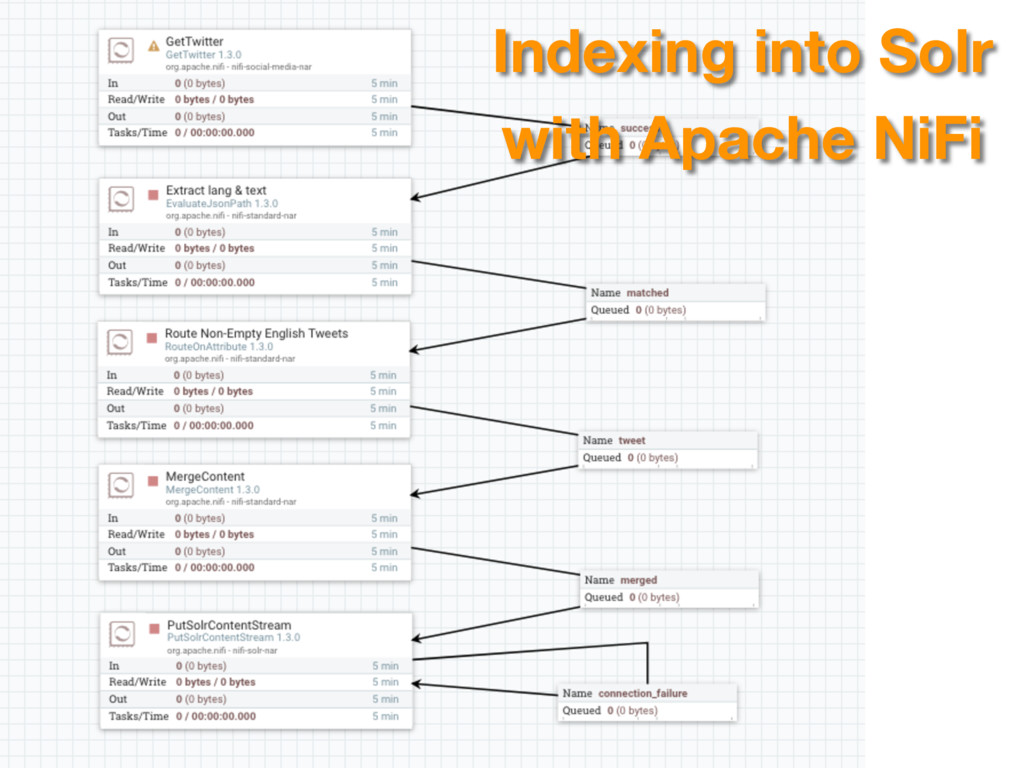{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}