Operating a complex distributed system such as Apache Kafka could be a lot of work, so many moving parts need to be understood when something wrong happens. With brokers, partitions, leaders, consumers, producers, offsets, consumer groups, etc, and security, managing Apache Kafka can be challenging.
From managing consistency, numbers of partitions, understanding under replicated partitions, to the challenges of setting up security, and others, in this talk we will review common issues, and mitigation strategies, seen from the trenches helping teams around the globe with their Kafka infrastructure.
By the end of this talk you will have a collection of strategies to detect and prevent common issues with Apache Kafka, in a nutshell more peace and nights of sleep for you, more happiness for your users, the best case scenario.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
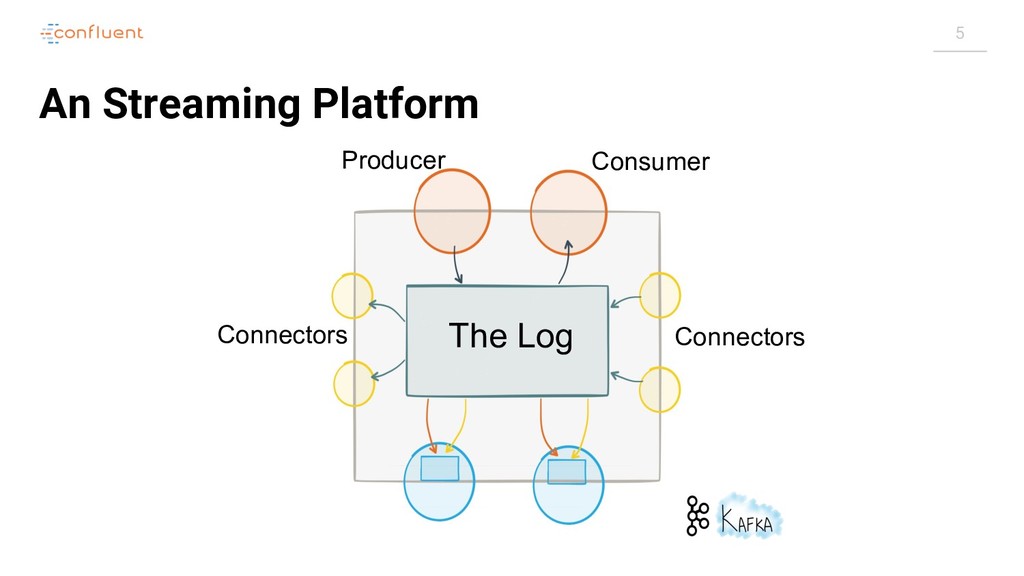{kind=link}
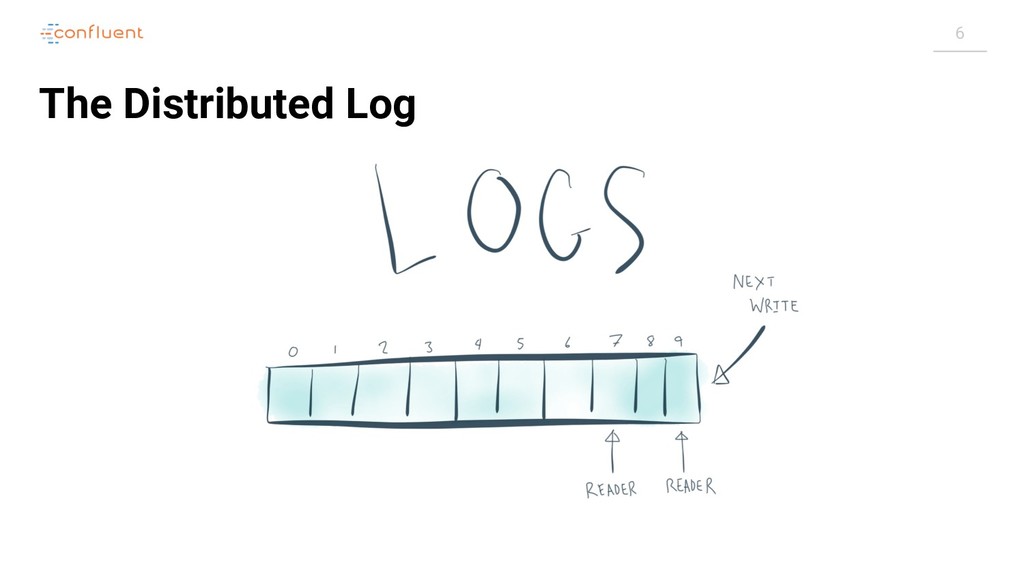{kind=link}
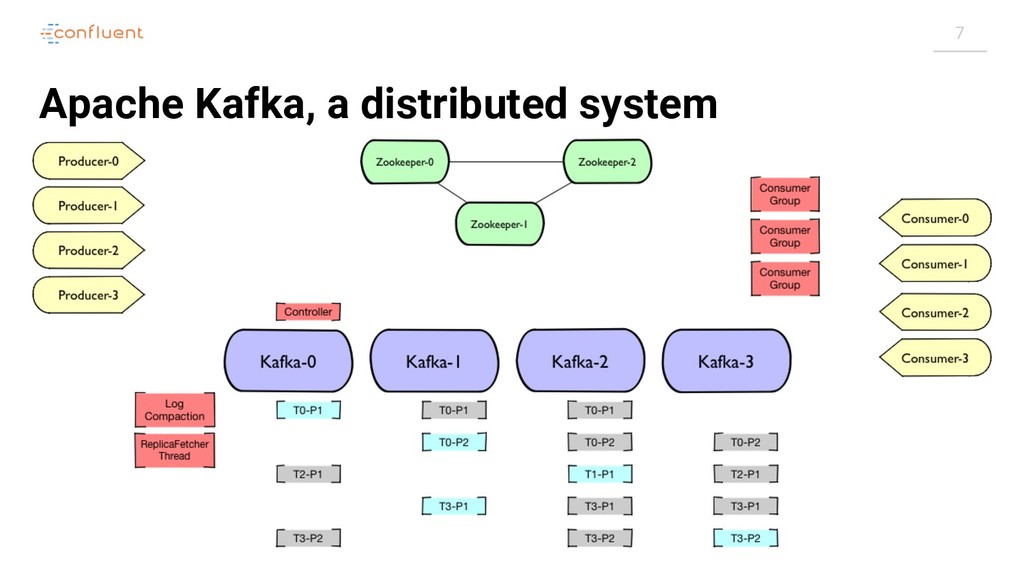{kind=link}
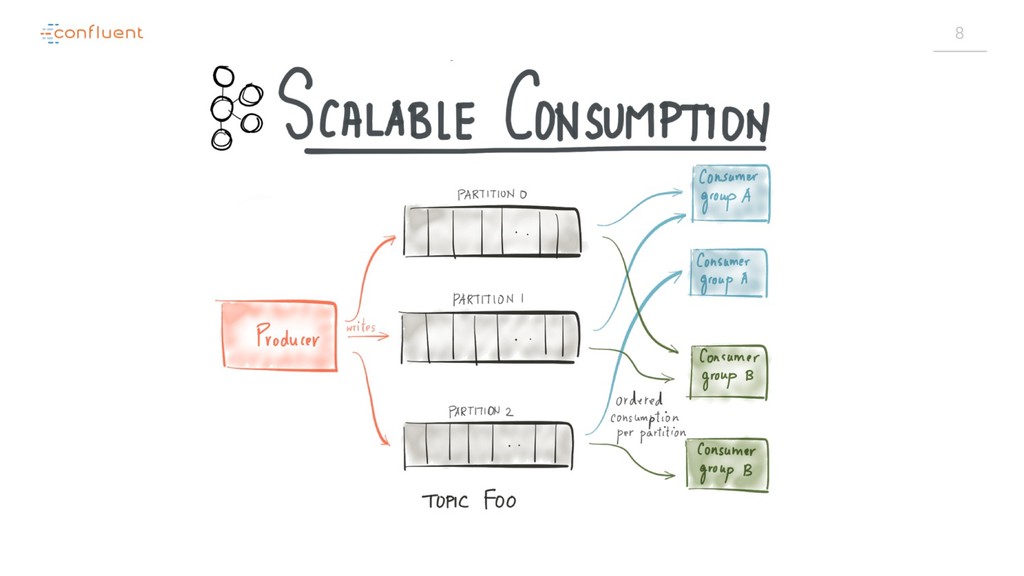{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}