If you have ever been involved in deploying an Apache Kafka cluster
I’m sure you have faced the question, how do I deploy it? From having
everything in one data center, multiple data centers or even the
cloud, Apache Kafka will give you flexibility and adapt to your
situation.
In this talk we’re going to review the different scenarios one might
be facing when installing a new cluster, from a single cluster, to
many clusters and stretched clusters, in all we’re going to review
pros, cons and the guarantees we can expect from them.
By the end of this talk you will know how to deploy Apache Kafka and
get the best of every situation, getting the most of your deployment
with understanding of how the cluster is going to behave.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
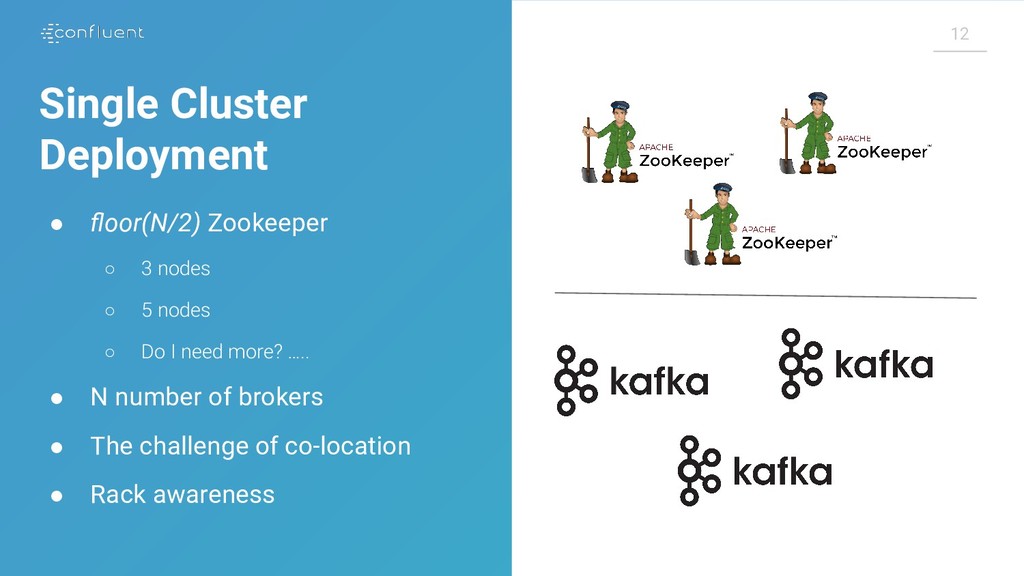{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
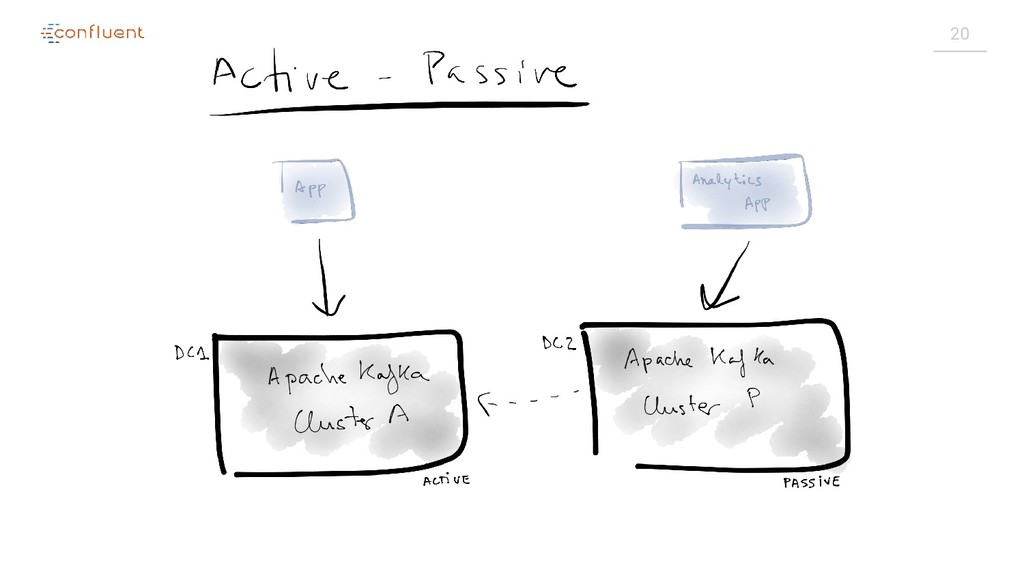{kind=link}
{kind=link}
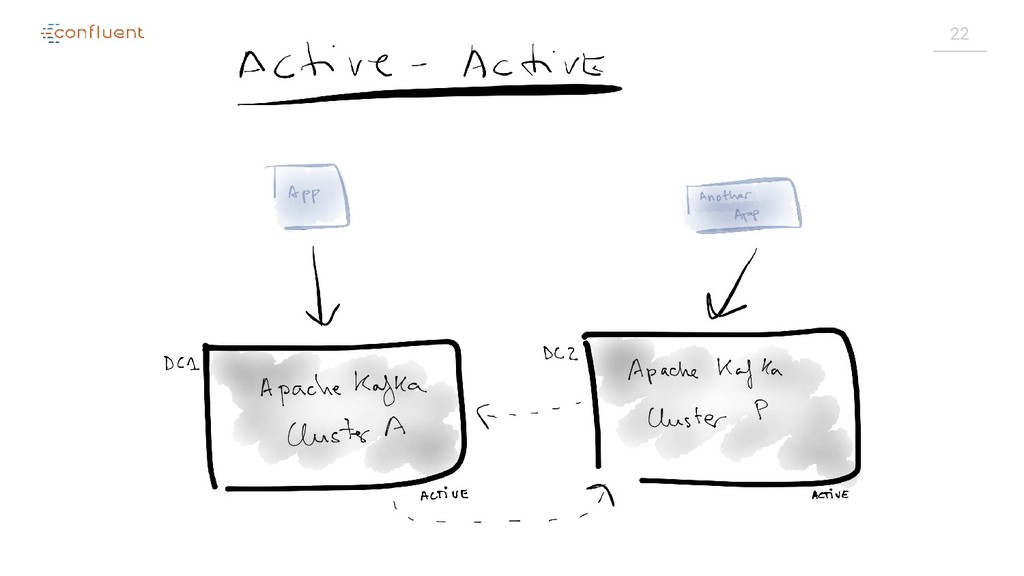{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
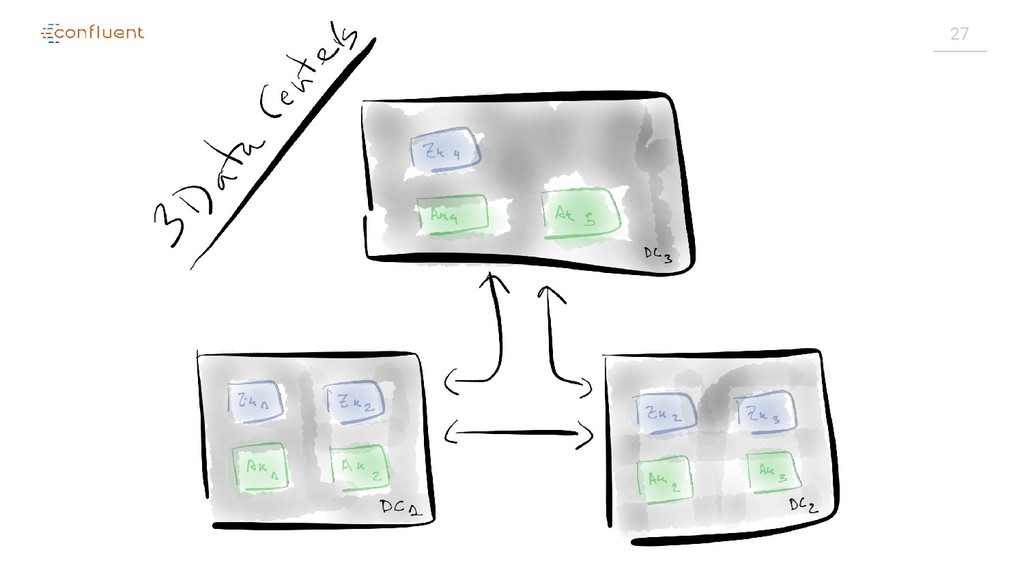{kind=link}
{kind=link}
{kind=link}
{kind=link}
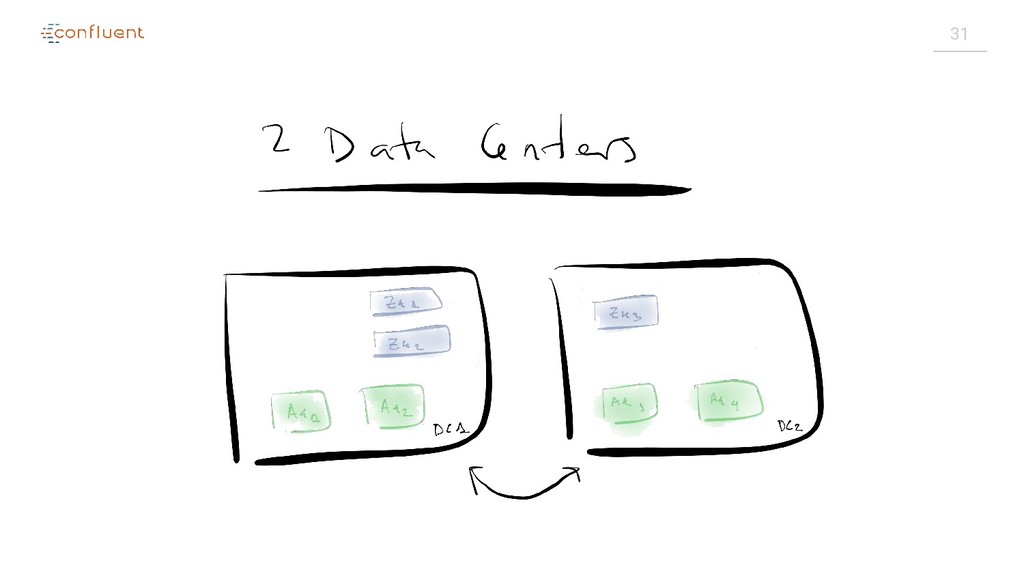{kind=link}
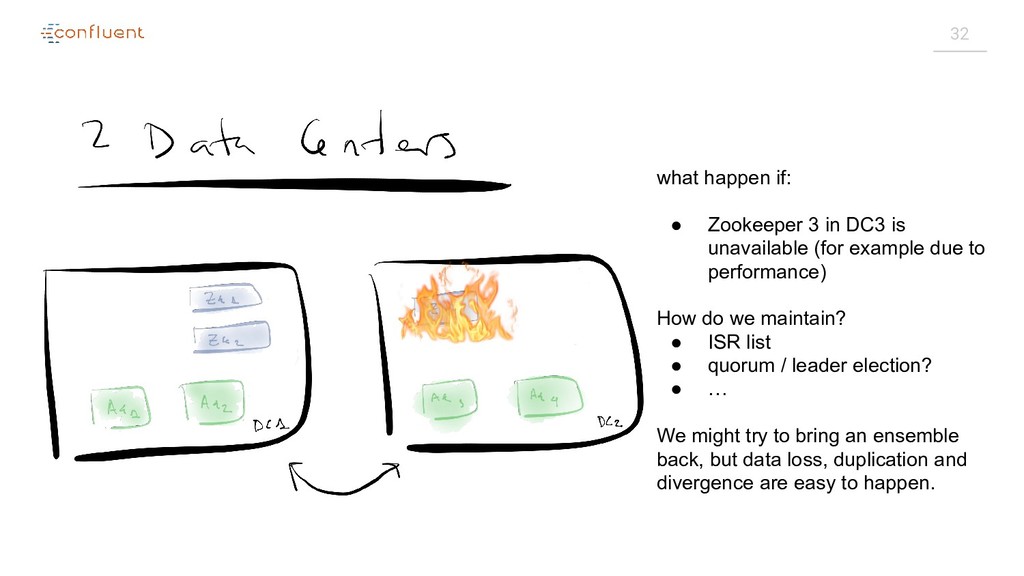{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}