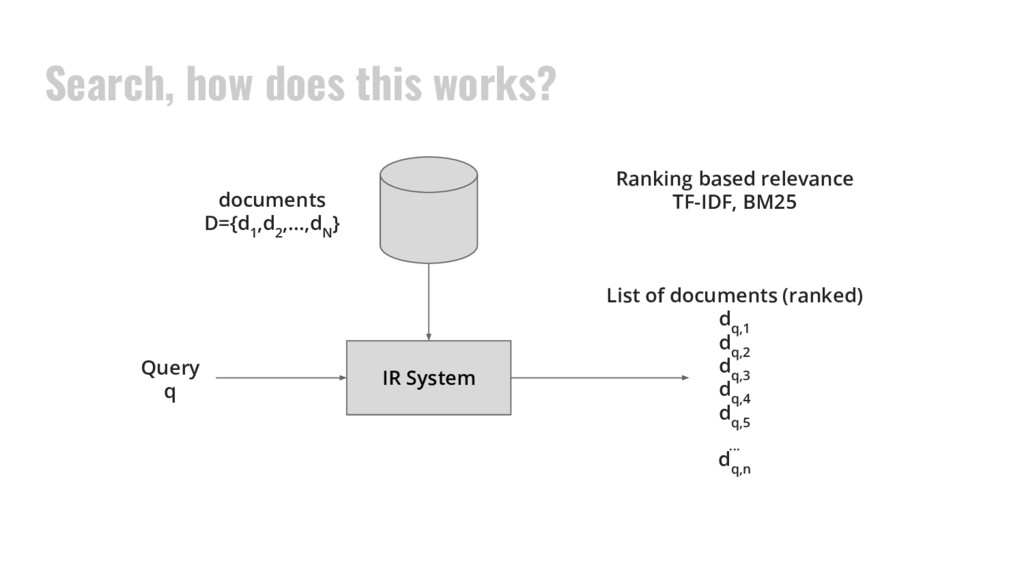
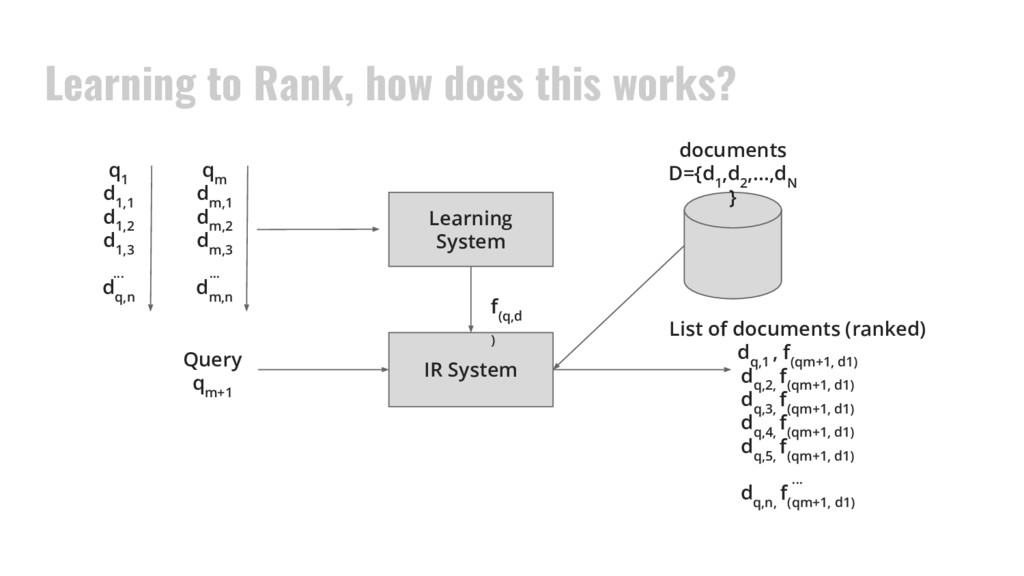
,d 2 ,...,d N } IR System Query q m+1 List of documents (ranked) d q,1 , f (qm+1, d1) d q,2, f (qm+1, d1) d q,3, f (qm+1, d1) d q,4, f (qm+1, d1) d q,5, f (qm+1, d1) ... d q,n, f (qm+1, d1) Learning System q 1 d 1,1 d 1,2 d 1,3 ... d q,n q m d m,1 d m,2 d m,3 ... d m,n f (q,d )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}