find a pattern of text within a bigger block of text. • Also useful for ensuring formatting consistency, or transforming data into a common format. @lukesneeringer
Python's re module. • import re re.search(needle, haystack) • PSA: Don't use re.match, at least while you're learning. Use re.search exclusively. @lukesneeringer
return a "match object". • Match objects have a few methods you commonly use: group, groups, groupdict. • If your regex doesn't match, re.search will return None. @lukesneeringer
string literal with r to get a "raw" string. • This is useful for regular expressions, as we'll see later, because it makes escaping regexes more sane. @lukesneeringer
number of times. + Used one or more times * Used zero or more times ? Used zero or one times (e.g. optional) {x} Used x times (e.g. {2}) {x,y} Used between x and y times, inclusive @lukesneeringer
"atomic thing" it folllows: ab{2} matches abb, not abab. • So far, the only "atomic thing" we've seen is a single literal character. • We're about to look at some more. @lukesneeringer
sets. This matches any single character in the set. >>> re.search('gr[ae]y', 'gray') <_sre.SRE_Match object at 0x100790780> >>> re.search('gr[ae]y', 'grey') <_sre.SRE_Match object at 0x100790cc8> >>> re.search('gr[ae]y', 'grzy') >>> @lukesneeringer
special. It designates a range of characters (usually). >>> re.search('[0-9]{3}-[0-9]{4}', '867-5309') <_sre.SRE_Match object at 0x1020b0d30> @lukesneeringer
literal hyphen in a character set, put it at the beginning or end (I prefer the end). • [a-z0-9-]+ will match one or more characters between a and z (lower-cased only), 0 and 9, and the literal hyphen character. • Obvious use case: [0-9a-f-]{36} for a Python UUID's string representation. @lukesneeringer
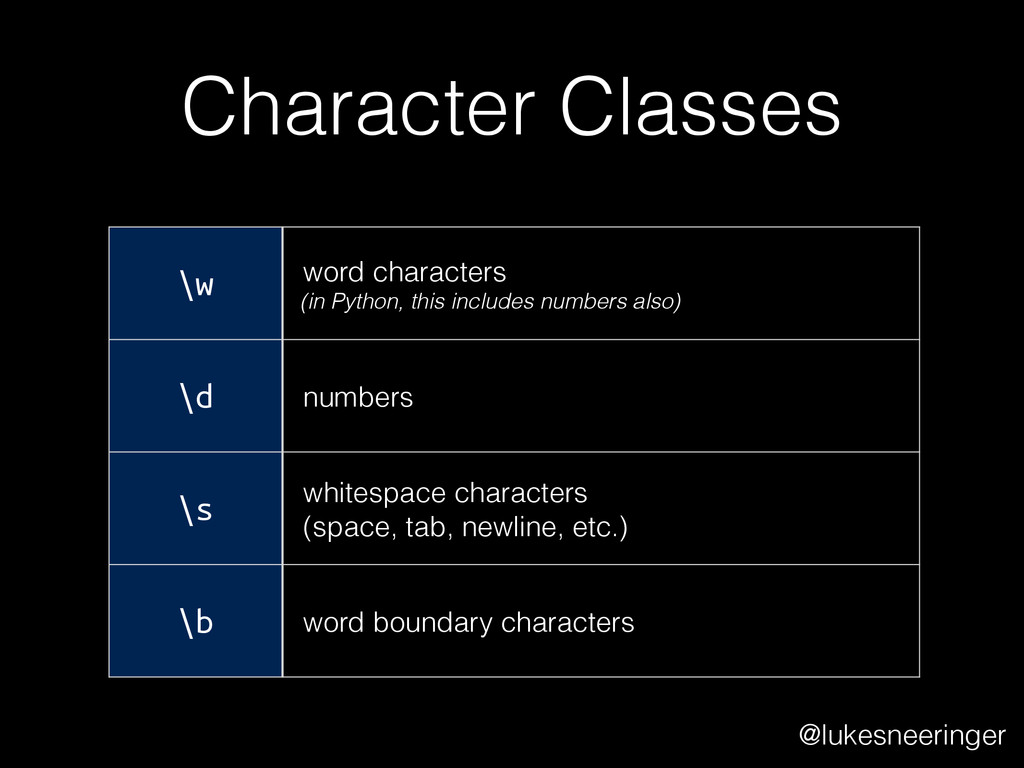
are essentially shorthands that give you common sets of characters. The expression on the previous slide could also be written thusly: [\d]{3}-[\d]{4} @lukesneeringer
check for the absence of a matching character. • Rather, a negated character class checks for the presence of a character that does not match a character in the set. >>> re.search(r'abc[^d]', 'abc') >>> re.search(r'abc[^d]', 'abcxyz').group() 'abcx' @lukesneeringer
match a block of text – in other words, to see whether it (or a piece of it) conforms to a pattern. • That's sometimes enough; usually, though, we want to extract text that matches a pattern and store or manipulate it. @lukesneeringer
to do is get the full match. • To do this, use the match object's group method. >>> m = re.search(r'[\d]{3}-[\d]{3}-[\d]{4}', r'blah 514-867-5309 blah') >>> m <_sre.SRE_Match object at 0x100690d30> >>> m.group() '514-867-5309'
entire match, but also defined pieces of your match. • The tool for doing this is called backreferences. • This is a fancy name for putting subsets of your regex in parentheses. @lukesneeringer
compatible regular expressions to have named backreferences. • This syntax has been ported to most other languages. • The syntax is to add ?P<foo> to the beginning of the backreference. @lukesneeringer
([A-Z]{2}) ([A-Z][\d][A-Z] [\d][A-Z][\d])$ Let's make those named backreferences (apologies for the line break): ^(?P<city>[\w ]+), (?P<province>[A-Z]{2}) (?P<postal>[A-Z][0-9][A-Z] [0-9][A-Z][0-9])$ @lukesneeringer
done with regular expressions. This talk has simply given the building blocks. • A few topics I haven't covered: alternation ("or"), lookahead, conditionals @lukesneeringer
{kind=link}
{kind=link}
{kind=link}
![\b[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}\b Dragons? @lukesneeringer](https://files.speakerdeck.com/presentations/c9228b60a3b1013145093607ee153eb8/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Character Sets Characters enclosed in [] characters are called character](https://files.speakerdeck.com/presentations/c9228b60a3b1013145093607ee153eb8/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Backreferences Consider the previous address example: ^[\w ]+, [A-Z]{2} [A-Z][\d][A-Z]](https://files.speakerdeck.com/presentations/c9228b60a3b1013145093607ee153eb8/slide_32.jpg){kind=link}
![Backreferences >>> regex = r'^([\w ]+), ([A-Z]{2}) '\ r'([A-Z][\d][A-Z] [\d][A-Z][\d])$'](https://files.speakerdeck.com/presentations/c9228b60a3b1013145093607ee153eb8/slide_33.jpg){kind=link}
{kind=link}
![Named Backreferences Our previous address with plain backreferences: ^([\w ]+),](https://files.speakerdeck.com/presentations/c9228b60a3b1013145093607ee153eb8/slide_35.jpg){kind=link}
![Named Backreferences >>> regex = \ r'^(?P<city>[\w ]+), '\ r'(?P<province>[A-Z]{2})](https://files.speakerdeck.com/presentations/c9228b60a3b1013145093607ee153eb8/slide_36.jpg){kind=link}
{kind=link}
![\b[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}\b The Dragon @lukesneeringer](https://files.speakerdeck.com/presentations/c9228b60a3b1013145093607ee153eb8/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}