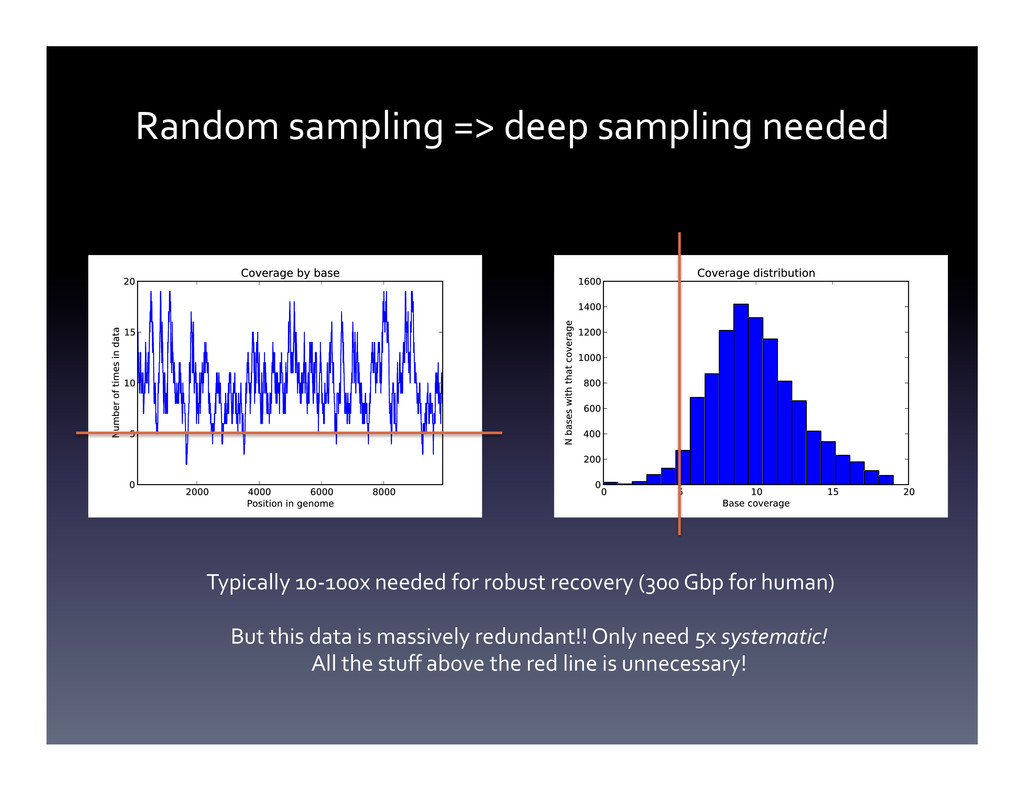
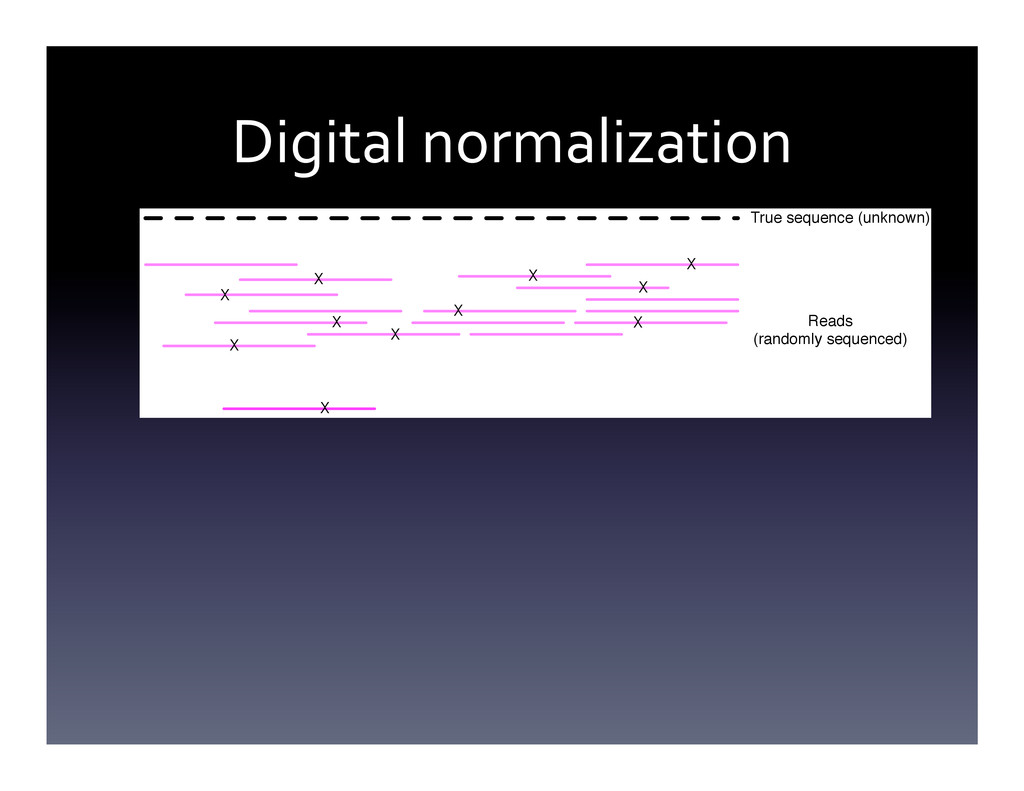
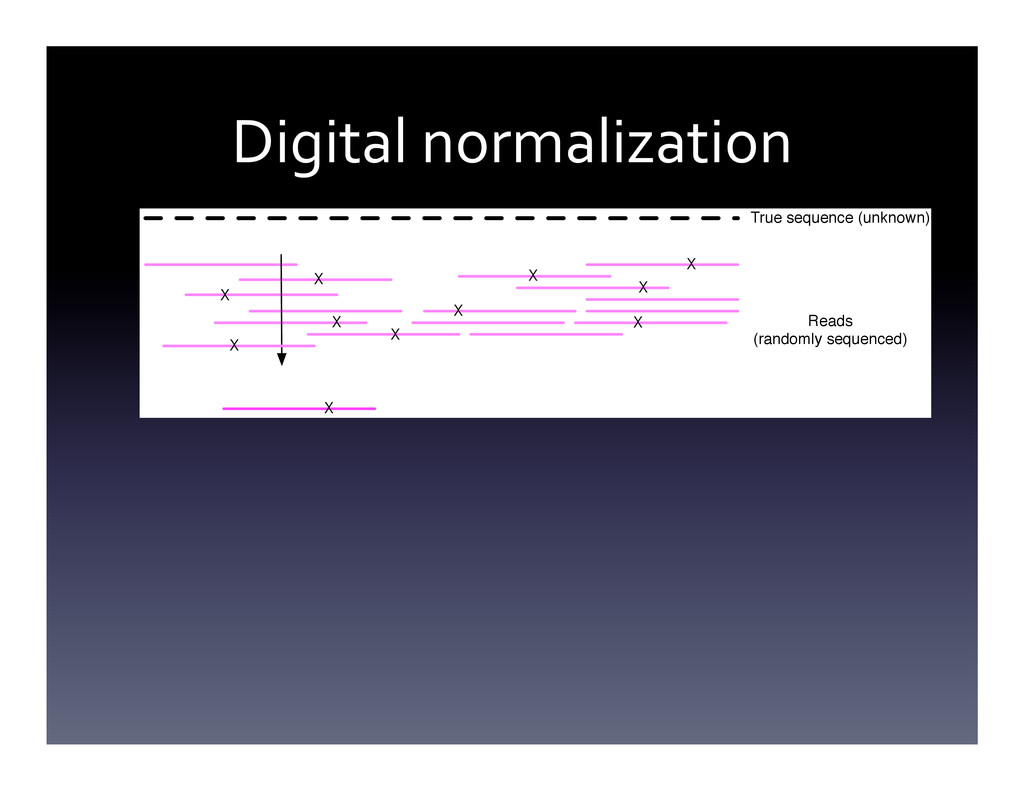
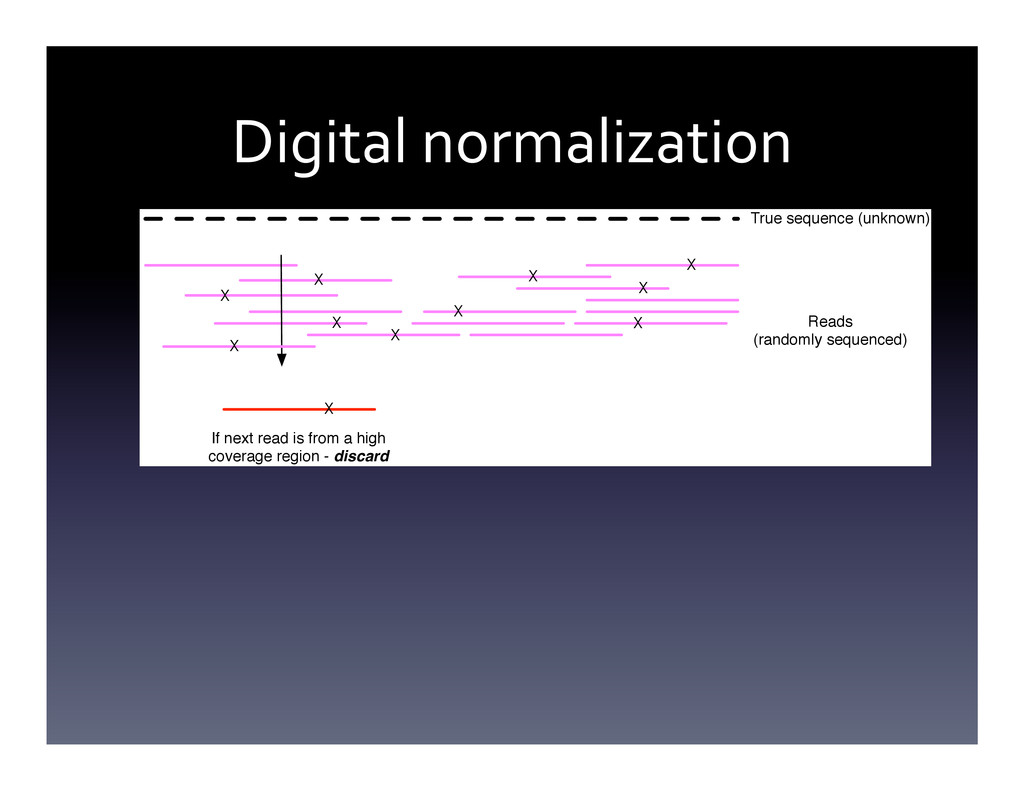
Random algorithms and probabilistic data structures are algorithmically efficient and can provide shockingly good practical results. I will give a practical introduction, with live demos and bad jokes, to this fascinating algorithmic niche. I will conclude with some discussions of how our group has applied this to large sequencing data sets (although this will not be the focus of the talk).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
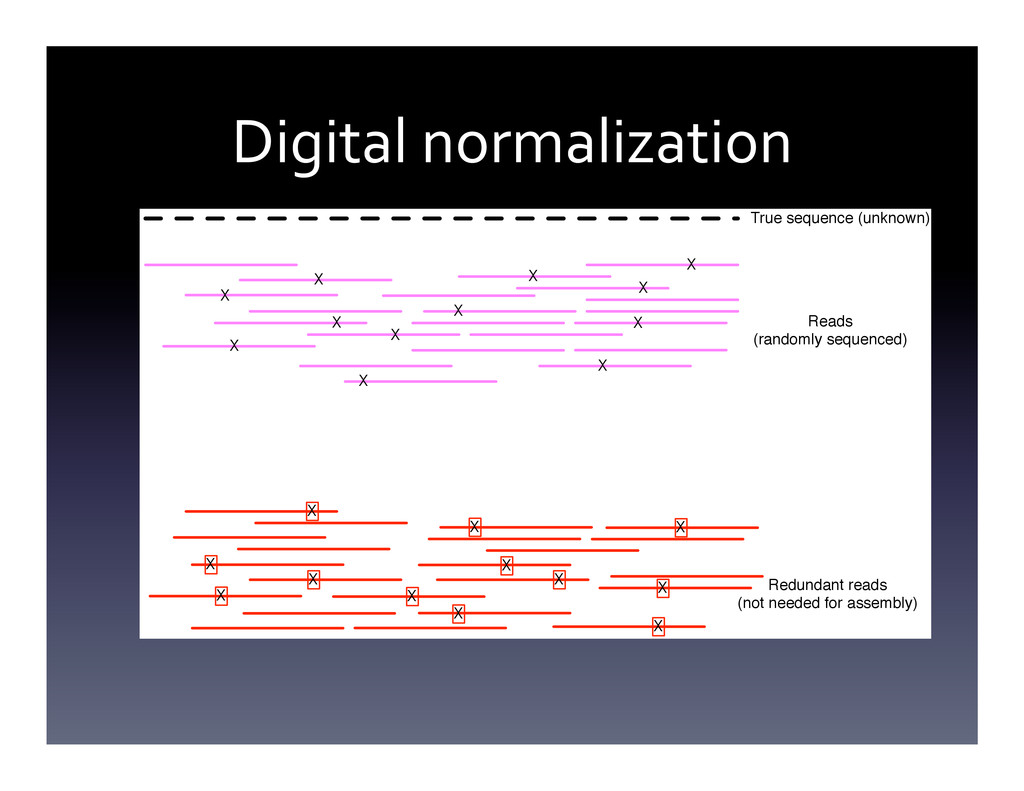{kind=link}
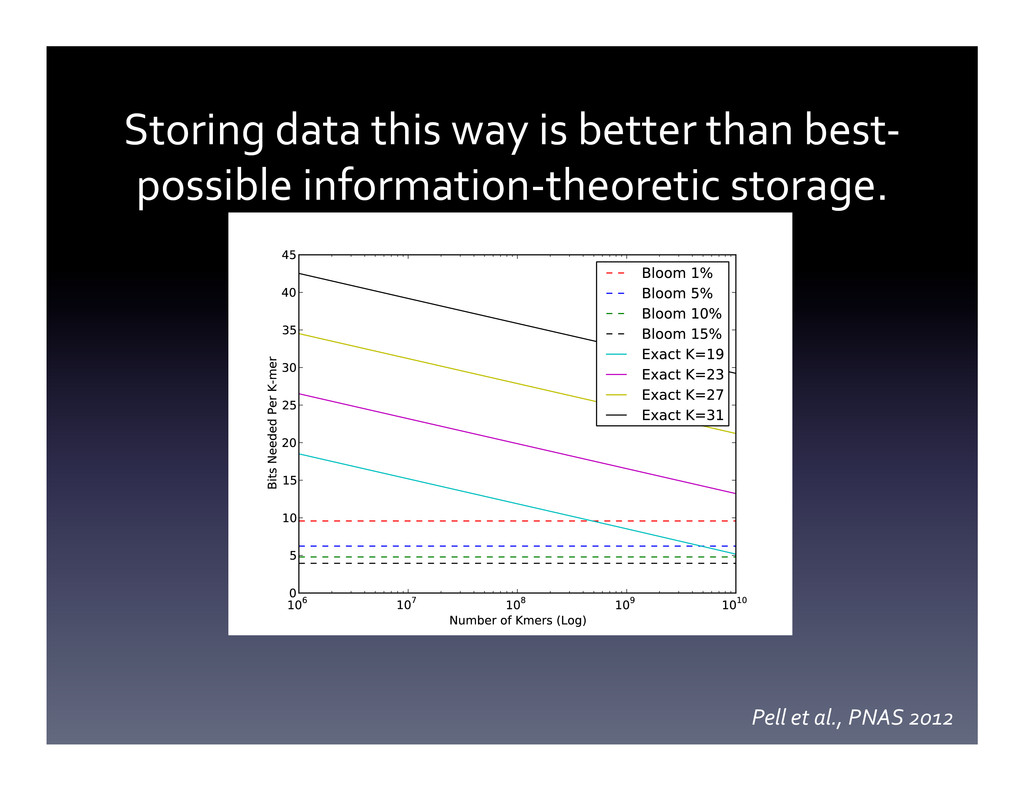{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}