2013 If you want to follow along with the slides for this talk on your laptop, you can view them on slideshare.net. The slides do have my presenter notes, so you can also read it all again later if you are too busy surfing the net, or didn't catch some point.
bloated and uses heaps of memory. • Is slow and doesn't perform very well. • Is not able to handle a high number of concurrent requests. Saturday, 16 March 2013 These days there seems to be a never ending line of people who will tell you that Apache sucks and that you are crazy if you use it, especially for hosting Python web applications. What is the truth? Do the people who make such claims actually understand how Apache works or are they just repeating what someone else told them?
bloated and uses heaps of memory. • Is slow and doesn't perform very well. • Is not able to handle a high number of concurrent requests. Saturday, 16 March 2013 As the author of the mod_wsgi module for Apache, what I want to do in this talk is go through and look at what some of the pain points are when configuring Apache to run Python web applications. The intent is that you can walk away with a bit more insight into how Apache works and what is required to properly setup Apache and mod_wsgi. So, if you like, I am going to explain how to make Apache suck less.
memory usage. • Python web applications are fat to start with. • Poor choice of multiprocessing module (MPM). • Poor choice of configuration for the MPM used. • Loading of Apache modules you aren't using. • Size of Apache memory pools for each thread. • Inability to benefit from copy on write. Saturday, 16 March 2013 The biggest criticism which seems to be levelled at Apache is that it is bloated and uses too much memory. There are various reasons Apache can use a lot of memory. Many of these are under the control of the user and not necessarily a failing of Apache though.
response times. • Not enough capacity configured to handle throughput. • Keep alive causing artificial reduction in capacity. • Machine slowing down due to frequent process recycling. • High cost of loading WSGI applications on process startup. Saturday, 16 March 2013 Another criticism is why is Apache so slow. Like with memory usage, this can also have a lot to do with how Apache has been configured. In practice, if Apache is simply setup properly for the specifics of running dynamic Python web applications, and takes into consideration the constraints of the system it is being run on, neither of these should be an issue.
LoadModule rewrite_module modules/mod_rewrite.so LoadModule wsgi_module modules/mod_wsgi.so Saturday, 16 March 2013 The first thing one can do is to strip down what modules Apache is loading. Because Apache is a workhorse that can be used for many different tasks, it comes with a range of pluggable modules. There is likely going to be any number of modules getting loaded you aren't using. To cut down on base memory used by Apache itself, you should disable all Apache modules you are not using.
Apache - Streamlined (2 MB) • Python WSGI Hello World • Apache/mod_wsgi - Streamlined (5 MB) • Apache/mod_wsgi - Kitchen Sink (10MB) • Gunicorn - Sync Worker (10MB) • Real Python Web Application • Django (20-100MB+) Saturday, 16 March 2013 Beyond the server, it has to be recognised that any use of Python will cause an immediate increase in memory used. Load a typical web application, along with all the modules from the standard library it requires, as well as third party modules and memory use will grow quite quickly. The actual base memory consumed by the web server at that point can be quite small in comparison.
Apache - Streamlined (2 MB) • Python WSGI Hello World • Apache/mod_wsgi - Streamlined (5 MB) • Apache/mod_wsgi - Kitchen Sink (10MB) • Gunicorn - Sync Worker (10MB) • Real Python Web Application • Django (20-100MB+) Saturday, 16 March 2013 Overall, it shouldn't really matter what WSGI server you use, the Python interpreter and the Python web application itself should always use a comparable amount of memory for a comparable configuration. The laws of nature don't suddenly change when you start using Apache to host a Python web application. Memory used by the Python web application itself in a single process should not suddenly balloon out for no reason.
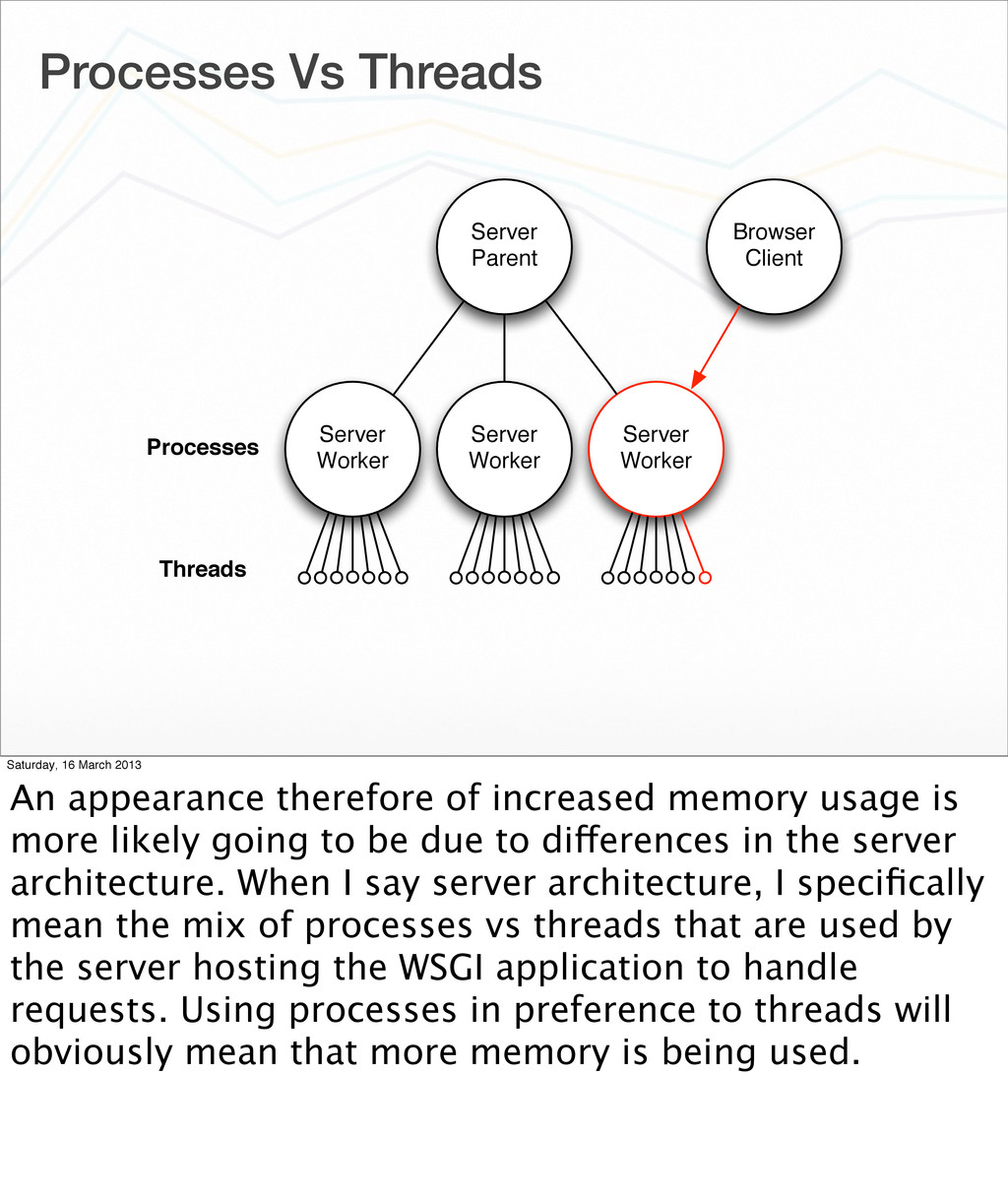
Worker Processes Threads Browser Client Saturday, 16 March 2013 An appearance therefore of increased memory usage is more likely going to be due to differences in the server architecture. When I say server architecture, I specifically mean the mix of processes vs threads that are used by the server hosting the WSGI application to handle requests. Using processes in preference to threads will obviously mean that more memory is being used.
single threaded processes. • Worker MPM - Multiple multi threaded processes. • WinNT MPM - Single multi threaded processes. • Gunicorn • Sync Worker - Multiple single threaded processes. MPM = Multiprocessing Module Saturday, 16 March 2013 The big problem in this respect is that beginners know no better and will use whatever the default configuration is that their server distribution provides. For Apache, which is often supplied with the prefork multiprocessing module, or MPM, this can very easily cause problems, because it uses single threaded processes.
processes (maximum) / 1 thread per process. • Worker MPM - 6 processes (maximum) / 25 threads per process. • WinNT MPM - 1 process (fixed) / 150 threads per process. • Gunicorn • Sync Worker - 1 process (fixed) / 1 thread per process. Saturday, 16 March 2013 Although prefork MPM may only initially start out with a single process, it can automatically scale out to 150 processes. That is 150 copies of your Python web application. At 20MB per process that is already 3GB and at 20MB that would be considered a small Python web application. In contrast, gunicorn sync worker defaults to a single process and single thread and doesn't scale. The memory requirement of gunicorn would therefore stay the same over time.
configurations for hosting Python web applications. • Don't use the prefork MPM unless you know how to configure Apache properly, use the worker MPM, it is more forgiving. • Don't allow Apache to automatically scale out the number of processes over too great a range. • Don't try and use a single Apache instance to host Python, PHP, Perl web applications at the same time. Saturday, 16 March 2013 So, whatever you do, don't use the default configuration that comes with your server distribution. For Python web applications you generally can't avoid having to tune it. This is because the Apache defaults are setup for static file serving and PHP applications. Especially don't try and use the same Apache instance to host Python web applications at the same time as running PHP or Perl applications as each has different configuration requirements.
'Server MPM' Server MPM: Prefork Saturday, 16 March 2013 How do you work out which MPM you are using? Prior to Apache 2.4 the type of MPM being used was defined when Apache was being compiled and was statically linked into the Apache executable. From Apache 2.4, the MPM can also be dynamically loaded and so defined at runtime by the Apache configuration. Either way, you can determine the MPM in use by running the Apache executable with the '-V' option.
FALSE TRUE FALSE Worker FALSE TRUE TRUE WinNT FALSE FALSE TRUE Saturday, 16 March 2013 Another way of determining the specific process architecture in use is by consulting the multiprocess and multithread attributes passed in the WSGI environ with each request. Neither of these though will actually tell you how many processes or threads are in use. For that you need to start looking at the Apache configuration itself.
MaxSpareServers 10 MaxClients 150 MaxRequestsPerChild 0 </IfModule> <IfModule mpm_worker_module> StartServers 2 MaxClients 150 MinSpareThreads 25 MaxSpareThreads 75 ThreadsPerChild 25 MaxRequestsPerChild 0 </IfModule> extra/httpd-mpm.conf Saturday, 16 March 2013 This is where we can actually end up in a trap. For the standard Apache configuration as provided with the Apache Software Foundation's distribution, although there are example MPM settings provided, that configuration file isn't actually included by default. The settings in that file are also different to what is compiled into Apache, so you can't even use it as a guide to what the compiled in defaults are.
10 MaxClients 256 MaxRequestsPerChild 10000 Saturday, 16 March 2013 So although I said before that the prefork MPM could scale up to 150 processes automatically, that was on the assumption that the default settings in the Apache configuration file were actually used. If those settings aren't used, then it is instead 256 processes, making it even worse. Some people recommend throwing away the default configuration files and starting from scratch meaning one uses the more lethal compiled in settings.
server processes created at startup. • MaxClients - Maximum number of connections that will be processed simultaneously. • MaxRequestsPerChild - Limit on the number of requests that an individual child server will handle during its life. Saturday, 16 March 2013 For those who are not familiar with these settings, what do they actually mean. StartServers is the initial number of processes created to handle requests. Because prefork uses single threaded processes, the maximum number of processes ends up being dictated by MaxClients.
idle child server processes. • MaxSpareServers - Maximum number of idle child server processes. Saturday, 16 March 2013 The settings which need more explanation are the min and max spare processes. The purpose of these is to control how Apache dynamically adjusts the number of processes being used to handle requests.
a single process elif idle_process_count < min_spare_servers: spawn one or more processes Saturday, 16 March 2013 In very simple terms, what Apache does is wake up each second and looks at how many idle processes it has at that point which are not handling requests. If it has more idle processes than the maximum specified, it will kill off a single process. If it has less idle processes than the minimum spare required it will spawn more. How many it spawns will depend on whether it had spawned any in the previous check and whether it is creating them quickly enough.
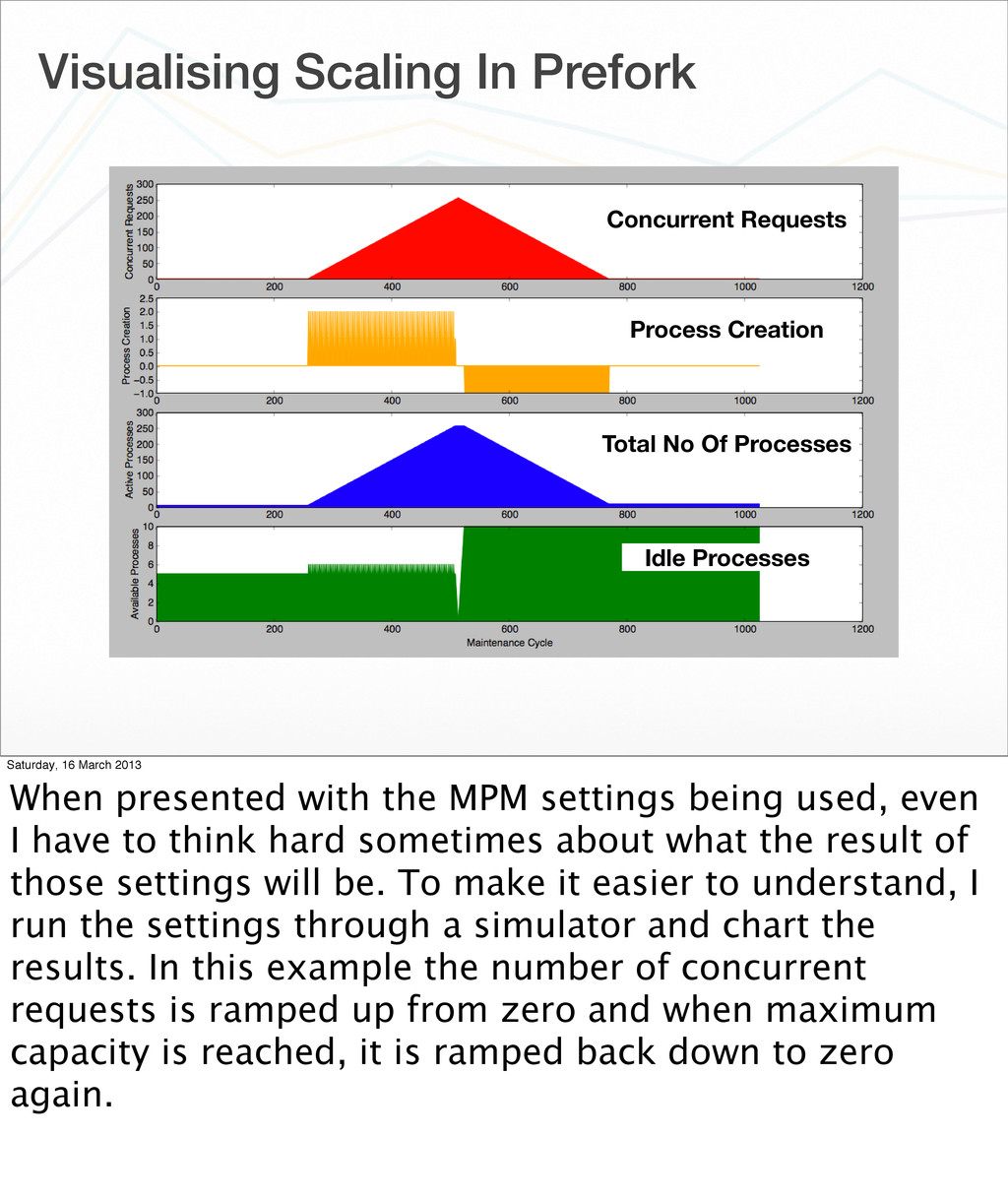
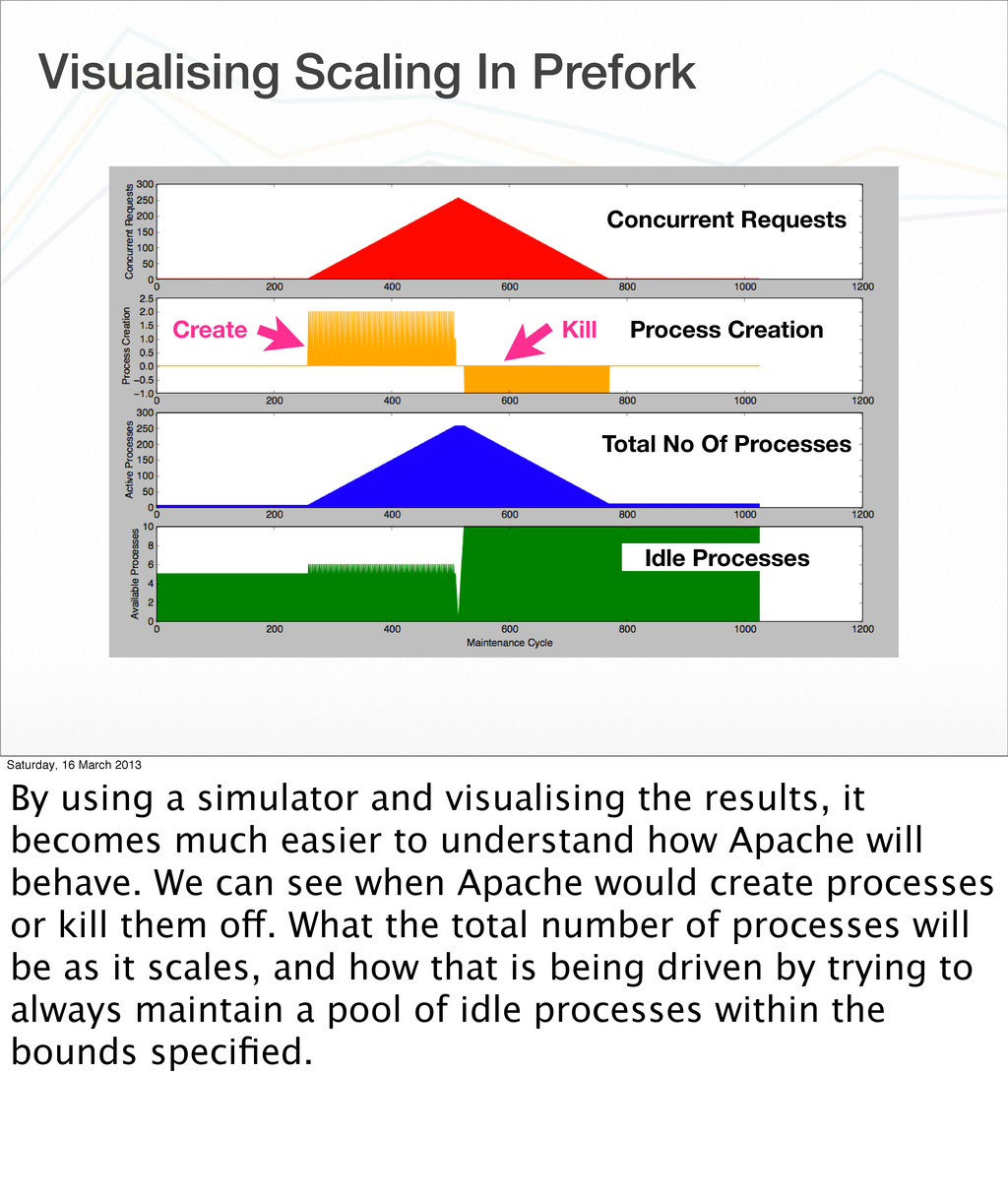
Of Processes Idle Processes Saturday, 16 March 2013 When presented with the MPM settings being used, even I have to think hard sometimes about what the result of those settings will be. To make it easier to understand, I run the settings through a simulator and chart the results. In this example the number of concurrent requests is ramped up from zero and when maximum capacity is reached, it is ramped back down to zero again.
Of Processes Idle Processes Create Kill Saturday, 16 March 2013 By using a simulator and visualising the results, it becomes much easier to understand how Apache will behave. We can see when Apache would create processes or kill them off. What the total number of processes will be as it scales, and how that is being driven by trying to always maintain a pool of idle processes within the bounds specified.
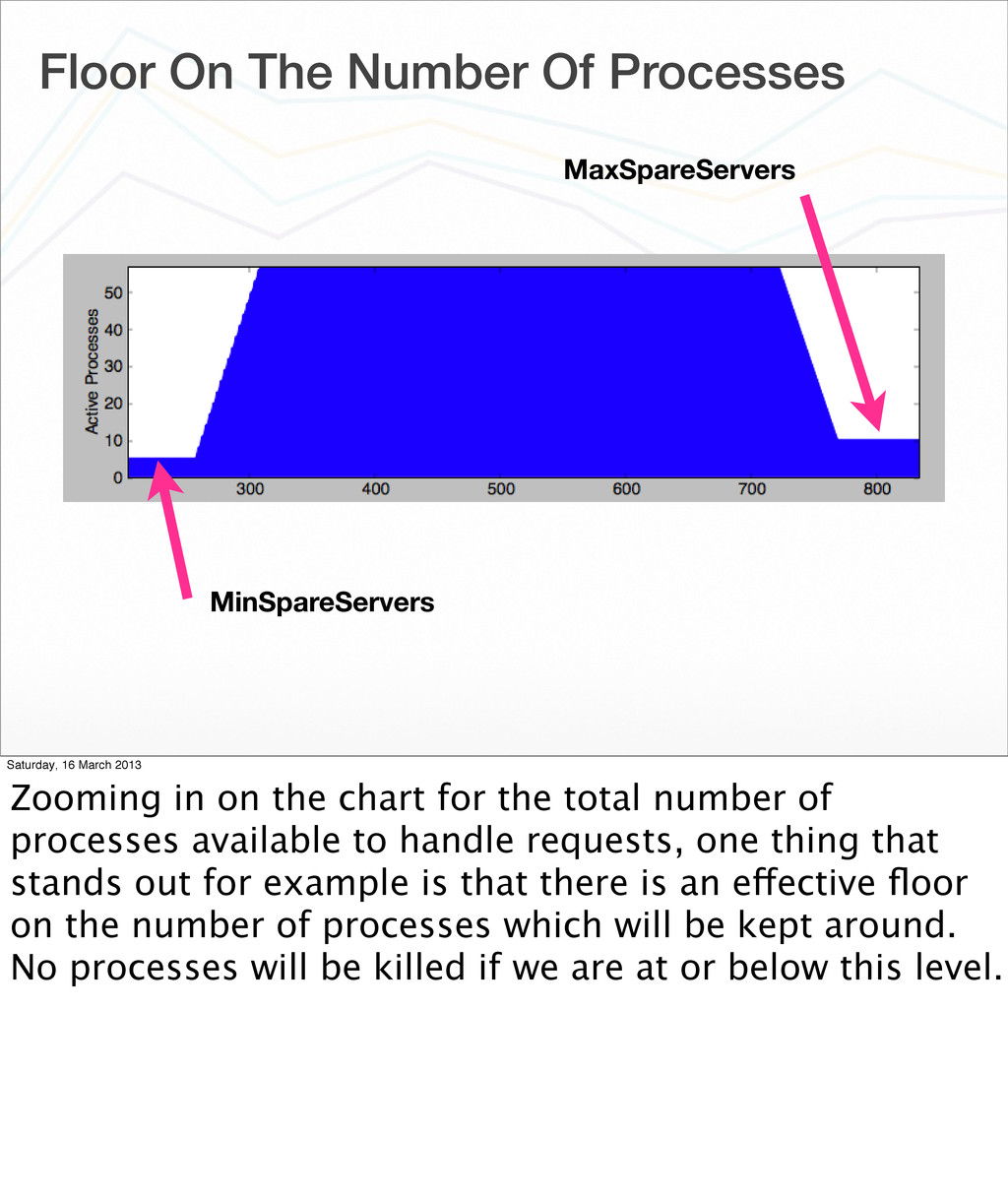
March 2013 Zooming in on the chart for the total number of processes available to handle requests, one thing that stands out for example is that there is an effective floor on the number of processes which will be kept around. No processes will be killed if we are at or below this level.
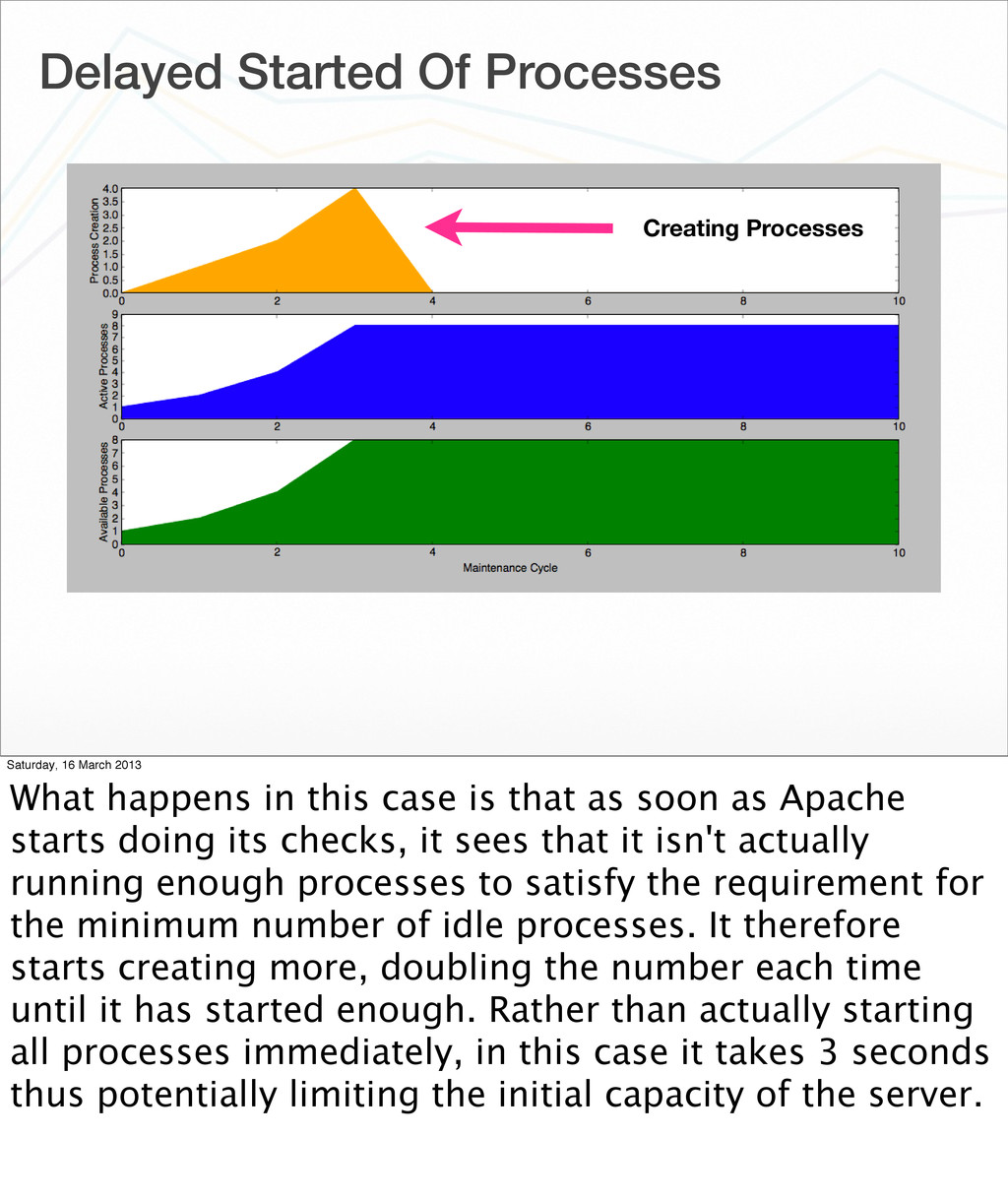
10 MaxClients 256 Saturday, 16 March 2013 Too often, people who have no idea how to configure Apache get in and start mucking around with these values, not understanding the implications of what they are doing. The simulator is great in being able to give a quick visual indicator as to whether something is amiss. One example is where the number of servers to be started is less than the minimum number of spare servers.
What happens in this case is that as soon as Apache starts doing its checks, it sees that it isn't actually running enough processes to satisfy the requirement for the minimum number of idle processes. It therefore starts creating more, doubling the number each time until it has started enough. Rather than actually starting all processes immediately, in this case it takes 3 seconds thus potentially limiting the initial capacity of the server.
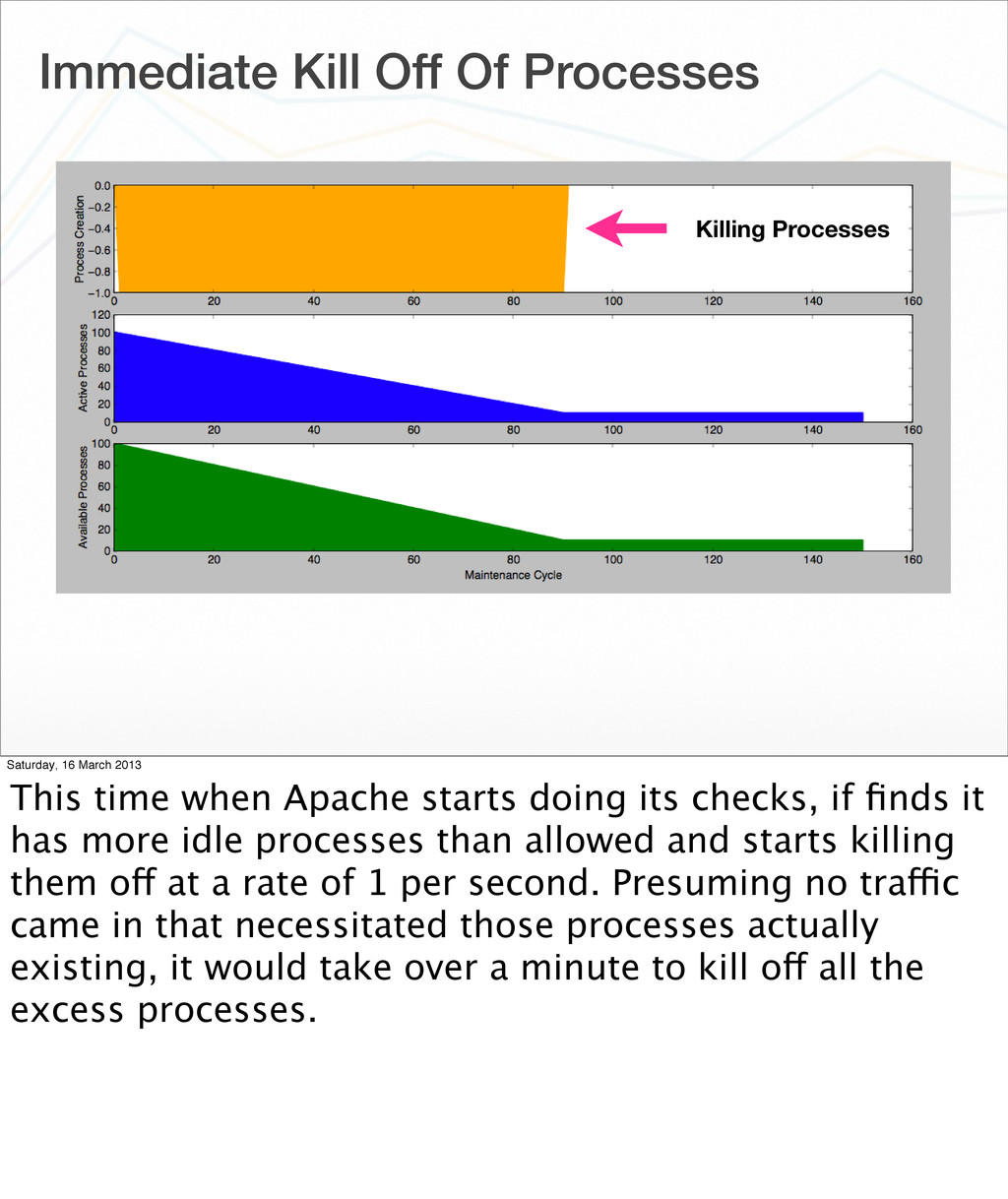
10 MaxClients 256 Saturday, 16 March 2013 At the other end of the scale, we have people who change the number of servers to be started to be greater than the maximum spare allowed.
2013 This time when Apache starts doing its checks, if finds it has more idle processes than allowed and starts killing them off at a rate of 1 per second. Presuming no traffic came in that necessitated those processes actually existing, it would take over a minute to kill off all the excess processes.
than MinSpareServers. If you don't, Apache will set MaxSpareServers to be MinSpareServers+1 for you anyway. • Don't set StartServers to be less than MinSpareServers as it will delay start up of processes so as to reach minimum spare required. • Don't set StartServers to be greater than MaxSpareServers as processes will start to be killed off immediately. Saturday, 16 March 2013 To avoid such delayed process creation, or immediate killing off of processes on startup, you should ensure that the value of StartServers is bounded by MinSpareServers and MaxSpareServers.
• Loading of the WSGI application. • Loading of required standard library modules. • Loading of required third party modules. • Initialisation of the WSGI application. Saturday, 16 March 2013 Why do we care about unnecessary process creation? After all, aren't the processes just a fork of the Apache parent process and so cheap to create? The problem is that unlike mod_php where PHP is initialised and all extension modules preloaded into the Apache parent process, when using mod_wsgi, Python initialisation is deferred until after the processes are forked. Any application code and required Python modules are then lazily loaded.
which WSGI application to load until the first request arrives for it. • Python web applications aren't usually designed properly for preloading prior to forking of worker processes. • All code run in the Apache parent process is run as root. Saturday, 16 March 2013 If initialising Python and loading the WSGI application in the worker process can be expensive, why can't we preload everything in the Apache parent process before the worker processes are forked? Even if a Python web application were designed to be able to be preloaded and run properly after the process was forked, the key issue is that users application code on startup would run as root if executed in the parent process and that is one very big security risk.
memory into the parent process when an Apache restart occurs. Saturday, 16 March 2013 Add to that, because of what Python does (or should I say doesn't do) when the interpreter is destroyed, combined with the way in which Apache reloads mod_wsgi when restarting, the Python interpreter will leak memory into the Apache parent process. If Apache restarts are done on a regular basis, the size of the Apache parent will keep growing over time and thus so will the forked worker processes as well.
new worker process. • Worker processes will not be immediately ready. • No saving in memory usage from copy on write. Saturday, 16 March 2013 So running within Apache we have no choice and have to defer initialisation of Python and loading of the WSGI application until after the child processes are forked. This causes additional CPU load each time a process is started up and the time taken will also mean that requests will be held up. Finally, because we are not preloading in the parent, we cannot benefit from reduced memory usage from copy on write features of the operating system.
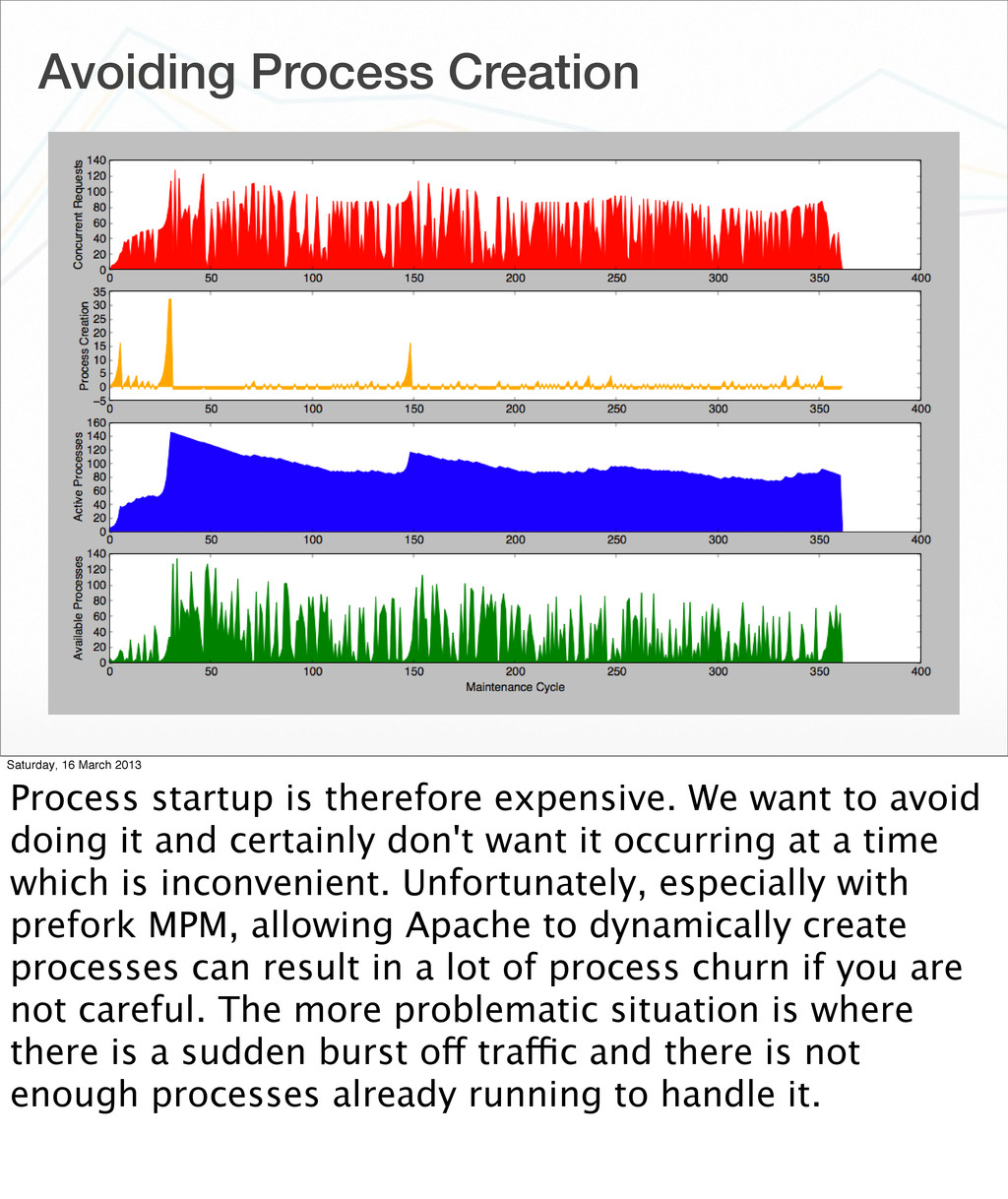
therefore expensive. We want to avoid doing it and certainly don't want it occurring at a time which is inconvenient. Unfortunately, especially with prefork MPM, allowing Apache to dynamically create processes can result in a lot of process churn if you are not careful. The more problematic situation is where there is a sudden burst off traffic and there is not enough processes already running to handle it.
16 March 2013 In the worst case scenario, the increased load from creating processes when a sustained traffic spike occurs, could see the whole system slow down. The slow down can make Apache think it isn't creating enough processes quickly enough, so it keeps creating more and more. Pretty quickly it has created the maximum number of processes, with the combined CPU load of loading the WSGI application for all of them, causing the server to grind to a halt.
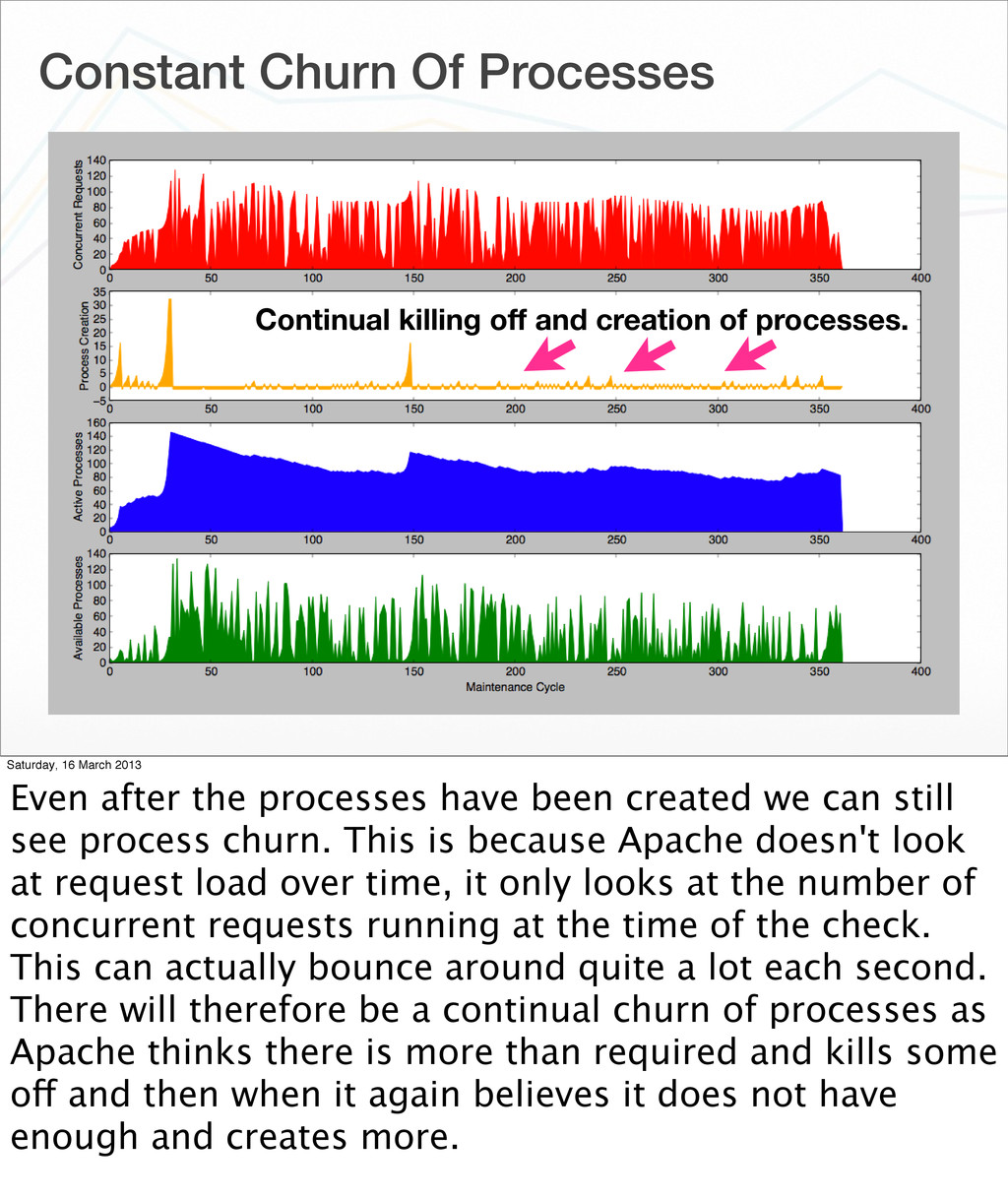
processes. Saturday, 16 March 2013 Even after the processes have been created we can still see process churn. This is because Apache doesn't look at request load over time, it only looks at the number of concurrent requests running at the time of the check. This can actually bounce around quite a lot each second. There will therefore be a continual churn of processes as Apache thinks there is more than required and kills some off and then when it again believes it does not have enough and creates more.
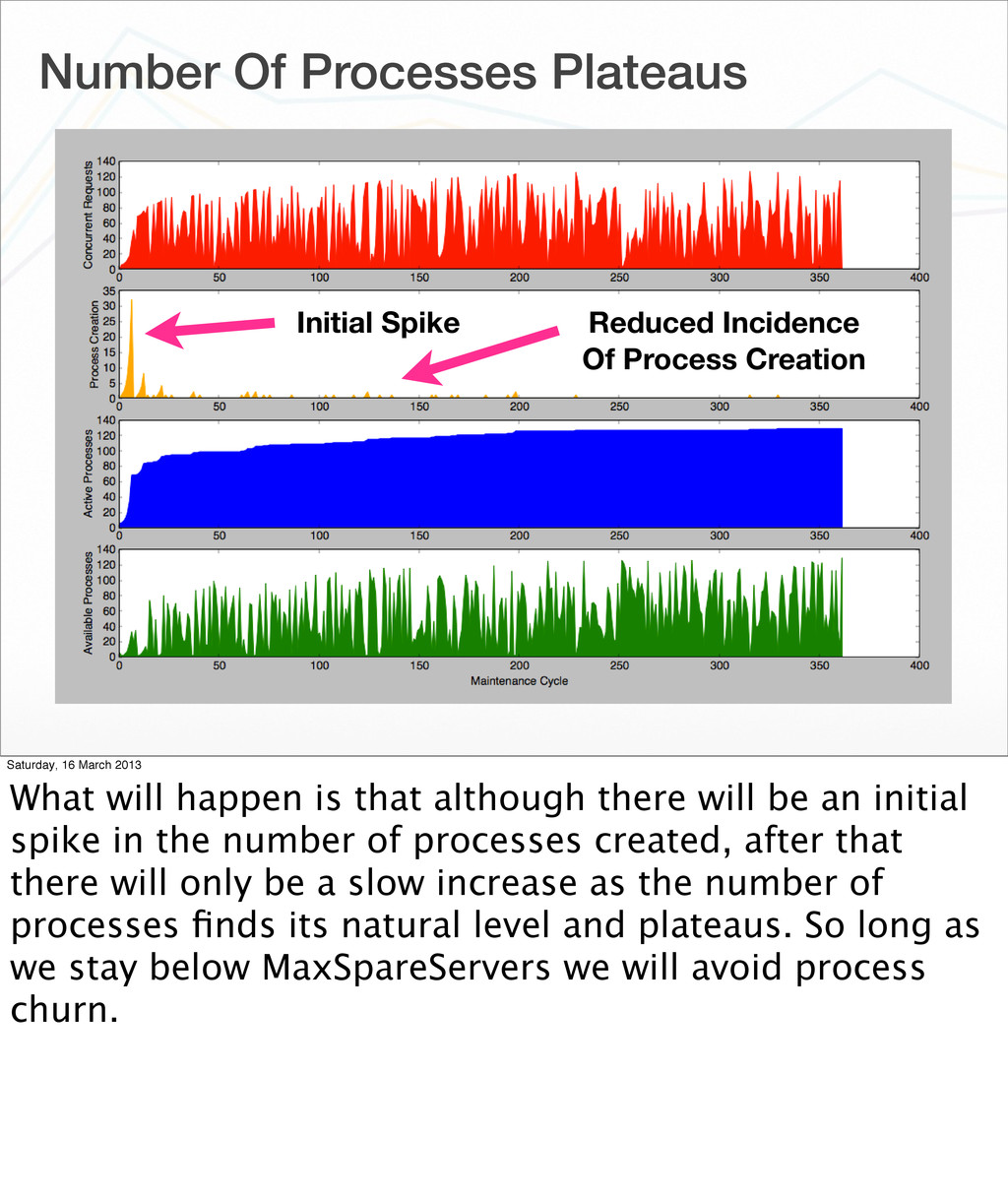
256 Saturday, 16 March 2013 What if we raise that floor on the number of processes as determined by the MaxSpareServers setting? We said that so long as the number of processes was below this level, none would be killed off. Lets try then setting that to a level above the average number of processes in use.
Creation Saturday, 16 March 2013 What will happen is that although there will be an initial spike in the number of processes created, after that there will only be a slow increase as the number of processes finds its natural level and plateaus. So long as we stay below MaxSpareServers we will avoid process churn.
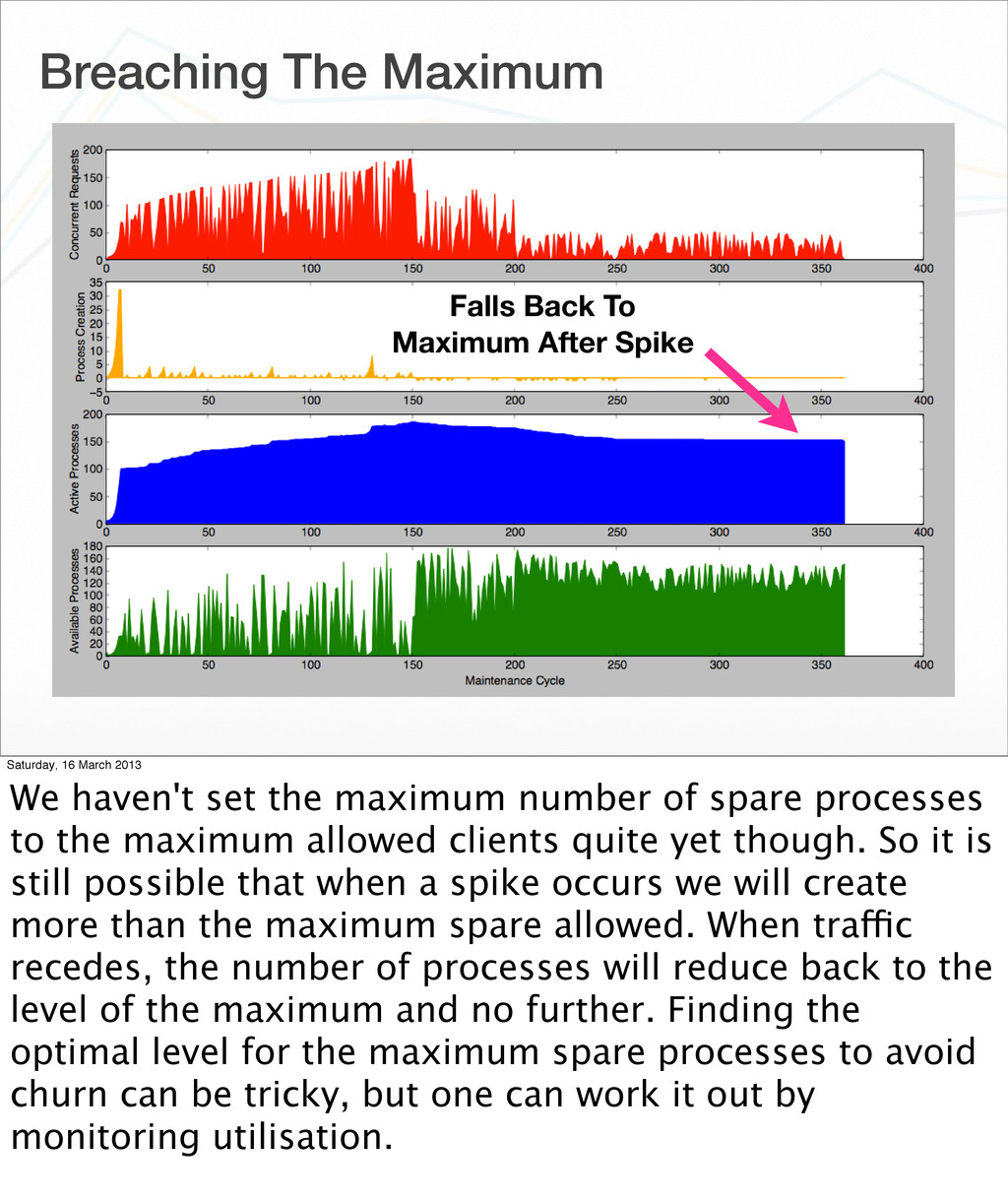
16 March 2013 We haven't set the maximum number of spare processes to the maximum allowed clients quite yet though. So it is still possible that when a spike occurs we will create more than the maximum spare allowed. When traffic recedes, the number of processes will reduce back to the level of the maximum and no further. Finding the optimal level for the maximum spare processes to avoid churn can be tricky, but one can work it out by monitoring utilisation.
Do be aware though that all this work in tuning the settings can be undone by the MaxRequestsPerChild setting. We want to avoid process churn. It is no good setting this to such a low value that this would cause process recycling after a very short period of time, as it just reintroduces process churn in another way. It is better to have this be zero resulting in processes staying persistent in memory until shutdown.
2013 Now the only reason that the defaults for Apache specify such a large value for MaxClients, and thus a large number of processes when single threading is used, is because of slow clients and keep alive. A high number is required to support concurrent sessions from many users. If using single threaded processes though, this means you will need to have much more memory available.
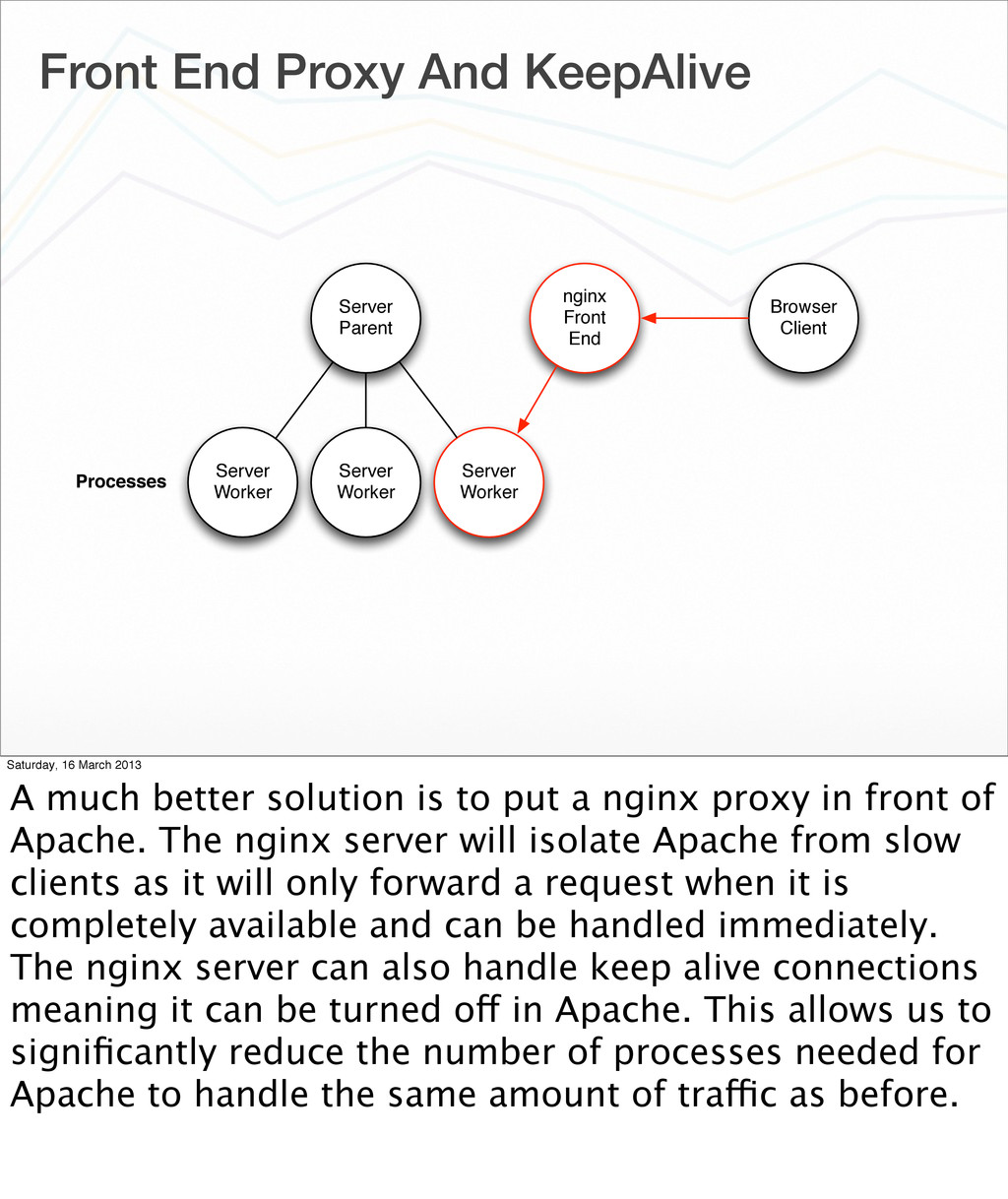
Worker Server Worker Processes nginx Front End Browser Client Saturday, 16 March 2013 A much better solution is to put a nginx proxy in front of Apache. The nginx server will isolate Apache from slow clients as it will only forward a request when it is completely available and can be handled immediately. The nginx server can also handle keep alive connections meaning it can be turned off in Apache. This allows us to significantly reduce the number of processes needed for Apache to handle the same amount of traffic as before.
level above the typical number of concurrent requests you would need to handle. • Do not use MaxRequestsPerChild, especially at a low count which would cause frequent process churn. • Remember that if you don't set MaxRequestsPerChild explicitly, it defaults to 10000. • Use nginx as a front end proxy to isolate Apache from slow clients. • Turn off keep alive in Apache when using nginx as a front end. Saturday, 16 March 2013 Key in eliminating unwanted CPU usage was therefore avoiding process churn which is achieved by adjusting the maximum allowed number of spare processes and ensuring we aren't periodically recycling processes for no good reason. We can though also reduce the number of processes we need in the first place by adding nginx as a proxy in front of Apache.
2013 All of what I have explained so far focused on prefork MPM. I have concentrated on it because it magnifies the problems that can arise. When people say Apache sucks it is usually because they were using prefork MPM with an inadequate configuration. Use of prefork MPM with a nginx proxy will give you the best performance possible if setup correctly. As I said before though, using worker MPM is much more forgiving of you having a poor setup.
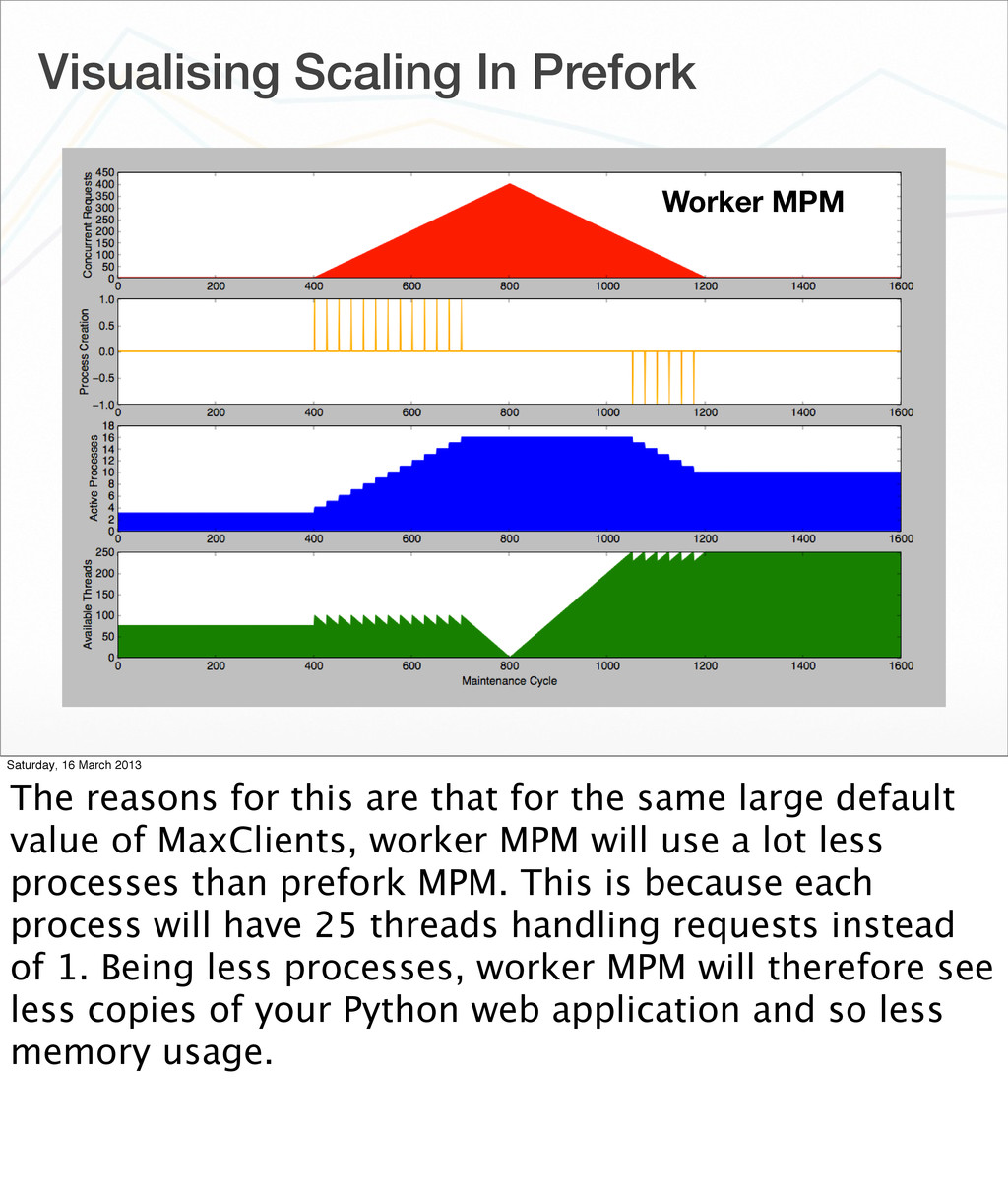
The reasons for this are that for the same large default value of MaxClients, worker MPM will use a lot less processes than prefork MPM. This is because each process will have 25 threads handling requests instead of 1. Being less processes, worker MPM will therefore see less copies of your Python web application and so less memory usage.
250 ThreadsPerChild 25 MaxClients 400 MaxRequestsPerChild 10000 Saturday, 16 March 2013 In the case of worker MPM, by default 3 processes would be started initially with the compiled in defaults. With MaxClients of 400 and ThreadsPerChild being 25, that means a maximum of 16 processes would be created.
idle threads available to handle request spikes. • MaxSpareThreads - Maximum number of idle threads. Saturday, 16 March 2013 Settings related to scaling when using worker MPM refer to threads whereas with prefork MPM they were in terms of processes. MaxSpareThreads defaults to 250, which equates to the equivalent of 10 processes.
at least MinSpareThreads +ThreadsPerChild. If you don't, Apache will set it to that for you anyway. • Suggested that MinSpareThreads and MaxSpareThreads be set as multiples of ThreadsPerChild. • Don't set StartServers to be less than MinSpareThreads/ ThreadsPerChild as it will delay start up of processes so as to reach minimum spare required. • Don't set StartServers to be greater than MaxSpareThreads/ThreadsPerChild as processes will start to be killed off immediately. Saturday, 16 March 2013 One very important thing to note, is that although these are expressed in terms of threads, Apache doesn't scale at the thread level. The number of threads per process is static. When scaling it is the same as prefork, a process will either be created or killed. The decision though is based on available threads instead.
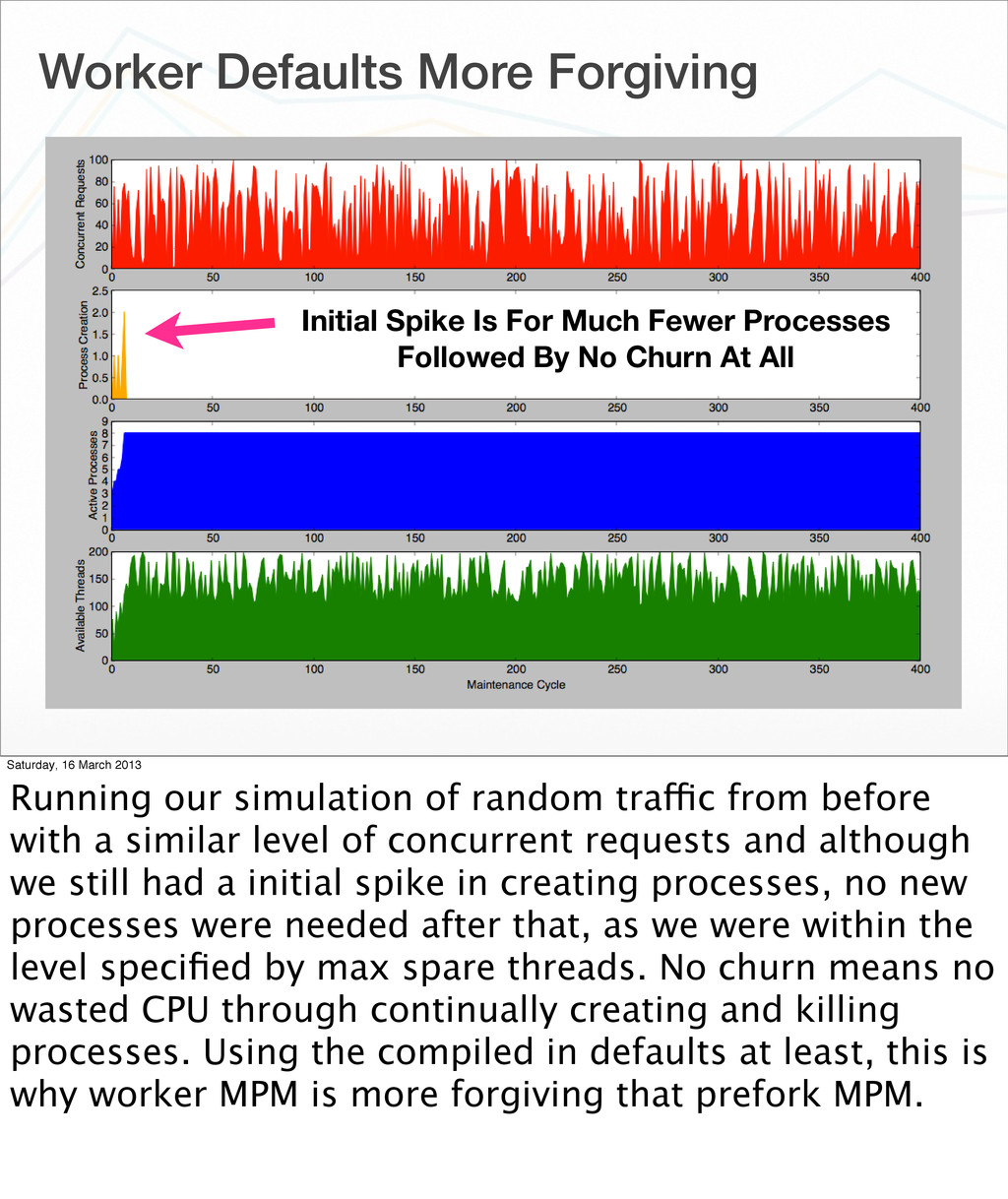
Processes Followed By No Churn At All Saturday, 16 March 2013 Running our simulation of random traffic from before with a similar level of concurrent requests and although we still had a initial spike in creating processes, no new processes were needed after that, as we were within the level specified by max spare threads. No churn means no wasted CPU through continually creating and killing processes. Using the compiled in defaults at least, this is why worker MPM is more forgiving that prefork MPM.
of memory that the main allocator is allowed to hold without calling free(). MaxMemFree 256 # KBytes Saturday, 16 March 2013 As before, and especially if using nginx as a front end proxy, one can adjust MaxClients, min and max spare threads and perhaps bring down even further the amount of resources used. A more important setting though is MaxMemFree. This is the maximum amount of memory the Apache per thread memory pool is allowed to hold before calling free on memory. Prior to Apache 2.4, this was unbounded. In Apache 2.4 it is 2MB.
set and not left to be unbounded. • Even on Apache 2.4 where is 2MB, consider reducing the value further. Saturday, 16 March 2013 Even at 2MB in Apache 2.4, this could mean that for 25 threads, 50MB can be held by the persistent memory pools in each process. When running mod_wsgi, under normal circumstances, there should not be much call for memory to be allocated from the per request memory pool. To be safe though you should ensure MaxMemFree is set and with a reduced value if possible.
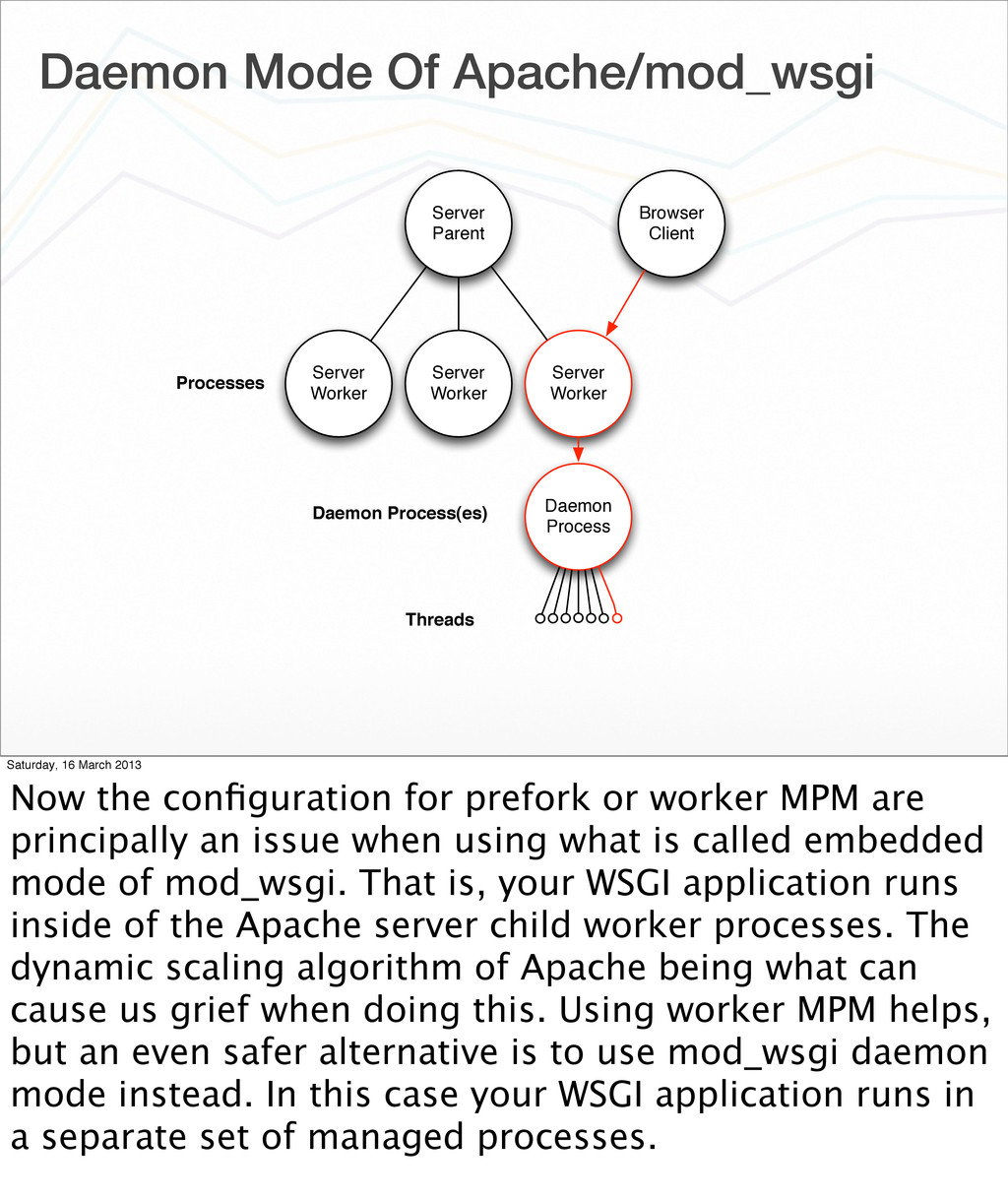
Server Worker Processes Browser Client Daemon Process Threads Daemon Process(es) Saturday, 16 March 2013 Now the configuration for prefork or worker MPM are principally an issue when using what is called embedded mode of mod_wsgi. That is, your WSGI application runs inside of the Apache server child worker processes. The dynamic scaling algorithm of Apache being what can cause us grief when doing this. Using worker MPM helps, but an even safer alternative is to use mod_wsgi daemon mode instead. In this case your WSGI application runs in a separate set of managed processes.
\ process-group=myapp application-group=%{GLOBAL} Saturday, 16 March 2013 The main difference when using daemon mode is that there is no automatic scaling of the number of processes. The number of processes and threads is instead fixed. Being fixed everything is more predictable and you only need to ensure you have sufficient capacity. Using daemon mode, the need to have nginx as a front end is reduced as the Apache server child worker processes are serving much the same process in isolating the WSGI application from slow clients.
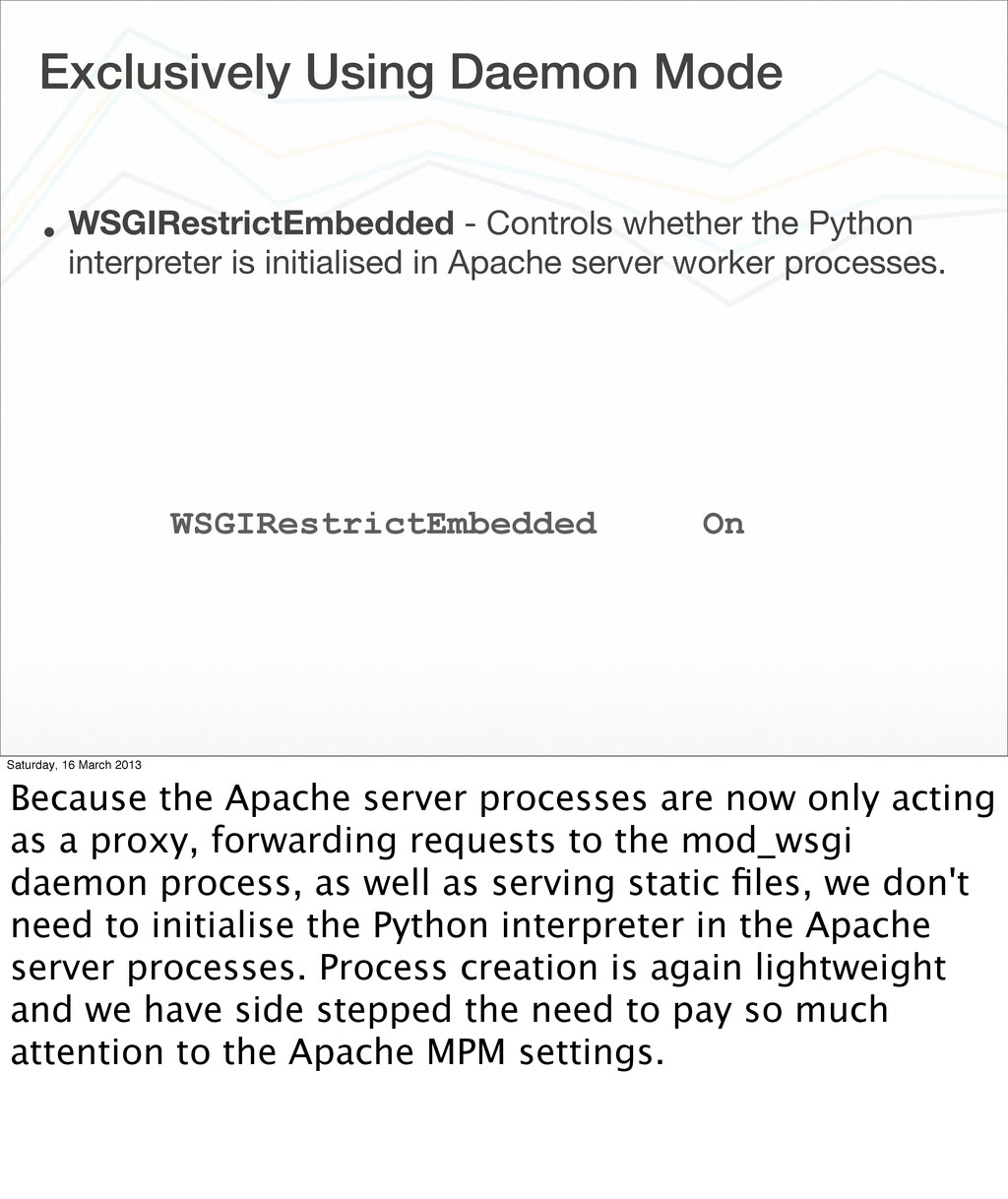
whether the Python interpreter is initialised in Apache server worker processes. Saturday, 16 March 2013 Because the Apache server processes are now only acting as a proxy, forwarding requests to the mod_wsgi daemon process, as well as serving static files, we don't need to initialise the Python interpreter in the Apache server processes. Process creation is again lightweight and we have side stepped the need to pay so much attention to the Apache MPM settings.
dynamically scaling processes which isn't particularly suited to embedded Python web applications. • Default MPM and settings which magnify the issues which can arise with dynamic scaling when running Python web applications. • A concurrency mechanism that can use a lot of memory for a high number of concurrent requests, especially around handling of keep alive connections. • Defaults for memory pool sizes which cause Apache to be heavyweight on memory usage. Saturday, 16 March 2013 So Apache can certainly be a challenging environment for running Python web applications. The main pain points are how its algorithm for dynamic scaling works and memory requirements to support high concurrency. With careful attention it is possible though to configure Apache to reduce the problems these can cause.
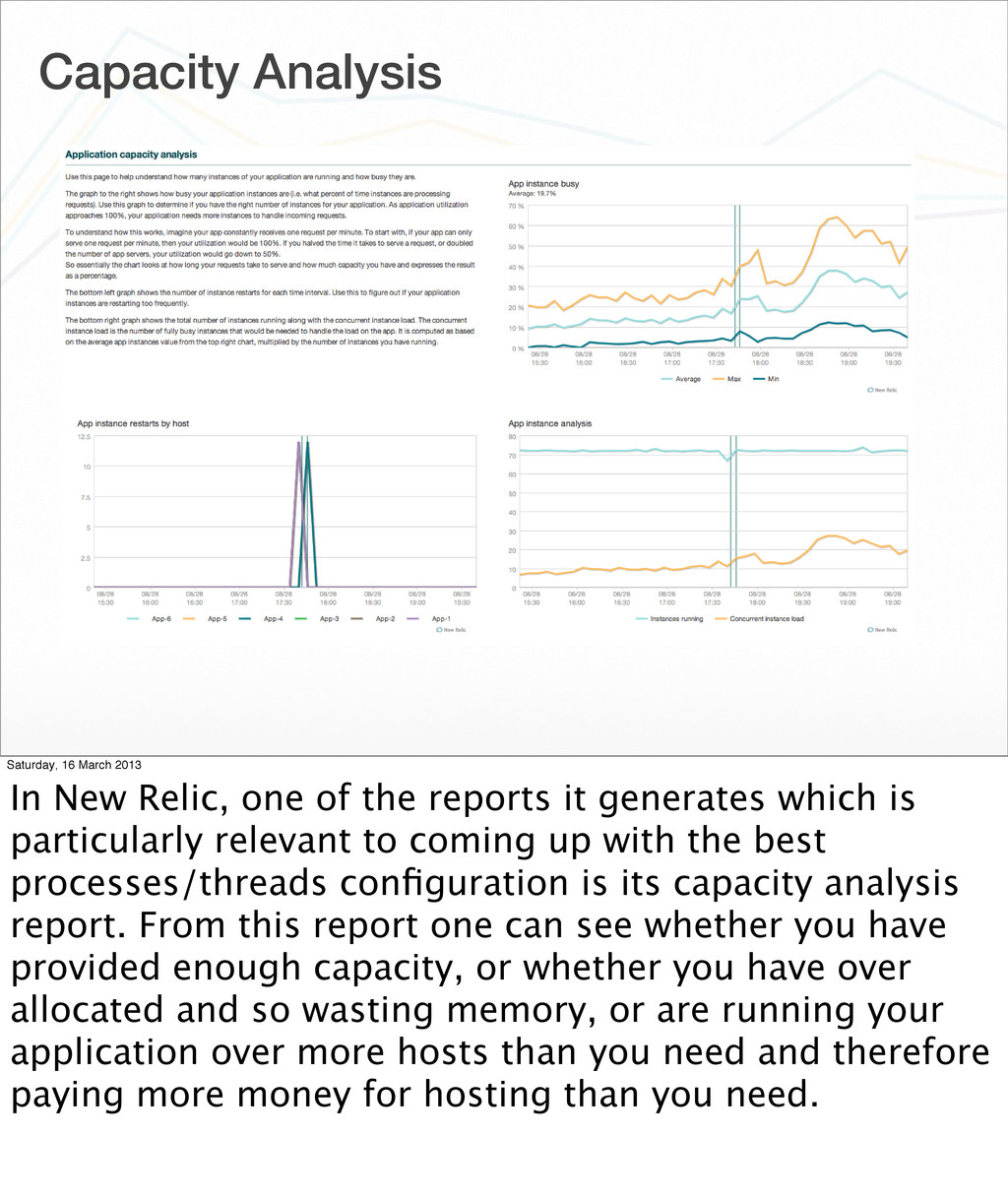
demonstrated can be used to try and validate any configuration before you use it, but the random nature of web site traffic means that it will not be conclusive. This is where live monitoring of traffic in your production web site provides a much better level of feedback. New Relic is obviously the package I would like to see you using, but any monitoring is better than none.
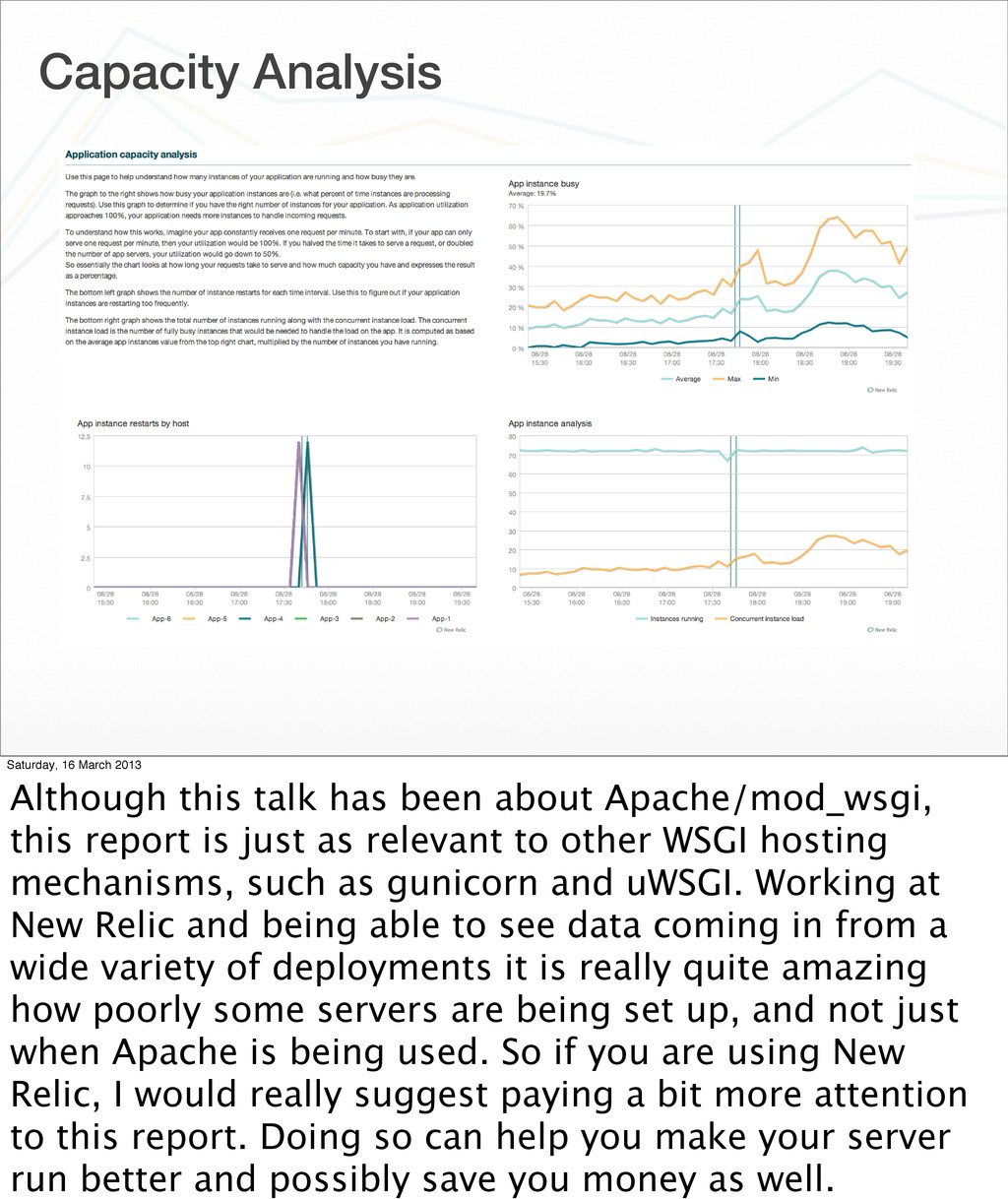
of the reports it generates which is particularly relevant to coming up with the best processes/threads configuration is its capacity analysis report. From this report one can see whether you have provided enough capacity, or whether you have over allocated and so wasting memory, or are running your application over more hosts than you need and therefore paying more money for hosting than you need.
been about Apache/mod_wsgi, this report is just as relevant to other WSGI hosting mechanisms, such as gunicorn and uWSGI. Working at New Relic and being able to see data coming in from a wide variety of deployments it is really quite amazing how poorly some servers are being set up, and not just when Apache is being used. So if you are using New Relic, I would really suggest paying a bit more attention to this report. Doing so can help you make your server run better and possibly save you money as well.
Apache/mod_wsgi mailing list (preferred contact point). • http://groups.google.com/group/modwsgi • New Relic (Application Performance Monitoring) • http://newrelic.com • http://newrelic.com/pycon (special 30 day promo code - pycon13) • Personal blog posts on Apache/mod_wsgi and WSGI. • http://blog.dscpl.com.au • If you really really must bother me directly. • [email protected] • @GrahamDumpleton Saturday, 16 March 2013 And that is all I want to cover today. If you are after more information, especially if you are interested in the simulator I demonstrated, keep an eye on my blog for more details of that sometime in the near future. If you are interested in using New Relic to better configure your WSGI server, then you can catch me in the expo hall after the talk. Questions?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}