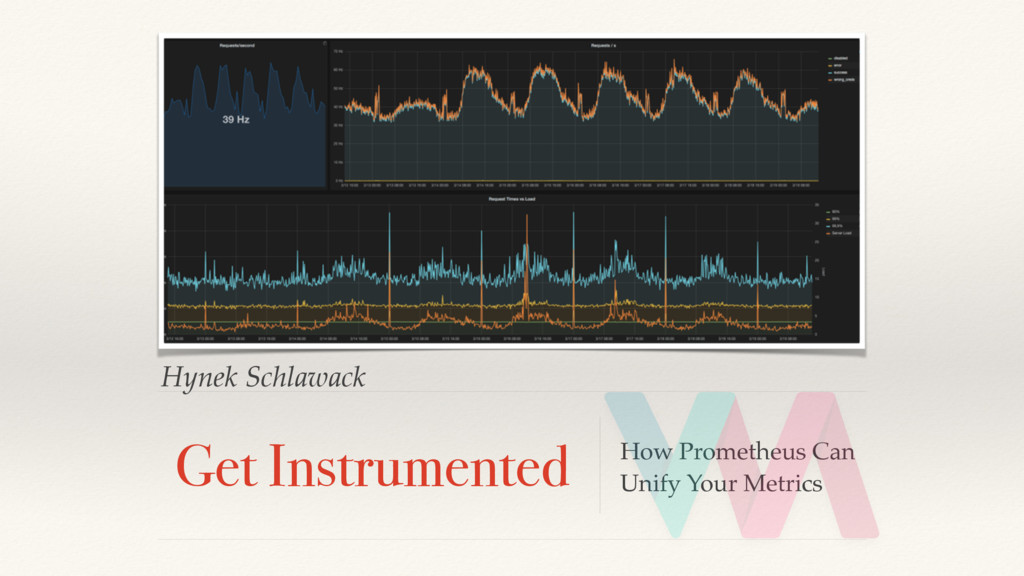
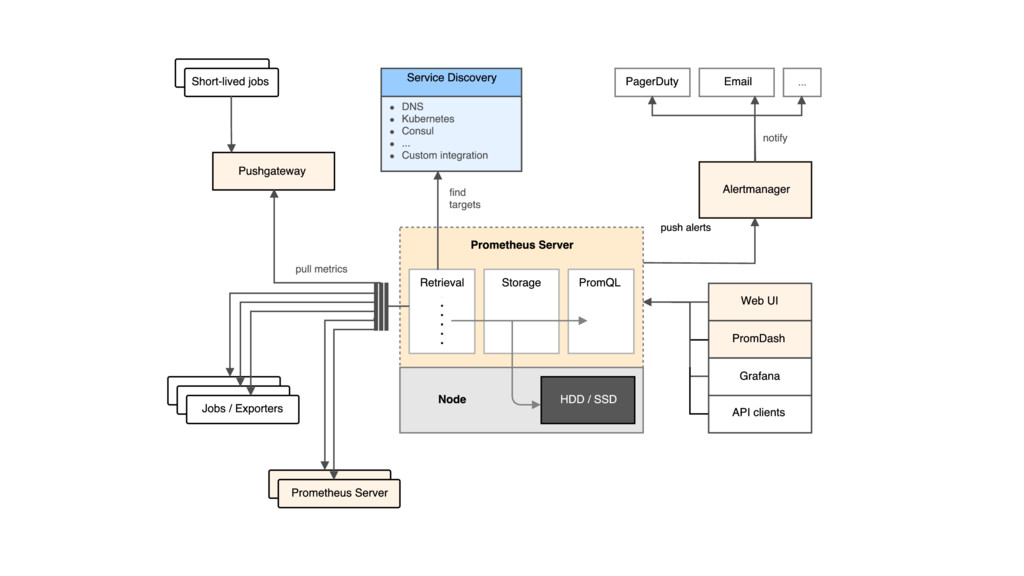
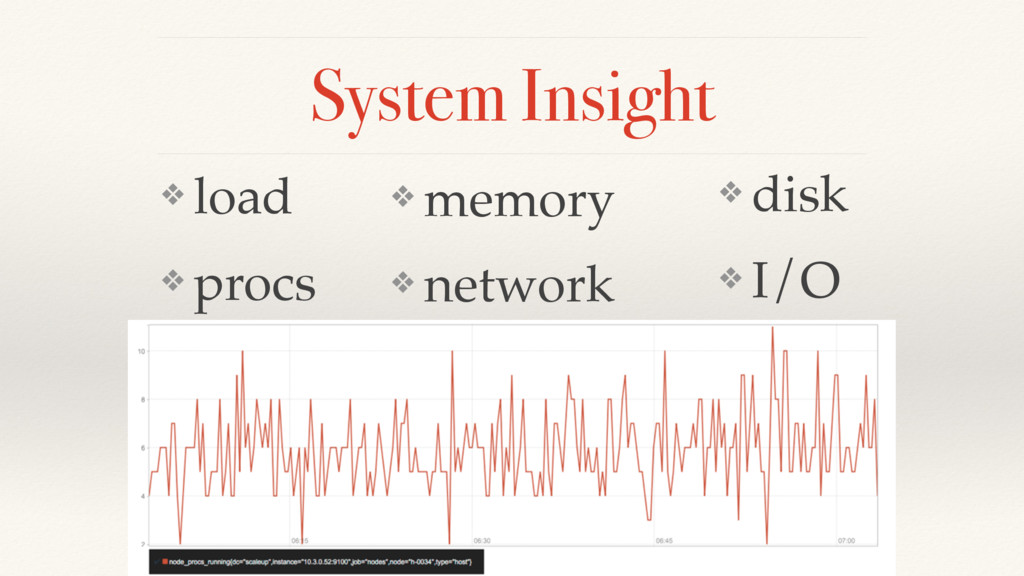
Metrics are highly superior to logging in regards of understanding the past, presence, and future of your applications and systems. They are cheap to gather (just increment a number!) but setting up a metrics system to collect and store them is a major task.
You may have heard of statsd, Riemann, Graphite, InfluxDB, or OpenTSB. They all look promising but on a closer look it’s apparent that some of those solutions are straight-out flawed and others are hard to integrate with each other or even to get up and running.
Then came Prometheus and gave us independence of UDP, no complex math in your application, multi-dimensional data by adding labels to values (no more server names in your metric names!), baked in monitoring capabilities, integration with many common systems, and official clients for all major programming languages. In short: a unified way to gather, process, and present metrics.
This talk will:
explain why you want to collect metrics,
give an overview of the problems with existing solutions,
try to convince you that Prometheus may be what you’ve been waiting for,
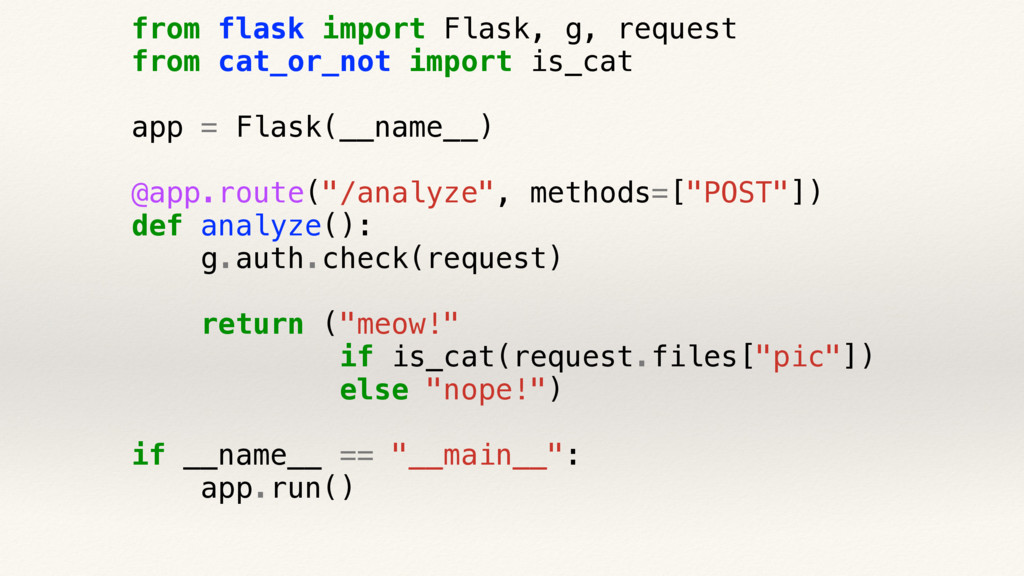
teach how to impress your co-workers with beautiful graphs and intelligent monitoring by putting a fully instrumented Python application into production,
and finally give you pointers on how to migrate an existing metrics infrastructure to Prometheus or how to integrate Prometheus therein.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
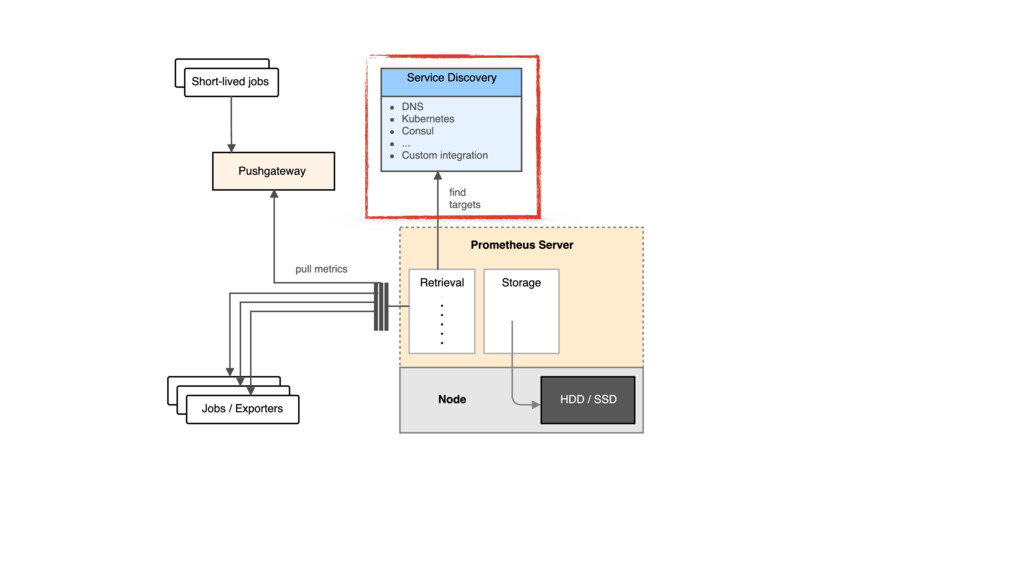{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
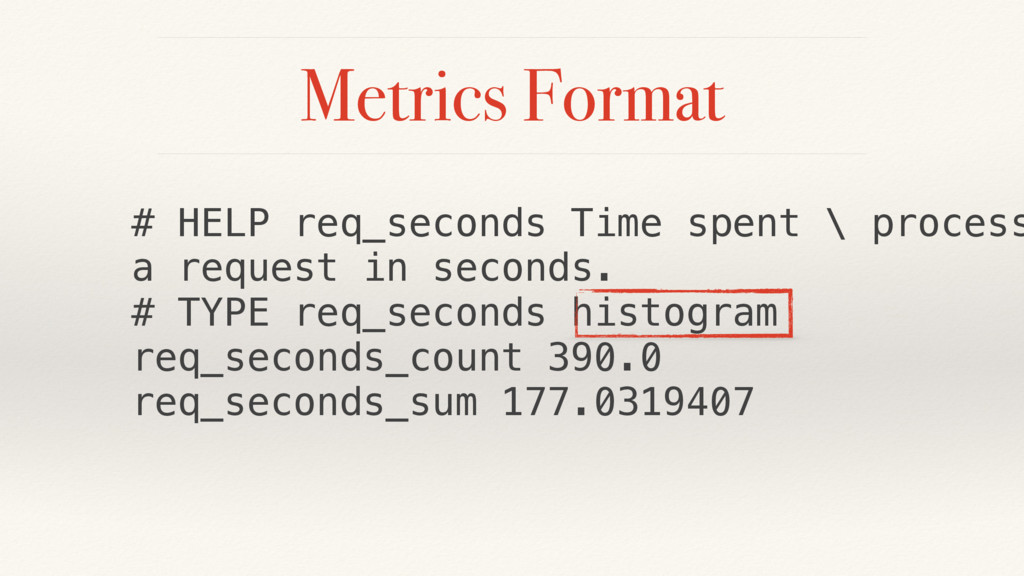{kind=link}
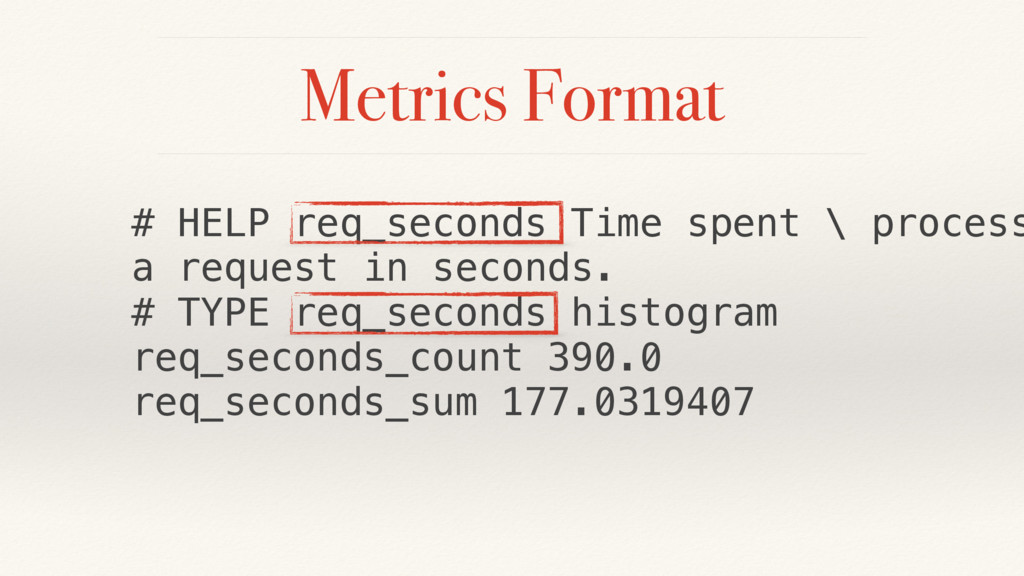{kind=link}
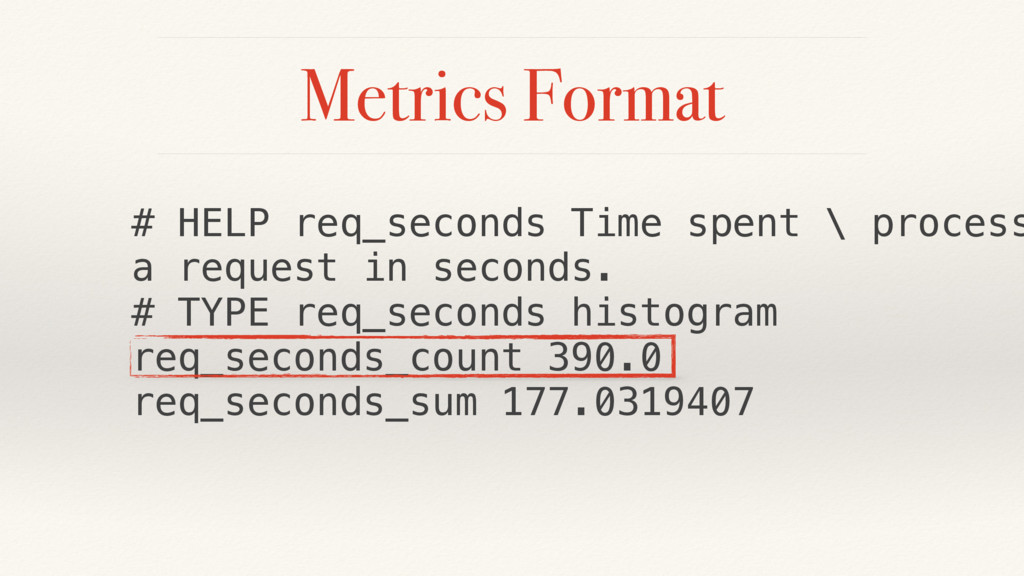{kind=link}
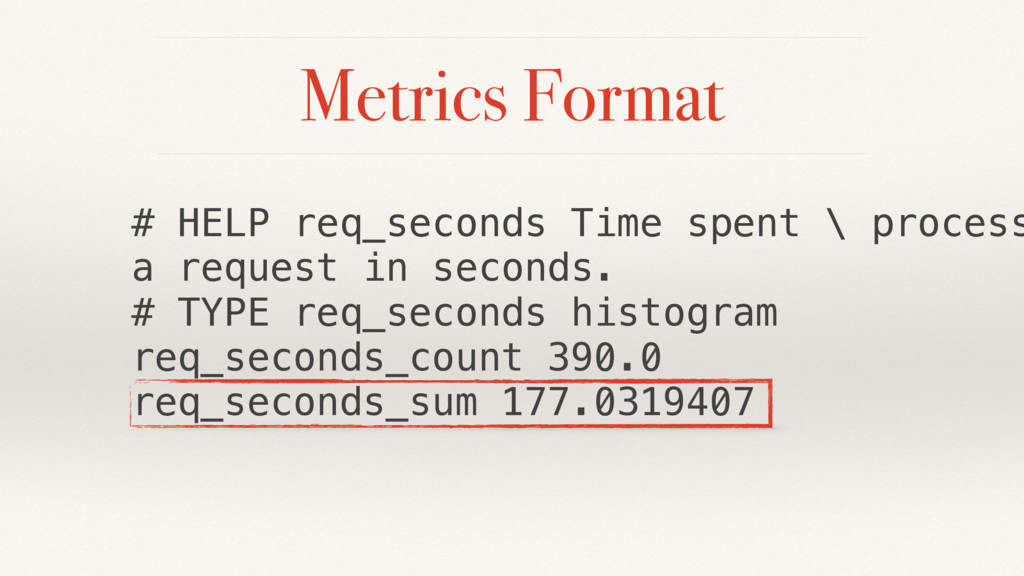{kind=link}
{kind=link}
{kind=link}
{kind=link}
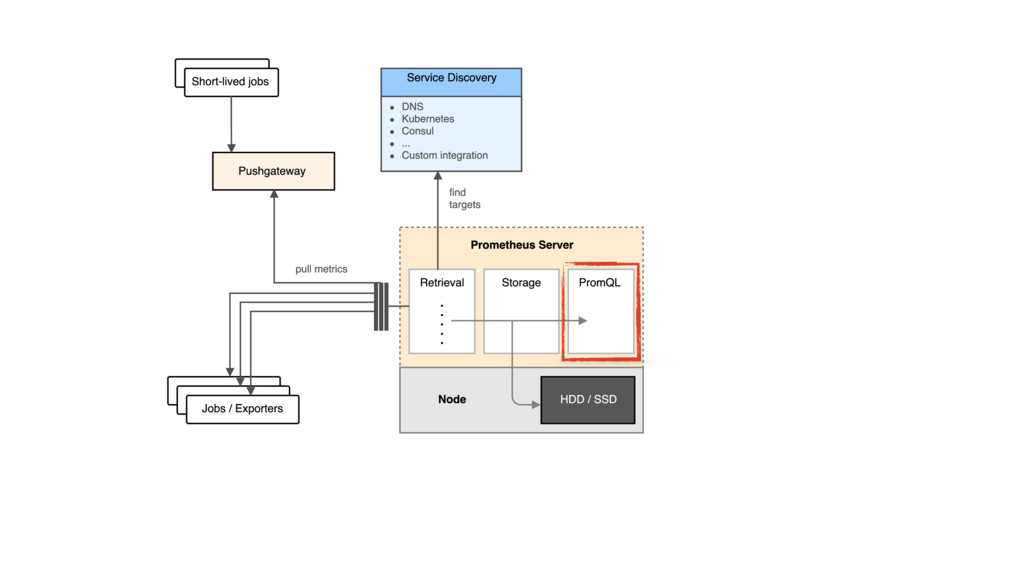{kind=link}
{kind=link}
![Aggregation sum( rate( req_seconds_count[1m] ) )](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_62.jpg){kind=link}
![Aggregation sum( rate( req_seconds_count[1m] ) )](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_63.jpg){kind=link}
![Aggregation sum( rate( req_seconds_count[1m] ) )](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_64.jpg){kind=link}
![Aggregation sum( rate( req_seconds_count[1m] ) )](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_65.jpg){kind=link}
![Aggregation sum( rate( req_seconds_count{dc="west"}[1m] ) )](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_66.jpg){kind=link}
![Aggregation sum( rate( req_seconds_count[1m] ) ) by (dc)](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_67.jpg){kind=link}
![Percentiles histogram_quantile( 0.9, rate( req_seconds_bucket[10m] ))](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_68.jpg){kind=link}
![Percentiles histogram_quantile( 0.9, rate( req_seconds_bucket[10m] ))](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_69.jpg){kind=link}
![Percentiles histogram_quantile( 0.9, rate( req_seconds_bucket[10m] ))](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_70.jpg){kind=link}
![Percentiles histogram_quantile( 0.9, rate( req_seconds_bucket[10m] ))](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_71.jpg){kind=link}
![Percentiles histogram_quantile( 0.9, rate( req_seconds_bucket[10m] ))](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_72.jpg){kind=link}
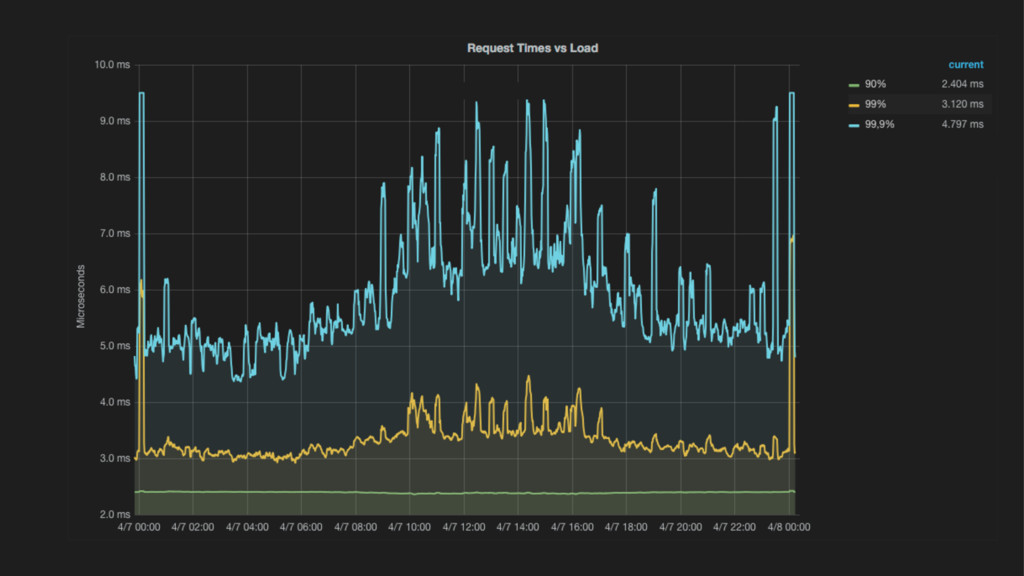{kind=link}
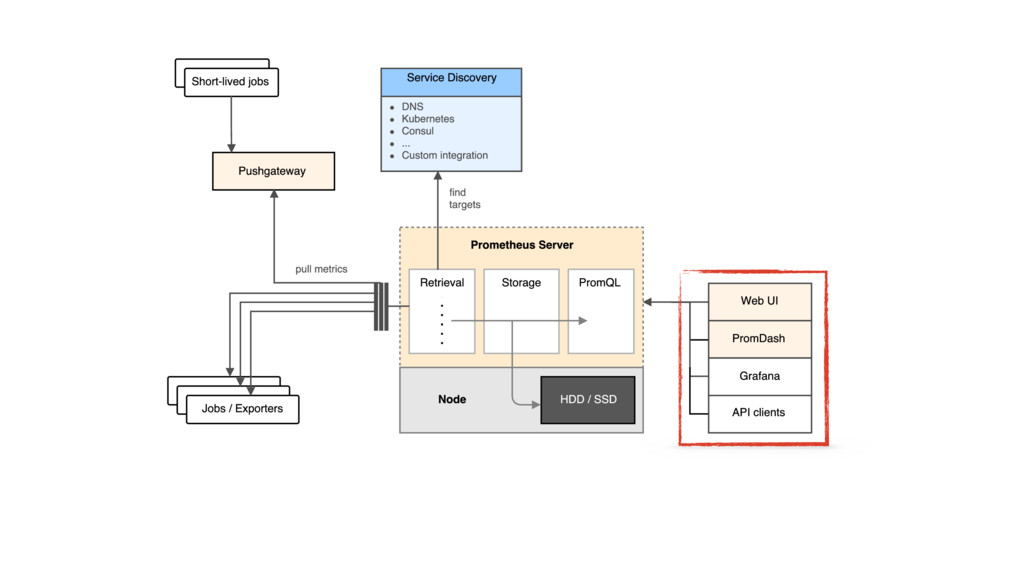{kind=link}
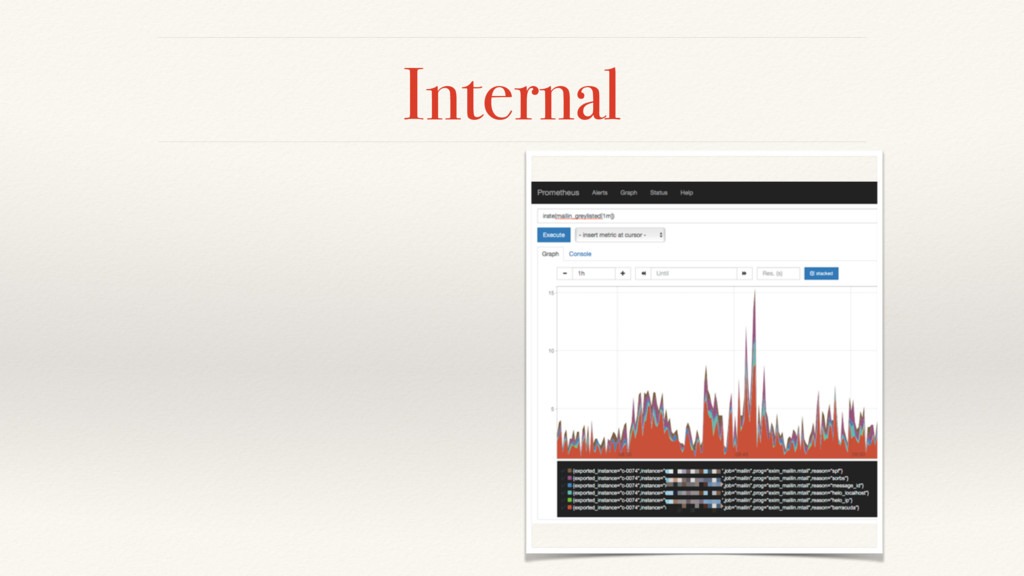{kind=link}
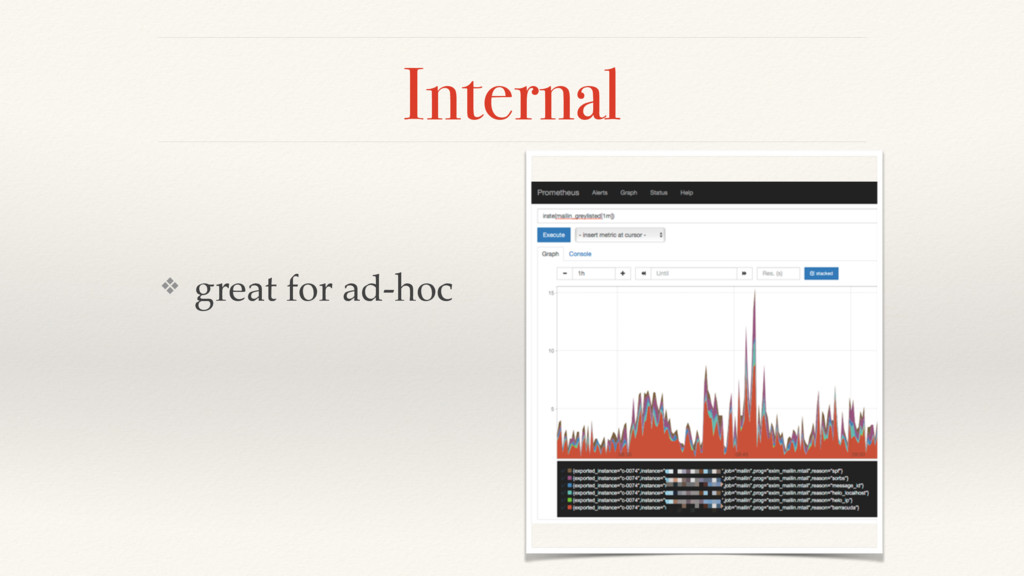{kind=link}
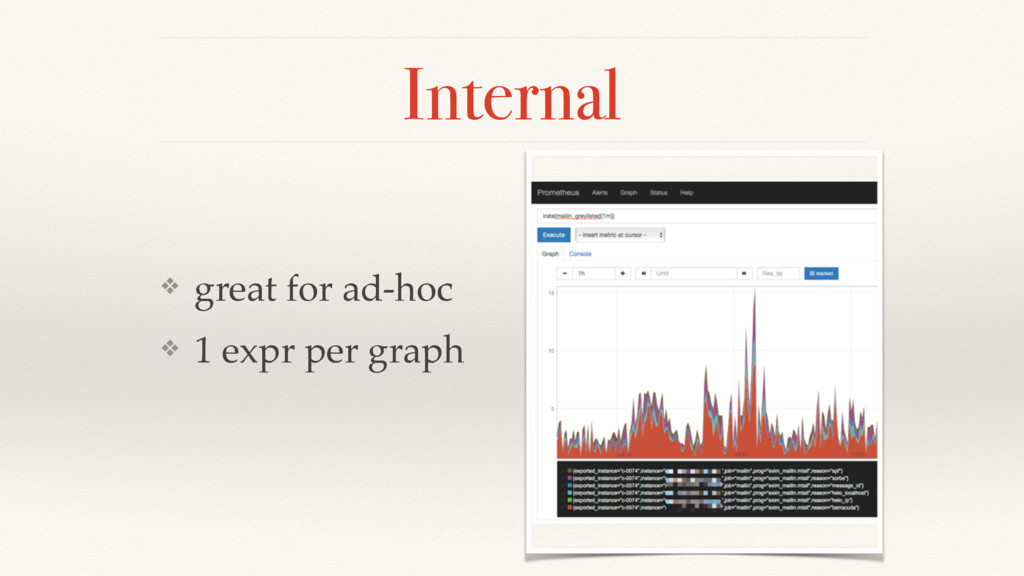{kind=link}
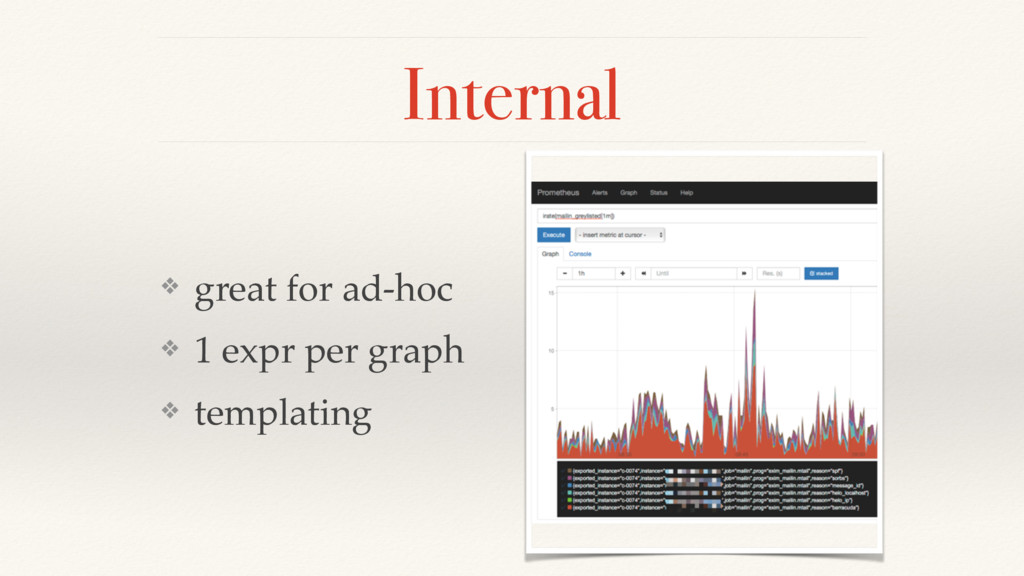{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
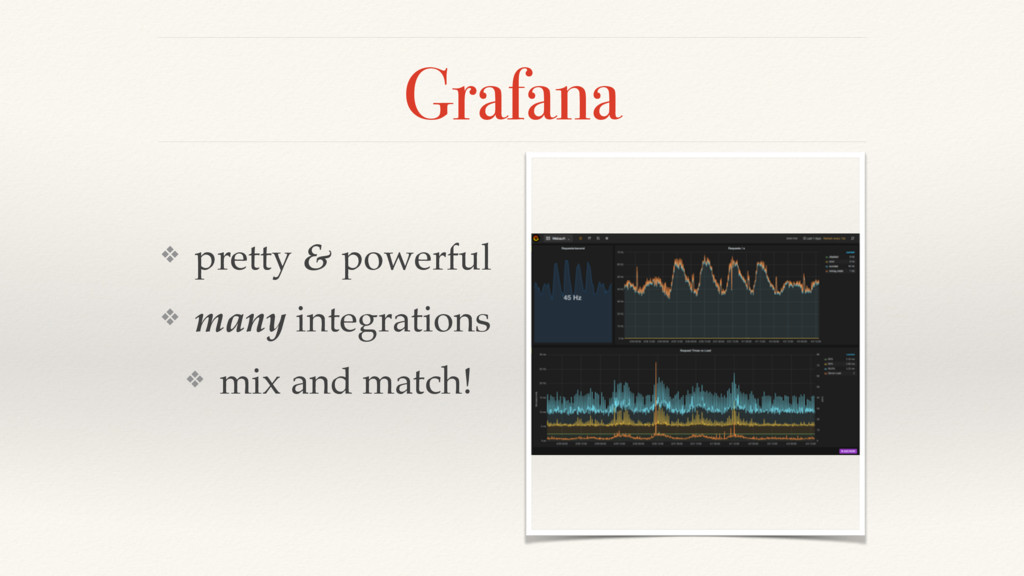{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Alerts & Scrying ALERT DiskWillFillIn4Hours IF predict_linear( node_filesystem_free[1h], 4*3600) <](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_88.jpg){kind=link}
![Alerts & Scrying ALERT DiskWillFillIn4Hours IF predict_linear( node_filesystem_free[1h], 4*3600) <](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_89.jpg){kind=link}
![Alerts & Scrying ALERT DiskWillFillIn4Hours IF predict_linear( node_filesystem_free[1h], 4*3600) <](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_90.jpg){kind=link}
![Alerts & Scrying ALERT DiskWillFillIn4Hours IF predict_linear( node_filesystem_free[1h], 4*3600) <](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_91.jpg){kind=link}
![Alerts & Scrying ALERT DiskWillFillIn4Hours IF predict_linear( node_filesystem_free[1h], 4*3600) <](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_92.jpg){kind=link}
![Alerts & Scrying ALERT DiskWillFillIn4Hours IF predict_linear( node_filesystem_free[1h], 4*3600) <](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_93.jpg){kind=link}
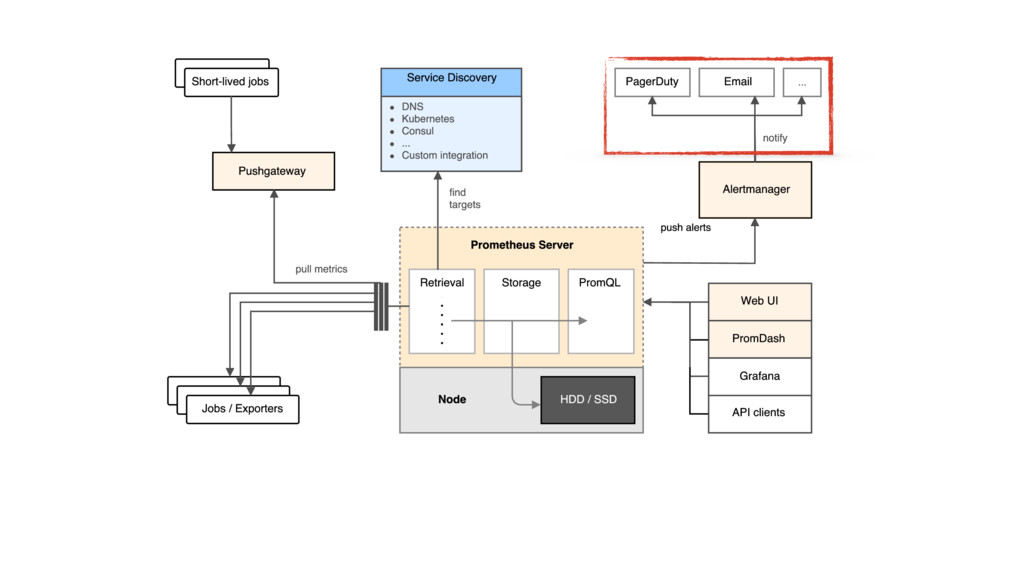{kind=link}
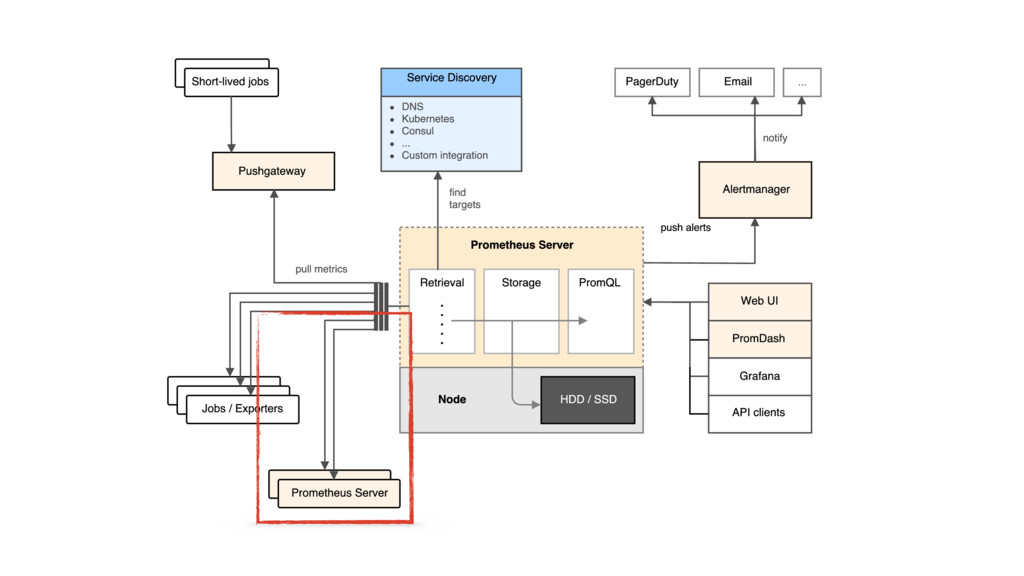{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
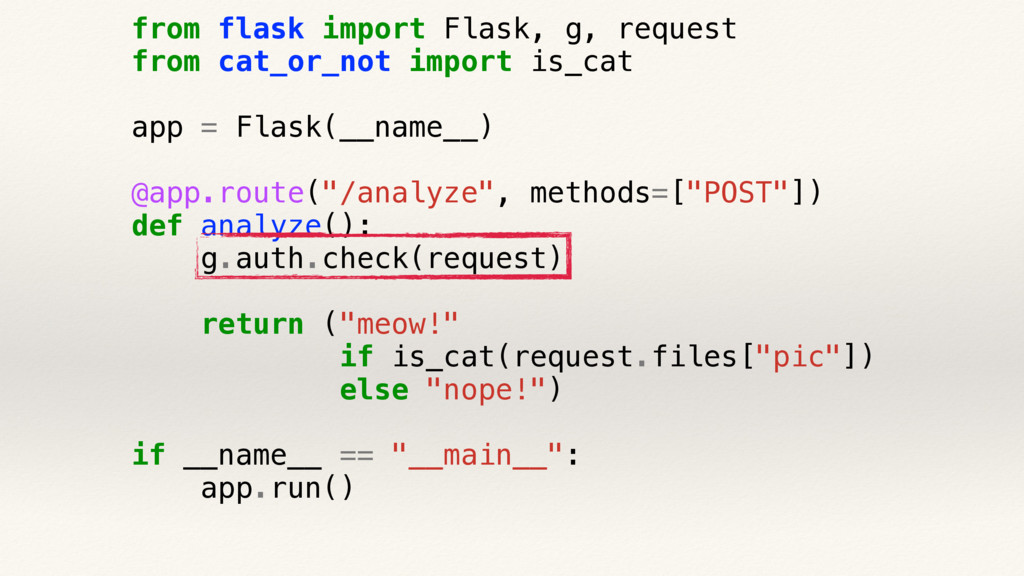{kind=link}
{kind=link}
{kind=link}
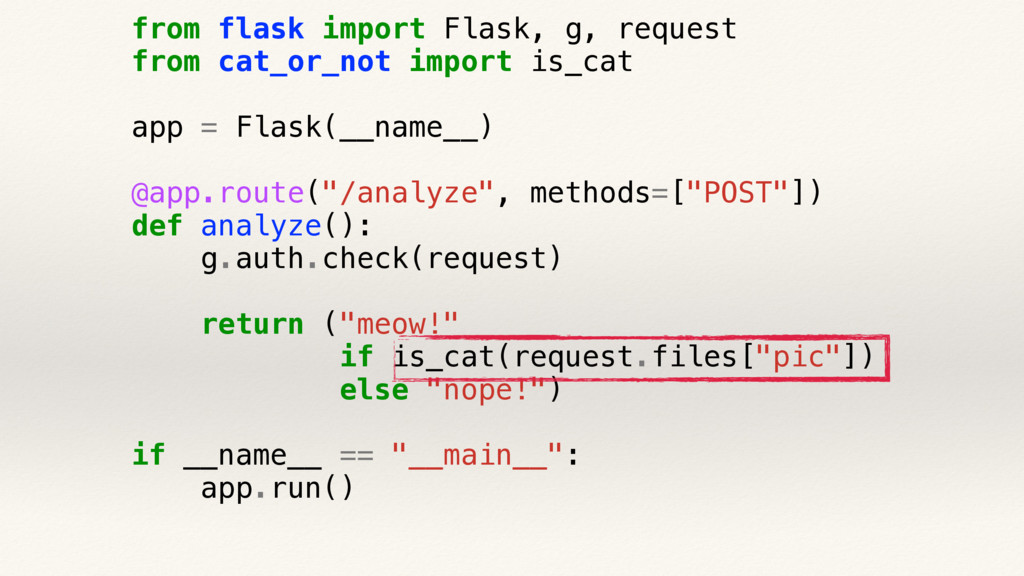
{kind=link}
{kind=link}
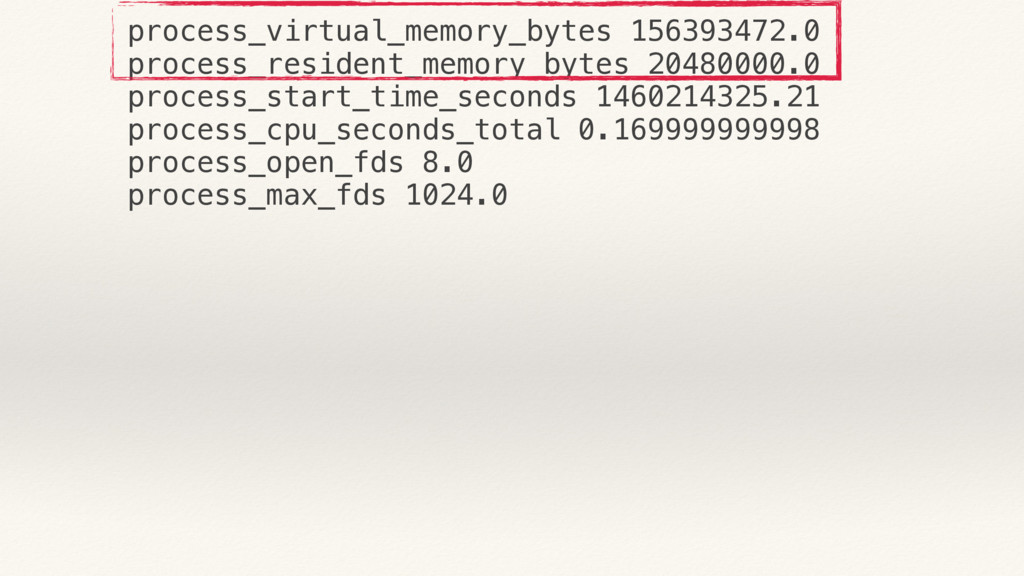{kind=link}
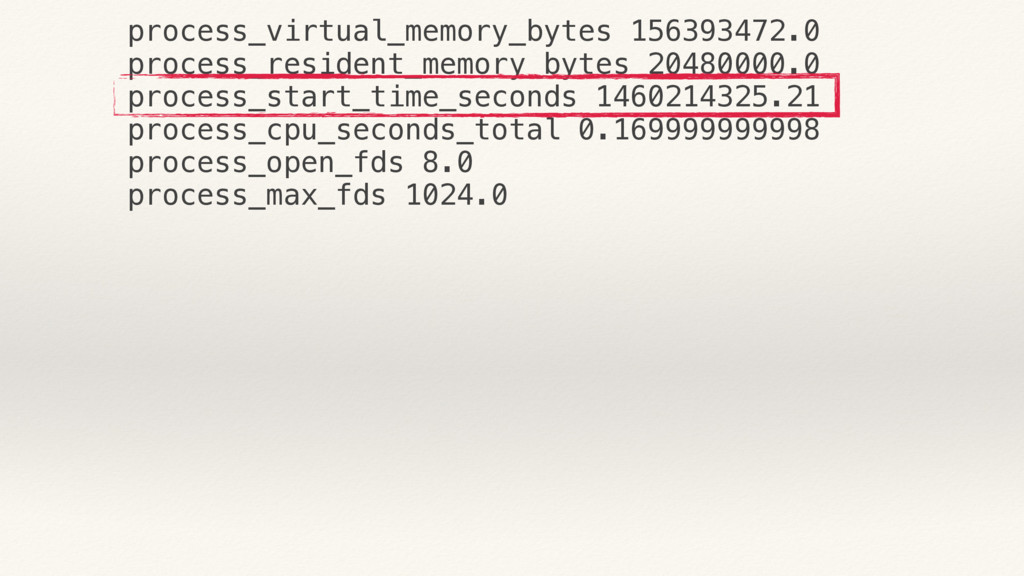{kind=link}
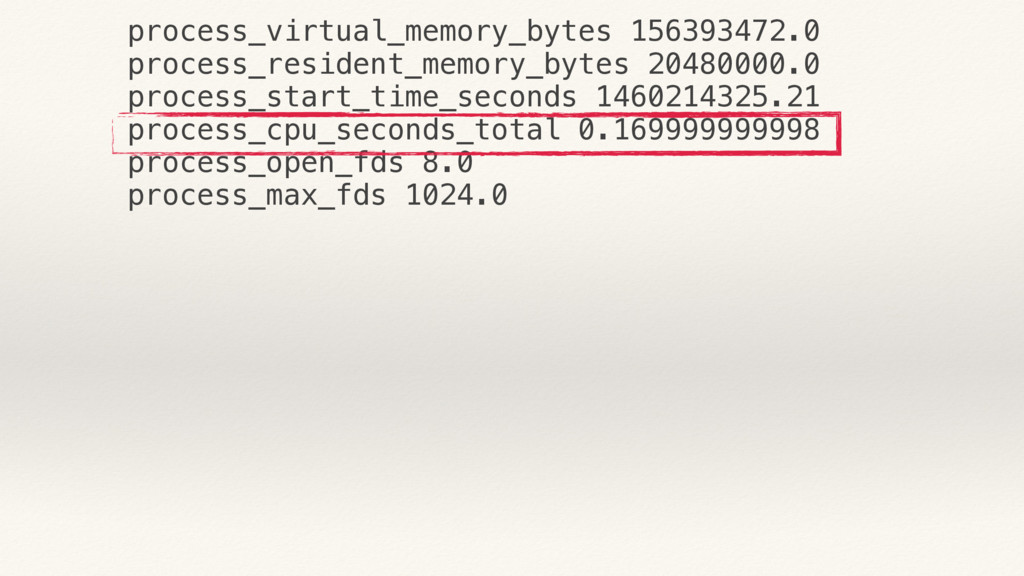{kind=link}
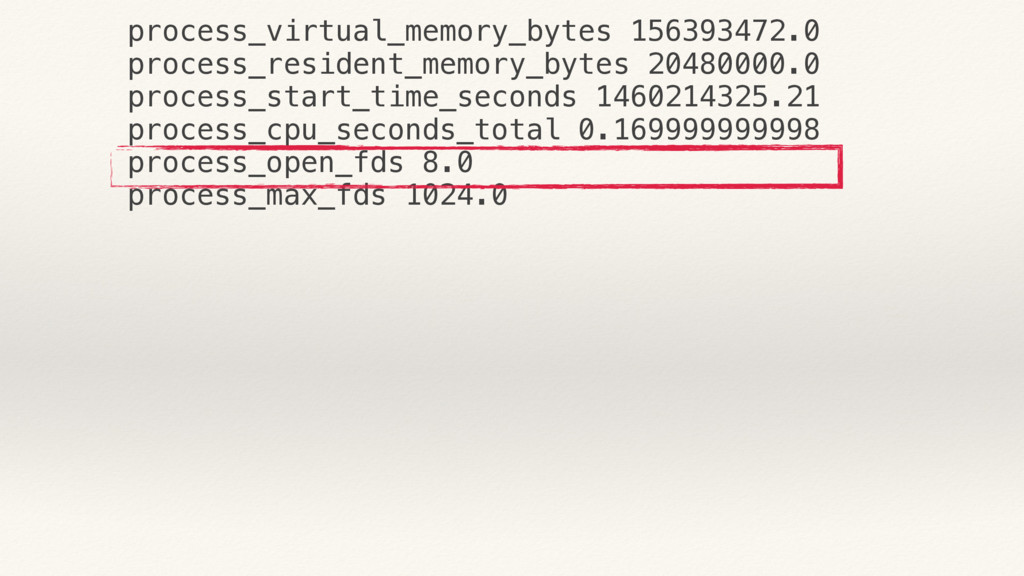{kind=link}
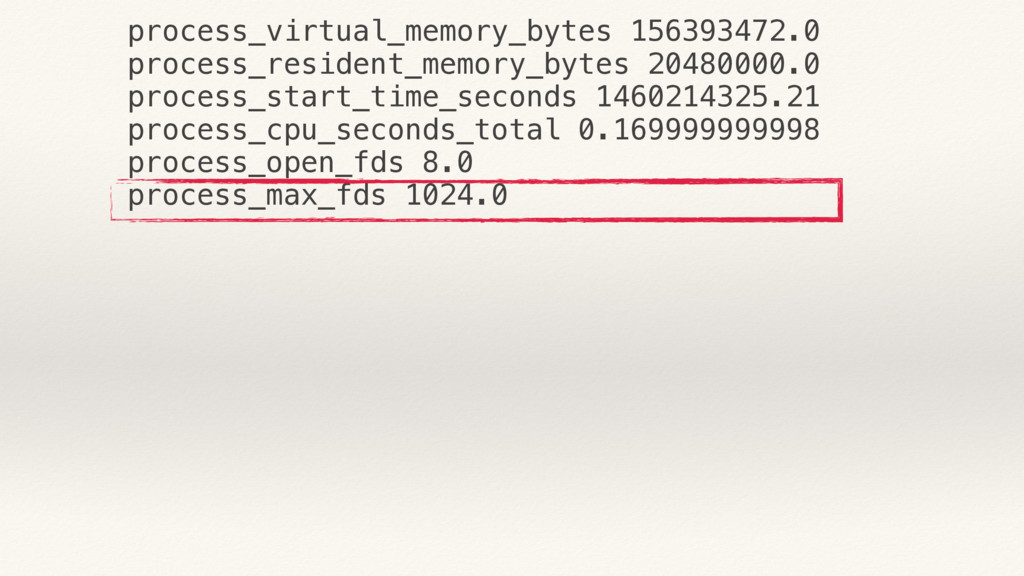{kind=link}
{kind=link}
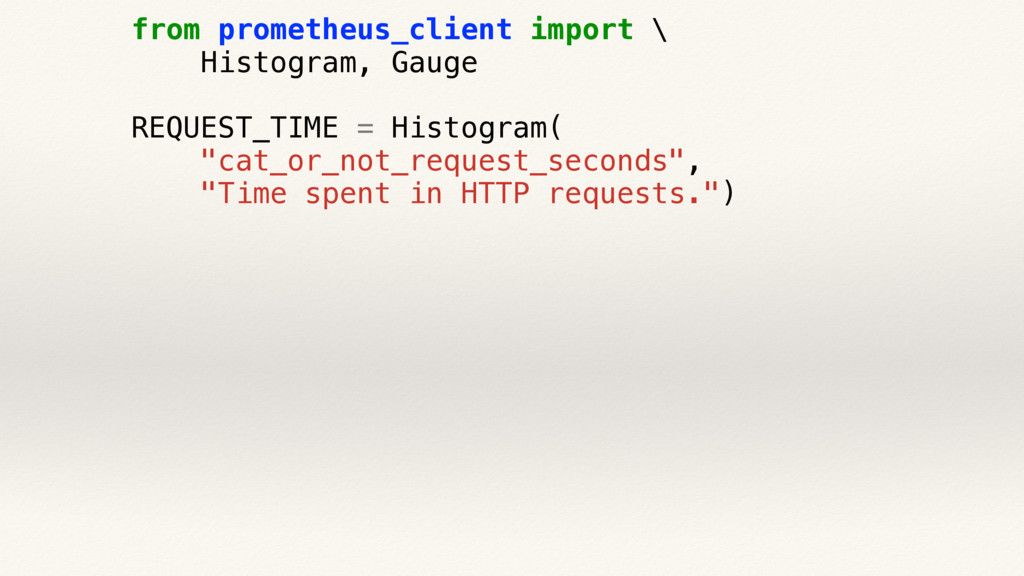{kind=link}
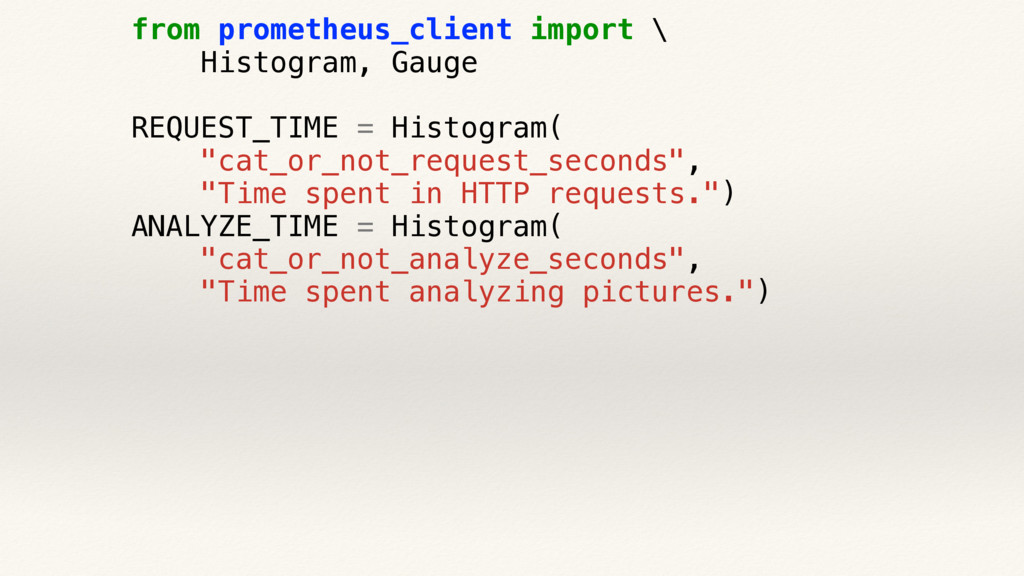{kind=link}
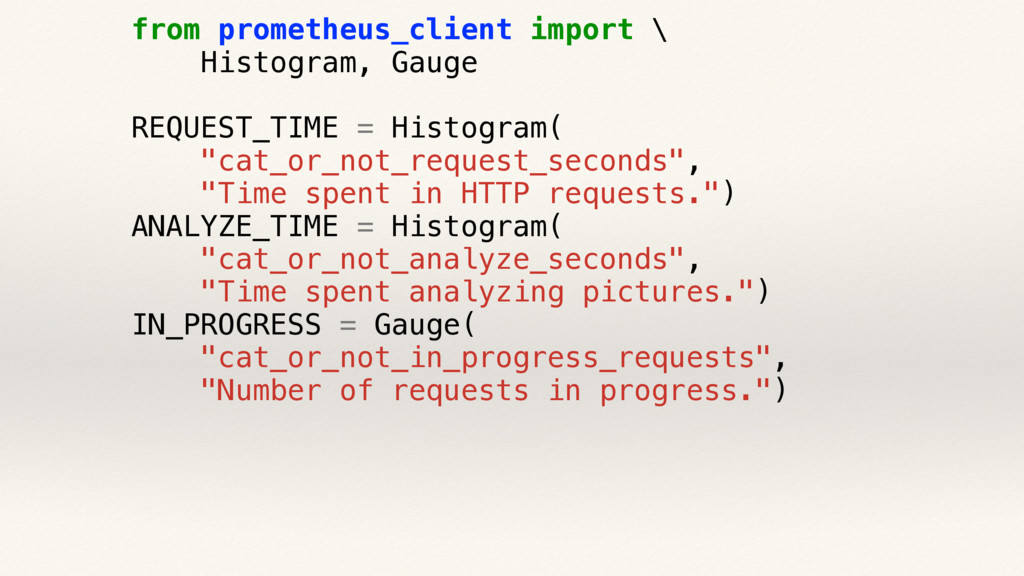{kind=link}
![@app.route("/analyze", methods=["POST"]) @IN_PROGRESS.track_inprogress() @REQUEST_TIME.time() def analyze(): g.auth.check(request) with ANALYZE_TIME.time(): result](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_133.jpg){kind=link}
![@app.route("/analyze", methods=["POST"]) @IN_PROGRESS.track_inprogress() @REQUEST_TIME.time() def analyze(): g.auth.check(request) with ANALYZE_TIME.time(): result](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_134.jpg){kind=link}
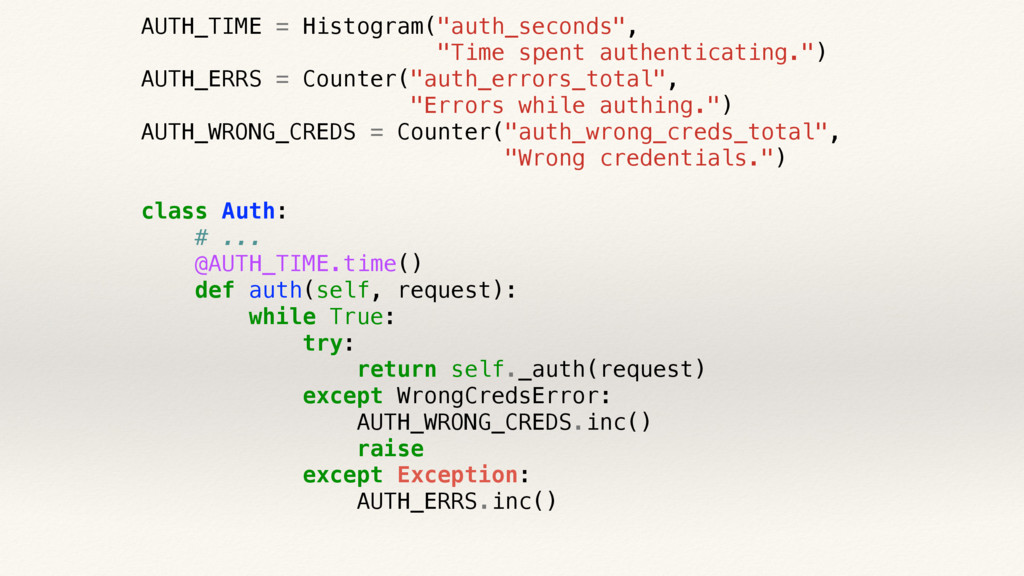{kind=link}
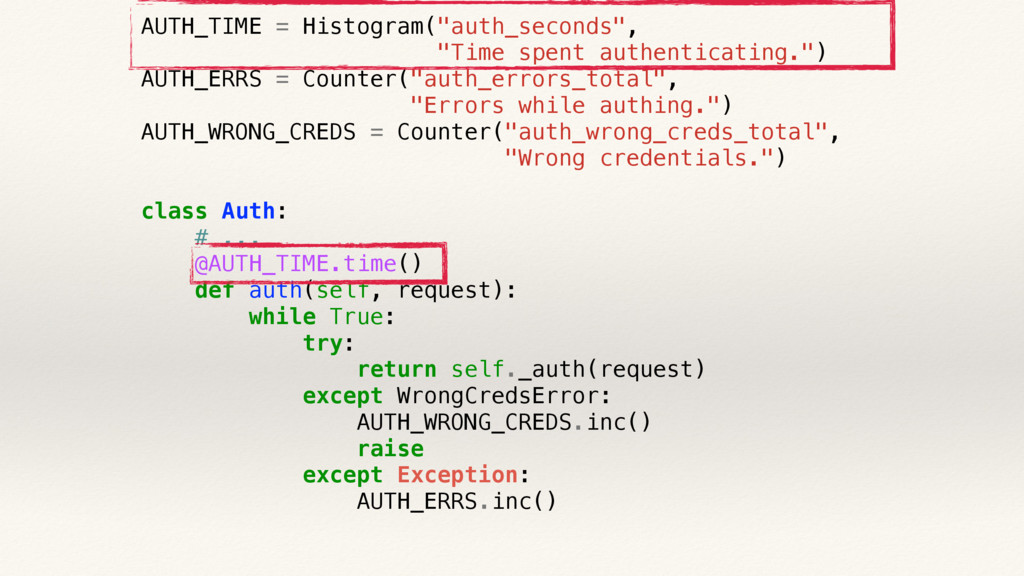{kind=link}
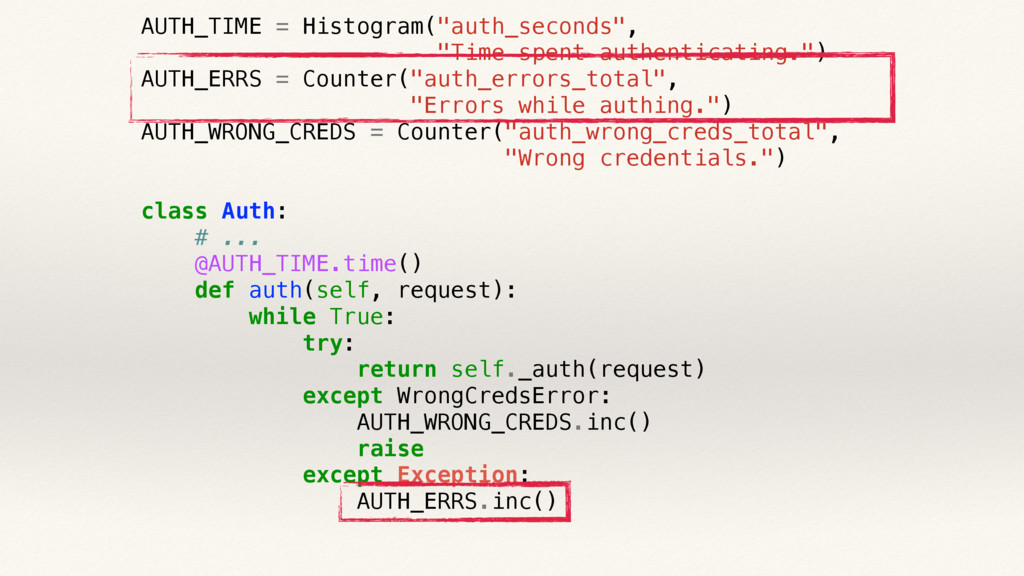{kind=link}
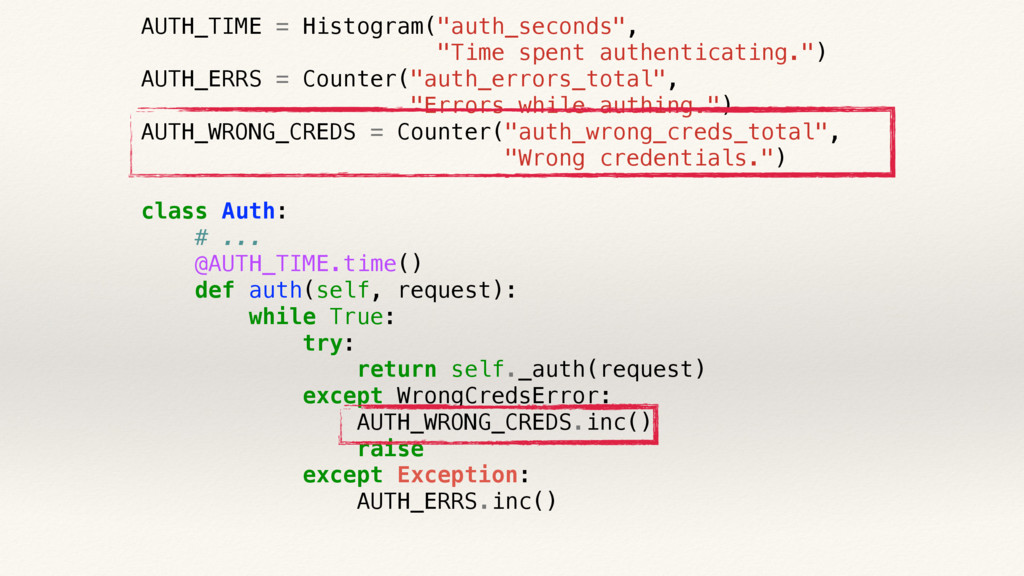{kind=link}
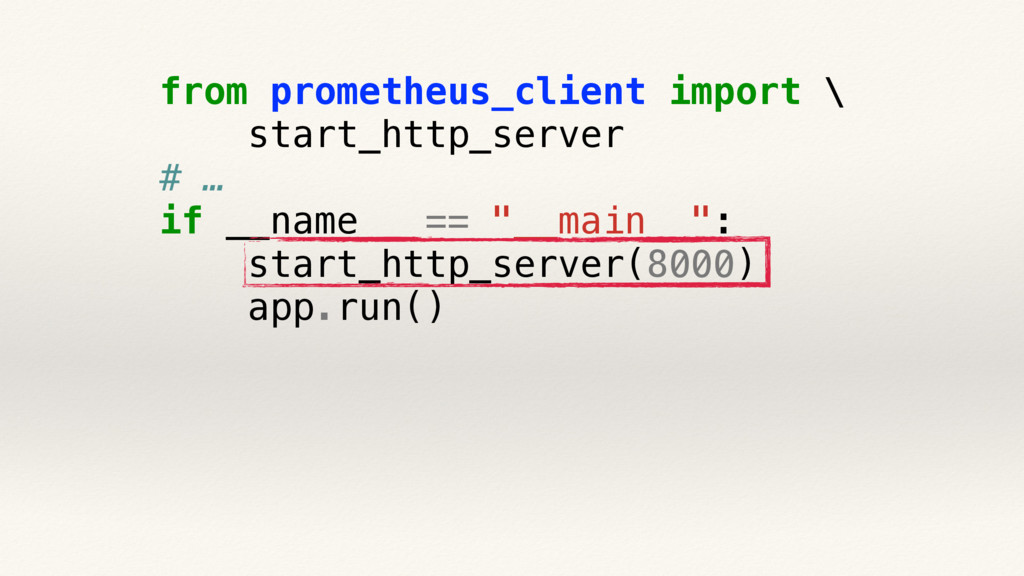
![@app.route("/analyze", methods=["POST"]) def analyze(): g.auth.check(request) with ANALYZE_TIME.time(): result = is_cat(](https://files.speakerdeck.com/presentations/d63813486af8403cbe952d7270452d9e/slide_139.jpg){kind=link}
{kind=link}
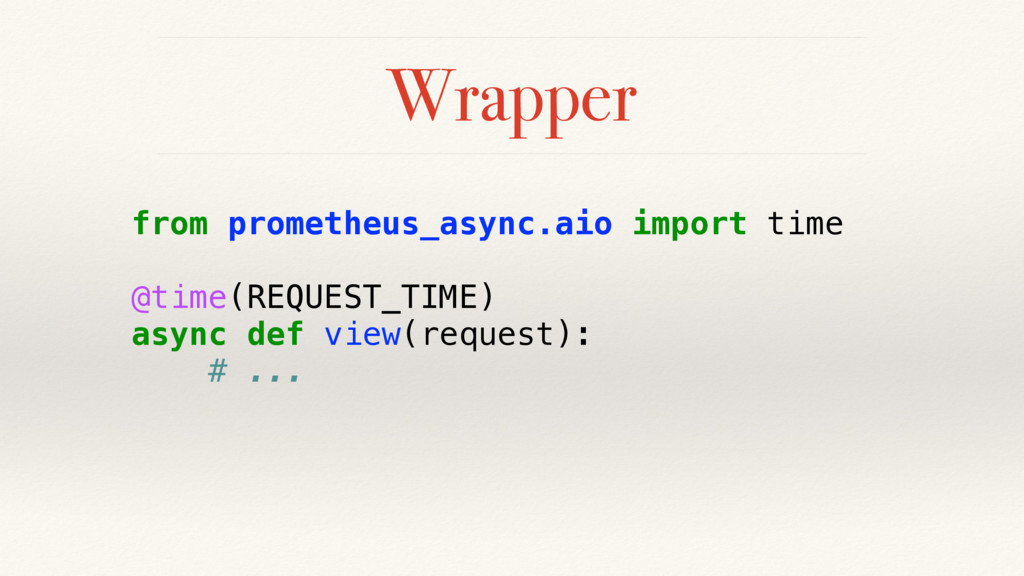{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}