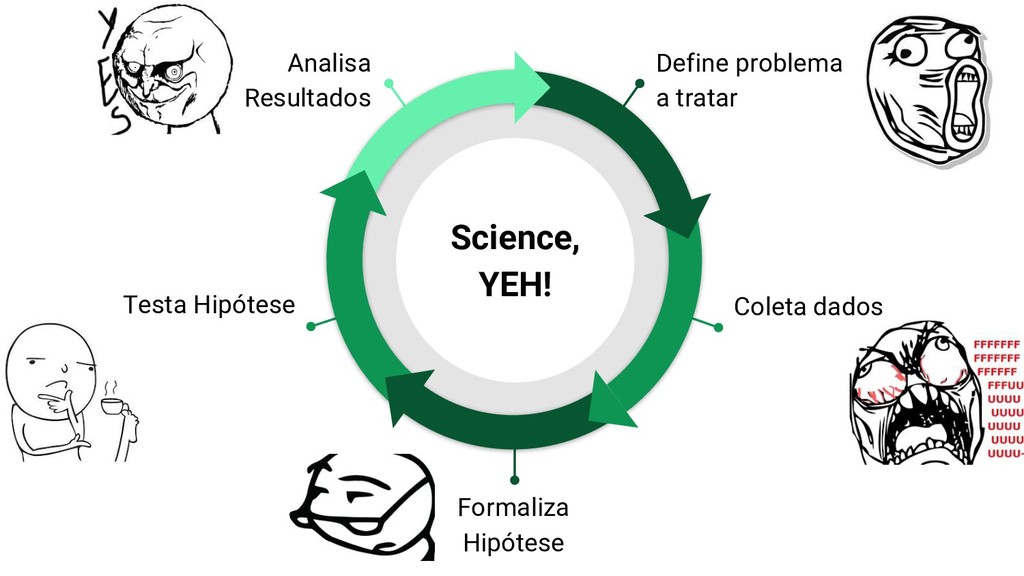
Quando os modelos clássicos de RNA são apresentados, pouco se fala sobre o processo de escolha dos parâmetros, sendo atribuídos ao "feeling" do cientista. Nesta apresentação, busco falar sobre as redes neurais, com enfoque na vantagem de cada uma sobre a outra de forma a auxiliar o processo decisivo e finalizo tratando de como selecionar os melhores parâmetros da rede.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
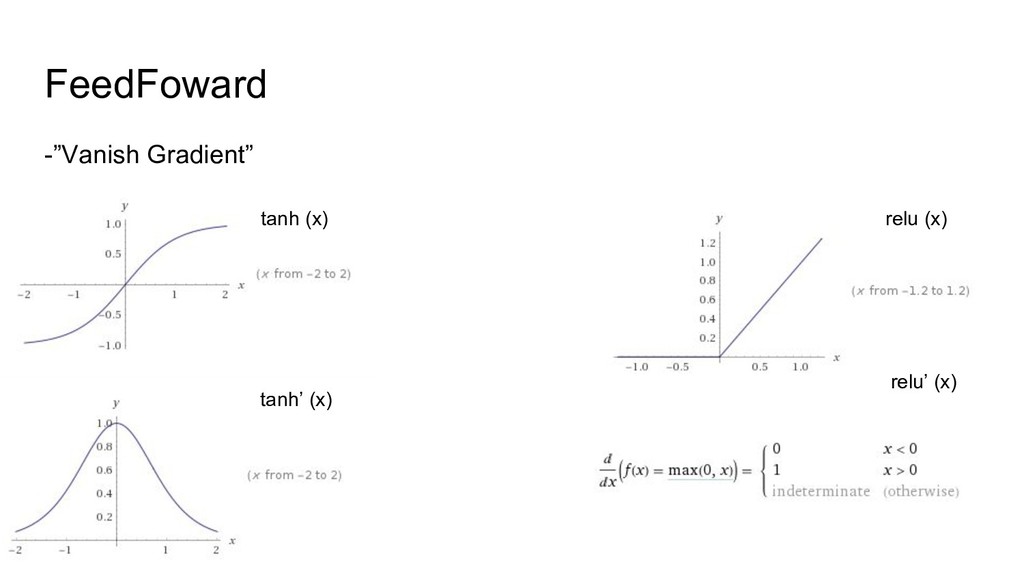
![FeedFoward -Teorema da Aproximação Universal [Geoge Cybenko 1989] Tendo quantidade](https://files.speakerdeck.com/presentations/3ef7565f4ed34a3b8cba78c4b6b34ae6/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
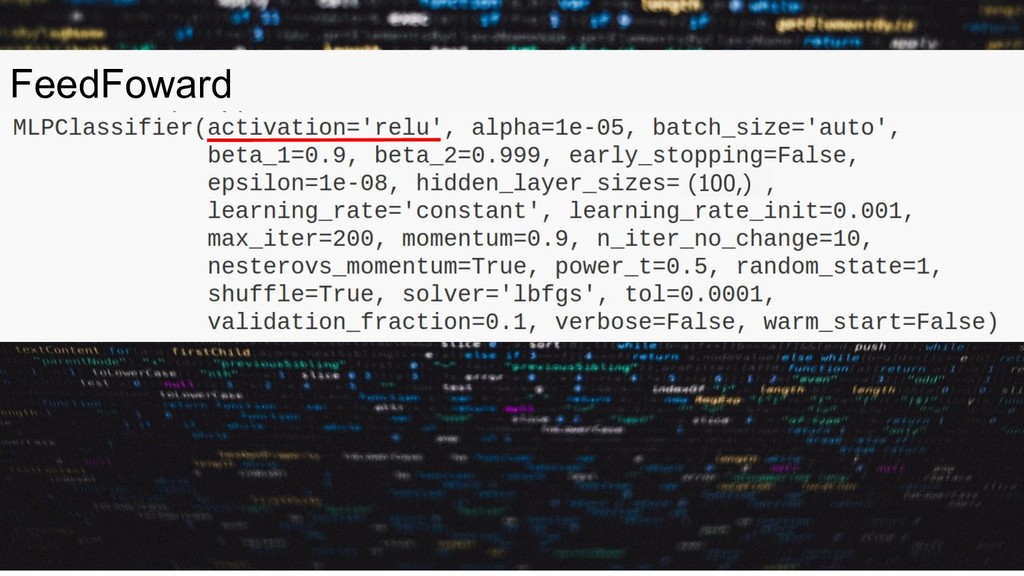{kind=link}
{kind=link}
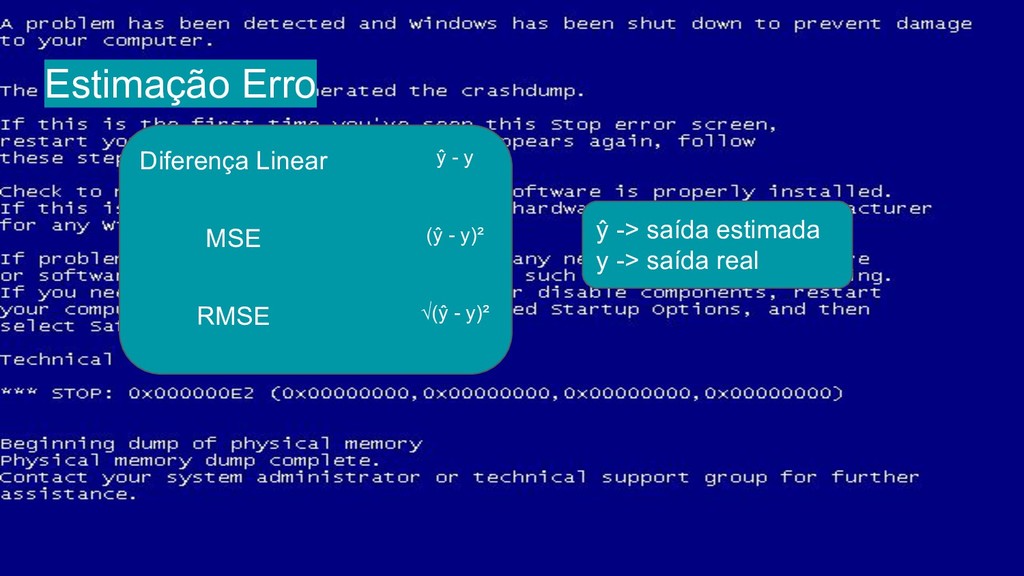{kind=link}
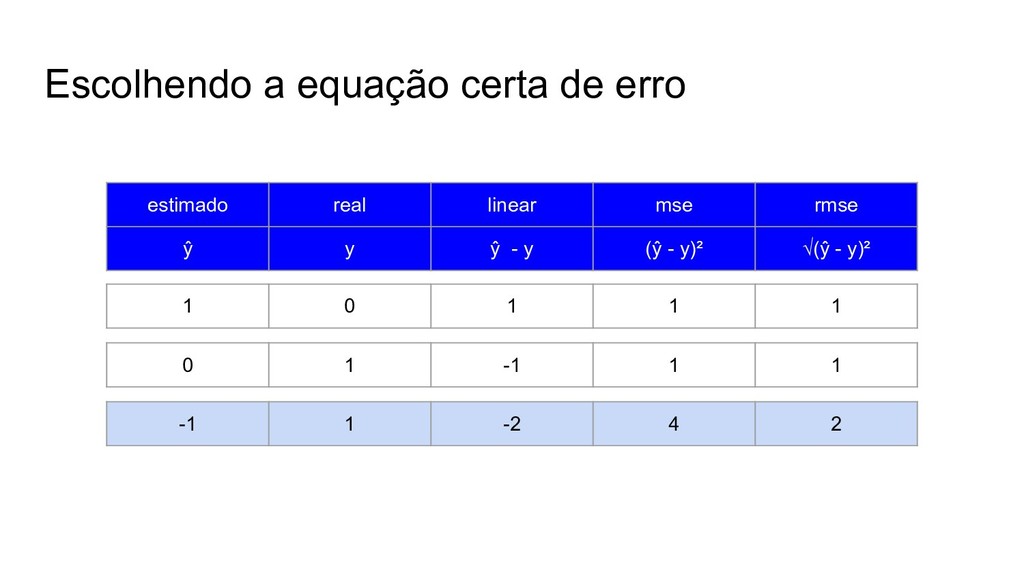{kind=link}
{kind=link}
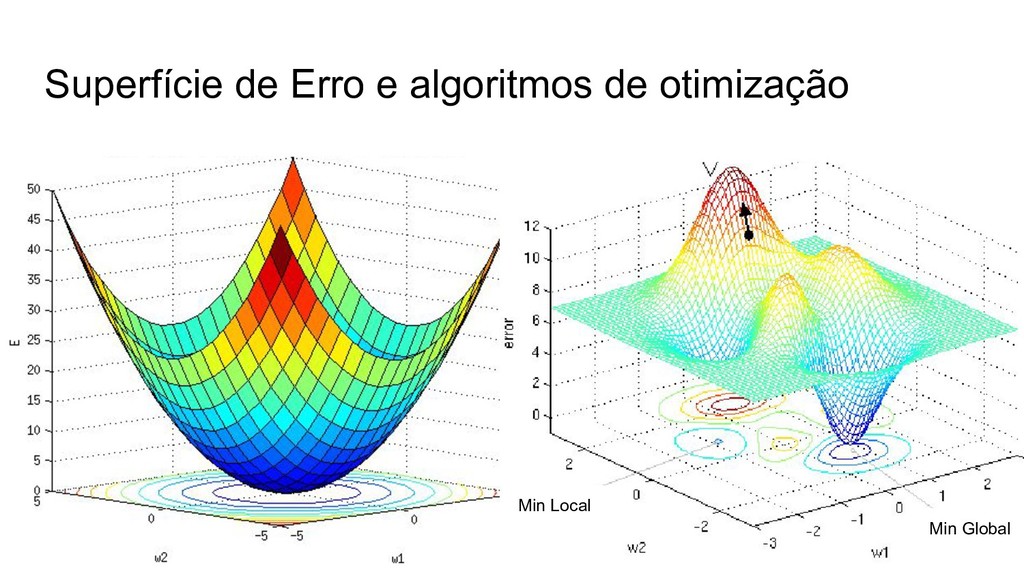{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}