• Tem a mesma funcionalidade de compartilhamento das planilhas e documentos do Google Docs • Permite ler datasets direto do Google Drive ou através do upload de arquivo usando suas bibliotecas. • Permite importar e rodar scripts • Permite usar GPU no notebook (Tesla K80 GPU)
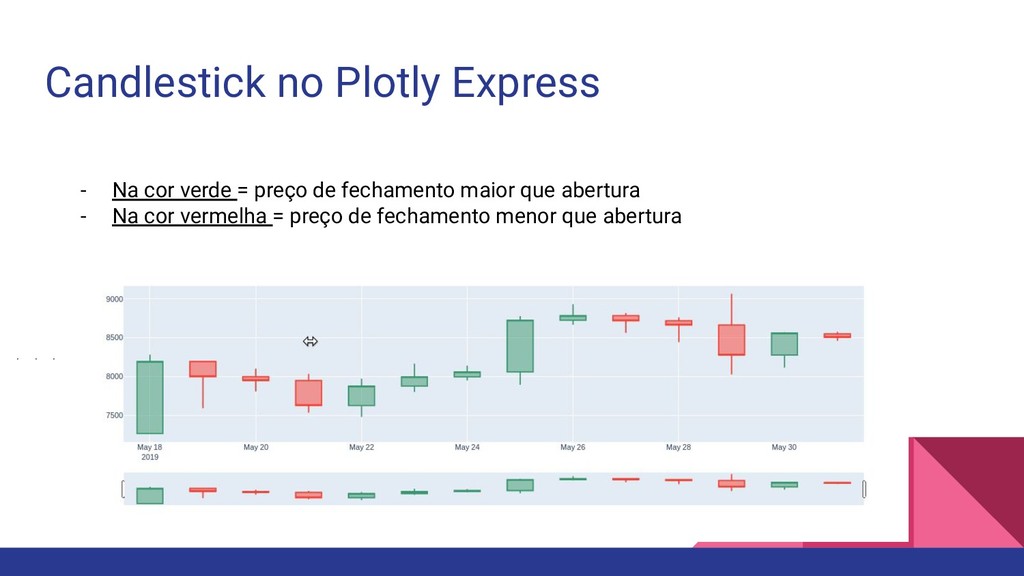
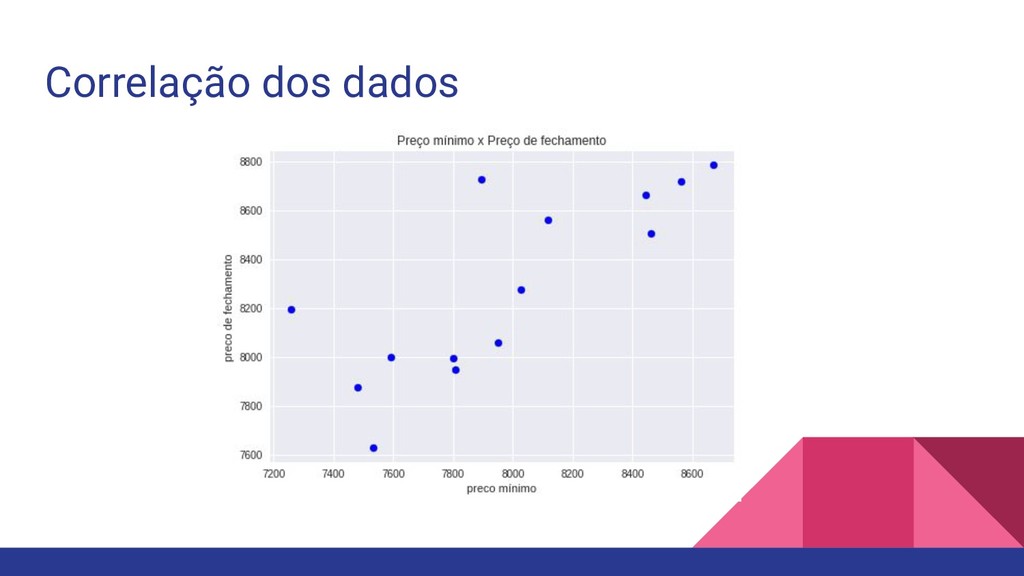
coletados sobre os preços de abertura, maior preço, menor preço,preço de fechamento e volume dos dados do Bitcoin de 18/05/2019 a 31/05/2019. Esse dataset está disponível no Kaggle em: https://www.kaggle.com/frankyano/bitcoin-trading-values
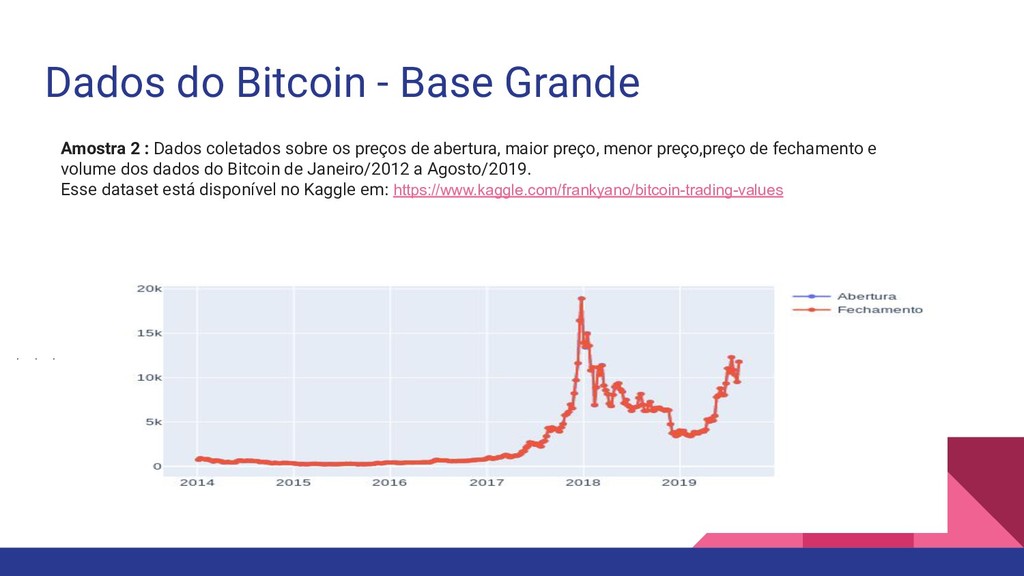
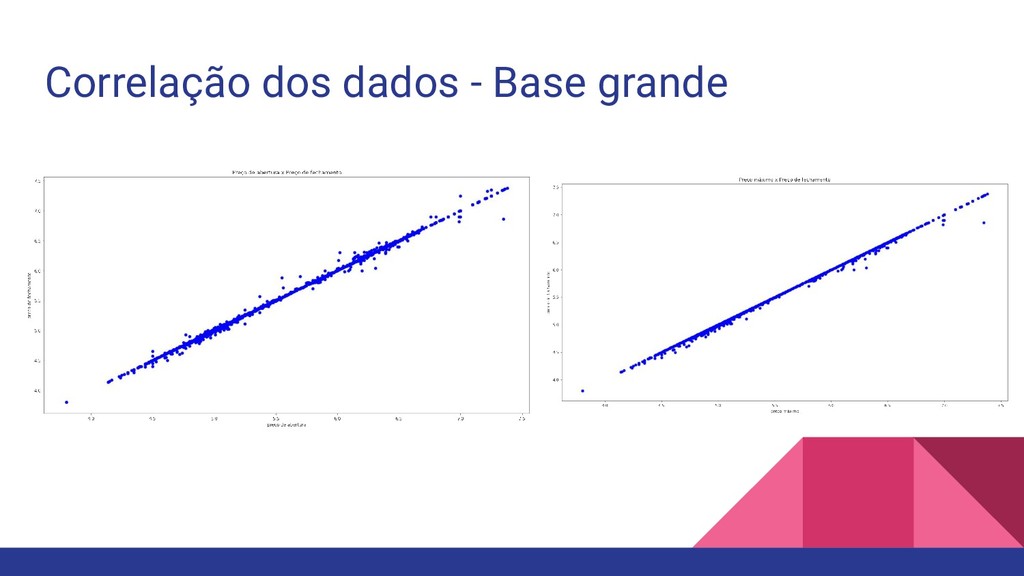
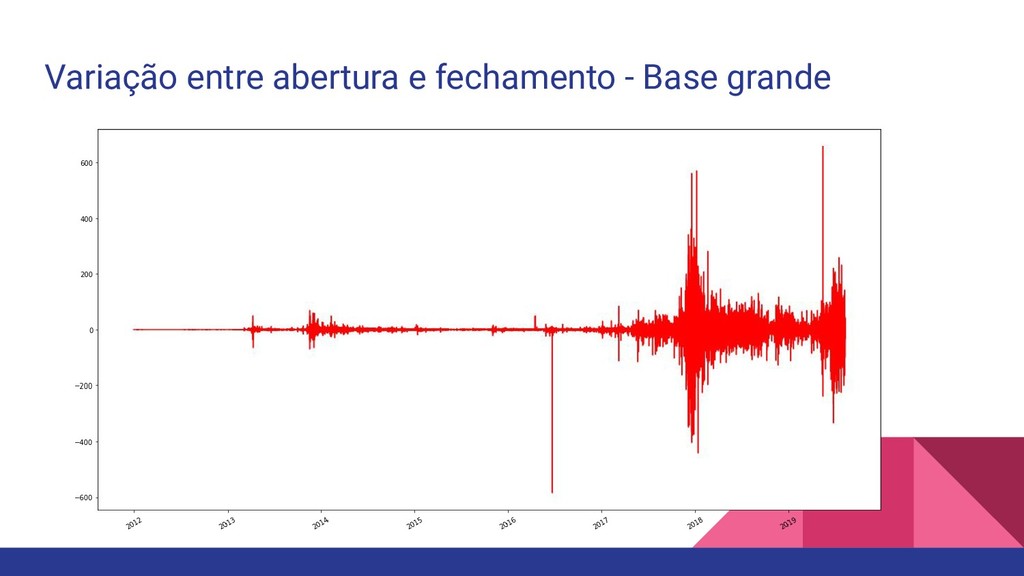
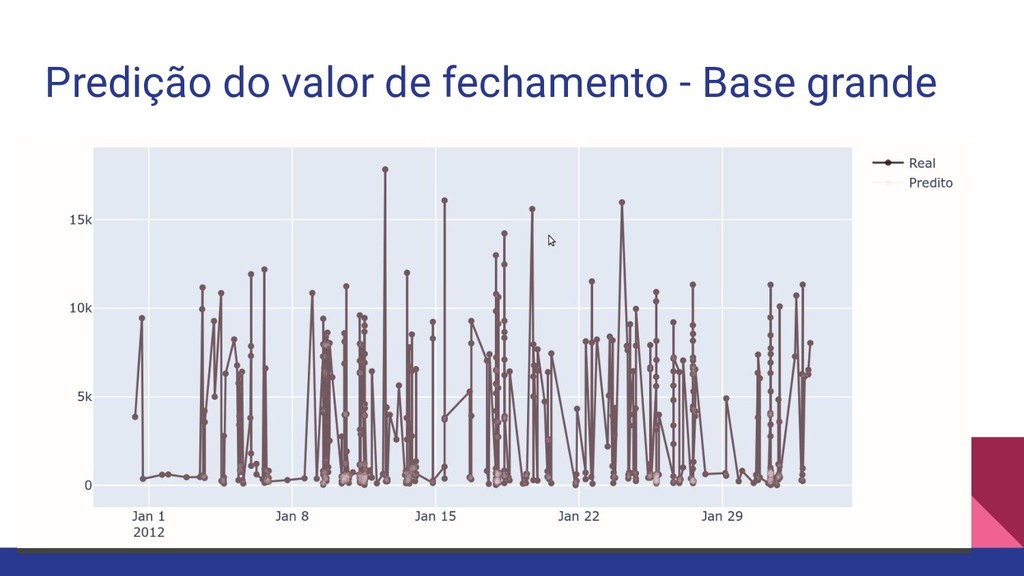
coletados sobre os preços de abertura, maior preço, menor preço,preço de fechamento e volume dos dados do Bitcoin de Janeiro/2012 a Agosto/2019. Esse dataset está disponível no Kaggle em: https://www.kaggle.com/frankyano/bitcoin-trading-values
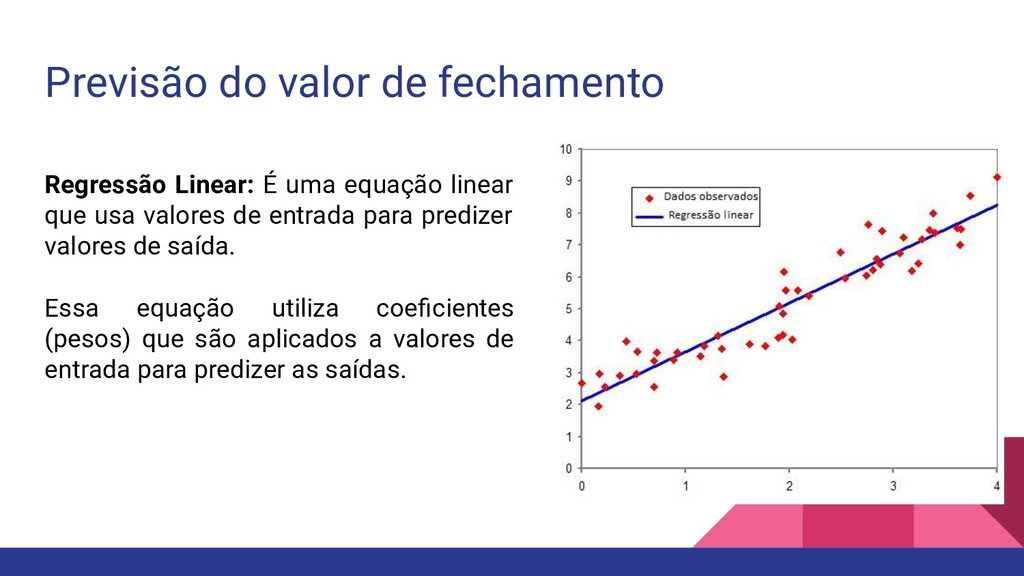
linear que usa valores de entrada para predizer valores de saída. Essa equação utiliza coeficientes (pesos) que são aplicados a valores de entrada para predizer as saídas.
= Constante, que representa a interceptação da reta com o eixo vertical; beta = Inclinação da reta ou coeficiente angular (peso); xi = Variável explicativa (independente); epsilon = Todos os fatores residuais mais os possíveis erros de medição
o dataset em dados para o treino e para o teste do modelo: treino = df2[['Open','High','Low']] y = df2['Close'] Vamos separar os dados em datasets para treino e teste do modelo: # 25% para teste e 75% para treino X_treino, X_teste, y_treino, y_teste = train_test_split(treino, y, random_state=42)
import LinearRegression # Criar um modelo usando Sklearn lr = LinearRegression() # Treinar o modelo com os dados separados para teste lr.fit(X_treino,y_treino) # Visualizar os pesos calculados para as 3 variáveis (Open, High, Low) lr.coef_ array([-0.31379481, 1.14190692, 0.2543172 ])
Quadrático (MSE): Cálculo da média dos quadrados dos erros. Usado para calcular o erro no algoritmo. Quanto menor, melhor Como é calculado: 1. Valores são preditos pelo algoritmo 2. Valores de erros são calculados (Real - Predito) 3. Valores de erros são elevados ao quadrado 4. Valores de erros são somados e é calculada a média dessa soma MSE = mean_squared_error(y_teste, lr.predict(X_teste)) 93969.20236984327
Erro Médio Quadrático (RMSE): Raiz do erro médio quadrático da diferença entre a predição e o valor real. Usado para visualizar o erro no preço. Quanto menor, melhor. Como é calculado: 1. Valores são preditos pelo algoritmo 2. Valores de erros são calculados (Real - Predito) 3. Valores de erros são elevados ao quadrado 4. Valores de erros são somados e é calculada a média dessa soma 5. Calcula-se a raiz quadrada desse valor RMSE = mean_squared_error(y_teste, lr.predict(X_teste))**0.5 306.54396482371544
Determinação (R²): Quanto (%) o modelo consegue explicar os valores observados. Quanto maior o R², mais explicativo é o modelo, melhor ele se ajusta à amostra Como é calculado: r2 = r2_score(y_teste, lr.predict(X_teste)) -1.089408042829365
o dataset em dados para o treino e para o teste do modelo: treino = df2[['Open','High','Low','Volume_(BTC)','Volume_(Currency)','Weighted_Price']] y = df2['Close'] Vamos separar os dados em datasets para treino e teste do modelo: # 25% para teste e 75% para treino X_treino, X_teste, y_treino, y_teste = train_test_split(treino, y, random_state=42)
import LinearRegression # Criar um modelo usando Sklearn lr = LinearRegression() # Treinar o modelo com os dados separados para teste lr.fit(X_treino,y_treino) # Visualizar os pesos calculados para as 6 variáveis ('Open','High','Low','Volume_(BTC)','Volume_(Currency)','Weighted_Price') lr.coef_ array([-4.08063873e-01, 7.33343405e-01, 6.74764364e-01, 8.78734592e-04, -2.13809820e-06])
Quadrático (MSE): Cálculo da média dos quadrados dos erros. Usado para calcular o erro no algoritmo. Quanto menor, melhor MSE = mean_squared_error(y_teste, lr.predict(X_teste)) 19.74504531232648
Erro Médio Quadrático (RMSE): Raiz do erro médio quadrático da diferença entre a predição e o valor real. Usado para visualizar o erro médio no preço. Quanto menor, melhor. RMSE = mean_squared_error(y_teste, lr.predict(X_teste))**0.5 4.443539727776323
Absoluto (MAE): O erro absoluto médio é uma medida da diferença entre duas variáveis contínuas. Valor real do erro MAE = mean_absolute_error(y_teste, lr.predict(X_teste)) 1.6088196403765398
Determinação (R²): Quanto (%) o modelo consegue explicar os valores observados. Quanto maior o R², mais explicativo é o modelo, melhor ele se ajusta à amostra Como é calculado: r2 = r2_score(y_teste, lr.predict(X_teste)) 1.00 ou seja, modelo com overfitting
predição real desses valores, devido ao overfitting durante o treinamento (as técnicas usadas não permitiram generalizar e realizar a predição para qualquer valor). Para criar um modelo mais realista é necessário testar outros tipos de modelo, como o LSTM que permite criar janelas de predição e um melhor entendimento do comportamento dos preços.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}