problema 4. Multi-Layer Perceptron 5. Redes de convolução 6. Arquitetura da rede 7. Obtenção dos dados 8. Preparação dos dados 9. Vetores de palavras embutidos 10. Como tudo se encaixa 11. Escolha de parâmetros e aplicação da rede 12. Análise do resultado
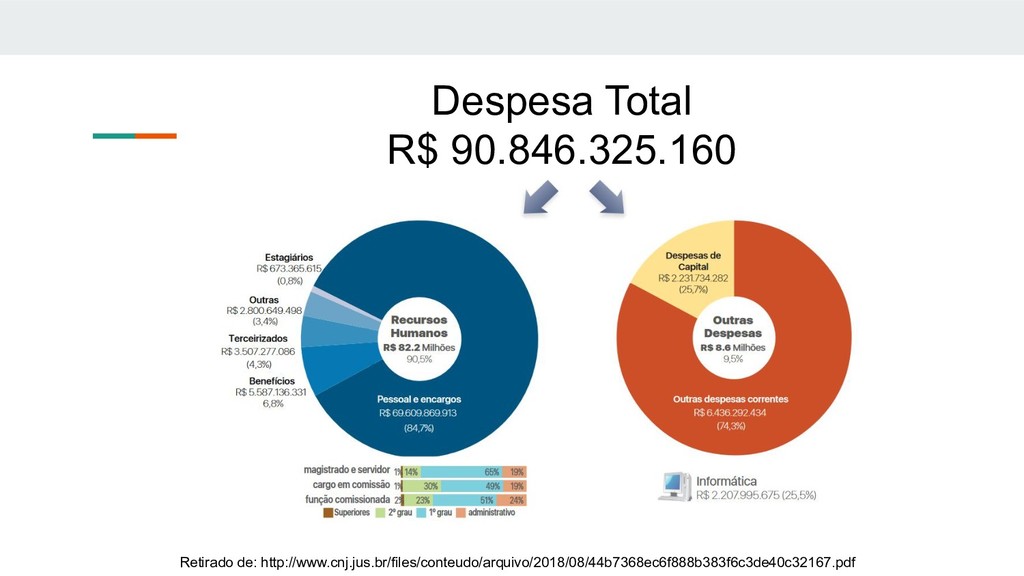
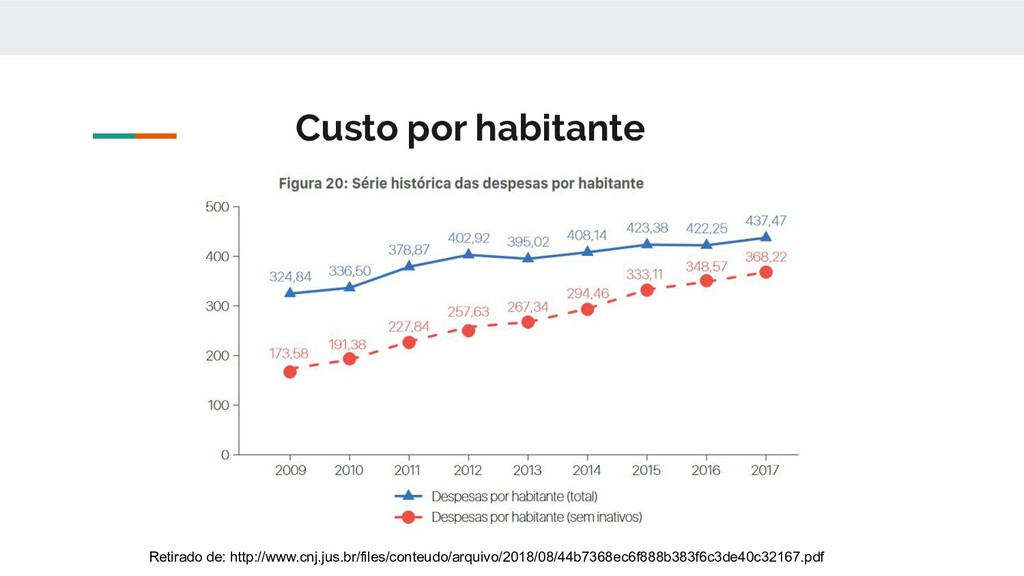
(CNJ) prepara um relatório chamado “Justiça em Números”, que tenta avaliar o panorama judiciário no Brasil. Para esse relatório são levantadas algumas estatísticas que tentam medir o andamento do Judiciário em vários ângulos, como: • Custo • Produtividade • Tempo de tramitação processual
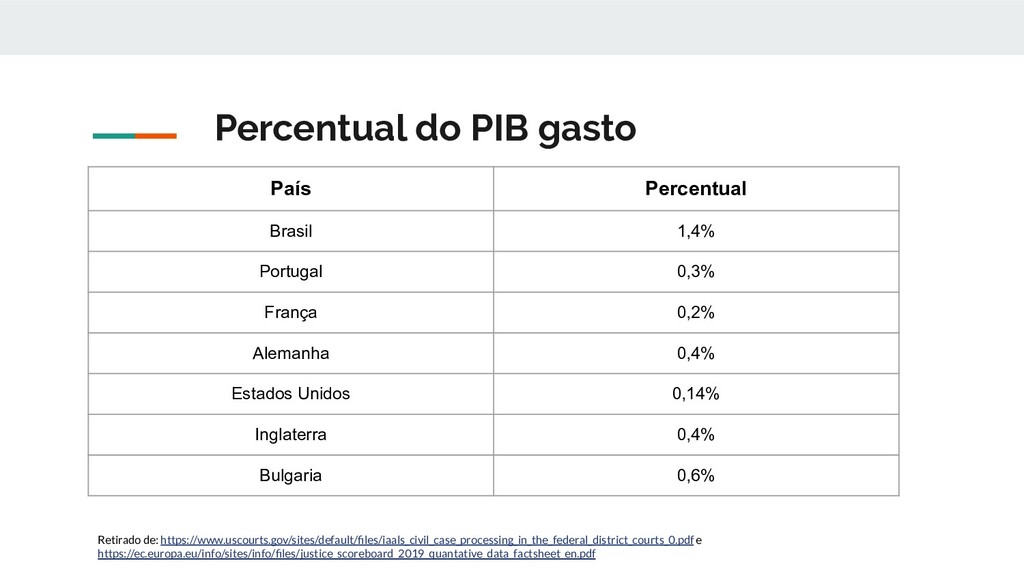
França 0,2% Alemanha 0,4% Estados Unidos 0,14% Inglaterra 0,4% Bulgaria 0,6% Retirado de: https://www.uscourts.gov/sites/default/files/iaals_civil_case_processing_in_the_federal_district_courts_0.pdf e https://ec.europa.eu/info/sites/info/files/justice_scoreboard_2019_quantative_data_factsheet_en.pdf
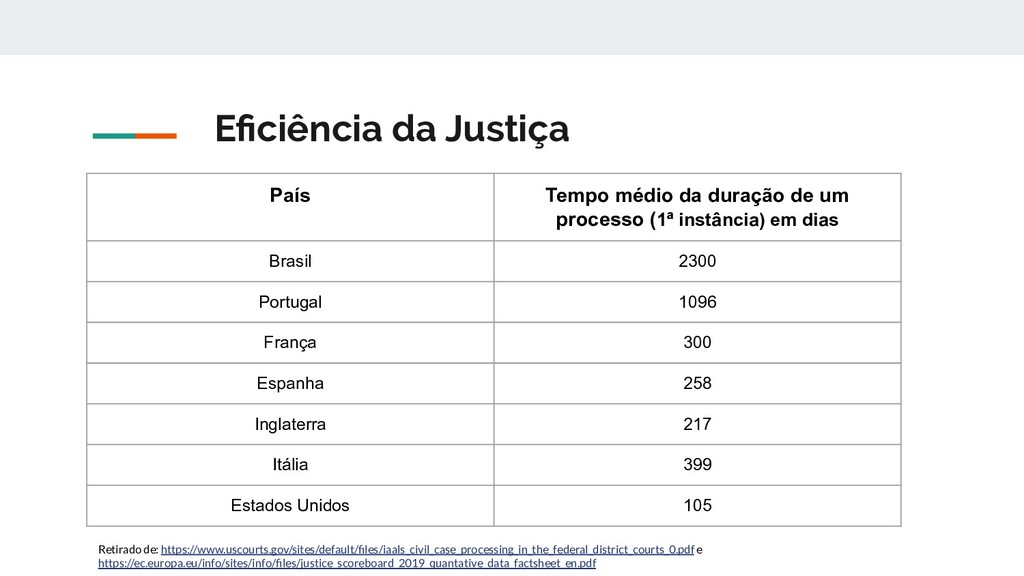
processo (1ª instância) em dias Brasil 2300 Portugal 1096 França 300 Espanha 258 Inglaterra 217 Itália 399 Estados Unidos 105 Retirado de: https://www.uscourts.gov/sites/default/files/iaals_civil_case_processing_in_the_federal_district_courts_0.pdf e https://ec.europa.eu/info/sites/info/files/justice_scoreboard_2019_quantative_data_factsheet_en.pdf
chamado de petição inicial • Na petição inicial é obrigatório o preenchimento da classe judicial do processo. Ex: ◦ Alimentos - Provisionais ◦ Procedimento Comum e Cível ◦ Cumprimento de Sentença • Acontecem as vezes de o advogado preencher de forma incorreta esse campo o que causa prejuízo no tempo e custo do processo. Ideia: • Propor um meio automatizado de sugestão da classe judicial do processo.
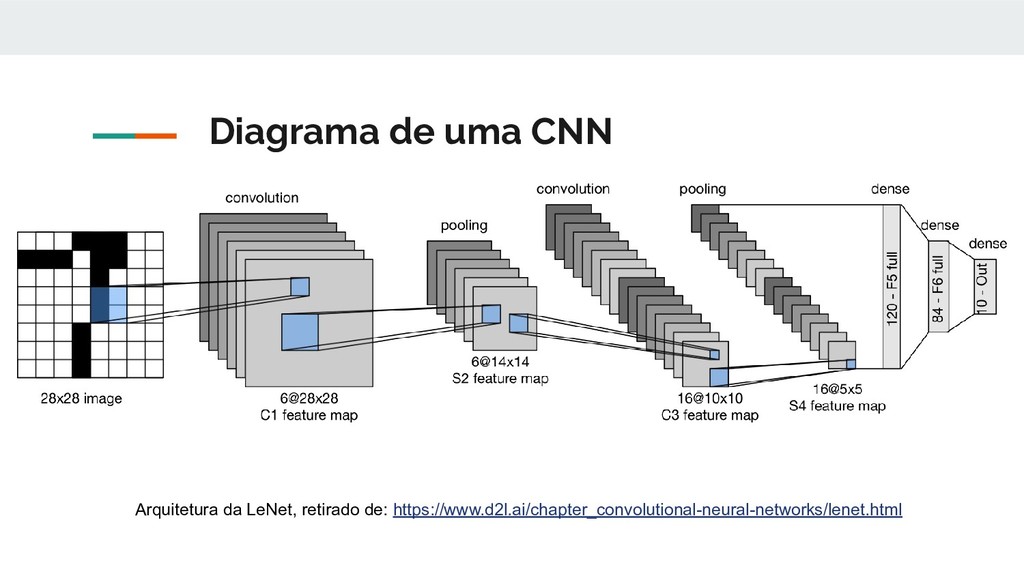
rede neural artificial feedforward. Um MLP consiste de pelo menos três camadas de nós: uma camada de entrada, uma camada oculta e uma camada de saída. Exceto para os nós de entrada, cada nó é um neurônio que usa uma função de ativação não linear. O MLP utiliza uma técnica de aprendizagem supervisionada chamada backpropagation para treinamento. Ele pode distinguir dados que não são linearmente separáveis. Retirado de: https://en.wikipedia.org/wiki/Multilayer_perceptron
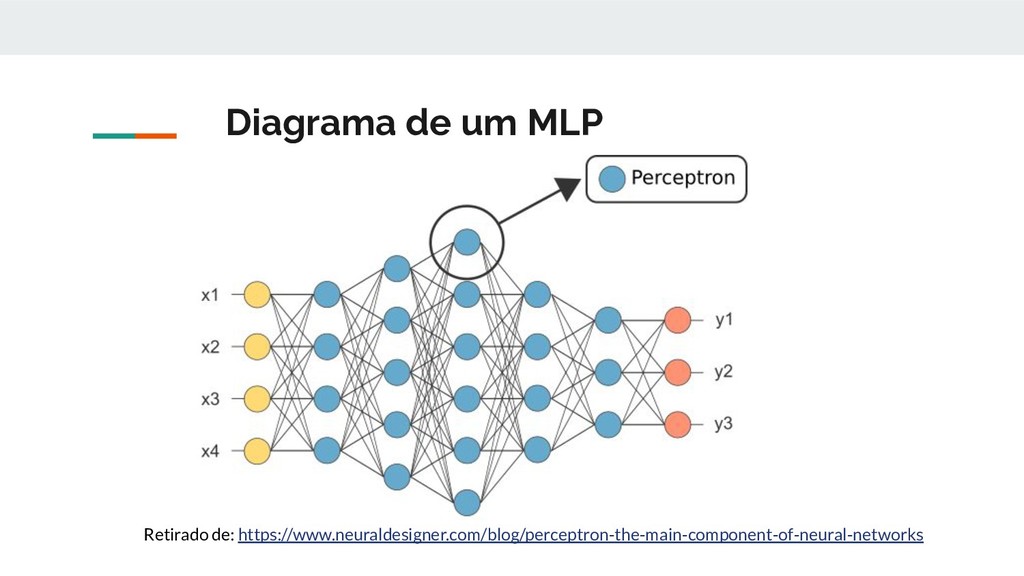
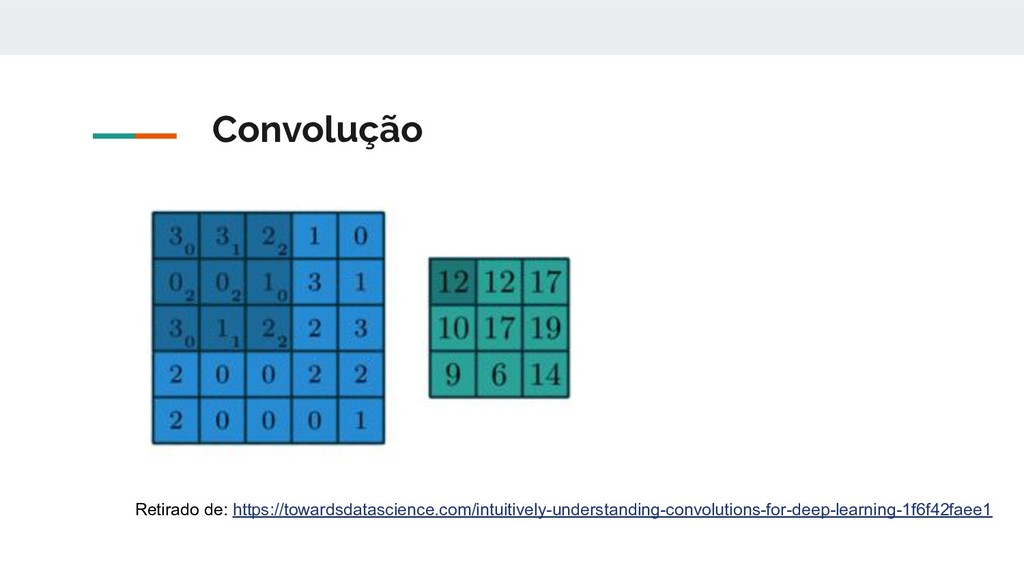
multicamadas. Os perceptrons multicamadas geralmente se referem a redes totalmente conectadas, ou seja, cada neurônio de uma camada está conectado a todos os neurônios da próxima camada. A "conexão total" dessas redes as torna propensas ao excesso de ajuste de dados. As CNNs têm uma abordagem diferente em relação à regularização: elas tiram proveito do padrão hierárquico dos dados e montam padrões mais complexos usando padrões menores e mais simples. https://en.wikipedia.org/wiki/Convolutional_neural_network
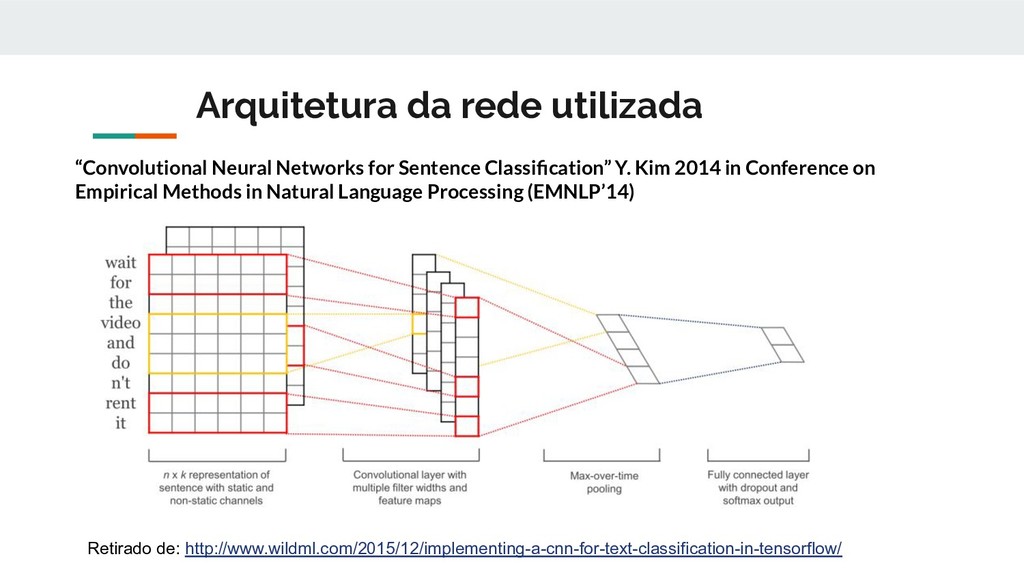
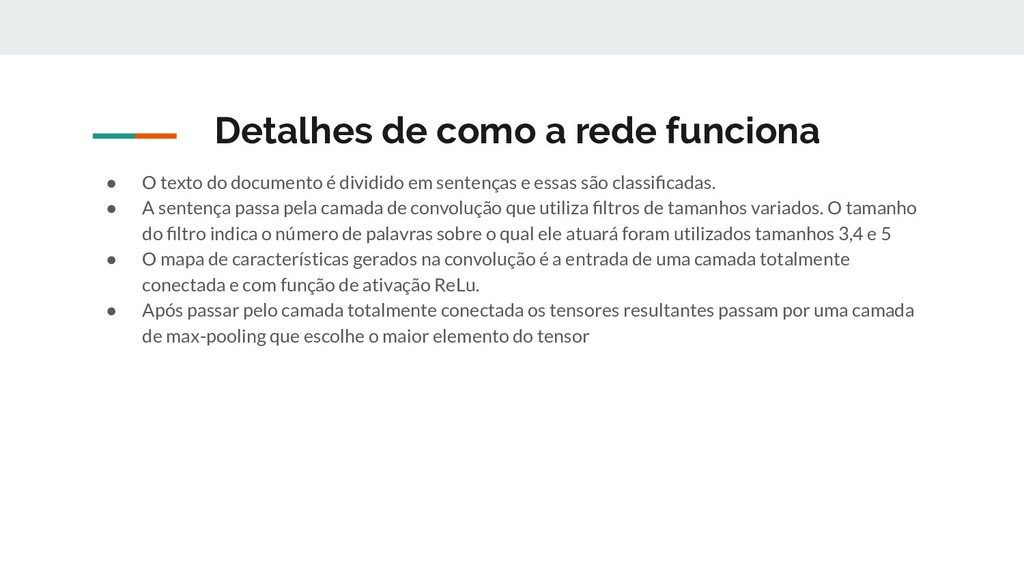
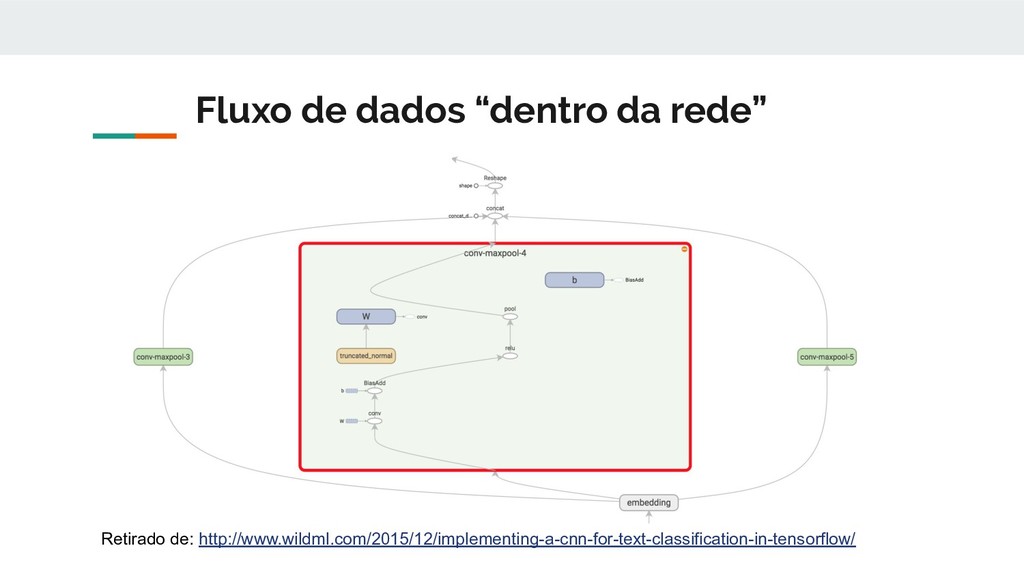
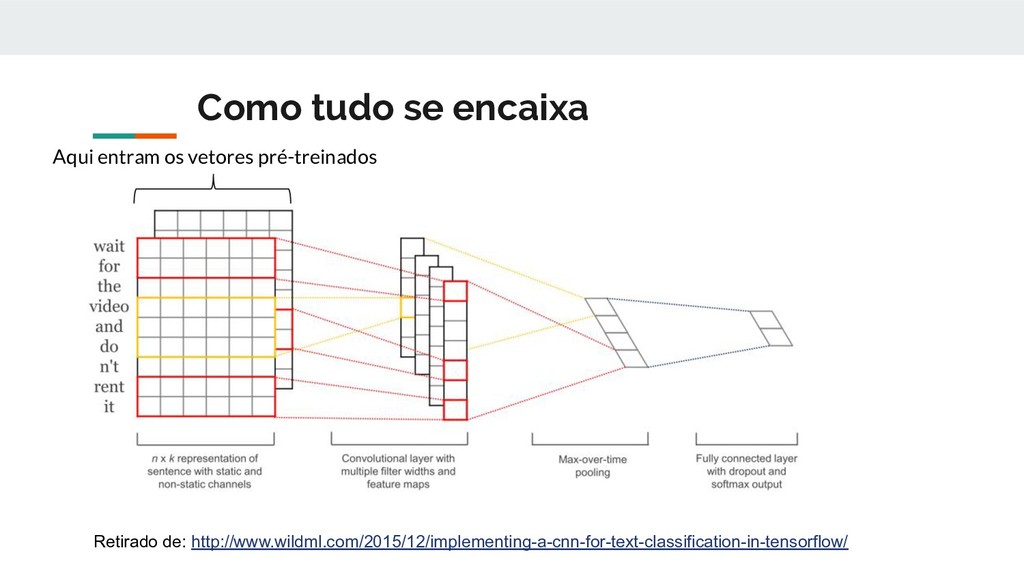
documento é dividido em sentenças e essas são classificadas. • A sentença passa pela camada de convolução que utiliza filtros de tamanhos variados. O tamanho do filtro indica o número de palavras sobre o qual ele atuará foram utilizados tamanhos 3,4 e 5 • O mapa de características gerados na convolução é a entrada de uma camada totalmente conectada e com função de ativação ReLu. • Após passar pelo camada totalmente conectada os tensores resultantes passam por uma camada de max-pooling que escolhe o maior elemento do tensor
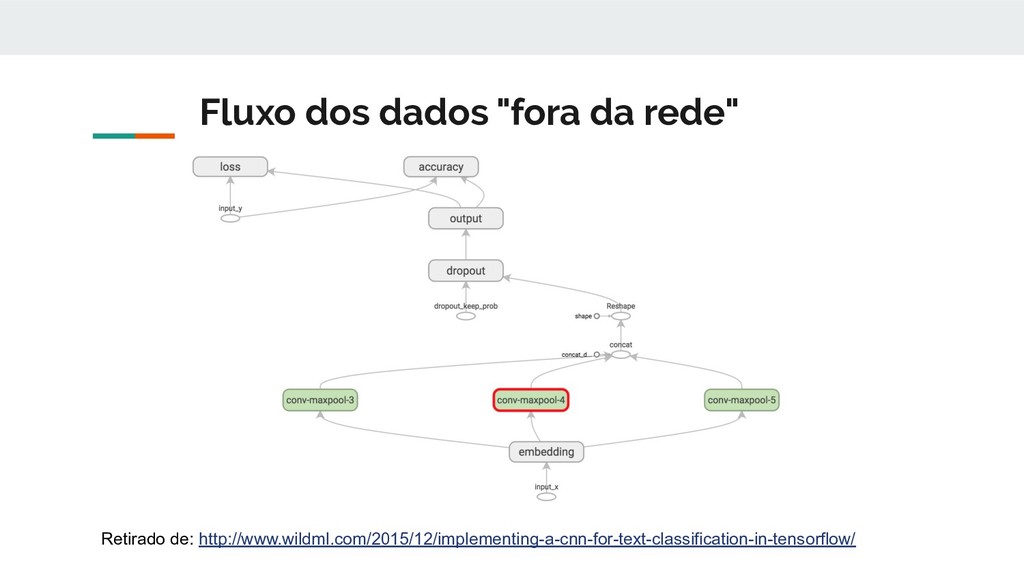
pela camada de max-pool é aplicada uma camada de dropout. Dropout é uma técnica de regularização comumente utilizada, o seu objetivo é desabilitar neurônios com um probabilidade (1 - p), ou manter com a probabilidade p. • Por fim é feita uma combinação linear do tensor resultante do passo anterior com um tensor de pesos do tamanho do número de classes judiciais, o resultado dessa combinação é transformado em probabilidades através da função softmax.
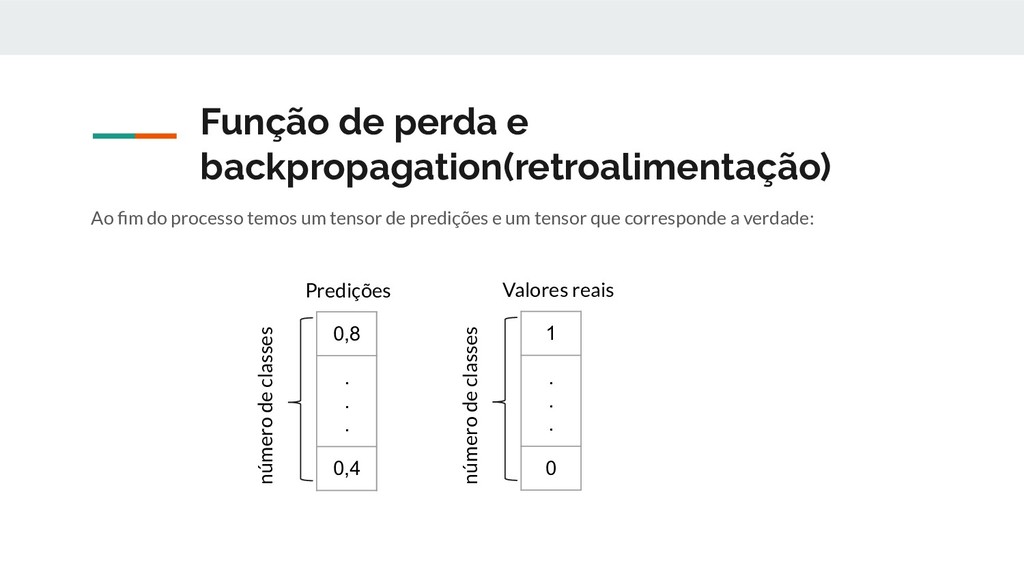
erro, derivamos a perda em relação a cada uma das variáveis envolvidas nos cálculos dessa predições e subtraímos o resultado da derivada de seus valores. Esse processo chamamos de backpropagation ou retroalimentação. Retirado de: https://becominghuman.ai/back-propagation-in-convolutional-neural-networks-intuition-and-code-714ef1c38199
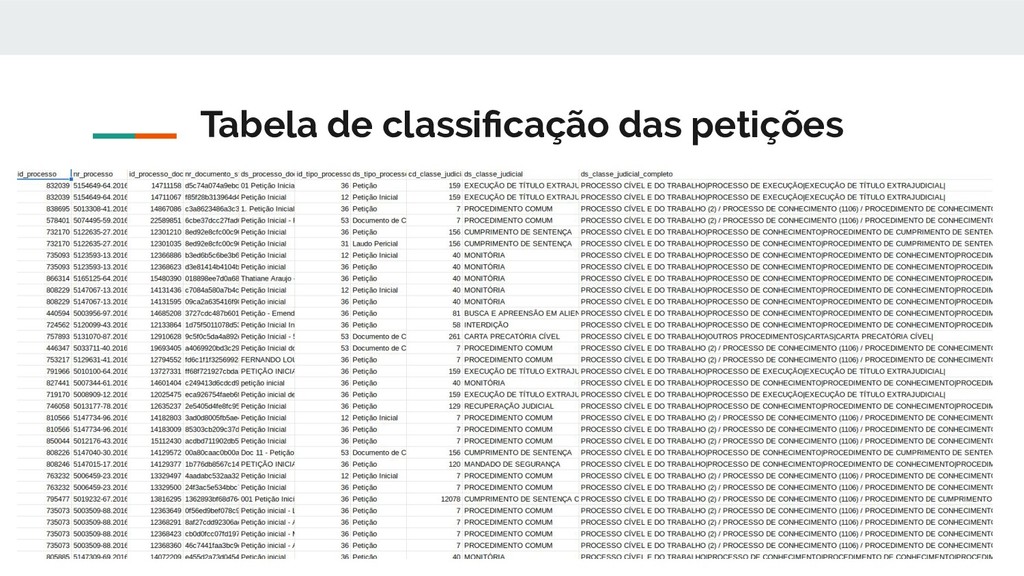
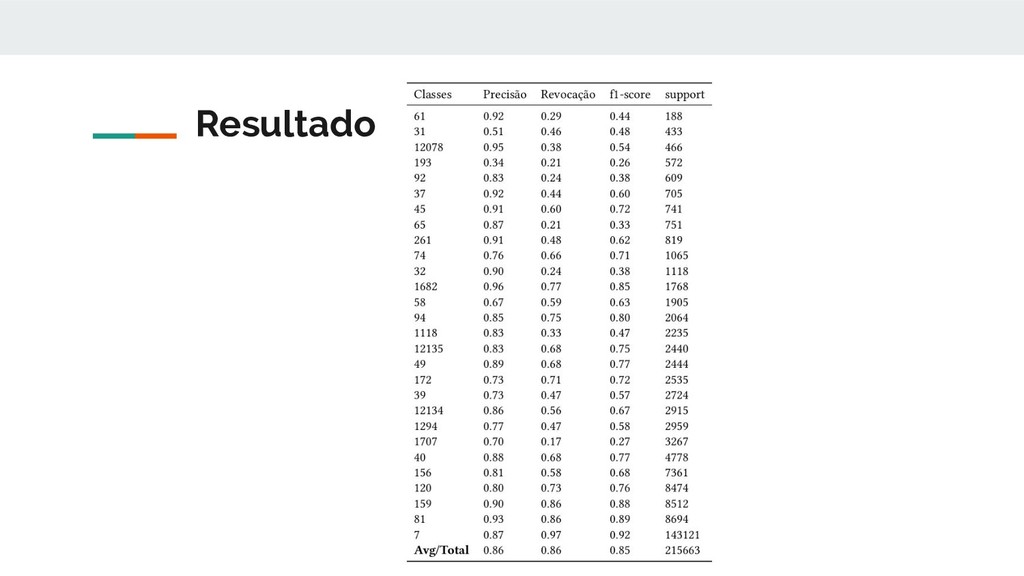
pertenciam a 118 classes de processuais diversas, dessas 118 classes apenas 28 possuíam relevância estatística em volume de dados e somente estas foram utilizadas. Exemplos de classes são: • procedimento comum, despejo por falta de pagamento cumulado com • cobrança, arrolamento sumário, consignação em pagamento, inventário, reintegração / manutenção de posse.
pdf, html ou eram uma imagem a. Considerados apenas dos arquivos que eram pdfs ou htmls e utilização da ferramenta pdftotext do linux para conversão do pdf em texto livre. 2. Removidas todas as marcações dos arquivos html 3. Retiradas todas as petições que eram menores que 1KB 4. Criação de uma tabela onde cada linha tem o identificador de um documento e sua classe judicial
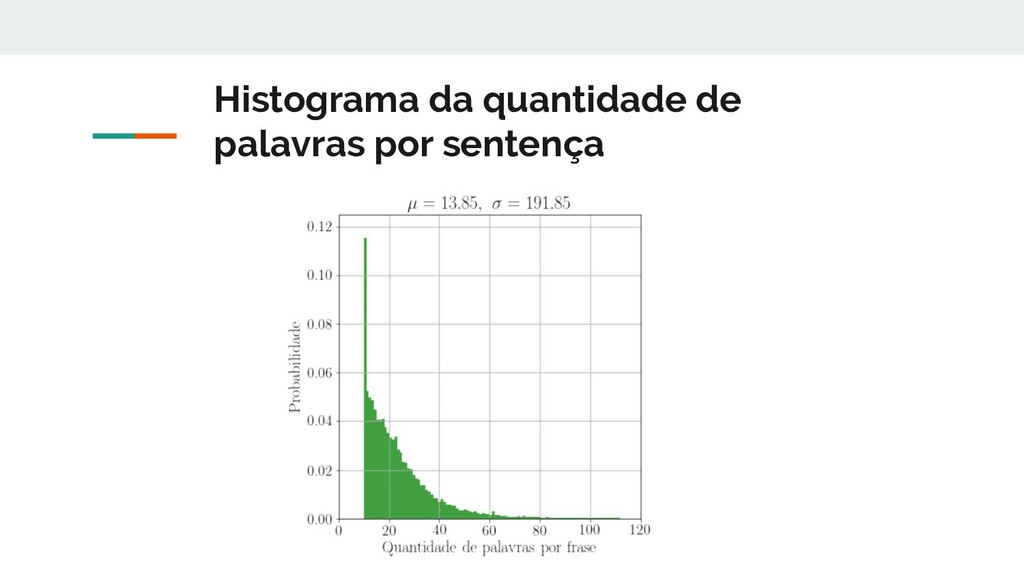
diretórios de acordos com suas classe 6. Todos os arquivos de um diretório, ou seja pertencentes a uma classe judicial, foram concatenados em somente um arquivo, que assim passava a conter o texto correspondente a todas as petições daquela classe. 7. Utilizada a biblioteca NLTK para fazer a segmentação de sentenças do texto do arquivo de cada classe judicial. 8. O texto das petições foram filtrados e foram removidas sentenças que contivessem menos que 10 palavras, pois dificilmente teriam um valor semântico capaz de identificar a classe de um processo, e também as sentenças maiores que 112 palavras pois correspondiam a de 0,1% do dataset
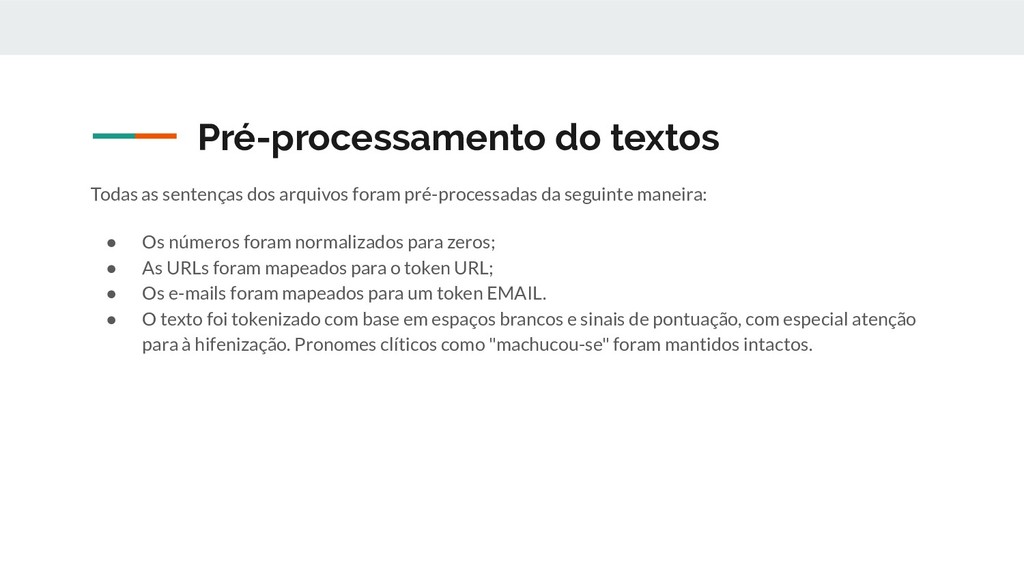
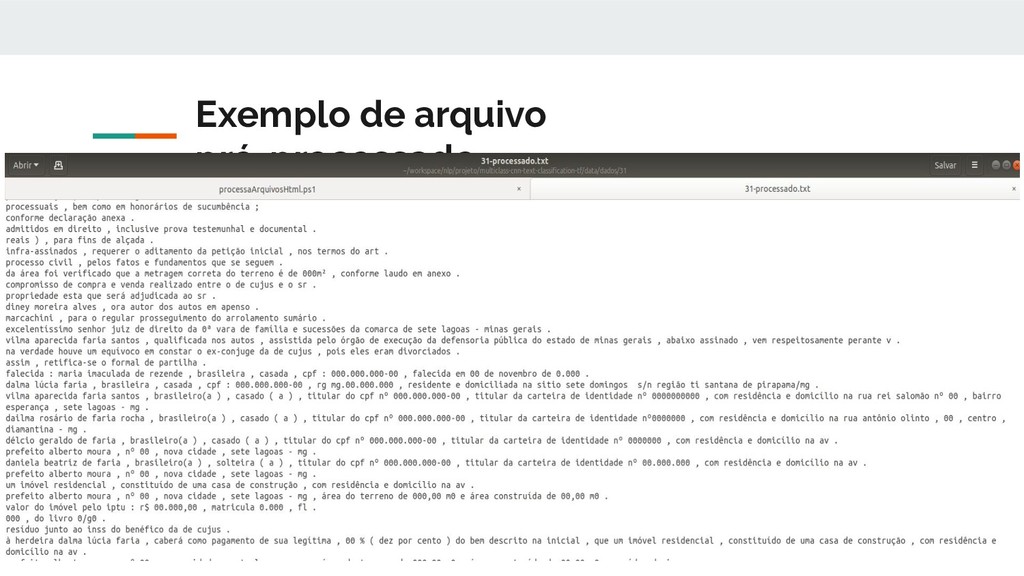
da seguinte maneira: • Os números foram normalizados para zeros; • As URLs foram mapeados para o token URL; • Os e-mails foram mapeados para um token EMAIL. • O texto foi tokenizado com base em espaços brancos e sinais de pontuação, com especial atenção para à hifenização. Pronomes clíticos como "machucou-se" foram mantidos intactos.
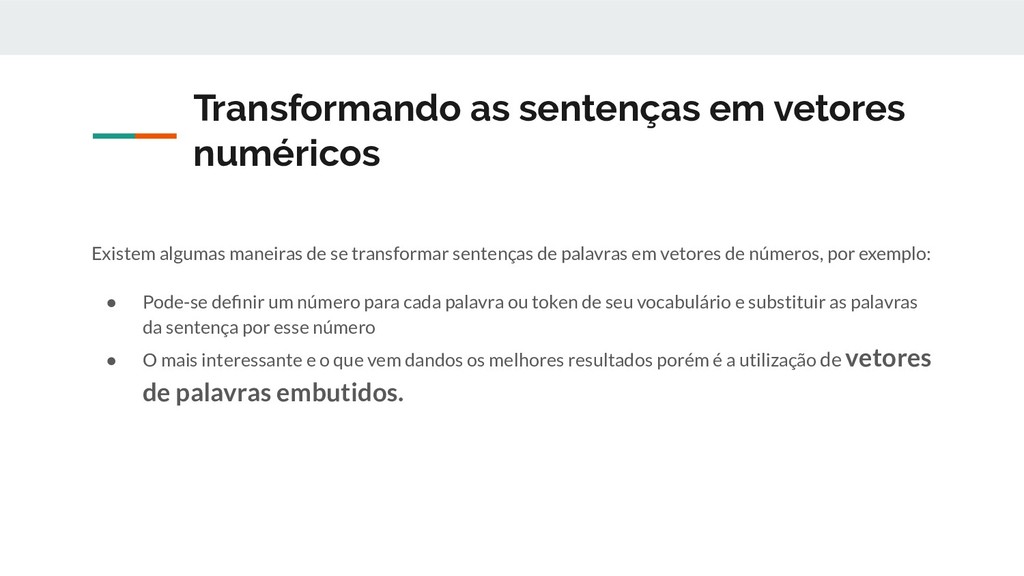
se transformar sentenças de palavras em vetores de números, por exemplo: • Pode-se definir um número para cada palavra ou token de seu vocabulário e substituir as palavras da sentença por esse número • O mais interessante e o que vem dandos os melhores resultados porém é a utilização de vetores de palavras embutidos.
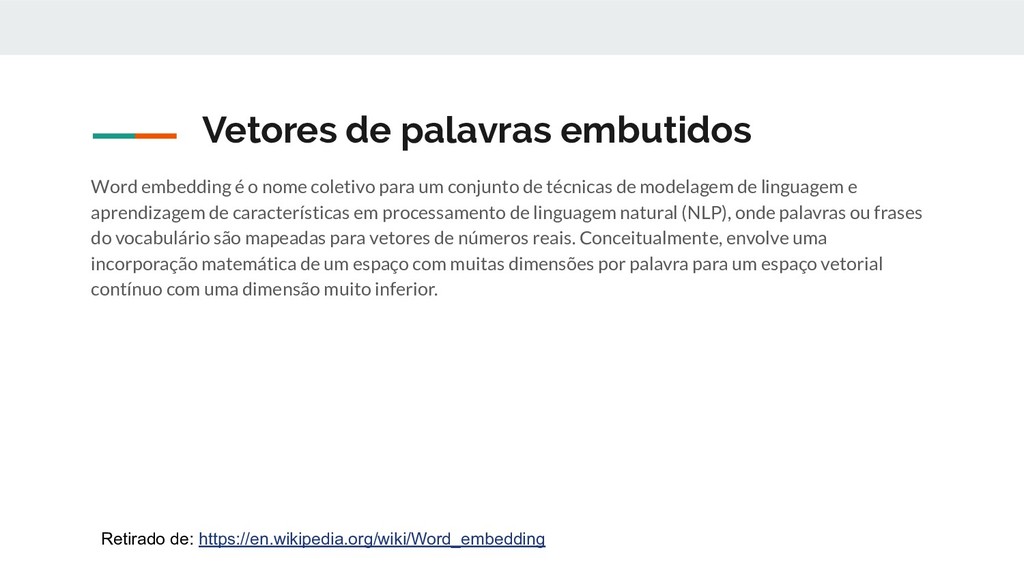
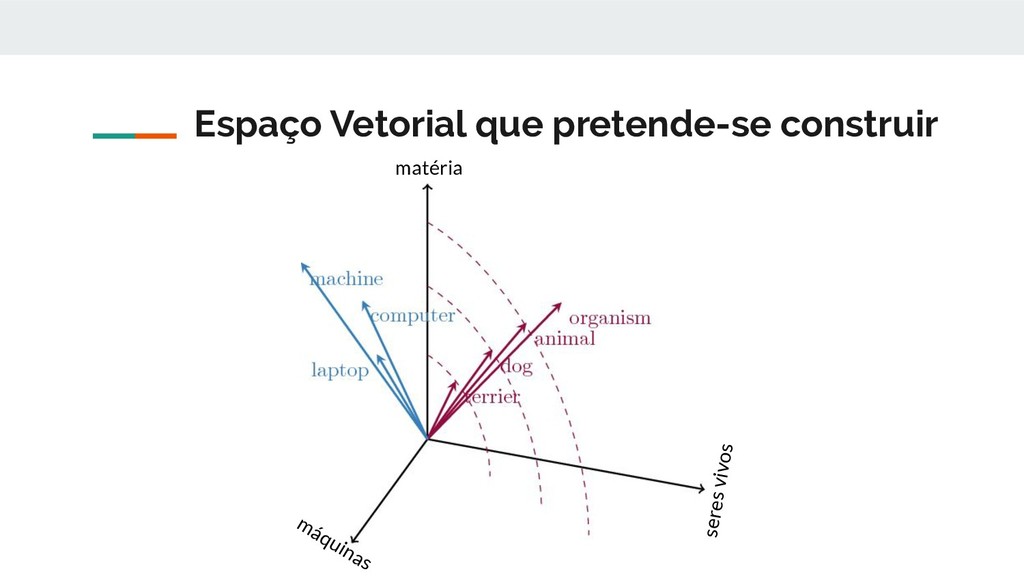
para um conjunto de técnicas de modelagem de linguagem e aprendizagem de características em processamento de linguagem natural (NLP), onde palavras ou frases do vocabulário são mapeadas para vetores de números reais. Conceitualmente, envolve uma incorporação matemática de um espaço com muitas dimensões por palavra para um espaço vetorial contínuo com uma dimensão muito inferior. Retirado de: https://en.wikipedia.org/wiki/Word_embedding
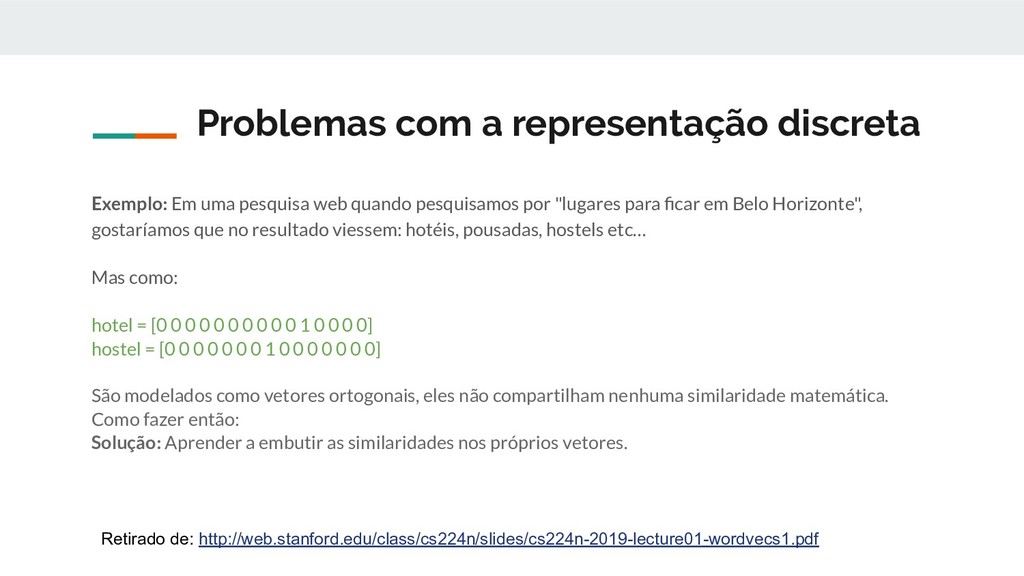
como símbolos discretos: hotel, conferência, motel. Uma representação que só leva em conta o contexto atual da palavra. Considerando isso podemos representar as palavras como vetores de 0's e 1's, chamados também de vetores one-hot: hotel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0] hostel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0] Nesse caso a dimensão dos vetores seria do tamanho do vocabulário (por exemplo 500.000) Retirado de: http://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture01-wordvecs1.pdf
quando pesquisamos por "lugares para ficar em Belo Horizonte", gostaríamos que no resultado viessem: hotéis, pousadas, hostels etc… Mas como: hotel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0] hostel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0] São modelados como vetores ortogonais, eles não compartilham nenhuma similaridade matemática. Como fazer então: Solução: Aprender a embutir as similaridades nos próprios vetores. Retirado de: http://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture01-wordvecs1.pdf
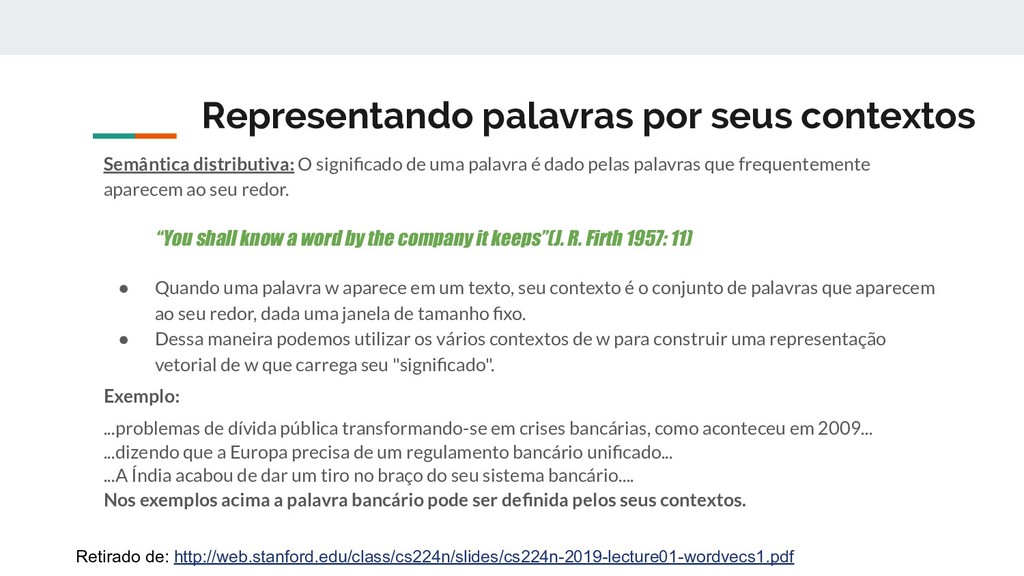
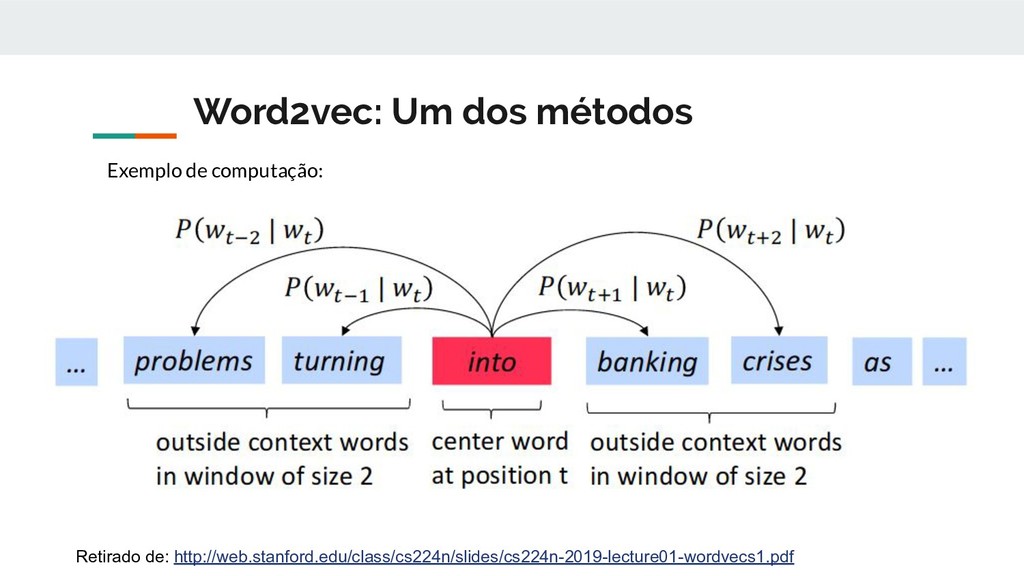
uma palavra é dado pelas palavras que frequentemente aparecem ao seu redor. “You shall know a word by the company it keeps”(J. R. Firth 1957: 11) • Quando uma palavra w aparece em um texto, seu contexto é o conjunto de palavras que aparecem ao seu redor, dada uma janela de tamanho fixo. • Dessa maneira podemos utilizar os vários contextos de w para construir uma representação vetorial de w que carrega seu "significado". Exemplo: ...problemas de dívida pública transformando-se em crises bancárias, como aconteceu em 2009... ...dizendo que a Europa precisa de um regulamento bancário unificado... ...A Índia acabou de dar um tiro no braço do seu sistema bancário.... Nos exemplos acima a palavra bancário pode ser definida pelos seus contextos. Retirado de: http://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture01-wordvecs1.pdf
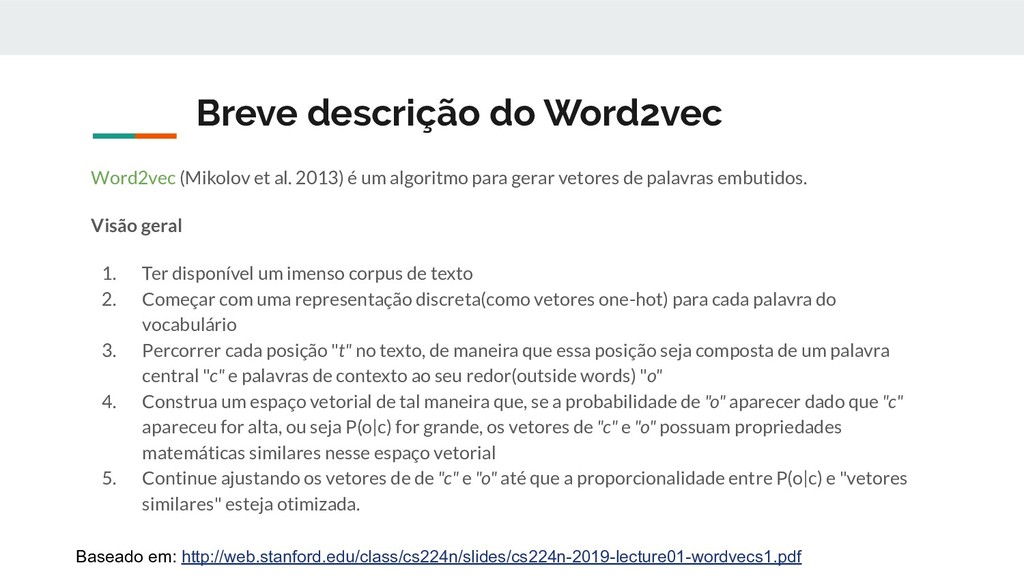
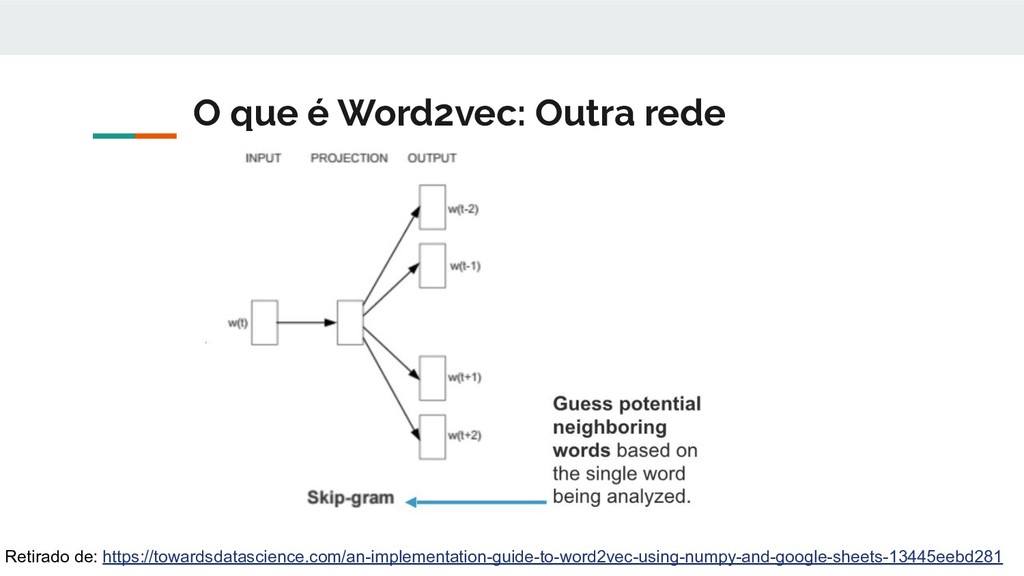
um algoritmo para gerar vetores de palavras embutidos. Visão geral 1. Ter disponível um imenso corpus de texto 2. Começar com uma representação discreta(como vetores one-hot) para cada palavra do vocabulário 3. Percorrer cada posição "t" no texto, de maneira que essa posição seja composta de um palavra central "c" e palavras de contexto ao seu redor(outside words) "o" 4. Construa um espaço vetorial de tal maneira que, se a probabilidade de "o" aparecer dado que "c" apareceu for alta, ou seja P(o|c) for grande, os vetores de "c" e "o" possuam propriedades matemáticas similares nesse espaço vetorial 5. Continue ajustando os vetores de de "c" e "o" até que a proporcionalidade entre P(o|c) e "vetores similares" esteja otimizada. Baseado em: http://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture01-wordvecs1.pdf
armazenamento e compartilhamento de vetores de palavras (do inglês, word embeddings) gerados para a Língua Portuguesa. O objetivo é fomentar e tornar acessível recursos vetoriais prontos para serem utilizados nas tarefas de Processamento da Linguagem Natural e Aprendizado de Máquina. O repositório traz vetores gerados a partir de um grande córpus do português do Brasil e português europeu, de fontes e gêneros variados. Foram utilizados dezessete córpus diferentes, totalizando 1,395,926,282 tokens. http://nilc.icmc.usp.br/embeddings
• Filtros: Tamanhos 3,4 e 5 • Função de ativação: ReLU (Rectified Linear Unit) • Max-pooling • Dropout de 0.5 Parte de classificação • Função de ativação: Softmax • Função de perda: Entropia cruzada • Algoritmo de backpropagation: Stochastic gradient descent (SGD) • Algoritmo de atualização da taxa de aprendizagem: Adam (Adaptive Moment Estimation)
Quantidade de exemplos de treino: 1.609.728 que corresponde a aproximadamente 87% do total. Quantidade de batchs de treino: 786 Tamanho do batch: 2.048 Ambiente de validação. Quantidade de exemplos de validação: 16.097 que corresponde a aproximadamente 0,9% do total. Tamanho do batch: 1609 Quantidade de batchs de validação: 10 Ambiente de testes. Quantidade de exemplos de validação: 215.663 que corresponde a aproximadamente 12% do total. Tamanho do batch: 2.048 Quantidade de batchs de validação: 106
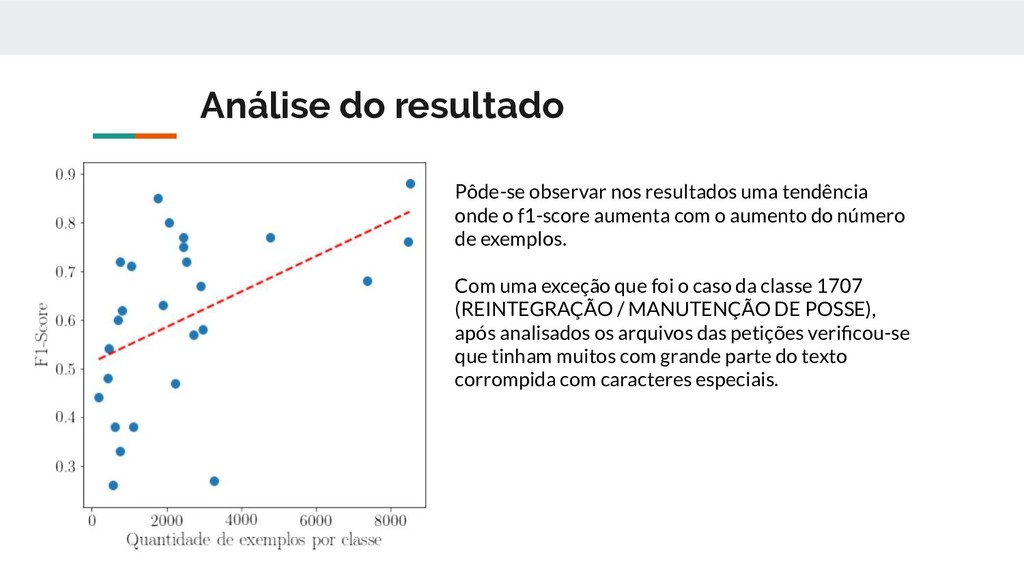
o f1-score aumenta com o aumento do número de exemplos. Com uma exceção que foi o caso da classe 1707 (REINTEGRAÇÃO / MANUTENÇÃO DE POSSE), após analisados os arquivos das petições verificou-se que tinham muitos com grande parte do texto corrompida com caracteres especiais.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}