The outline of the presentation that was given for 2012, February 7th's webmardi:
Life without MySQL: Manipulating data sets that break the single machine barrier
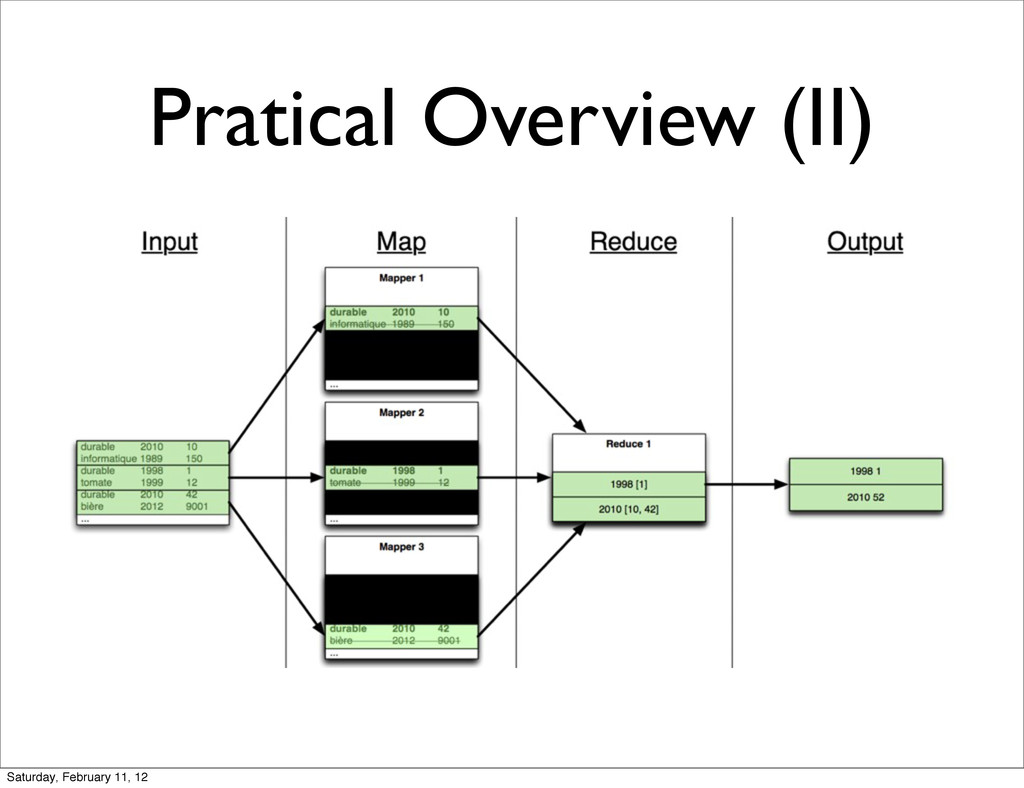
Understanding the role of Hadoop & Map/Reduce
Handling large amounts of storage and computing instances
Applications: Logs, Open Data, Streams
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}