Best of the Best Award - 1st Runner Up presentation by Infosys @STC 2012.
Authors - Mahesh Gudipati, Jaya Bhagavathi Bhallamudi & Shanthi Rao
Presentation Abstract
Big Data is one of the most discussed topics in recent times and implementation of Big Data is on the top of CIOs list. Taming big data is one of the opportunity areas looked by management in most of the organizations to unearth hidden valuable information. New technologies like Hadoop, HDFS, NoSQL DBs etc. are evolving to mine, store huge volume of data and Big Data market is expected to grow up to $50 Billion by 2017.
Big Data is a general term used to describe the voluminous amount of unstructured, structured and semi-structured data. Volume, Variety and Velocity (3Vs) are the three dimensions of Big Data. These three characteristics of Big Data require advanced technologies like distributed computing, in memory database, high volume storage systems to process and provide a meaningful data.
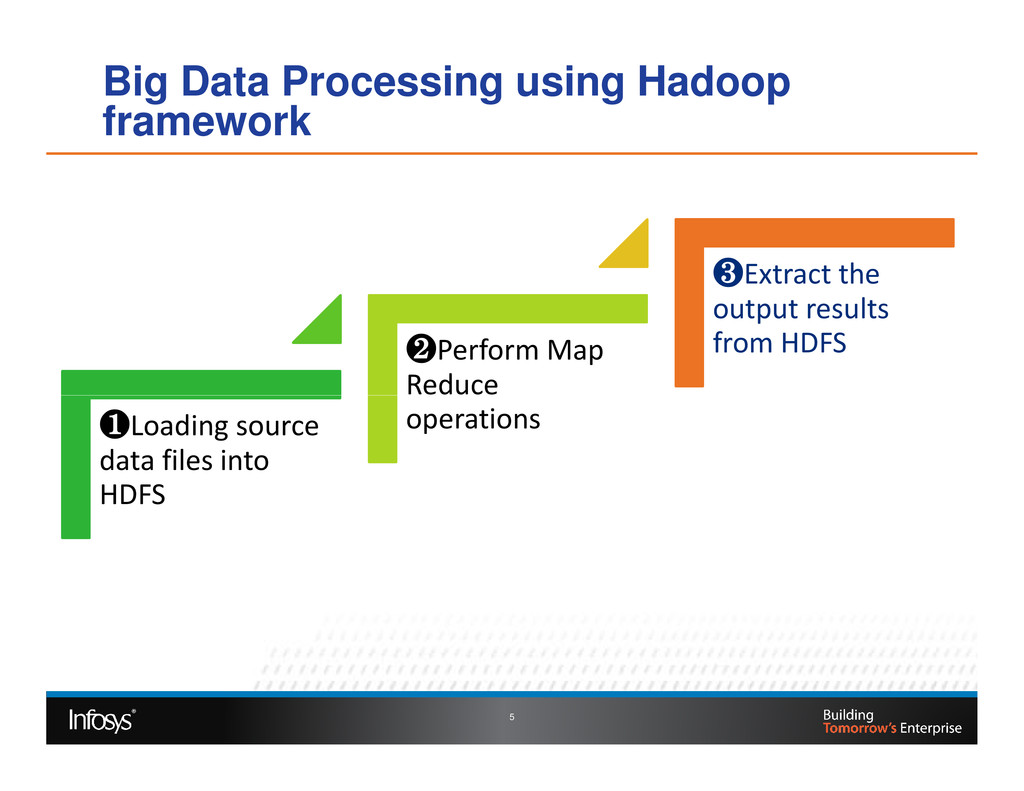
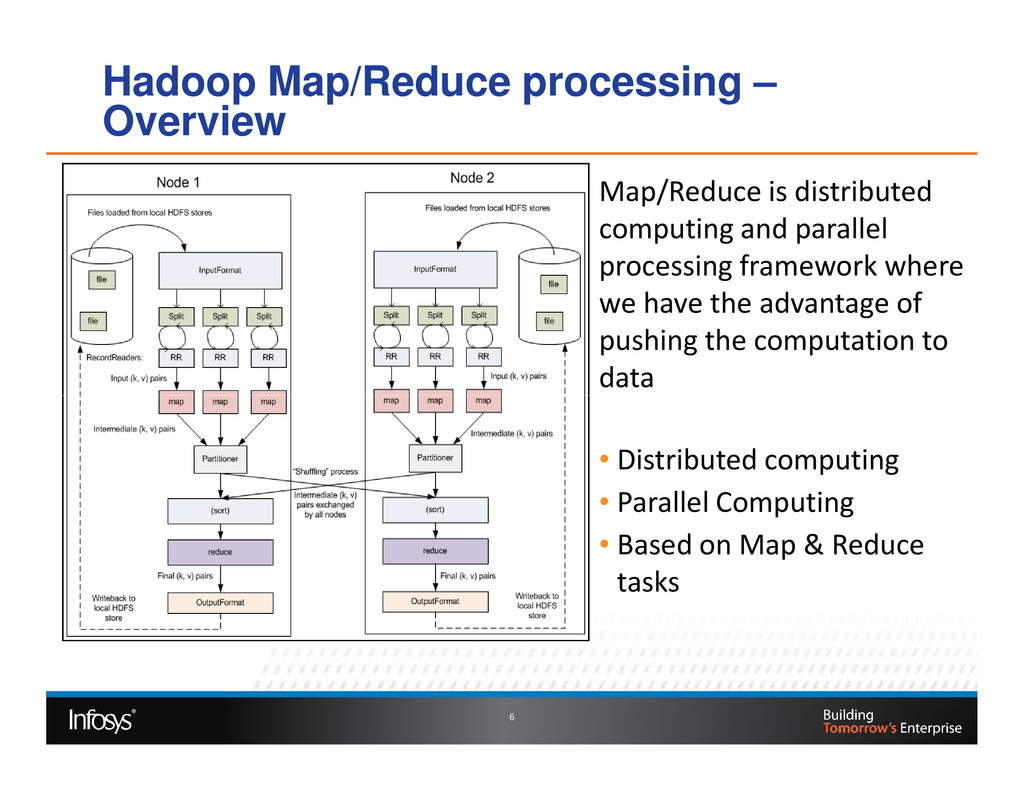
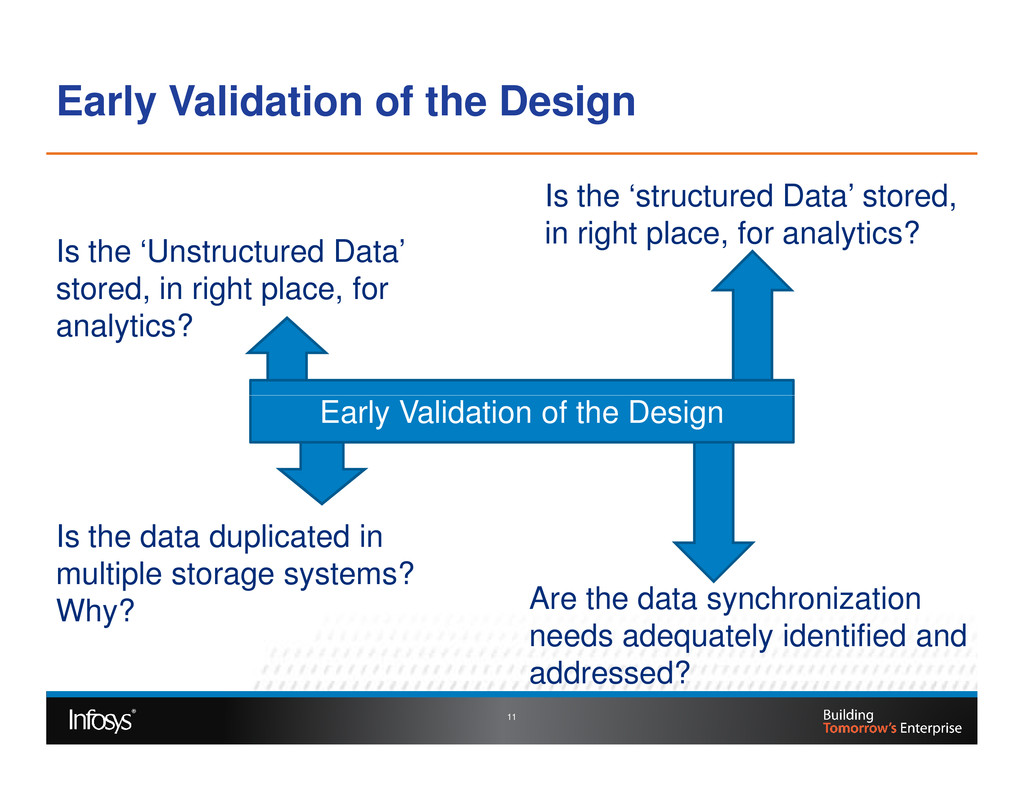
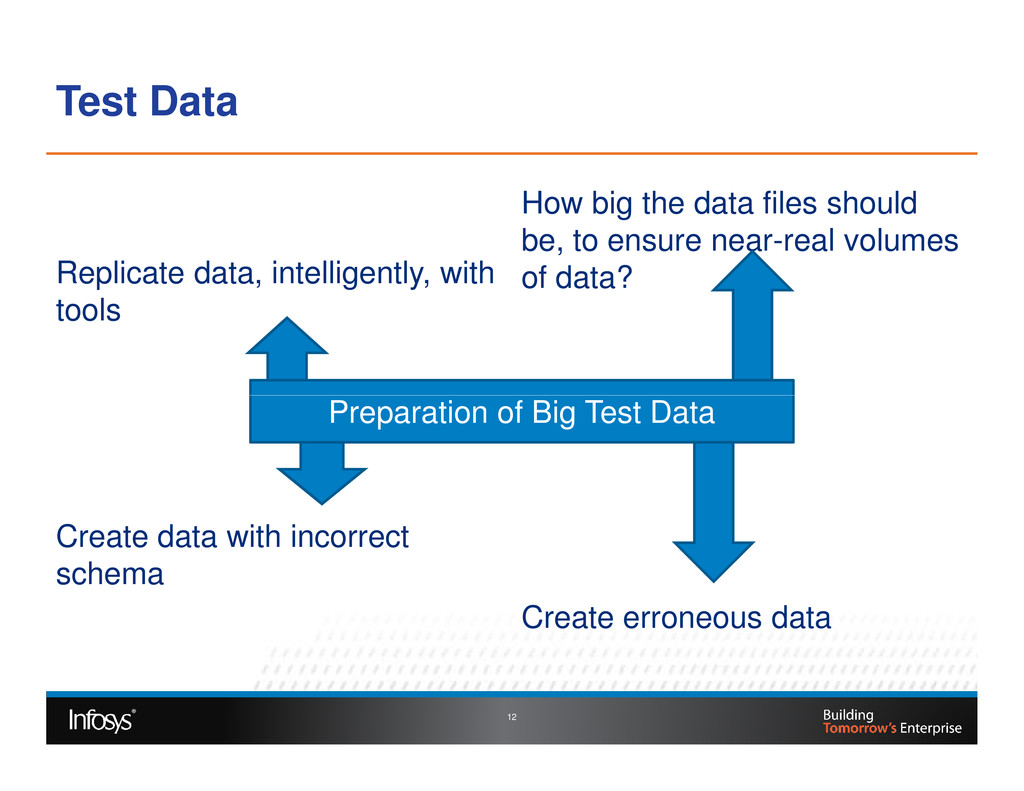
Testing of Big Data involves validating the data extract from source systems, validating Map Reduce jobs and load of data into external systems. At each of these validation stages the three Vs of Big Data need to be validated. Volume and Variety requires robust functional testing approach and velocity dimension requires non-functional testing. Validating requires skills on working with distributed file systems like HDFS, No SQL DBs and knowledge on Hadoop Map Reduce processing. In this paper we will talk about various approaches used for validating the Volume, Variety and Velocity dimensions of Big Data.
About the Authors
Mahesh is having more than 9 yrs of testing experience and have worked in multiple testing projects across different domains. He has strong experience working on data warehouse/BI testing, demand forecasting testing, Big Data testing and product testing. He has implemented automation techniques in multiple ETL/DW testing projects and holds a Patent for developing an end to end solution for ETL/DW testing. He is PMP certified project manager and has managed multiple data warehousing testing projects.
Jaya has over 14 years of experience in the IT industry. She is a Certified Function Point Specialist (CFPS from IFPUG ). She specializes in Test Automation and had led the Test Automation Services at Infosys, in the past. She is currently leading Research and Development of Infosys Validation Service offerings and solutions, focusing on specialized testing disciplines such as Data Validation, Security Testing, and Agile Testing. She contributes to both internal and external thought leadership papers and Infosys blog.
Shanthi has been in the IT industry for 15 years. She has widespread experience in all kinds of projects Development, Maintenance and testing. For the past 6 year she has been exclusively focusing on testing. She is a core member of Specialized testing practice working for Financial and Insurance customers. She is part of incubation team of new service lines like Test Data Management and Big Data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}