documents. obama budweiser baseball speech pizza words ϕk Topic k LDA tags each document with topics. politics sports news economy war topics θd Document d
1, ..., K do Draw a word-distribution ϕk ∼ Dir(β) for document d = 1, ..., D do Draw a topic-distribution θd ∼ Dir(α) for position i = 1, ..., N in document d do Draw a topic k ∼ Discrete(θd ) Draw a word wdi ∼ Discrete(ϕk )
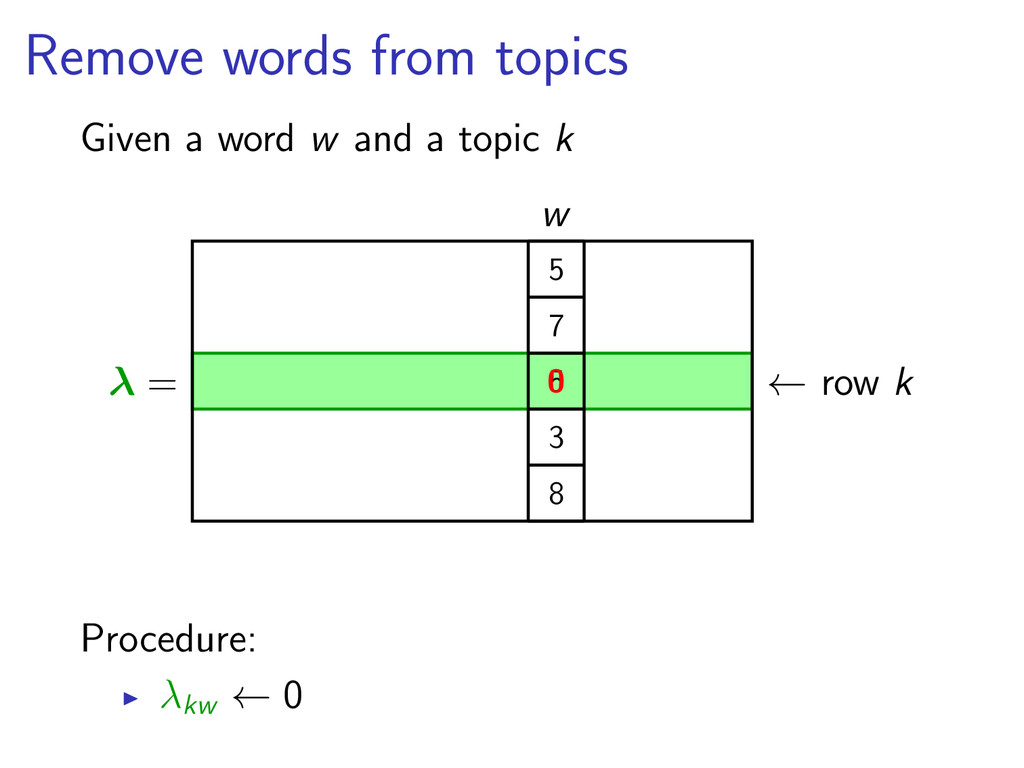
intractable Approximate it using Variational EM Instead of having ϕk ∼ Dir(β) Break dependencies ϕk ∼ Dir(λk ) λkw count(word w has been drawn from topic k)
convergence: E step. tag documents with topics keeping topics λ fixed M step. update topics λ according to assignments in E step We can modify topics λ between each epoch.
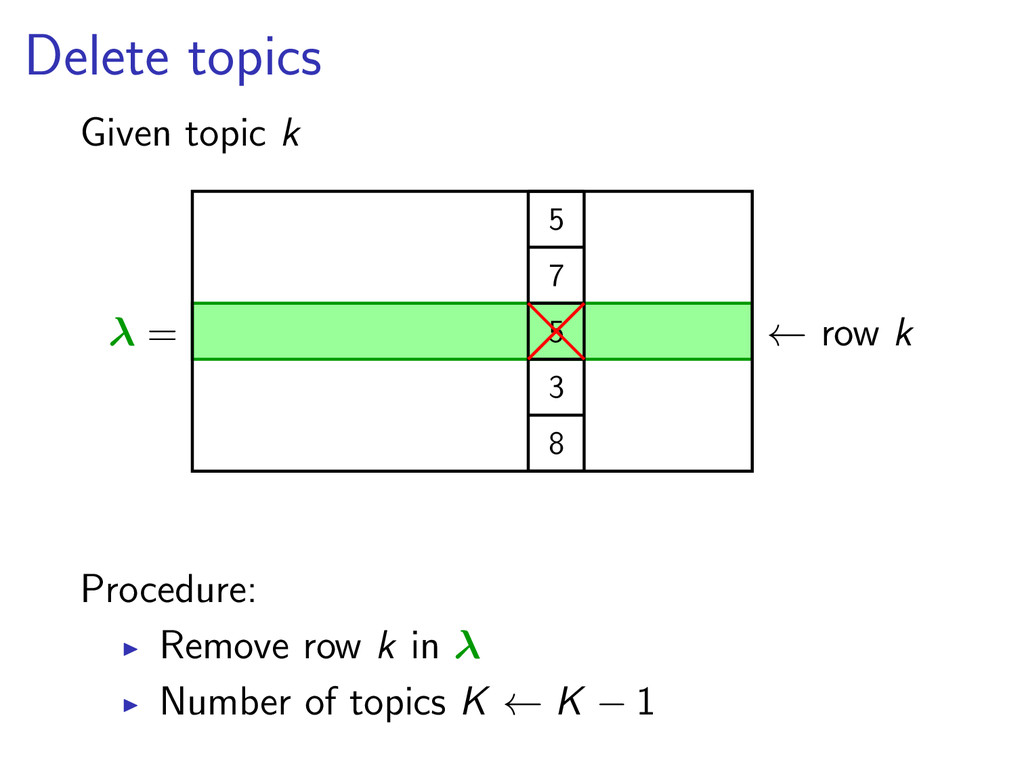
topic k1 λ = 1 3 5 7 5 2 1 1 8 4 ← row k1 ← row k2 move fraction ρw Procedure: Add a row k2 in λ For each word w: λk2 w = ρw λk1 w λk1 w = (1 − ρw ) λk1 w with ρw = p(w|W2 ) i p(w|Wi ) Number of topics K ← K + 1
No assumption about λ between epochs. Is the model still optimal? Yes. After each user update, LDA converges again. Variational EM Initialize λ randomly Repeat: E step tag docs M step update λ Interactive LDA Repeat: λ = EMepochs(λ) User updates λ
![Interactive LDA Quentin Pleple [email protected] May 3, 2013](https://files.speakerdeck.com/presentations/b76ffa509d8f013015e61ecd4316d9eb/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Previous work [Andrzejewski et. al, 2009] [Hu et. al, 2013]](https://files.speakerdeck.com/presentations/b76ffa509d8f013015e61ecd4316d9eb/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}