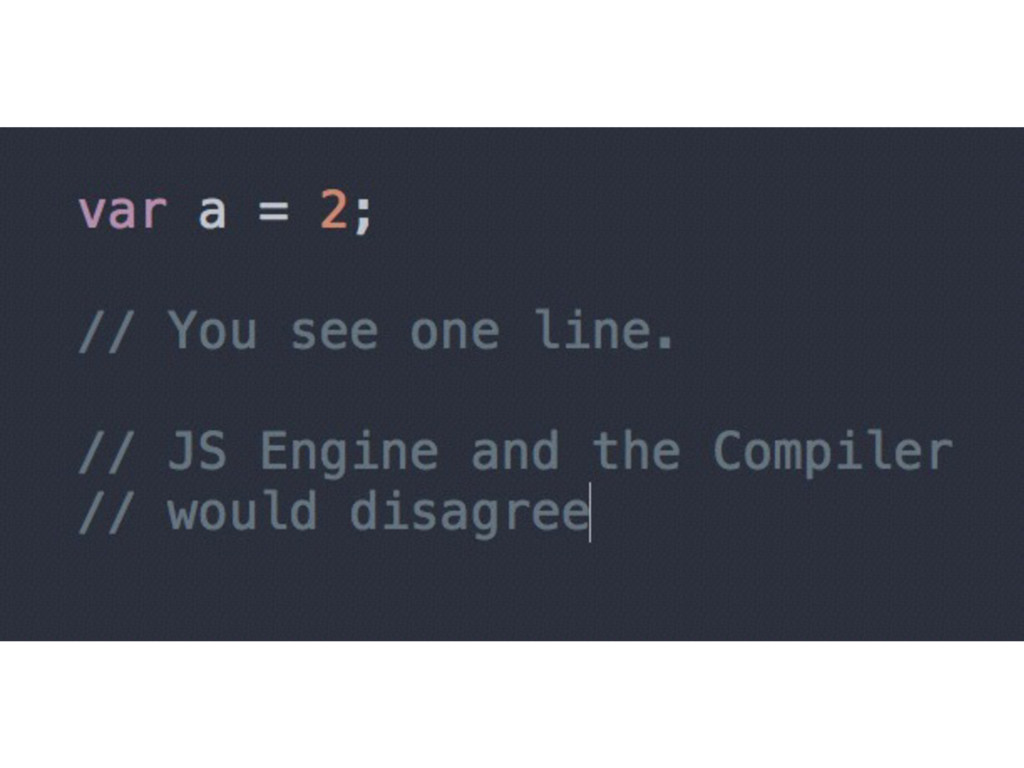
• Interpreted = line by line • Javascript is closer to a compiled language than to an interpreted one (compiled every single time) • There are differences (no bytecode, no compilations errors, we send the source code out not the compiled one, etc.)
and execution of our JS program • Compiler - handles all the dirty work of parsing and code-generation • Scope - collects and maintains a look-up list of all the declared identifiers (variables), and enforces a strict set of rules as to how these are accessible to currently executing code
characters and transform them into tokens (attributes, properties, etc.) • Parsing - get the tokens and generate an AST • Code-generation - take the AST and transform it into machine interactions • A lot of other stuff …
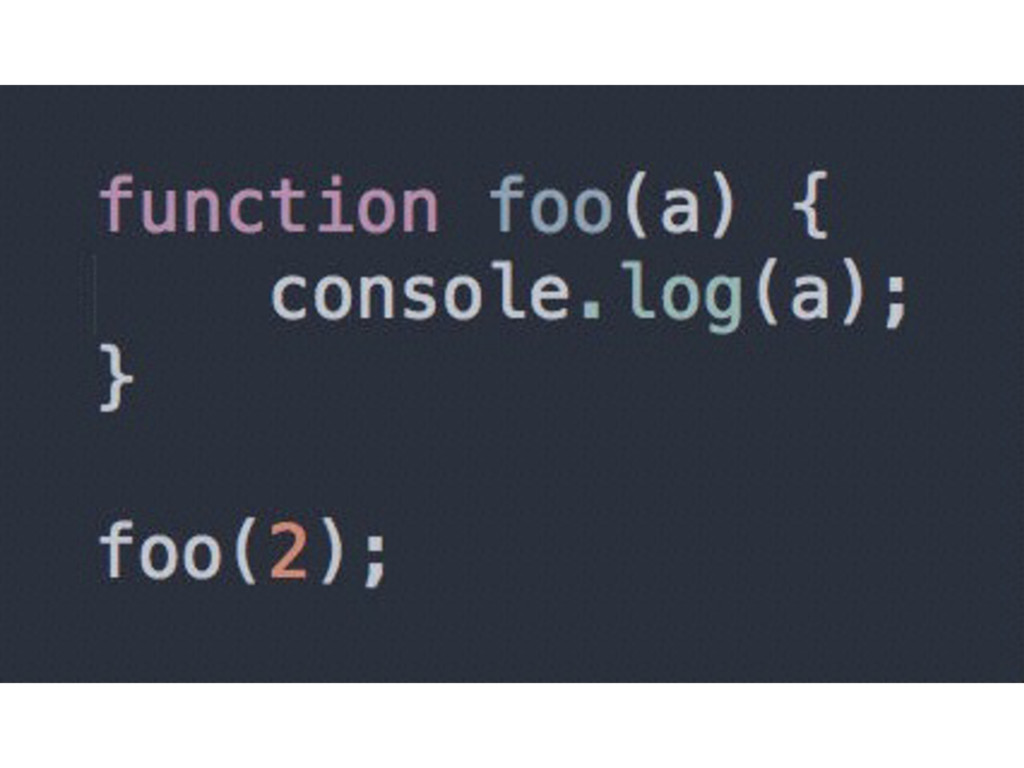
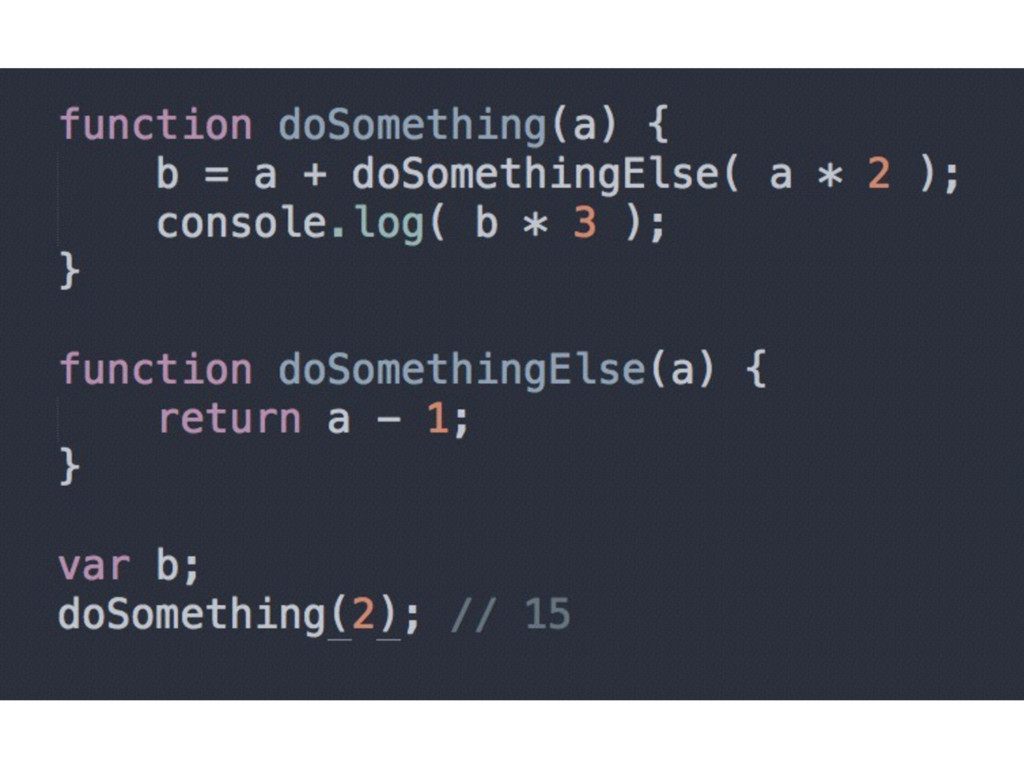
to see if a variable “a” already exists for that particular scope collection. If so, Compiler ignores this declaration and moves on. Otherwise, Compiler asks Scope to declare a new variable called “a” for that scope collection
to later execute, to handle the a = 2 assignment. The code Engine runs will first ask Scope if there is a variable called “a” accessible in the current scope collection. If so, Engine uses that variable. If not, Engine looks elsewhere (enter nested Scopes…)
reference for foo. Ever heard of it? Scope: Why yes, I have. Compiler declared it just a second ago. He's a function. Here you go. Engine: Great, thanks! OK, I'm executing foo. Engine: Hey, Scope, I've got an LHS reference for a, ever heard of it? Scope: Why yes, I have. Compiler declared it as a formal parameter to foo just recently. Here you go. Engine: Helpful as always, Scope. Thanks again. Now, time to assign 2 to a. Engine: Hey, Scope, sorry to bother you again. I need an RHS look-up for console. Ever heard of it? Scope: No problem, Engine, this is what I do all day. Yes, I've got console. He's built-in. Here you go. Engine: Perfect. Looking up log(..). OK, great, it's a function. Engine: Yo, Scope. Can you help me out with an RHS reference to a. I think I remember it, but want to be sure. Scope: You're right, Engine. Same guy, hasn't changed. Here you go. Engine: Cool. Passing the value of a, which is 2, into log(..).
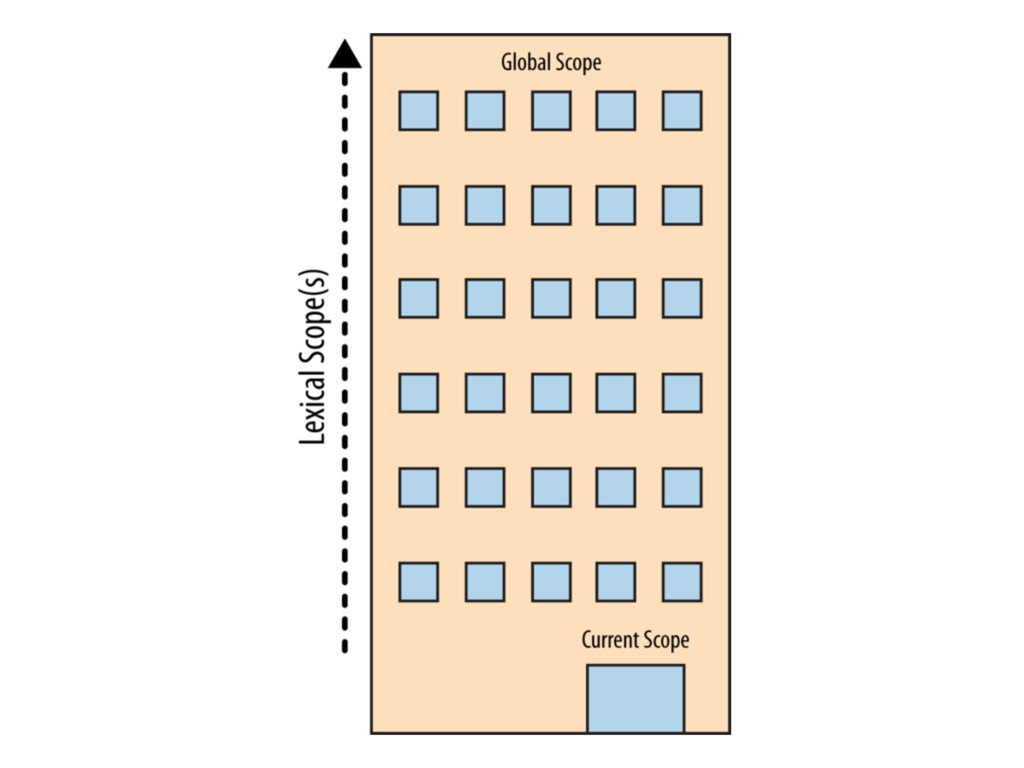
scopes as well • There’s always the feared global scope in JS • If a variable cannot be found in the immediate scope, Engine consults the next outer containing scope, continuing until found or until global scope is reached
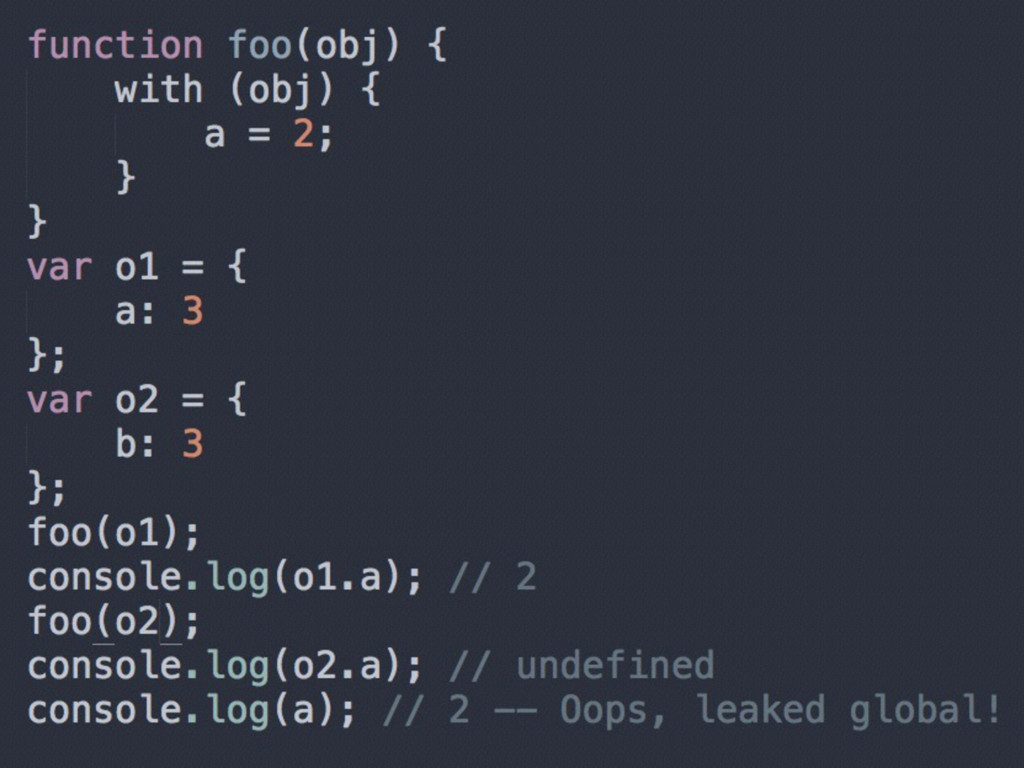
of b? Got an RHS reference for it. Scope: Nope, never heard of it. Leave me alone. Engine: Hey, Scope outside of foo, oh you're the global Scope, ok cool. Ever heard of b? Got an RHS reference for it. Scope: Yep, sure have. Here you go.
variable has not yet been declared • If an RHS look-up fails to ever find a variable, this results in a ReferenceError • If an LHS look-up fails, then the global Scope will create a new variable of that name in the global scope, and hand it back to Engine *
RHS look-up, but you try to do something with its value that is impossible, you get TypeError • ReferenceError is Scope resolution-failure related, whereas TypeError implies that Scope resolution was successful, but that there was an impossible action attempted
From random chars to tokens with semantic meaning • Lexical scope is scope that is defined at lexing time • It is based on where variables and blocks of scope are authored at write time, and thus is (mostly) set in stone by the time the Lexer processes your code
• One for the global scope and one for the anonymous function • The bubble for the anonymous function is strictly contained in the bubble of the global scope
The same identifier can be specified multiple times in different scopes - shadowing • Only shadowed global variables can be accessed even if they are shadowed - window.x
where from or how a function is invoked, its lexical scope is only defined by where the function was declared • The lexical scope look-up process only applies to first-class identifiers • Eg: foo.bar - lexical finds only foo after which object property-access rules take over
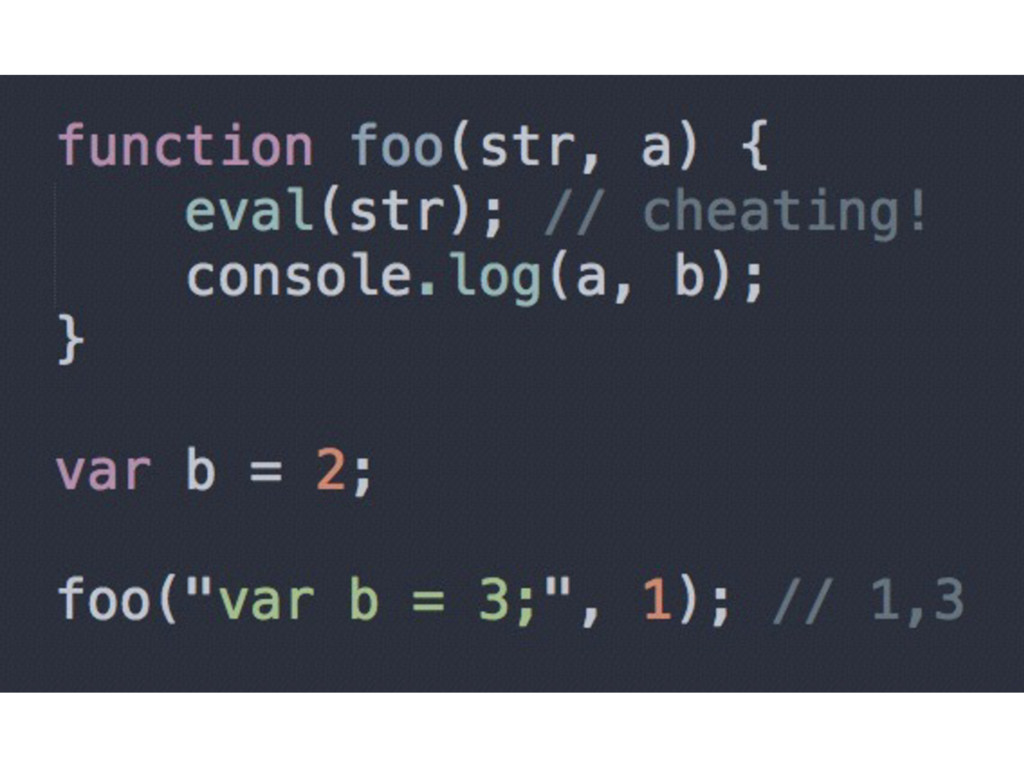
it were written at author time • Bad because the Engine will preserve its behaviour (make the same look-ups, etc.) • The evaluation of the string in eval dynamically modifies the lexical scope (variable declarations, etc.)
references against an object without repeating the object each time • Treats that object as if it is a wholly separate lexical scope (actually it creates it) • Also a bad thing!
(modify or create a new one) • This poses performance problems because the Engine cannot perform its optimizations at lexing time (the Engine will always try to reduce the look- ups time, but with eval or with, it’s impossible, so he makes none) • Don’t use them! (best practice)
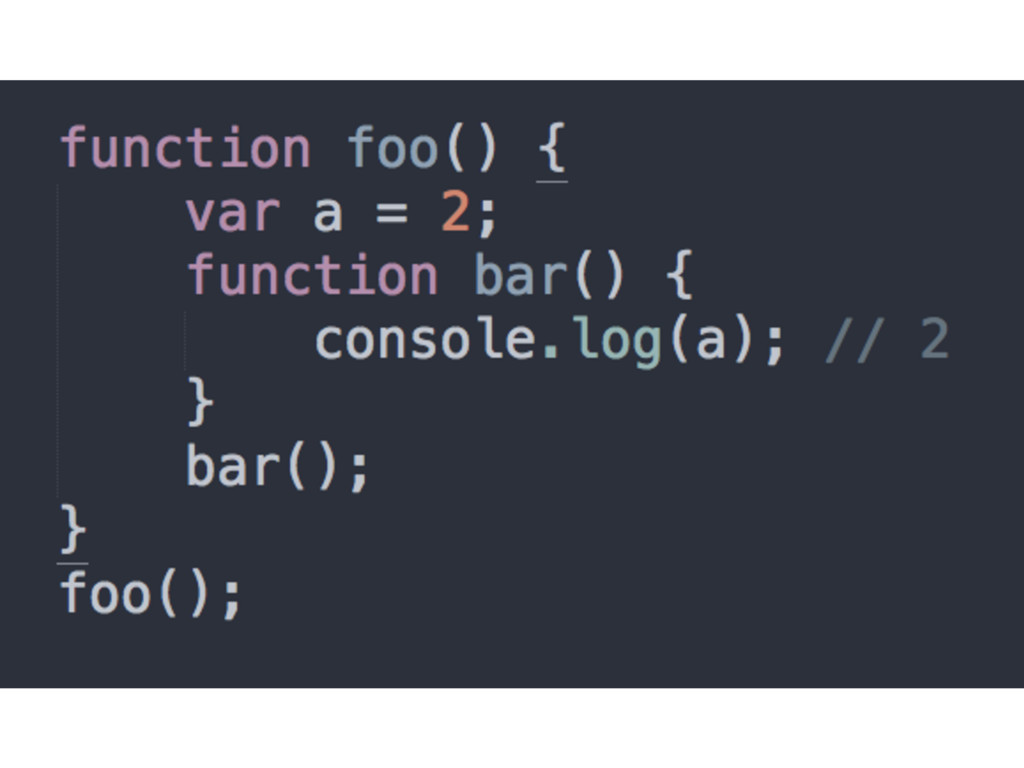
* • Each function with its own scope bubble * • Nesting is always preserved - scopes end up forming a hierarchy that represent the landscape of variable look-ups
arbitrary piece of code, wrap a function over it, and make it “private” • Hiding variables employs the Principle of Least Privilege (Least Exposure) • Avoids global pollution (also a best practice)
as a wrapper over an existing piece of code, we get “privacy” • But we also introduce a new function name + the fact that we have to call the function specifically • Javascript to the rescue!
can have parameters passed if you need certain bindings (eg: window) • IIFE is a function expression not a function declaration (first word is not function) • An encouraged pattern and very useful sometimes
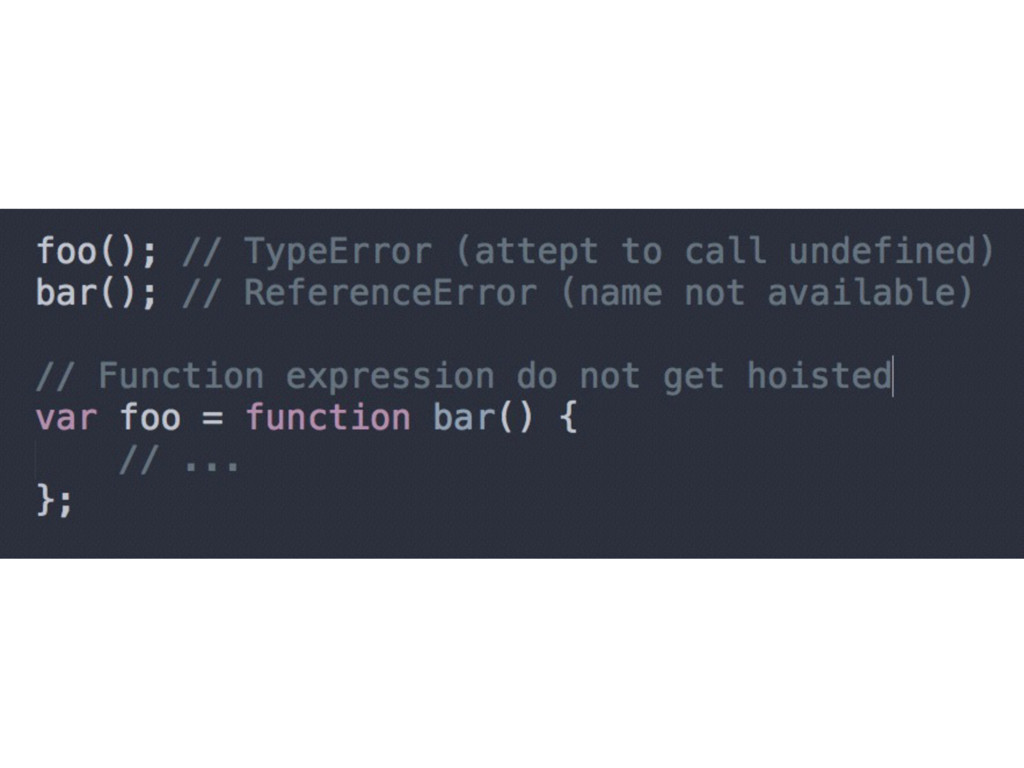
a name • Function declarations can be put anywhere in the code (even be called before they were declared - hoisting) • Function expression will have the assignment after the compilation phase • Function declaration - first word is function
your function expressions (even IIFEs sometimes) • Names in stack traces - easier debugging • Can have recursion in place (there are methods to recursively call an anonymous function but don’t do it) • Names can be descriptive and help with code understanding
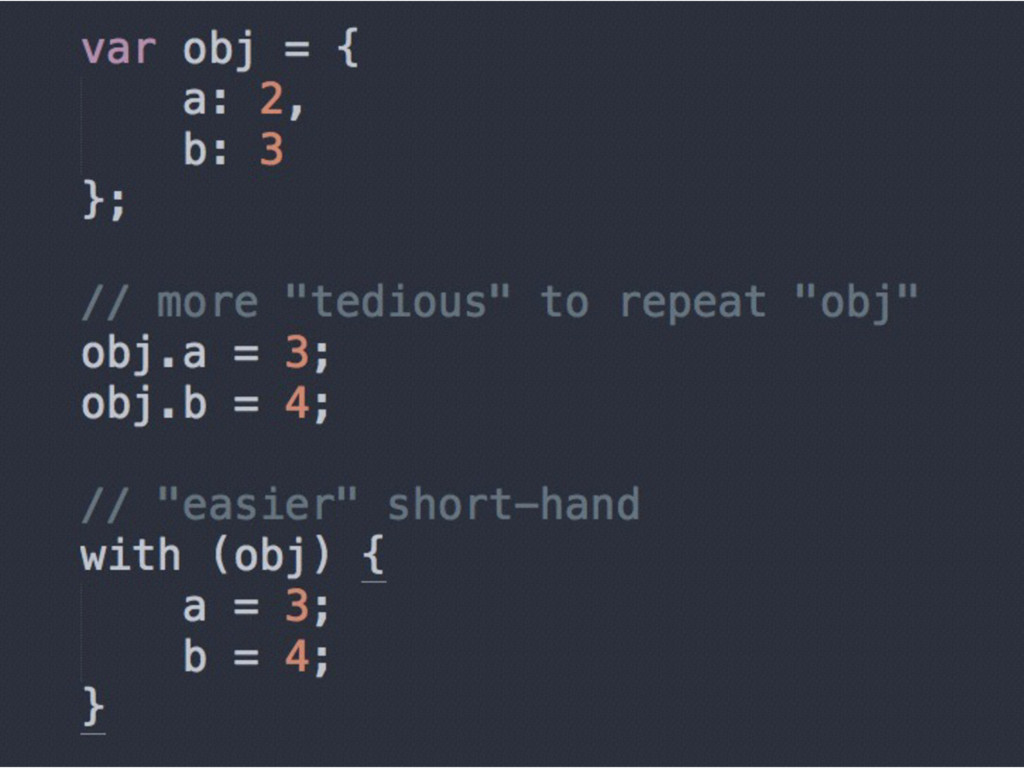
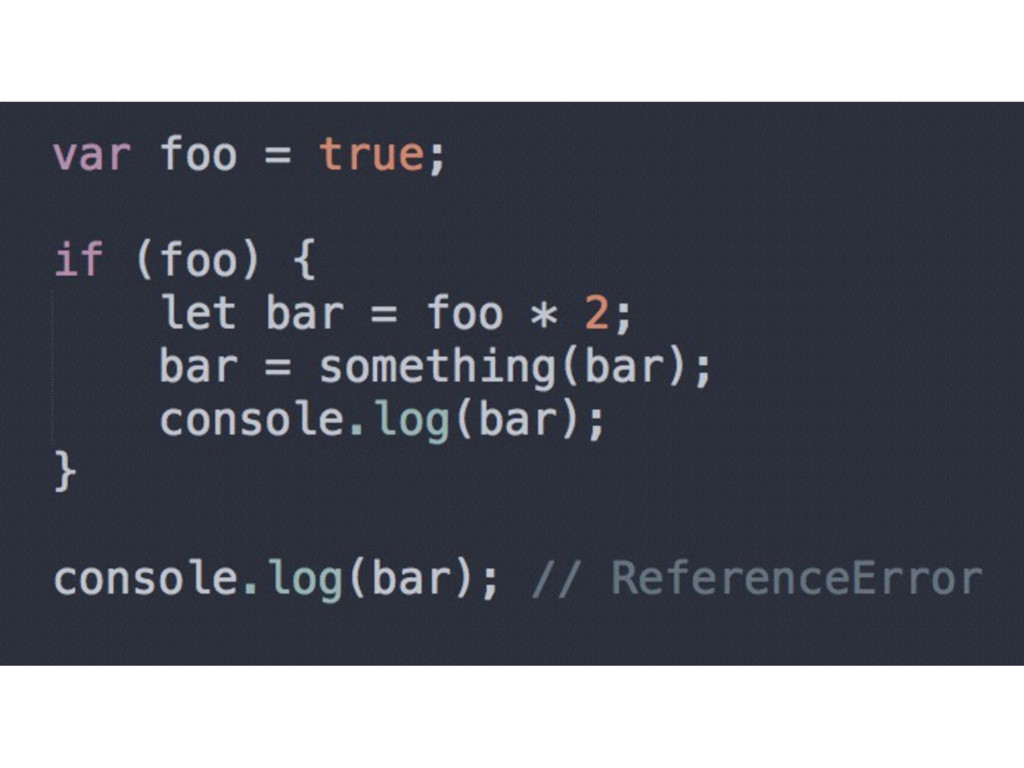
it is an example of block scope (exists for the lifetime of that with statement) • try/catch - variables defined in catch are local to the definition • But the real deal with block-level scope in ES6 is…
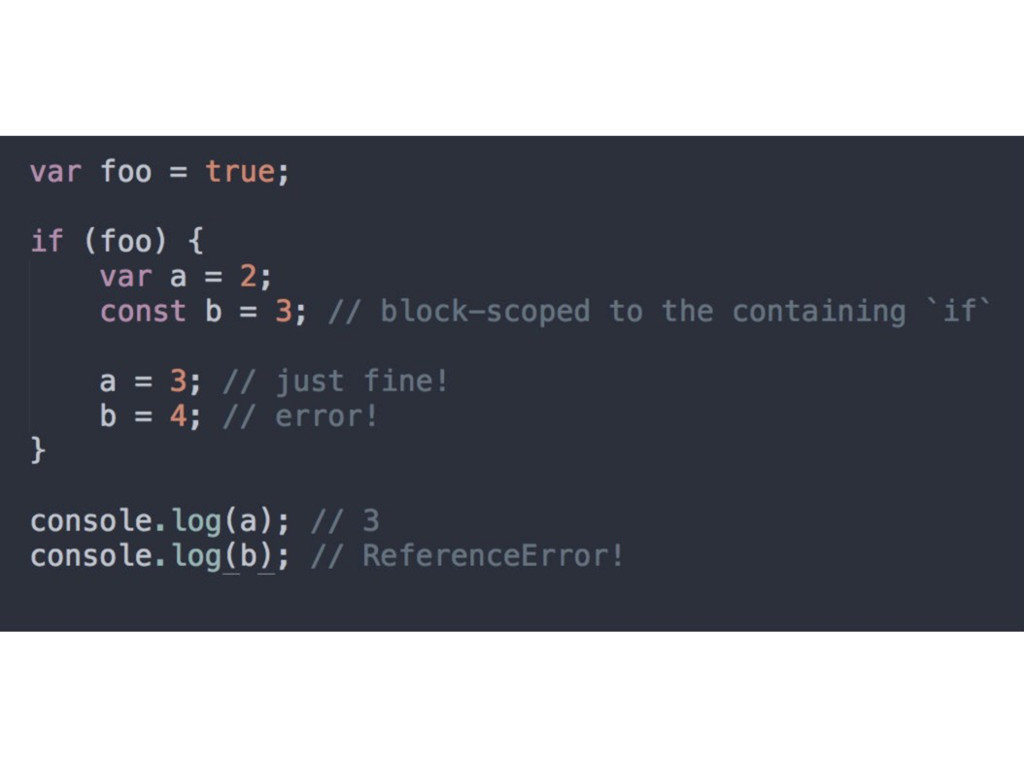
way to declare a variable • Memory efficient - facilitates GC • Attaches the variable declaration to the scope of whatever block it's contained in • Does not hoist!
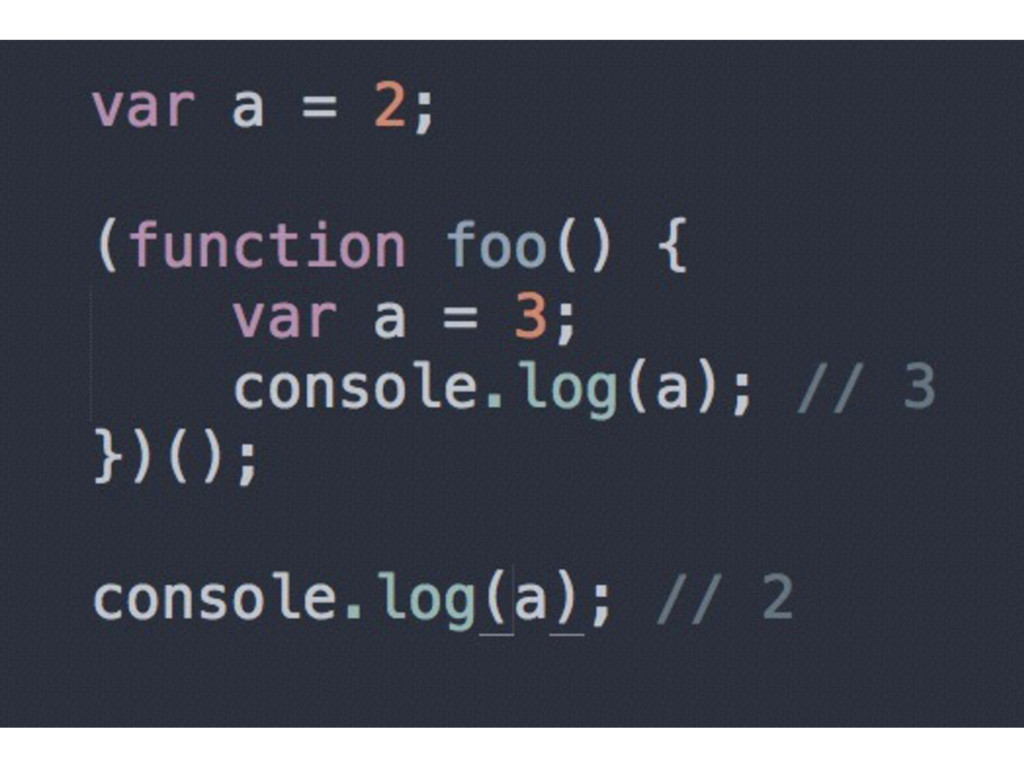
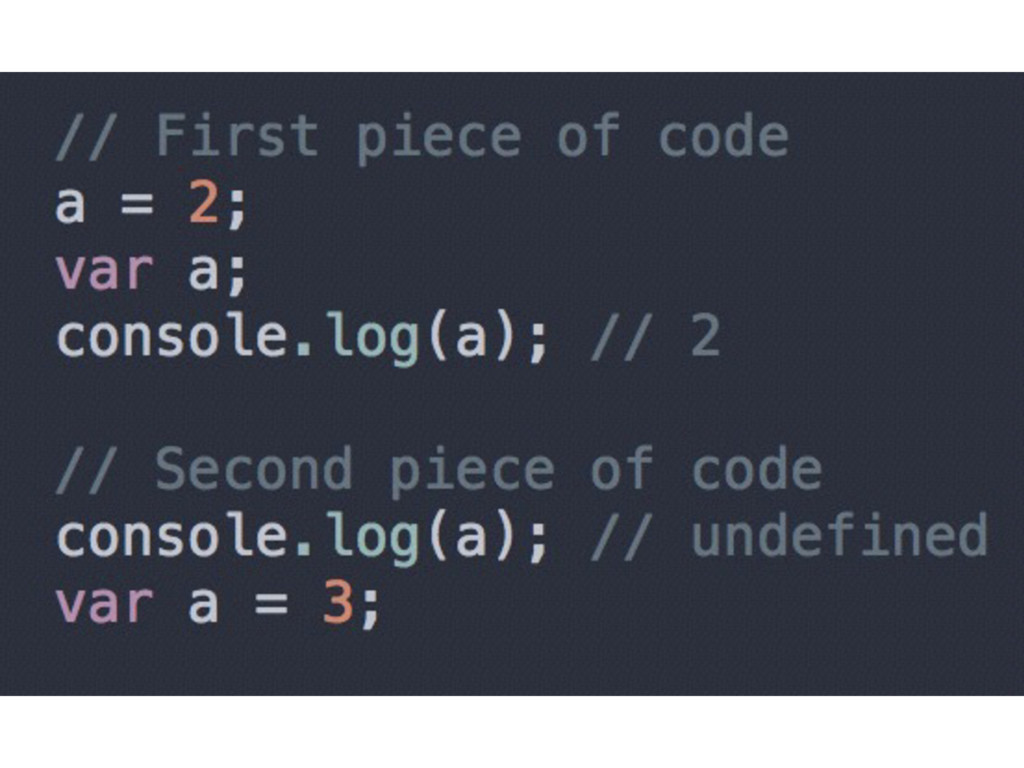
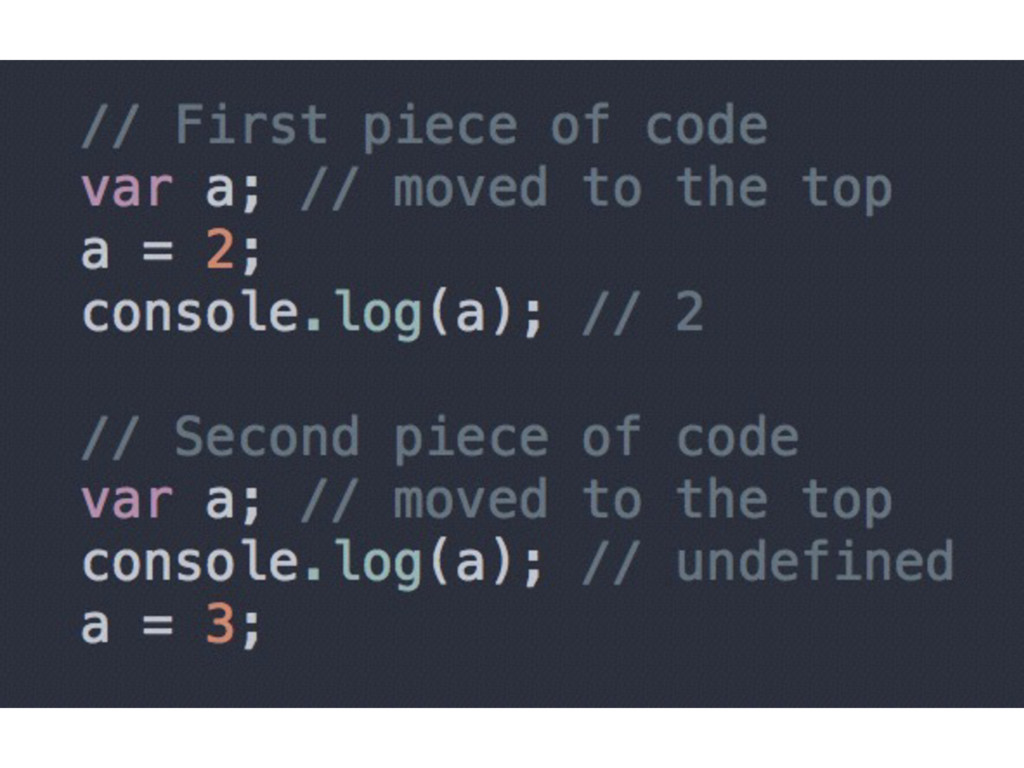
• Instead of var a = 2; the JS Engine sees two instructions: var a; and a = 2; • The first statement is processed during the compilation phase • The second one is left in place for the execution phase
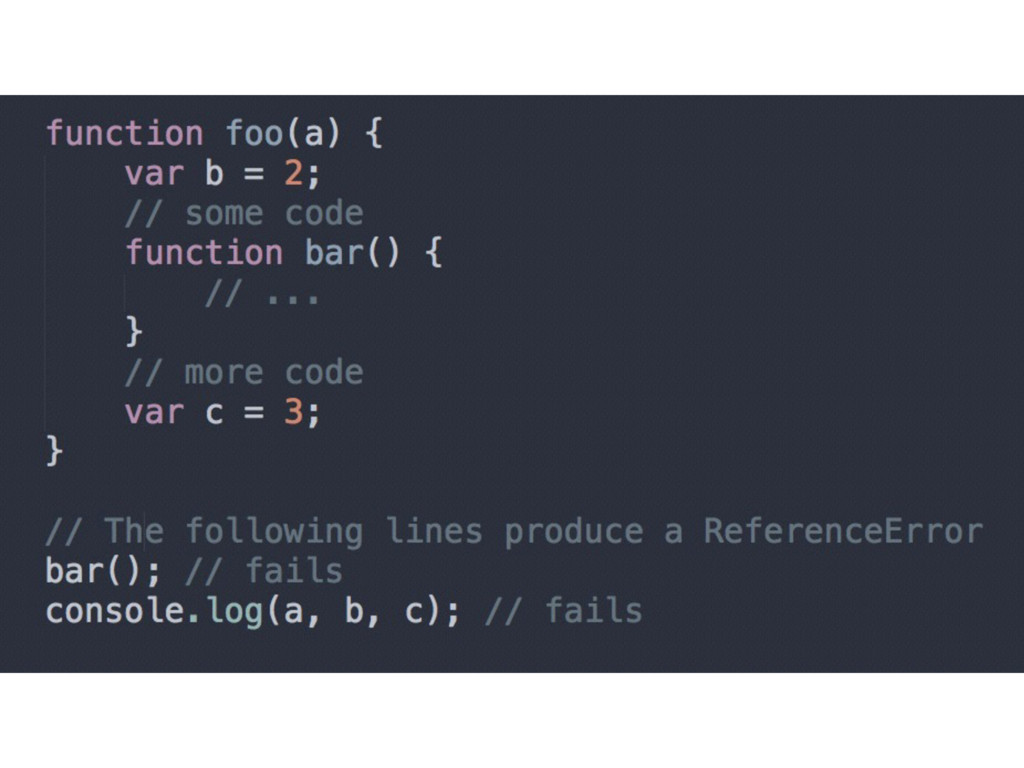
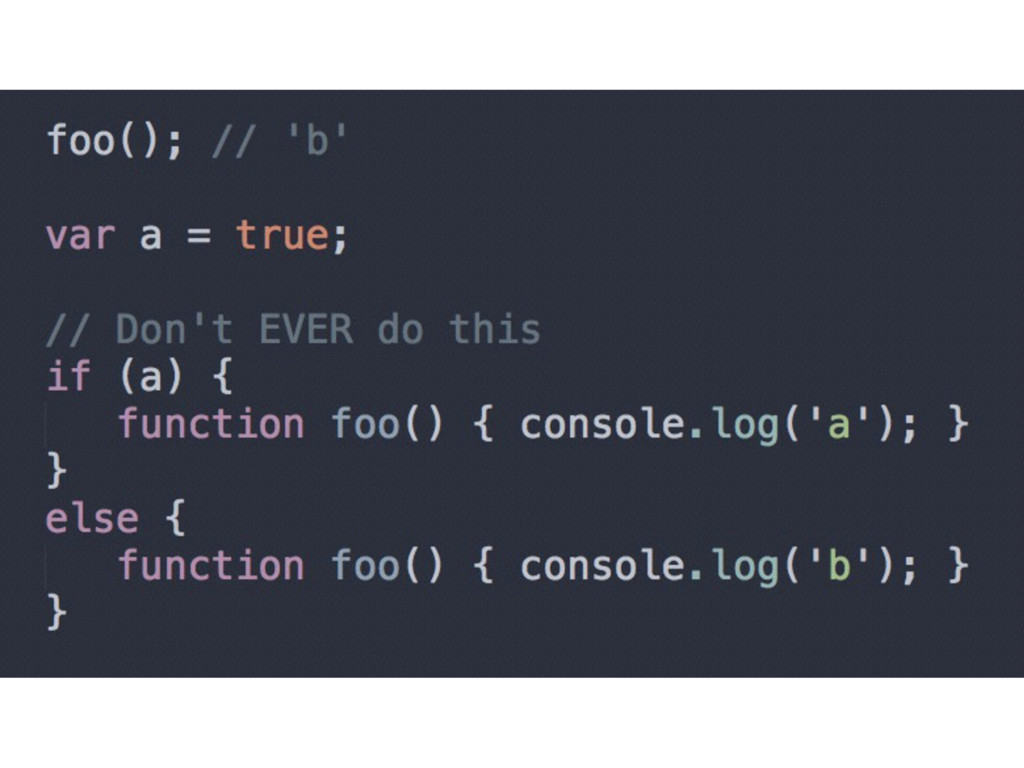
you can call foo before it is defined as a function declaration) • Applies to the containing scope only • It’s not a good idea to rely on hoisting as a feature
It’s the developer’s responsibility (and a best practice) to declare all variables at the top of the containing scope • Use named function expressions instead of function declarations (always rely on WHERE you call the functionality)
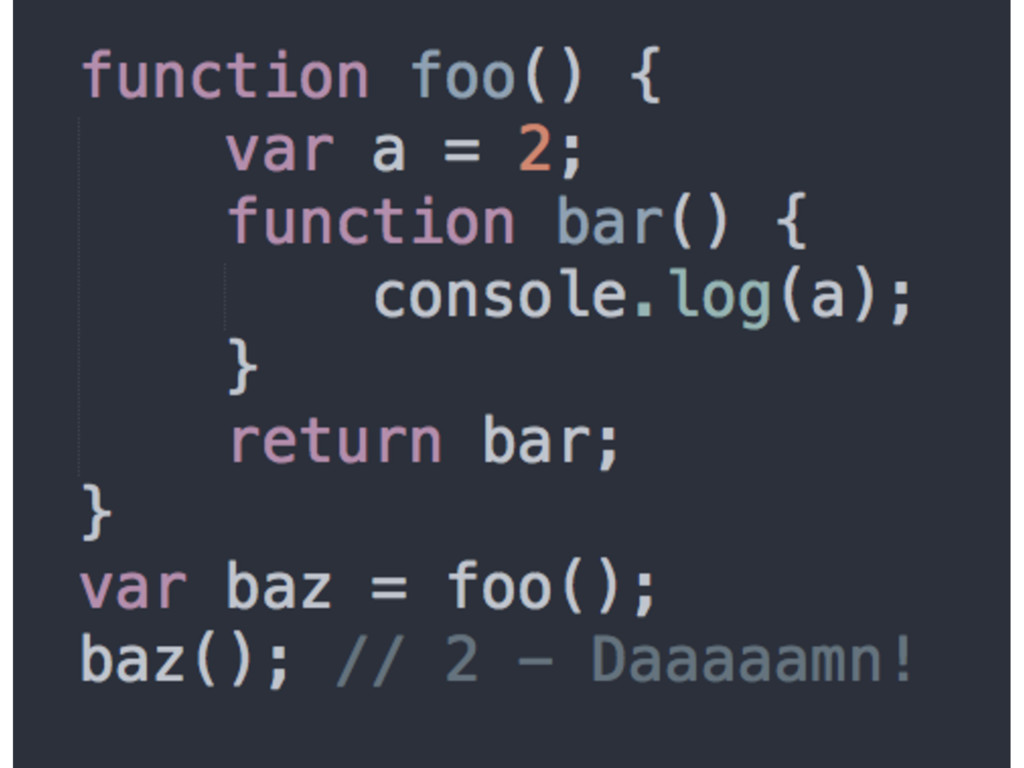
Closures happen as a result of writing code that relies on lexical scope • What you are missing is the proper mental context to recognize, embrace, and leverage closures for your own will
value (in this case, we return the function object itself that bar references) • After foo() executed, we would expect that the entirety of the inner scope of foo would go away because the Engine employs a Garbage Collector for that • bar is using the inner foo scope = MAGIC (still has a reference to that scope and it’s called closure)
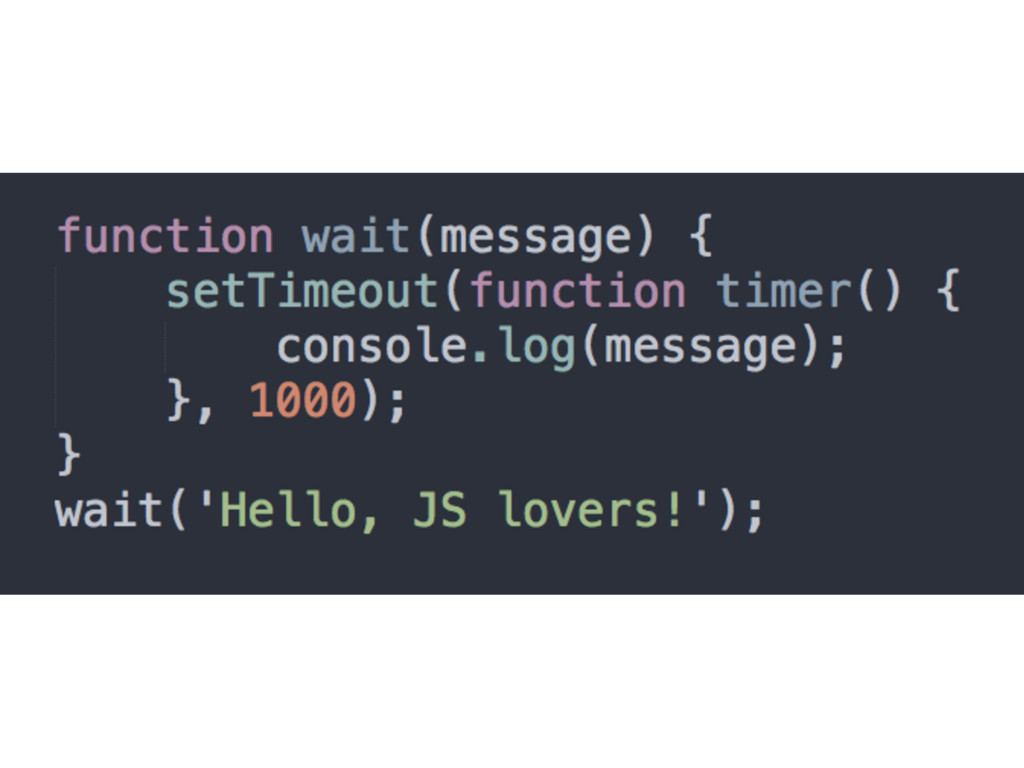
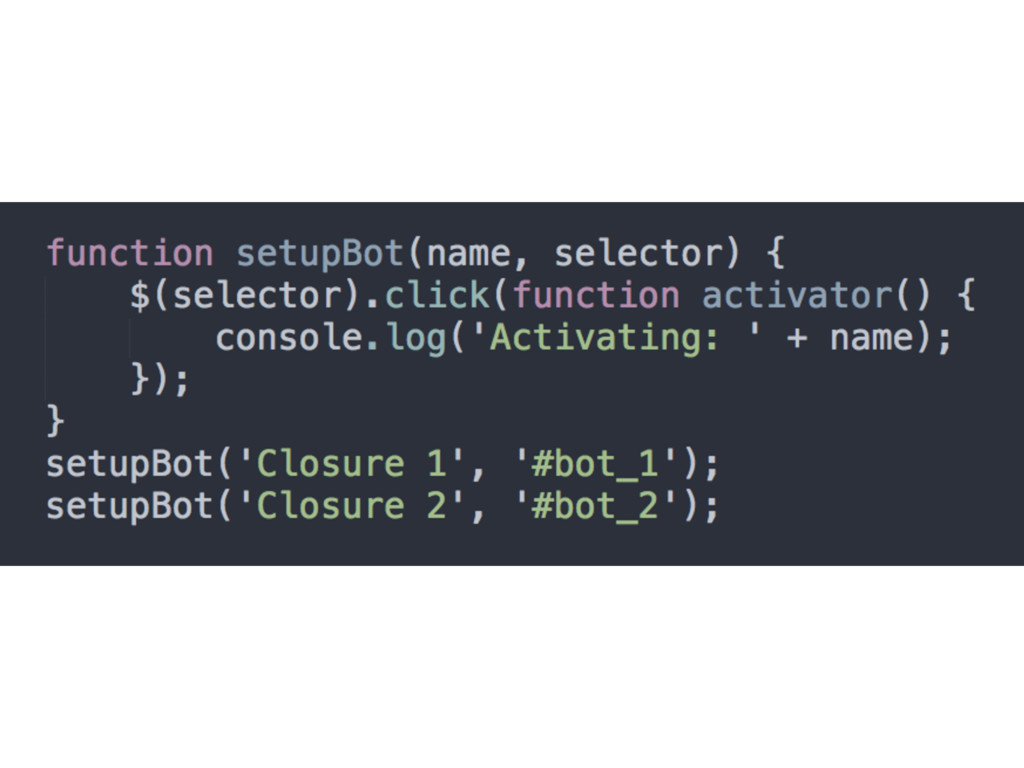
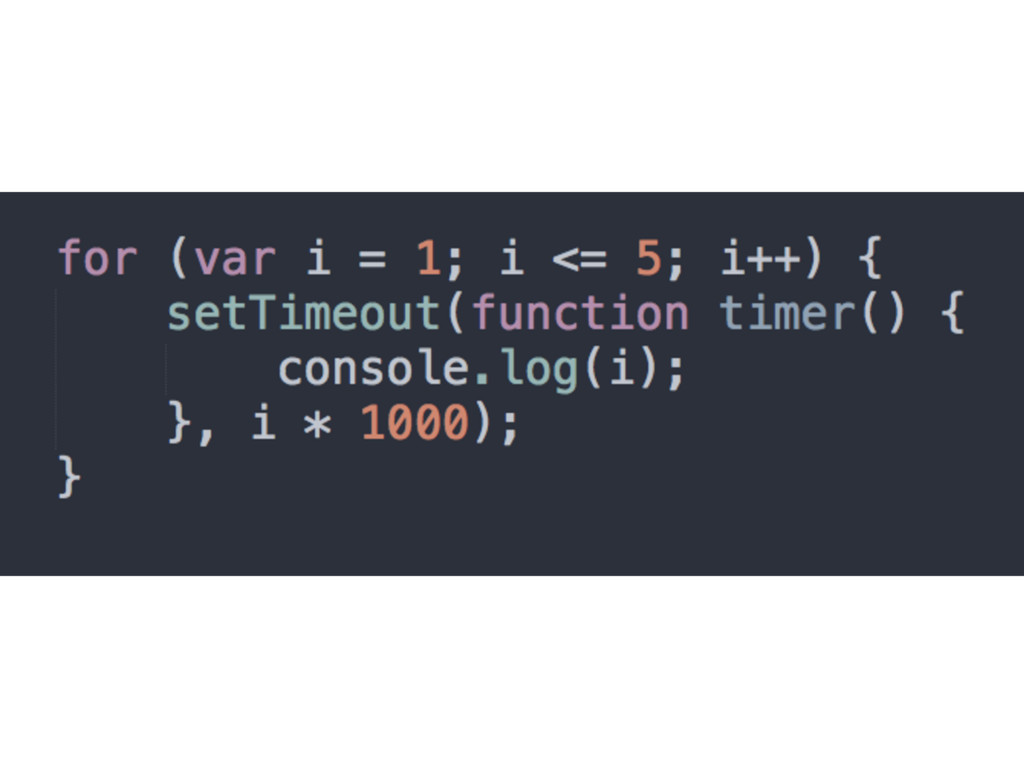
pass them around, you’ll probably see closures in action • Timers, event handlers, AJAX requests, cross- window messaging, web workers, callback, etc. • IIFE is not exactly a closure because it’s not executed outside of its lexical scope
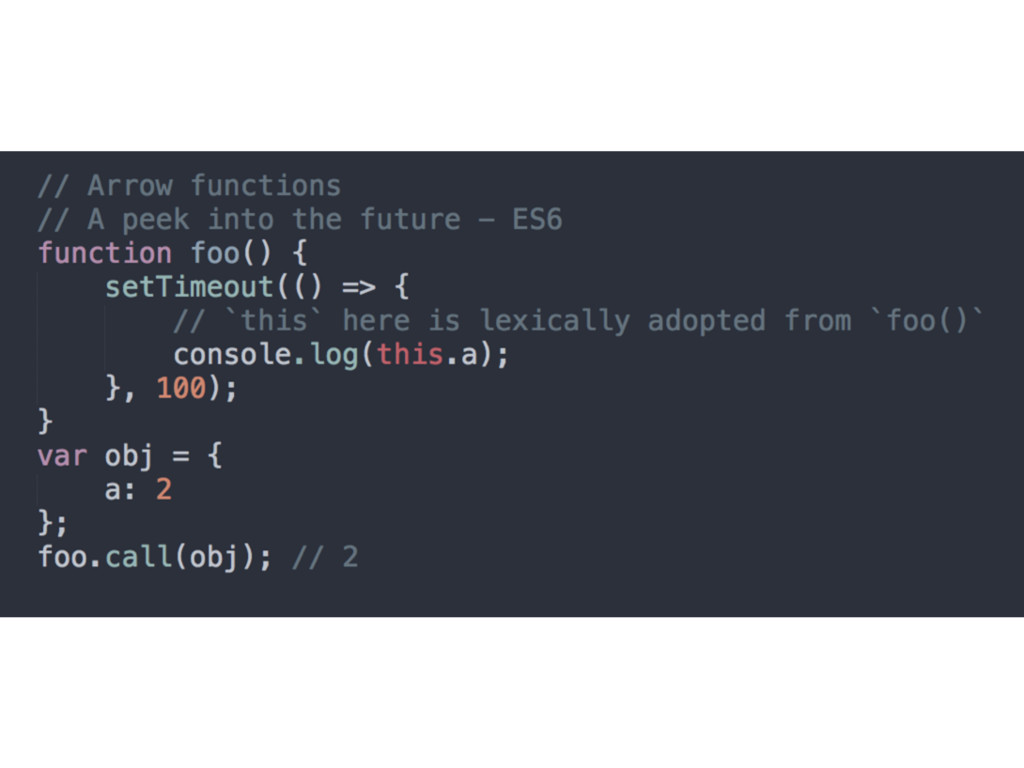
an author-time binding) • this binding has nothing to do with where a function is declared, but with the manner in which the function is called • When a function is invoked an execution context is created (one of the props is this)
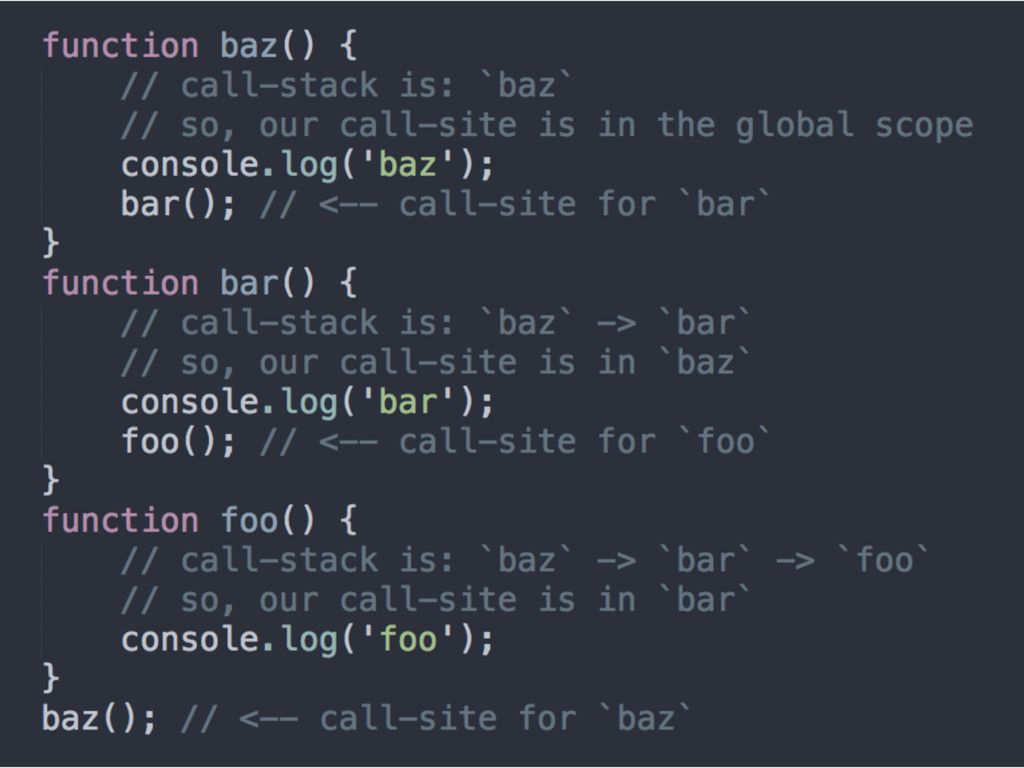
function is called • Some programming patterns can obscure the real call-site of a function • Think about the call-stack. The call-site we care about is in the invocation before the currently executing function
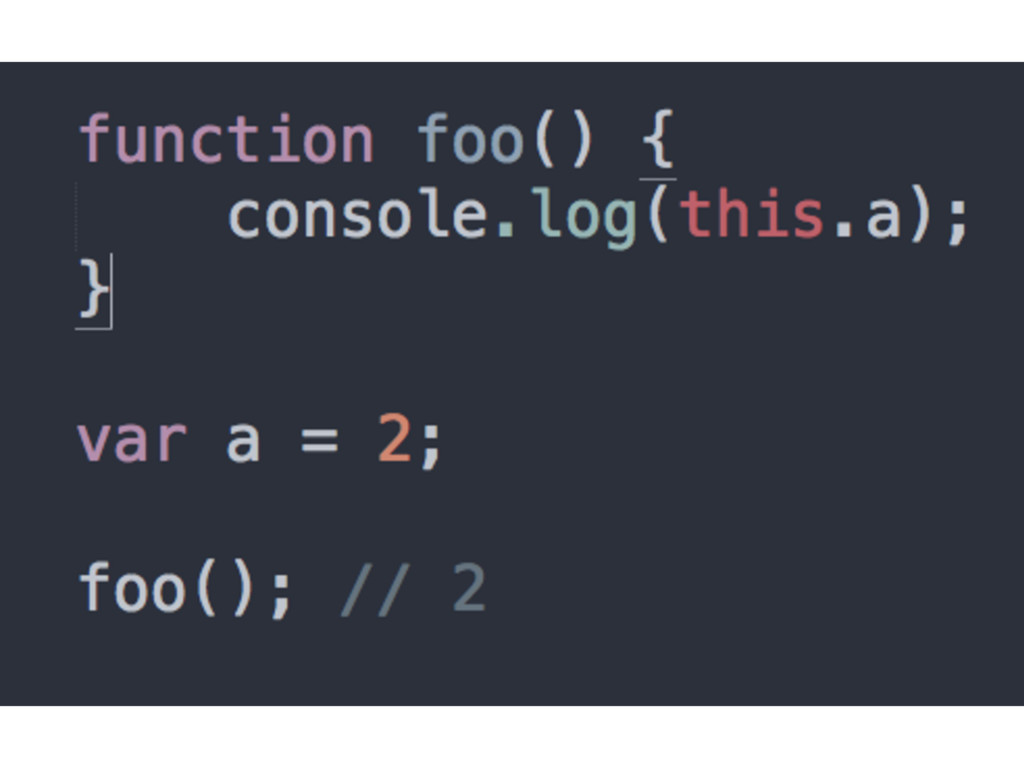
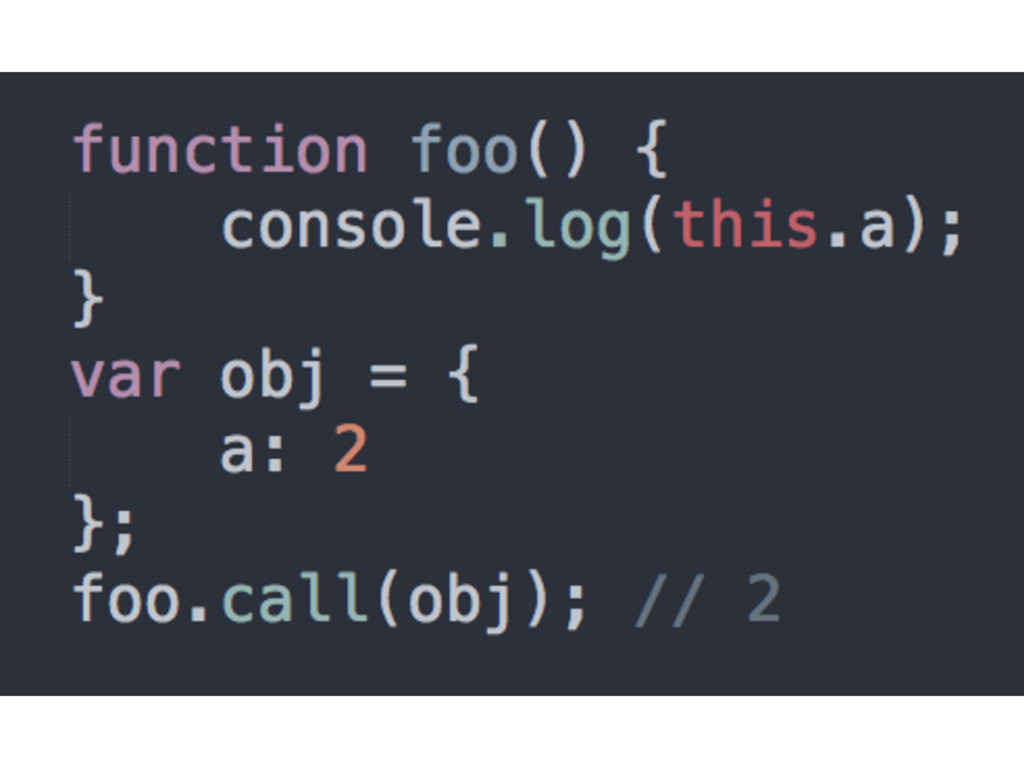
rules apply • The function is called with a plain, un-decorated function reference • this points to the global object in non-strict mode and to undefined in strict mode
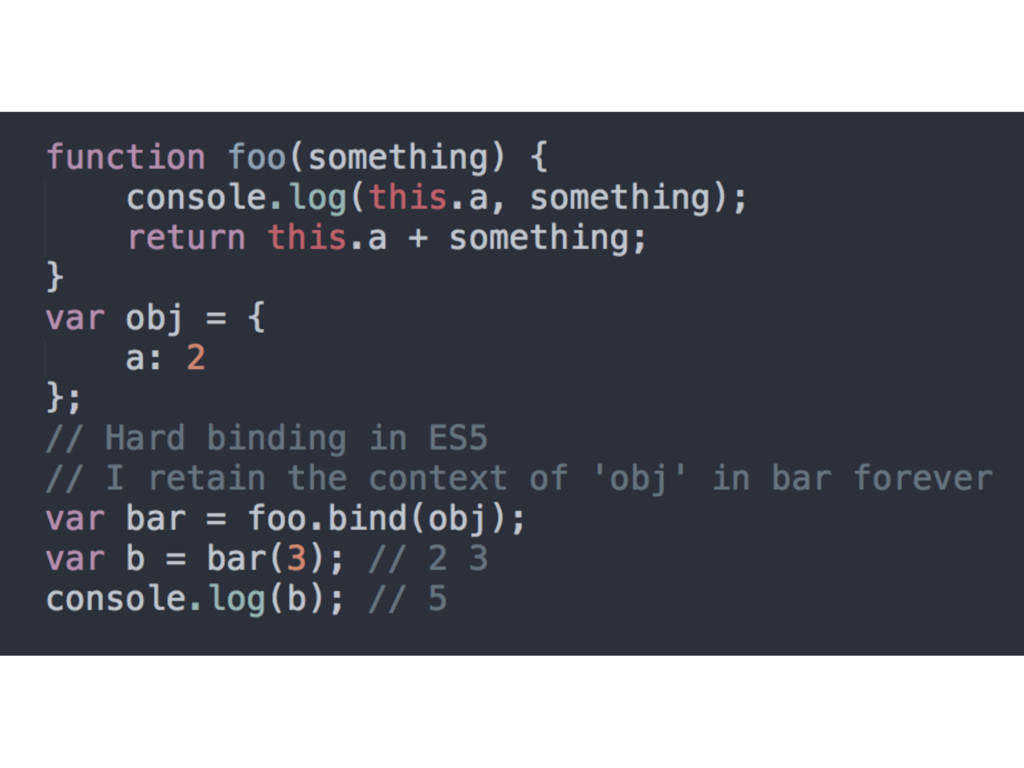
as the execution context for a function’s call-site • Done with the help of call() or apply() • The forced containing object will be what this will point to
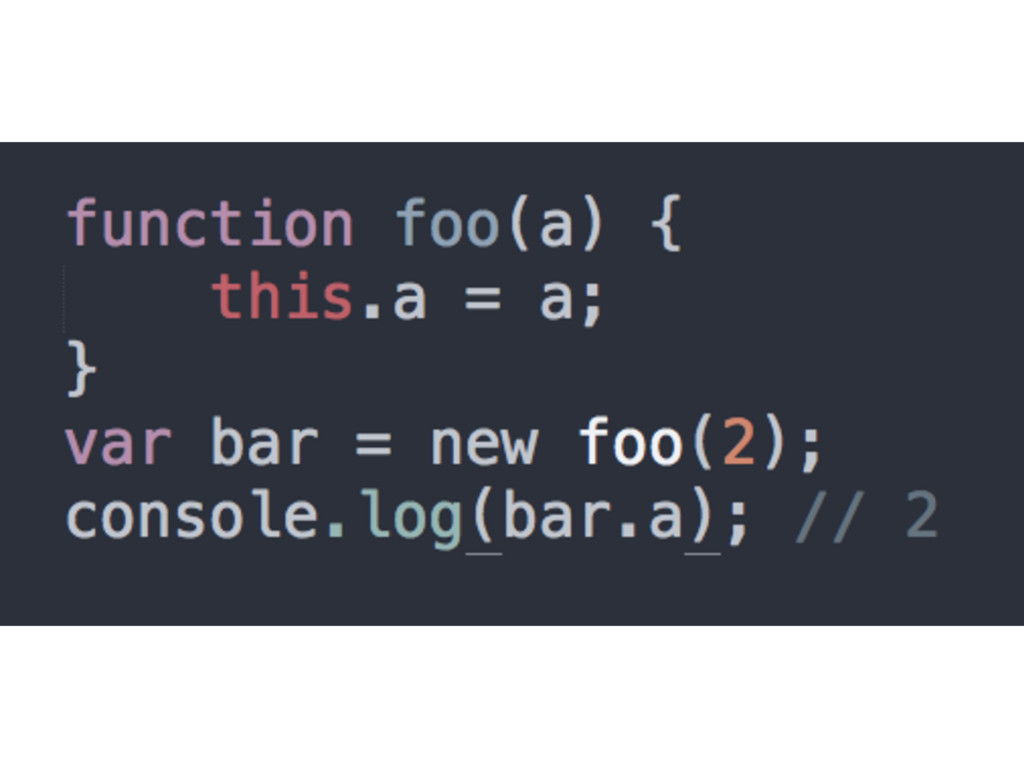
constructed) out of thin air • The newly constructed object is [[Prototype]]-linked • The newly constructed object is set as the this binding for that function call • Unless the function returns its own alternate object, the new-invoked function call will automatically return the newly constructed object
binding)? If so, this is the newly constructed object • Is the function called with call or apply (explicit binding), even hidden inside a bind hard binding? If so, this is the explicitly specified object • Is the function called with a context (implicit binding), otherwise known as an owning or containing object? If so, this is that context object • Otherwise, default the this (default binding). If in strict mode, pick undefined, otherwise pick the global object
and on what is it dependant? • How many types of binding we have to determine the value of this? • What is their order of precedence? • What happens when you create a “constructor function”?
inheritance, polymorphism, etc. • Because of the prototypal nature of JS and its strong relation to objects, these patterns don’t always map as expected • Frustrated developers
(the one that is the base for others - Iterator, Observer, Singleton, etc.) • There is procedural programming, functional programming, etc. • Some languages don’t give you any choice - Java • Some languages do - C/C++, PHP, etc. • Some languages behave their own way - Javascript
was never thought and designed for that • new, instanceof, class (ES6) • Internal mechanics function differently (and sometimes against your desire to “class-ify”) • You can choose between emulation classes and using JS built-in power
copy the “blueprint” to the instance (and work with the instance; the class is an abstraction) • Javascript's object mechanism does not automatically perform copy • We fake it - explicitly and implicitly
copied by reference - e.g.: arrays, functions, inner objects • The two separate objects can still affect each other, unlike traditional class-ready programming languages
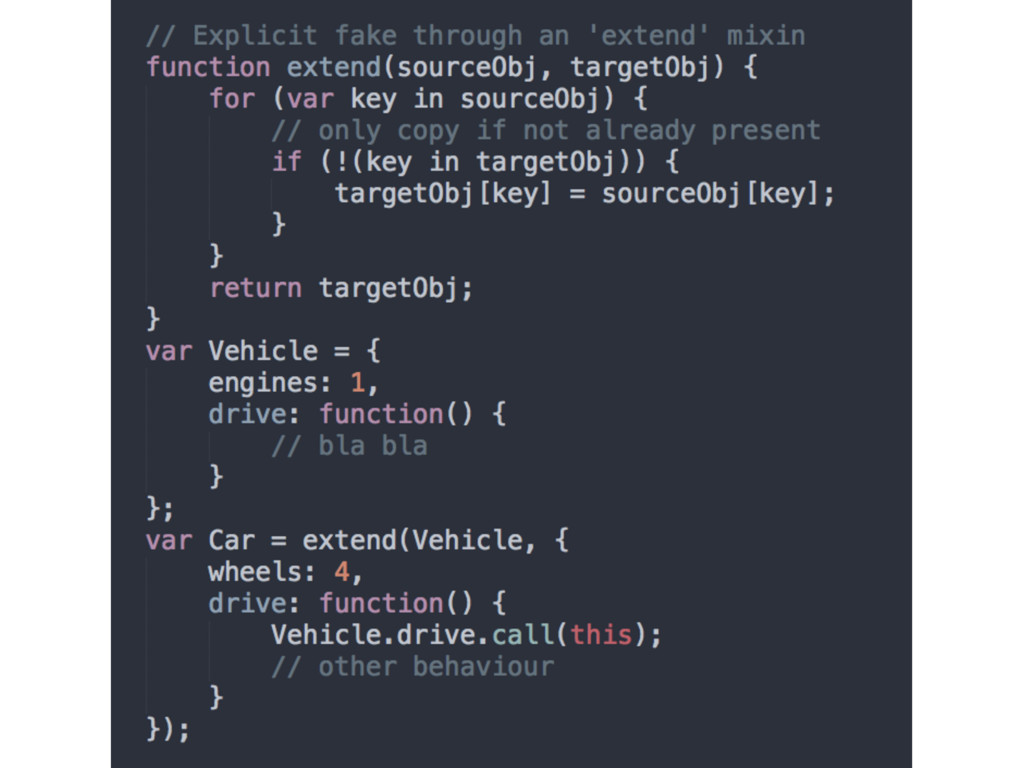
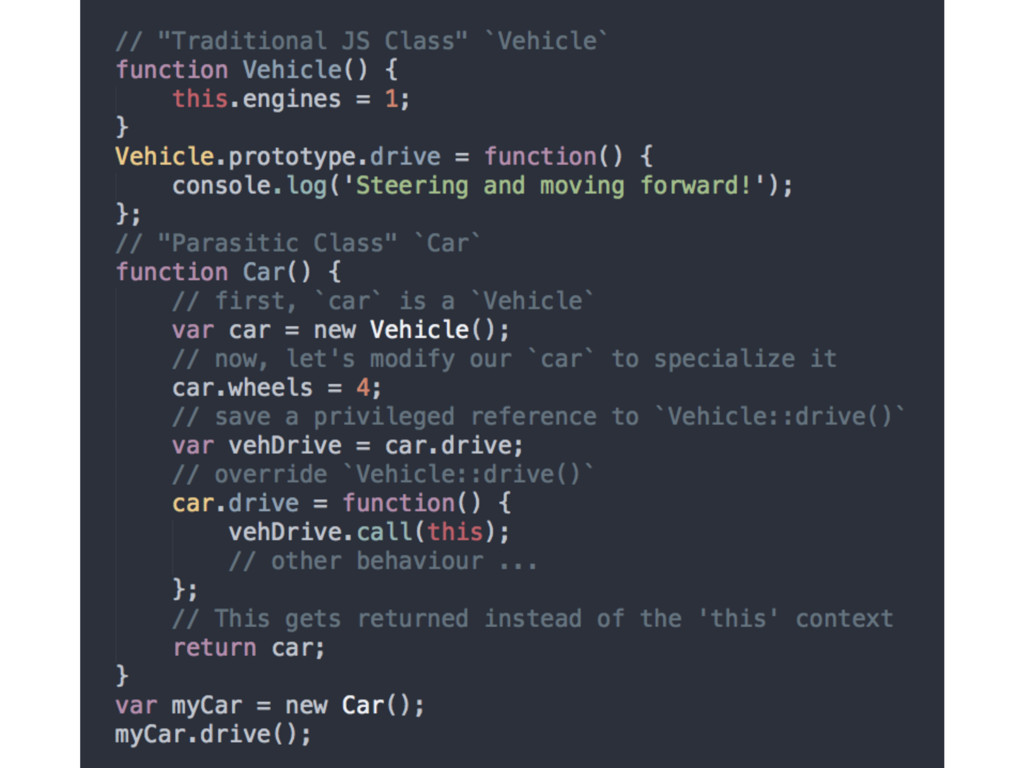
• Javascript does not automatically create copies (as classes imply) between objects • We emulate class-like behaviour through explicit or implicit methods • Faking classes in JS often sets more problems for future coding than solving issues (personal experience)
get their own, non-null prototype property at the time of their creation • [[Prototype]] is what JS looks for (with the [[Get]] method) if the property can’t be found on the object
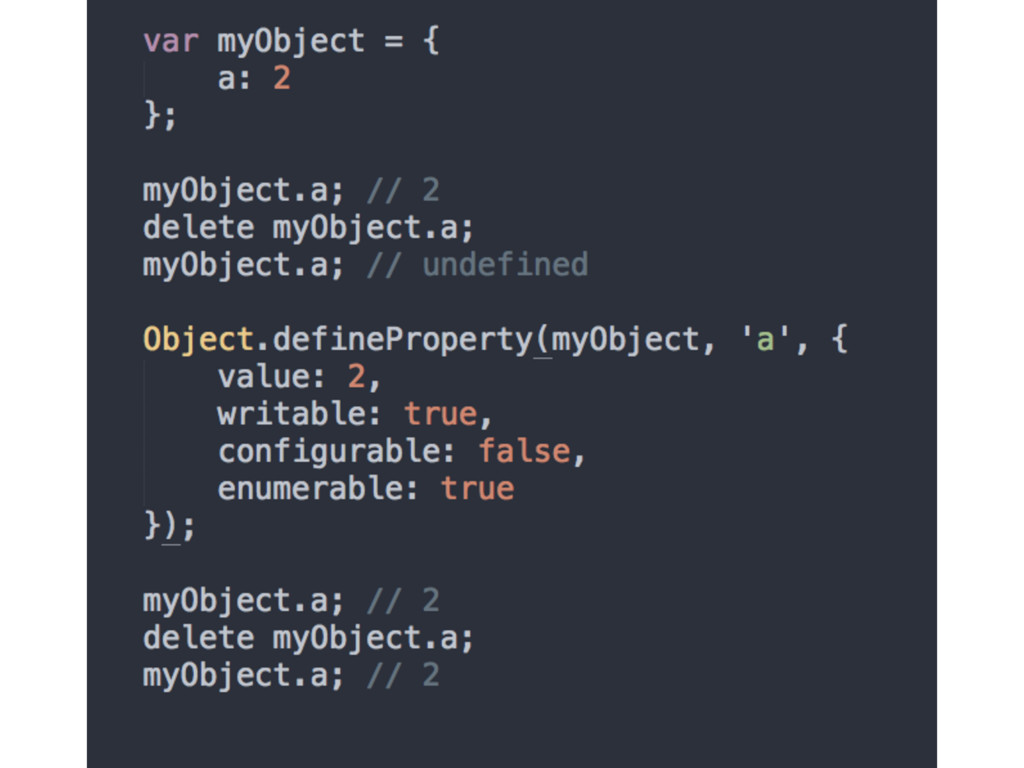
change the value of a property • Configurable: As long as a property is currently configurable, we can modify its descriptor definition, using defineProperty() • Enumerable: Controls if a property will show up in certain object-property enumerations, such as the for..in loop
Object.seal() creates a "sealed" object, which means it takes an existing object and prevents the addition of other properties on it • Freeze: creates a frozen object, which means it takes an existing object and essentially calls Object.seal() on it, but it also marks all "data accessor" properties as writable: false, so that their values cannot be changed.
• When setting a value, the [[Prototype]] chain might be examined - if value is found on the object, then it’s value is updated; if it’s not found on the object not it’s [[Prototype]] chain, the value is created on the object
is found anywhere higher on the [[Prototype]] chain, and it's not marked as read-only (writable: false) then a new property called foo is added directly to the object, resulting in a shadowed property
the [[Prototype]] chain, but it's marked as read-only (writable: false), then both the setting of that existing property as well as the creation of the shadowed property on the object are disallowed • If the code is running in strict mode, an error will be thrown. Otherwise, the setting of the property value will silently be ignored • No shadowing occurs
the [[Prototype]] chain and it's a setter, then the setter will always be called • No foo will be added to (aka, shadowed on) the object, nor will the setter be redefined
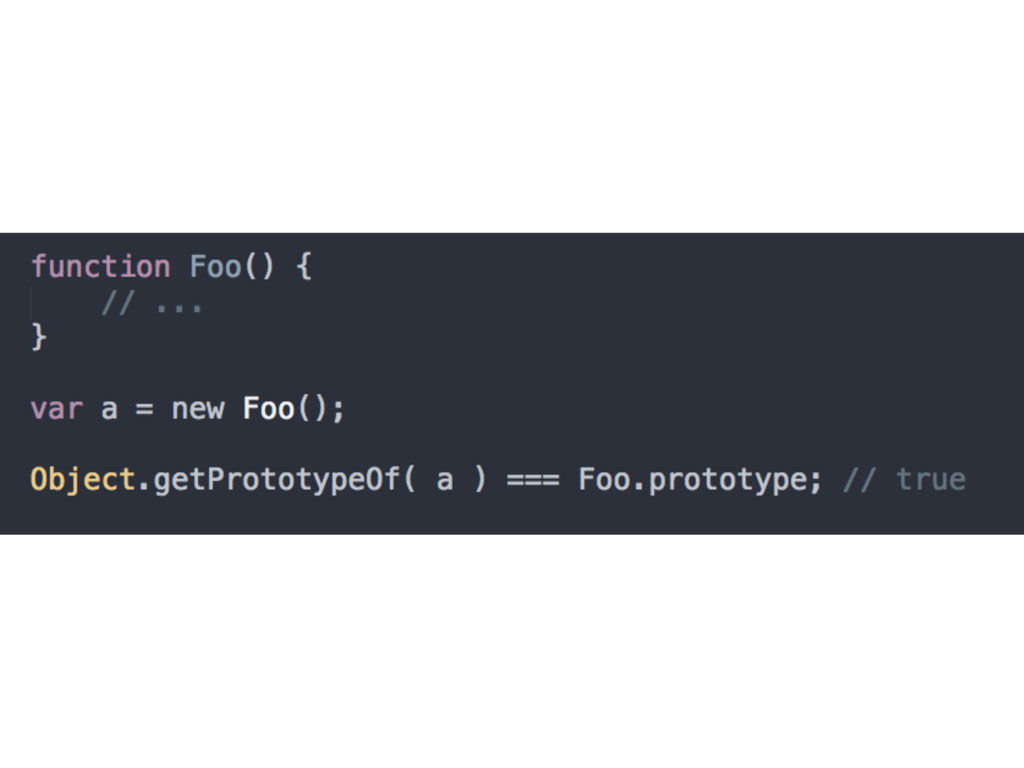
functions by default get a public, non- enumerable property on them called prototype, which points at an otherwise arbitrary object • Bug in JS: each object created from calling new Foo() will end up (somewhat arbitrarily) [[Prototype]]-linked to Foo.prototype
can be made • This happens because the process of instantiating (or inheriting from) a class means to copy the behaviour from that class into a new object, and this is done again for each new instance • But in JavaScript, there are no such copy-actions performed. We end up with two objects, linked to each other (which is also an accidental effect)
points back to Foo • When calling obj.constructor, it resolves the [[Prototype]] chain and points to Foo in the end (more confusion…) • If you manually set an object to Foo.prototype, you lose constructor
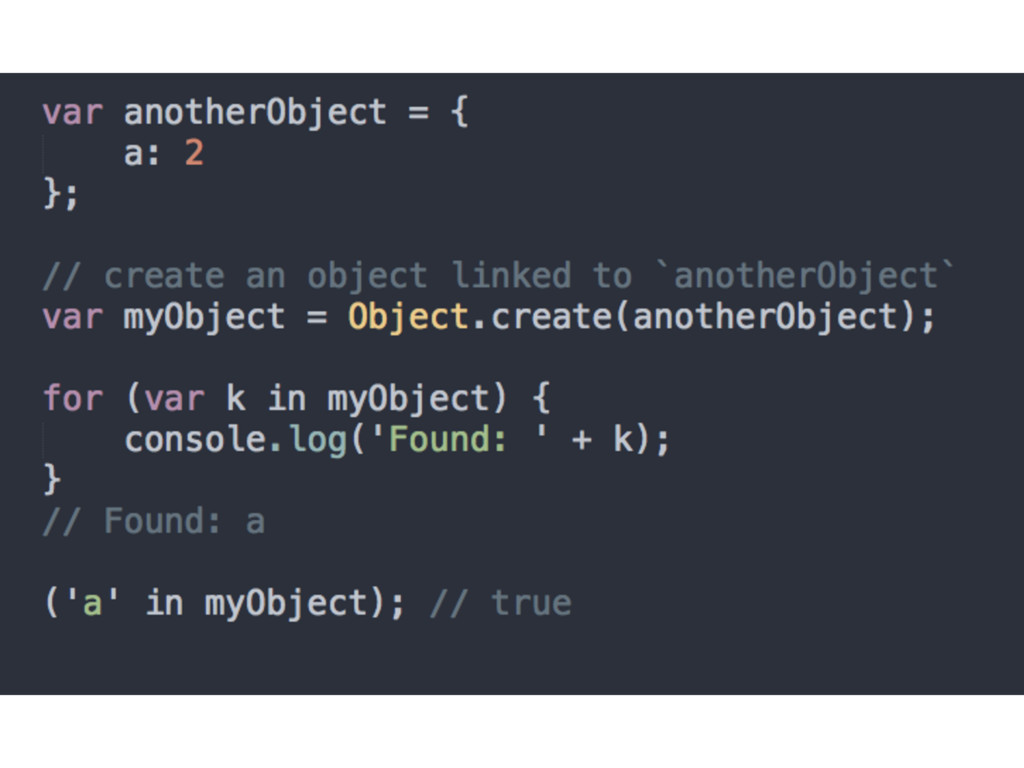
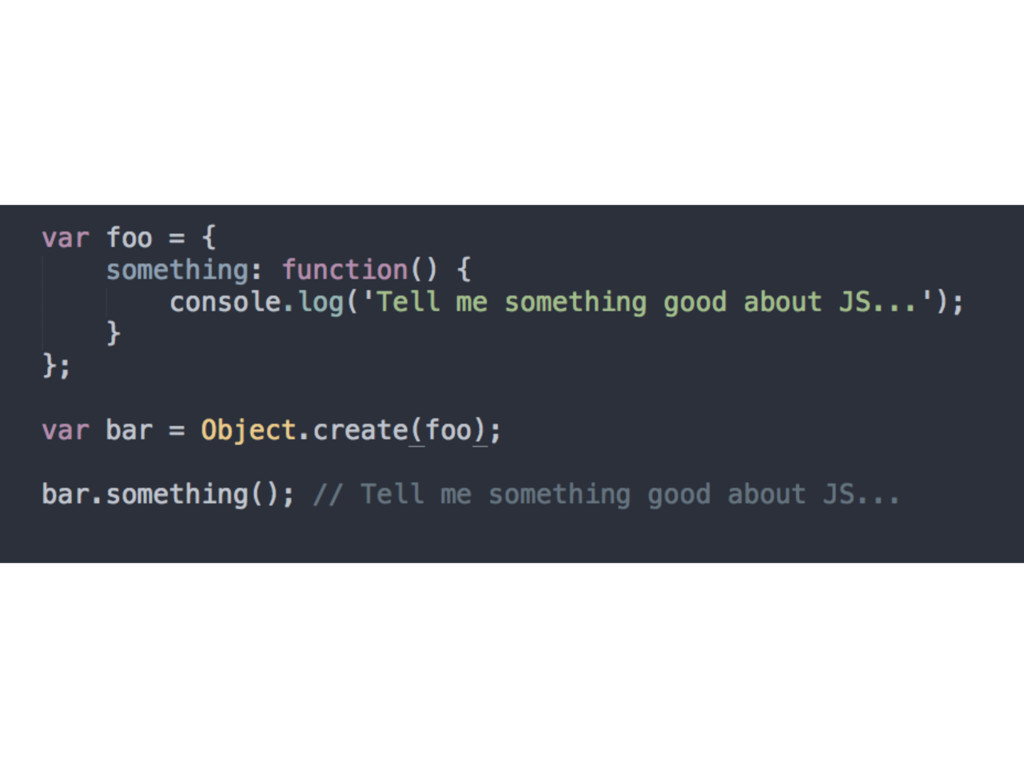
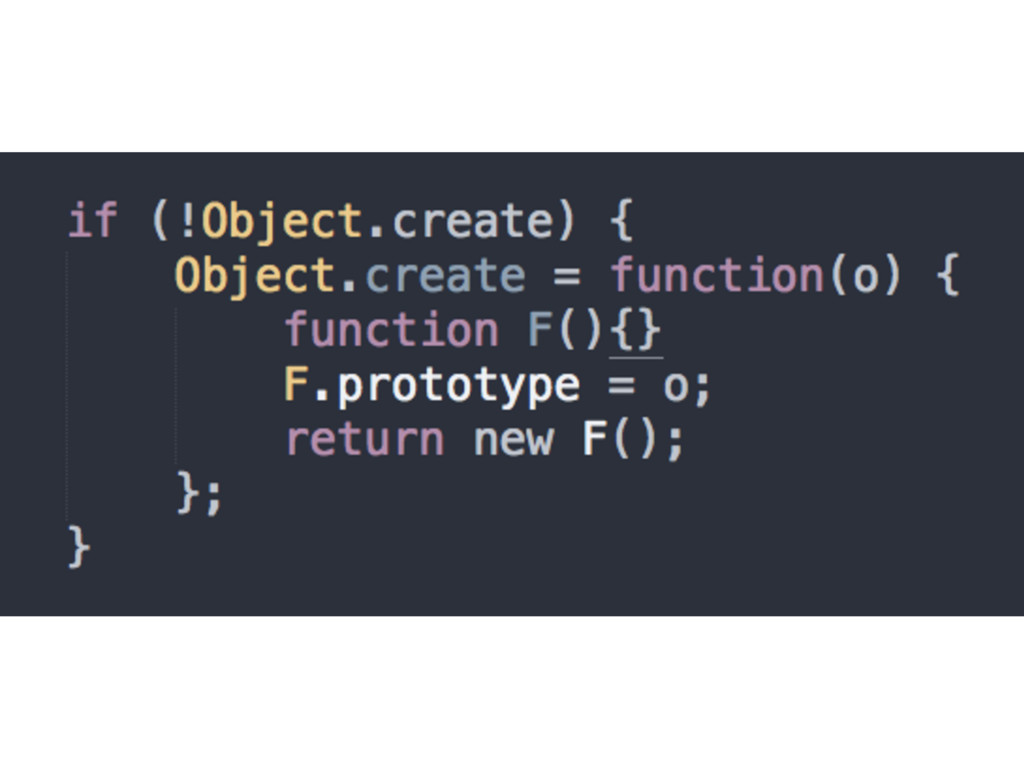
if we understand it • Based on Object.create() for the right modifications (creates an object out of thin air and sets the [[Prototype]] link to whatever you pass as an argument)
we specify, which gives us all the power (delegation) of the [[Prototype]] mechanism, but without any of the unnecessary complication of new functions acting as classes and constructor calls, confusing .prototype and .constructor references, or any of that extra stuff • Allows for instance vs. instance comparison • IE9+ in terms of browser support
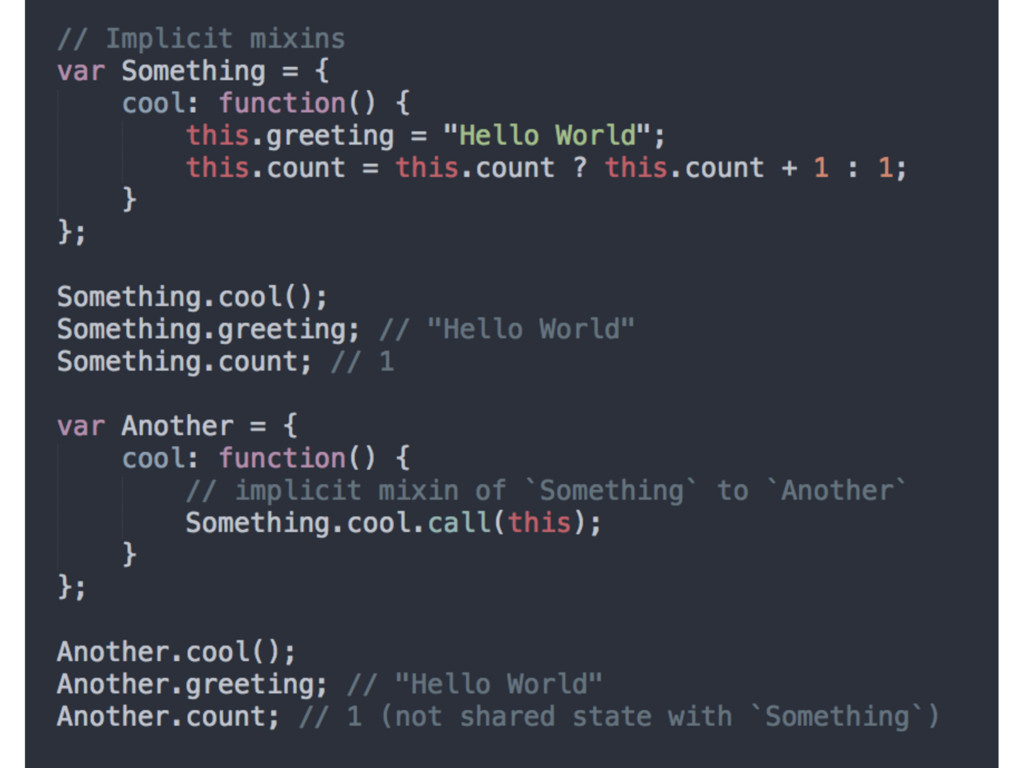
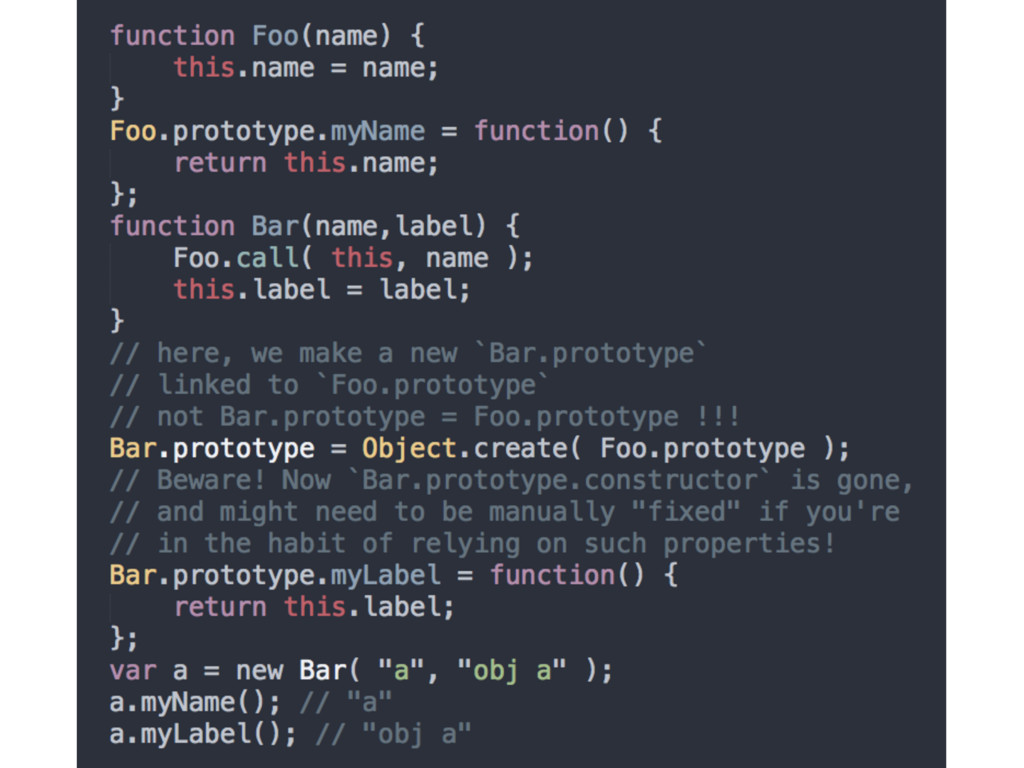
- it does not copy, it delegates! • [[Prototype]]-links are used in conjunction with .prototype which is an odd bug in JS • Shared instanced of .prototype (another object) can be an advantage if understood correctly • We can also copy objects, extend them, use parasitic inheritance or implicit mixing (remember call()?)
robust application's architecture and typically help in keeping the units of code for a project both cleanly separated and organized • You have several options of including modules inside your app: object literals, the module pattern, AMD modules, CommonJS modules, EMCAScript 6 modules, etc.
not scale very well and have the disadvantage of polluting the global scope • Everything in the object is accessible (no privacy) • Order is important (in case of multiple scripts)
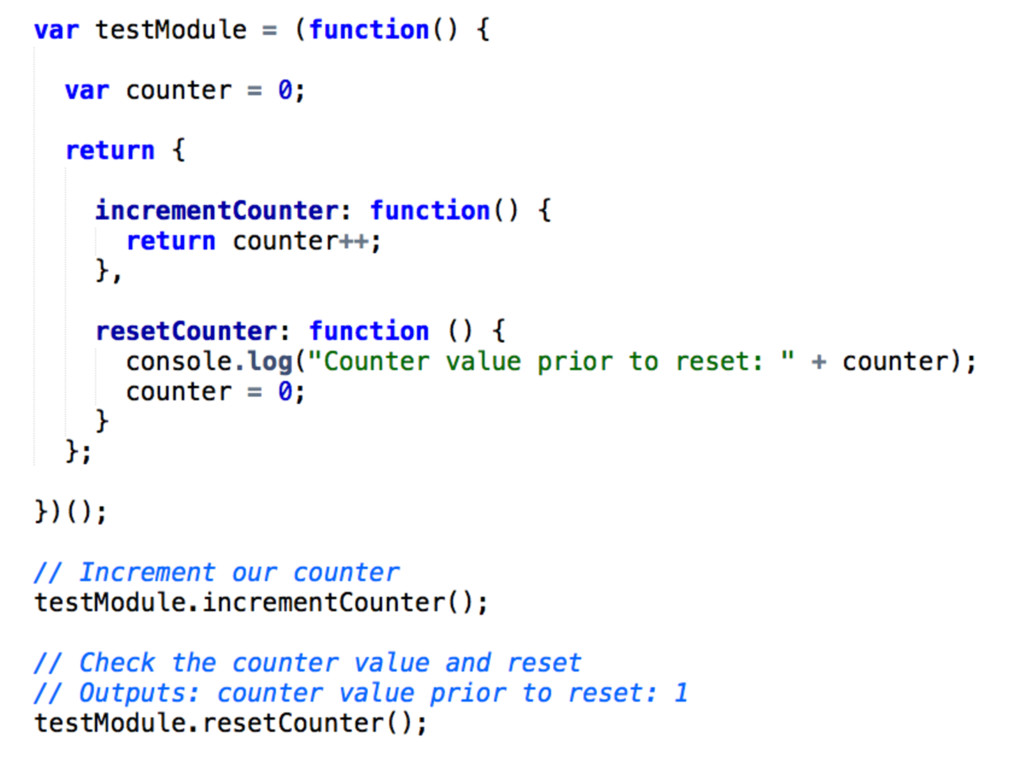
both private and public encapsulation • The Module pattern encapsulates "privacy", state and organization using closures • Only a public API is returned, keeping everything else within the closure private • Relies on IIFE
functions which can only be consumed by our module. As they aren't exposed to the rest of the page (only our exported API is), they're considered truly private • Given that functions are declared normally and are named, it can be easier to show call stacks in a debugger • Effective namespace under the “basketModule” module
object- oriented background than the idea of true encapsulation, at least from a JavaScript perspective • Supports private data - so, in the Module pattern, public parts of our code are able to touch the private parts, however the outside world is unable to touch the class's private parts (no laughing :D)
differently, when we wish to change visibility, we actually have to make changes to each place the member was used • Can't access private members in methods that are added to the object at a later point • Inability to create automated unit tests for private members
serve as a shared resource namespace which isolate implementation code from the global namespace so as to provide a single point of access for functions • Eg: Angular uses singletons A LOT (for the services)
when exactly one object is needed to coordinate others across a system (eg: utility class with helper functions, a MessageManagement “class” to deal with the messages flow in an app, etc.) • Using too many Singletons is bad • They're often an indication that modules in a system are either tightly coupled or that logic is overly spread across multiple parts of a codebase
a list of objects depending on it (observers), automatically notifying them of any changes to state • When a subject needs to notify observers about something, it broadcasts a notification to the observers (which can include specific data related to the topic of the notification) • When we no longer wish for a particular observer to be notified of changes by the subject they are registered with, the subject can remove them from the list of observers
wishing to receive topic notifications must subscribe this interest to the object firing the event (the subject) • Pub/Sub pattern uses a topic/event channel which sits between the objects wishing to receive notifications (subscribers) and the object firing the event (the publisher) • This event system allows code to define application specific events which can pass custom arguments containing values needed by the subscriber • The idea here is to avoid dependencies between the subscriber and publisher
relationships between different parts of our application. • They also help us identify what layers containing direct relationships which could instead be replaced with sets of subjects and observers • Use where you need to maintain consistency between related objects without making “classes” tightly coupled • Event-based communication & dynamic relations = flexibility
sometimes become difficult to obtain guarantees that particular parts of our applications are functioning as we may expect • If the subscriber crashes (or for some reason fails to function), the publisher won't have a way of seeing this due to the decoupled nature of the system • Subscribers are quite ignorant to the existence of each other and are blind to the cost of switching publishers
of abstraction over a chosen implementation • Aims to simplify the API being presented to other developers, something which almost always improves usability • jQuery for example uses Facades A LOT (for everything from DOM manipulation to AJAX, etc.)
• Normalized API, fixing cross-browser quirks under the hood, consistency • Need to change only the implementation, not the API (the implementation resides in one place) • Always try to determine the performance impact (Facades almost always have slower execution times because of the thin layer on top)
Definition • Born out of Dojo roots (XHR + eval on the fly) • Both the module and dependencies can be asynchronously loaded • Highly flexible, reduces coupling, asynchronous
approach defining flexible modules • Clean way to declare stand-alone modules and dependencies • Module definitions are encapsulated • Doesn't have issues with cross-domain, local or debugging and doesn't have a reliance on server-side tools • It's possible to lazy load scripts if this is needed
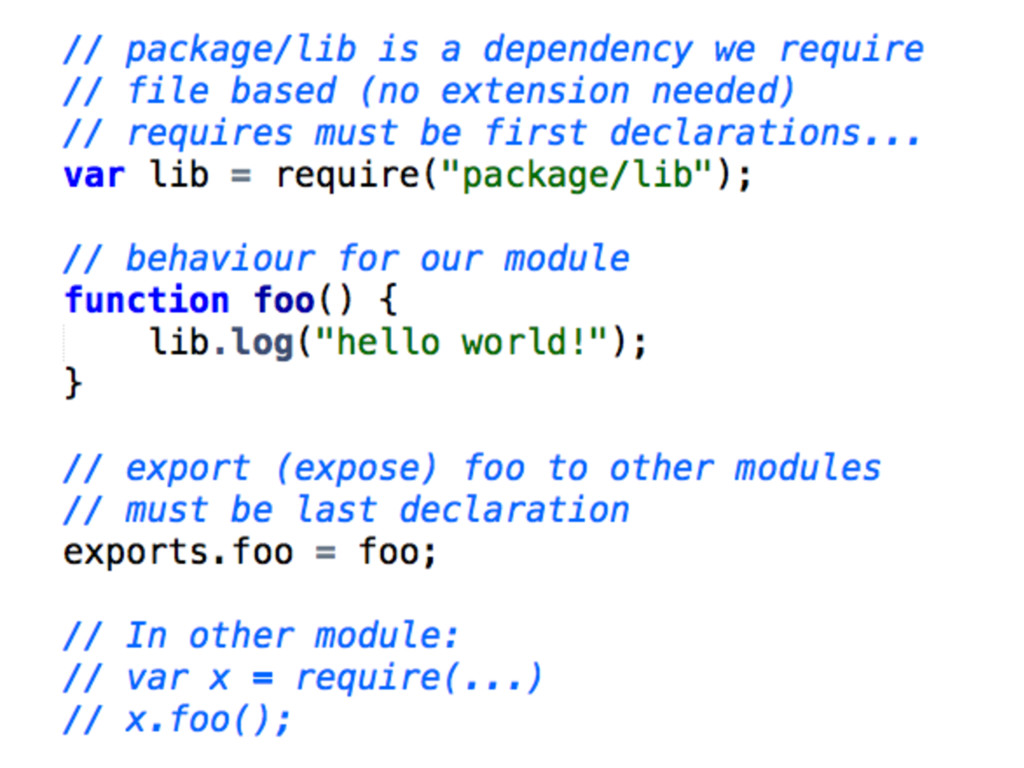
modules server-side • Unlike AMD attempts to cover a broader set of concerns such as I/O, file-system, promises, etc. • Available on the client-side also through tools like Browserify • A reusable piece of JavaScript which exports specific objects made available to any dependent code
is better suited to server-side development • CommonJS modules are only able to define objects which can be tedious to work with if we're trying to obtain constructors out of them (AMD lets you specify dependencies, import plugins,etc.) • Tools like Browserify DO NOT represent async module loaders
asynchronous behaviour, supports objects, functions, constructors, strings, JSON and many other types of modules, running natively in the browser + flexibility • CommonJS - server-first approach s(File, I/O), assuming synchronous behaviour, supports unwrapped modules so it can feel a little more close to the ES6 specifications (no define() ) but support only objects as modules
export • import - declarations bind a modules exports as local variables and may be renamed • export - declare that a local-binding of a module is externally visible such that other modules may read the exports but can't modify them (also can’t export other modules defined elsewhere)
in order to have the best of both worlds (AMD + CommonJS) • At present, our best options for using Harmony syntax in today's browsers is through a transpiler such as Google Traceur or Esprima
context • Performance advice is addictive, and sometimes focusing on deep advice first can be quite distracting from the real issues • You need to take a holistic view of the performance of your web application - before focusing on these performance tip, you should probably analyze your code with tools like PageSpeed and get your score up • This will help you avoid premature optimization
and generates native machine code before it is executed, rather than executing bytecode or simply interpreting it. This code is initially not highly optimized • Objects in V8 are represented with hidden classes, which are an internal type system for optimized lookups
run and identifies “hot” functions, objects (code that ends up spending a long time running) • An optimizing compiler recompiles and optimizes the “hot” code identified by the runtime profiler, and performs optimizations such as inlining (replacing a function call site with the body of the callee - JIT-ed code)
compiler can bail out of code generated if it discovers that some of the assumptions it made about the optimized code were too optimistic • And garbage collector of course. Understanding how it works can be just as important as the optimized JavaScript
code, and starts executing code as soon as possible, quickly generating good but not great code • This compiler assumes almost nothing about types at compilation time - it expects that types of variables can and will change at runtime • The code generated uses Inline Caches (ICs) to refine knowledge about types while program runs, improving efficiency on the fly
V8 re-compiles "hot" functions (functions that are run many times) with an optimizing compiler • Uses type feedback to make the compiled code faster (taken from ICs) • In the optimizing compiler, operations get speculatively inlined (directly placed where they are called). This speeds execution (at the cost of memory footprint), but also enables other optimizations
lot more harm than good behind the scenes, as it changes o‘s hidden class and makes it a generic slow object • Avoid using delete whatsoever • Use variables and functions with appropriate scope (so they get GC when they’re supposed to)
after the function finished executed • This mean the variables inside don’t get GC • Try to limit the data that you retain a reference to (don’t return a kilometre of string…)
what number type you are dealing with. • After that, it uses tagging to represent values efficiently, because these types can change dynamically. • There is sometimes a cost to changing these type tags, so it's best to use number types consistently (optimal to use 31-bit signed integers where appropriate)
Arrays • Don't pre-allocate large Arrays (e.g. > 64K elements) to their maximum size, instead grow as you go • Don't delete elements in arrays, especially numeric arrays (will slow the process and lose optimizations)
arrays • Preallocate small arrays (<64k elements) to correct size before using them • Don't store non-numeric values (objects) in numeric arrays • Be careful not to cause re-conversion of small arrays if you do initialize without literals
indivisible unit • It’s a good practice to separate your code into multiple functions and work with parameters • Helps with inlining in JIT-ed code, which results in speed • Favor composition of functions and respect SRP (Single Responsibility Principle)
of data containing items with a numeric ID then… • Draws a table containing this data, then… • Adds event handlers for toggling a class when a user clicks on any cell
of optimisations • Eg: a try-catch block cannot be optimized • The engine doesn’t know the outcome and cannot inline functions or make optimization assumptions
sure that variables only ever contain objects with the same type) • Don’t load from uninitialized or deleted elements (this won’t make a difference in output, but it will make things slower) • Don’t write enormous functions, as they are more difficult to optimize (a rule of max 30-35 loc) • Don’t do stuff like eval or with
bunch of numbers, or a list of objects of the same type, use an array • If what you semantically need is an object with a bunch of properties (of varying types), use an object with properties • Integer-indexed elements, regardless of whether they’re stored in an array or an object, are much faster to iterate over than object properties • At an engine level, Arrays are better optimised (especially when the array contains numbers) because properties on objects are quite complex and customisable
code are not in sync • DOM GC and JavaScript GC have no connection with each other • The most common memory leaks for web applications involve circular references between the JavaScript engine and the browsers' objects implementing the DOM
Chrome's JavaScript runtime for easily building fast, scalable network applications • Uses an event-driven, non-blocking I/O model that makes it lightweight and efficient, perfect for data- intensive real-time applications • Opens the world of npm
you to quickly search & install packages from the open-source community, including dependencies • package.json file • http://nodejs.org/download/ • https://www.npmjs.org/
care of hunting, finding, downloading, and saving the stuff you’re looking for • Optimized for the front-end. Bower uses a flat dependency tree, requiring only one version for each package, reducing page load to a minimum • bower.json file • http://bower.io/
packages are available only on nom, some only for Bower, but most of them are available for both… • npm started on the server with Node packages, and does heavy dependency • Bower is optimized for frontend (you will install frameworks like Angular, jQuery, etc. with it)
you kickstart new projects, prescribing best practices and tools to help you stay productive • Relies on a generators ecosystem (BB, Ember, Angular, HTML5 app, etc.) • http://yeoman.io/
to automate your workflow (minification, compilation, unit testing, linting, etc.) • Favors configuration over code convention - Gruntfile.js • http://gruntjs.com/
the block” • Gulp - plugin ecosystem smaller, but it’s growing very fast (almost all you would need to automate in the frontend process is available already) • Gulp is faster - uses streams in Node and does I/O operations only at the end (as opposed to Grunt, which does them after each task)
for in-browser use • Fully allows you to embrace the idea of AMD in your code • Great browser support (all the way back to IE6) • http://requirejs.org/
bundling up all of your dependencies • Helps you out with the CommonJS syntax • Has packages for both Grunt and Gulp so you can include the browserify task in your build process • http://browserify.org/
frameworks to chose from • Some only concentrate on a part of the application (model, view) whereas some aim to be a full solution (Angular, Ember) • The choice depends on your project’s particularities and needs
jQuery UI and gone (personal opinion btw…) • Use vanilla JavaScript when possible (DOM manipulation, AJAX support, etc are here now) • Use frameworks like Twitter Bootstrap or Foundation (which include components with JS behaviour already implemented)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[[Prototype]] • Just a reference to another object • Objects](https://files.speakerdeck.com/presentations/61b29ed672a840b2bf8e8656b30c4bf0/slide_114.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
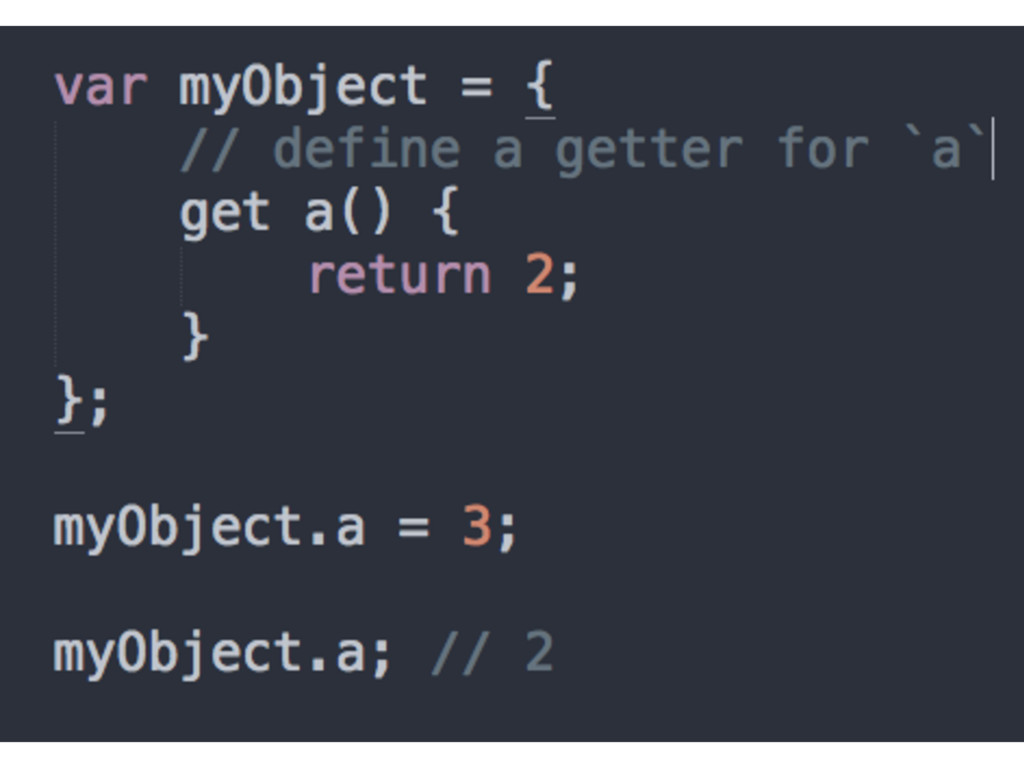
![Getters and setters • Can override the behaviour of [[Get]]](https://files.speakerdeck.com/presentations/61b29ed672a840b2bf8e8656b30c4bf0/slide_119.jpg){kind=link}
{kind=link}
![[[Prototype]] • The chain is examined until Object is reached](https://files.speakerdeck.com/presentations/61b29ed672a840b2bf8e8656b30c4bf0/slide_121.jpg){kind=link}
![What happens when we have the value on the [[Prototype]]](https://files.speakerdeck.com/presentations/61b29ed672a840b2bf8e8656b30c4bf0/slide_122.jpg){kind=link}
![[[Prototype]] • If a normal data accessor property named foo](https://files.speakerdeck.com/presentations/61b29ed672a840b2bf8e8656b30c4bf0/slide_123.jpg){kind=link}
![[[Prototype]] • If a foo property is found higher on](https://files.speakerdeck.com/presentations/61b29ed672a840b2bf8e8656b30c4bf0/slide_124.jpg){kind=link}
![[[Prototype]] • If a foo property is found higher on](https://files.speakerdeck.com/presentations/61b29ed672a840b2bf8e8656b30c4bf0/slide_125.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Quiz time • What is the [[Prototype]] chain? • What](https://files.speakerdeck.com/presentations/61b29ed672a840b2bf8e8656b30c4bf0/slide_138.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}