de sortare • Paralelizarea algoritmilor • Obținerea de rezultate experimentale ale algoritmilor paraleli • Construirea de algoritmi paraleli hibrizi • Obținerea de rezultate experimentale ale algoritmilor hibrizi
de a construi și rula astfel de algoritmi pe arhitecturi paralele • Dorința de a construi algoritmi de sortare hibrizi și de a descoperi dacă aceștia oferă sporuri de performanță • Metoda de cercetare - predominant experimental
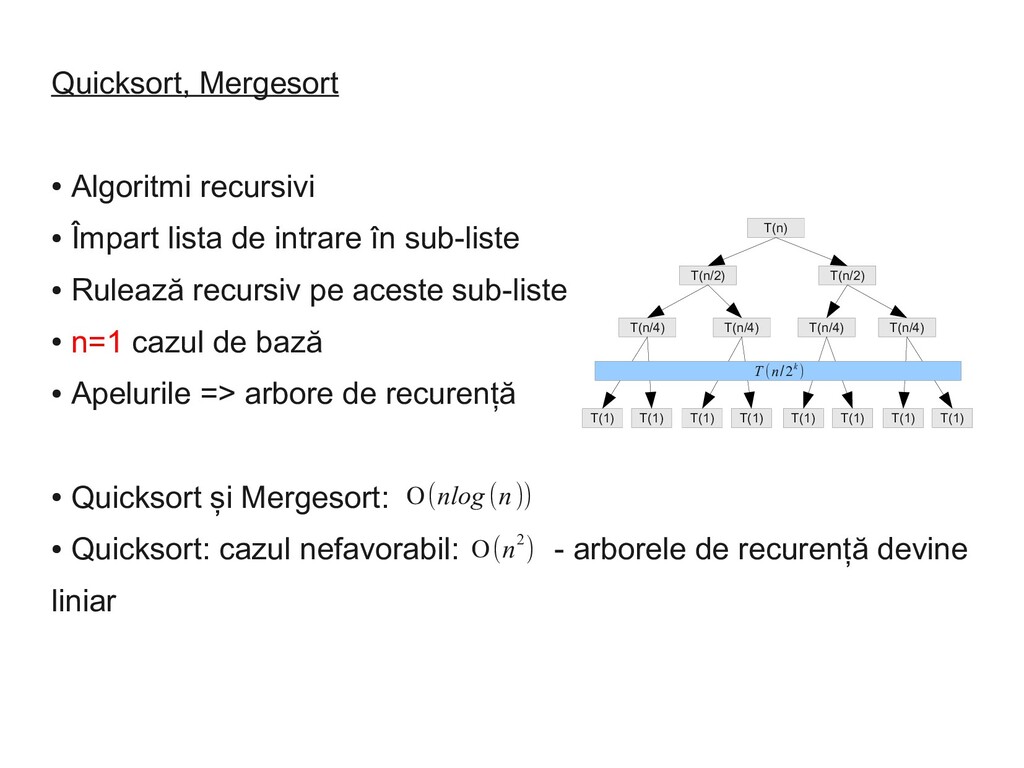
în sub-liste • Rulează recursiv pe aceste sub-liste • n=1 cazul de bază • Apelurile => arbore de recurență • Quicksort și Mergesort: • Quicksort: cazul nefavorabil: - arborele de recurență devine liniar T(n) T(n/2) T(n/2) T(n/4) T(n/4) T(n/4) T(n/4) T(1) T(1) T(1) T(1) T(1) T(1) T(1) T(1) T (n/2k ) Ο(nlog (n)) Ο(n2)
paralelizați cel mai ușor • Firele de execuție nu trebuie să se sincronizeze • Nu facem paralelizarea în funcție de nr. de procesoare • Paralelizare în funcție de nivelul de recurență • La fiecare nivel de recurență putem lansa procese separate • Arborele de procese se va suprapune arborelui de recurență al algoritmului Ο( n p log( n p ))
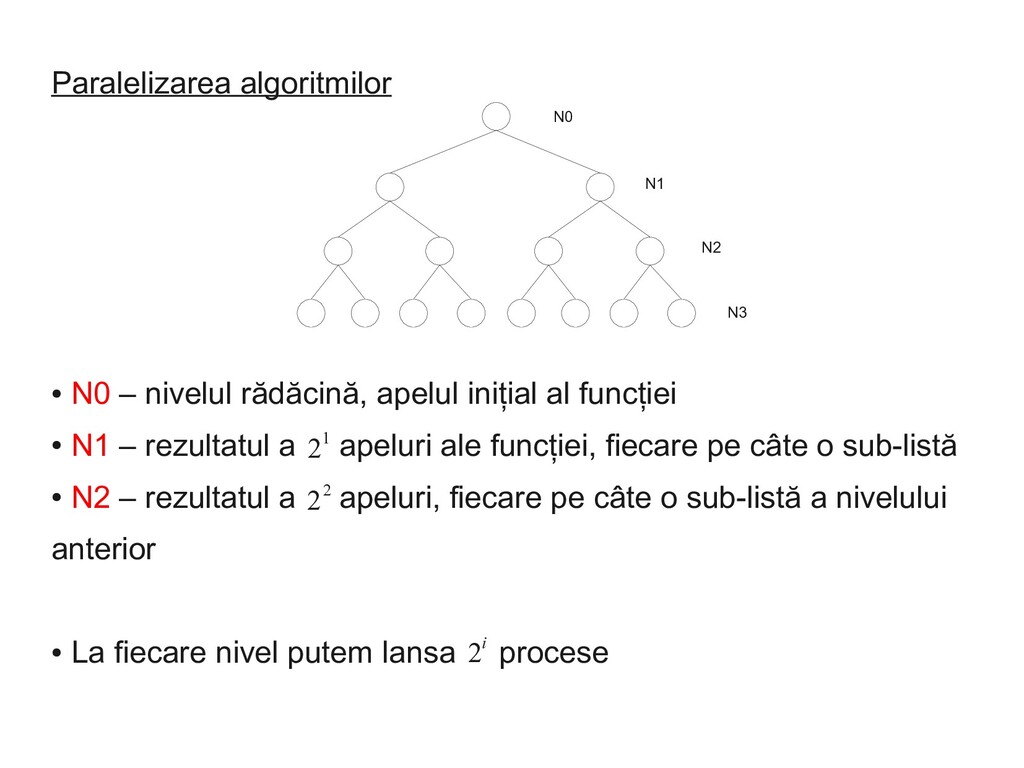
funcției • N1 – rezultatul a apeluri ale funcției, fiecare pe câte o sub-listă • N2 – rezultatul a apeluri, fiecare pe câte o sub-listă a nivelului anterior • La fiecare nivel putem lansa procese N0 N1 N2 N3 21 2i 22
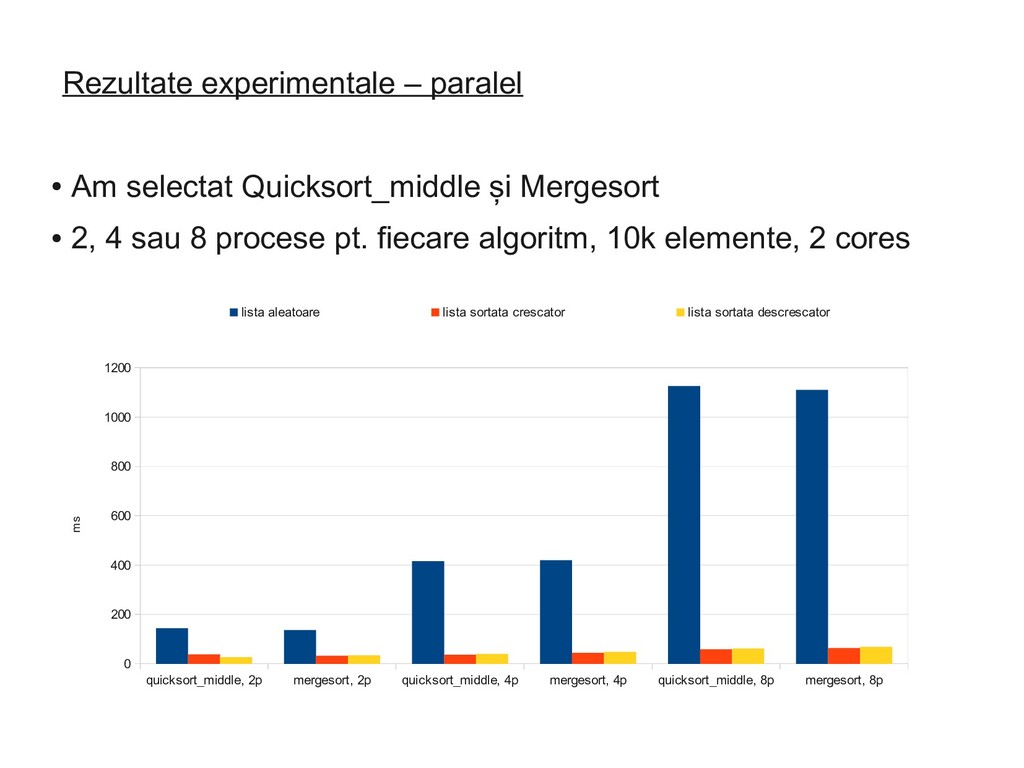
respectiv 1, 2, 4 și 8 procese • După ce acest nivel e depășit, algoritmul la rula în mod secvențial mai departe • Între procese separate - comunicare (IPC) printr-un obiect de tip coadă • Obiectul coadă e accesibil de către procesul părinte și cei doi copii ai săi (local) • Între apeluri de funcție obișnuite - return
sortată crescător, listă sortată descrescător • Fiecare algoritm a fost rulat de 10 ori pe fiecare listă de intrare • Fiecare algoritm a fost rulat pe liste de 10.000 (10k), 100.000 (100k), 1.000.000 (1M) și 5.000.000 (5M) de elemente, nr nat. • Rulați: • în mod secvențial, pe 1 core • în mod paralel 2 cores și 6 cores • Comparați pentru corectitudine cu implementarea standard Python (Timsort)
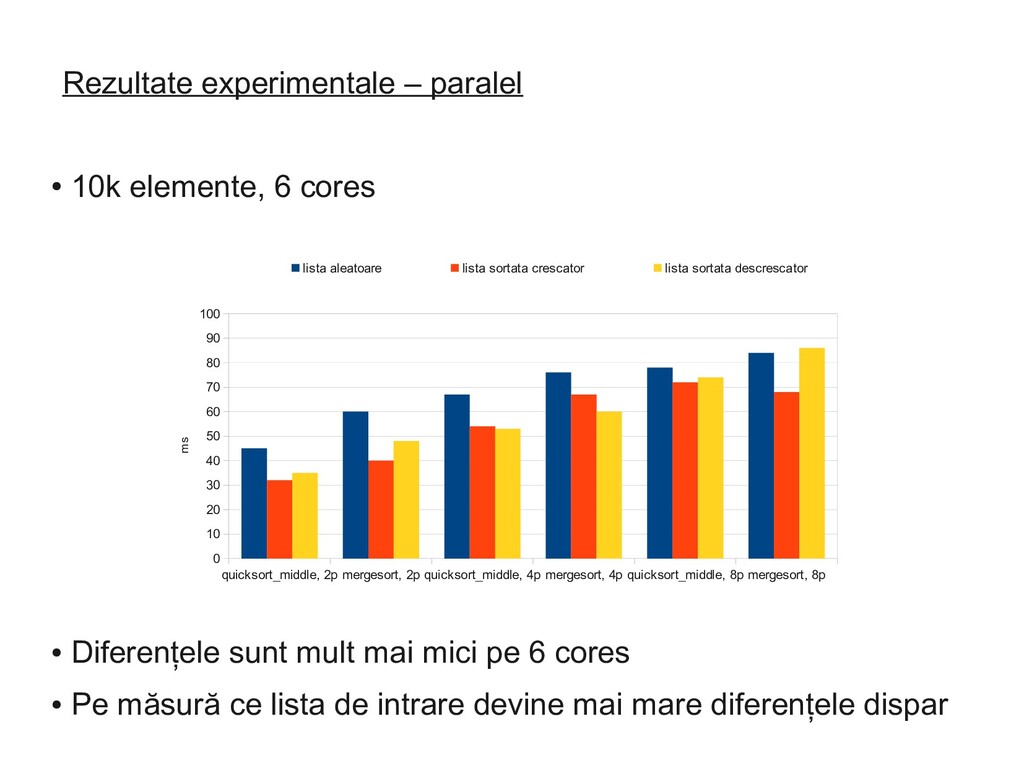
Diferențele sunt mult mai mici pe 6 cores • Pe măsură ce lista de intrare devine mai mare diferențele dispar quicksort_middle, 2p mergesort, 2p quicksort_middle, 4p mergesort, 4p quicksort_middle, 8p mergesort, 8p 0 10 20 30 40 50 60 70 80 90 100 lista aleatoare lista sortata crescator lista sortata descrescator ms
de tip divide et impera • unul secvențial • Odată ce algoritmul principal trece de un anumit nivel va avea performanțe slabe - overhead • De la un anumit nivel vom trece la un algoritm secvențial • Cel secvențial va avea performanțe mai bune pe liste mici
bune pe liste de 1000 el. • După 4000 elemente, performanțele sale se degradează quicksort_middle mergesort heapsort selection 0 1 2 3 4 5 6 7 8 9 lista aleatoare ms
nivelul 1, 2 sau 3 vom lansa procese separate (2, 4 respectiv 8) • până la nivelul 12 vom rula algoritmul secvențial • de la nivelul 12 vom rula sub-algoritmul pe liste mici • dacă lista de intrare e mai mică de 4096, sub-algoritmul nu va intra în funcțiune => algoritm adaptiv
Selection • Mergesort cu Heap și Selection • 1M elemente, 2p quicksort mergesort quicksort P mergesort P quick_selection H quick_heap H merge_selection H merge_heap H 0 2000 4000 6000 8000 10000 12000 14000 16000 secvential 2 cores 6 cores ms
- și mai rapid după hibridizare • Mergesort cu selection sort - cel mai rapid: • de 1.90 ori mai rapid decât mergesort secvențial în medie, (2.14 max) • de 1.10 ori mai rapid decât mergesort paralel simplu în medie, (1.22 max) • Varianta cu 4 procese - performanțe constante atât pe 2 cores cât și pe 6 cores, varianta cu 2 procese dispusă la fluctuații
paralel hibrid adaptiv • Odată ce avem acest algoritm putem să-l implementăm pe arhitecturi cum este CUDA: • programe generale rulate pe GPU • procesoare puternic paralele • un nr. mare de cores (480) • mai rapid decât CPU pt asemenea task-uri
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}