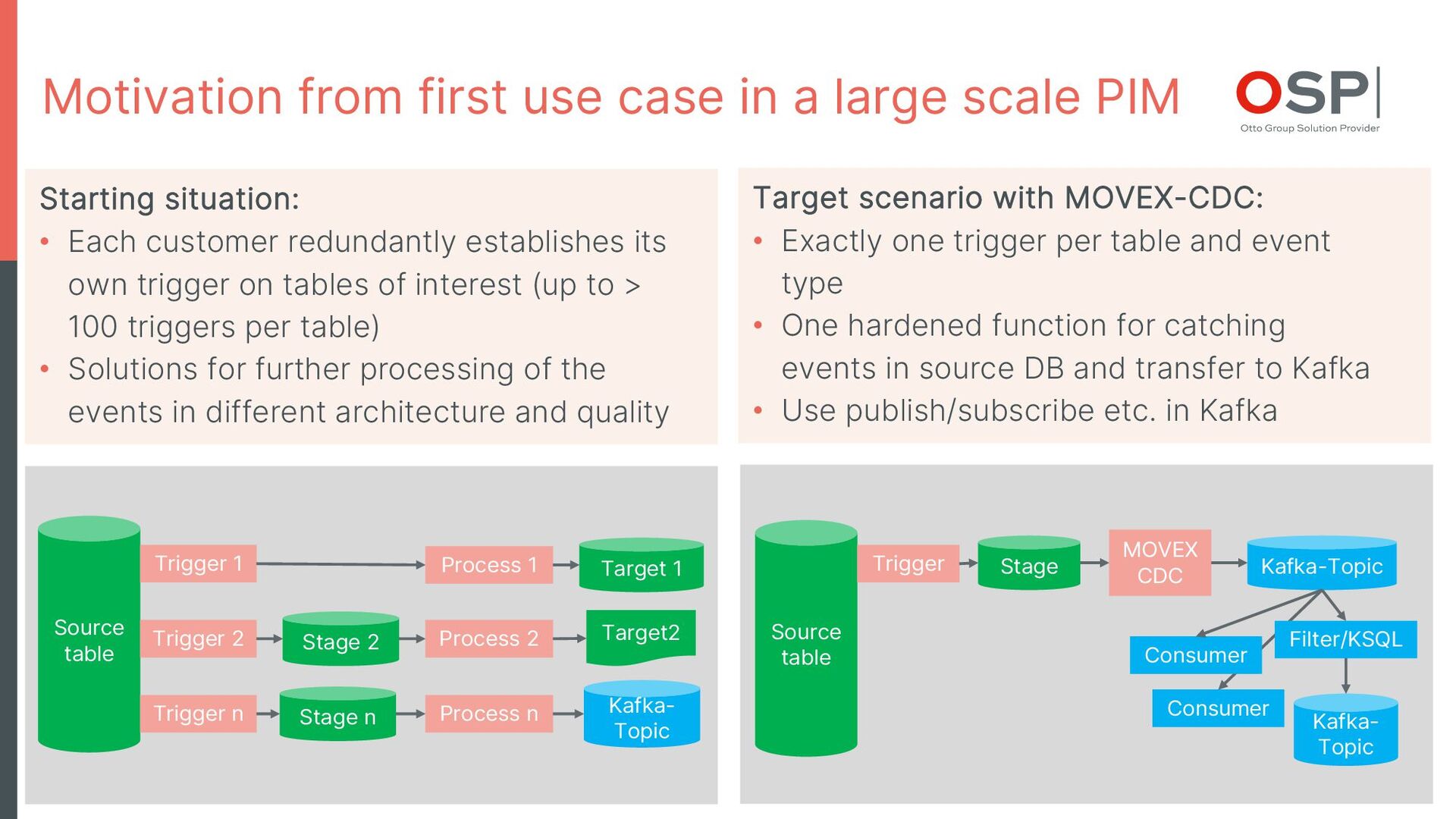
Various solutions exist for change data capture from Oracle DB to Kafka, which generally require intervention in the operational management of the Oracle DB.
Thus, hurdles exist e.g. in migration scenarios of legacy applications or in managed cloud DB without the possibility to intervene in operation.
The tool "MOVEX Change Data Capture" presented here addresses these problems:
- without intervention in the operation of the DB
- without intervention in the structures of the DB applications monitored with regard to changes
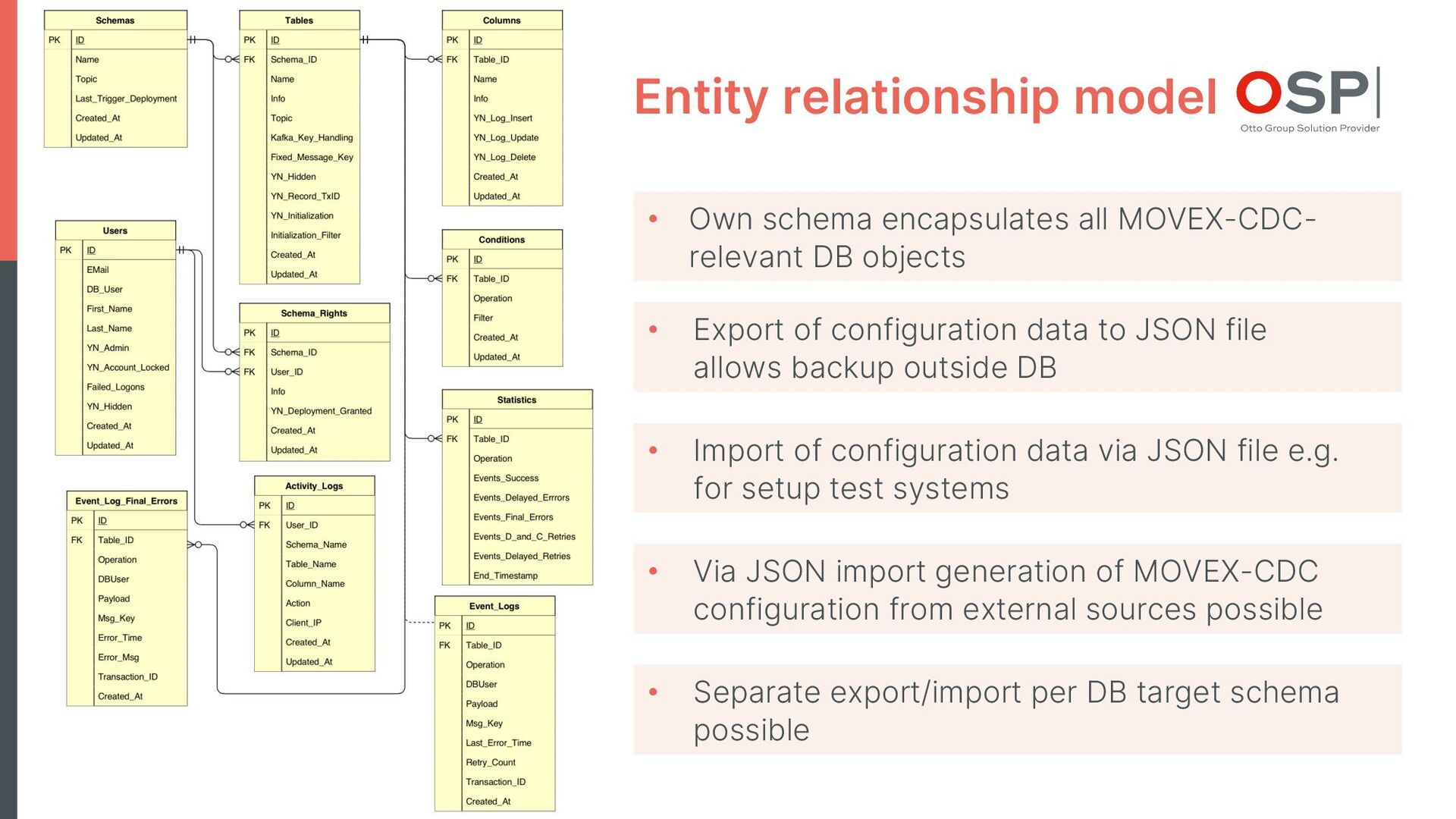
- with isolation of all DB structures required for CDC in a separate DB schema
- scalable up to billions of events/day
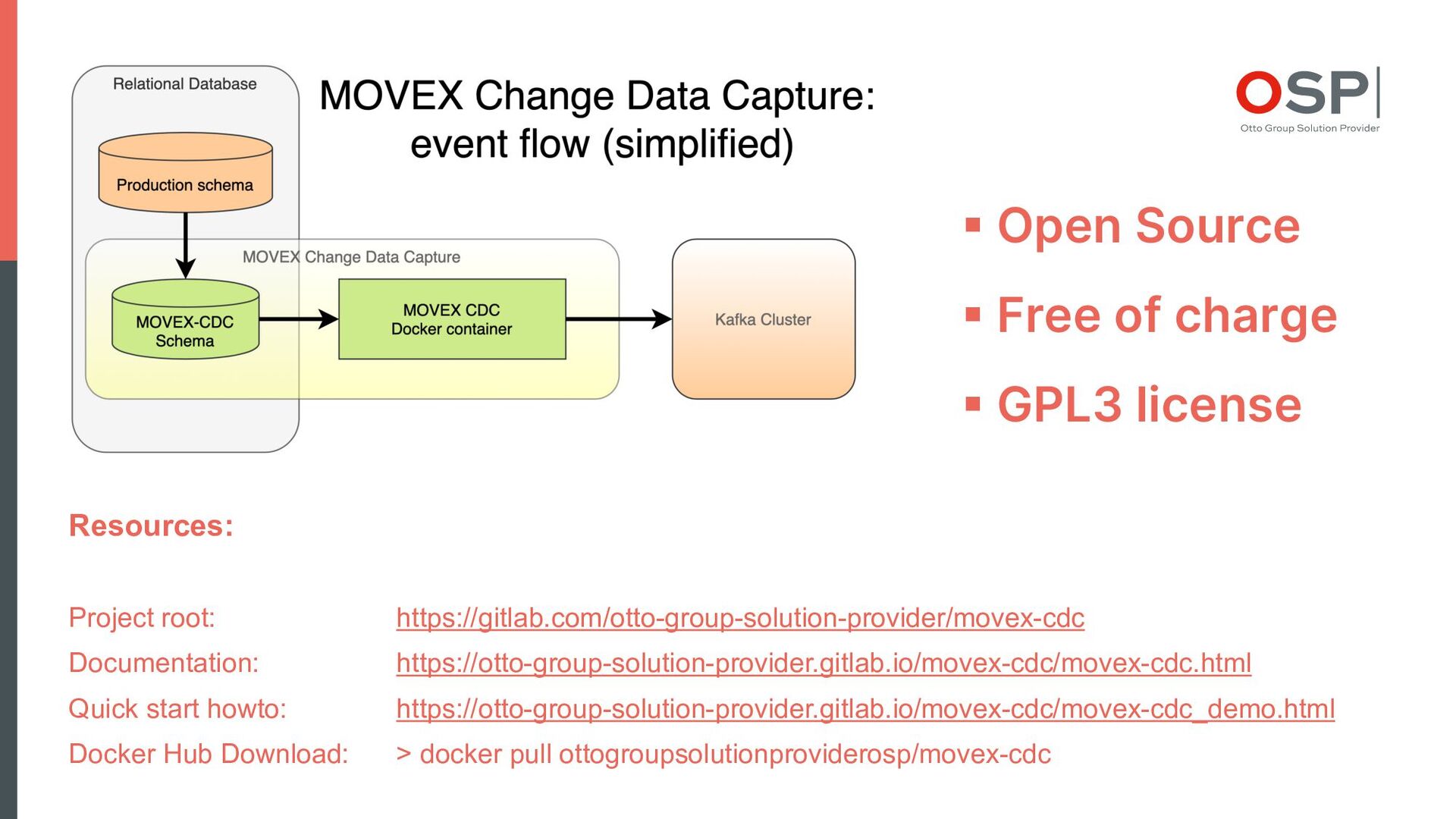
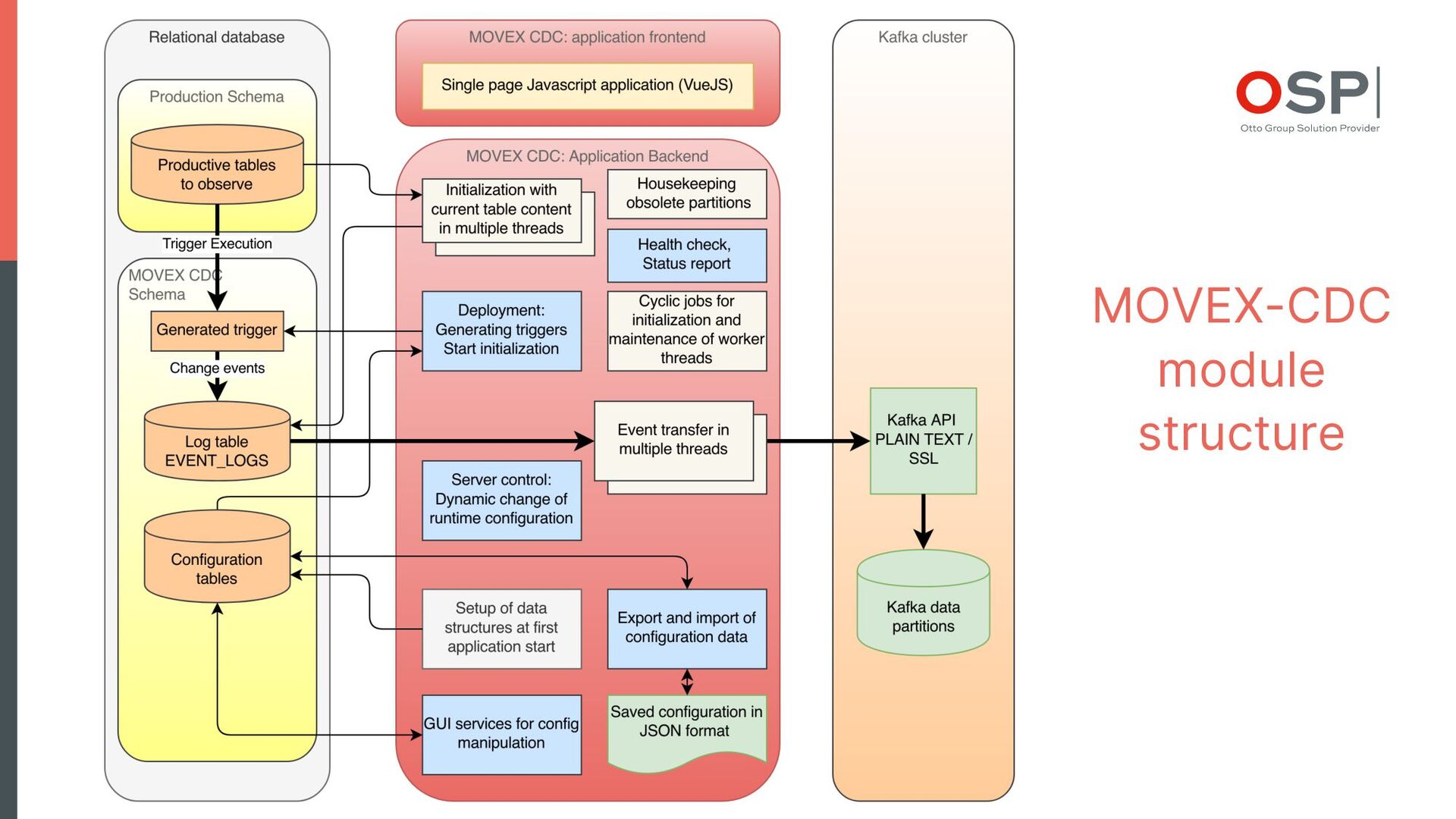
This lightweight solution is based on DB triggers as event source and encapsulates all functions for initialization of own data structures, API, web GUI for configuration, trigger generation, event transfer to Kafka in exactly one Docker container.
"MOVEX Change Data Capture" is open source and freely available at https://gitlab.com/otto-group-solution-provider/movex-cdc.
Translated with www.DeepL.com/Translator (free version)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}