Build a simple business intelligence dashboard using python and open-source tools.
Zero-to-one hands-on introduction to building a business dashboard using Bonobo ETL, Airflow, and a bit of Grafana (because graphs are cool). Although the opposite is better, there is no need of prior knowledge about any of those tools.
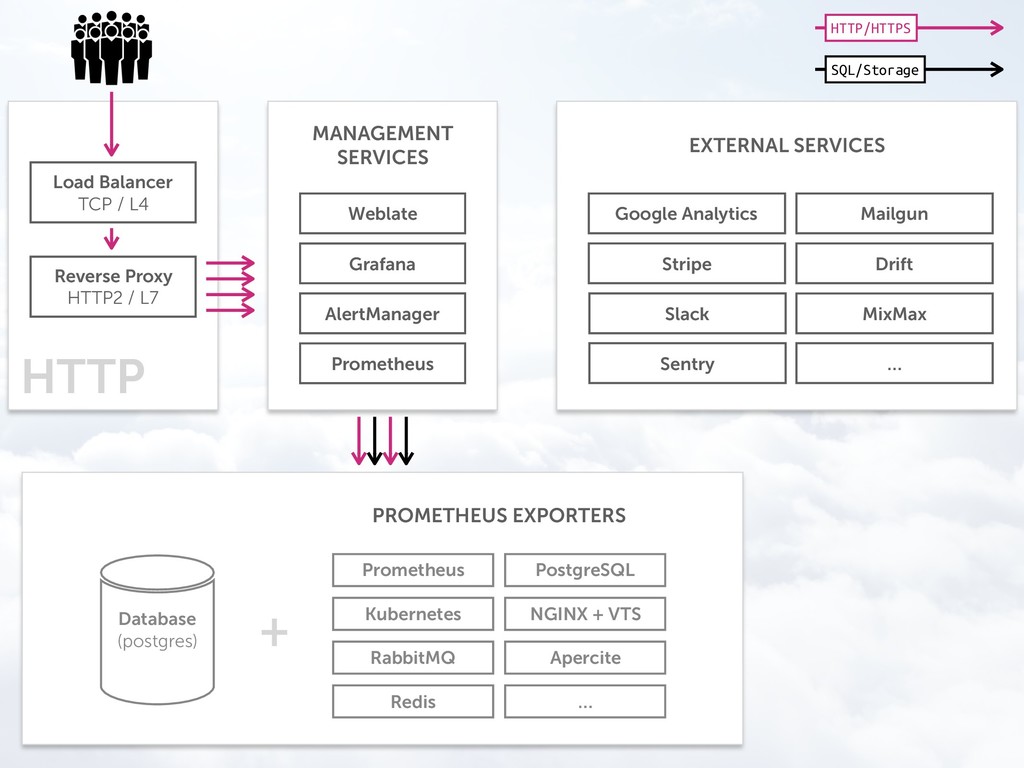
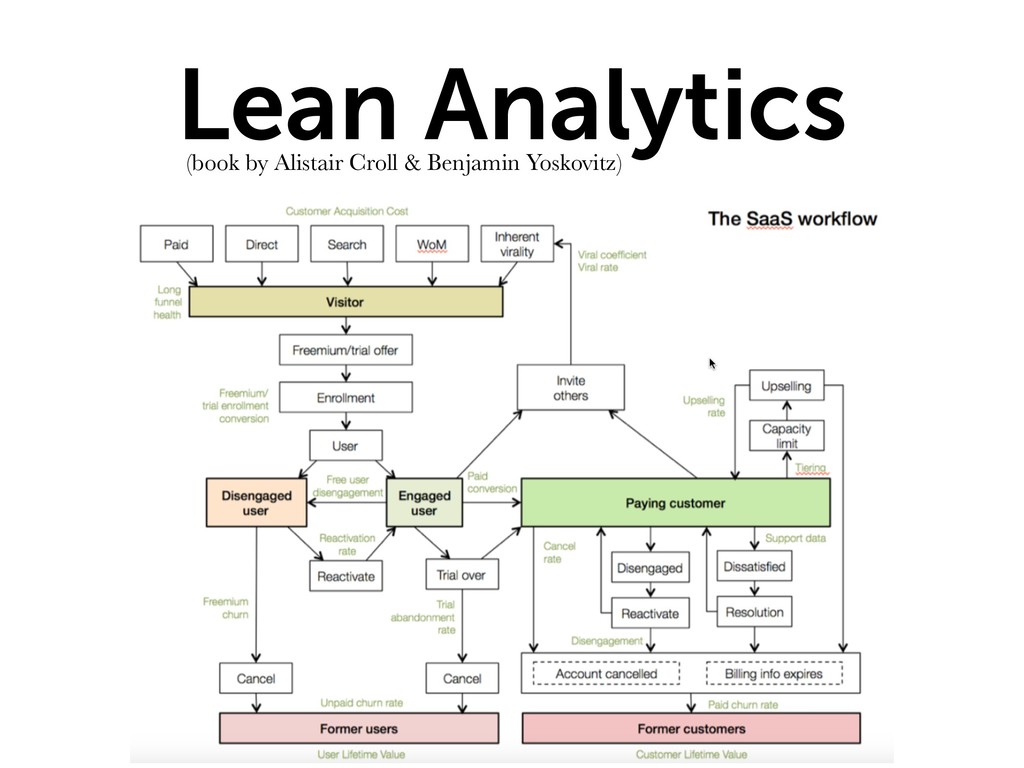
After a short introduction about the tools, we'll go through the following topics, using the real data of a small SaaS software:
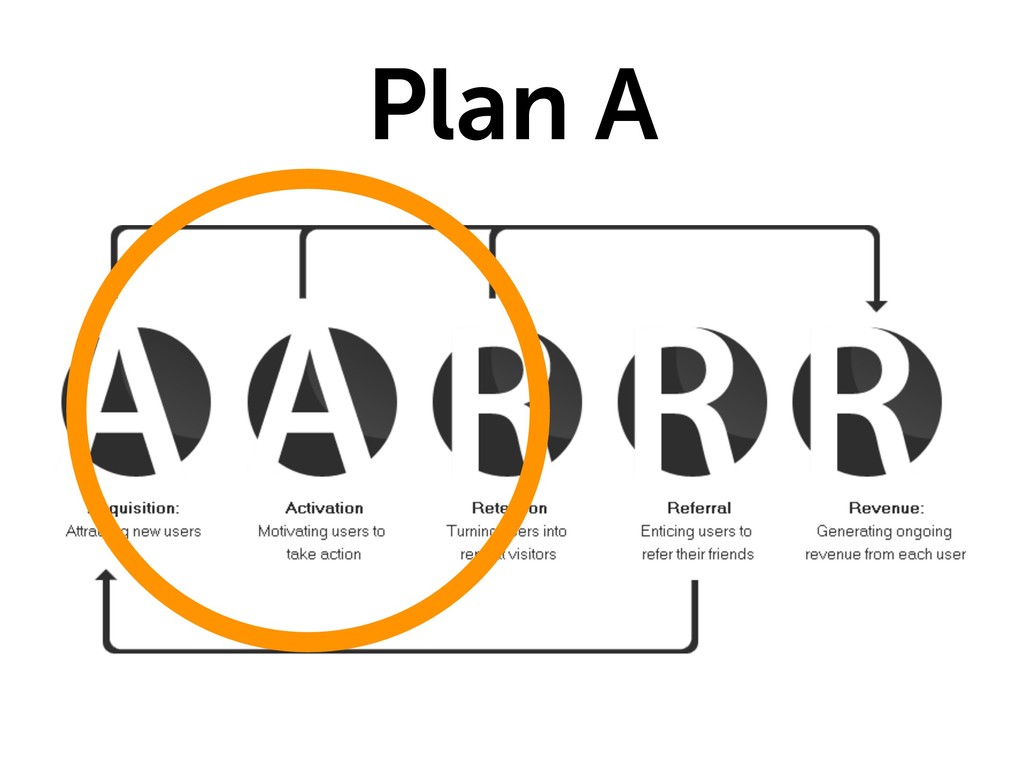
* Plan (What data do we need to see?)
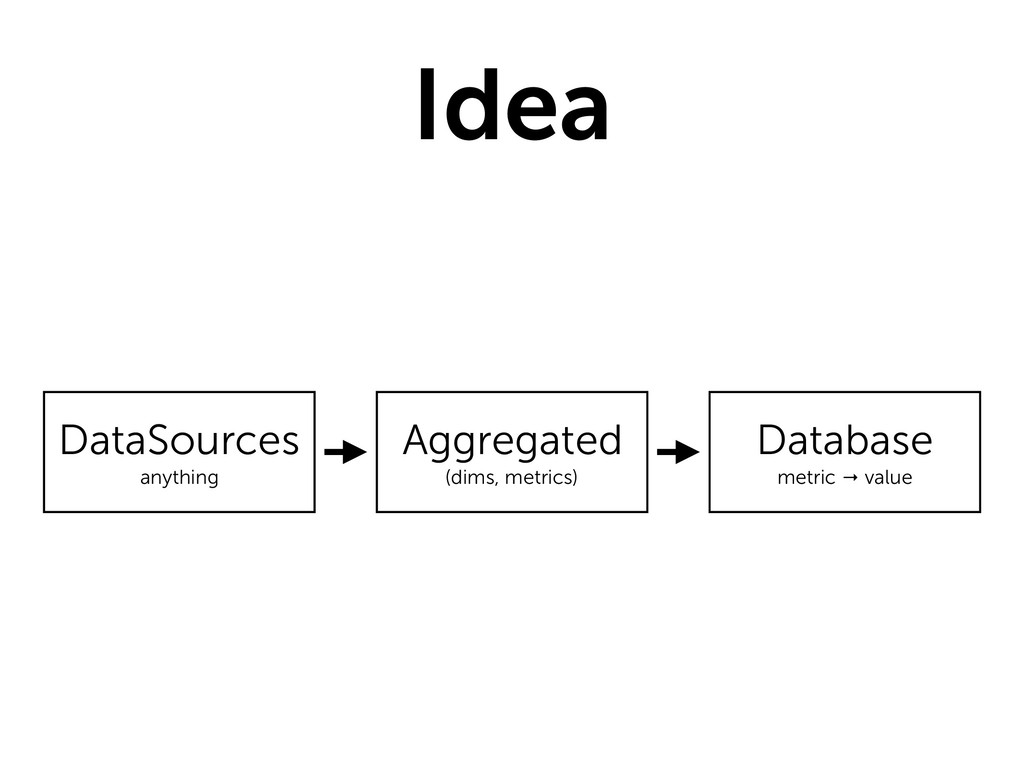
* Implement (How do we quickly get those graphs up?)
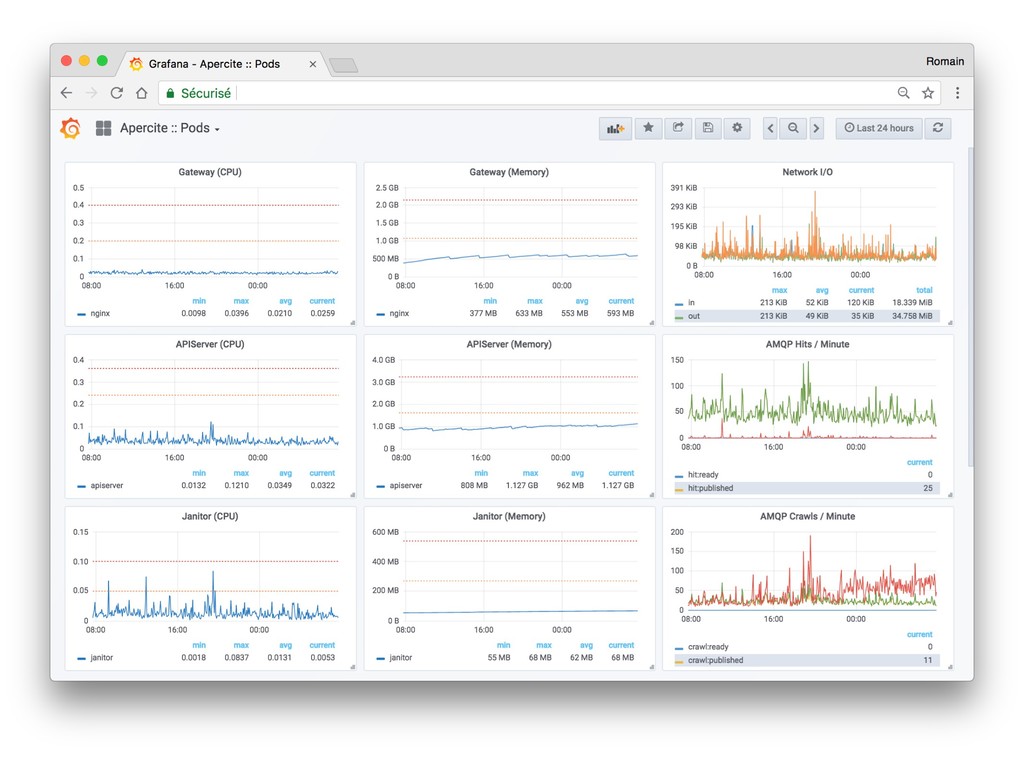
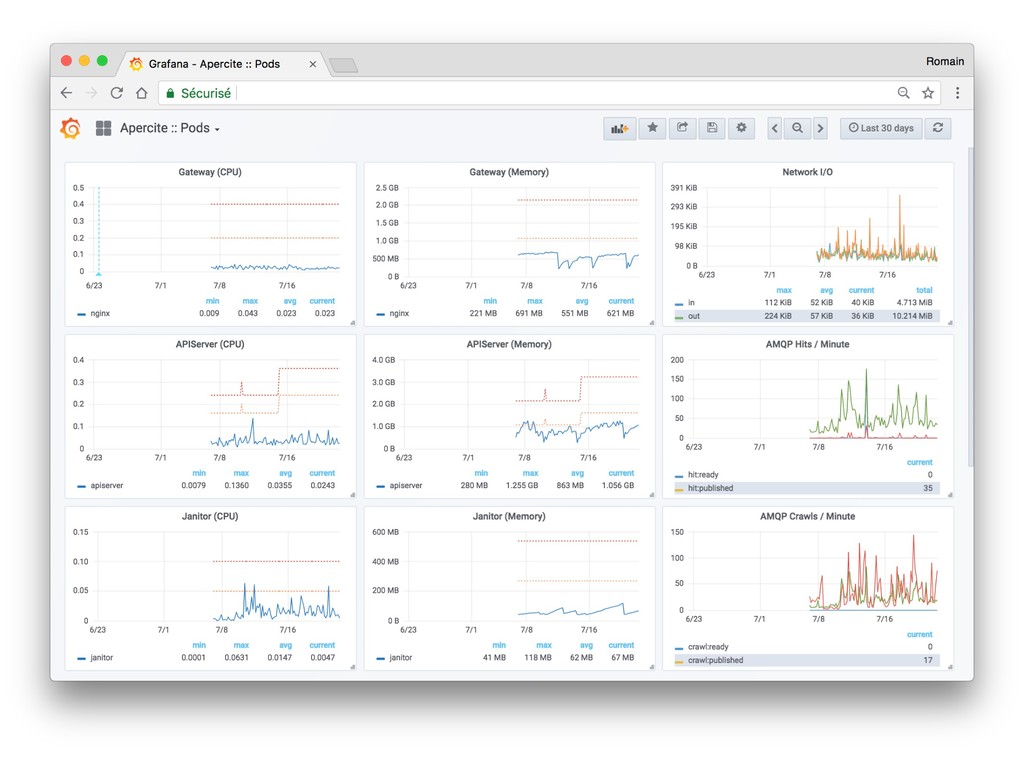
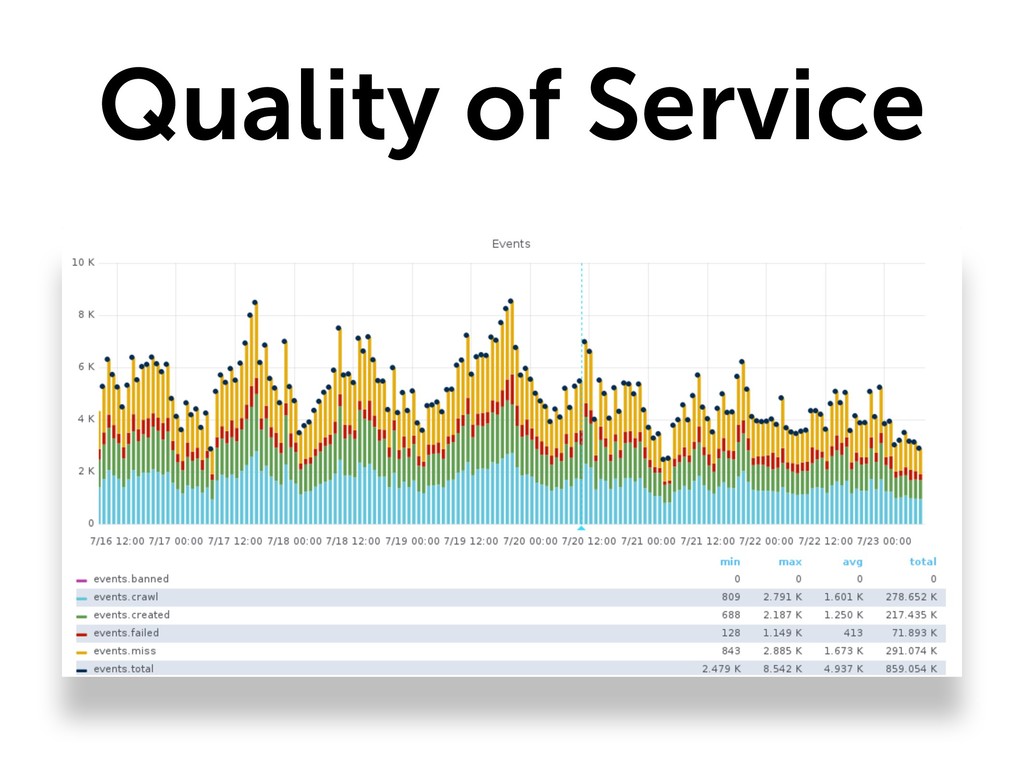
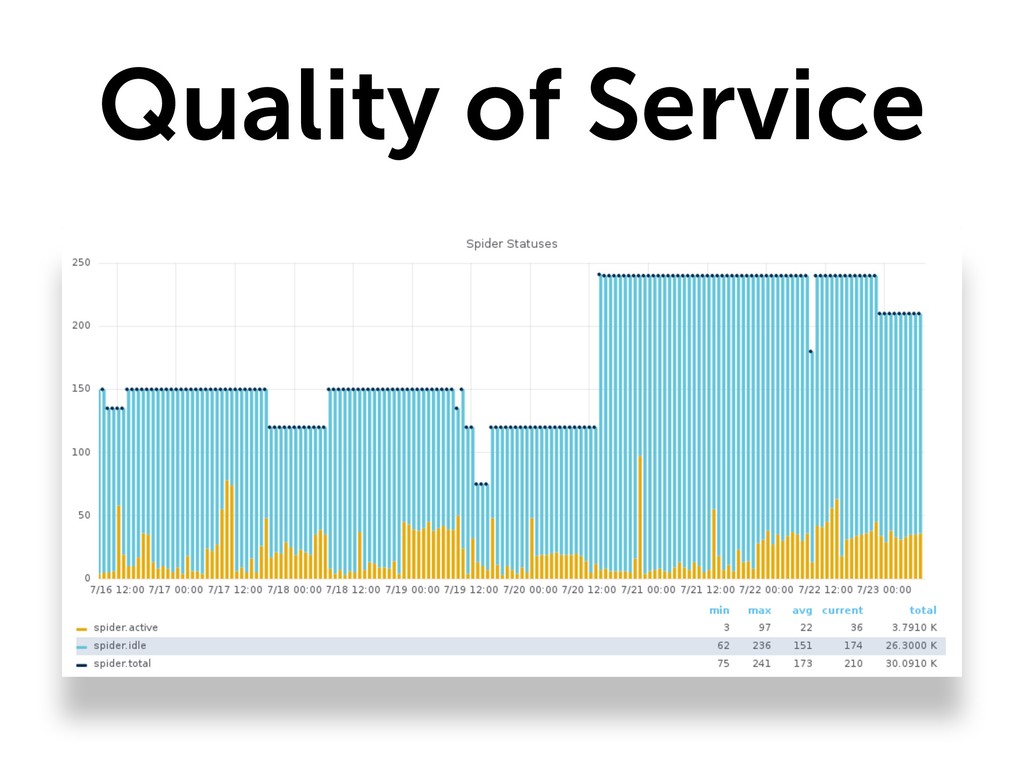
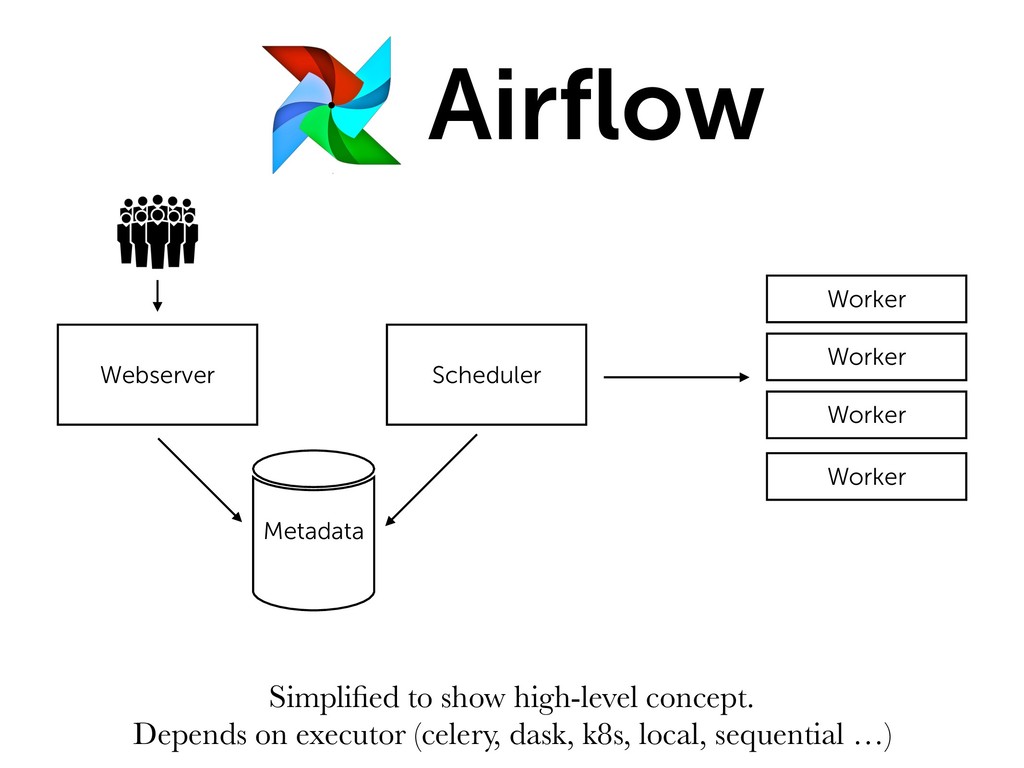
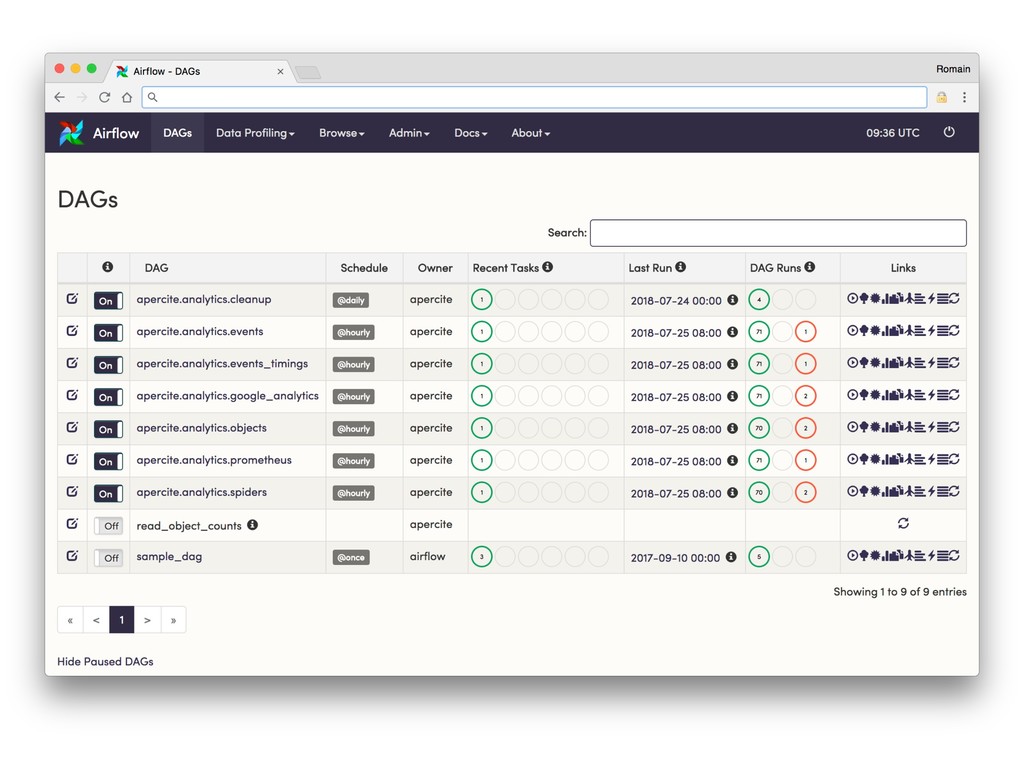
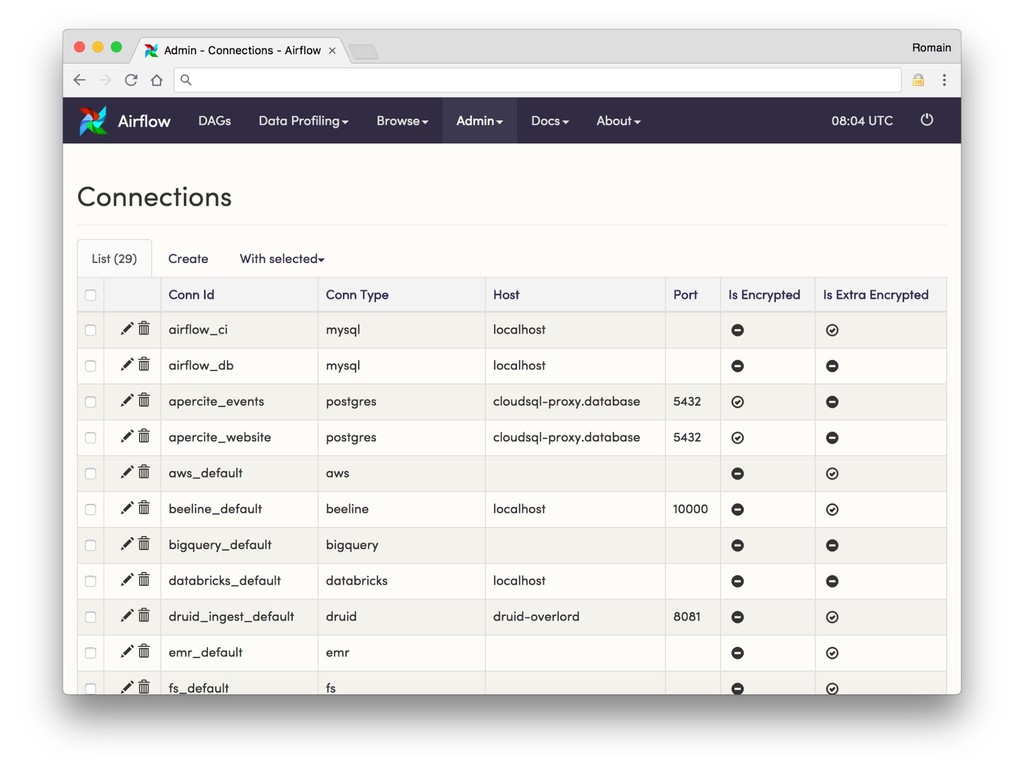
* Monitor (Are you sure your data's still there?)
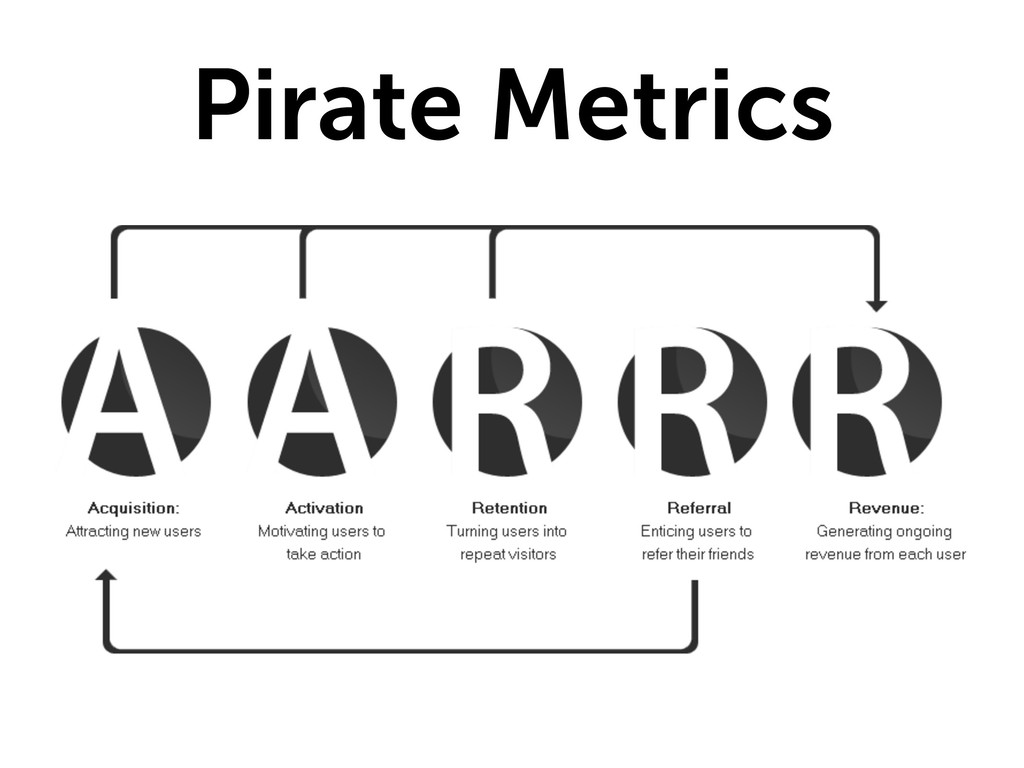
«Metrics you watch tend to improve over time»
{kind=link}
![makersquad.fr Romain Dorgueil [email protected] Building software from Zero to](https://files.speakerdeck.com/presentations/dd5a73e5c0b6496a83e29d0b0e0f9deb/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
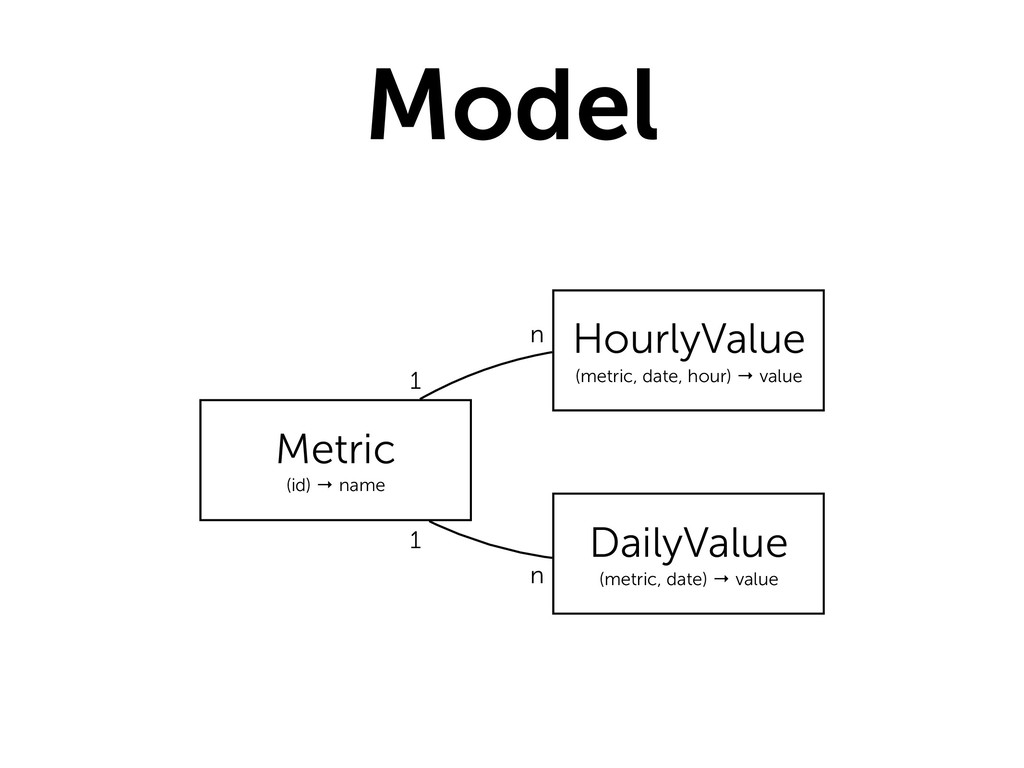{kind=link}
{kind=link}
{kind=link}
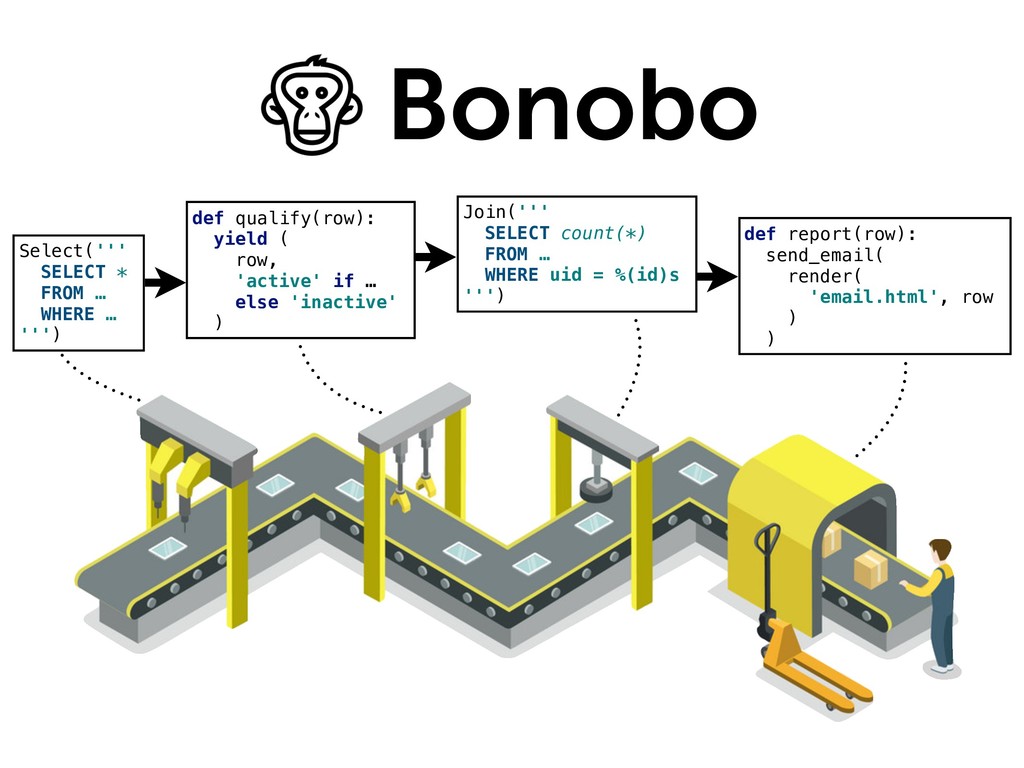{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Normalize bonobo.SetFields(['dims', 'metrics']) All data should look the same](https://files.speakerdeck.com/presentations/dd5a73e5c0b6496a83e29d0b0e0f9deb/slide_32.jpg){kind=link}
{kind=link}
![Compose def get_graph(): normalize = bonobo.SetFields(['dims', 'metrics']) graph = bonobo.Graph(*get_readers(),](https://files.speakerdeck.com/presentations/dd5a73e5c0b6496a83e29d0b0e0f9deb/slide_34.jpg){kind=link}
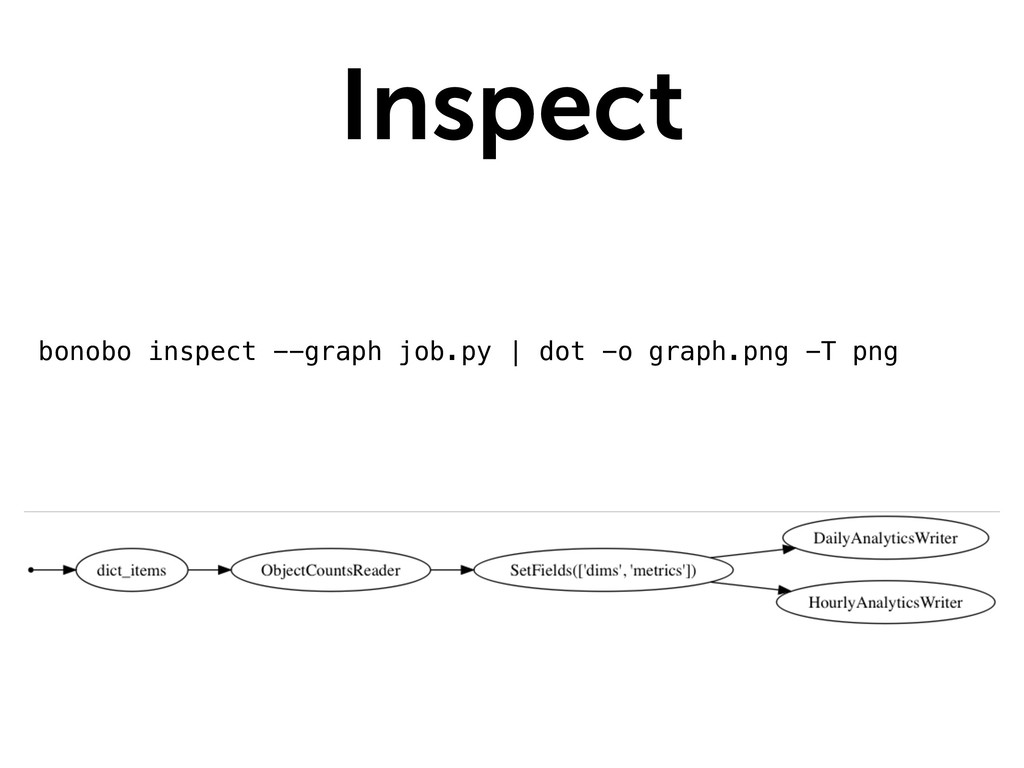{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Spider counts class SpidersReader(Select): kwargs = Option() output_fields = ['row']](https://files.speakerdeck.com/presentations/dd5a73e5c0b6496a83e29d0b0e0f9deb/slide_41.jpg){kind=link}
![Spider counts def spider_reducer(self, left, right): result = dict(left) result['spider.total']](https://files.speakerdeck.com/presentations/dd5a73e5c0b6496a83e29d0b0e0f9deb/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
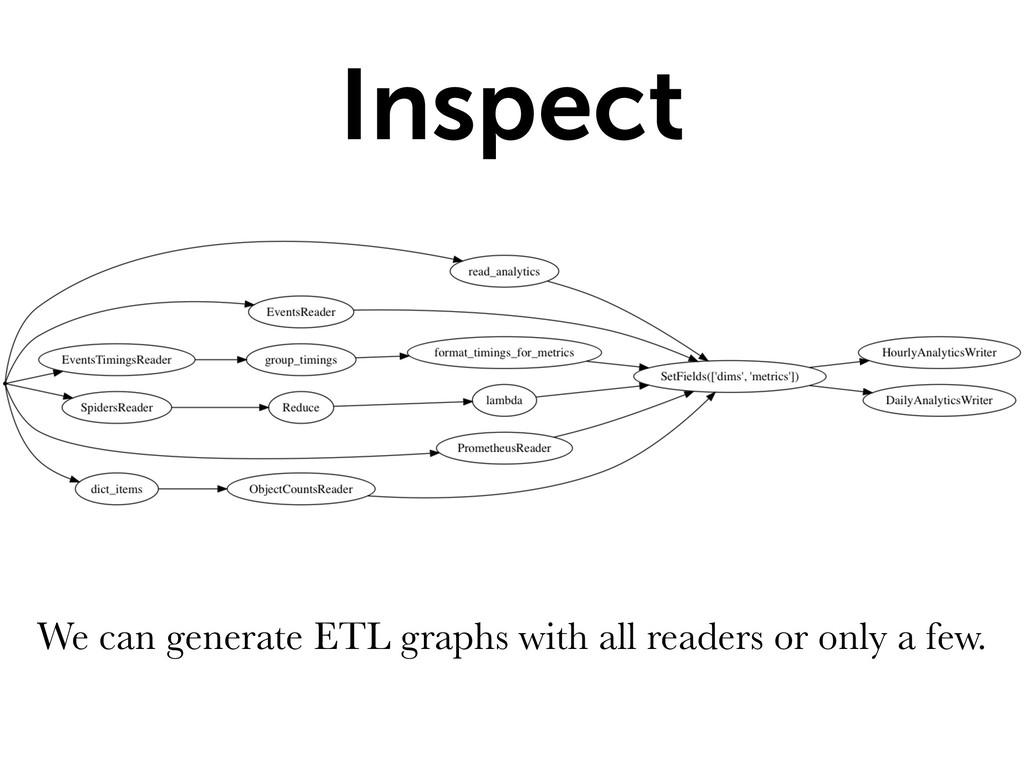{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
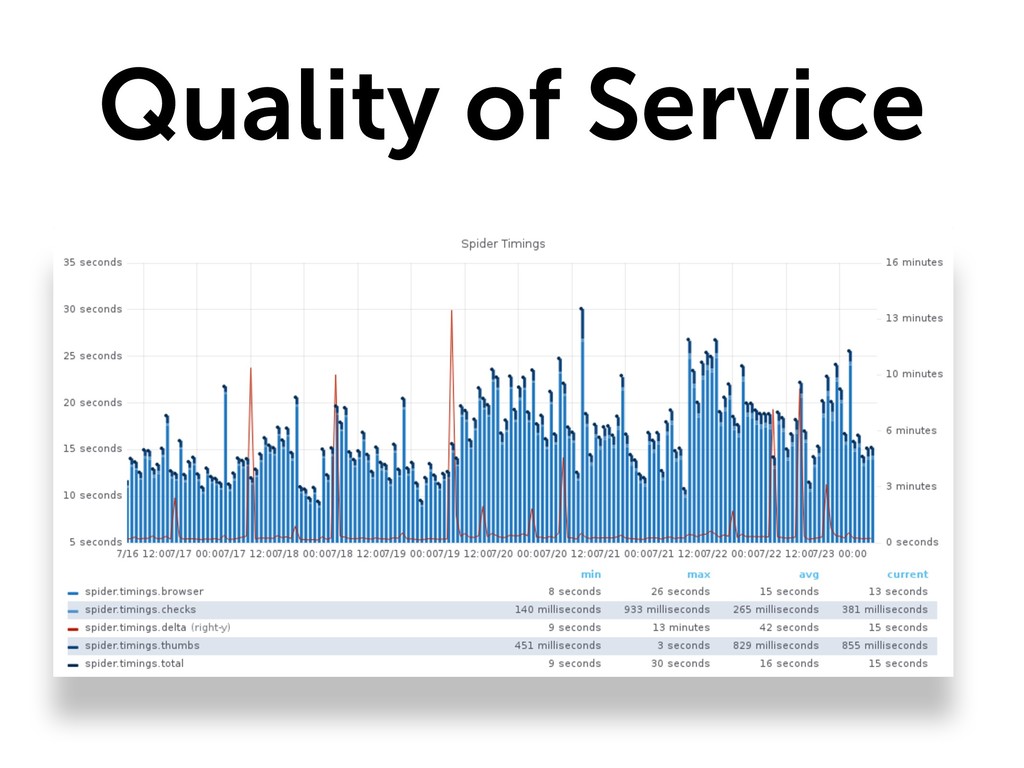{kind=link}
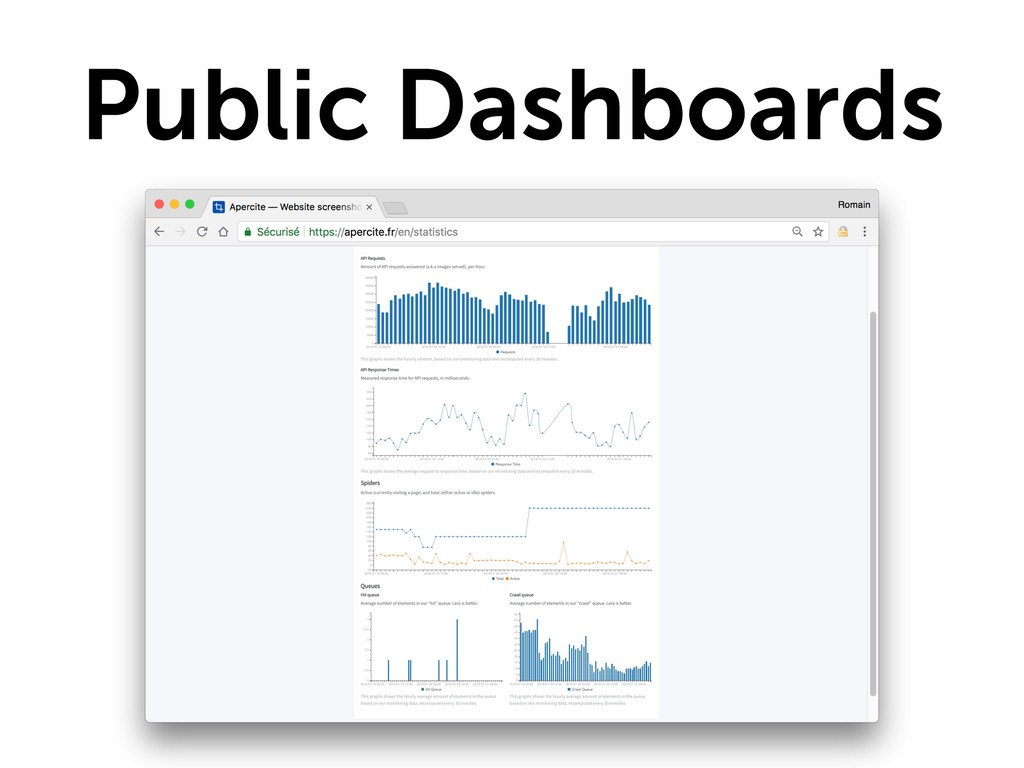{kind=link}
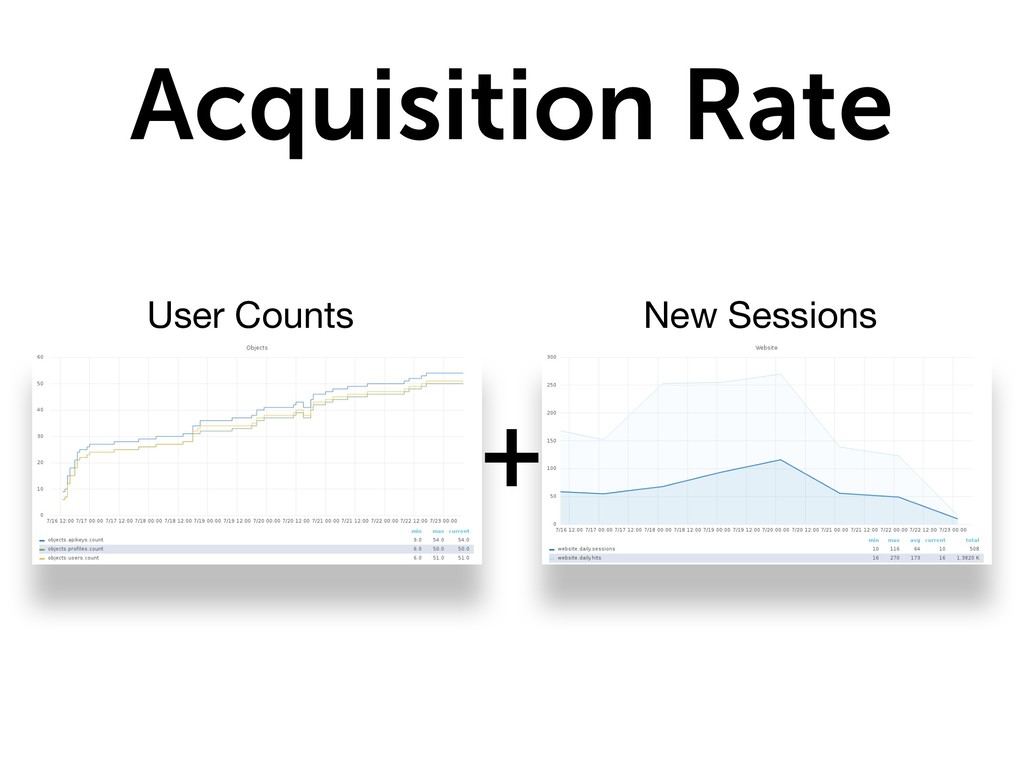{kind=link}
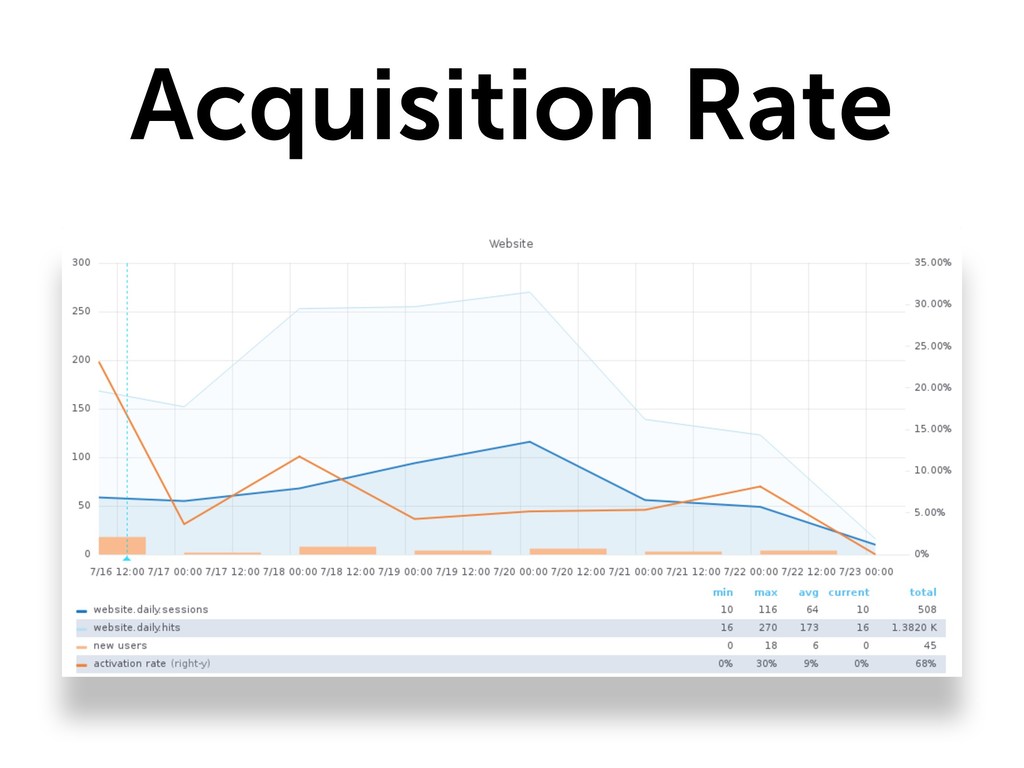{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] rdorgueil](https://files.speakerdeck.com/presentations/dd5a73e5c0b6496a83e29d0b0e0f9deb/slide_74.jpg){kind=link}