“Scaling Laws for Neural Language Models”(Jared Kaplan, et al. @ OpenAI, arXiv, 2020.) スケーリング則(Scaling Laws for Neural Language Models) 自然言語処理モデルの パラメーター数・データセットのサイズ・トレーニングに使用される計算量が 増えるほど損失(Loss、誤差)が「べき乗則」に従って減少するという法則
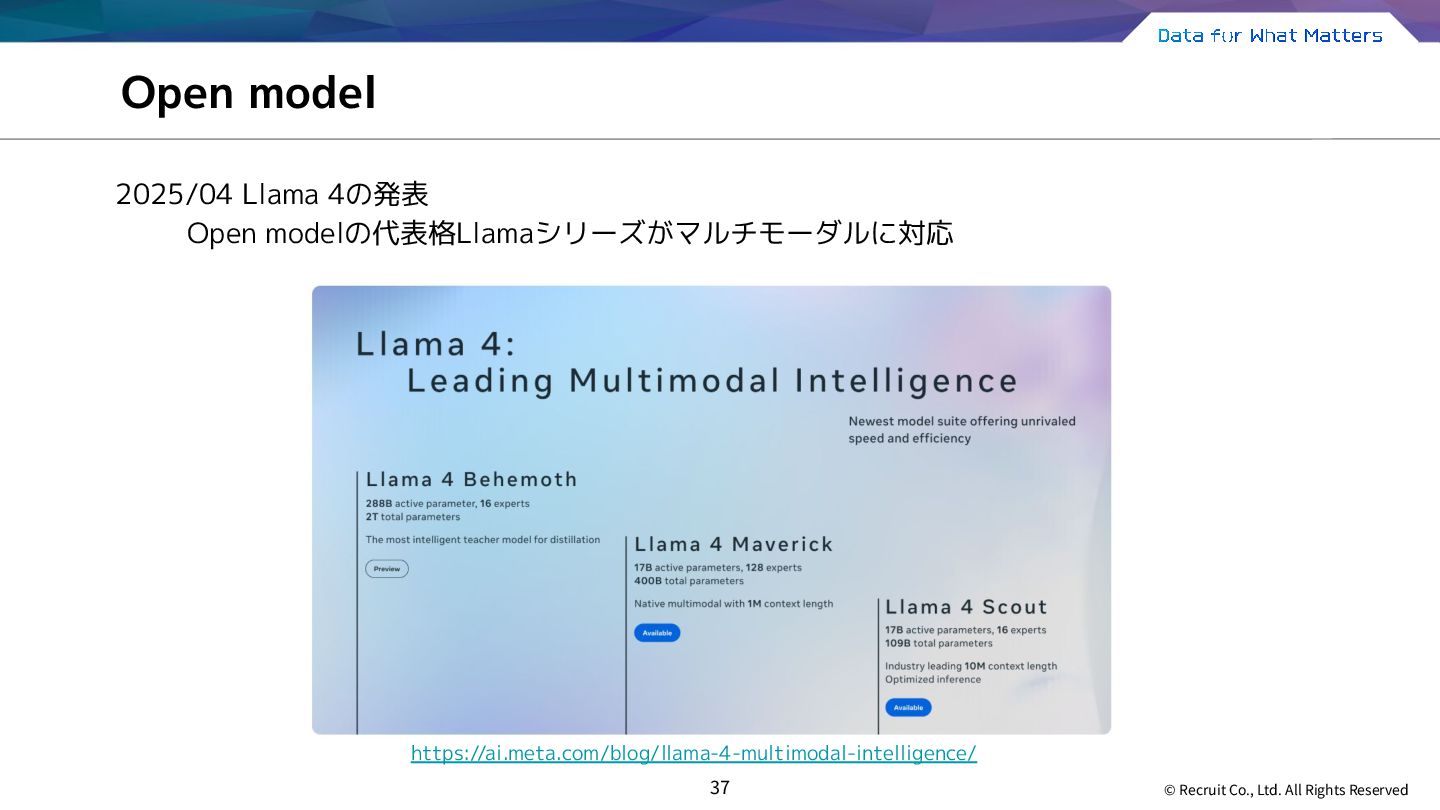
Open model Closed Model Open Model 具体例 OpenAI GPT-4o Google Gemini 2.0 Pro Meta Llama-3.1-8B Mistral AI Mistral-7B-v0.3 モデルパラメータ 公開されていない 公開されている 推論の方法 APIを呼び出して推論 GPUにロードして推論 モデルチューニング モデルプロバイダーによる 制限下で実施可能 比較的自由に実施可能 習得コスト 比較的低い 比較的高い 世の中に出回っている大規模言語モデルはパラメータ公開の観点で2タイプに分類できる モデルのタスク性能は基本的にClosedモデルが先行する どちらのタイプもほぼ共通したコア技術が用いられている
Transformerについて詳しく知りたい人向け GPTとは何か Transformerの視覚化 | Chapter 5, Deep Learning https://www.youtube.com/watch?v=KlZ-QmPteqM 30分で完全理解するTransformerの世界 https://zenn.dev/zenkigen_tech/articles/2023-01-shimizu Attention Is All You Need (あまりにも有名な図の原典→ https://arxiv.org/pdf/1706.03762
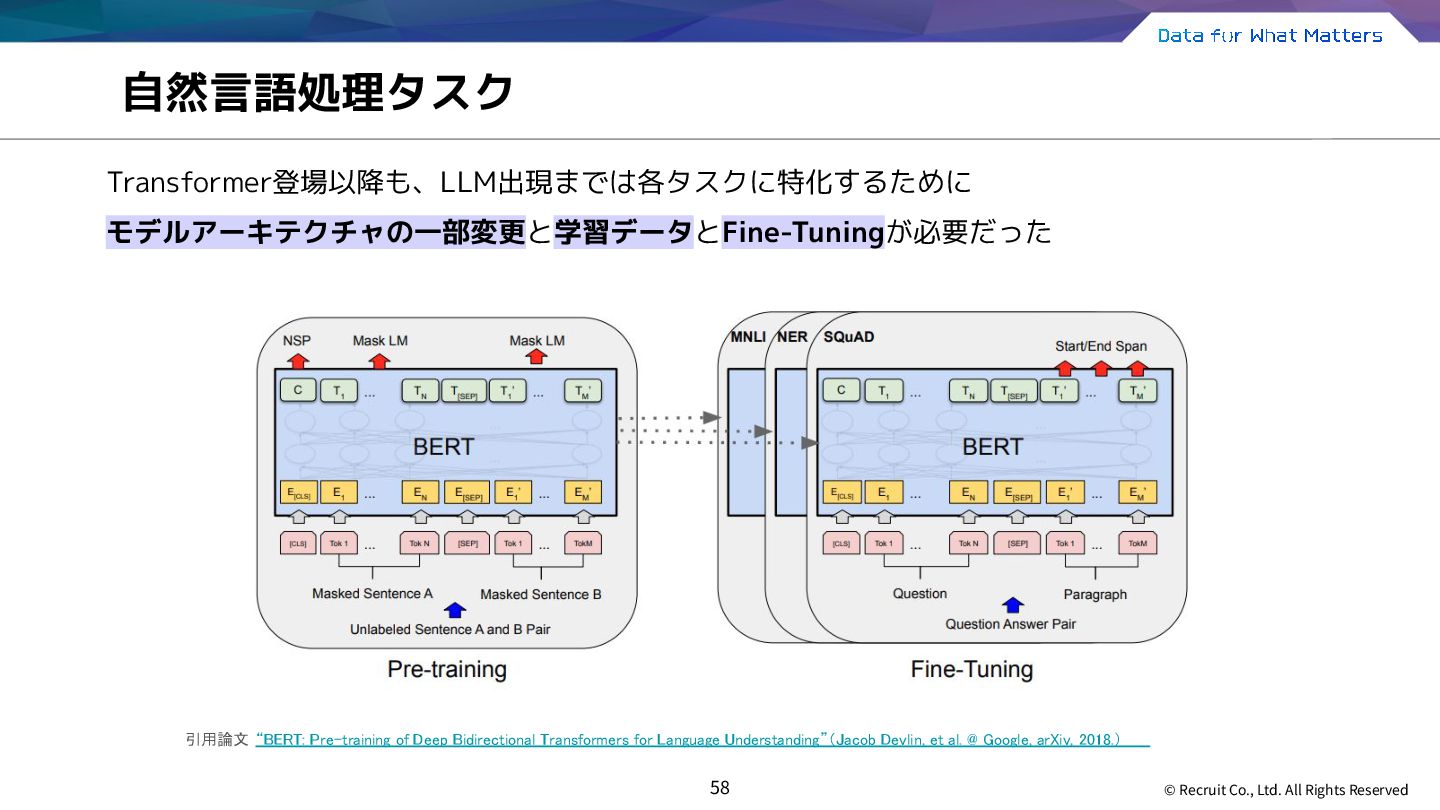
モデルアーキテクチャの一部変更と学習データとFine-Tuningが必要だった 引用論文 “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”(Jacob Devlin, et al. @ Google, arXiv, 2018.)
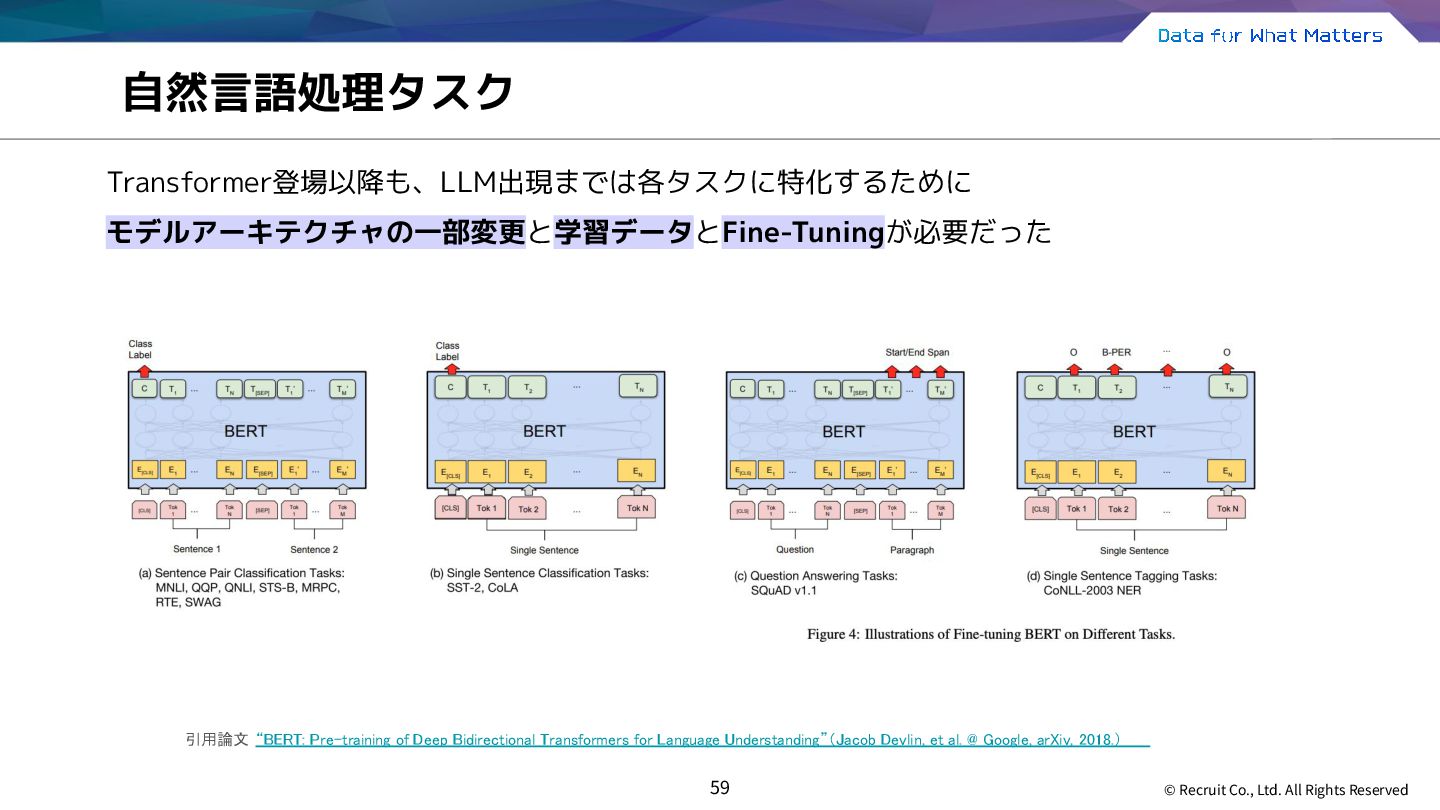
モデルアーキテクチャの一部変更と学習データとFine-Tuningが必要だった 引用論文 “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”(Jacob Devlin, et al. @ Google, arXiv, 2018.)
文章埋め込みモデルについて詳しく知りたい人向け Ruri: 日本語に特化した汎用テキスト埋め込みモデル https://zenn.dev/hpp/articles/b5132c64c40d24 エンベディング | Gemini API | Google AI for Developers https://ai.google.dev/gemini-api/docs/embeddings?hl=ja
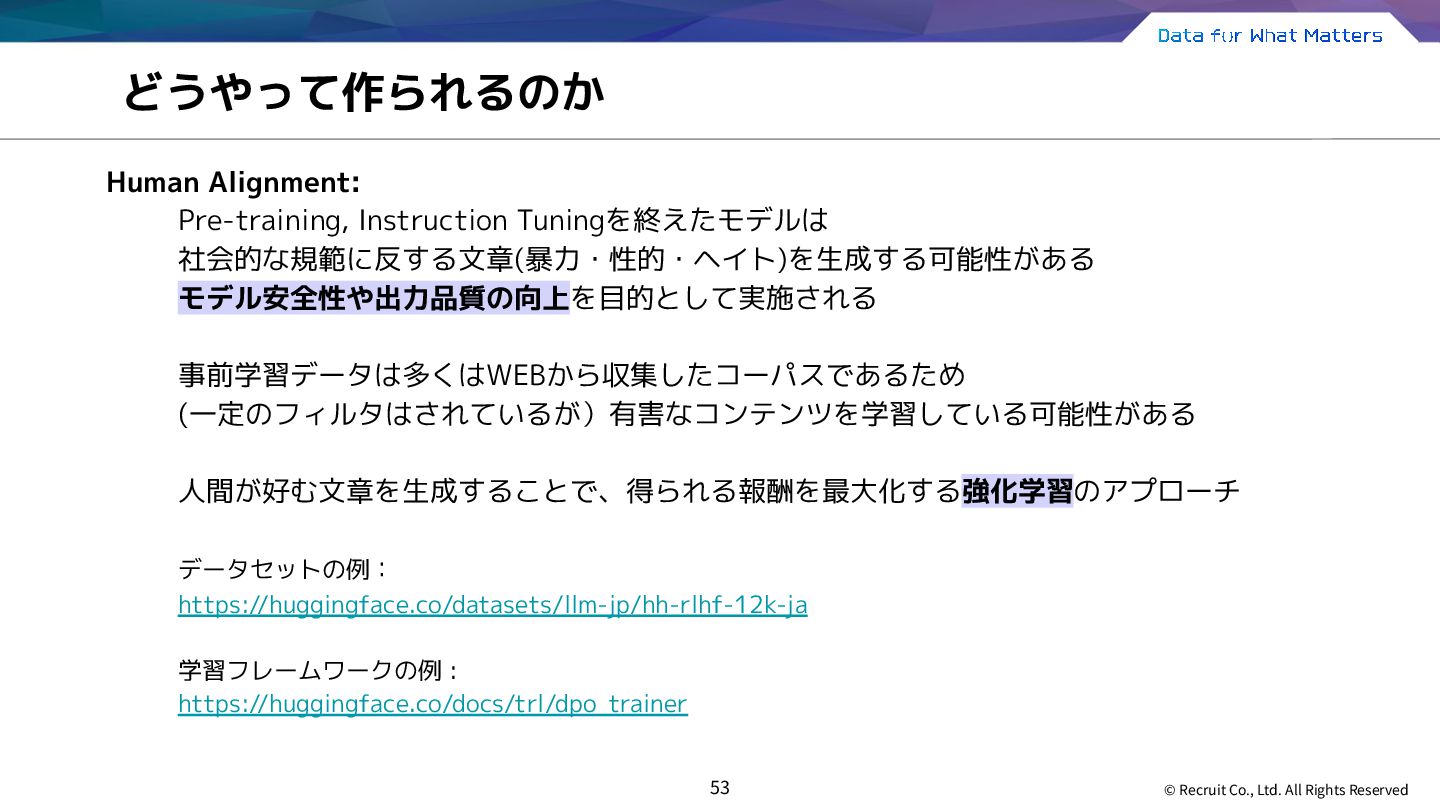
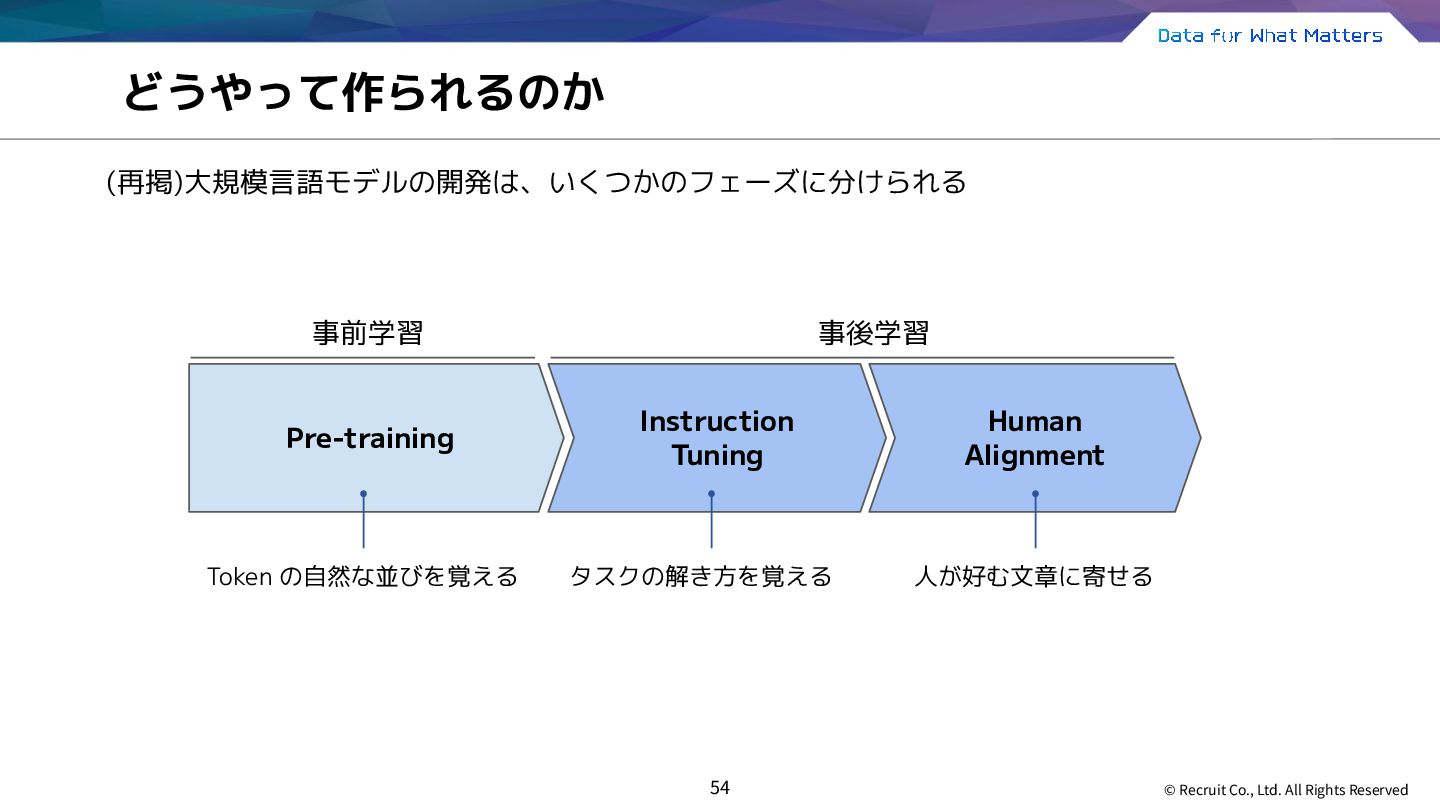
大規模言語モデルを使って俳句大会をしました • 大規模言語モデルを使ってテキストごとの対数尤度を出力しました • 大規模言語モデルのTokenizerを使ってその役割を理解しました • 大規模言語モデルを使ってLLM-as-a-judgeを試してみました • 大規模言語モデルのStructured Outputを使って出力の構造化をしました • 大規模言語モデルで簡単なRAGシステムを作ってみました Part 0:大規模言語モデルで遊ぶ Part 1:大規模言語モデルってなんですか Part 2 : Deep dive into LLM Part 3 : LLM as a Workshop
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
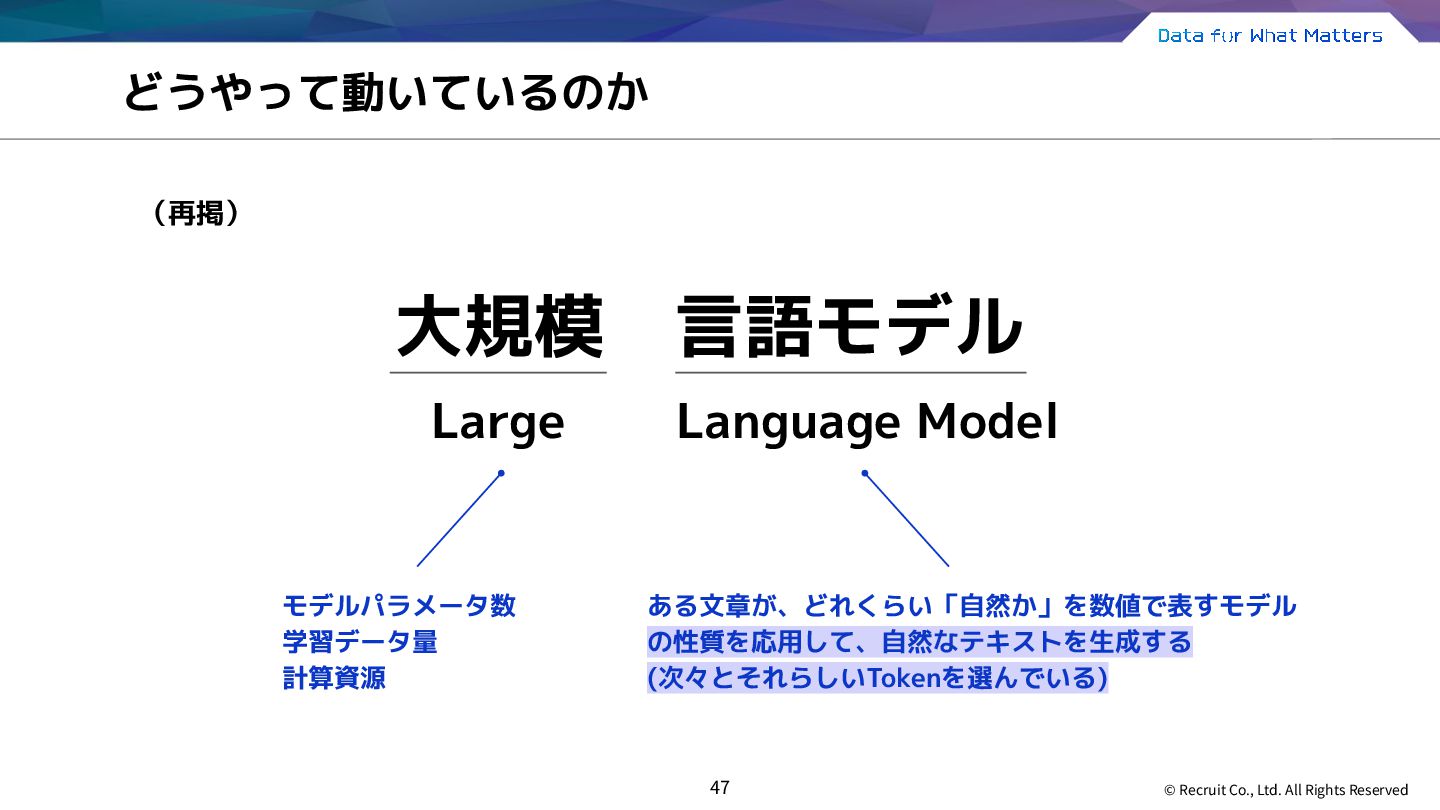{kind=link}
{kind=link}
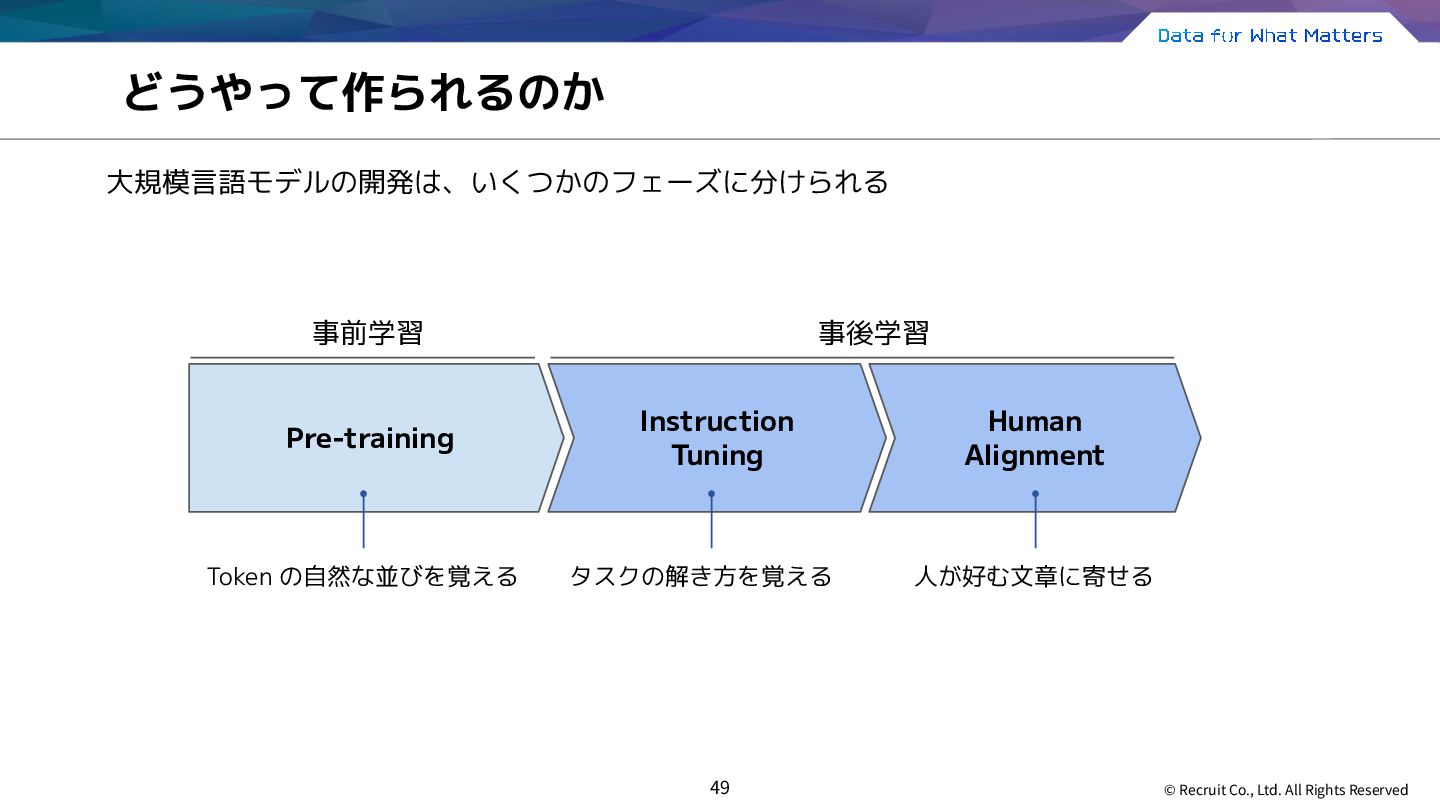{kind=link}
{kind=link}
{kind=link}
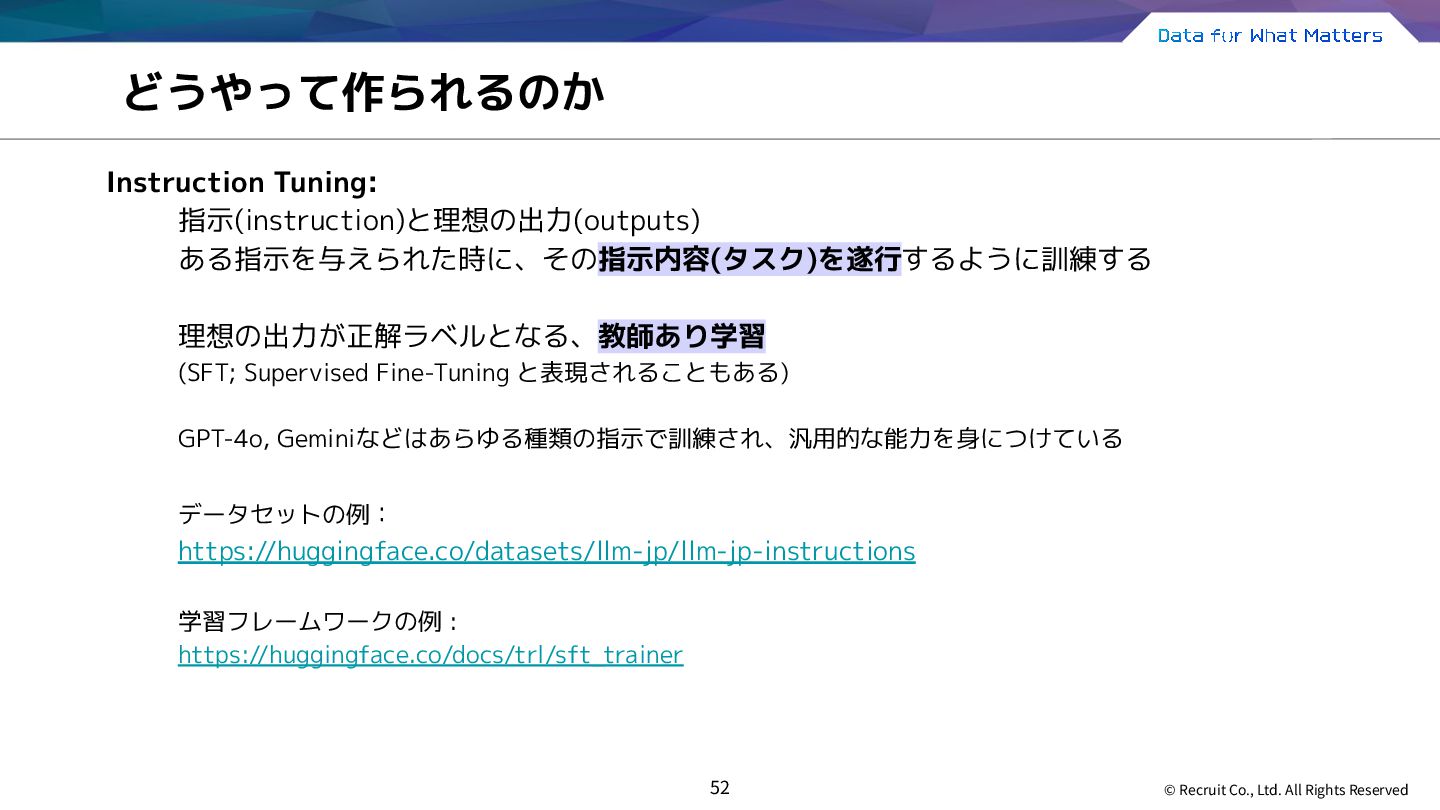{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
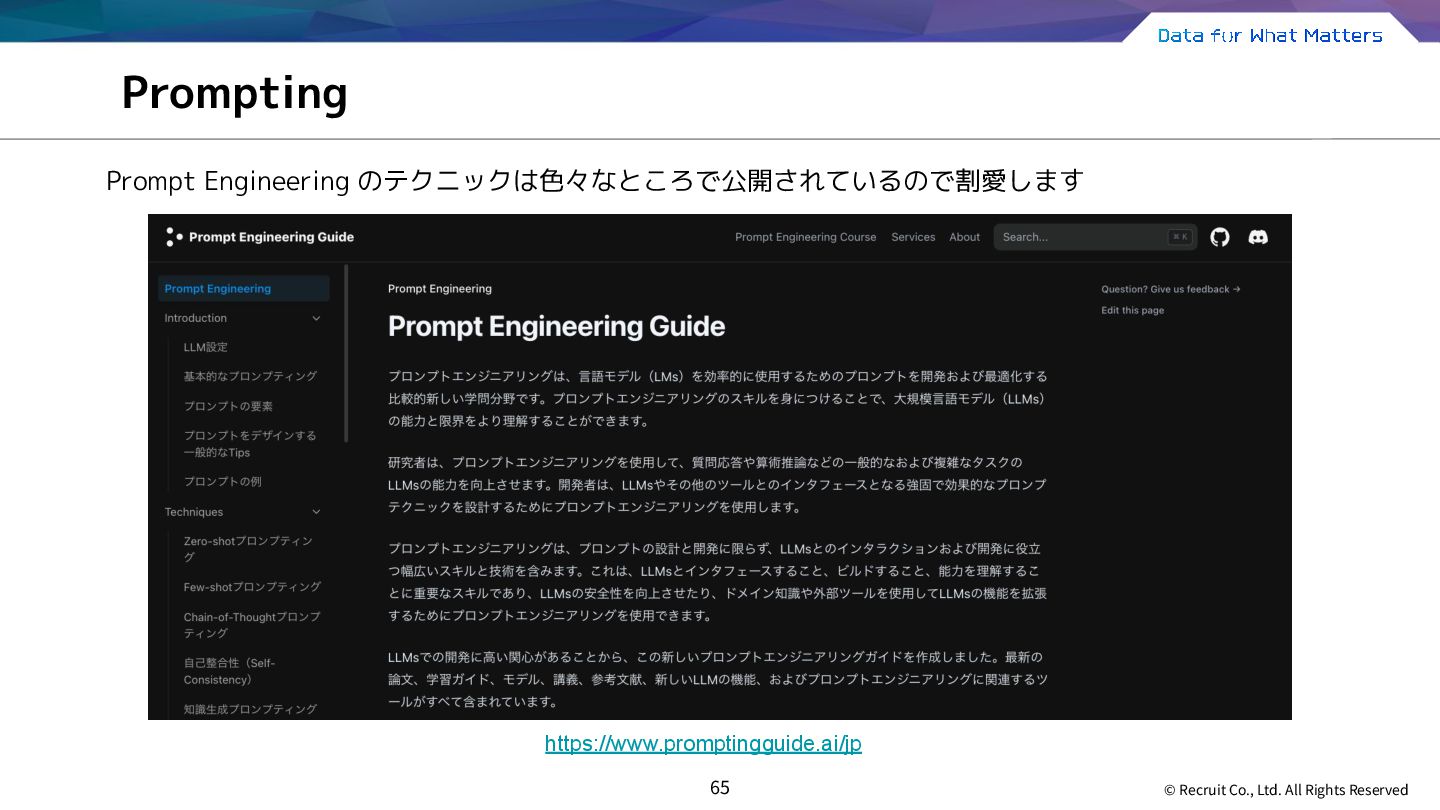{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
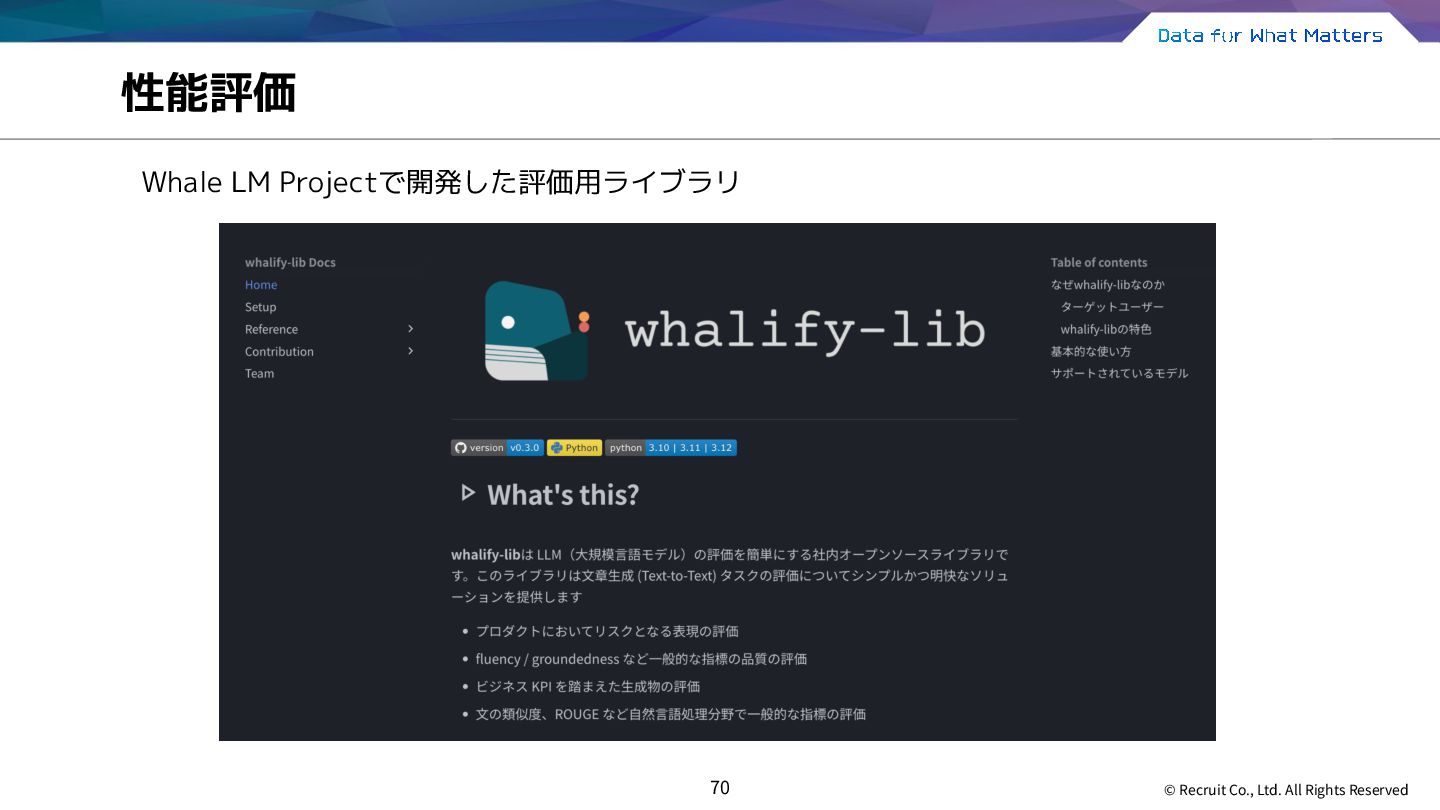{kind=link}
{kind=link}
{kind=link}
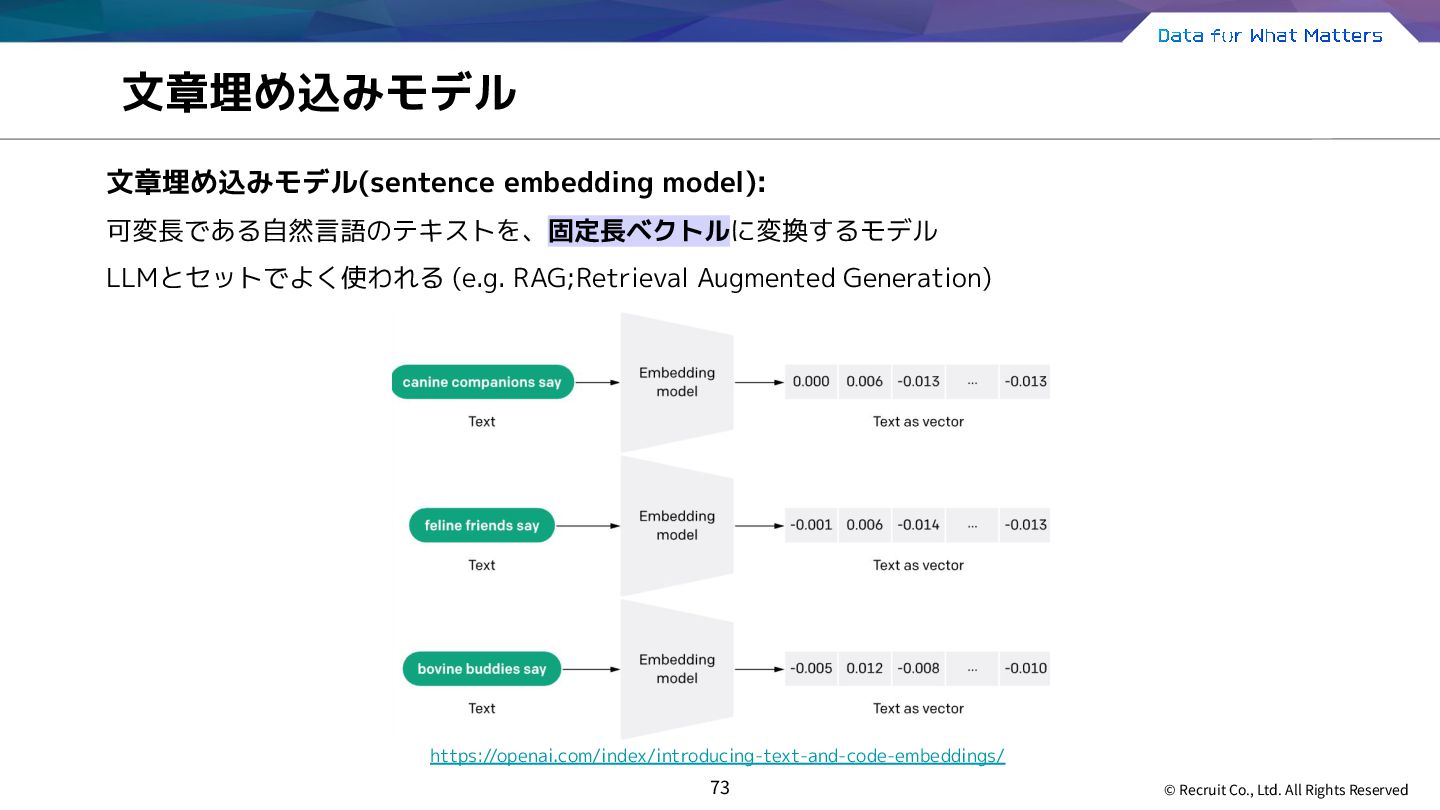{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
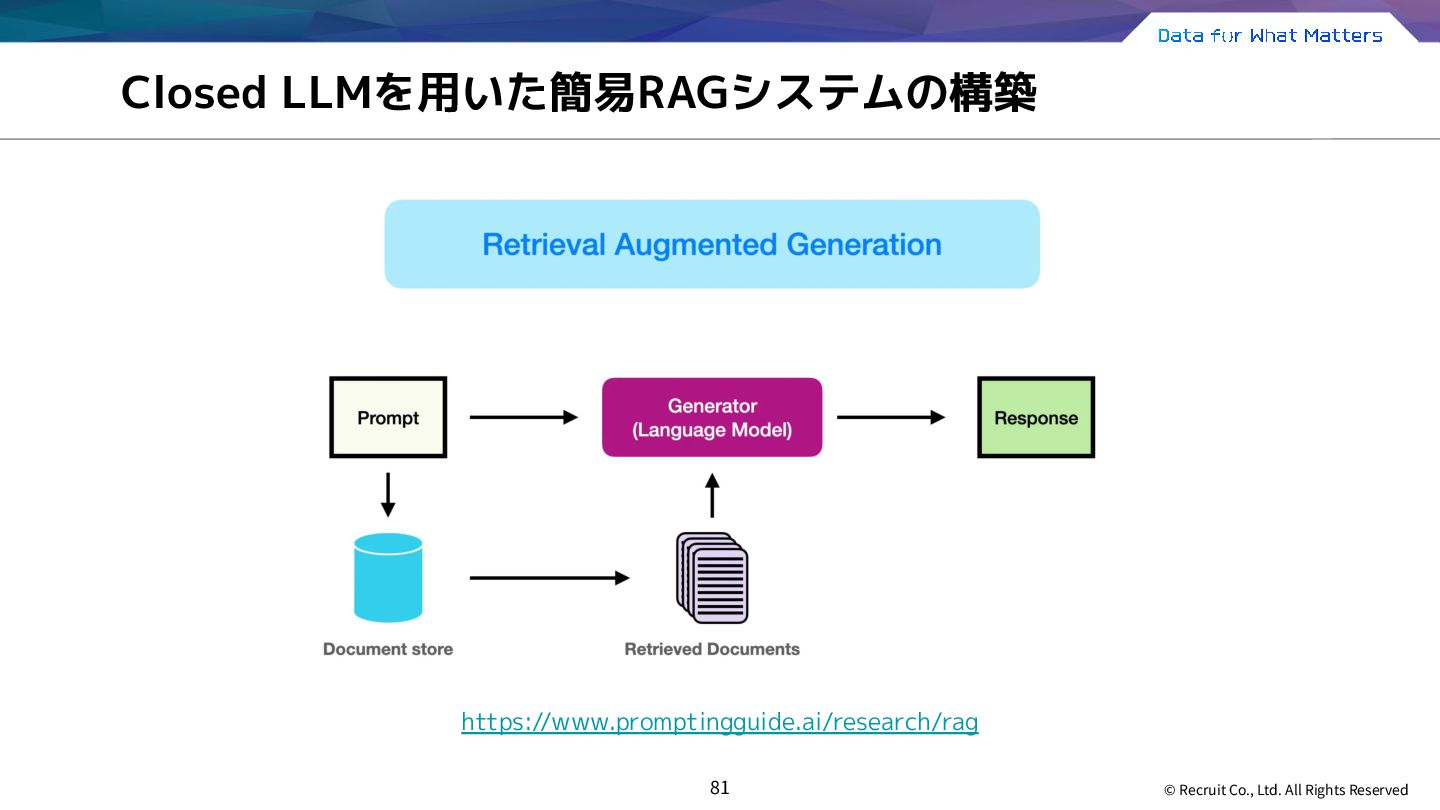{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}