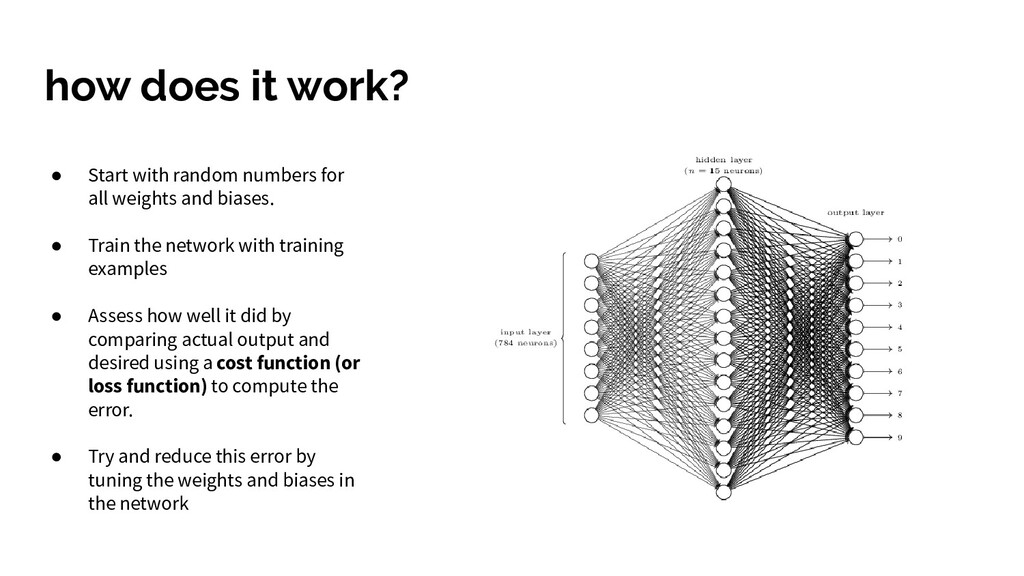
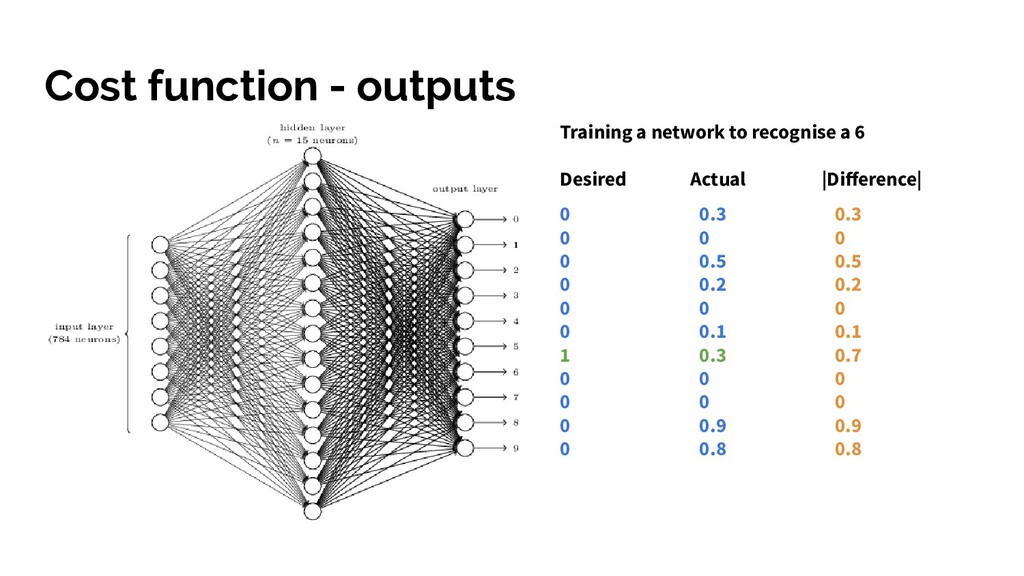
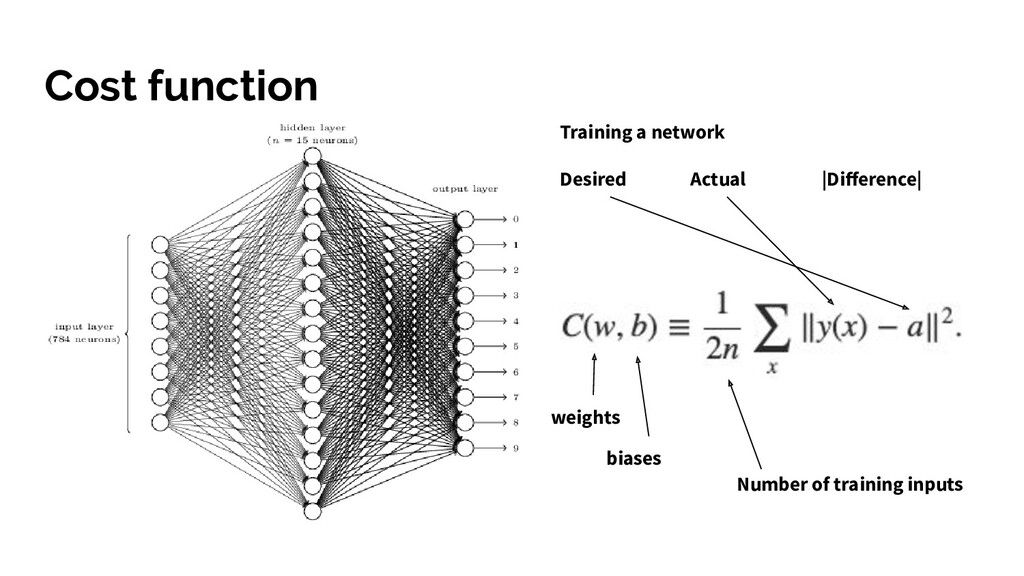
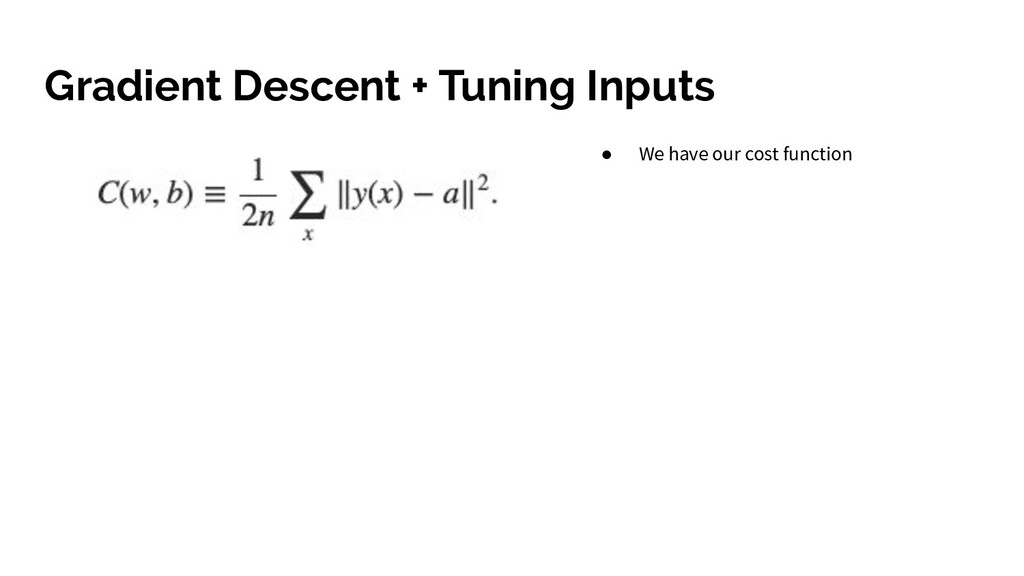
all weights and biases. • Train the network with training examples • Assess how well it did by comparing actual output and desired using a cost function (or loss function) to compute the error. • Try and reduce this error by tuning the weights and biases in the network
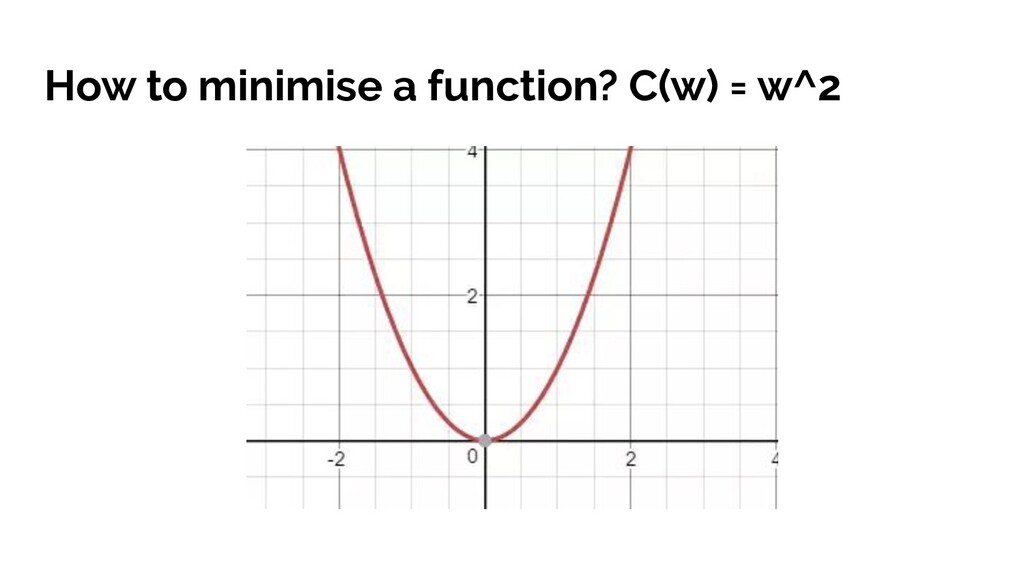
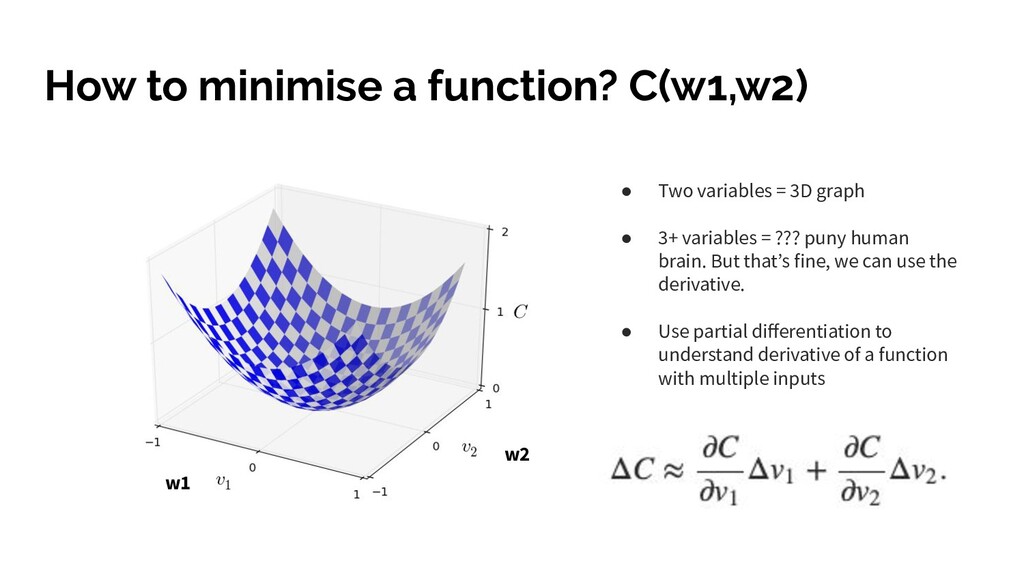
variables = 3D graph • 3+ variables = ??? puny human brain. But that’s fine, we can use the derivative. • Use partial differentiation to understand derivative of a function with multiple inputs
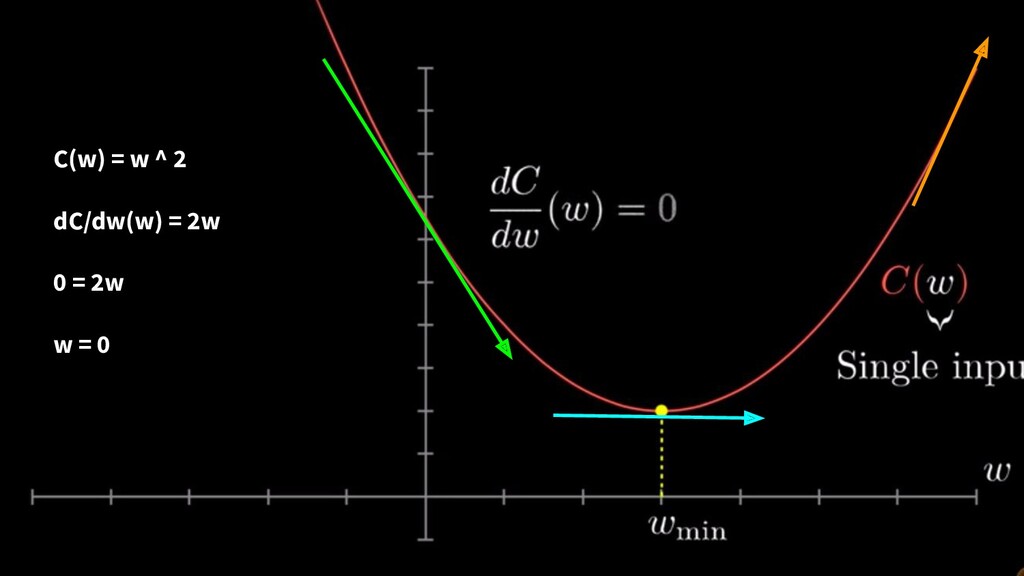
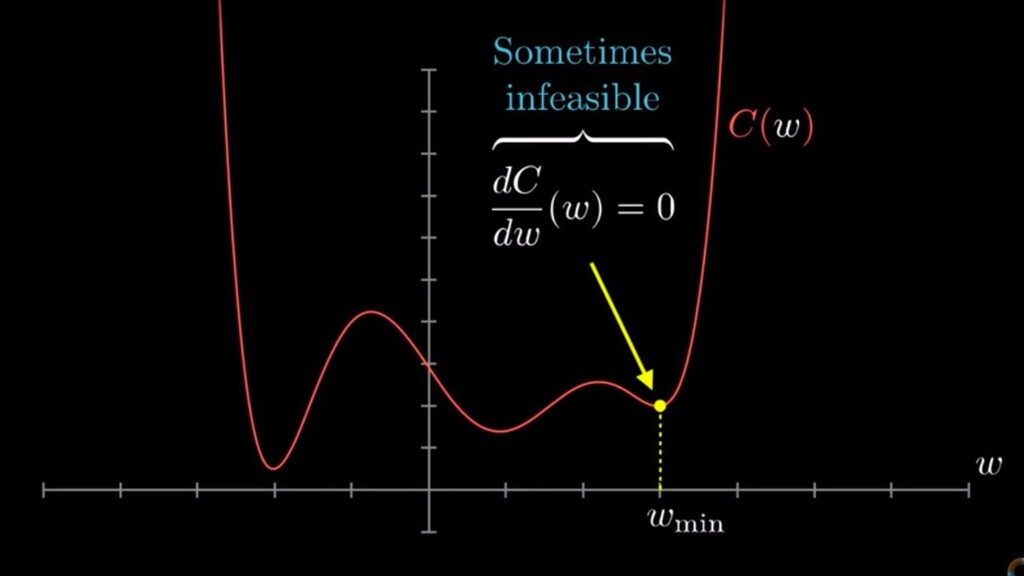
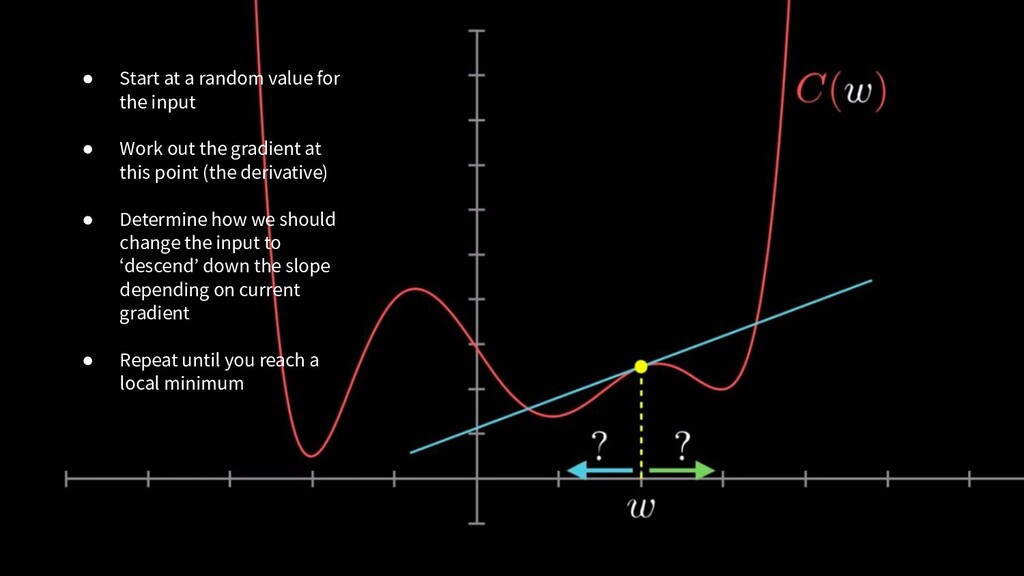
Work out the gradient at this point (the derivative) • Determine how we should change the input to ‘descend’ down the slope depending on current gradient • Repeat until you reach a local minimum
Work out the gradient at this point (the derivative) • Determine how we should change the input to ‘descend’ down the slope depending on current gradient • Repeat until you reach a local minimum
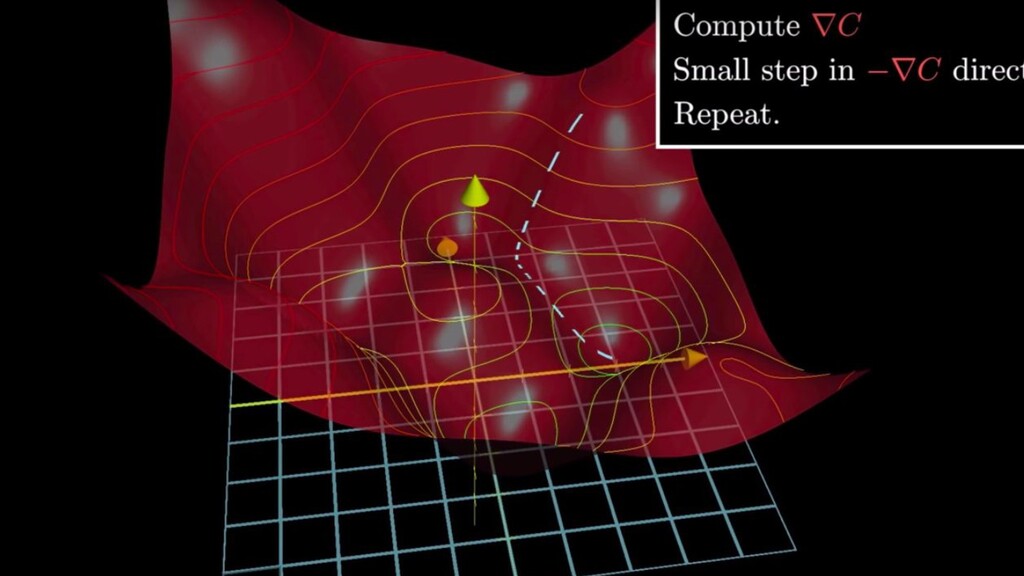
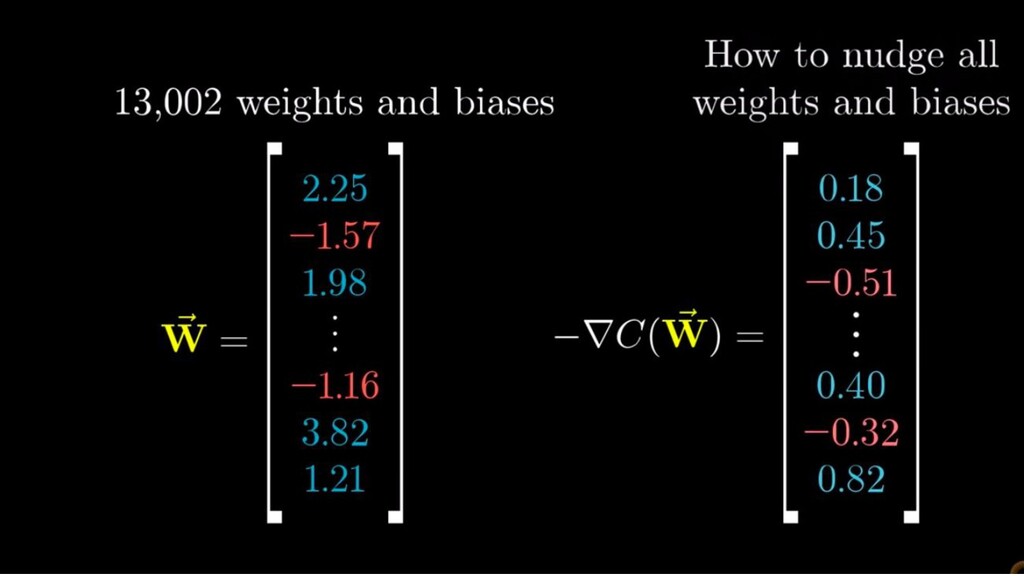
function • We have the gradient of C for the current inputs - some shiny maths (vector of partial derivatives of C for each variable in the system). • Use gradient descent to work out the change we want to make to each variable’s current value - the gradient times a variable called learning rate
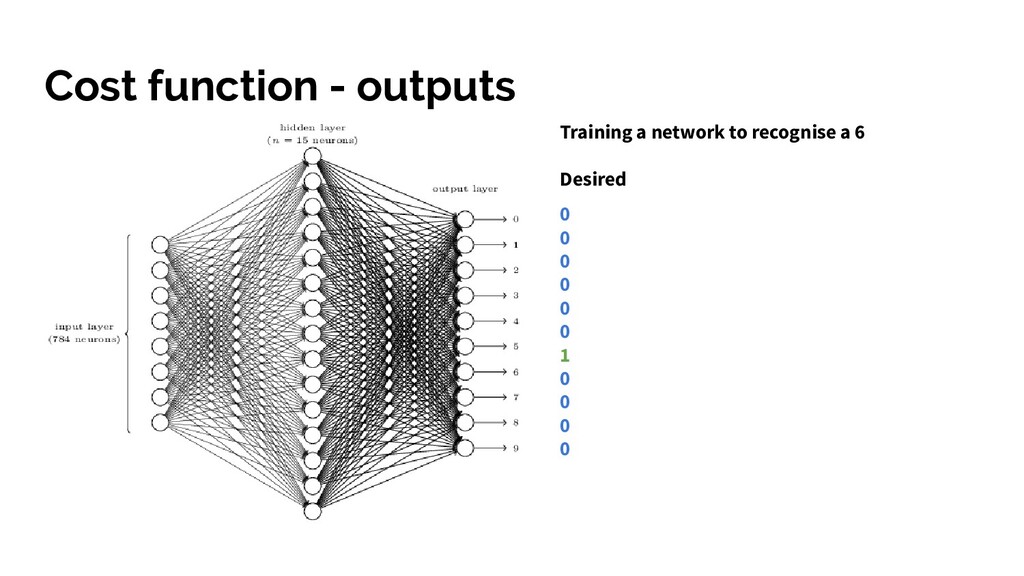
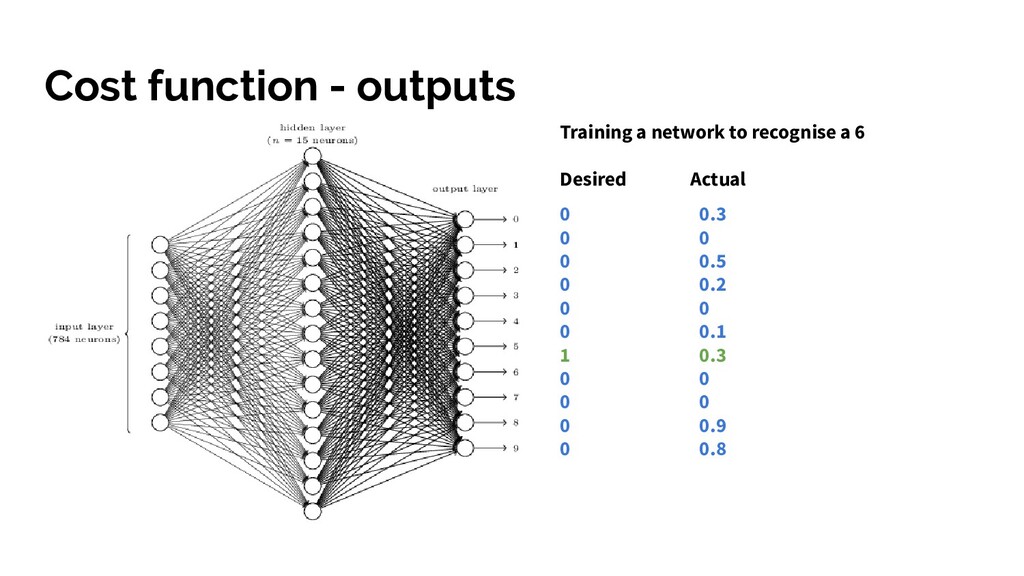
function • We have the gradient of C for the current inputs - some shiny maths (vector of partial derivatives of C for each variable in the system). • Use gradient descent to work out the change we want to make to each variable’s current value - the gradient times a variable called learning rate • Produces a list of changes/nudges for every weight and bias in the system
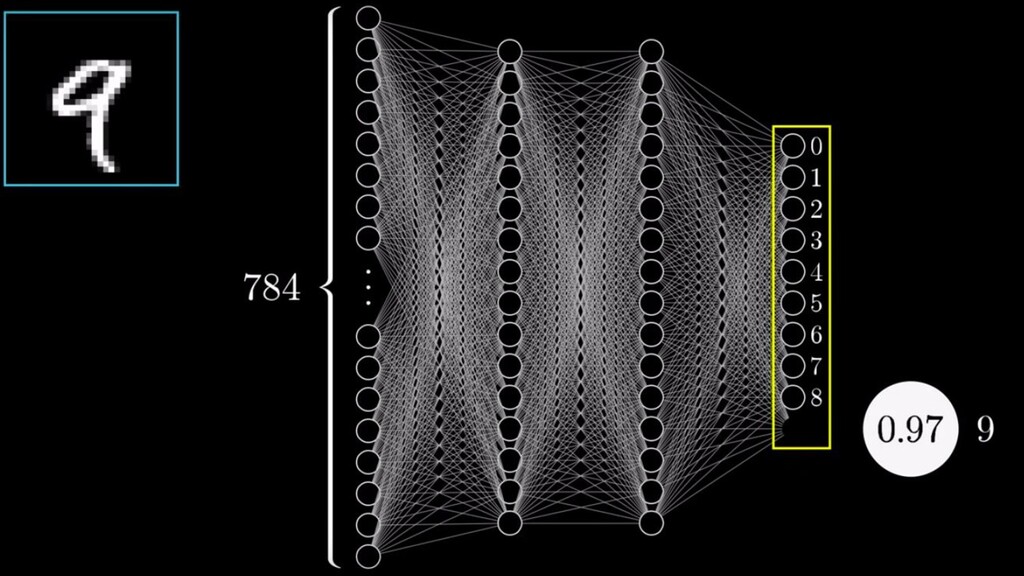
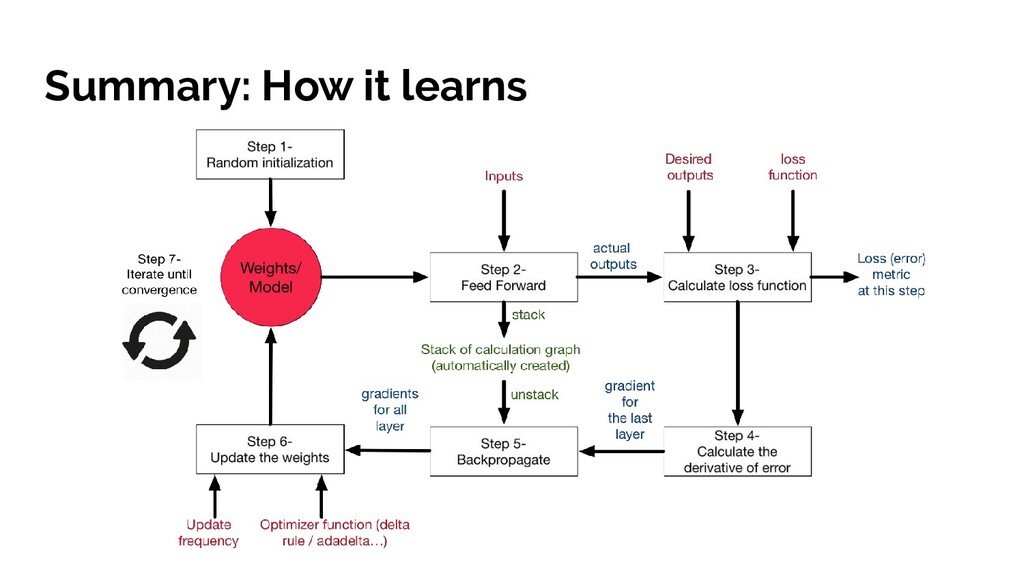
all weights and biases. • Train the network with training examples • Assess how well it did and recognising the numbers using a cost function. • Minimise the cost function during gradient descent, create list of small nudges to the current values. • Update all weights + bias for all neurons in one layer, then do the same process for every neuron in the previous layer (backpropagation) • Iterate until we get a cost function output close to 0 and test accuracy!
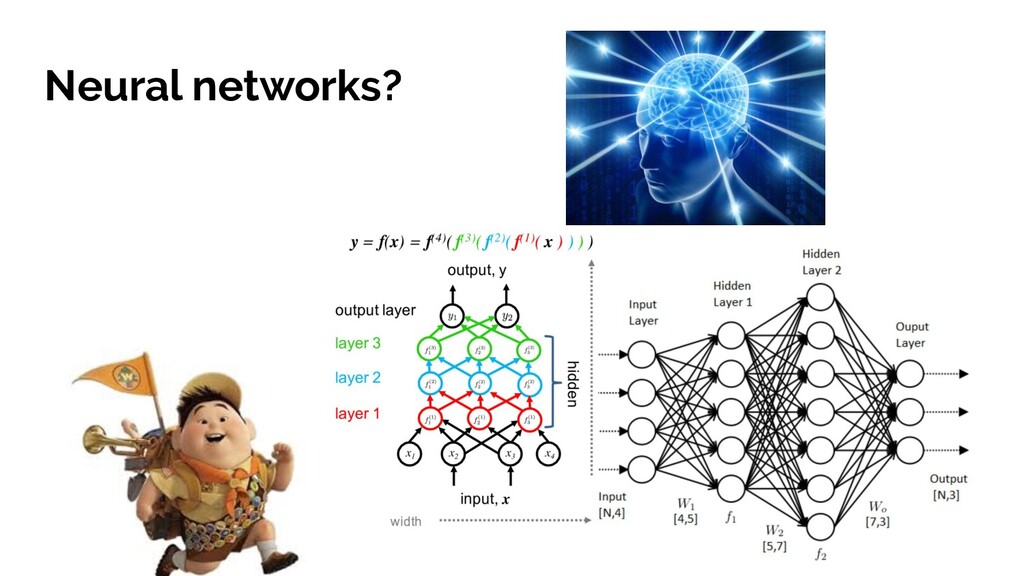
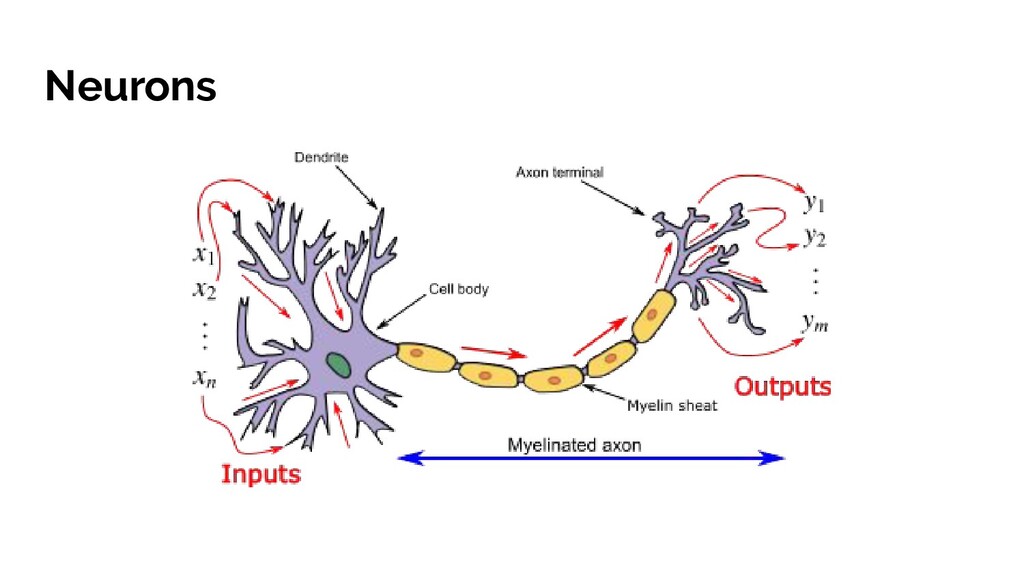
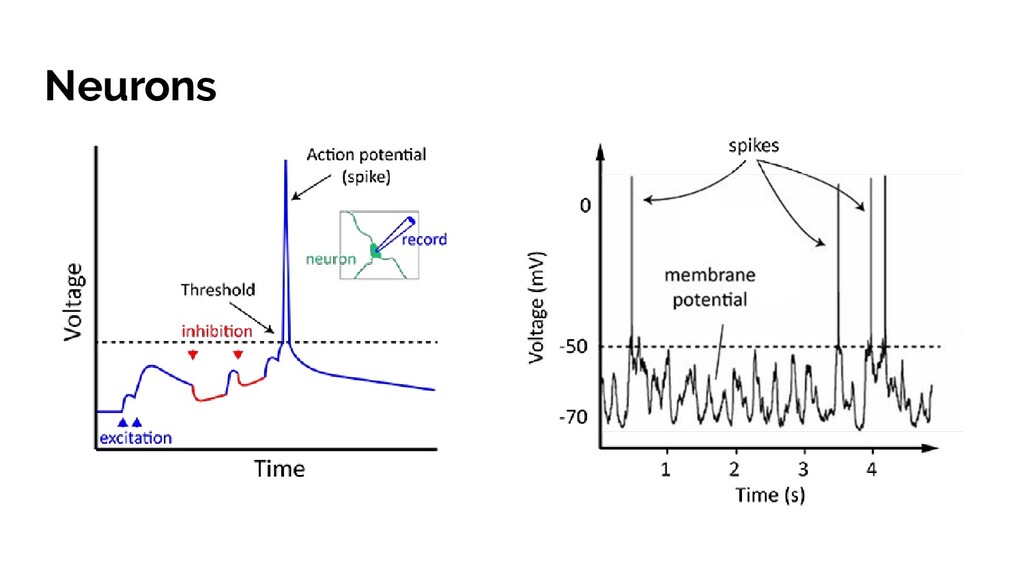
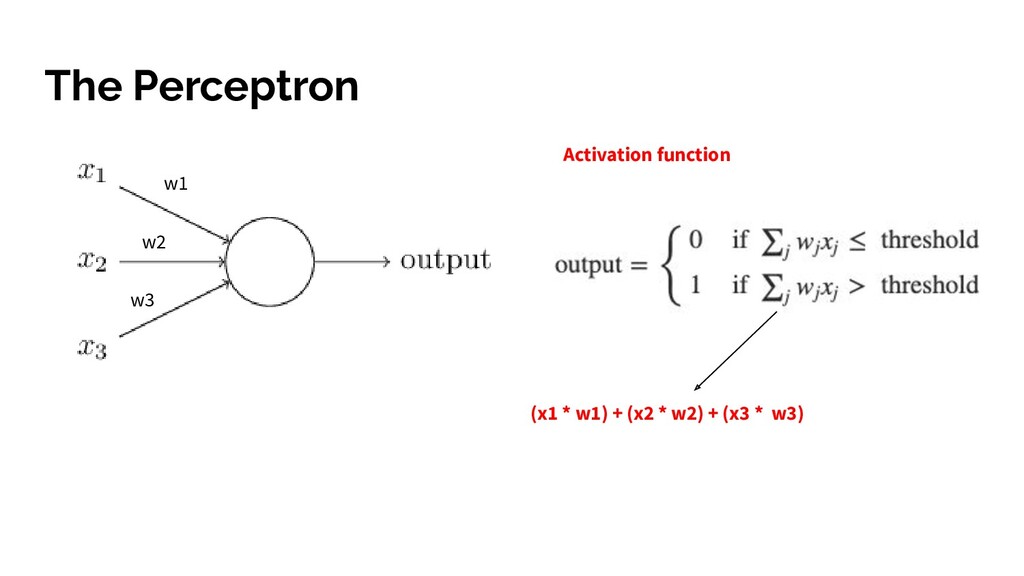
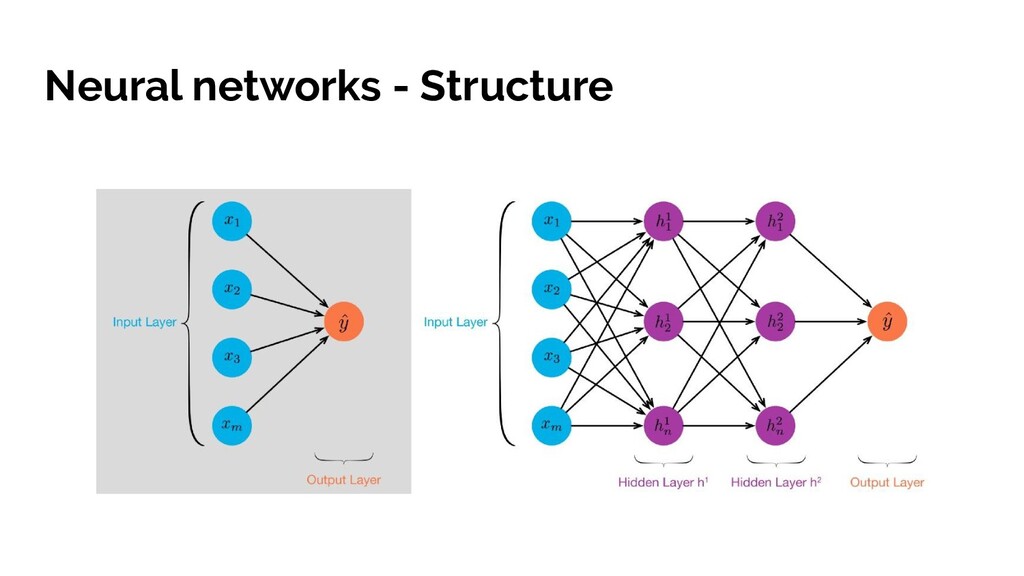
and an activation function. • Emergent, automatically inferred decision making based on tying all these neurons together into layers • Magical hidden layers of neural networks that infer decision using rules humans would not • Improving performance by minimising cost function • Using some hardcore maths to work out how adjust thousands of variables to improve an algorithm - making it learn from it mistakes! *AKA what I found cool about Neural Networks and hopefully you did too
3blue1brown (4 videos on NN, plenty of other great content) • Gradient Descent + Backpropagation https://medium.com/datathings/neural-networks-and-backpropagation-explained-in-a-simple-way-f540a3611f5e • Machine Learning failures - for art! https://www.thestrangeloop.com/2018/machine-learning-failures---for-art.html • Look at other types of NN / Machine Learning (RNN, CNN, untrained models)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}