は行われない。 • B5G時代の問題 ◦ ネットワーク資源と計算機資源の民主化により、アドホックに需給の増減が発 生し得るだろう。トポロジも変化し得る。 ◦ トポロジーの変化と規模の増大に伴い、中央集権的な情報収集と適切な割り 当て手法は変化に追従できなくなることが想定される。 Challenges of resource distribution in B5G era
Measure demand and supply of resources then allocate 'appropriately' ◦ The overall composition is fixed, no dynamic change in supply at least. • Problems in the B5G era ◦ Due to the democratisation of network and computing resources, supply and demand could change on an ad-hoc basis. Topologies can also do. ◦ As topologies change, centralised information gathering and appropriate allocation methods will not be able to keep up with the changes. in the B5G era
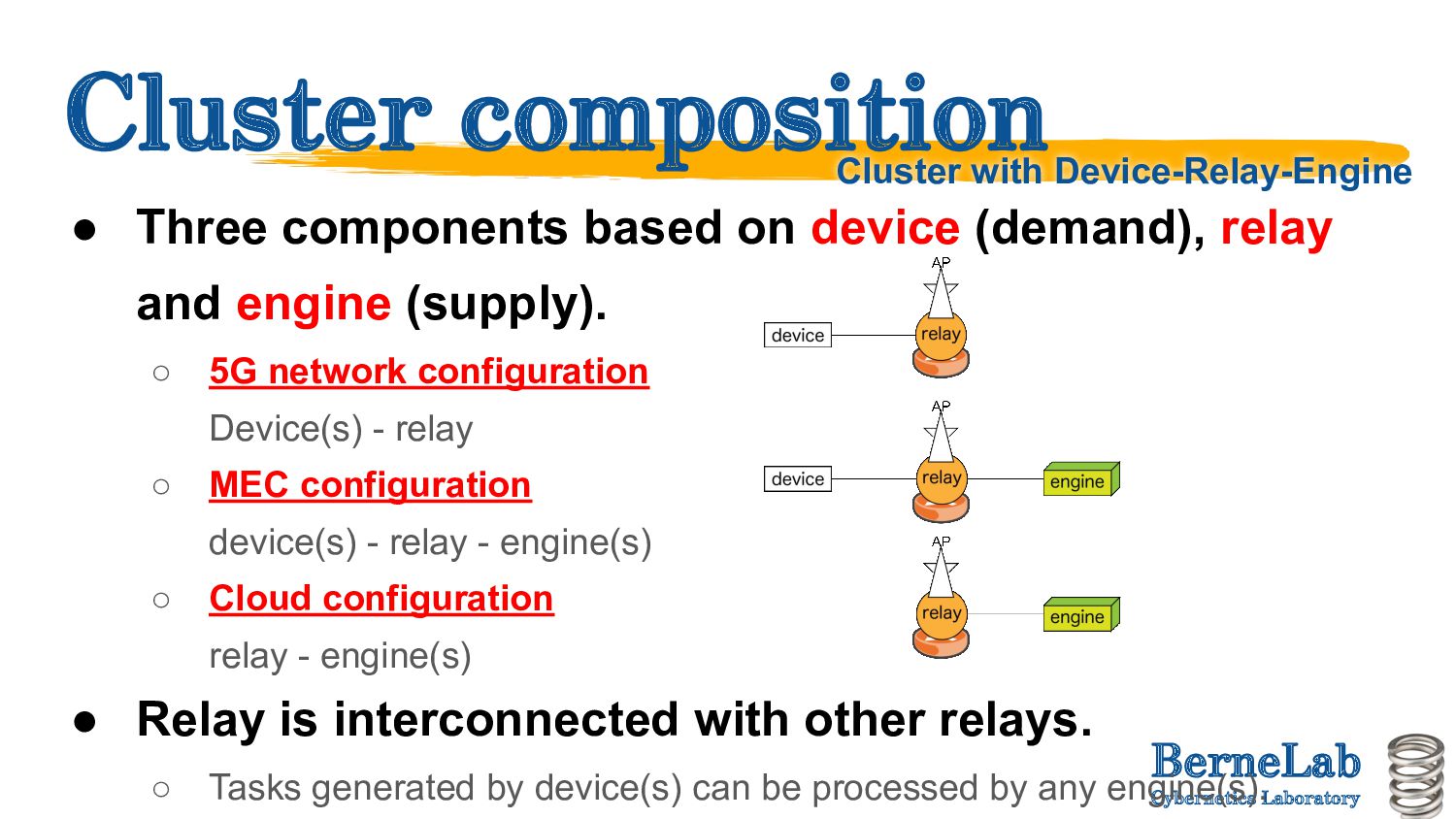
device (demand), relay and engine (supply). ◦ 5G network configuration Device(s) - relay ◦ MEC configuration device(s) - relay - engine(s) ◦ Cloud configuration relay - engine(s) • Relay is interconnected with other relays. ◦ Tasks generated by device(s) can be processed by any engine(s). Cluster with Device-Relay-Engine
a centralised approach ◦ In fact, it was too hard to do it with a decentralised approach all of a sudden, and to compare the decentralised approach with the centralised approach that will be available in the future. • Fairly-Algorithm (Fa-Al) servers ◦ A 'resource allocation server' that determines the 'appropriate' allocation (supply) for a given demand for the use of computing resources. a.k.a Fa-Al server. ◦ Relay periodically collects information on the free computing resources of the engines in the cluster and provides it to the Fa-Al server.
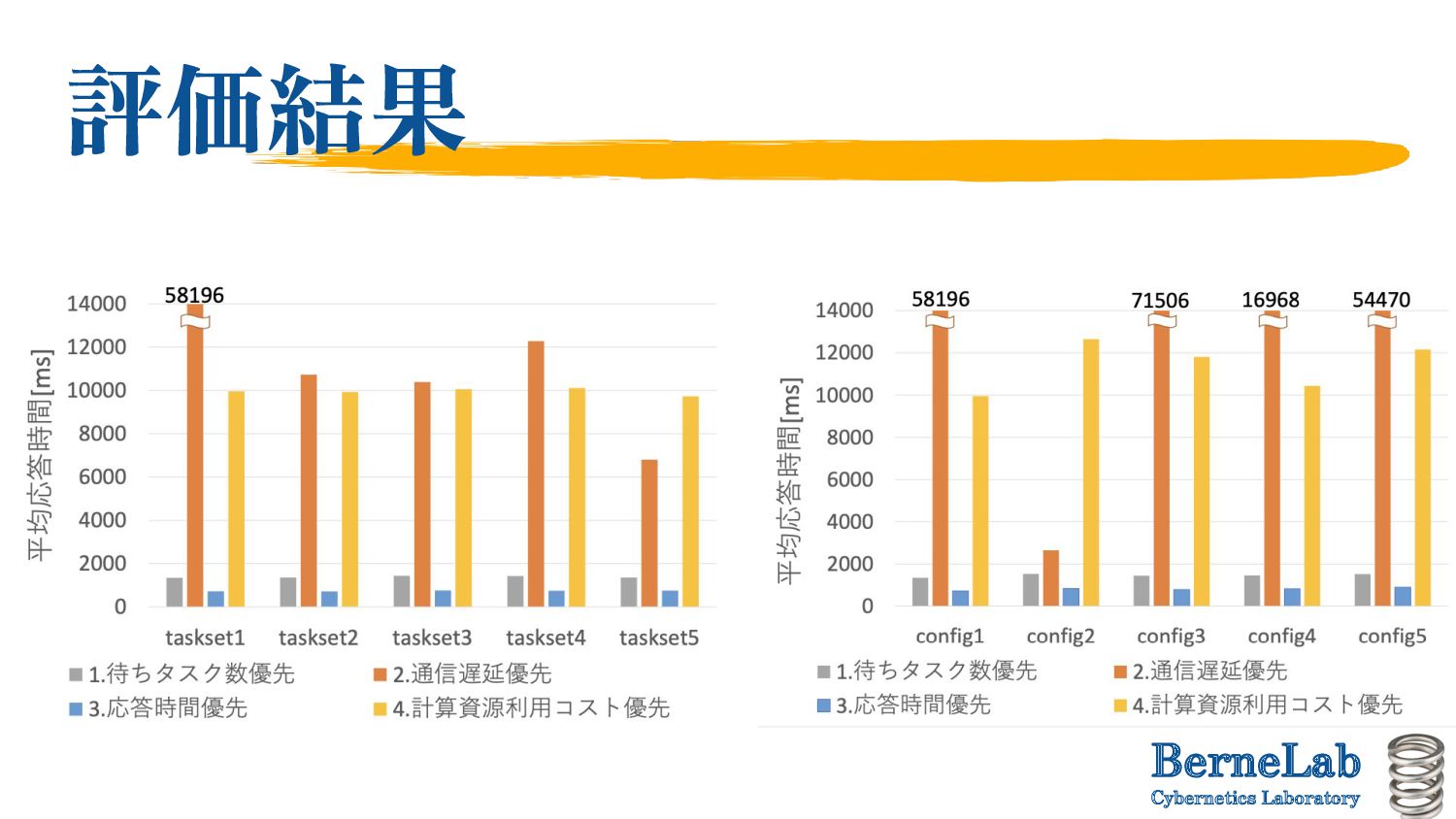
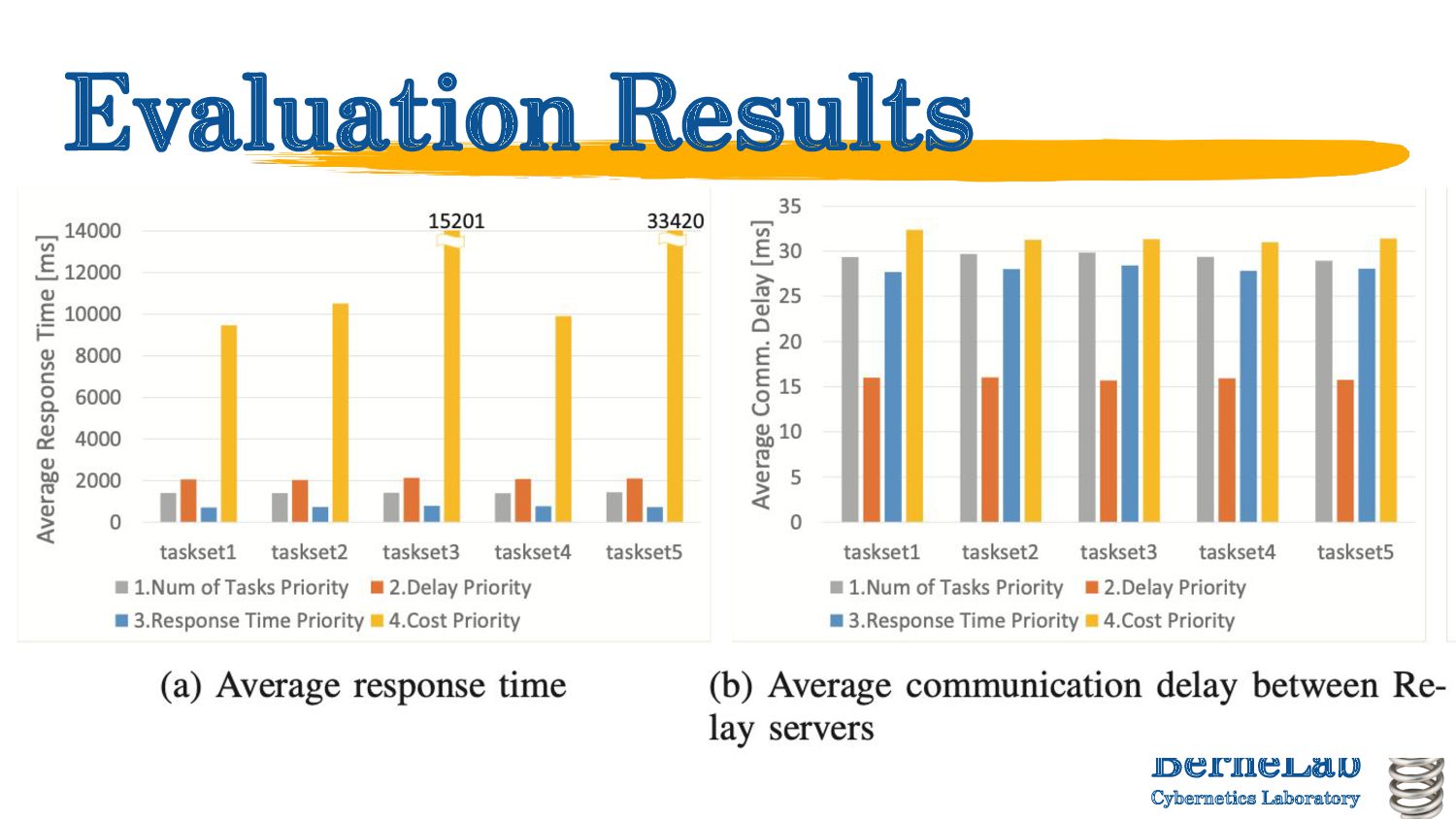
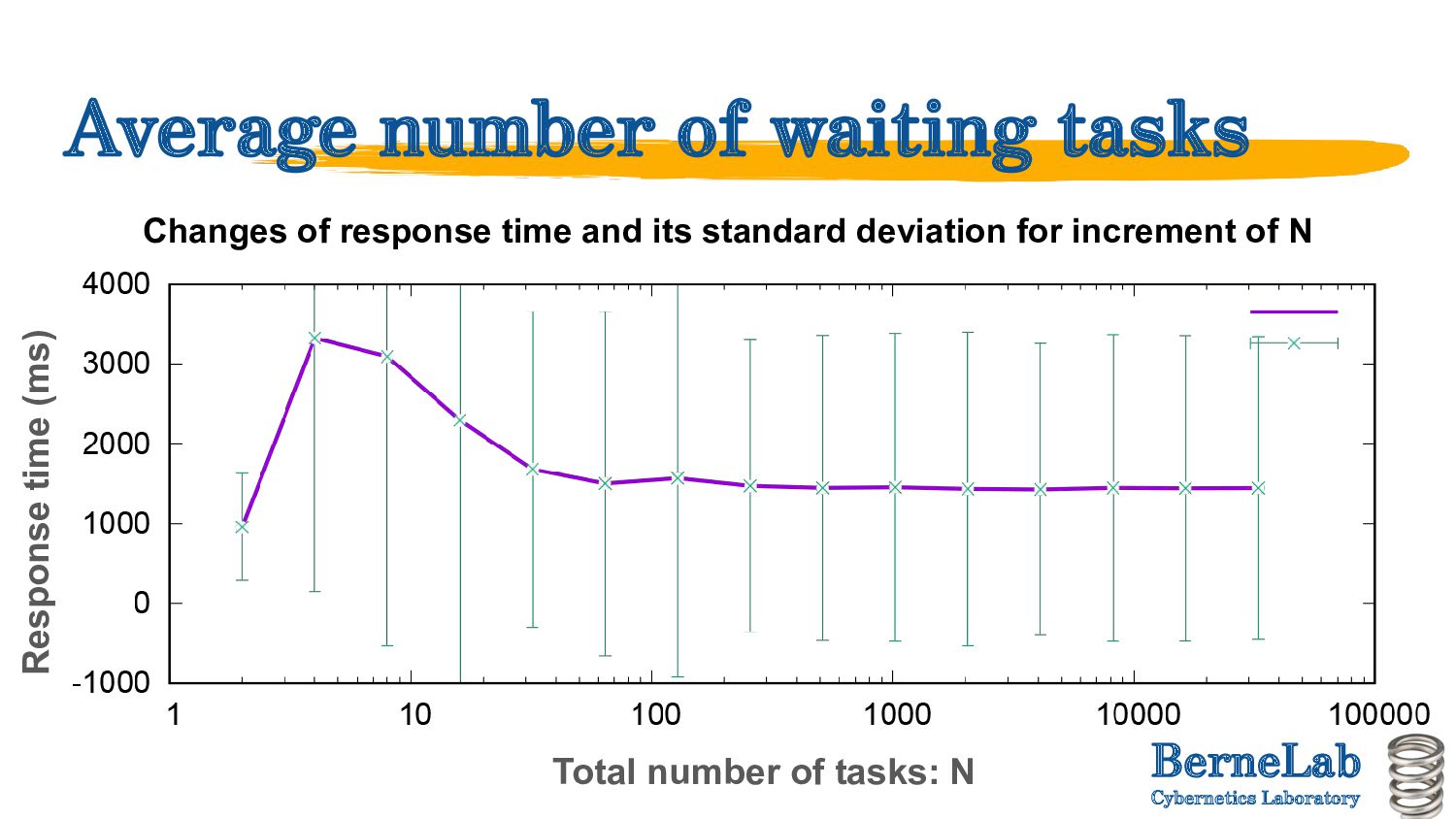
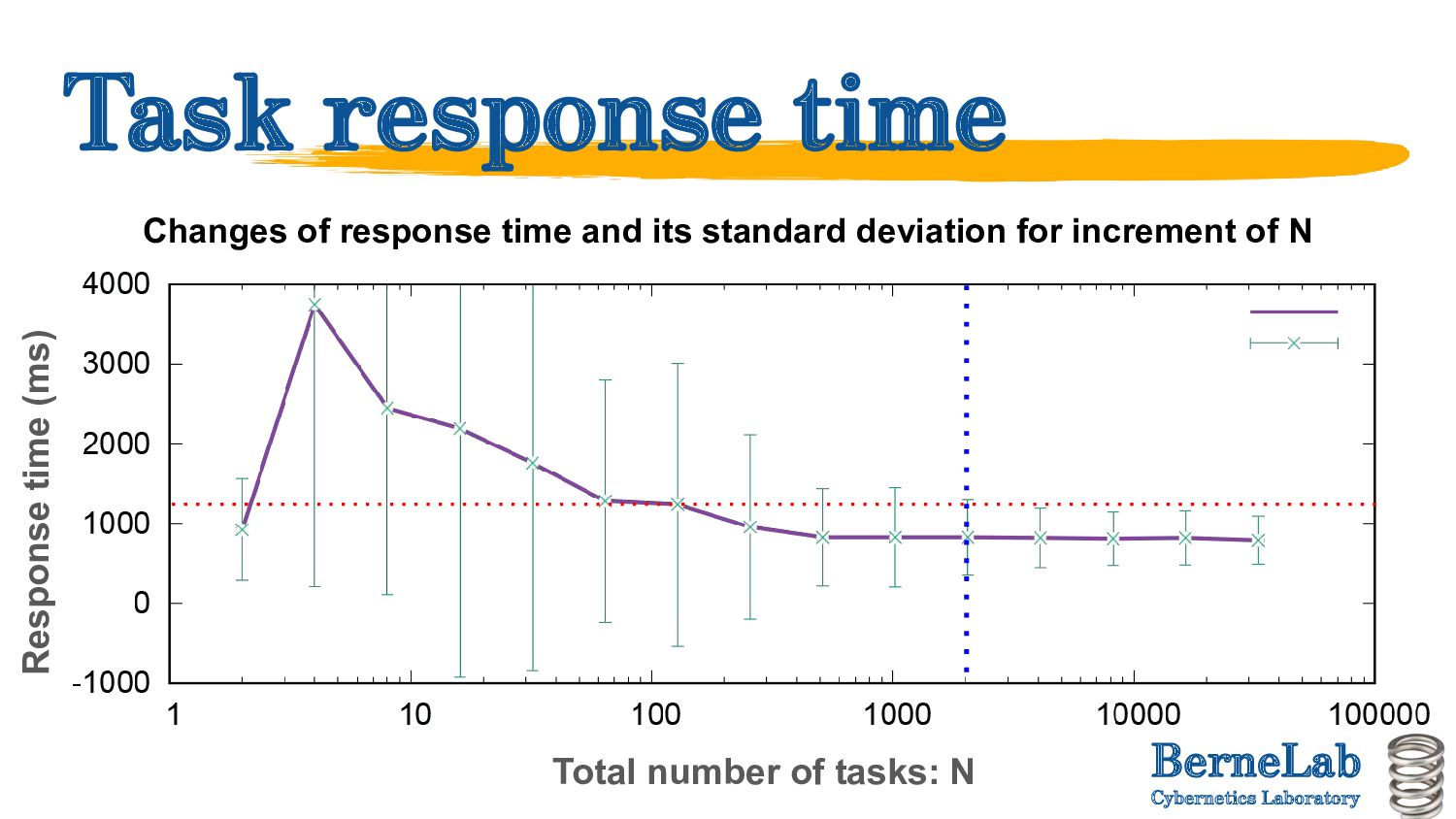
algorithms depending on the evaluation value to be prioritised. ◦ Average number of waiting tasks ◦ Communication delay ◦ Task response time ◦ Computational (resource usage) cost • Evaluation of the characteristics of each algorithm ◦ Collect the interval between task occurrences, task weight, total number of tasks, computational processing power of the engine, queue length of the engine and inter-relay delay, and make a decision. Detail explanation of Fa-Al
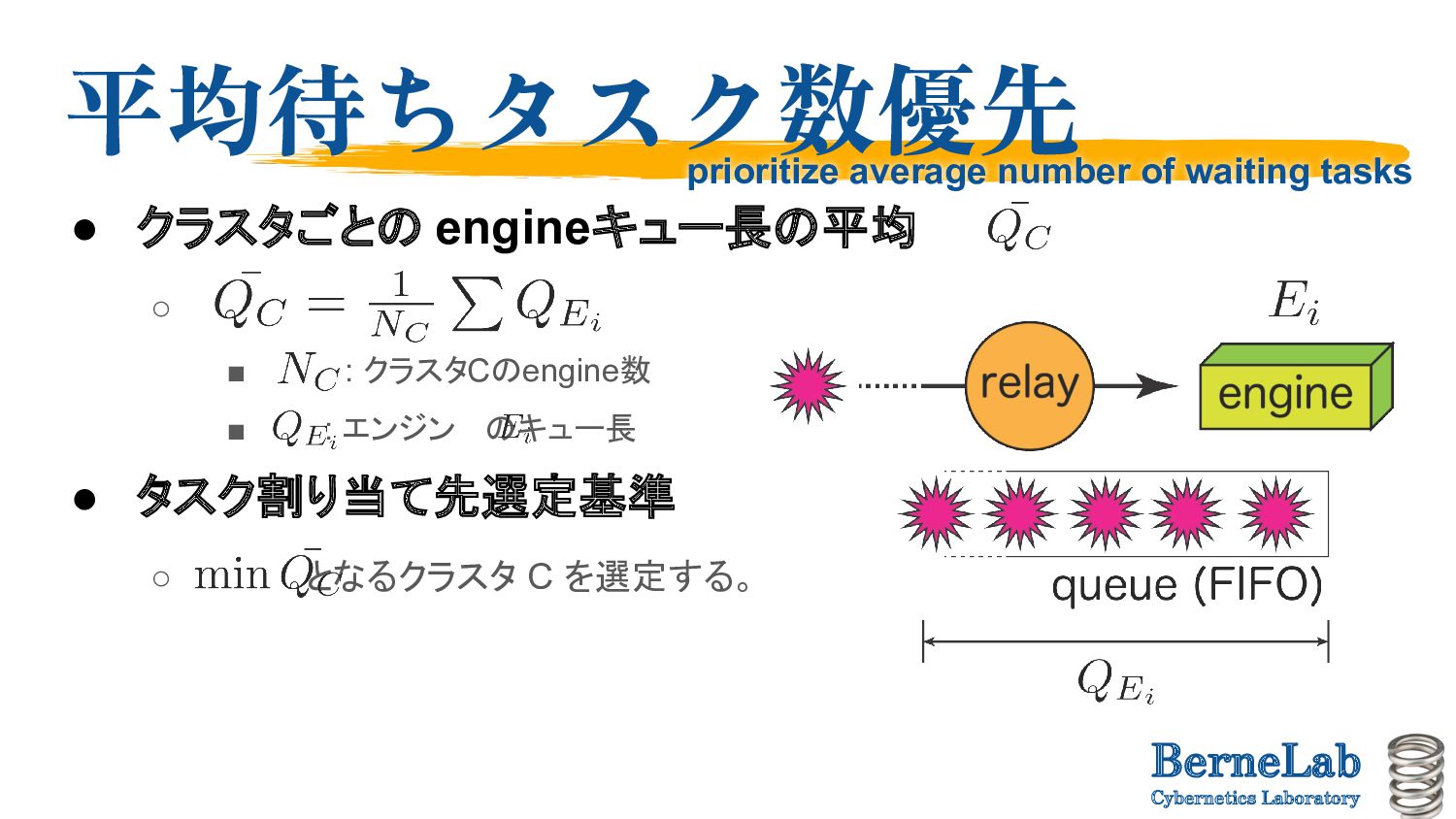
of engine queue length per cluster ◦ ▪ : Number of engines in cluster C ▪ : queue length of engine • Task allocation destination selection criteria ◦ Select cluster C to be the prioritize average number of waiting tasks
of the relay of cluster i. ◦ Define as the delay between cluster A and B. ◦ When a task is generated in the cluster i, assign the task to the cluster j that has minimum delay from the cluster i: prioritize delay
is generated in Cluster i: • When the expected execution time RTj can be calculated when the task is executed in cluster j, ◦ Assign to cluster j such that min (Δ(Ri, Rj) × 2 + RTj). prioritize tasks response time
per FLOPS processed for each engine Ei in the MEC and in the cloud. ◦ Set the price by a function that becomes more expensive according to processing capacity. ◦ Congestion penalty P (exponential function with queue length as a variable) is given and the processing capacity F x P is set to Ci. ◦ Assign to the cluster i that satisfies min(Ci). prioritize computational resource usage cost
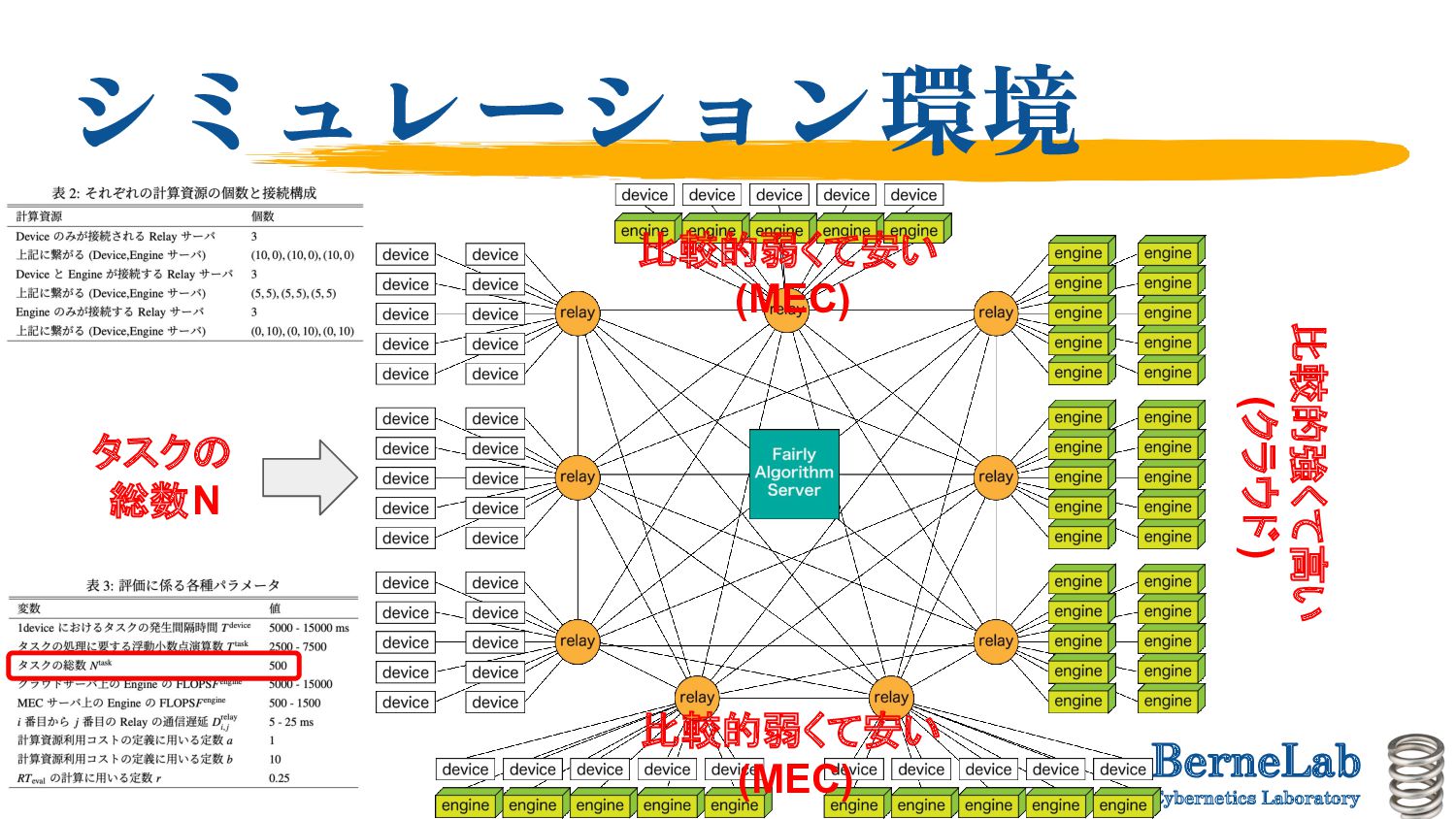
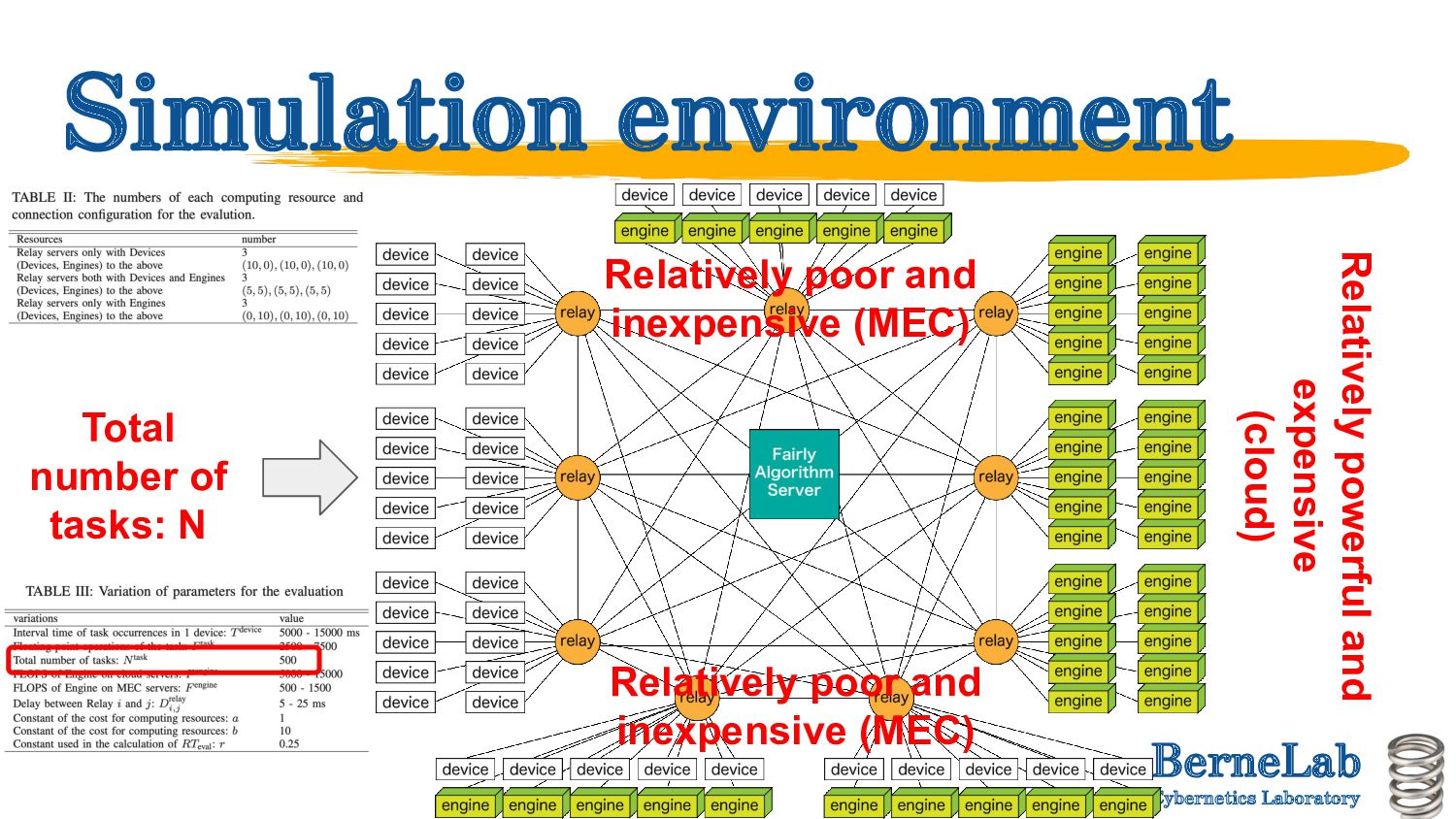
Weights are varied randomly. ◦ Time taken by one task to process: 500 ms to 1.5 sec (cloud), 1.6 to 15 sec (MEC) • More simulation in the future ◦ Vary the topology parametrically (will explain in next page). ◦ Increase the task processing time variance (so that communication delays are not negligible).
in full mesh in this evaluation ◦ If execution time of tasks is sufficiently long, communication delay can be NEGLIGIBLE. ◦ Meanwhile, as the average execution time decreases, the topology becomes more susceptible. • Barabasi-Albert (BA) model. ◦ A model in which a random network → scale-free network can be continuously generated by changing the coefficients. ◦ In the modified BA model, changing the coefficients ◦ Tree → Scale-free can be generated by changing the coefficients.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}