These are the slides used as support by Quentin in our last technical workshop at Reputation VIP.
If you want to go futher, you can find the giant and awesome associated article here: http://reputationvip.io/elasticsearch-always-pays-its-debts, on our technical blog.
{kind=link}
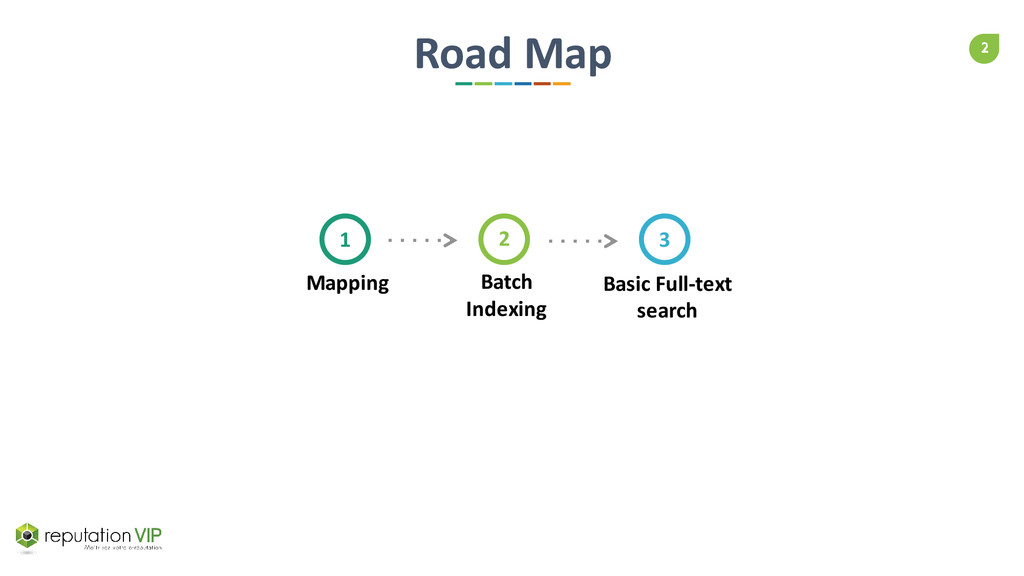{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}