in Java • Building Microservices • Continuous Delivery, CC2E • How Google Tests Software • AWS Whitepapers ◦ AWS Well-Architected Framework ◦ Architecting for the Cloud: AWS Best Practices ◦ ... 30
Administration • 系統管理工程師:他們很神秘,和公司內的體制與整個行業也格格不入 • IT 行業大多自我封閉,交流甚少 ◦ 整個軟體產業都在鼓吹厚顏無恥的 “Just show me the code” ◦ ZYX as Code, ABC as an Service • 這本書沒有萬靈丹,沒有什麼東西能解決一切的。 • 不斷自省 33
features and see them adopted by users. • 維運部門:一但在 Production 正常運作,就不要進行任何變動 ◦ the ops teams want to make sure the service doesn’t break while they are holding the pager. Because most outages are caused by some kind of change—a new configuration, a new feature launch, or a new type of user traffic—the two teams’ goals are fundamentally in tension Dev & Ops 想要的 46
responsible for the availability, latency, performance, e ciency, change management, monitoring, emergency response, and capacity planning of their service(s) 此方法論也規範了如何與產品研發部門、測試部門、終端用戶進行有效溝通。 51
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
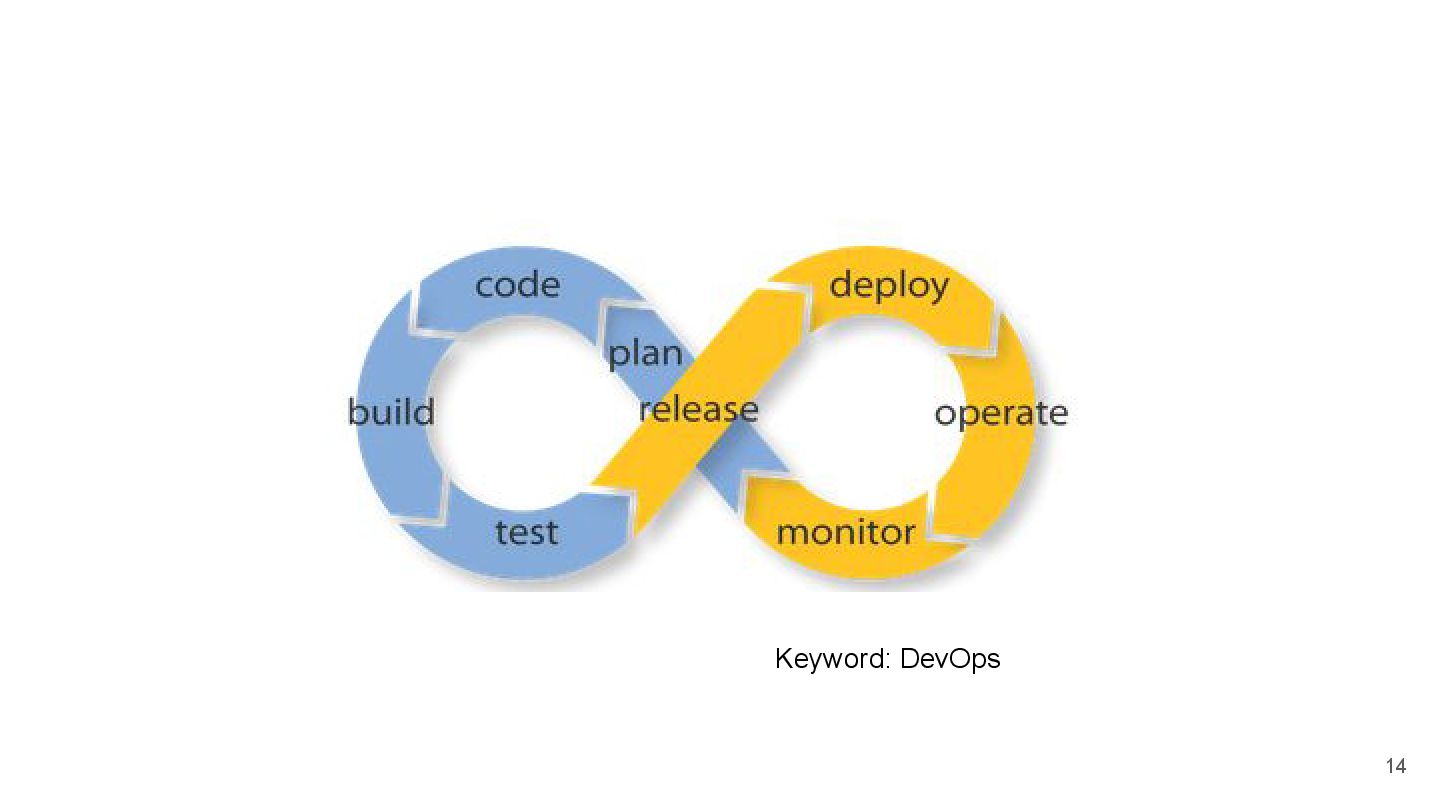{kind=link}
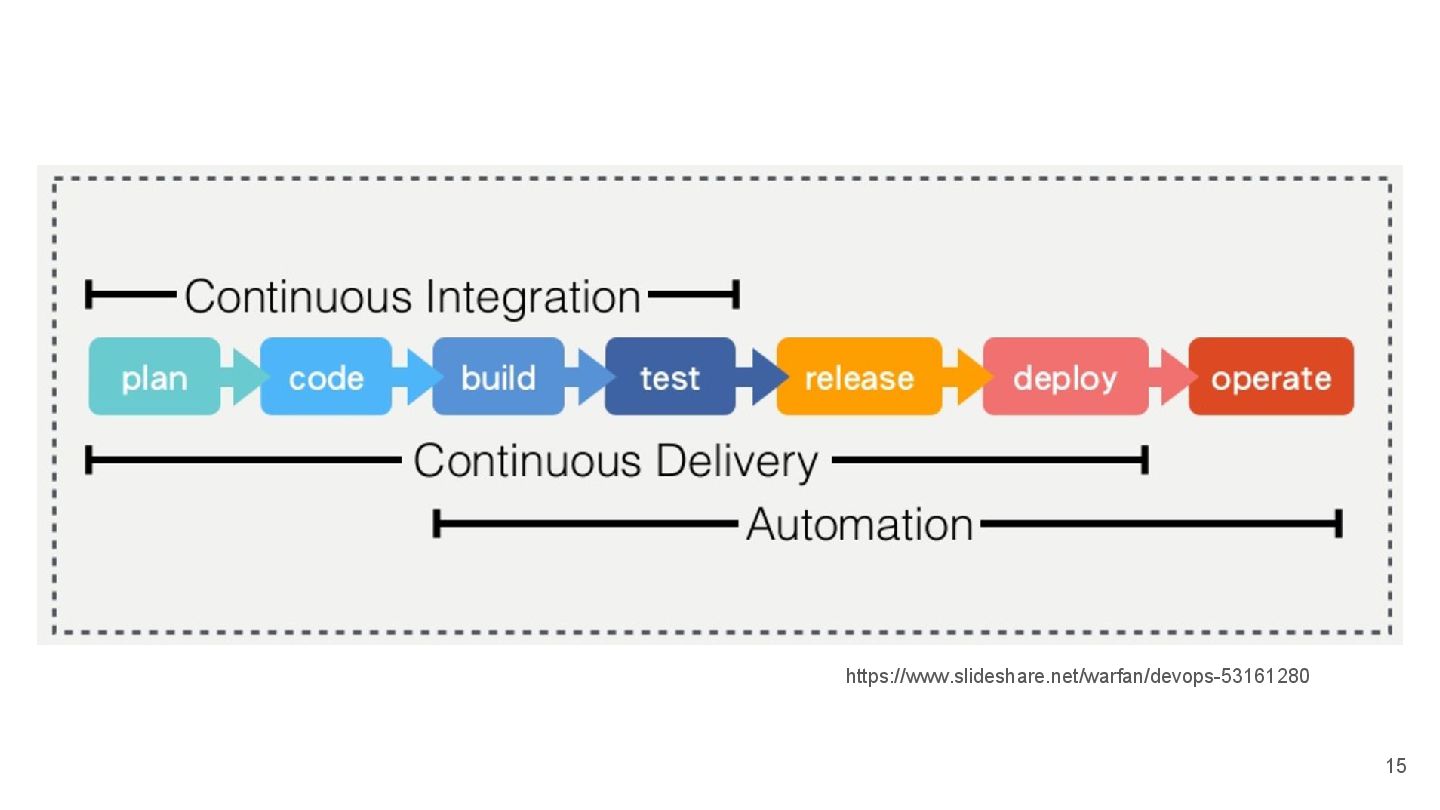{kind=link}
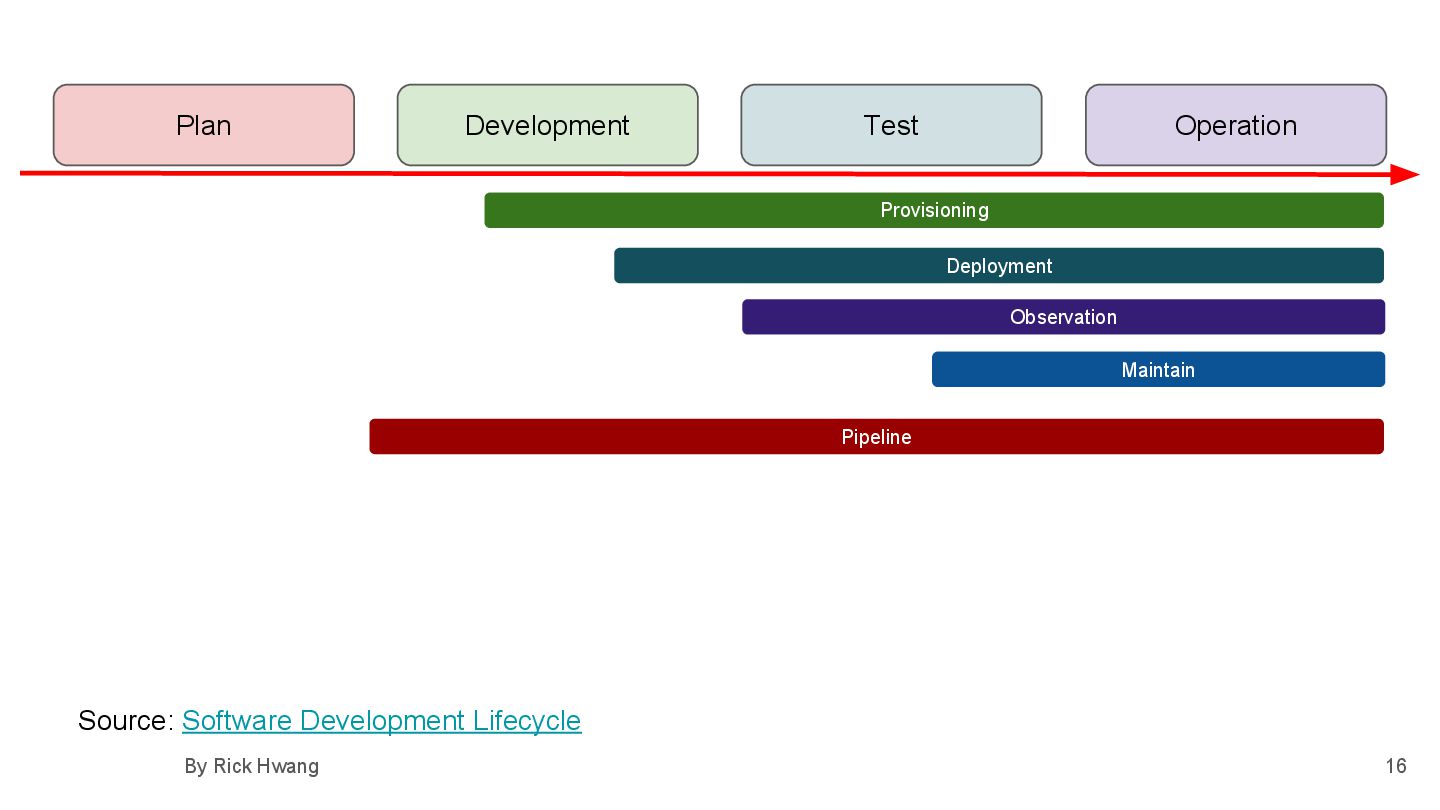{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
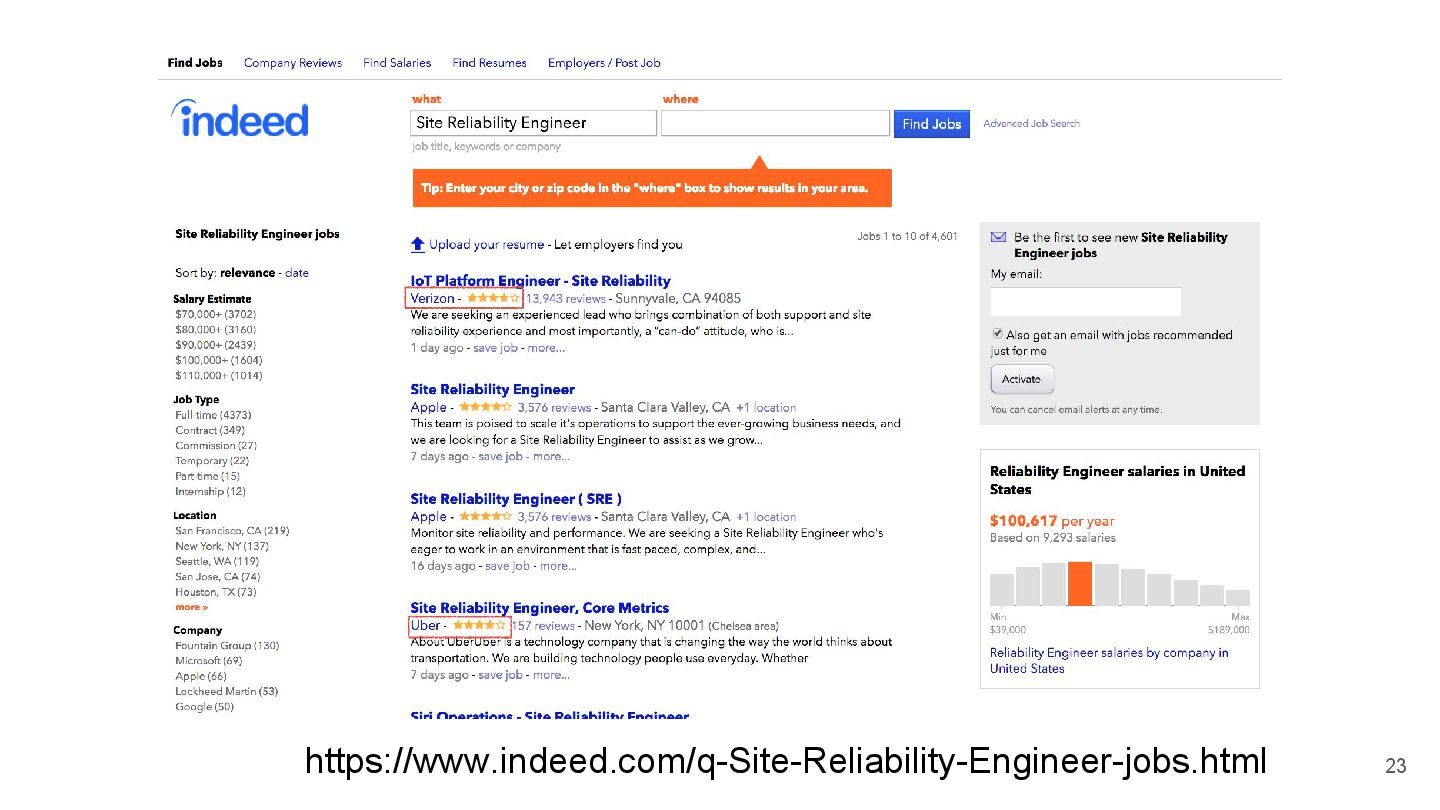{kind=link}
{kind=link}
{kind=link}
{kind=link}
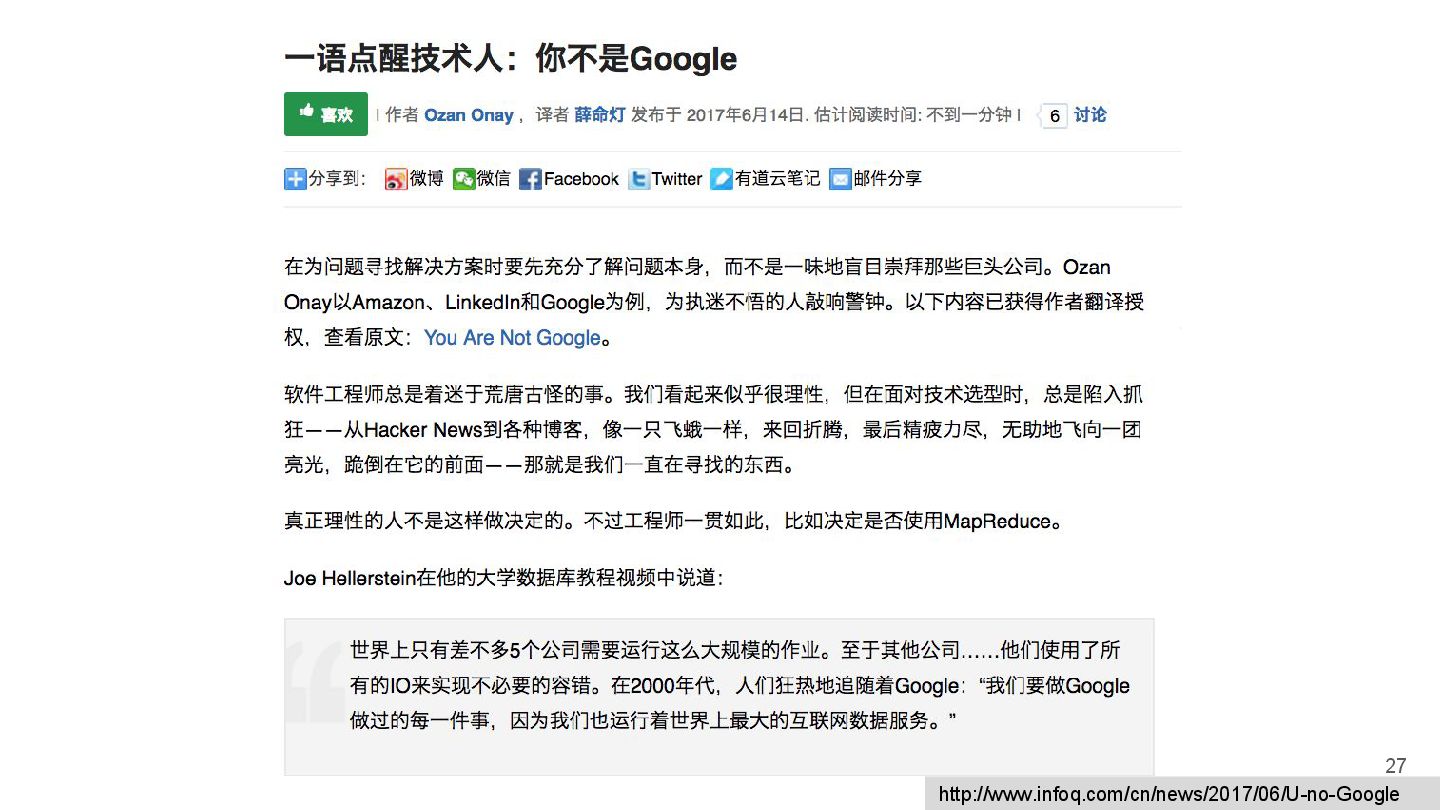{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
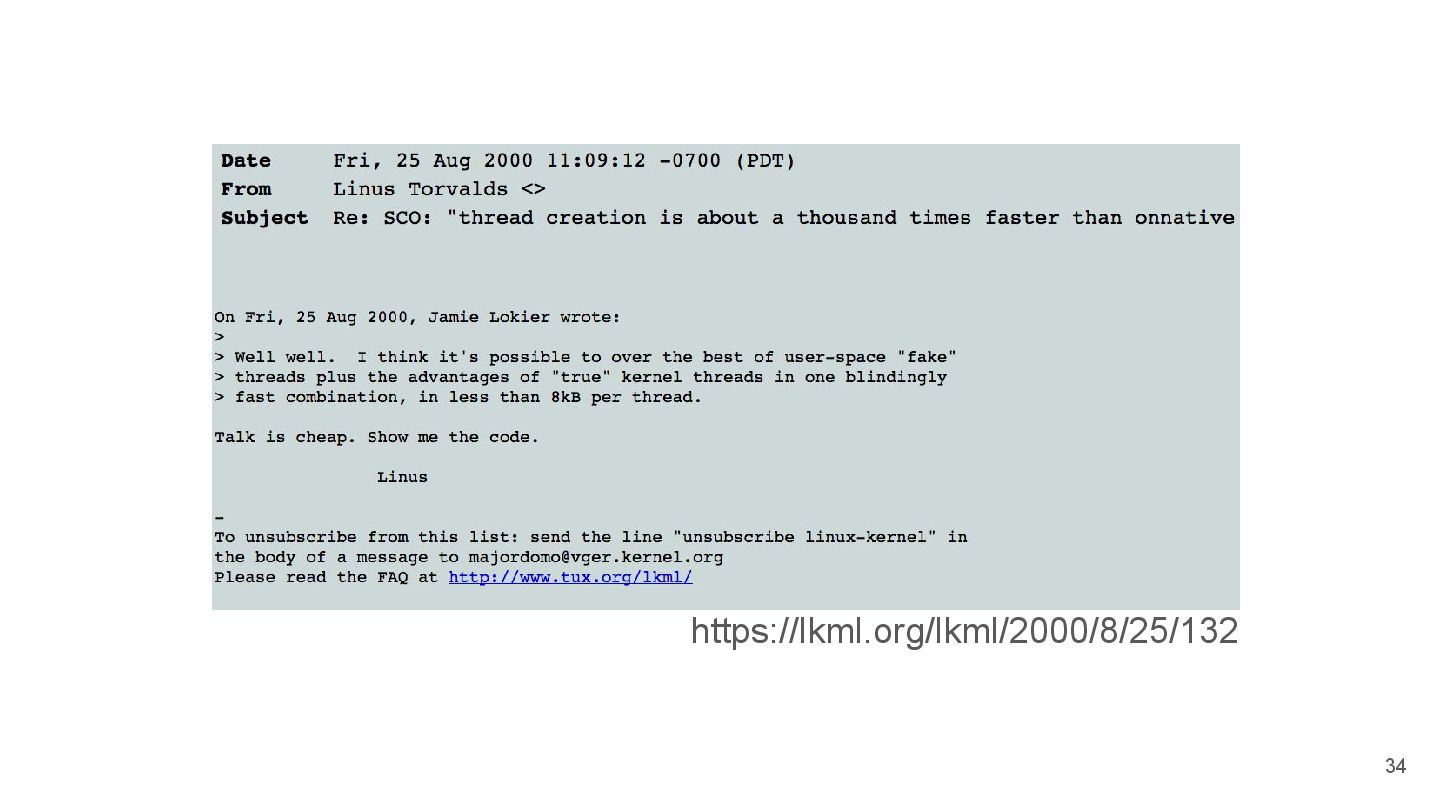{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
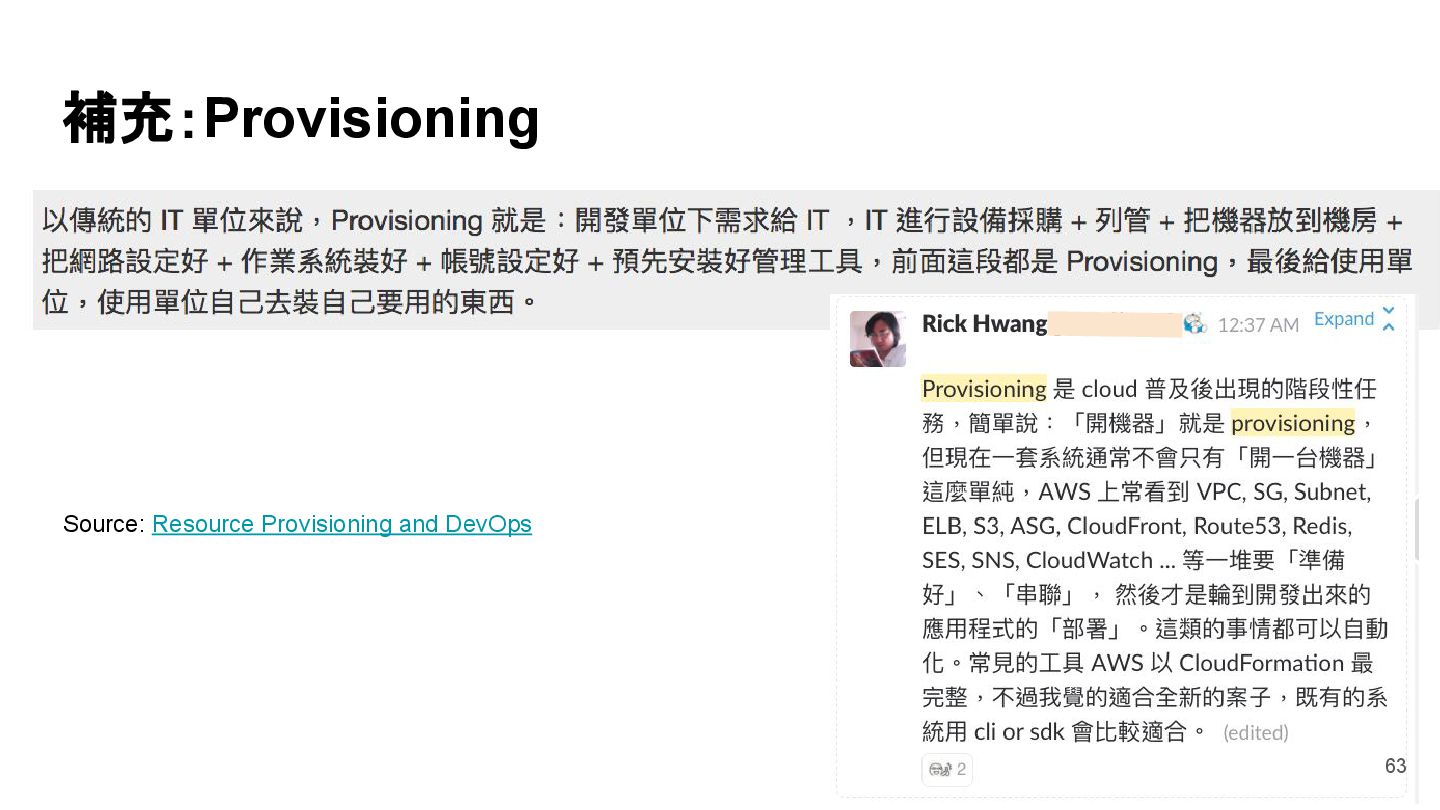{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}