Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
カーネル法まとめ
Search
Ringa_hyj
August 26, 2020
Science
620
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
カーネル法まとめ
まだ仮
Ringa_hyj
August 26, 2020
More Decks by Ringa_hyj
See All by Ringa_hyj
DVCによるデータバージョン管理
ringa_hyj
0
410
deeplakeによる大規模データのバージョン管理と深層学習フレームワークとの接続
ringa_hyj
0
120
Hydraを使った設定ファイル管理とoptunaプラグインでのパラメータ探索
ringa_hyj
0
240
ClearMLで行うAIプロジェクトの管理(レポート,最適化,再現,デプロイ,オーケストレーション)
ringa_hyj
0
260
Catching up with the tidymodels.[Japan.R 2021 LT]
ringa_hyj
3
880
多次元尺度法MDS
ringa_hyj
0
420
因子分析(仮)
ringa_hyj
0
210
階層、非階層クラスタリング
ringa_hyj
0
160
tidymodels紹介「モデリング過程料理で表現できる説」
ringa_hyj
0
690
Other Decks in Science
See All in Science
機械学習 - K近傍法 & 機械学習のお作法
trycycle
PRO
1
1.6k
データベース02: データベースの概念
trycycle
PRO
2
1.2k
Utiliser Bitcoin sans Internet
rlifchitz
0
300
20260410_SystemsThinking
takusamar
1
120
水耕栽培を始める前に知っておきたい植物の科学
grow_design_lab
0
270
ハミルトン・ヤコビ方程式の解の性質と物理的意味
enakai00
0
810
フィードフォワードニューラルネットワークを用いた記号入出力制御系に対する制御器設計 / Controller Design for Augmented Systems with Symbolic Inputs and Outputs Using Feedforward Neural Network
konakalab
0
160
HDC tutorial
michielstock
2
750
人生を変えた一冊「独学大全」のはなし / Self-study ENCYCLOPEDIA: The Book Which Change My Life #独学大全 #EM推し本
expajp
0
180
Wet Active Matter
rajeshrinet
0
120
機械学習 - 授業概要
trycycle
PRO
0
560
Tensor Factorization Meets Deformed Information Geometry: Convex Relaxation under Deformed Algebra
gkazunii
0
110
Featured
See All Featured
Being A Developer After 40
akosma
91
590k
エンジニアに許された特別な時間の終わり
watany
108
250k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Chasing Engaging Ingredients in Design
codingconduct
0
240
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
Six Lessons from altMBA
skipperchong
29
4.3k
Transcript
カーネル法 (仮)
カーネル法は1990年代から カーネル密度推定などの「カーネル」とは別 正定値性のカーネルという意味がカーネル法 1900年から正定値カーネルが研究され始め、1907年に再生性が示された パターン認識への応用は1964年ごろから
古典的なパターン認識では、 逆行列や固有値などの線形代数的アプローチから線形回帰、最小二乗法、主成分分析を行った カーネル法では特徴量の次元を莫大に増やすので古典的なアプローチでは計算爆発が起こる (200次元を3次モーメントまで作るなら・・・) 3次モーメント = 特徴量のうち3つを選択して掛け合わせる 200C1 + 200C2
+ 200C3 = 1333500次元 しかし、カーネル法はデータ側を非線形変換することで線形モデルが使える強力な手法なので なんとかしてでも使いたい そこで計算爆発を抑えるカーネルトリックが考えられ、 カーネルトリックのための制約を持った変換関数が正定値カーネルである
円形データを x2 x2 √2xxで変換すると、分離面ができる U字型のxy関係はxを2乗すると線形モデルで回帰できる データを非線形にすることで、非線形特徴(高次モーメント)が表現されることで 関係性をとらえた特徴量が作られる。 故に線形モデルでとらえられるようになる。 しかし、その変換方法が経験的であったり、 高次元のデータでは視覚化が困難で変換の糸口を見つけるのが難しい
(だから経験的にうまくいく多項式カーネルや、無限次元のガウスカーネルが良く使われる) もちろん正定値性を満たすカーネルを考えて自作・アレンジしてもOK
線形K 1 ⅈ, = 1 , 1 … 1 ,
… … , 1 … , 0 , = , = exp , = exp − − 2 22 , = exp − − , = + グラム行列 指数K ガウスRBFK ラプラスK 多項式K
カーネル法
SVMで広く知られるようになった 昔からあった 非線形データに非線形モデルを当てはめたいという気持ちからきている ただし非線形モデルは最適化も複雑 そこで単純な線形モデルで非線形データに当てはめたいという型破りの発想 さらに計算しやすくするために、手法側に問題を合わせる
関数解析の核関数がカーネル関数の由来である 複雑なデータA,Bに実数値関数(カーネル関数)を当てはめる データを数値の世界に飛ばして処理する カーネル法はカーネル関数の関わる手法すべてのこと
関数推定 原点を通る線形モデル = = =1 Wの推定は関数と実測値のズレを損失関数として設定する , ; =
− 2 = =1 , ; = − − R(W)は二次式であり、Wに対して微分して0になるときが最小 行列で表すなら ⅆ ⅆ = 2 − = 0 = −1 式を見るとわかるが行列計算で求めるなら逆行列がなければ計算できない
カーネル関数に以下を選ぶとする , ′ = exp − − ′ 2 2
= =1 2 このカーネルではx-x’=0のとき値が最大となる 直感的にはxに対してx’がどれだけ近い値の大きさを持っているかを表す βはハイパーパラメータ
カーネル関数部分は あるxにたいしてxjがどれだけ近い値なのかを計算する 近さに変換 というよりも、特徴量を合成してxを別物にしているイメージ αjは重み(係数) カーネル部分のx一方を固定せず、全データの組み合わせを考える この計算で得られる行列をKと置く。 この二乗誤差を考える。 Kが行列として正則ならば、以下で重みが求まる =
=1 , = , ⅈ = − − = −1
カーネルの中身は絶対値で符号が無くなっている 計算された行列Kを見てみると、対象行列になっていることから、転置したものも等しい ′, = , ′ = よって係数αの計算は = −1
2 −1 = −1 = 単純な計算によって求められることが分かった この計算で求められるのは無限次元多項式に等しいような過学習した曲線である 外挿部分やデータ間の予測精度は悪い これは1変数をデータの行数だけの行列に増やすことによる次元の呪いである サンプル数と同じだけ自由度があるので過学習する 汎化性が欲しくなるよね
汎化性を考える 次元数は高くしたままに、汎化性を得るために正則化を使う 最小化する損失関数に正則化項を設ける 正則化項も二次関数のような凸関数であれば、「凸関数の和も凸関数になる」という性質から 微分して最小化できる(局所最適解の問題は残る) λは正則化パラメタであり0以上を設定する λが大きければ最小化するためにはαを小さくするしかないので係数αは0の線形モデルになる λが小さいとαは自由な値を取りやすく、複雑なモデルになる 上式を微分して0と置くと の計算で係数が求まる。
Inはn次元の単位行列 ただしKは正則である必要がある。 = − − + − − + = 0 = + −1
ここで見たカーネル関数のように、データを非線形変換し、 高次元に写像することを特徴抽出と呼ぶ カーネル関数による変換をΦで表現すると、 多項式であれば こうして変数xをΦ(x)という行列に変換し、モデルを計算することを考えると 変数の数(次数の数)だけの係数を使って以下のように求められる データ側で前処理しているので、これは特徴抽出したデータに線形モデルを当てはめる問題 カーネル関数で実ベクトルに変換できるなら元データは画像でも音声でも実ベクトルでなくても対応できる = 1
⋯ = , 2, ⋯ 3 = = =1
このΦによる計算を施した行列の 特徴量同士の内積を考える。 これをカーネル関数とする場合、以下のように表現できる 多項式変換した行列の内積は である , ′ = =1
′ = ′ , ′ = =1 ′
通常の多変量解析では特徴抽出したデータの係数を求めた ここで係数をαとΦで置き換えることを考える すると、特徴抽出を行ったデータの内積を計算したデータに対して係数を求めるモデルになっている = = =
テキスト
リプレゼンター定理 ←複雑な正則化項を含む式を最小化するのではなく、特徴ベクトルの内積とその係数を もとめたらおなじことだよって意味?? 正則化がλ||w||^2であれば、最適解は右のように表せる この定理は、y=wΦ(x)の wをΦによる変換(特徴ベクトル)と係数αで表現できることを証明するものである 0 = =1
係数をαとΦで表すことにする 上記のような特徴ベクトルの線形和についてΦに直交するような ξ成分を加えたWを考える ξはΦと直交するのでその積は0になり、前項のみが残る つまりξは影響しなくなるので、 wはw0の他の要素を含まない。 正則化項も ||w||^2 = ||w0||^2 + ||ξ||^2 として考えるとξ=0のとき最小値となる よって損失関数と正則項の加わった式の最小化を考えると、W=W0となる。 以上より、 Φ(xi)TΦ(x) = k(xi, x) と書き直せることより、 上式の最適解がもとまる = 0 + = = 0 + 0 + = = =1 ,
係数wと特徴ベクトルΦの内積をwΦ(x)とおいて y-wΦ(x) の最小二乗法 + 正則化項 という式をわざわざ計算しなくとも 特徴ベクトル同士Φと別の重みαで表現できるよ という定理 これが成り立つとカーネル法を使って表現できるのでカーネル法を学ぶ上で知っトク ξが直交する要素
というのは、Φ(x)で張られる空間上に内 という待遇を考えてみることである ξに依存しないことが分かるので、最適解wはΦで張られる空間上に存在する。 wについての問題をαについて解くことで自然とwも決まるような問題に変形している このような問題を双対問題という というかwとか考えなくてもよくなる。もちろん問題を変換せず元の式でといてもいいが カーネル法を使うとカーネルトリックが聞いて計算が楽。
テキスト 2 = ා =1 =1 = =
=1 , = ා =1 =1
カーネル関数として内積計算を考えてきた 内積は直交すると0、同じ方向なら大きな値を返すのでベクトルとしての類似度と考えられる 類似度の前に正定値性について紹介する カーネル関数を使うことによって得られる行列はグラム行列である カーネルによって得られたグラム行列と係数αの 二次形式が非負であるとき、そのカーネル関数を 正定値である関数 という グラム行列 xiとxjの内積<xi,xj>がi,j成分であるような行列のこと。
ා =1 =1 ≥ 0
特徴ベクトルに写像してから、その内積を計算していた。 あこれでは行数が膨大の時、計算量も膨大になる カーネルが正定値であるとわかっている時、このような複雑な計算が不要となる これをカーネルトリックと呼ぶ 正定値であるカーネルとして有名なものがガウスカーネル(RBFカーネル)や多項式カーネルである ほかにも正定値なカーネル関数は存在するが、自分で調べて。 一部のカーネル(RBFとか)では、無限次元の特徴ベクトルを使った場合と結果が等しくなるなど、 極めて複雑な計算を単純にできる可能性を秘めているのが カーネルトリックのすごいところ。 ガウスカーネルは正規分布のような形になるのでそう呼ばれる。
ガウスカーネルによって計算される行列は対象であり、正定値性を満たす。 ある正定値関数によって得られる行列が対象行列ならば、特徴行列の内積として考える 特徴ベクトルの内積は正定値である
カーネルトリックについてもうちょっと咀嚼 X=[x1,x2] X’=[x’1,x’2]とする カーネル法だと内積計算だったりするので、X=X’だったりするけど、見やすさのために分けてかく 手法1 6つの基底関数を考えて特徴ベクトルに写像してカーネル行列(グラム行列) を求めてから内積を計算する場合 回答 Φ(X) =
(X1^2,x2^2,√2 *x1x2,√2x1, √2x2,1)という特徴抽出を考える XもX’もこの変換を使って6次元のデータを二つ作る これの内積計算を行う Φ(X)TΦ(X’) を得る 手法2 カーネル関数を使う 説明のためカーネル関数に帰着させる 上記のΦ(X)TΦ(X’)は(X1^2,x2^2,√2 *x1x2,√2x1, √2x2,1) ・ (X‘1^2,x’2^2,√2 *x’1x’2,√2x’1, √2x’2,1) を計算することであり、実際に展開してから平方完成を行うと (x1x’1 + x2x’2 + 1)^2 という式になる。 n*1 + n*1 回の掛け算だけで済む 行列で計算しなくても各要素をこれで計算したら直接求められる。 K(X, X’) =(XTX’ +1)^2 と定義したらいい。
ガウスカーネルが無限次元の特徴ベクトルの内積を表現 できることの証明 正定値性を満たすことの証明 は勉強ノート参照
データ生成過程を考えた回帰 生成モデル・・・確率分布に従って値が生成する という背景があるとき これを確率分布を使ってモデル化したもの ある値が正規分布に従って生成するものとする ただしパラメータはわからないことが一般的。 まずデータが先にあり、 そのあと、データを最も生成しやすいようなモデルのパラメータを推定する必要がある 正規分布に従うことだけは知っているものとする これを考える時、ベイズの事後確率を大きくするようなパラメータをMAP推定により求める
MAP推定で、対数尤度関数に変形すると、これは正則付き二乗誤差の最小化と等しくなる 各変数が正規分布に従うとき、これを多変量正規分布でモデル化することができる。 このような生成過程を、正規過程(gaussian process)と呼ぶ 別に時系列データのtに対して適応しなくてもいい。 ガウスカーネルを使ってデータにモデルを当てはめることも多くある。
テキスト
カーネル主成分分析 変数を特徴抽出によって作り出してから主成分分析をする 二次元の変数 X=[X1,X2] Φ(X) = {Φ1(X1), Φ2(X2),Φ3(X2)} Φ1=X1 Φ2=X2^2
Φ3=X2 三次元に拡張して、主成分軸(平面)の方程式を考える a1Φ1 + a2Φ2 + a3Φ3 + a4 *1 =0 通常の主成分分析を使っても解ける これを カーネル主成分分析 と呼ぶ
主成分分析をカーネル法で書き直す 通常の主成分分析の場合はラグランジュ未定乗数λを使って最小化の式をつくる = カーネル法の考え方より、w=ΣαΦ(x)として代入する = = ⅈ, f(x)の分散、Φxが既に中心化されている時、平均は考えくていい 1
ා , 2 2 = 2 = = 1 ノルムは
纏めてラグランジュ方程式にすると = − 1 2 + − 1 ⅆ ⅆ
= − 2 2 + 2 = 0 微分して0と置いて = 以上より、以下のようにグラム行列の固有値問題にできた カーネルPCAは元の特徴量について綺麗に写像できているかは不明 拡張した特徴ベクトルの世界での分散の最大化を目的にしている 主成分分析の主成分軸(面)は線形であるため、元のデータ空間の関係性が非線形の時には カーネルPCAが有用になる(スイスロール) ただし、どのカーネル関数を選ぶかによって有用にならない時もある
トランスダクション 汎用なカーネル関数について考えるのでなく、データを直接グラム行列に変形する方法を考える方法 現在のデータがグラム行列になるように方法を考えるので、新しいデータに対応はできない。
ラプラシアン固有マップ
テキスト
カーネル判別分析 ただ漠然と列を減らすのでなく 目的変数に対して影響を大きく持つ特徴量だけに絞りたい、 という考えのもと次元削減を行うこともあるだろう 離散な目的変数があるとき、線形判別(LDA)は 離散な目的変数のグループごとのデータ集合の散らばりが小さく、 異なるグループ間の距離・散らばり が大きくなるように次元圧縮を行いたい
次元圧縮を特徴ベクトルの線形和として定義する = ばらつきの指標を 異なるクラス間分散 σ B 2 同じクラス内の分散 σ W
2 とする。 うまい具合に分けるためには、 σ B 2 /σ W 2 が最大となるような関数fを考えてやればいい これを最大にする一つの解は分母を0にすることであるので、これは制約をかける リプレゼンターの定理から、上式f(x)をカーネル関数を含んだ式で表現できるので = =1 ,
各クラスの分散をσl2とすると、データのクラス内分散は以下のように表せる クラスはCクラスあるとする 2 = 1 =1 2 あるクラス限定の分散計算のために、例えばC=1の時のデータだけ取り出して平均を求めたい =
1 ා =1 = , 以上より、クラス限定の分散は このクラスが限定された状態でのカーネル行列はK’とする 2 = 1 ා = =1 , − ′ 2 ここで、式を展開して、Slを使って表現すると
μTは 全体サンプルで計算した平均である。 2 = 1 ා =1 ′ ′
− , − = 1 ා =1 , クラス間の分散は
の最大化は、分母が1であるという制約を課した上でのラグランジュ方程式で解ける 以下まだあるけど略 σ B 2 /σ W 2
凸計画法 最小二乗法による係数推定はロバストではない なぜならば、外れ値があった際に2乗にしていることによって 大きな重みのある修正をかけられてしまうから これを 損失関数がロバストでない と呼ぶ リプレゼンターの定理によって、カーネル関数を使った計算に置き換えた カーネルトリックがあれど、データ数が増えれば計算は膨大である。 そもそも計算量を減らせないものか?
これを 結果のスパース性 と呼ぶ
SVM 離散のクラス識別について最小二乗法を見せ、 その後最小二乗法でない損失関数を使った場合を例示する
分類問題として2値の目的変数を1,-1にするとしよう 値をある関数で変形した後、 その値が0以上なら1 0以下なら-1 のクラスに分類するルールを作る この関数を識別関数と呼ぶ = = 1 f(x)>=0
-1 f(x)<0 {
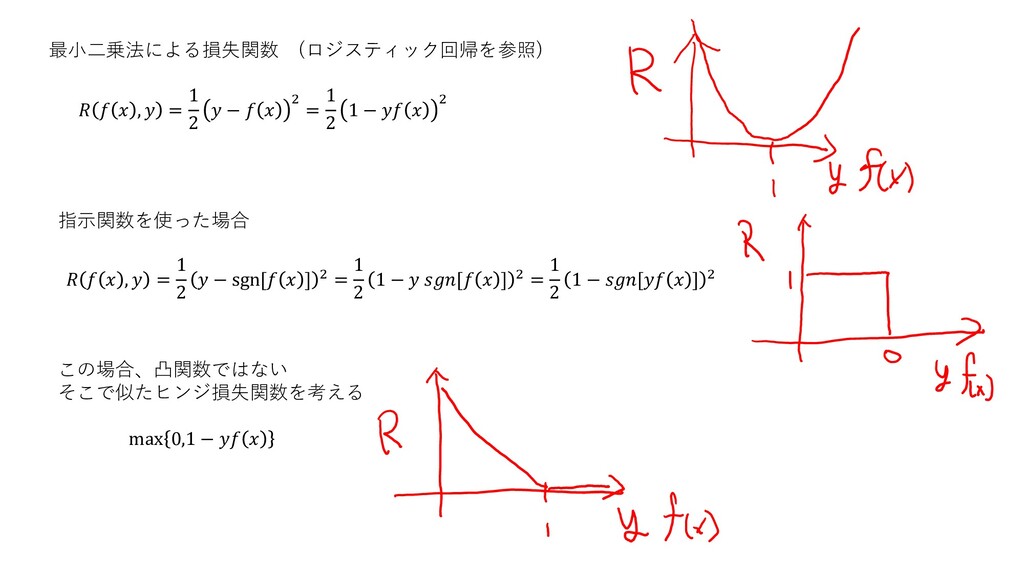
最小二乗法による損失関数 (ロジスティック回帰を参照) , = 1 2 − 2 = 1
2 1 − 2 指示関数を使った場合 , = 1 2 − sgn[ ] 2 = 1 2 1 − [ ] 2 = 1 2 1 − [ ] 2 この場合、凸関数ではない そこで似たヒンジ損失関数を考える max 0,1 −
求めるべき識別関数の損失関数は、ヒンジ損失Rhを使って 正則化項も加えた形を考えると、リプレゼンター定理より 以下のように表現することができる min ℎ + = ,
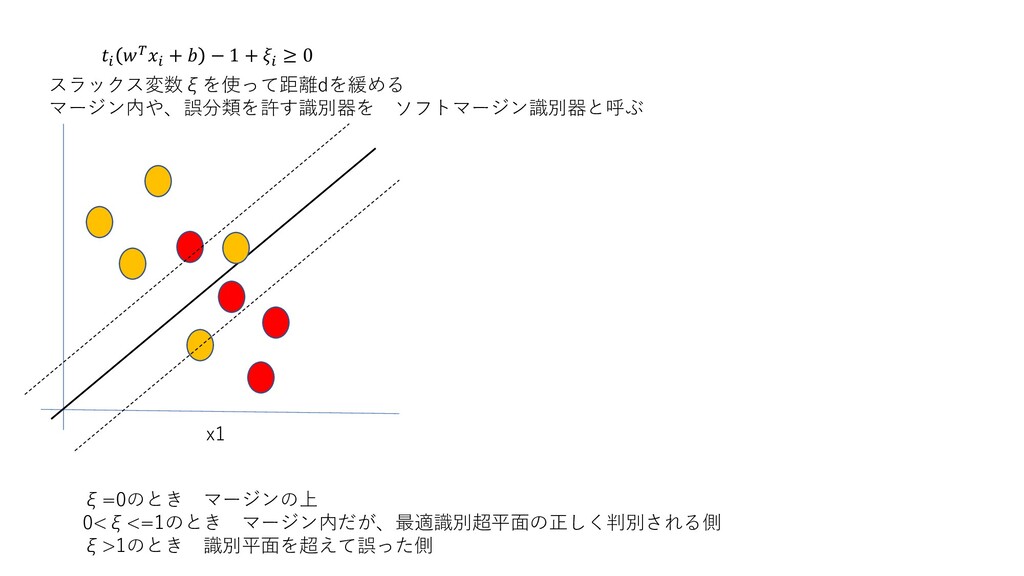
スラック変数ξを使って制約を考える ξ>=0 ≥ 1 − ⅈ ⅈ = 1 −
ⅈ 両方の制約を満たすうち、最小になるような識別関数のパラメータを求める min ℎ + min + 1 2 制約を考えて上記を書き直す これは凸二次計画問題となる
てきすと さらに制約が二つなのでラグランジュ未定乗数βとγを使う。 βγは0以上 = + 2 − −
ා − 1 +
カルーシュ・キューン・タッカー定理KKT m個の不等式制約gを考えた 関数fの最小化では、 関数f,gが微分可能な凸関数であれば、m個のラグランジュ未定乗数を使った式で最適化ができる ラグランジュでは等式の制約であったがKKTでは不等式制約も使える ≤ 0 i = 1
… min , = + fとgに関して偏微分して0と等値することで求められる
SVM 完全分離可能な場合、 教師ありの識別モデルでは過学習に陥る場合がある 2クラス間に複数の識別境界を引くことができる SVMではこの識別境界を過学習させないように、汎化性を保って学習することができる。 その概要は 入力空間を高次元の特徴量空間に飛ばすことで、線形分離の可能性を高める 高次元空間での識別超平面がどちらかのクラスに近い場合、それは過学習であるので 互いのクラスから最も離れた位置に超平面を作り、繁華性を確保する
ハードマージンサポートベクトルマシン wTx + b という識別関数を考える。 識別関数(決定関数)が0を超えたら1,0以下なら-1としてクラス分類する 線形分離が可能であることから、決定関数=0となるような教師データはない。 そこで学習するのは wTx +
b>=1 y=1 wTx + b<=-1 y=-1 この式は以下の1つの式で表現できる。 y(wTx + b) > 1 この条件式を満たすようなWとBを求めることが目的となる
条件式を満たす関数を求め、 また、条件の等号が成立するようなデータが存在するならば 等号を満たすデータが最も異なるクラスデータと近い点となる。 クラス間の最も近いデータ点(等号をみたすデータ点)をサポートベクトルと呼ぶ このサポートベクトル同士の中心にあたる位置に超平面を引くことは、 クラス間を最も綺麗に分離するものと考えることができる (完全線形分離可能であるとは、データが線形で分離できることであり、非線形の関係 性をもっていないことである) この超平面までの距離をマージンと呼ぶ マージンを最大に取った場合の平面を
最適超平面 と呼ぶ
この超平面はどう求めるか? 最適超平面の係数wはwTx+b=0という超平面から直交している これは原点を通るように平行移動するとwTx=0となることからわかる
点と線の距離の公式の証明 ある直線式 ax + by + c= 0 と 点P(x1,y1)
を考える 点と線の距離は、点から線に垂直に線を下した線分の距離とする 法線の交点をQ(x2,y2)とする ここで、この線分PQの傾きを考える 傾きとはxが1変化する時にyがどれだけ変化するかを表すものだった。 y2-y1 / x2-x1 直線の傾きはy=の形に変形して –a/b である 垂直な二直線の傾きの積は-1になる という法則から、上記の傾きを式変形する 以上から x2-x1=am y2-y1 = bmという式が出る − 2 − 1 2 − 1 = −1 2 − 1 = 2 − 1 =
直交する直線の傾きの積が-1の証明 y=m’x+c (y-m’x-c) y=mx+c (y-mx-c) A(1,m) O(0,0) 直交するベクトルの内積は0という前提より 1, −
1 −′ = 1 + ′ = 0 ※切片c=0 よって mm’=-1 B(1,m’)
直交する直線の傾きの積が-1の証明 三平方の定理 y=m’x+c (y-m’x-c) y=mx+c (y-mx-c) A(1,m) O(0,0) B(1,m’) H(1,0)
※切片c=0 三角形OAHは角Hで直角である。 (AO)2 = (AH)2 + (OH)2 = (m2+1) (BO)2 = (BH)2 + (OH)2 = (m’2+1) 求めたAO,BOを使ってABを求める (AB)2 = (BO)2 + (AO)2 = (m2+1) + (m’2+1) これは図形から以下のようになる = (m-m’)2 以上を変形して mm’=-1
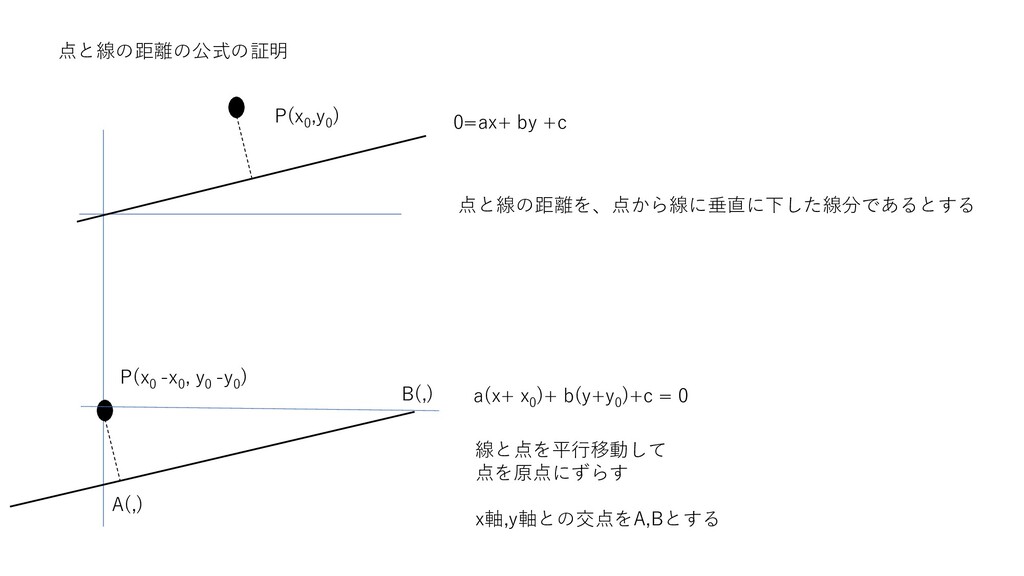
点と線の距離の公式の証明 点と線の距離を、点から線に垂直に下した線分であるとする P(x 0 -x 0 , y 0 -y
0 ) 線と点を平行移動して 点を原点にずらす x軸,y軸との交点をA,Bとする 0=ax+ by +c a(x+ x 0 )+ b(y+y 0 )+c = 0 P(x 0 ,y 0 ) A(,) B(,)
点と線の距離の公式の証明 P(x 0 -x 0 , y 0 -y 0
) a(x+ x 0 )+ b(y+y 0 )+c = 0 x=0の時 つまり点B a(0+ x 0 )+ b(y+y 0 )+c = 0 y=(-ax 0 -by 0 -c)/b y=0の時 つまり点A a(x+ x 0 )+ b(0+y 0 )+c = 0 x=(-ax 0 -by 0 -c)/a OA=|(ax 0 +by 0 +c)/a| OB=|(ax 0 +by 0 +c)/b| 三平方の定理より AB=sqrt( (OA)2+(OB)2 ) となる 三角形の面積は以下で成り立つはず ½(OA)(OB)=1/2(AB)*d A(,) B(,) 0 + 0 + 2 = 1 2 + 1 2 0 + 0 + = 0 + 0 + 2 + 2
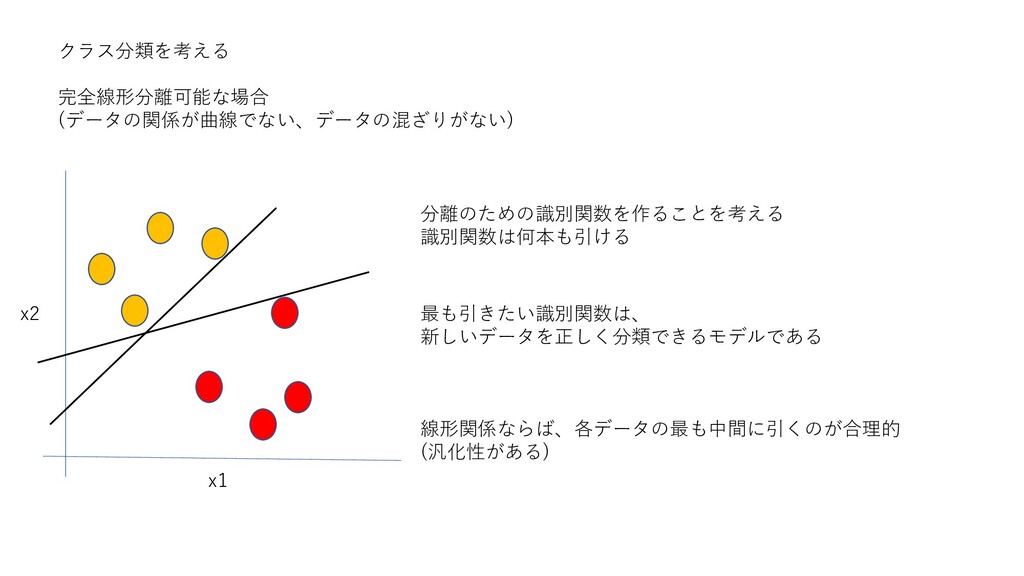
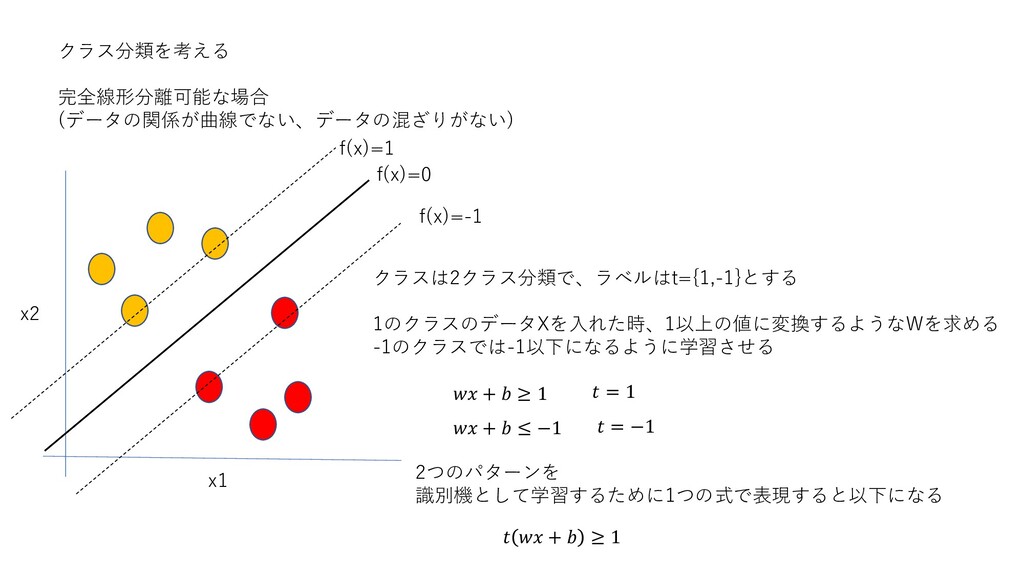
クラス分類を考える 完全線形分離可能な場合 (データの関係が曲線でない、データの混ざりがない) x1 x2 分離のための識別関数を作ることを考える 識別関数は何本も引ける 最も引きたい識別関数は、 新しいデータを正しく分類できるモデルである 線形関係ならば、各データの最も中間に引くのが合理的
(汎化性がある)
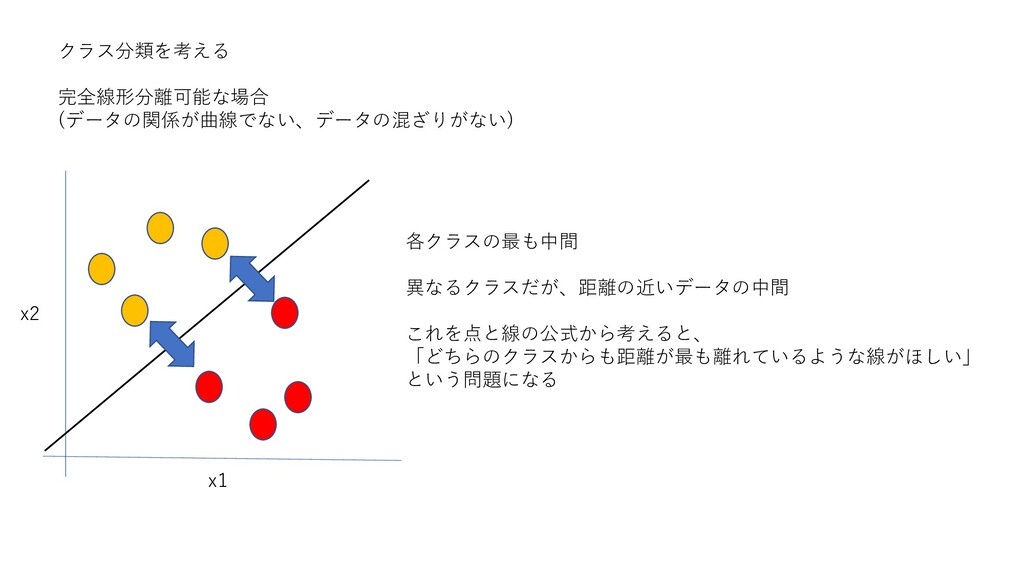
クラス分類を考える 完全線形分離可能な場合 (データの関係が曲線でない、データの混ざりがない) x1 x2 各クラスの最も中間 異なるクラスだが、距離の近いデータの中間 これを点と線の公式から考えると、 「どちらのクラスからも距離が最も離れているような線がほしい」 という問題になる
クラス分類を考える 完全線形分離可能な場合 (データの関係が曲線でない、データの混ざりがない) x1 x2 クラスは2クラス分類で、ラベルはt={1,-1}とする 1のクラスのデータXを入れた時、1以上の値に変換するようなWを求める -1のクラスでは-1以下になるように学習させる f(x)=0 f(x)=-1
f(x)=1 + ≥ 1 + ≤ −1 = 1 = −1 2つのパターンを 識別機として学習するために1つの式で表現すると以下になる + ≥ 1
クラス分類を考える マージン最大化分類器 完全線形分離可能な場合 (データの関係が曲線でない、データの混ざりがない) x1 x2 f(x)=0 f(x)=-1 f(x)=1 =
0 + 0 + 2 + 2 識別関数は互いのデータ点の中間である必要がある。 + ≥ 1 = 2 d d 識別関数は互いのデータ点の中間である必要がある。 両側d+dが最大になる場合が求めたい。 2dを最大にするには、上式の分母||w||2が小さくなる時である よって、最大化でなく、単に分母の最小化を考えてもいい。 分子は赤色までの距離のとき|-1|,黄色までの時|+1|となるので2 距離の計算に使われるベクトルを サポートベクトル 点と線の距離dをマージンと呼ぶ。 マージン最大化分類器は、 異クラスデータ間に最も幅の広い板を挿し込むもの
以上より t(wx+b) >=1 の制約での係数ベクトルwの最適化 ただし、||w||2の最小化を目指す 制約付き最適化 = ラグランジュに相談 上記は凸二次計画問題なので微分して0とおけば最小値が求まる 微分時にwノルムの二乗から2が発生するので事前に2で割った式が作られる
計算に使用するのは直線から一番近いデータ点であり、 計算コストが小さいこともわかってもらえると思う
不等式制約を持つラグランジュ未定乗数法は カルーシュ・キューン・タッカー条件を満たす解から解が選ばれる , , = 1 2 − +
− 1 = − = 0 特に一番最後の部分は相補性条件として知られる。 未定乗数αが0でないと成り立たない場合は括弧内が0より大きい場合であり、 αが解を持つ時とは制約式が計算して0になるような時である。 つまりサポートベクトルだけから計算する必要があることが分かる = = 0 + − 1 ≥ 0 ≥ 0 + − 1 = 0 KKT条件 ① ② ③ ④ ⑤
wに関する偏微分式①を変形して = とする。この変形式と②を元の目的関数L()に代入すると = 1 2 − −
+ = − 1 2 = − 1 2 ා 上記のように、もとのパラメータwもbも存在しない、αを求めるだけの式に変形できた このように元の課題(主問題)を変形して、 別の問題(双対問題)の解を求めることで元の問題の解も求まる方法
双対表現を確認すると、 行数Nに対する内積XTXと、そのラベルデータtからなる行列がある これをHと置く = − 1 2 ා
= 1 − 1 2 この双対問題は、②よりαTt=0であったので、これを制約として、 ラグランジュ未定乗数 βを使うことで以下に直せる。 , = 1 − 1 2 − 上記でαを解き、αとt,xからwが求まる。 t(wx+b)-1=0を、サポートベクトルのt,x値を代入してbを求める
主問題を見ると、正則化項の付いた式のようになっている , , = 1 2 − + −
1 wx+bを作るが、ノルムを大きくしすぎないように選ばれる
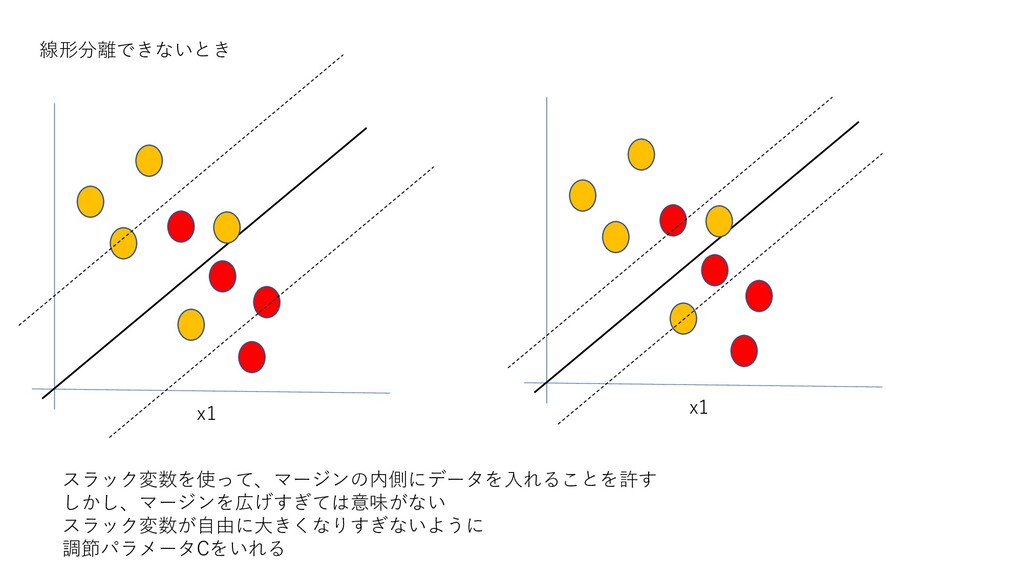
スラック変数を使って、マージンの内側にデータを入れることを許す しかし、マージンを広げすぎては意味がない スラック変数が自由に大きくなりすぎないように 調節パラメータCをいれる 線形分離できないとき x1 x1
+ − 1 + ≥ 0 x1 ξ=0のとき マージンの上 0<ξ<=1のとき
マージン内だが、最適識別超平面の正しく判別される側 ξ>1のとき 識別平面を超えて誤った側 スラックス変数ξを使って距離dを緩める マージン内や、誤分類を許す識別器を ソフトマージン識別器と呼ぶ
ソフトマージン識別器 = max 0,1 − + 上記は本来分類したい値から、どれだけ外れているかを表すので 損失関数と考えることができる。
ソフトマージン識別器の主問題 , = 1 2 2 + 制約 +
− 1 + ≥ 0 ≥ 0 どれだけの誤りを許すのかをCによって制御することからC-svmとも呼ばれる ξとwの最小化を目指すように学習する Cは分類性能を交差検証によって確かめて決定する ラグランジュ未定乗数μをつかって = 1 2 2 + − − + − 1 +
ソフトマージン識別器の主問題 , = 1 2 2 + / pは1か2が入る。1の時、L1
SVM(標準、正規svmとも) 2のときL2 SVMと呼ばれる。
解はKKT条件を満たすものから選ばれる = 1 2 2 + − −
+ − 1 + = − − = 0 = − = 0 = = 0 + − 1 + ξ i ≥ 0 ≥ 0 ① ② ③ ④ ⑤ ξ ≥ 0 μ ≥ 0 α i ( + − 1 + ξ i ) ≥ 0 ⑥ ⑦ = 0 ⑥,⑦が相補性条件
もしCがαよりも大きいならば、③よりμは0よりおおきくなる すると⑦でξが0にならなければならない。 →マージンに関係のないベクトル 自由サポートベクトル ξ>0ならμ=0となるので③よりα=Cとなる 上記より、αの上限はCということがわかる。 →このようなデータ点を上限サポートベクトルと呼ぶ バイアスは0<α<Cとなるようなデータ点を使って求める
双対問題化 = 1 − 1 2 マージン最大化ではaTt=0の制約だけだったが、 0<=α<=Cの制約を付け加えたものがソフトマージン識別器の双対問題となる
ここらでカーネル法
非線形な関係性を持つ場合 分離平面を非線形な関数で作ればいい、というのがいままでの考え方 カーネル法のすごいところは、 「データ側を様々な非線形変換にしたとき、高次元空間でなら線形による分離平面が書けるのではな いか??」 と考えたところ。(経験的にその可能性が高まる、という程度であるが、それが良く働くんです) イメージとしては多項式での重回帰のような変換をデータに対して行うことで、 疎な特徴量空間を作って単純な超平面を入れる X1 X2
X3 X 1 2 X 1 3 √x 1 x 2 X 2 2 x 2 3 x 3 2
元データXに対するこの変換した後のデータ行列を Φ(X)={Φ 1 (X),Φ 2 (X),…Φ M (X)} として表現する。次元はMになる。 Φ
0 (X)=1 としてバイアス項を以降明記しないこととする 識別関数は を求めることであり、SVMの目的関数の偏微分から重みベクトルwは として求まるのだった。 もとの式に代入するとΦ(X)に関する計算が現れる。 これを一つの関数K(x,x)という形で表現する。このK()を核関数、カーネル関数、単にカーネル、と呼ぶ = = = ,
, グラム行列 カーネル関数で行われる計算は内積だけではない。 いくつかの特徴的な計算がカーネル関数として採用される。 (グラム行列が対称であり半正定値になる関数ならOK。) カーネル関数によって得られる行列はグラム行列である。 n行のデータに対して、I,j成分がK(xi行,xj行)によって計算される。 この計算からわかる通り、n行n列の行列となり、その成分は対称である
カーネル関数はなぜうれしい? 1 X 1 2 √x 1 x 2 X
2 2 √x 1 √x 2 六次元の内積計算でn*n行列を作るためにはn*n要素の計算が必要 しかし、ΦTΦによる計算を展開して 1+x 1 2x’ 1 2+2x 1 x 2 x’ 1 x’ 2 +x 2 2x’ 2 2+2x 1 x’ 1 +2x 2 x’ 2 これを平方完成すると (1+x 1 x’ 1 +x 2 x’ 2 )2 = (1 + XTX’)2 Φすると、元のn*d行列の内積からスカラを得て、1を足して、二乗したらいい。 このように計算が単純で済むし、 計算さえ決まれば何次元も特徴量を生成した行列をメモリ内に保持しなくて済む。 今回の例は二次の多項式カーネルを例にとった。
他にもカーネルとして、 シグモイドカーネル ラプラシアンカーネル ガウシアンカーネル(RBF,動径基底,距離を考えるもの) などが、 カーネル関数として求められる性質を満たしながら、 複雑な問題をSVMによってよく分離できる特徴抽出を行えるということで 頻繁に採用される。 以上のようにカーネル関数を取り入れた手法がカーネル法である。 カーネル関数は
非線形変換のΦや、高次元で複雑な特徴量空間を意識せずとも(内積計算が重すぎてすぐ解けない) 条件を満たすカーネル関数を設計することによって、同じことが簡単な計算でできてしまう。
多項式カーネル , = + p次の特徴量を生成したことと同値にするカーネル関数 だいたい3~4次までのものしか見ない。 16*16の画像 256特徴量 をp=4での特徴量を考えた時、 そこから合成される次元は186043585次元までの抽出が考えられていることになる
非常に高次元の非線形特徴空間への写像になるため、各データの距離は離れ、疎な空間となる このような学習法が背景にあるため、 疎なカーネルマシン と呼ばれる
動径基底関数カーネル (RBFカーネル) , = exp − 1 22 − 2
σはカーネル関数の広がりを調節するパラメタ σが大きい時、入力データに対する広い範囲でのサポートベクトルが識別に関わる σが小さいとき入力データと近いデータのみがサポートベクトルとなる また、動径基底カーネルは無限次元の特徴量に展開することに等しい(証明pass)
1class-SVM 一つのクラスだけを学習し、そこからの外れ値・異常判断に利用できる データ空間を超球によって包み、その球の中に入るか外に出るかで決める 大きく二つの作り方がある データを包む球が、原点から球までの距離をρで最適化して求める。 1クラスν-SVM 正例を超球で包み、その半径を最適化する サポートベクトル領域記述法
1クラスSVMでの主問題 最小化 不等式制約 , = 1 2 − + 1
− + ≥ 0 ≥ 0 この双対問題は = − 1 2 ා , 制約条件 0 ≤ ≤ 1 = 1
ν-SVM 今まで t(wx+b) >= 1 という制約によって考えてきたが、この1さえも自動的に決めさせることを考える。(νトリック) t(wx+b) >= ρ その場合、最大化するマージンは
2ρ/||w||2 ρが小さいとマージンも小さくなり汎化性は落ちる ρにたいしての調節を外部から加えられるようにνというハイパーパラメータを設ける w,ξの最小化を目指す。制約は νによって、マージンの大きさ、識別器の複雑さ、誤り率、を調節できる。 = 1 2 2 − + 1 + − + ≥ 0 ≥ 0
ν-SVMの双対表現 = − 1 2 ා この最大化、 制約 0≦γi
≦ 1/n ν≧Σγi
SVMでの回帰 SVR 特徴量を合成(データ側を非線形変形)する考えによって線形回帰モデルを当てはめる z=y-f(x) の差分を最小にするように学習を進める。 二乗誤差による学習ではなく、区分線形関数γ()を使う γ(z) = { この区分線形関数を損失関数として考える
真ん中の条件、ε以下の誤差は目をつぶる、ということから ε不感応関数 と呼ぶ 最小二乗法では二乗するために外れ値にロバストでないが、 この関数は緩やかな損失を与える z-ε (ε≦z) 0 (-ε≦z<ε) -z-ε (z<-ε)
ξ i =γ(z)=γ(y i -f(x i )) ξ i ≧y
i -f(x i )-ε ξ i ≧0 ξ i ≧-(y i -f(x i ))-ε 上記の制約の下で、二次の正則項を含めた以下を解くと回帰が求まる。 min +
SVM回帰の双対表現 , , , , − = + 1
2 − − ා + − + − ා − + + − 双対表現 これを最大化する。 制約は 0≦γ i + γ- i ≦1 , − = − 1 2 − − − − − − + − − +
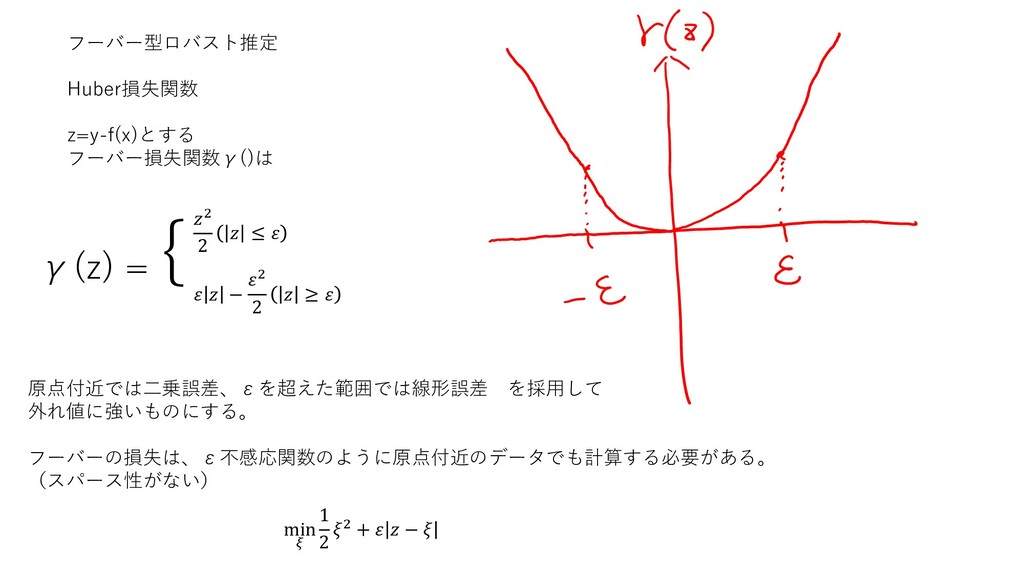
γ(z) = {2 2 ≤ − 2 2 ≥ 原点付近では二乗誤差、εを超えた範囲では線形誤差
を採用して 外れ値に強いものにする。 フーバーの損失は、ε不感応関数のように原点付近のデータでも計算する必要がある。 (スパース性がない) フーバー型ロバスト推定 Huber損失関数 z=y-f(x)とする フーバー損失関数γ()は min 1 2 2 + −
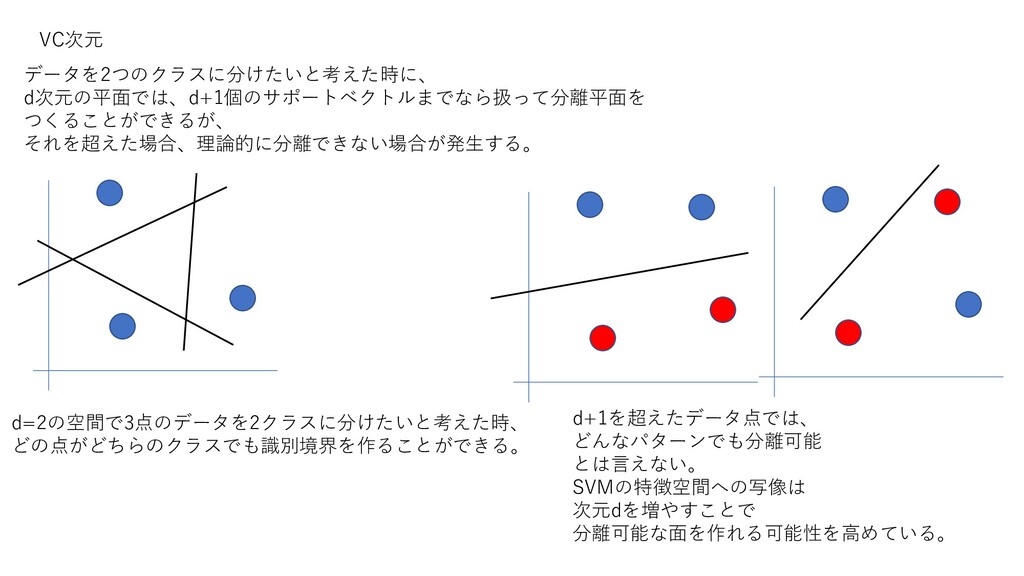
VC次元 データを2つのクラスに分けたいと考えた時に、 d次元の平面では、d+1個のサポートベクトルまでなら扱って分離平面を つくることができるが、 それを超えた場合、理論的に分離できない場合が発生する。 d=2の空間で3点のデータを2クラスに分けたいと考えた時、 どの点がどちらのクラスでも識別境界を作ることができる。 d+1を超えたデータ点では、 どんなパターンでも分離可能 とは言えない。
SVMの特徴空間への写像は 次元dを増やすことで 分離可能な面を作れる可能性を高めている。
カーネルを自分で設計できるということは、 問題に対して汎化性の高い特徴量を作りだすこともできる。 タスクごとのカーネル:文字列カーネル、グラフカーネル、 合成特徴量:HOG、bag of words
SVMは凸二次計画であり、 線形分離可能という仮定をしているので、 微分して0と置くことで解が必ず得られる。 この解を 実行可能解、許容解 と呼ぶ SVMの解 w=0となる場合がある この解を縮退解と呼ぶ
二次計画問題を解くのでなく L2SVMの不等号制約を等号に置き換えたもの 最小二乗法によるSVM(LS SVM)となる L1SVMで最小化をノルムの二乗にしていたが、1次の項にすることで、 目的関数も制約も線形な線形計画問題にする 線形計画SVM(linear programming SVM) LP
SVM 二次計画なら最小化問題にできたが、LPは解が一意でない。
スパースSVM SVMは境界付近のデータだけを使って解を求めることができるので 解がスパースである と言われる(ラグランジュ未定乗数αは多くが0) しかしクラスが混合してしまっている場合、それらがすべて参照される(サポートベクトル となる) そのためスパースではない スパースSVMは汎化性能を保ちながら、なるべくサポートベクトルを減らす。 ・SVMにより関数を求める ・サポートベクトルの数を減らす(スパース性向上のアプローチ)
・カーネル展開式により学習を進める ∈ , + SVMの解は、サポートベクトルのデータ集合をSとする時、ラグランジュ未定乗数を重み グラム行列をデータとして、バイアス項を加えた式から与えられる。 この式を カーネル展開 と呼ぶ
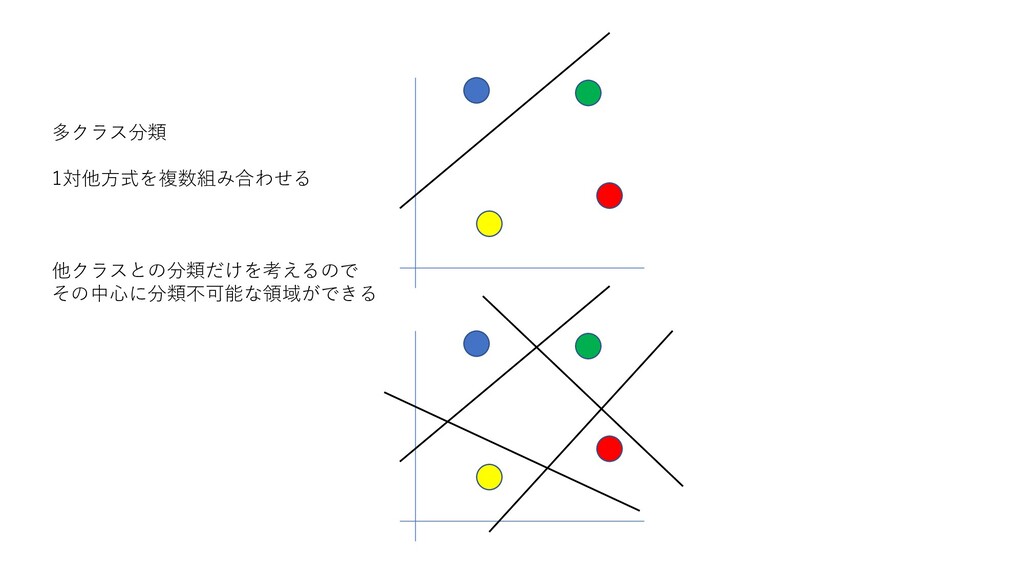
多クラス分類 1対他方式を複数組み合わせる 他クラスとの分類だけを考えるので その中心に分類不可能な領域ができる
複数の識別器を同時に求めるSVMもある 求め方はpass
多重パターン認識器(コミッティーマシンとも) バギングやブースティング、adaboostのように、 複数の分類器を合わせて学習する方法はある SVMでは、複数種類のカーネルを線形和にして性能を上げたいという考え方から 多重カーネルを使った手法が存在する βは合計で1となる非負のパラメタ。 学習によってβが0となる場合、そのカーネルは問題に対して必要でなかったと判断する。 ′, =
′,
多重カーネルの学習 下記を最大化する。制約は省略 , = − 1 2 ා
⋅
カーネル法の関数近似への拡張
入出力の関係を近似する関数をつくることを 関数近似 もしくは 回帰 と呼ぶ パターン認識が離散量の出力 関数近似は連続量の出力 どちらも手元のデータから、未知のデータに対する 汎化性を持った関数を実現することが求められる
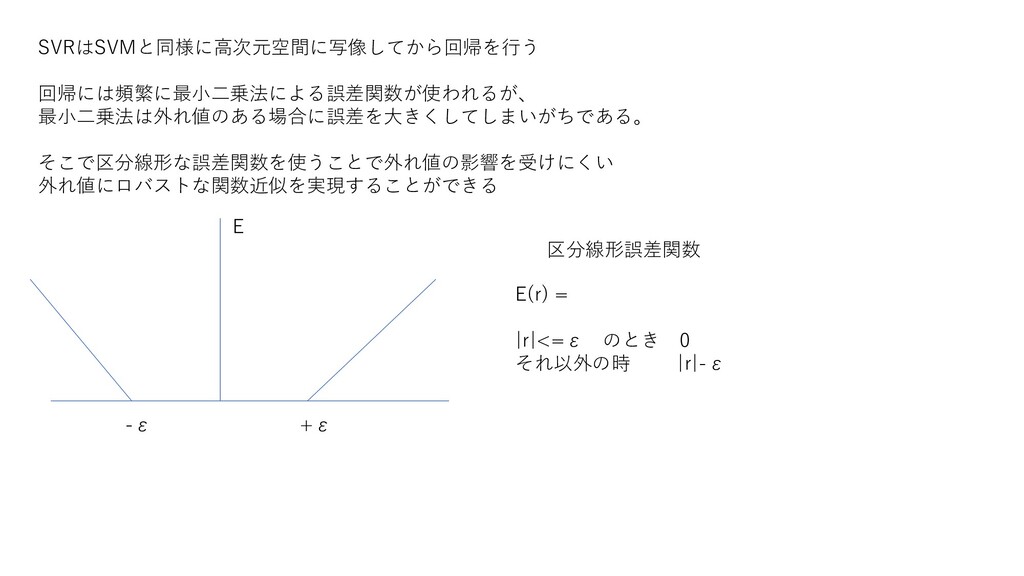
SVRはSVMと同様に高次元空間に写像してから回帰を行う 回帰には頻繁に最小二乗法による誤差関数が使われるが、 最小二乗法は外れ値のある場合に誤差を大きくしてしまいがちである。 そこで区分線形な誤差関数を使うことで外れ値の影響を受けにくい 外れ値にロバストな関数近似を実現することができる -ε +ε 区分線形誤差関数 E E(r)
= |r|<=ε のとき 0 それ以外の時 |r|-ε
残差を小さくするには |y-f(x)| < ε になるようなf(x)を学習する つまり、関数 f(x)±ε の範囲にyが入れば誤差は0と判定される この幅を εチューブ
と呼ぶ このεを大きくしていけば誤差は小さくできるが、汎化のことも考えて、 データ点と関数f(x)(=最適超平面) のマージンを最大にする、という条件も付け加える必要がある +ε -ε
超平面 はD(x,y)=0 であるので、データ(x,y)までの距離は |D(x,y)| / ||w*|| ここでの ||w*|| は ||w*||=(1,
-wT)T である データまでの最大距離をδとすると すべてのデータは |D(x,y)| <= δ||w*|| を満たす。 よって、最も超平面から遠くにあるデータが |D(x,y)| = ε である。 (SVCでは最も近いものとの距離を気にしていたが、チューブに全部いれるなら離れたデータとの距離を考える) y-f(x) は教師データと説明データの対 (x,y)から成り立つ損失関数Dとして考え、 D(x,y)と表現する
|D(x,y)| = ε であるとは δ||w*|| = ε であるということになる。 マージンδを最大化するには||w*||を最小化する。 最小化するための凸二次計画のため二乗にすると、
||w*|| = (1, -wT)T だったので、 ||w*||2 = ||w||2 + 1 よって||w*||の最小化とは||w||の最小化として考えて問題ない min 1 2 2 − − ≤ + − ≤ 制約
εチューブにすべてのデータを含めるということは、 高バイアスなモデルになりそう。 εチューブの外側も許すためにスラックス変数を導入する = 0 1 − ← D(xi,yi) -ε
<=0 ←それ以外 ∗ = 0 − 1 − ← ε+D(xi,yi ) >=0 ←それ以外
制約 以上から求める式は min , 1 , ∗ = 1 2
2 + + ∗ − − ≤ + + − ≤ + ∗ ≥ 0 ∗ ≥ 0 Cはマージンパラメータ pは1 or 2 p=1 のとき L1 SVR p=2 のとき L2 SVR と呼ぶ
双対問題 KKT条件 LP ν 最小二乗LS 系のSVR導出 はちょっとpass
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![カーネルトリックについてもうちょっと咀嚼 X=[x1,x2] X’=[x’1,x’2]とする カーネル法だと内積計算だったりするので、X=X’だったりするけど、見やすさのために分けてかく 手法1 6つの基底関数を考えて特徴ベクトルに写像してカーネル行列(グラム行列) を求めてから内積を計算する場合 回答 Φ(X) =](https://files.speakerdeck.com/presentations/fd5cc93ed4a14942bc1a59754cce6d71/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![カーネル主成分分析 変数を特徴抽出によって作り出してから主成分分析をする 二次元の変数 X=[X1,X2] Φ(X) = {Φ1(X1), Φ2(X2),Φ3(X2)} Φ1=X1 Φ2=X2^2](https://files.speakerdeck.com/presentations/fd5cc93ed4a14942bc1a59754cce6d71/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
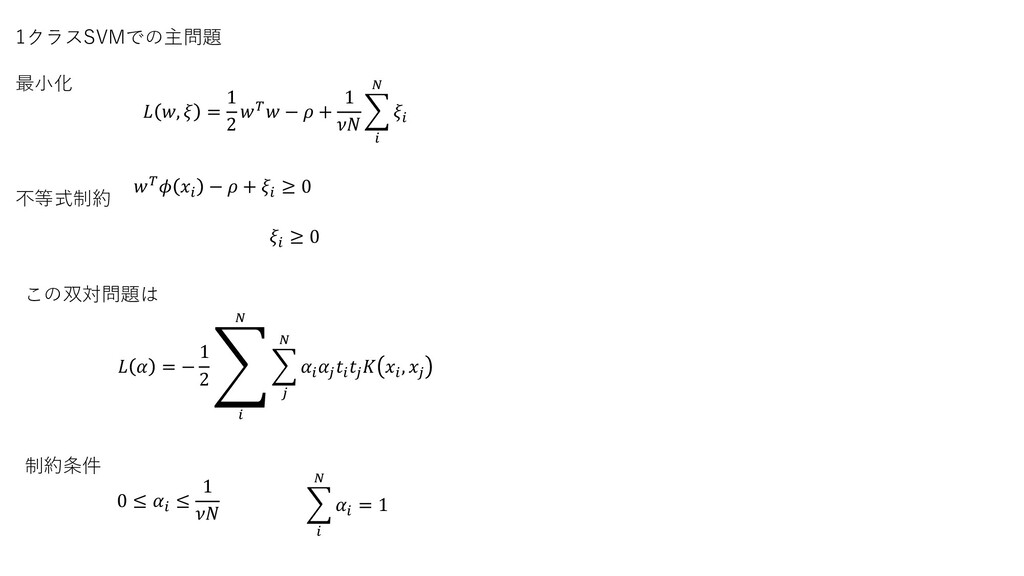{kind=link}
{kind=link}
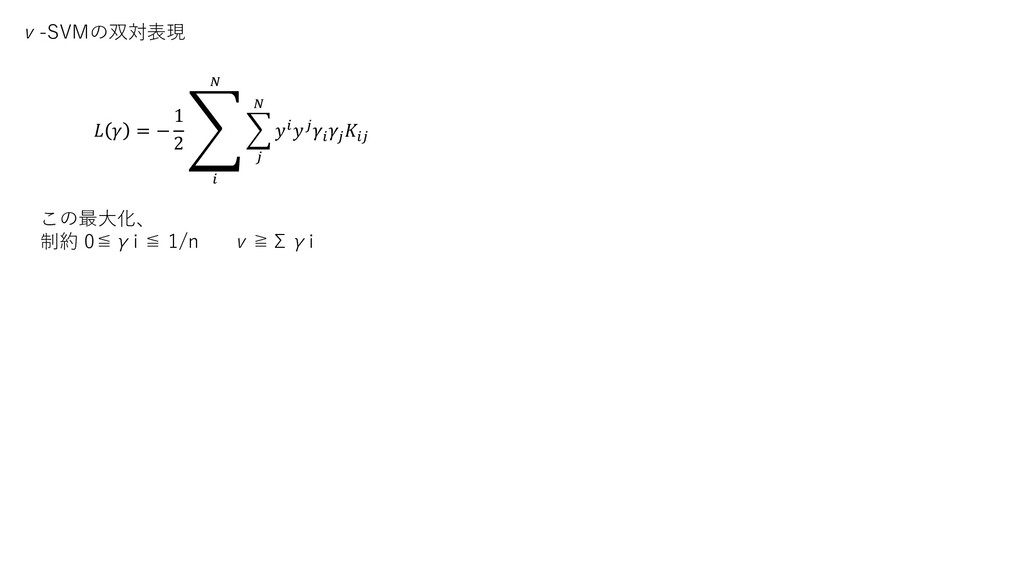{kind=link}
{kind=link}
{kind=link}
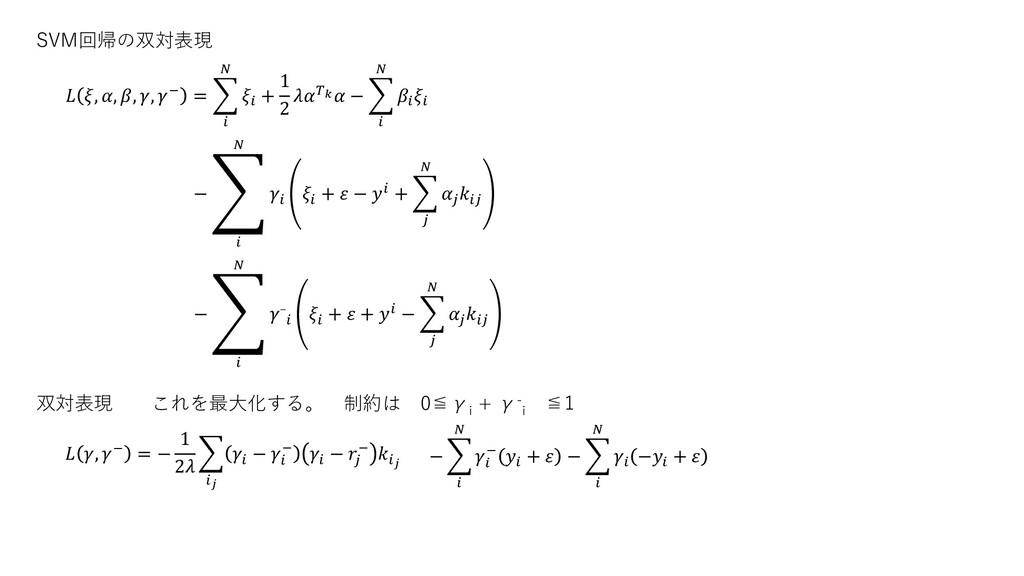{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
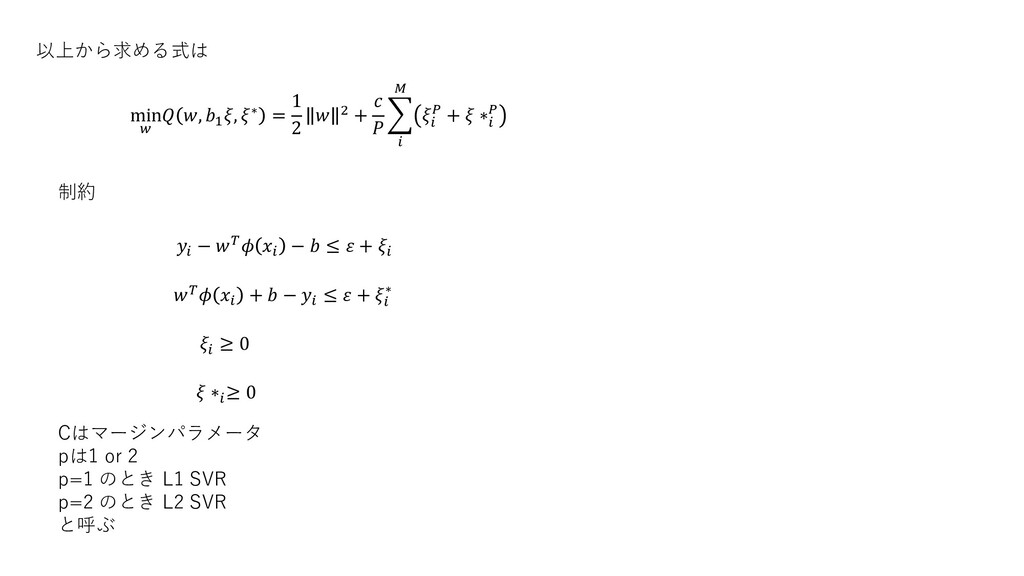{kind=link}
{kind=link}