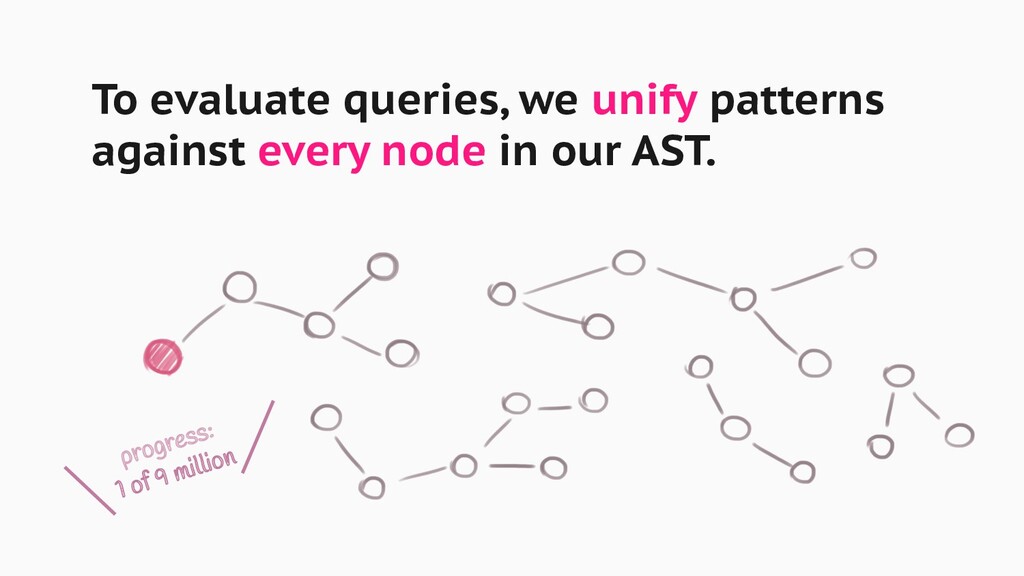
Reading source code is not really doable once you hit the tens of thousands of lines of code. It's even more hopeless at millions of them. Yet, analysis tools that can summarise this information struggle just as much as humans do. So how do we build tools that can handle such ginormous codebases, anyway?
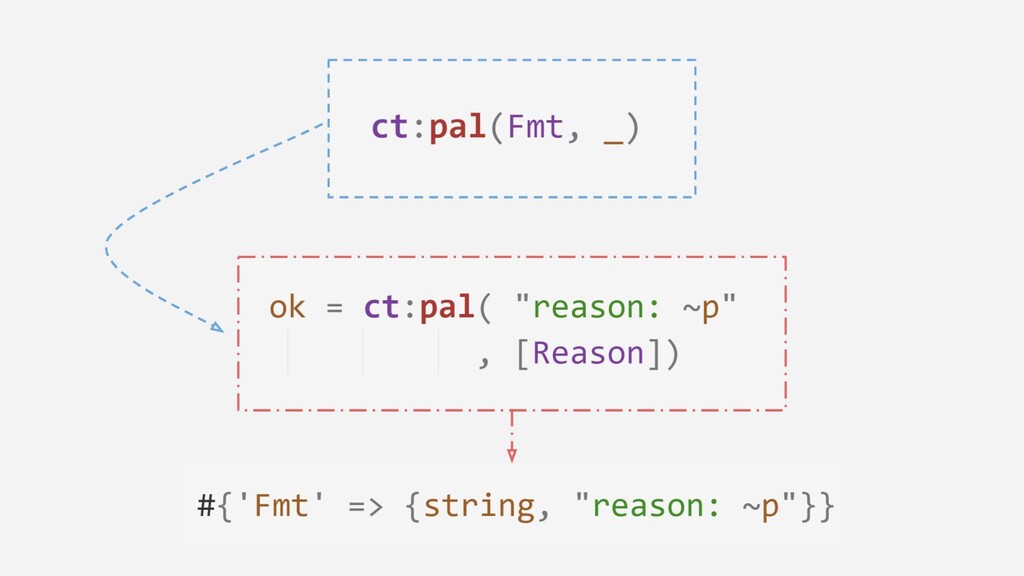
In this talk we'll take a practical (but superficial) look at some of the algorithms involved in the making of Glass, a static analysis tool developed at Klarna, and the optimisations that allow providing answers to analysis in real-time for IDEs, and reasonable-time for build/CI tools.
Links:
- Glass' GitHub repository: https://github.com/klarna-incubator/glass
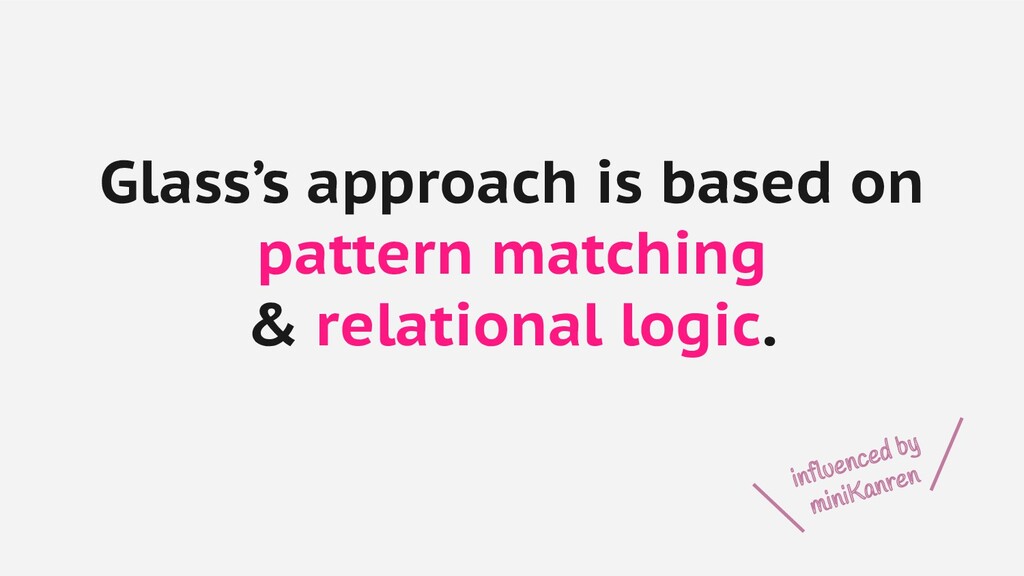
- µKanren: A Minimal Functional Core for Relational Programming: http://webyrd.net/scheme-2013/papers/HemannMuKanren2013.pdf
- How Developers Search for Code: A Case Study: https://research.google/pubs/pub43835/
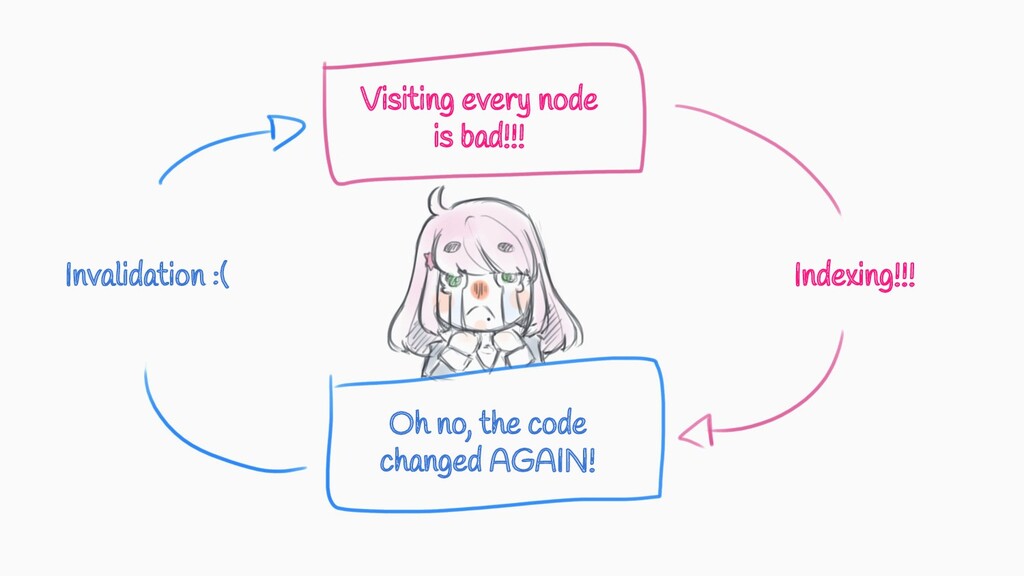
- Adapton: Composable, Demand-Driven Incremental Computation: http://matthewhammer.org/adapton/adapton-pldi2014.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}