Reliability in the Age of AI: Engineering for AI Velocity
AIを踏まえた開発の予防と処方の在り方 ( https://forkwell.connpass.com/event/394661/ ) #Forkwell_開発の予防処方 というイベントで「Reliability in the Age of AI: Engineering for AI Velocity」というタイトルで発表した際の資料です。
… with organizations targeting up to a 4x increase in productivity — traditional, manual practices are becoming unsustainable" "Human code review cannot scale linearly with machine-generated code volume" SRE の本質 (SLI/SLO / エラーバジェット / toil 削減) は変わらないが、運用は新フェーズに入る "…the operational landscape has reached a new inflection point" SRE は「直接の対応者」から「AI 安全性の設計者」へシフトする "SREs must move up the abstraction ladder, transitioning from direct incident responders to architects of AI safety" [10] https://sre.google/resources/practices-and-processes/ai-engineering-reliable-operations/ Google SRE Perspective
SLI/SLO の設計と運用観測を AI で補助する GitHub のリポジトリを AI に読み込ませ、サービスの構造から SLI/SLO の候補を提案する PR で重要な機能が追加されたら、SLI/SLO への追加が必要かを AI が確認する 既存のメトリクスや過去のポストモーテムを AI が解析し、SLI の改善案を出す SLO 違反の予兆を AI が継続観測で検知し、原因の仮説を提示する SLO の見直しタイミングや組織レベルの妥当性も AI で評価する Case 1
変更内容を AI が Production-Readiness 観点でレビューし、人間が承認する形で進行中 リリースタイミングで差分を AI に読み込ませ、PRC 観点でのリスクと観点漏れを提示する 過去のリリースと本番障害の相関から、Readiness Check への反映を AI が提案する 最終的な意思決定は人間が保持する Case 2
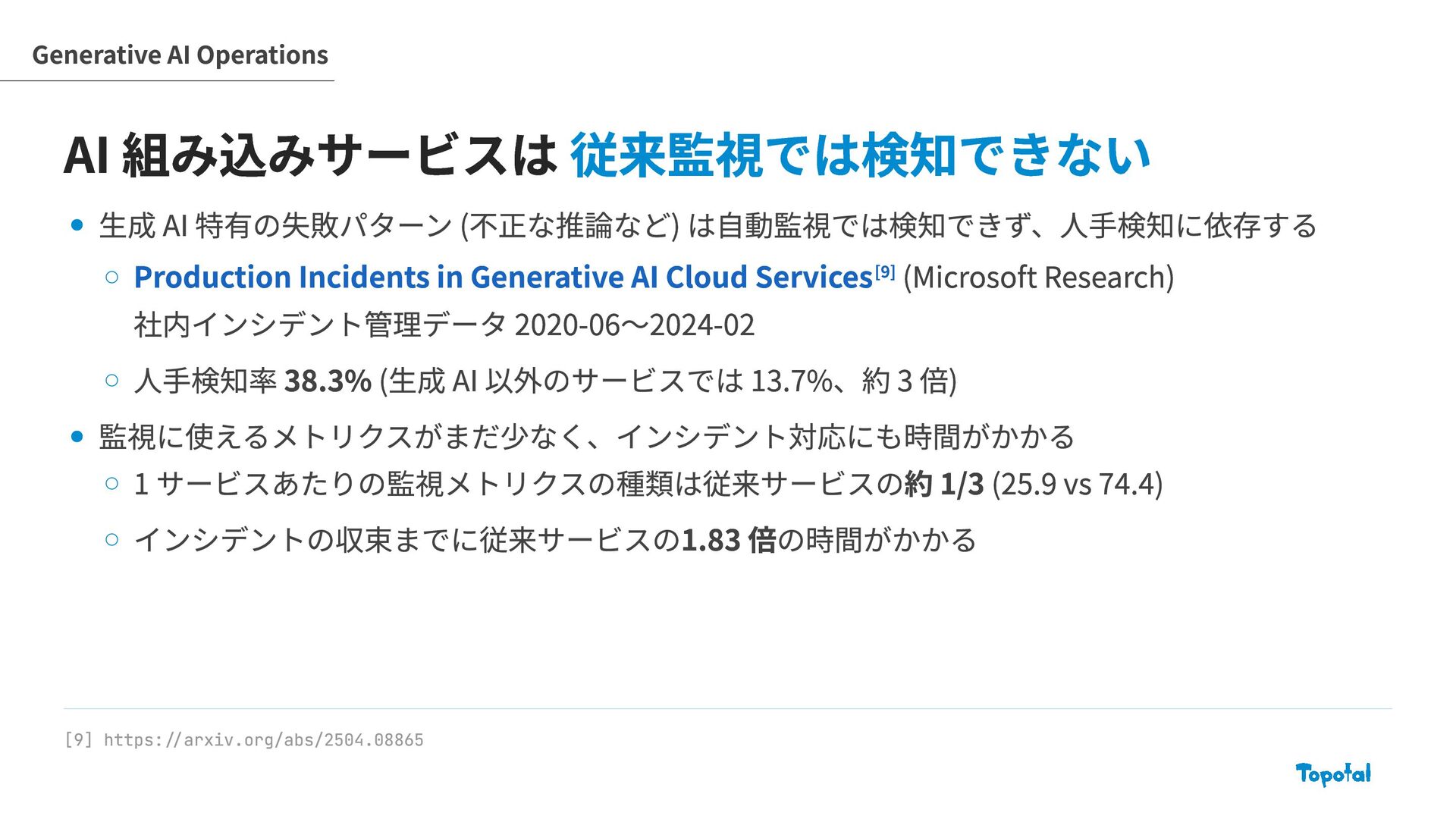
コードは品質問題が残り続け、AI 組み込みサービスは従来監視では検知しづらい 課題: SRE は速度と信頼性のバランスを AI 時代に取り直す必要がある 変化のスピードに観測 → 判断のサイクルを追従させ、データドリブンな判断ができるようにする AI 生成物のコントロールと、安全なデプロイ担保の両方の重要性が増している 進化: SRE プラクティス自体も AI を活用して、開発加速に追従する必要がある SRE 業務に AI を取り込み、信頼性運用をスケーラブルにする 更に AI に任せていくには、段階的にガードレールや評価データを整える必要がある Summary
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![AI 採用は 業界全体に浸透している 大規模な業界調査で開発者の大多数が AI を業務利用している DORA Research: 2025[1] (State](https://files.speakerdeck.com/presentations/da9a6dbb639149188011633c34828d1c/slide_4.jpg){kind=link}
![生産性向上は 研究でも認められている 実験室では明確な速度向上が示される The Impact of AI on Developer Productivity[3]](https://files.speakerdeck.com/presentations/da9a6dbb639149188011633c34828d1c/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
![AI コードの品質・技術的負債は 残り続ける AI コミットは一定割合で不具合を導入し、その大半が永続化する Debt Behind the AI Boom[7]](https://files.speakerdeck.com/presentations/da9a6dbb639149188011633c34828d1c/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Google SRE も同じ パラダイムシフト を認識[10] AI による速度加速で、従来の人手プラクティスは持続不能になる "AI coding assistants](https://files.speakerdeck.com/presentations/da9a6dbb639149188011633c34828d1c/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}