novel benchmark for measuring Word Sense Disambiguation biases in Machine Translation. In: ACL 2022, pp. 4331-4352, 2022. • [Wang and Wang, 2020] Ming Wang and Yinglin Wang. A synset relation-enhanced framework with a try-again mechanism for word sense disambiguation. In: EMNLP 2020, pp. 6229–6240, 2020. • [Wang+, 2021] Ming Wang, Jianzhang Zhang, and Yinglin Wang. Enhancing the context representation in similarity-based word sense disambiguation. In: EMNLP 2021, pp. 8965–8973, 2021. • [Wang and Wang, 2021] Ming Wang and Yinglin Wang. Word sense disambiguation: Towards interactive context exploitation from both word and sense perspectives. In: ACL-IJCNLP 2021, pp. 5218–5229, 2021. • [Loureiro and Jorge, 2019] Daniel Loureiro and Alıpio Jorge. Language modelling makes sense: Propagating representations through wordnet for full-coverage word sense disambiguation. In: ACL 2019, pp. 5682–5691, 2019. • [Raganato+, 2017] Alessandro Raganato, Jose Camacho-Collados, and Roberto Navigli. Word sense disambiguation: Aunified evaluation framework and empirical comparison. In: EACL 2017, pp. 99–110, 2017. • [Deng+, 2019] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In: CVPR 2019, pp. 4690–4699, 2019. • [Brown+, 2020] BROWN, Tom, et al. Language models are few-shot learners.In: NeurIPS 2020, 33: 1877-1901, 2020. • [Petroni+, 2019] PETRONI, Fabio, et al. Language Models as Knowledge Bases?. In: EMNLP 2019, pp. 2463-2473, 2020. • [Pan+, 2023] PAN, Xiaoman, et al. Knowledge-in-Context: Towards Knowledgeable Semi-Parametric Language Models. In: ICLR 2023. 2023. • [Meng+, 2022] MENG, Kevin, et al. Locating and Editing Factual Associations in GPT. In: NeurIPS 2022. 2022. 28
{kind=link}
{kind=link}
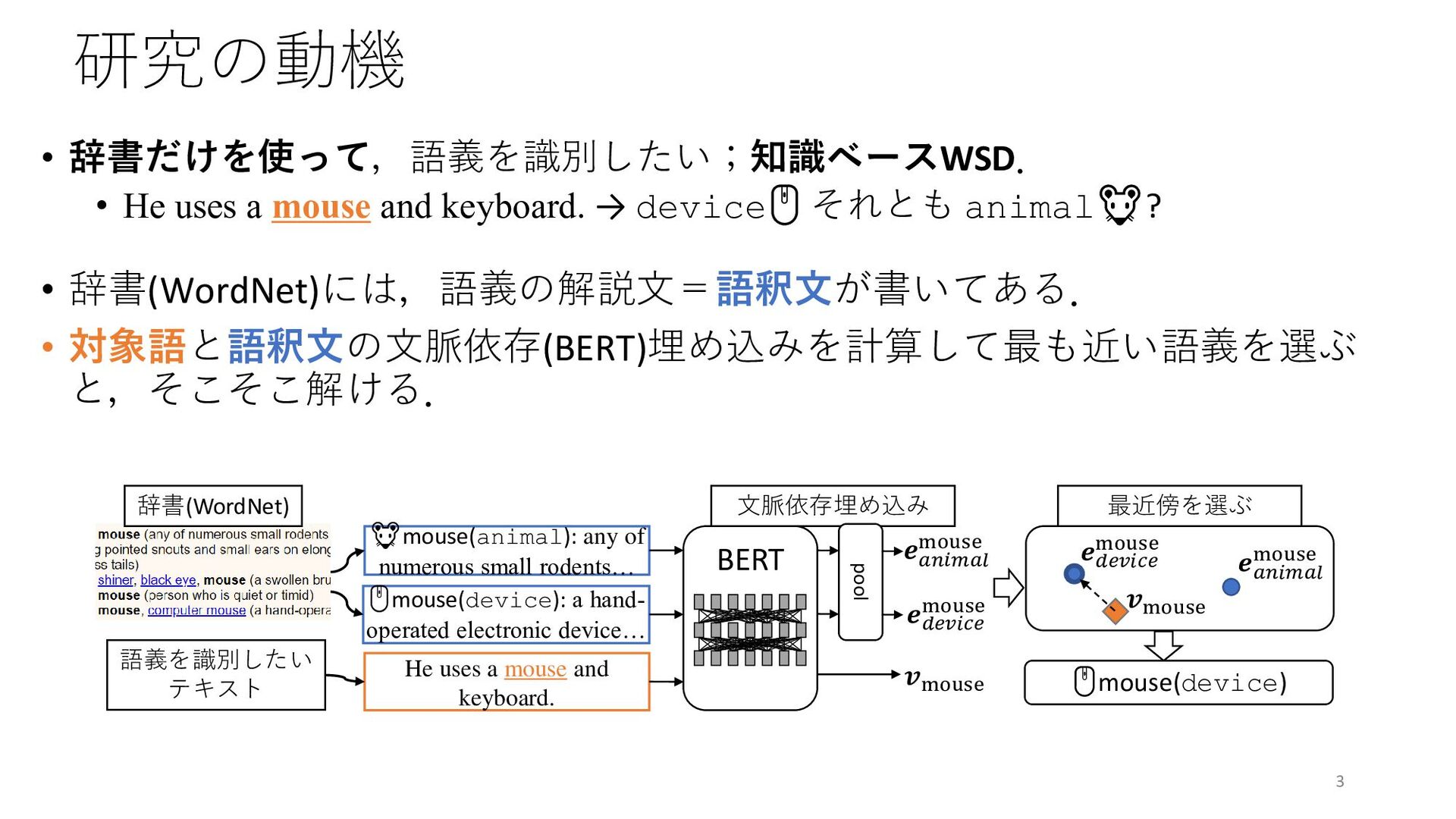{kind=link}
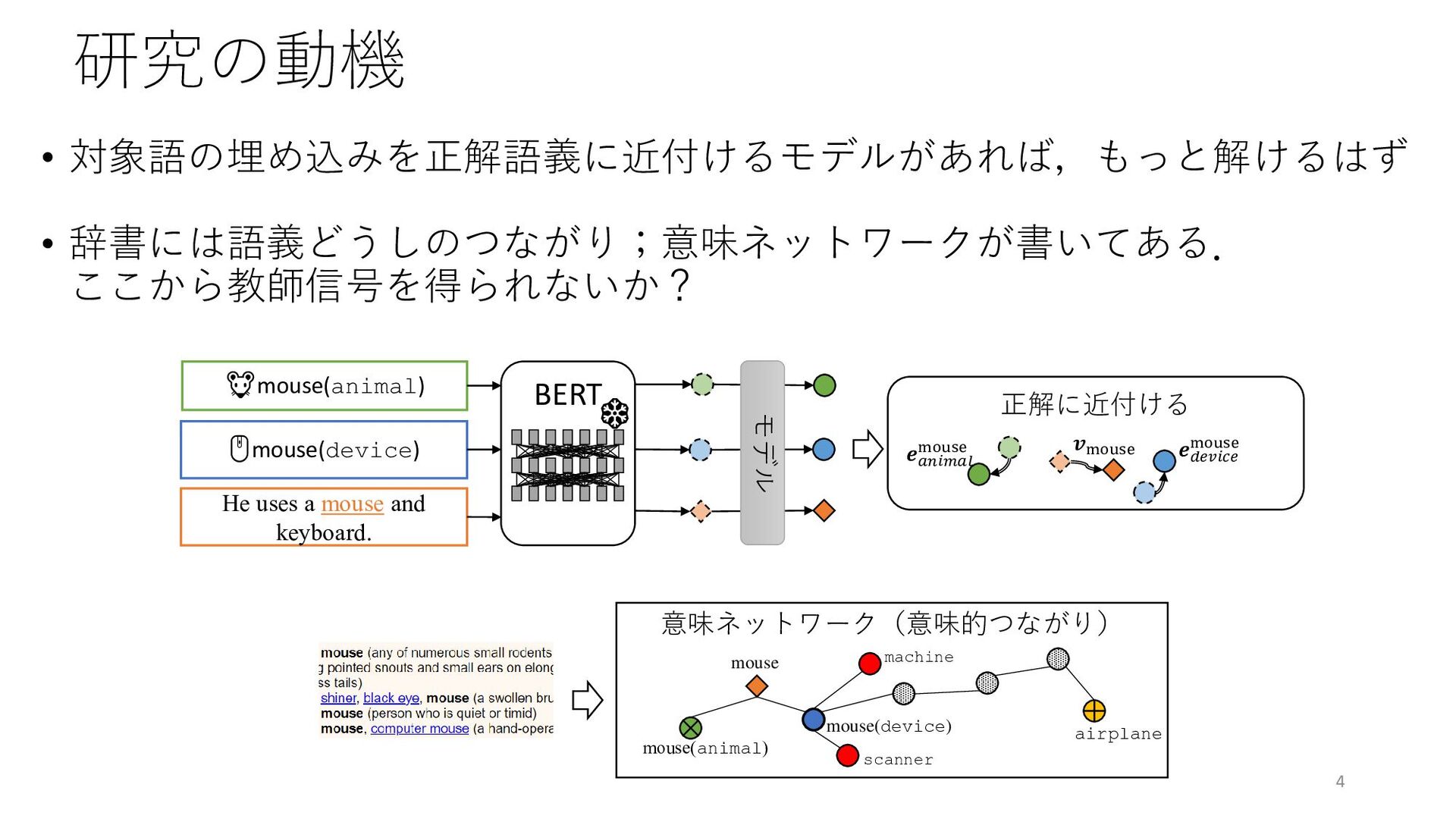{kind=link}
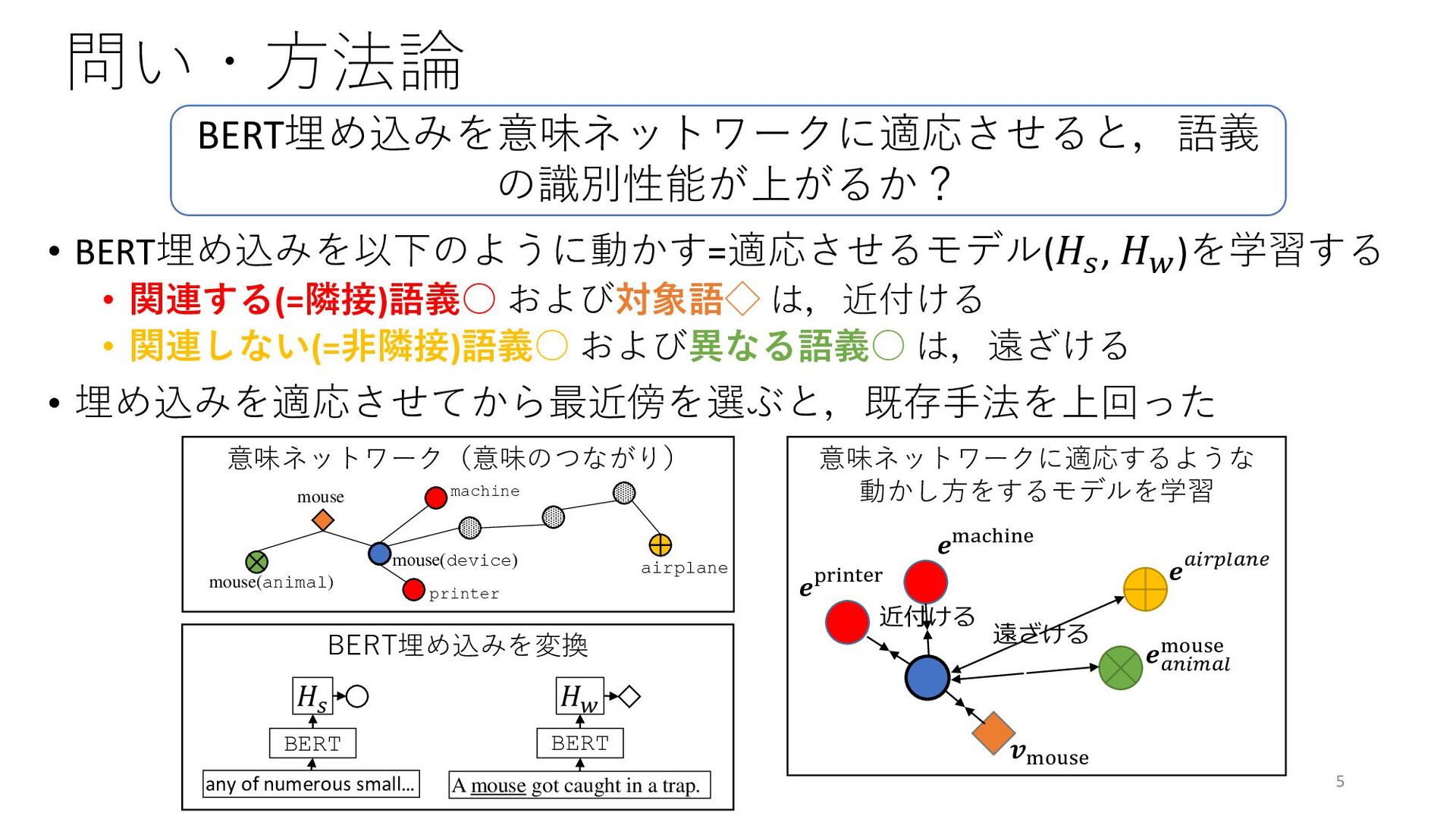{kind=link}
{kind=link}
{kind=link}
![BERT埋め込みの最近傍法に基づく既存研究 • 関連する語義を互いに近付ける:SREF[Wang and Wang, 2020] 👍 意味ネットワーク上の隣接性を語義埋め込みに反映.性能が改善. 👎 対象語埋め込みはそのまま.無関連語義・異義は未活用.](https://files.speakerdeck.com/presentations/6e266e25efe447c5bdfab0d7a2e0f124/slide_7.jpg){kind=link}
{kind=link}
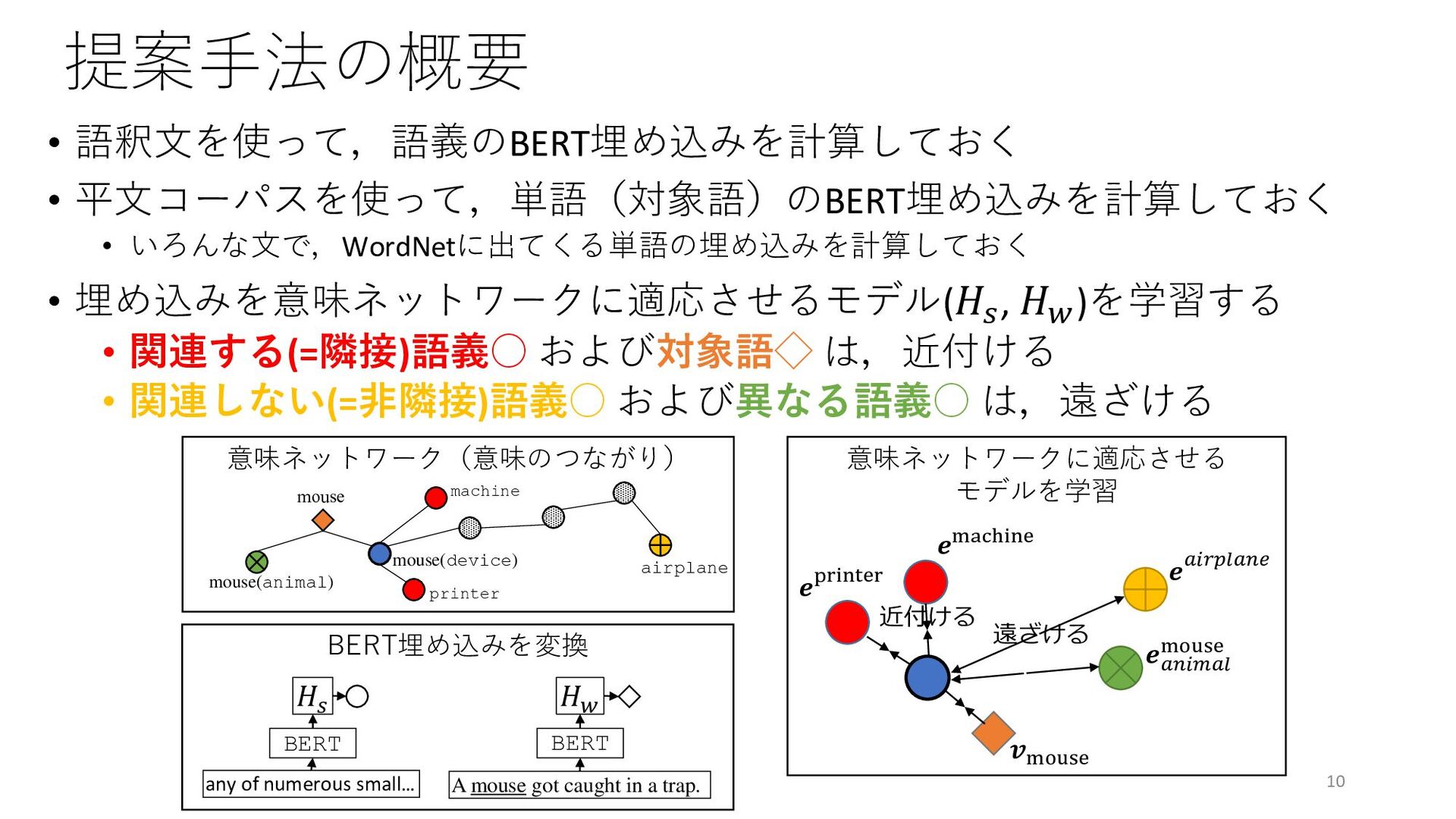{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
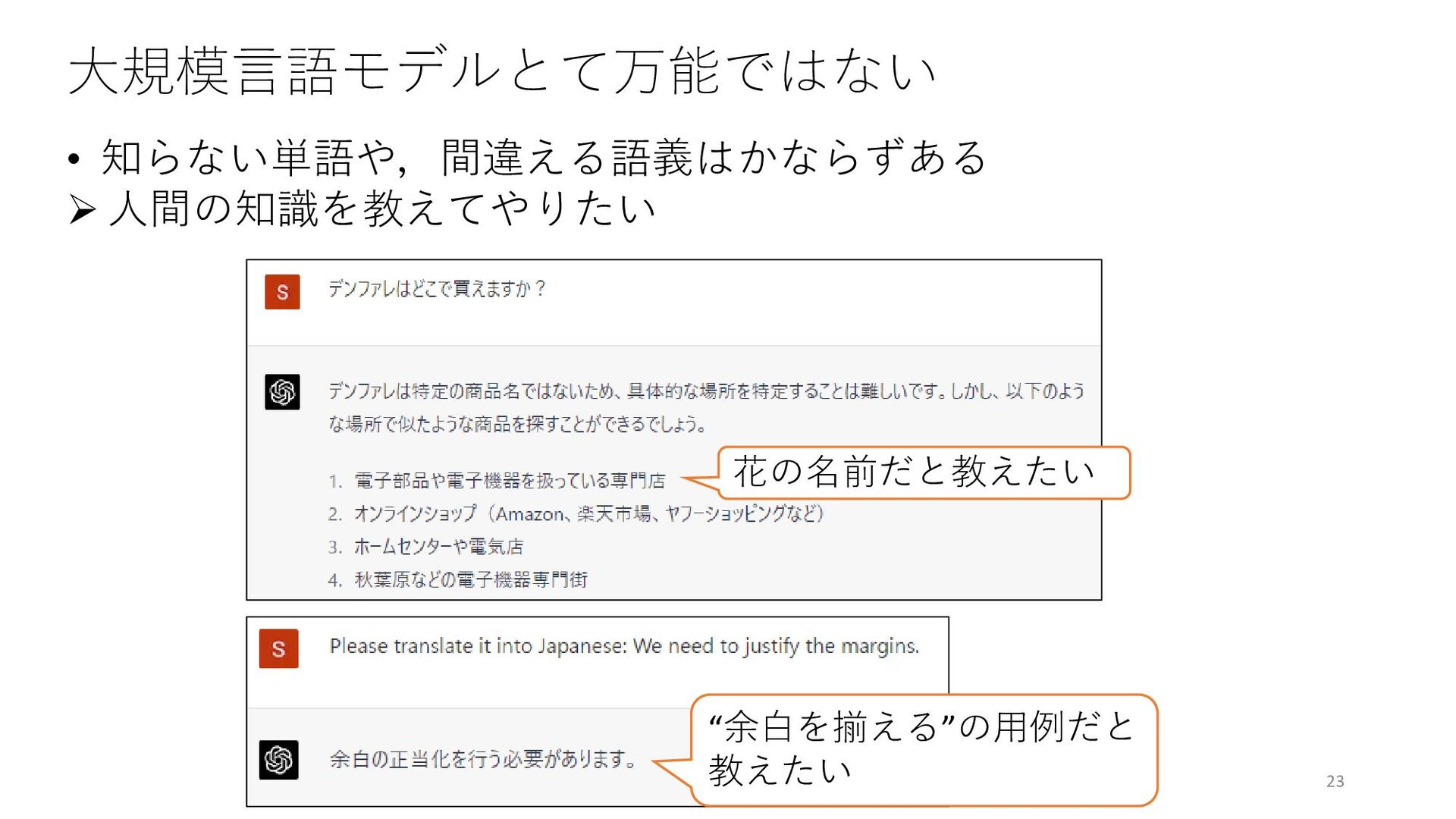
![大規模言語モデルは語義識別が不得意? • Word-in-Context(WiC)[Pilehvar and Camacho-Collados, 2019] という語義識別タスクがある • 文脈語の語義が2文間で同じか違うかを分類するタスク. WSDの亜種[Hauer](https://files.speakerdeck.com/presentations/6e266e25efe447c5bdfab0d7a2e0f124/slide_23.jpg){kind=link}
{kind=link}
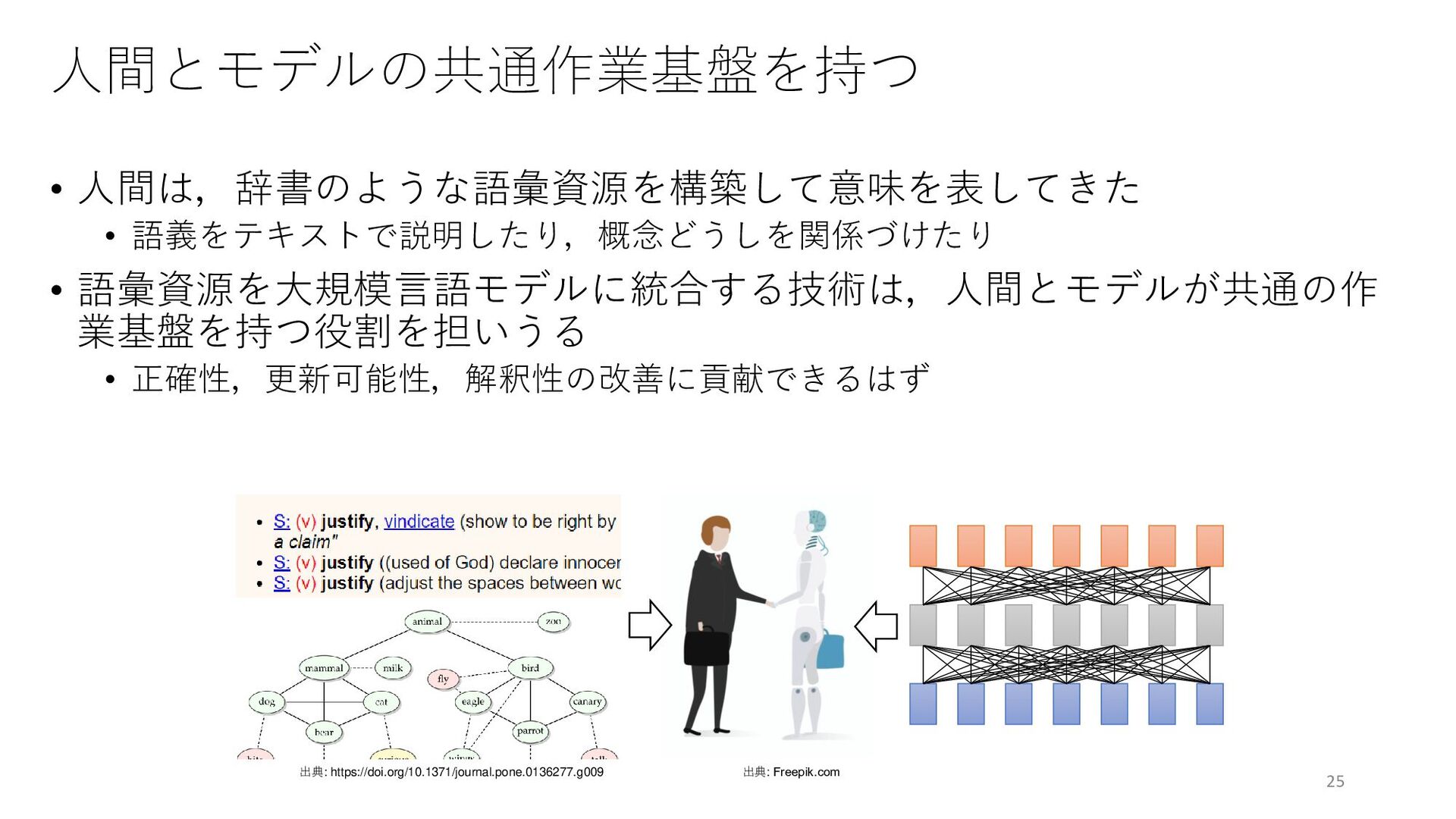
![「事例で学ぶ」から「知識を学ぶ」へ • 大規模言語モデルは構造化知識と相性がよい • 少ない事例で学習できる[Brown+, 2020] • 相応の常識や知識を保持している[Petroni+, 2019] •](https://files.speakerdeck.com/presentations/6e266e25efe447c5bdfab0d7a2e0f124/slide_25.jpg){kind=link}
{kind=link}
![参考文献 • [Campolungo+, 2022] CAMPOLUNGO, Niccolò, et al. DiBiMT: A](https://files.speakerdeck.com/presentations/6e266e25efe447c5bdfab0d7a2e0f124/slide_27.jpg){kind=link}