Bowman. Do latent tree learning models identify meaningful structure in sentences? Transactions of the Association of Computational Linguistics, 6:253–267, 2018. [Yogatama+, 2016] Dani Yogatama, Phil Blunsom, Chris Dyer, Edward Grefenstette, and Wang Ling. Learning to compose words into sentences with reinforcement learning. arXiv preprint arXiv:1611.09100, 2016. [Shen+ 2017] Yikang Shen, Zhouhan Lin, Chin-Wei Huang, and Aaron Courville. Neural language modeling by jointly learning syntax and lexicon. arXiv preprint arXiv:1711.02013, 2017. [Gulordava+ 2018] Kristina Gulordava, Piotr Bojanowski, Edouard Grave, Tal Linzen, and Marco Baroni. Colorless green recurrent networks dream hierarchically. In Proc. of NAACL, pp. 1195–1205, 2018. [Kuncoro+ 2018] Adhiguna Kuncoro, Chris Dyer, John Hale, Dani Yogatama, Stephen Clark, and Phil Blunsom. Lstms can learn syntax-sensitive dependencies well, but modeling structure makes them better. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pp. 1426–1436, 2018. [Lakretz+ 2019] Yair Lakretz, German Kruszewski, Theo Desbordes, Dieuwke Hupkes, Stanislas Dehaene, and Marco Baroni. The emergence of number and syntax units in lstm language models. In Proc. of NAACL, 2019. [Dyer+ 2016] Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, and Noah A Smith. Recurrent neural network grammars. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 199–209, 2016. 30
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Related works • 木構造の導入は(長距離依存関係などに)有効である. • モデル:RNNG[Dyer+ 2016],Recursive NN[Socher+ 2013] •](https://files.speakerdeck.com/presentations/e4f30c9584104a28bf8f41c7be2cae30/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
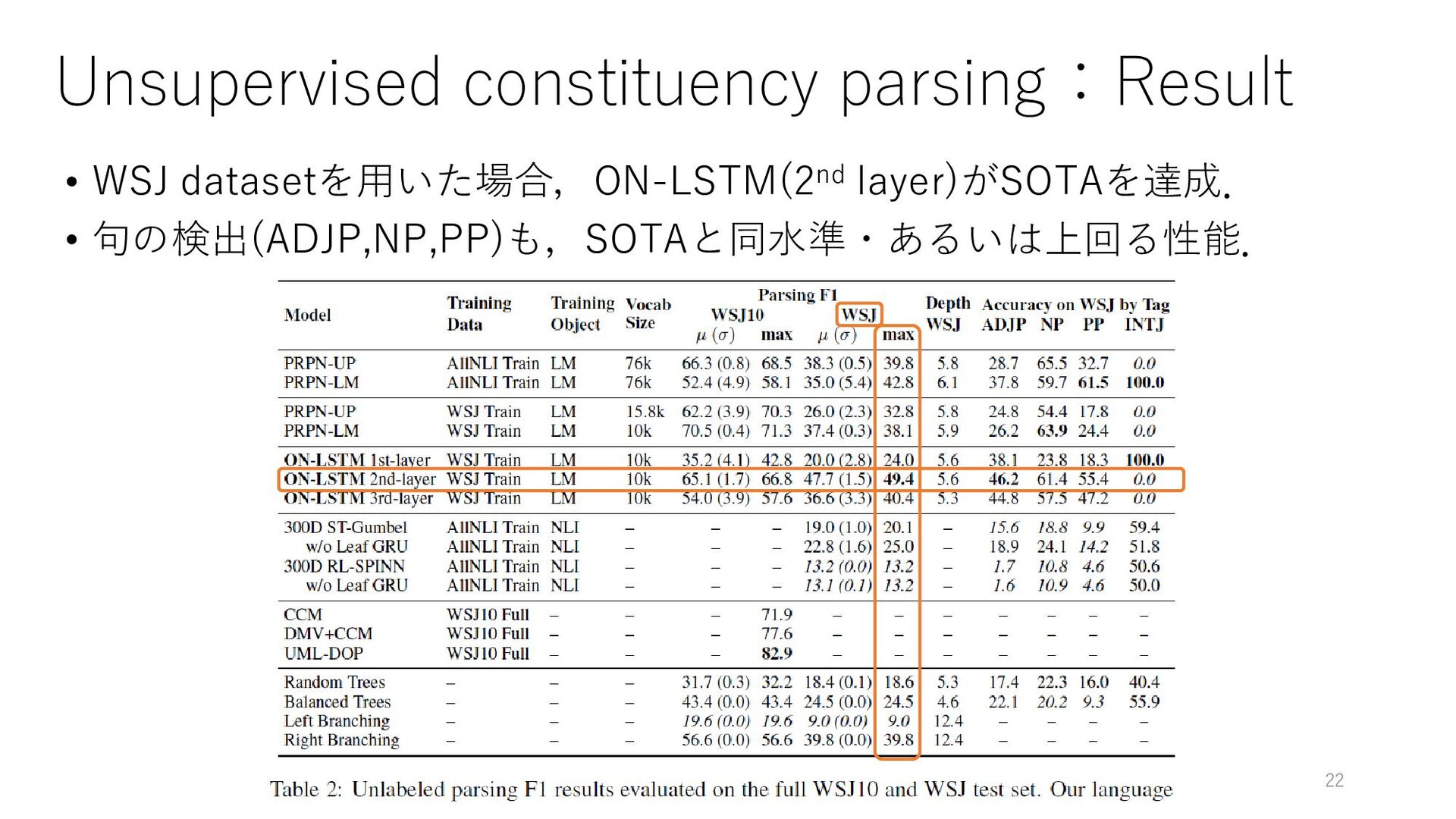{kind=link}
{kind=link}
{kind=link}
{kind=link}
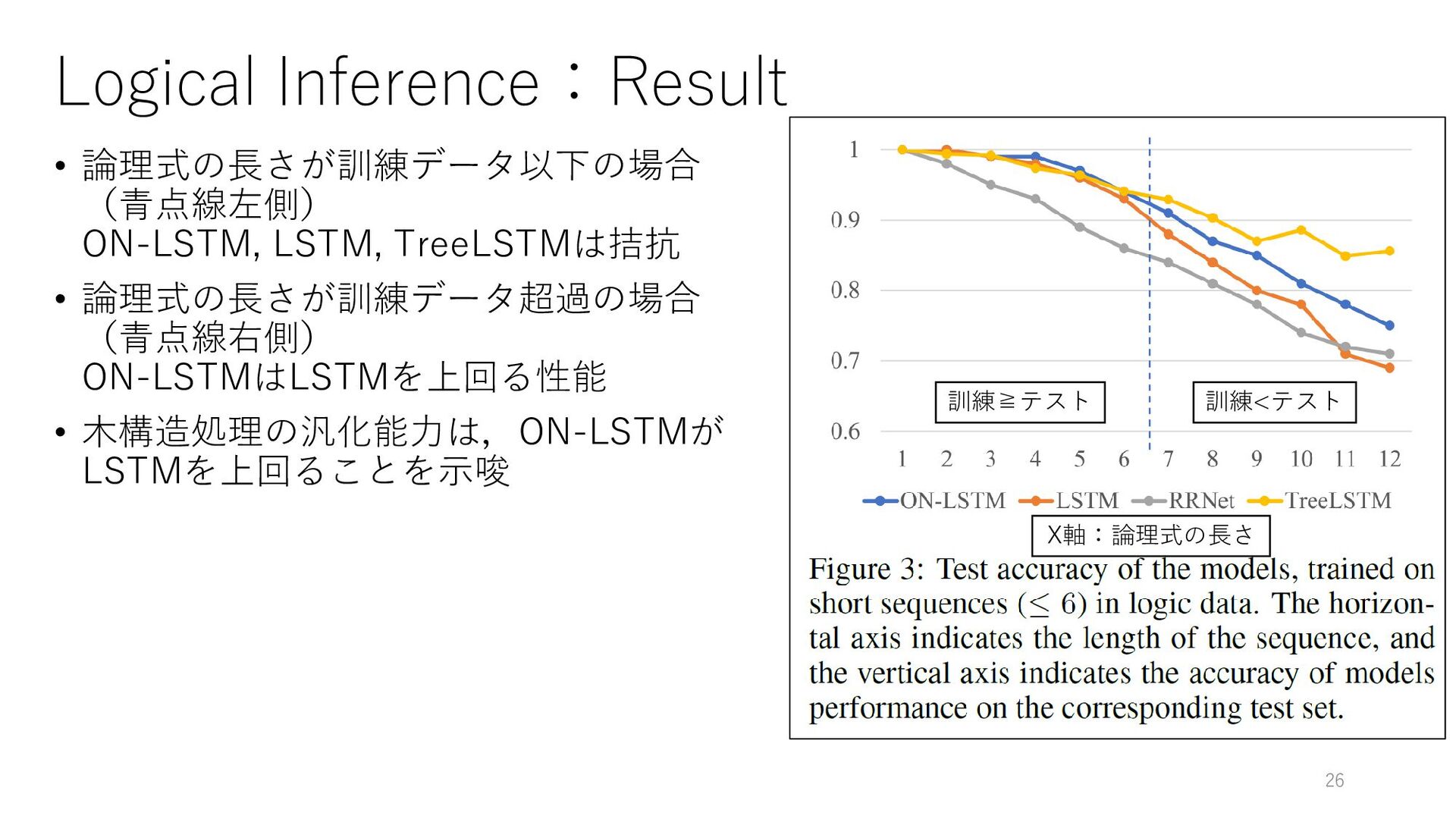{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Referenced Works [Williams+, 2018] AdinaWilliams, Andrew Drozdov*, and Samuel R](https://files.speakerdeck.com/presentations/e4f30c9584104a28bf8f41c7be2cae30/slide_28.jpg){kind=link}
![Referenced Works [Socher+ 2013] Richard Socher, Alex Perelygin, Jean Wu,](https://files.speakerdeck.com/presentations/e4f30c9584104a28bf8f41c7be2cae30/slide_29.jpg){kind=link}
{kind=link}
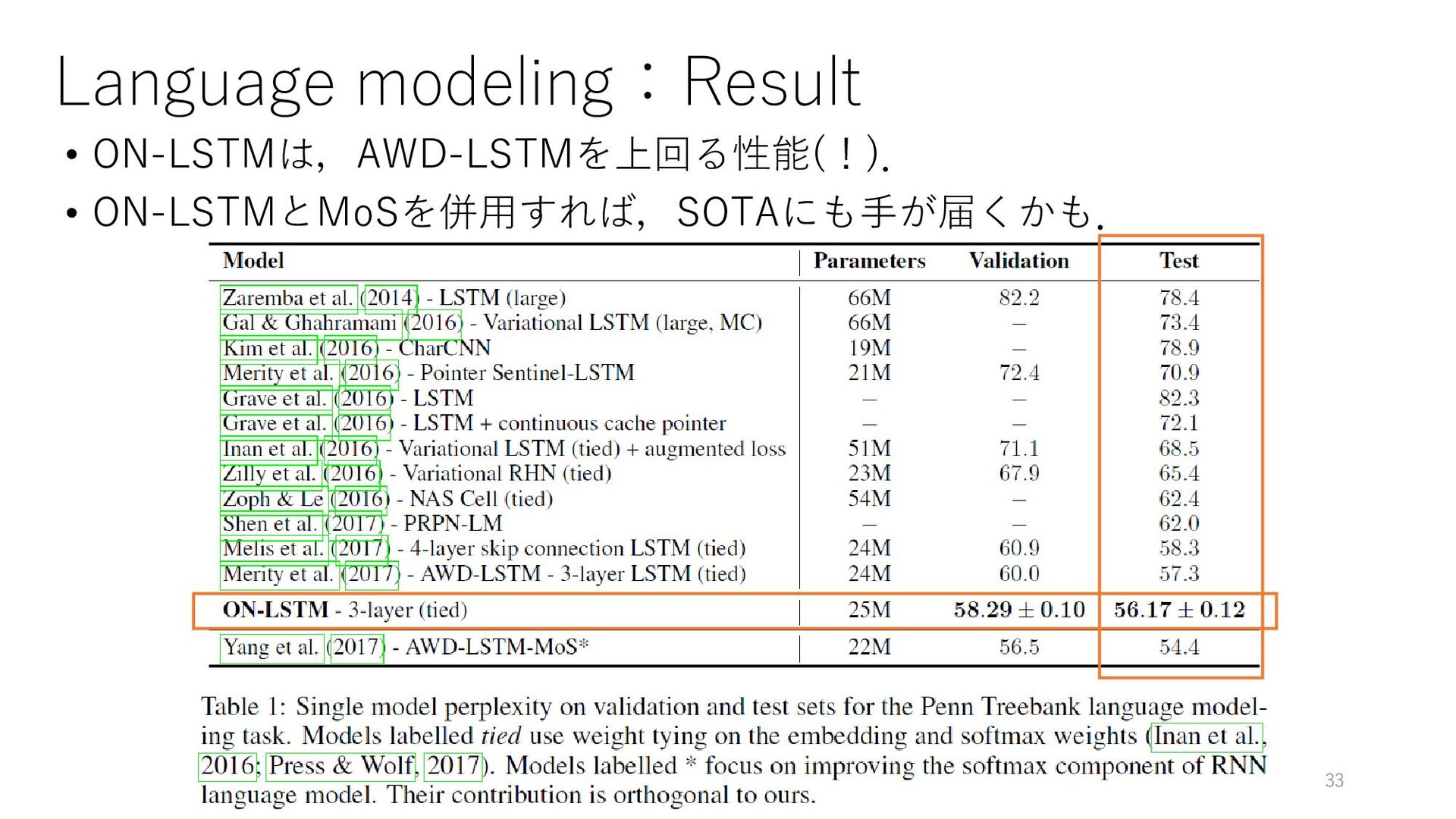{kind=link}
{kind=link}