Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
GCPをフル活用したゲームログ収集基盤の構築
Search
Takumasa Sakao
July 14, 2018
Technology
3.2k
6
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
GCPをフル活用したゲームログ収集基盤の構築
Takumasa Sakao
July 14, 2018
More Decks by Takumasa Sakao
See All by Takumasa Sakao
k9s のプラグイン機構とモダンな watch コマンド、viddy の紹介
sachaos
0
1.6k
Cloud Run でシェルスクリプトを動かす
sachaos
0
2.8k
GAE を利用したゲーム内通貨管理サービスの運用〜可用性を損なわないための工夫〜
sachaos
0
1.3k
Go の静的解析ツールの作成と活用
sachaos
0
3.2k
レイトレーシングとGoroutine
sachaos
2
1.2k
OSSを作っている時に 考えていること ーUNIX哲学を添えてー
sachaos
2
600
Other Decks in Technology
See All in Technology
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
2
2.2k
どうして今サーバーサイドKotlinを選択したのか
nealle
0
210
Road to SRE NEXTの今までとこれから
hiroyaonoe
0
220
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
170
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
350
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
360
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
12
1.8k
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
400
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
0
140
20260702_生成AIはどこまで成長するのか_チャットだけじゃない世界
doradora09
PRO
0
110
AWS Blocks を触ってみた/first-tach-aws-blocks
fossamagna
2
150
知らん間に、回ってる
ming_ayami
0
330
Featured
See All Featured
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
480
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
BBQ
matthewcrist
89
10k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.5k
Tell your own story through comics
letsgokoyo
1
990
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
330
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.1k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
Believing is Seeing
oripsolob
1
170
The Limits of Empathy - UXLibs8
cassininazir
1
400
Transcript
GCPをフル活用した ゲームログ収集 基盤の構築 Rails Developers Meetup 2018 Day 3 Extreme
@sachaos
自己紹介 • @sachaos (サカオスと読みます) • 好きなもの 黒い画面 Golang
OSS をいくつかGitHubで 公開しています • 所属: 株式会社アカツキ 新卒 3 年目 技術基盤開発 Golang, GCP とか ゲーム新規開発・運用 Ruby on Rails, etc 最近仕事で Elixir 書き始めました
Q. ゲームログとはなにか?
Q. ゲームログとはなにか? ゲームログ = プレイヤーの行動の記録 A.
ゲームログの例 ・ ・ ・ • 2018/07/13 16:36:09 sachaos がエリクサーを 5
個手に入れた! • 2018/07/13 16:36:13 sachaos がエリクサーを 3 個消費した! • 2018/07/13 16:38:20 sachaos がクエストをクリアしたよ! • 2018/07/14 01:10:05 sachaos がガチャを引いて強キャラを手に入れた!
Q. なぜログを集めるのか?
Q. なぜログを集めるのか? A. 分析をするため
Q. なぜログを集めるのか? A. 分析をするため データからゲームを遊んでいるプレイヤーの状態、 感情を理解してそれをゲームの改善につなげる。
分析 • 定常的な分析 • アドホックな分析
定常的な 分析
定常的な分析 • DAU (Daily Active User) や 売上など毎日知りたい情報。 • KPI
の達成具合を測り、様々な意思決定をする。 • ダッシュボードで常に表示しておく。 • Slack に定期的に通知するようにしている。
アドホックな 分析
アドホックな分析 • 今後の施策の意思決定のために現状を把握する。 e.g. エリクサーが多く流通している。 次はもう少し難しいイベントを企画してみよう。 • 因果関係を見つける為、仮説を探し検証する。
e.g. 1. 継続率が高い(毎日ログインしている)ユーザーを 分析して見ると他のユーザーに比べて フレンドが多いという結果が出た。 2. これを仮説として、 フレンドを増やす施策を打ち出してみた。 3. これの効果測定(継続率が上がったか否か)をして、 仮説を検証する。
ゲームログを BigQuery に送ることができれば とりあえず分析はできる
しかし、 早く正確に分析するために 遅延・抜け漏れ無く ログを集めたい
GCPをフル活用した ゲームログ収集基盤
GCPをフル活用した ゲームログ収集基盤 Cloud Pub/Sub Cloud Dataflow BigQuery App Engine App
Engine AWS GCP Cloud Dataflow 定期的なバッチ処理 BigQueryと BIツール(Metabase)による分析 ログの収集システム アプリケーション サーバークラスタ
Q. なぜこの構成にしたのか?
Q. なぜこの構成にしたのか? A. GCP が使いたかったから!
Q. なぜこの構成にしたのか? A. GCP が使いたかったから! A. 様々な構成を検討した結果、 一番楽に運用できそうだったから
検討したログ収集システム構成 Fluentd Log Aggregator Pattern 1 AWS Kinesis Firehose 2
AWS Kinesis + Lambda 3 Cloud Pub/Sub + Dataflow 4
Fluentd Log Aggregator Pattern • Pros Fluentd Plugin が豊富なので、簡単に
Aggregator から 様々なデータウェアハウスに送ることができる。 • Cons プラグインごとに設定を細かく行う必要がある。 マネージドサービスはない 自前でサーバーを立てないといけない。 データの送信失敗などを監視・通知するような仕組みを 作らないといけない Log Aggregator が落ち、fluentd の設定不足で ログを欠損させてしまったという苦い思い出もある・・・。
AWS Kinesis Firehose • Pros とりあえず S3 に自動的にデータを転送することができる。 勝手にスケールもする。
• Cons S3 から BigQuery にどうやって格納するか という別の問題が発生する。 Embulk などを使用する?しかしそれでは別のサーバーが必要。 S3 の Put event を検知して AWS Lambda を走らせる? しかし、失敗した場合はどのように再実行させるか?
AWS Kinesis + AWS Lambda • Pros Firehose と比べるとストリームを
Lambda で処理でき、 BigQuery にそのまま投げることができて嬉しい。 エラーが起きた場合はリトライもやってくれる。 • Cons シャード数のチューニングを考えないといけない。
Cloud Pub/Sub + Dataflow • Cloud Pub/Sub アプリケーションのログを一旦ストアしておくために使用する。 メッセージキューサービス。
複数のサブスクライバ(購読者)に対してメッセージを送ることが可能。 BigQuery 向けだけではなく Storage 向けの Dataflow にも購読させ、 両方にデータをストアするようにしている。 • Cloud Dataflow Pub/Sub からデータを取得して BigQuery へインサートする。 Google 提供のテンプレートも存在する Pub/Sub to BigQuery Pub/Sub to Storage 処理するデータ量、計算量に応じて勝手にスケールする。 エラーの際にリトライはもちろん、 コードに問題があった場合は更新もすることができる。 サーバーレスは麻薬。
運用 インフラ管理 バッチによる データ処理の 方法 データ分析の 方法
インフラ管理
インフラ管理 • リソース作成・更新操作が必要 Dataflow の Job の実行 BigQuery
の テーブル定義 Pub/Sub トピックの作成 • これらをコードで管理したい • Terraform でもよかったが GCP API を Rake タスクで叩くようにした。
Q. なぜ GCP API ? A. BigQuery のテーブルのスキーマと ログのスキーマ定義の二重管理を 防ぎたかったから
また、設定項目がシンプルなので API を叩くだけで十分そうだった。
ログのスキーマ定義の二重管理 • BigQuery のスキーマを定義する何か(例えば JSON, DDL)と アプリケーション内でログを表す(例えばクラス)で スキーマ定義が重複する。 • e.g.
signin というユーザーのサインインのログを考える signin.rb signin.json RUBY JSON LOG ログデータ BigQuery の signin テーブル
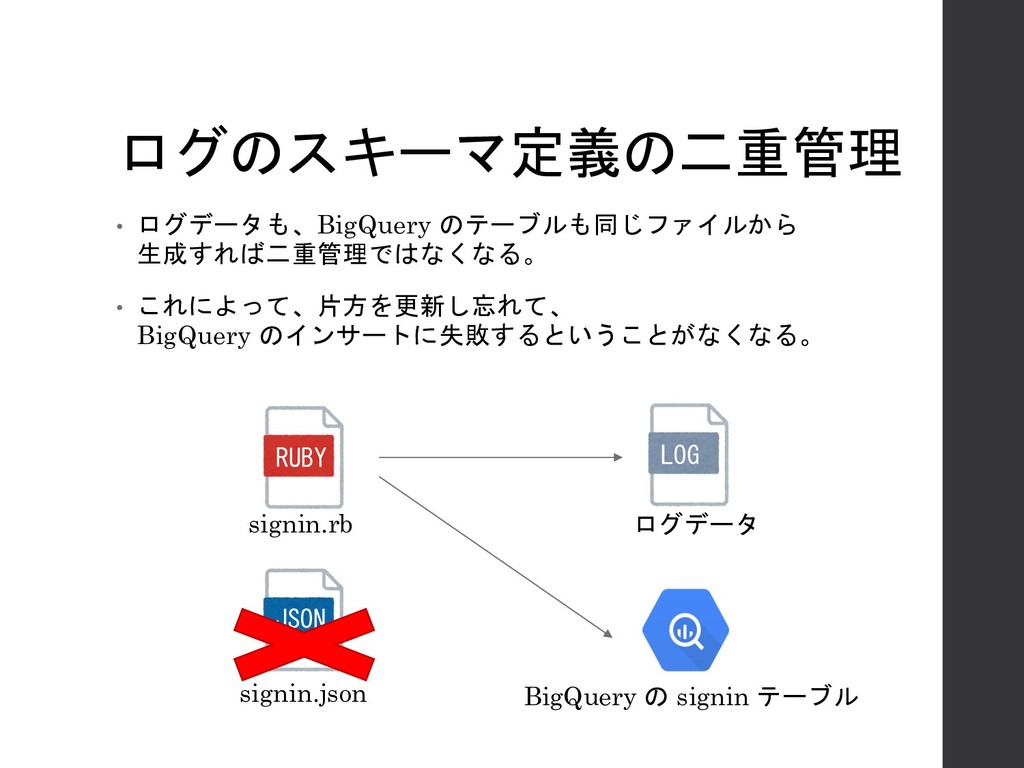
ログのスキーマ定義の二重管理 • ログデータも、BigQuery のテーブルも同じファイルから 生成すれば二重管理ではなくなる。 • これによって、片方を更新し忘れて、 BigQuery のインサートに失敗するということがなくなる。 signin.rb
signin.json RUBY JSON LOG ログデータ BigQuery の signin テーブル
Schema をログクラスに定義 テーブル名を 定義 各フィールドの 型を定義
Schema から BigQuery のテーブルを作成 先ほどのクラス を取得 BigQuery API の形式に調整 APIを叩いて
テーブル作成
バッチによる データ処理の方法
定常的な分析を行うために • 定期的に(Cron のように)分析を行う。 • 分析のための中間テーブルを作成する。
バッチ処理をやるにも GCP では様々な選択肢がある。 • Cloud Dataflow バッチ、ストリーム両方に対応した ETL サービス。
• Cloud Functions AWS の Lambda のようなもの いわゆる FaaS • Google App Engine AWS Elastic beanstalk, heroku のようなもの いわゆる PaaS Standard Environment と Flexible Environment がある。 SE の方が、 FE に比べて様々な制限があるが、 よりサーバーレスをキメることができる。 デプロイ早い! スケールも爆速!
クエリ一発で終わって 結果セットが小さい物は GAE。 それ以外は Dataflow。 • クエリ1発で結果セットが小さい物は Cloud Dataflow で実行させる必要がない。
例えば、売上を計算する場合結果セットは 1 レコードで済む しかし、ユーザーごとの売り上げを計算する場合は ユーザーごとにレコードがあり、結果セットが大きい。 • Dataflow は実行のオーバーヘッドがかなり大きいので、 小さなものを処理させるのには向いていない。 • GAE を使用すると GAE Cron Serviceと組み合わせることもできて楽。
データ分析の方法
定常的な分析、ダッシュボード • Google App Engine Flexible Environment を使って 試験的に Metabase
を動かしている。 • が、Metabase のつらみは結構ある。。。 BigQuery Standard SQL の相性が悪い。 複合グラフが作れない Slack の public チャンネルにしか投稿できない etc • Re:dash, Google Data Studio の導入を検討中。
まとめ • ユーザーを正しく分析するために早く正確な分析基盤を 作ることが大事です。 • GCP をフル活用したゲームログ収集基盤の構築とそこに 至った過程、運用方法の共有を行いました。 • GCP
のマネージドサービスは 本当にマネージドされている感があって 運用フローも楽に構築できた印象です。
以上です。 ご静聴ありがとうございました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}