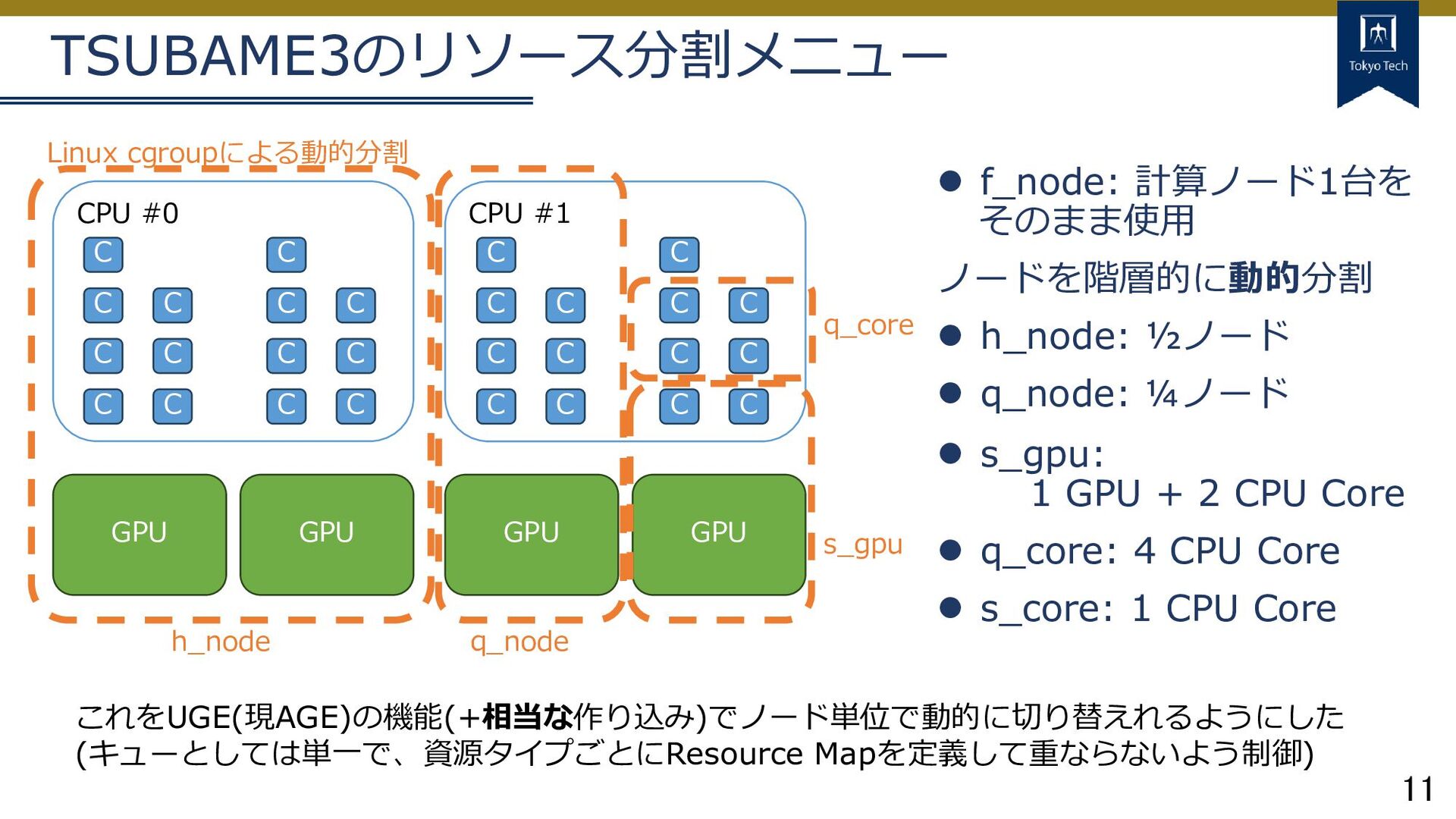
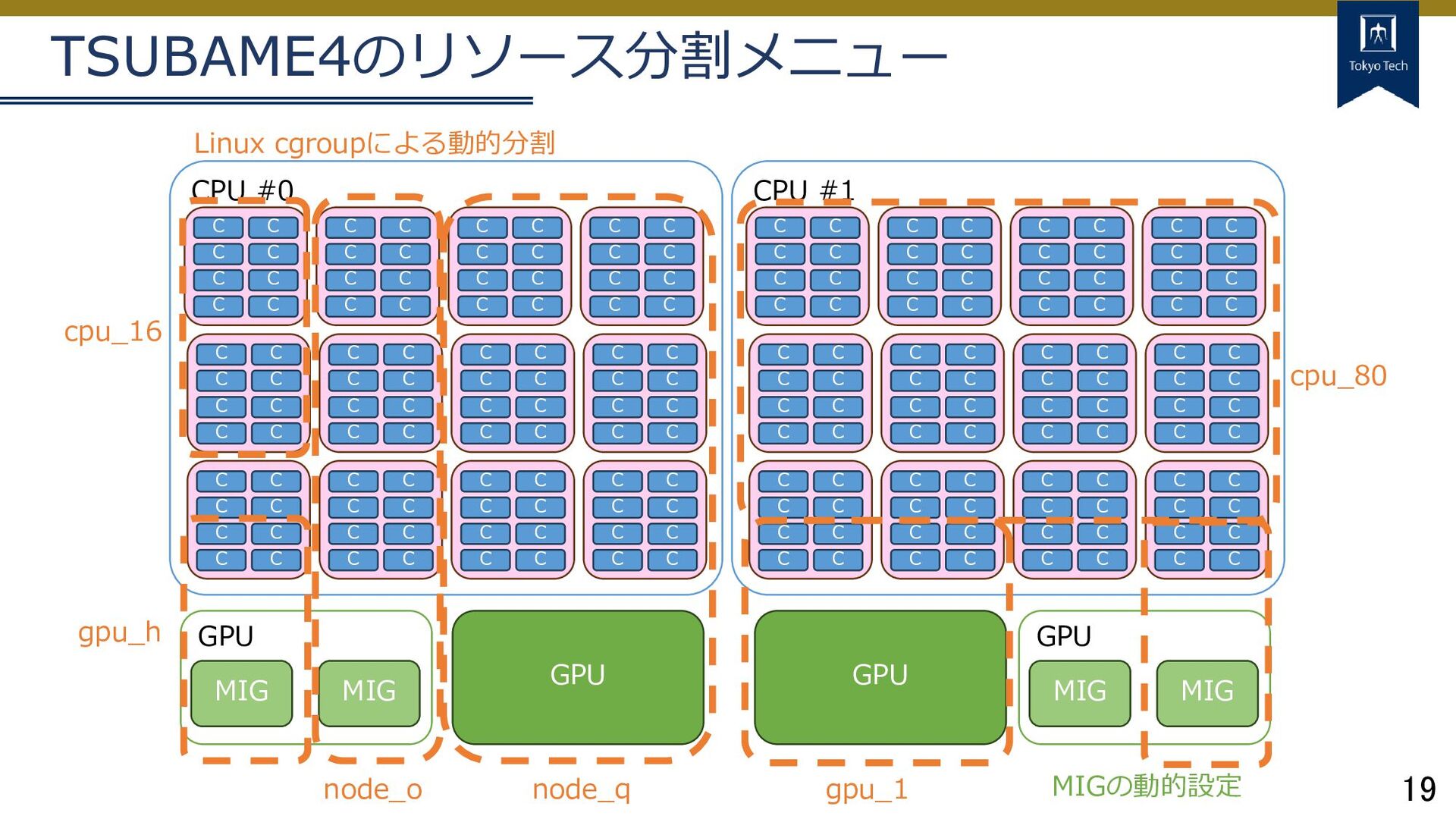
⚫ q_node: ¼ノード ⚫ s_gpu: 1 GPU + 2 CPU Core ⚫ q_core: 4 CPU Core ⚫ s_core: 1 CPU Core これをUGE(現AGE)の機能(+相当な作り込み)でノード単位で動的に切り替えれるようにした (キューとしては単一で、資源タイプごとにResource Mapを定義して重ならないよう制御) GPU GPU GPU CPU #0 CPU #1 C GPU C C C C C C C C C C C C C C C C C C C C C C C C C C C h_node q_node s_gpu q_core Linux cgroupによる動的分割
C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C CPU #1 C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C GPU GPU GPU MIG MIG node_q MIGの動的設定 node_o gpu_h GPU MIG MIG cpu_16 gpu_1 cpu_80 Linux cgroupによる動的分割
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}