из себя представляют данные: - Распределение значений переменной • Есть ли между признаками заметная связь: - Визуализация отношений переменных: точечные графики - Корреляция • В перспективе: построить предсказательную модель — предсказывать значение неизвестной целевой переменной по значениям известных признаков
• 506 образцов • Здесь больше нет archive.ics.uci.edu/ml/datasets/Housing • Осталось здесь archive.ics.uci.edu/ml/machine-learning-databases/housing/ • Или поиск по датасетам на Каггле: www.kaggle.com/altavish/boston-housing-dataset
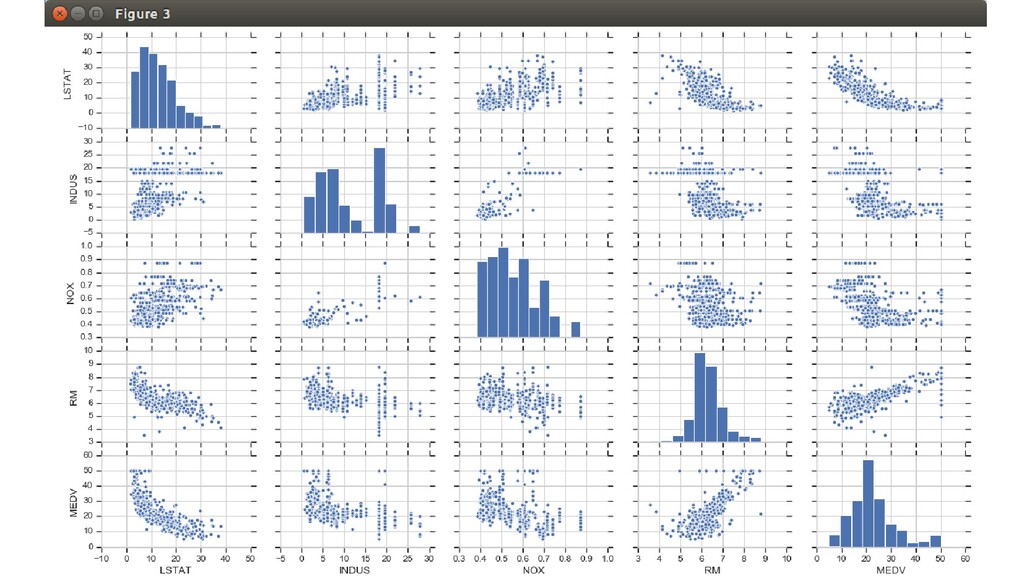
по городам • ZN: доля жилых земельных участков, предназначенных для лотов свыше 25000 кв. футов • INDUS: доля акров нерозничного бизнеса в расчете на город • CHAS: фиктивная переменная реки Чарльз (~1, если участок ограничивает реку, иначе 0) • NOX: концентрация окислов азота (частей на 10 млн.) • RM: среднее число комнат в жилом помещении • AGE: доля занимаемых владельцами единиц, построенных до 1940 г.
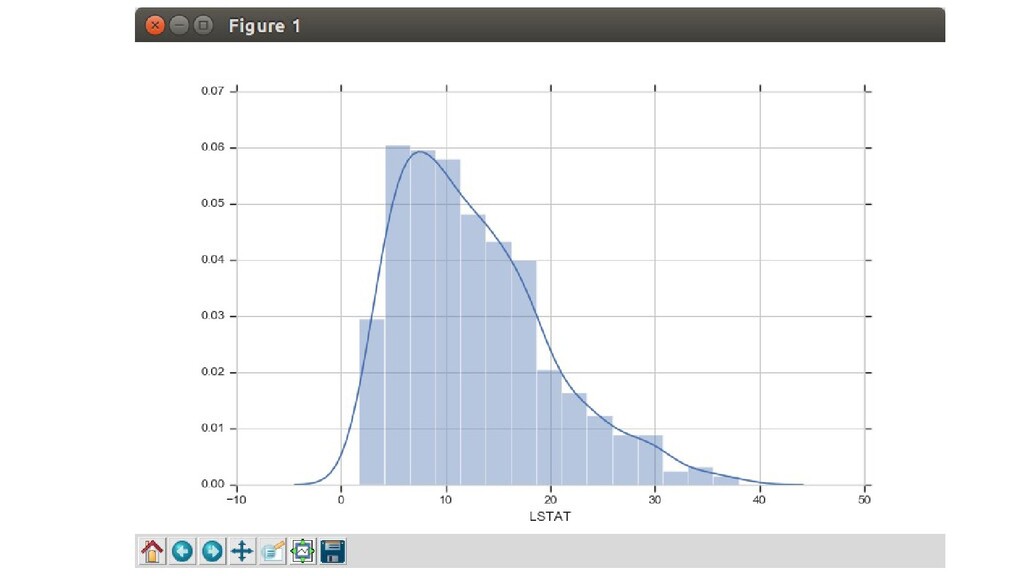
центров занятости • RAD: индекс доступности к радиальным шоссе • TAX: полная ставка налога на имущество на 10 тыс долларов • PTRATIO: соотношение ученик-учитель по городу • B: вычисляется как 1000 (Bk - 0.63)^2, где Bk — доля людей афроамериканского происхождения по городу • LSTAT: процент населения с более низким статусом • MEDV: медианная стоимость занимаемых владельцами домов (в тыс долларов)
matplotlib seaborn.pydata.org • pip install --user seaborn (на Python 2.7 может потребоваться обновить pip до 19-й версии или выше, иначе ругается на зависимости) pip install --upgrade pip
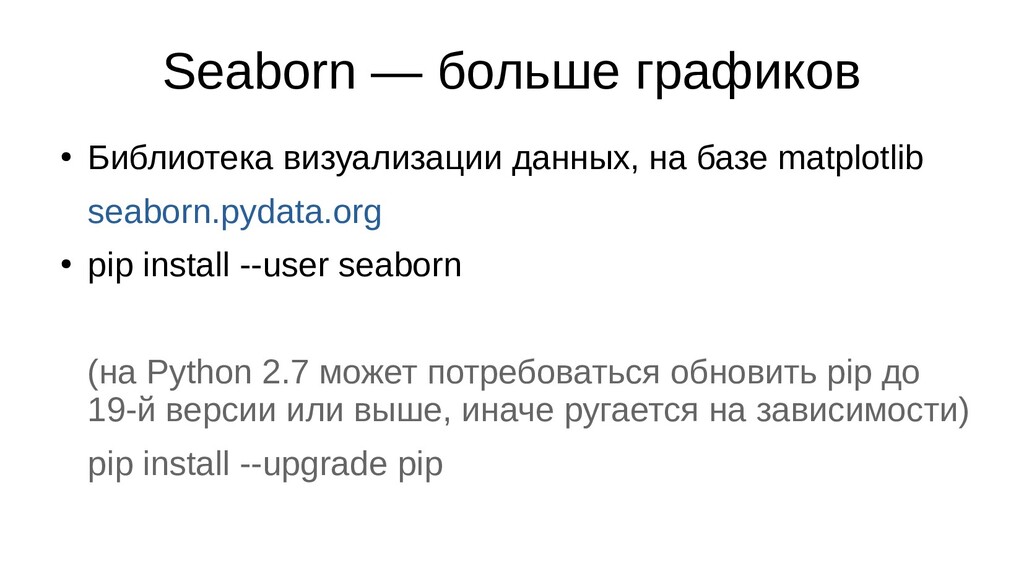
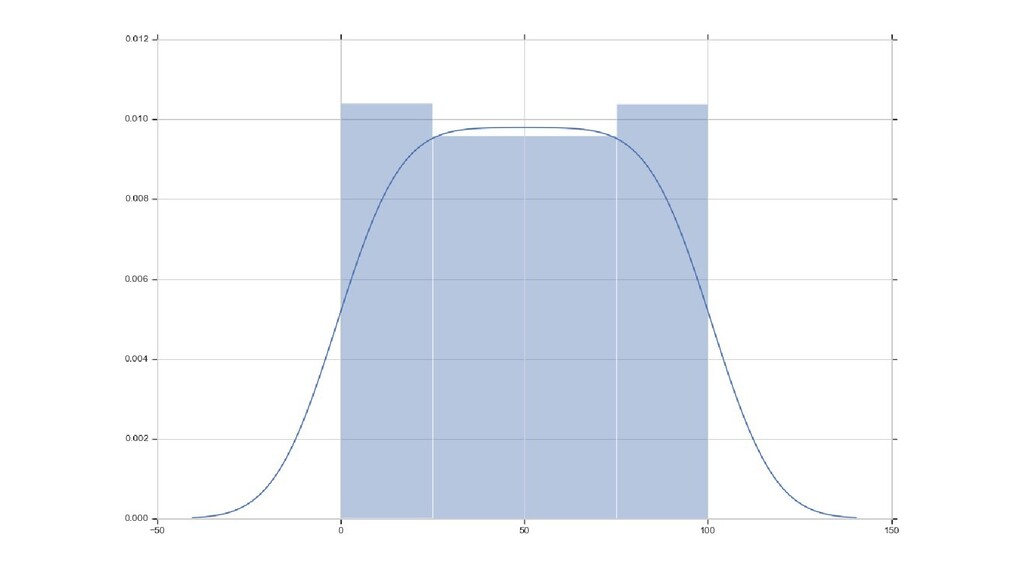
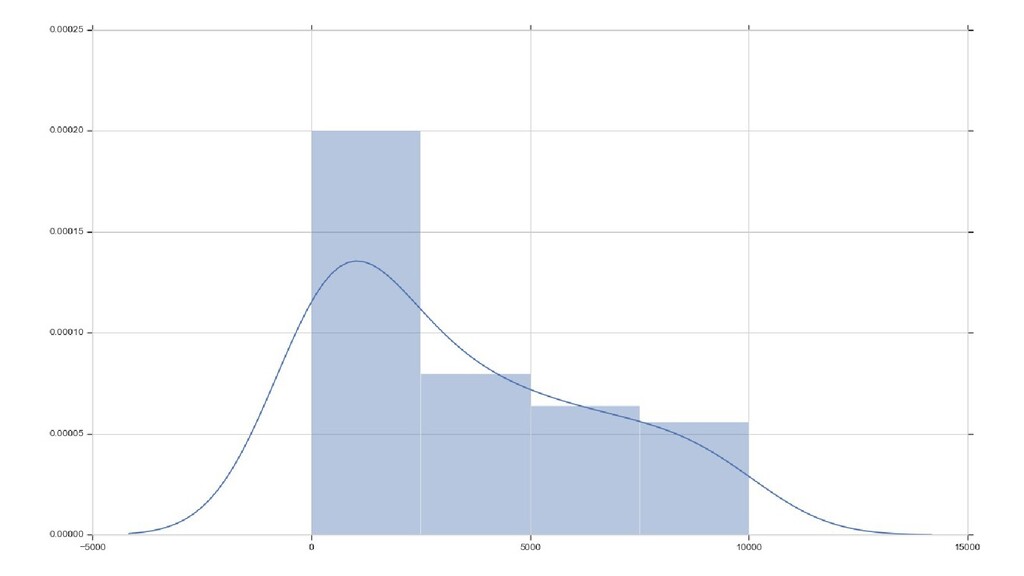
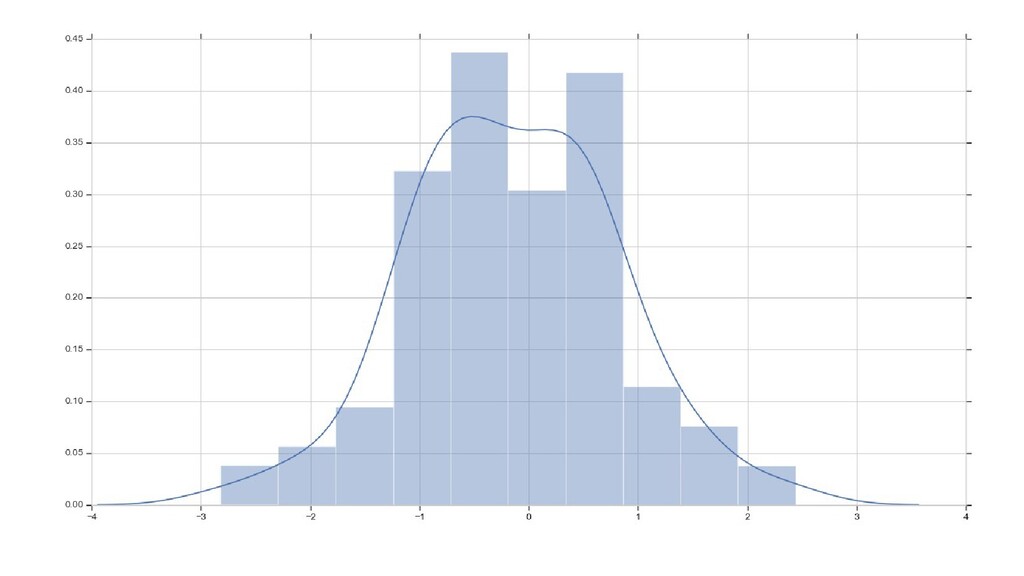
distribution) случайной величины seaborn.pydata.org/generated/seaborn.distplot.html stackoverflow.com/questions/51666784/what-is-y-axis-in-seaborn-distplot • По X — значения параметра, разбитые на группы (диапазоны) (столбцы гистограммы — группы значений) • По Y: площадь столбца — вероятность появления значения из данного диапазона (грубо: нормализованное количество элементов в каждой группе) • сумма площадей всех столбцов графика равна 1
признака X m как выборку значений случайной величины — по одному результату «эксперимента» на строку • Основываясь на значениях выборки, мы можем посчитать вероятность попадания значения в тот или иной диапазон на шкале • Чем больше значений выборки (значений признака X m ) попадают в данный диапазон, тем больше вероятность в него попасть.
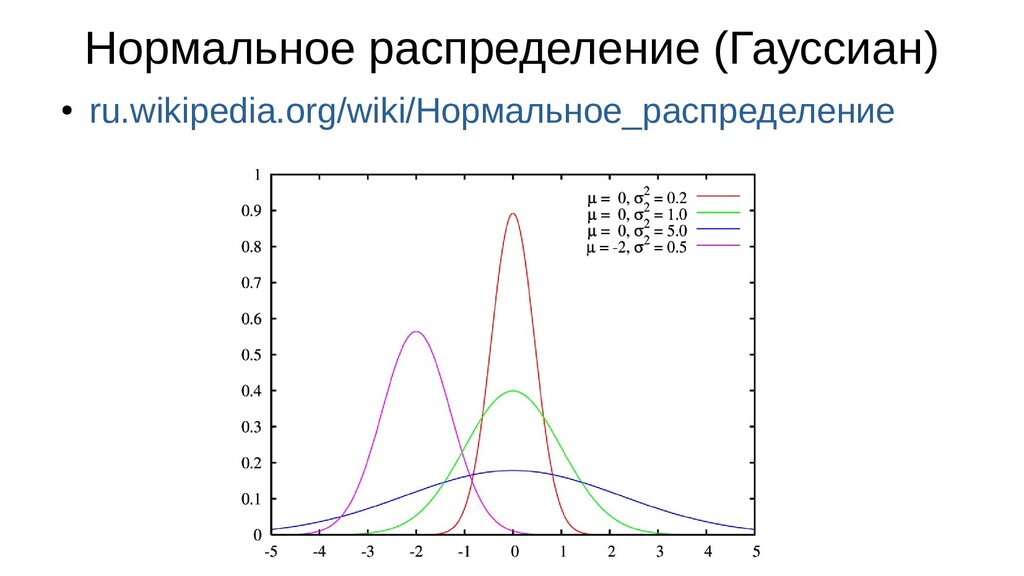
• Стандартное отклонение — показатель рассеивания случайной величины относительно её матожидания • Стрелок целится в мишень: он не всегда будет в нее попадать, но скорее всего выстрелы буду ложиться где-то недалеко - Мишень — матожидание выстрела - Чем меньше стандартное отклонение, чем ближе выстрелы ложатся к центру мишени
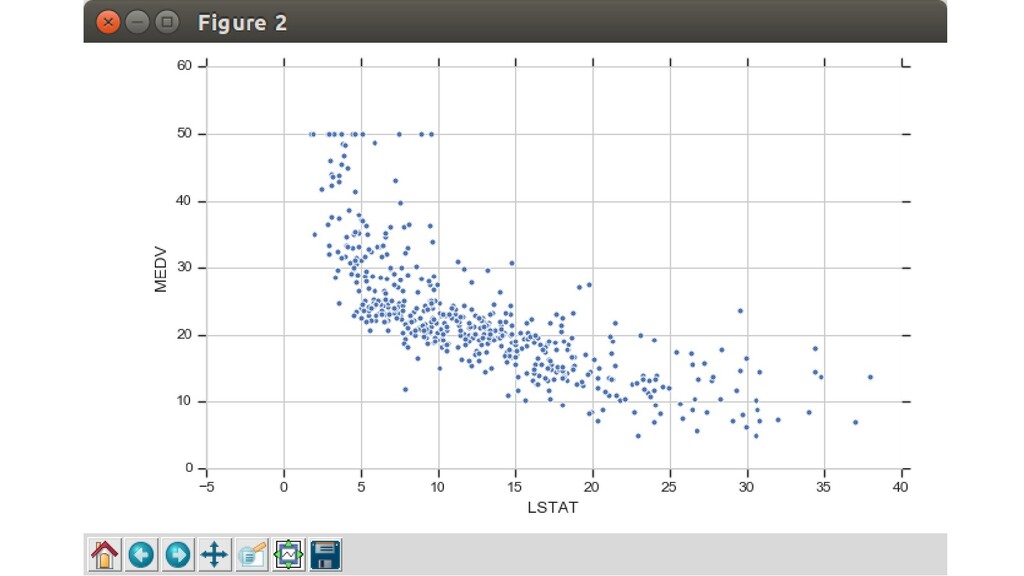
симпатичная сетка на белом фоне sns.set(style='whitegrid') # LSTAT: процент населения с низким статусом # MEDV: медианная стоимость домов sns.relplot(x='LSTAT', y='MEDV', data=df) plt.show()
доля акров нерозничного бизнеса в расчете на город • NOX: концентрация окислов азота (частей на 10 млн.) • RM: среднее число комнат в жилом помещении • MEDV: медианная стоимость занимаемых владельцами домов (в тыс долларов)
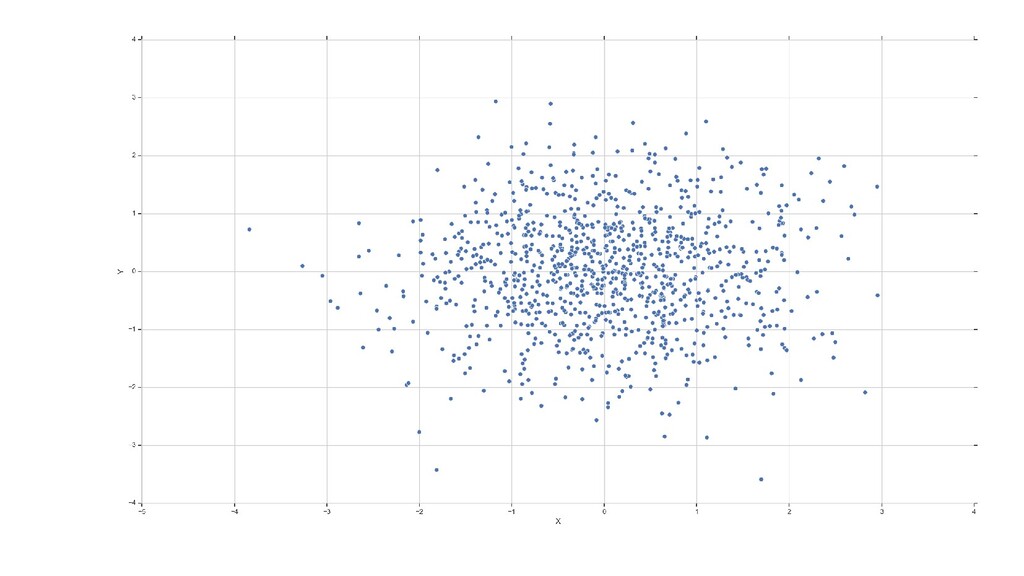
друга, тем сильнее они коррелируют • Чем больше данных отражено в каждой точке (значение элемента) и чем больше элементов в выборке (протяженность наблюдений по времени), тем наблюдаемая корреляция достовернее
= x • r = -1 для любого y = -x • r = 1 для любого y = kx, если k > 0 • r = -1 для любого y = kx, если k < 0 • r = 1 для любого y = kx + c, если k > 0 • r = -1 для любого y = kx + c, если k < 0
доля акров нерозничного бизнеса в расчете на город • NOX: концентрация окислов азота (частей на 10 млн.) • RM: среднее число комнат в жилом помещении • MEDV: медианная стоимость занимаемых владельцами домов (в тыс долларов)
Здесь списка палитр нет: seaborn.pydata.org/tutorial/color_palettes.html seaborn.pydata.org/generated/seaborn.color_palette.html • Здесь есть: matplotlib.org/examples/color/colormaps_reference.html • Или задать некорректное значение в cmap и полный список доступных палитр будет выведен вместе с ошибкой в консоль • Для тепловой карты хорошее значение cmap='RdYlBu_r' (красный- желтый-синий)
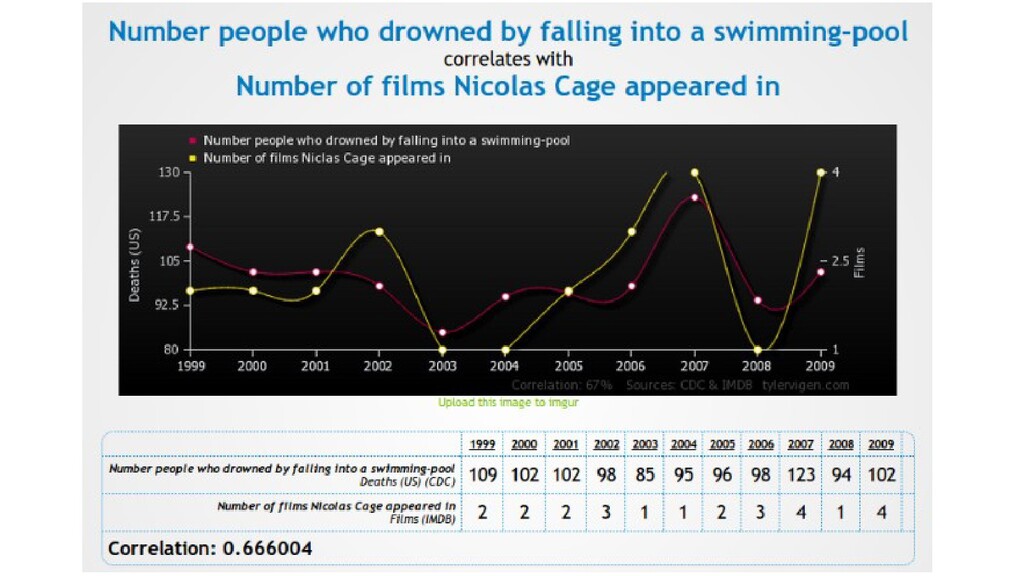
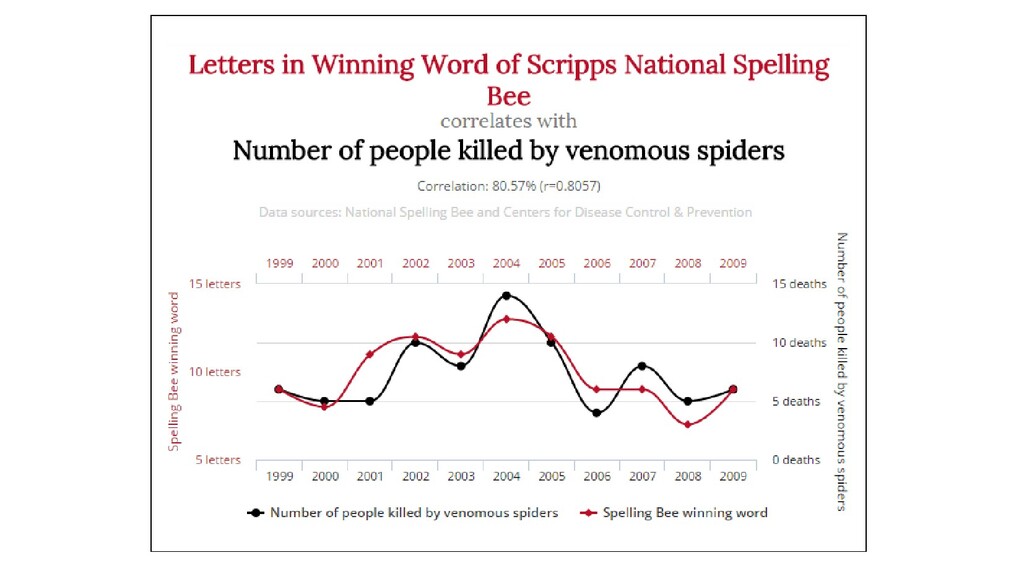
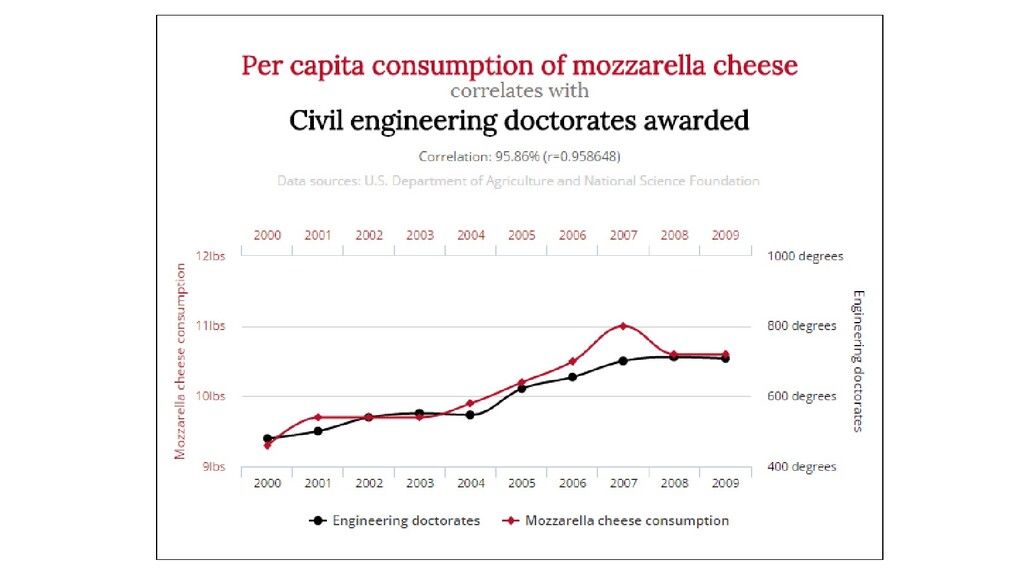
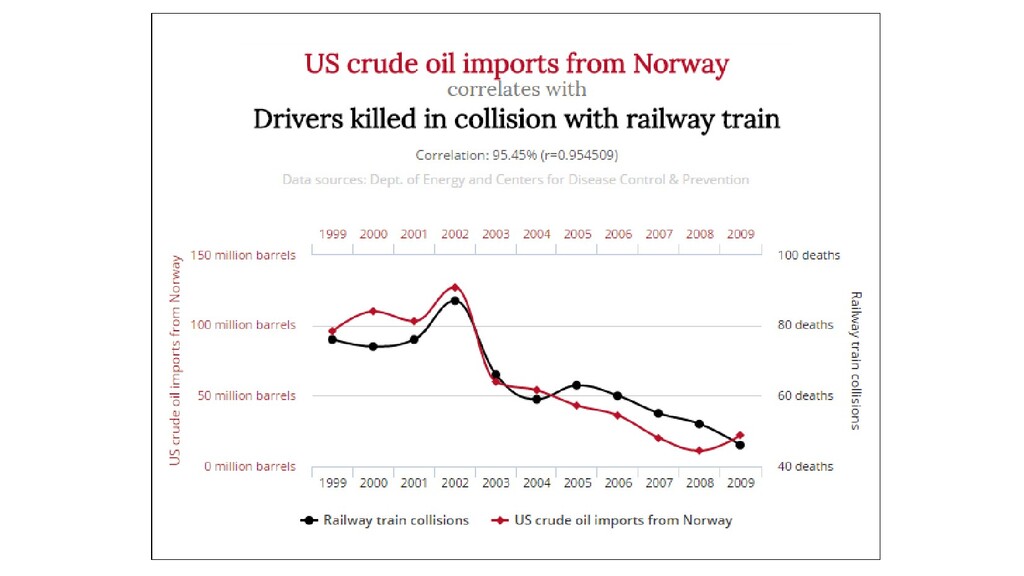
формуле • На оба события может влиять 3-я причина (любые сезонные явления скорее всего будут коррелировать) • Смотрите на объем собранных данных для каждого элемента и продолжительность наблюдений
(источники) • Проверить вычисления, приведенные на графике (фактчек) • Убедиться, что источники содержат актуализированные данные за период времени после 2009 года • Вычислить корреляцию для новых данных (2009-2019) • Построить новый график и вычислить корреляцию для всего периода (1999 — 2019) • еще: www.tylervigen.com/spurious-correlations
Housing Market www.kaggle.com/c/sberbank-russian-housing-market/data • Высказать интуитивные гипотезы на основе названий колонок • Провести разведочный анализ датасета: построить графики распределений и отношений переменных, точечные графики, посчитать попарные коэффициенты корреляции, тепловая карта корреляций • Выявить признаки, которые наилучшим образом коррелируют • Построить для них предсказательные модели
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
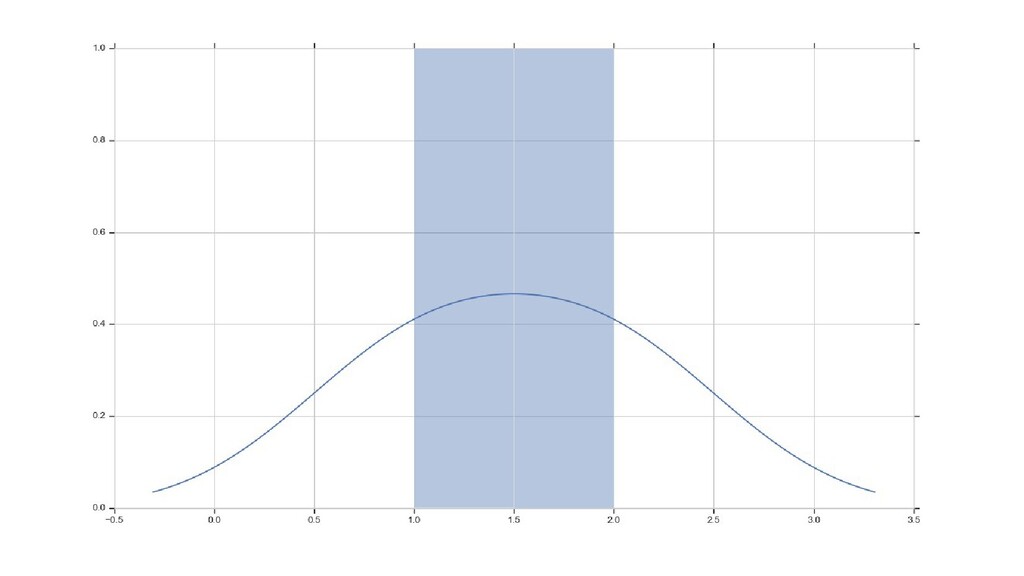
![distplot-demo.py # здесь обе строки покажут один результат sns.distplot(np.array([1,2])) sns.distplot(np.array([1,1,2,2]))](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_14.jpg){kind=link}
{kind=link}
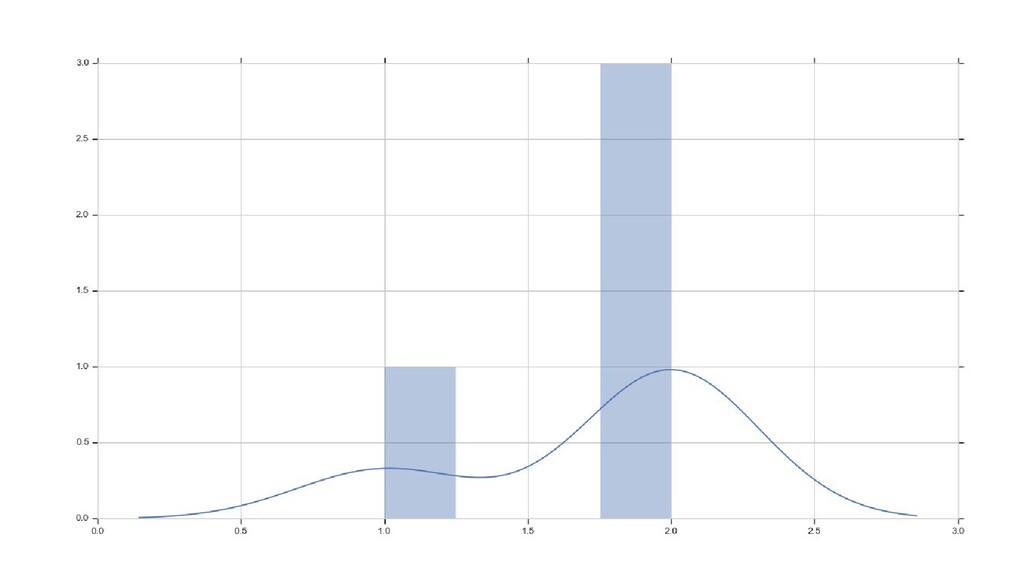
![distplot-demo.py sns.distplot(np.array([1,1,2,2,2,2,2,2]))](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
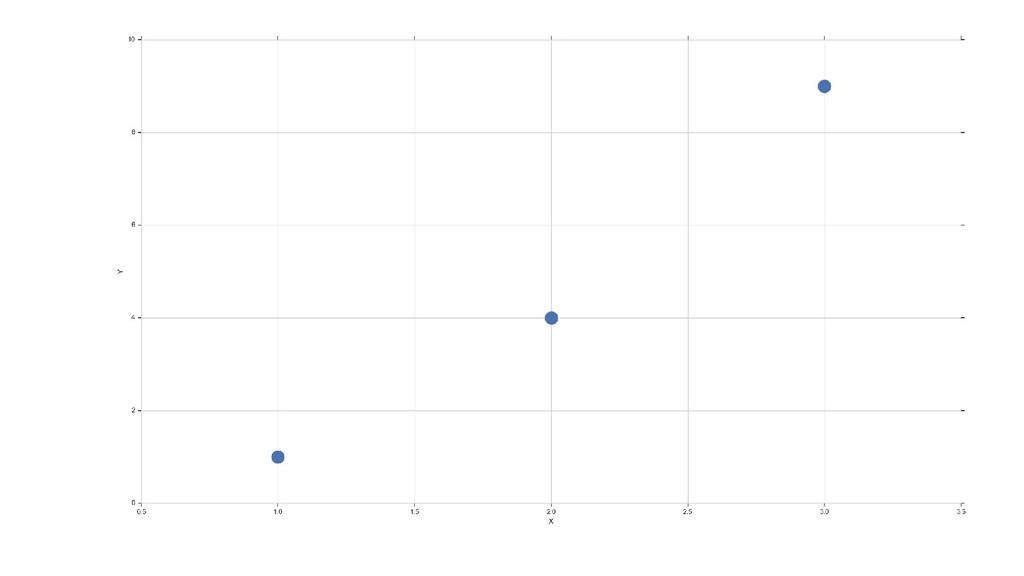
![relplot-demo.py df = pd.DataFrame( data={'X': [1,2,3], 'Y': np.array([1,2,3])**2}) sns.relplot(x='X', y='Y',](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Пример 1 • x = [1, 2, 3] • y](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_52.jpg){kind=link}
{kind=link}
![Пример 2 • x = [1, 2, 3] • y](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_54.jpg){kind=link}
![Пример 3 • x = [1, 2, 3] • y](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_55.jpg){kind=link}
![Пример 4 • x = [1, 2, 3] • y](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_56.jpg){kind=link}
![Пример 5 • x = [1, 2, 3] • y](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Матрица корреляций: numpy.corrcoef # возьмем правое верхнее значение: print(np.corrcoef([[1,2,3], [1,2,3]])[0][1])](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_61.jpg){kind=link}
![Матрица корреляций: numpy.corrcoef # матрица 3x3 print(np.corrcoef([[1,2,3], [1,8,27], [11,19,0]])) [[](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_62.jpg){kind=link}
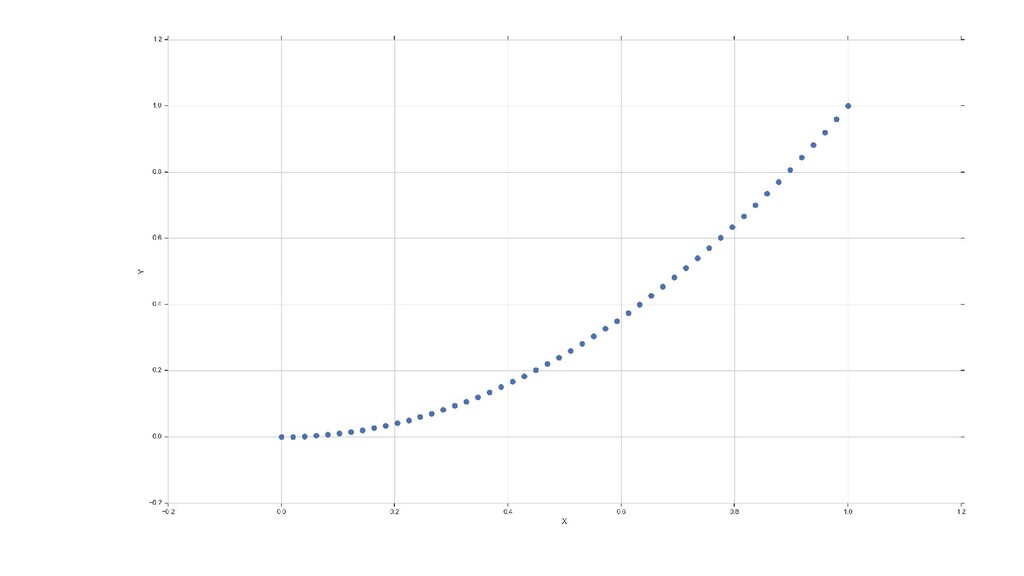
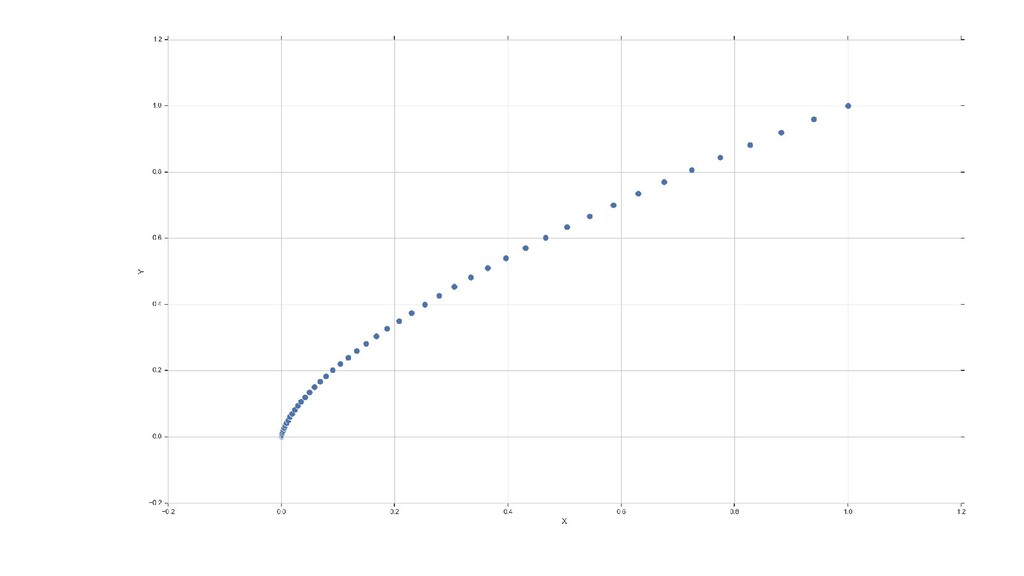
![Матрица корреляций: numpy.corrcoef x=np.linspace(0,100) y=x**3 print(np.corrcoef([x, y])[0][1]) y=x**3-x**2 print(np.corrcoef([x, y])[0][1])](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_63.jpg){kind=link}
{kind=link}
{kind=link}
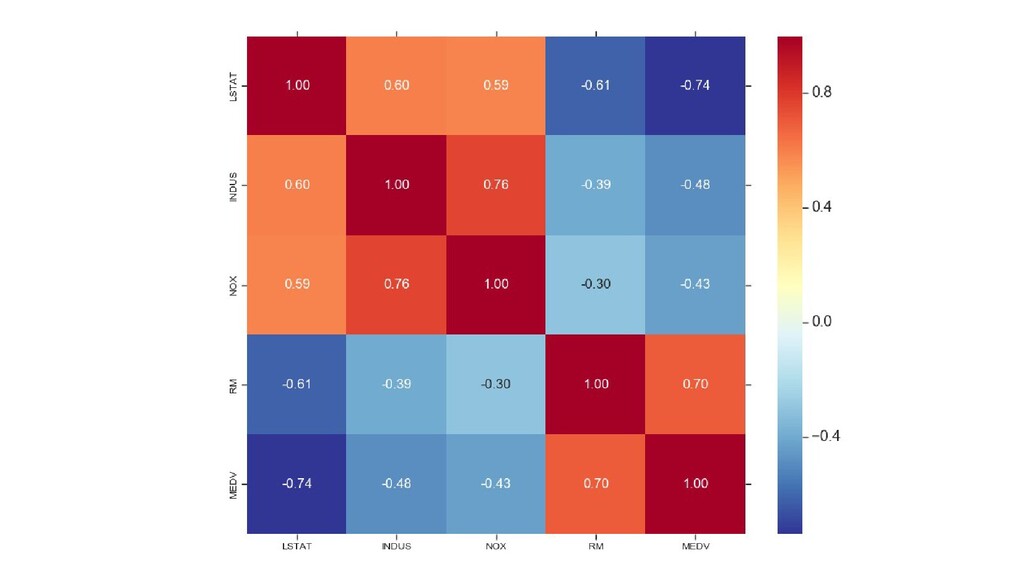
![boston-housing.py cols = ['LSTAT', 'INDUS', 'NOX', 'RM', 'MEDV'] # .T](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_66.jpg){kind=link}
![В консольке [[ 1. 0.60379972 0.59087892 -0.61380827 -0.73766273] [ 0.60379972](https://files.speakerdeck.com/presentations/c3041d86ff5146f2bb0af0deb2cfd901/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}